SQL Tuning Practices - Index Failure Caused by Collations
According to discussions on the OceanBase community forum, the engineers on duty can provide prompt technical support for addressing simple issues that arise during installation and deployment.
However, if you encounter performance optimization issues, you may need to wait until R&D engineers are free to provide troubleshooting suggestions.
To enhance our SQL tuning capabilities, I intend to record and summarize key issues identified in the OceanBase community forum and share them with everyone for mutual progress.
Background
This section introduces two terms: character set and collation, as well as two common hints: LEADING and USE_NL. If you have understood the terms and hints, you can ignore the section.
Character sets
To put it simply, character sets define how characters are encoded and stored. Here is an example:
- If the character set is
utf8, the uppercase letter "A" is encoded as the byte 0100 0001, which is represented as 0x41 in hexadecimal. - If the character set is
utf16, the uppercase letter "A" is encoded as two bytes 0000 0100 0000 0001, which is represented as 0x0041 in hexadecimal.
Different character sets support the storage of different types and ranges of characters. For example, the utf8 character set can store all Unicode characters, whereas the latin1 character set supports the storage of only characters from Western European languages.
Collations
A collation is an attribute of character sets. It defines a set of rules for comparing and sorting characters. For example, the utf8mb4 character set supports collations such as utf8mb4_general_ci, utf8mb4_bin, and utf8mb4_unicode_ci.
utf8mb4_general_ci: the case-insensitive general collation ofutf8mb4.utf8mb4_bin: the case-sensitive binary collation ofutf8mb4.utf8mb4_unicode_ci: the Unicode-based case-insensitive collation ofutf8mb4.utf8mb4also supports collations for different languages, such asutf8mb4_zh_pinyin_ci, which sorts data by Pinyin.
A character set can have multiple collations. However, a collation belongs to only one character set. For example, if you define a column as c3 varchar(200) COLLATE utf8mb4_bin, the character set of the column is automatically set to utf8mb4.
Common hints
Compared with the optimizer behaviors of other databases, the behaviors of the OceanBase Database optimizer are dynamically planned, and all possible optimal paths have been considered. Hints are mainly used to explicitly specify the behavior of the optimizer, and SQL queries are executed based on hints.
This section introduces the following two common hints: LEADING and USE_NL.
- The
LEADINGhint specifies the order in which tables are joined. The syntax is as follows:/*+ LEADING(table_name_list)*/. You can use()intable_name_listto indicate the join priorities of right-side tables to specify a complex join. It is more flexible than theORDEREDhint.
Here is an example:
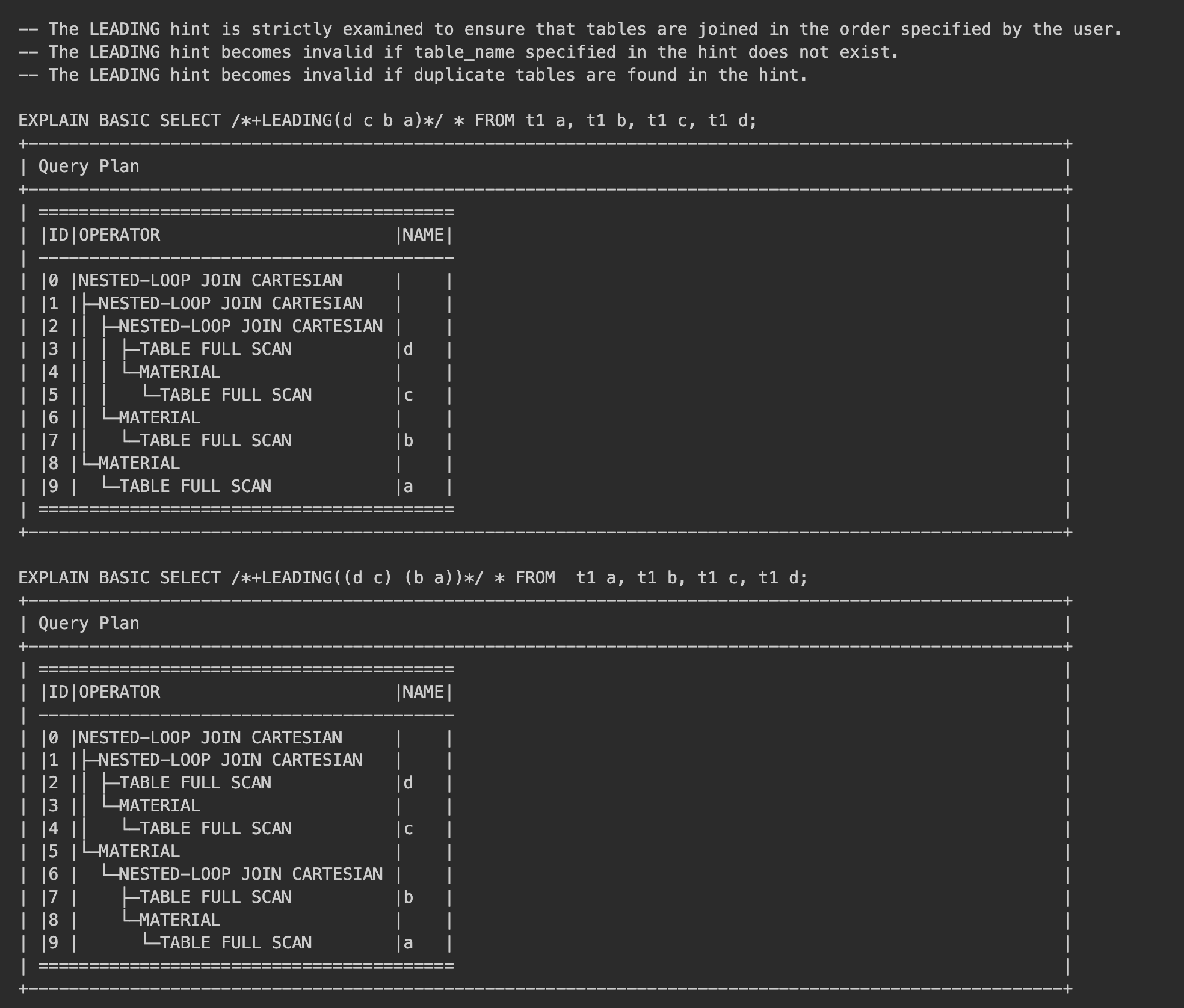
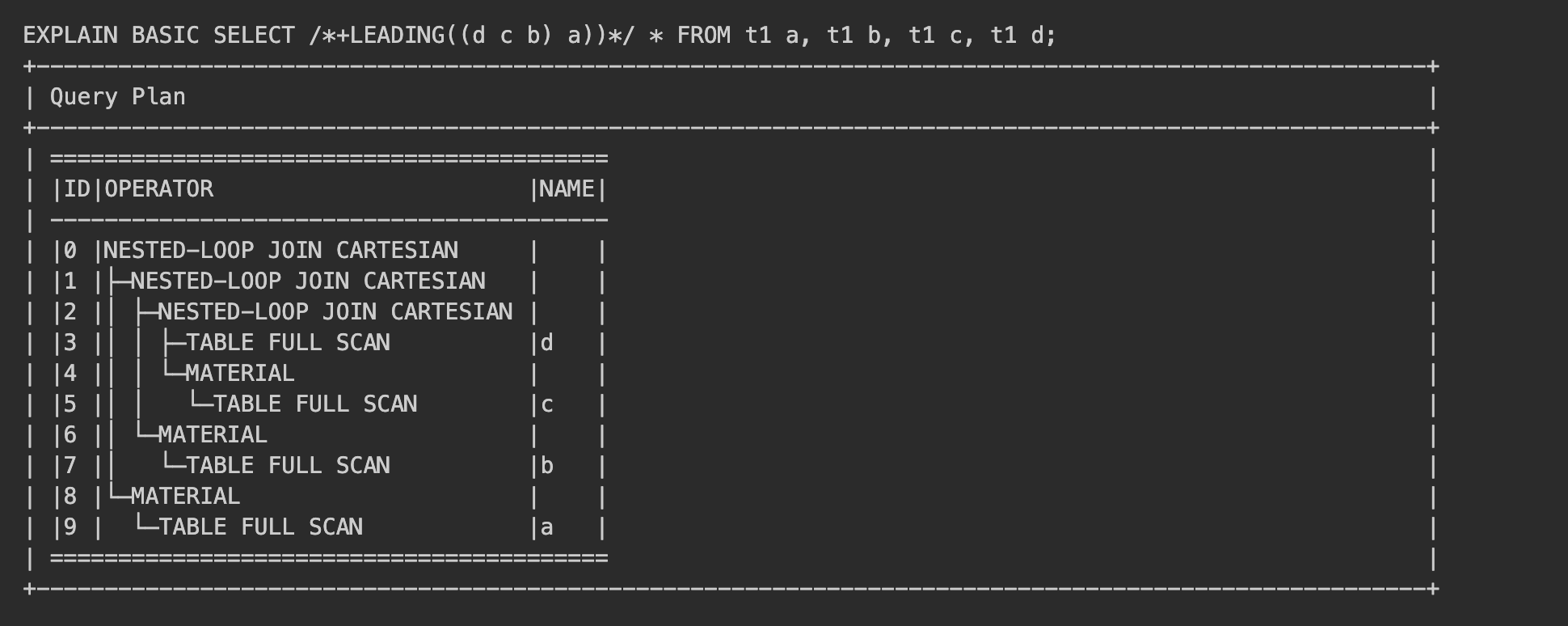
- The
USE_NLhint specifies to use the nested loop join algorithm for a join when the specified table is a right-side table. The syntax is as follows:/*+ USE_NL(table_name_list)*/
Here is an example:
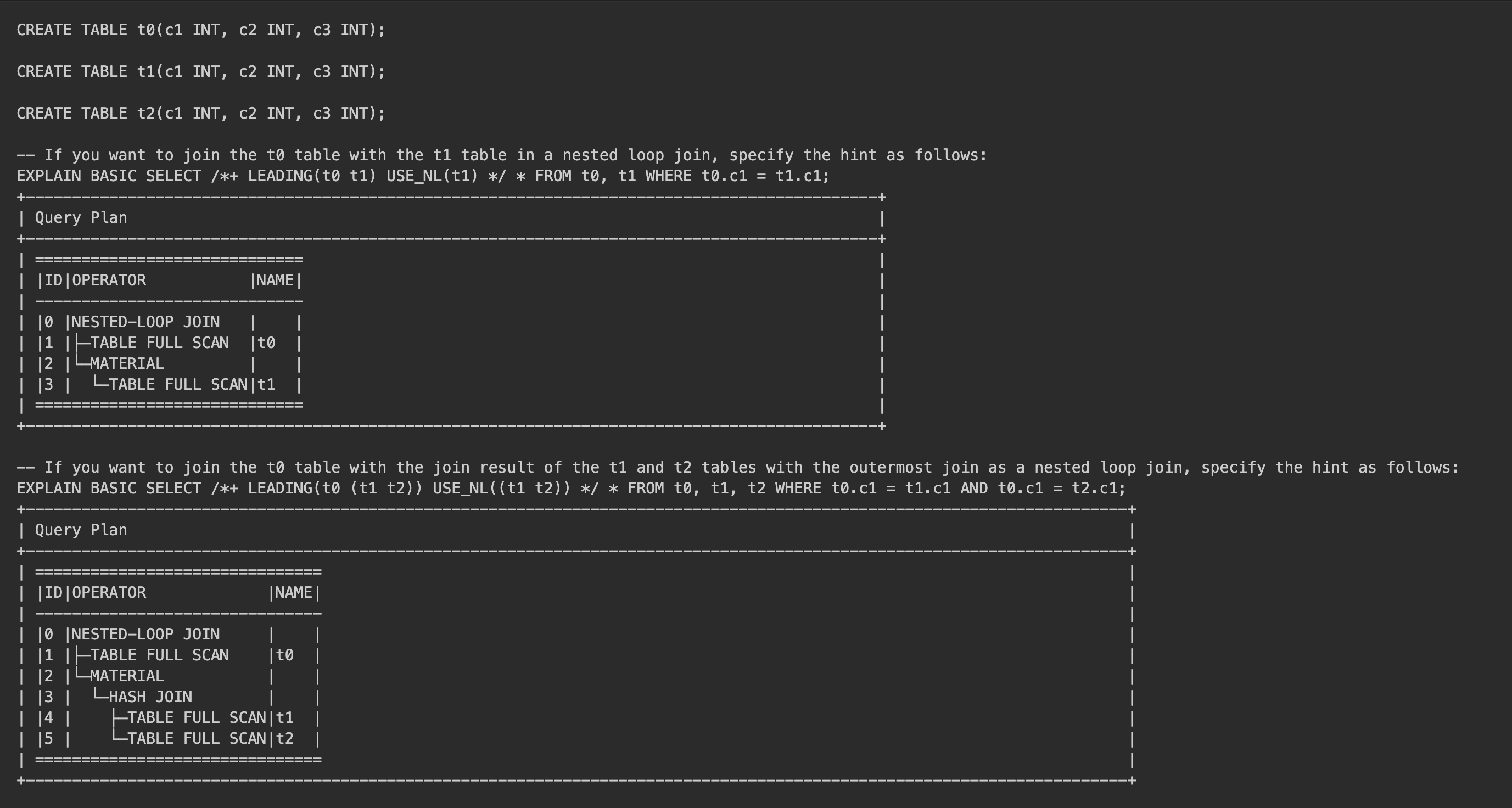
Note
The
USE_NL,USE_HASH, andUSE_MERGEhints are usually used with theLEADINGhint because the optimizer generates a plan based on the hint semantics only when the right-side table in the join matchestable_name_list.Here is an example: Assume that you want to modify the join method for the
t1andt2tables in the plan for theSELECT * FROM t1, t2 WHERE t1.c1 = t2.c1;statement.
Six plans are originally available:
• t1 nest loop join t2• t1 hash join t2
• t1 merge join t2
• t2 nest loop join t1
• t2 hash join t1
• t2 merge join t1
If you specify the hint
/*+ USE_NL(t1)*/, four plans are available:• t1 nest loop join t2
• t1 hash join t2
• t1 merge join t2
• t2 nest loop join t1
The
t2 nest loop join t1plan is generated according to the hint only when thet1table is the right-side table of the join. When thet1table is the left-side table of the join, the hint does not take effect.If you specify the hint
/*+ LEADING(t2 t1) USE_NL(t1)*/, only one plan is available:t2 nest loop join t1.
Description
Let’s now turn to a specific issue. You can view the detailed information about the issue in the SQL statement execution order and time-consuming SQL query post. The specifications of the t1 and t2 tables are as follows:
- The
c3column in thet1table is of type VARCHAR, with theutf8mb4character set andutf8mb4_bincollation. - The
c3column in thet2table is also of type VARCHAR, with theutf8mb4character set, but uses theutf8mb4_general_cicollation automatically set for the character set.

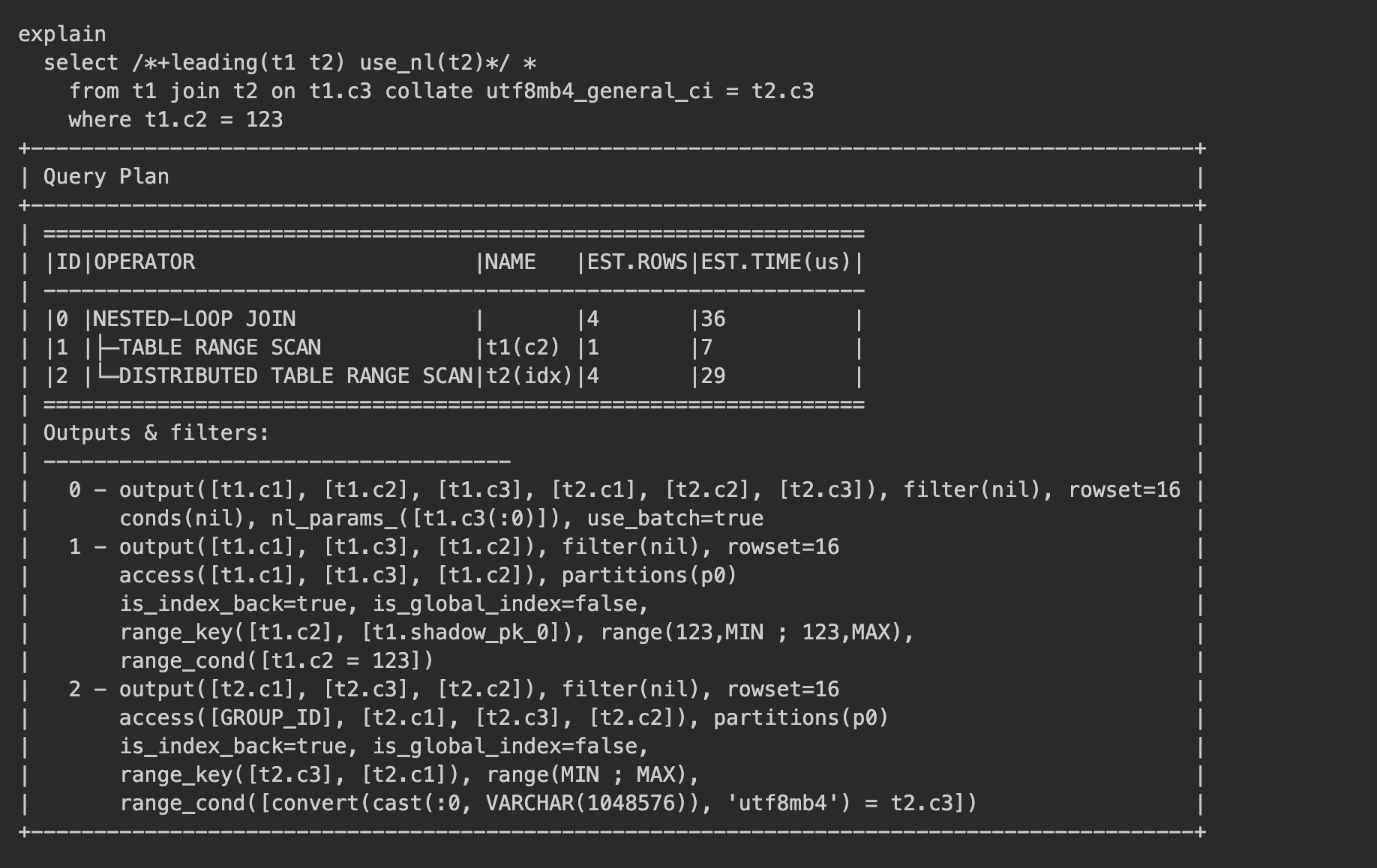
After the two c3 columns from the t1 and t2 tables are joined, the idx index on the t2 table is not used during the join. The /*+leading(t1 t2) use_nl(t2)*/ hint is specified to reproduce the plan, which indicates that the t1 table is joined with the t2 right-side table in a nested loop join.
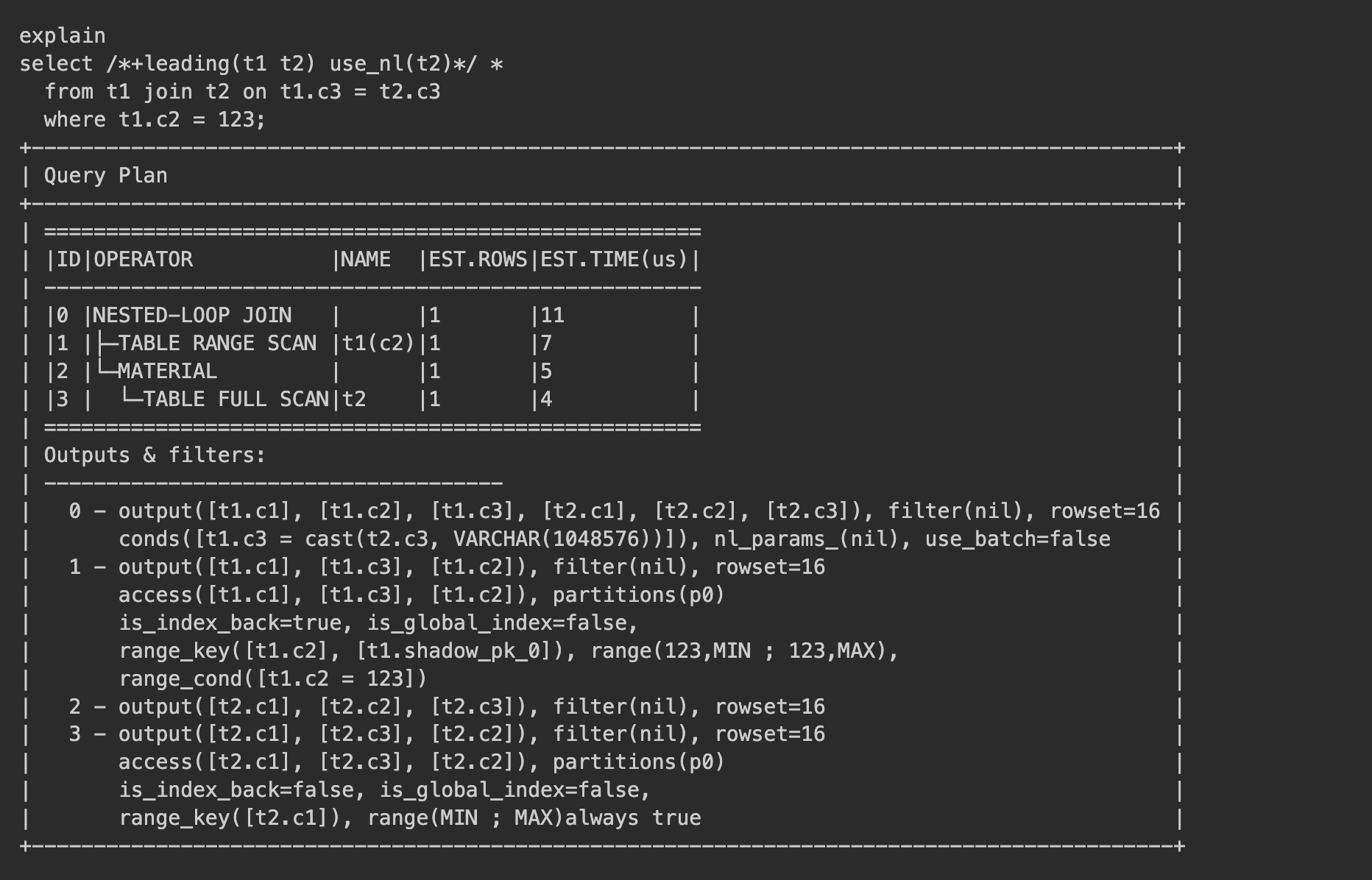
The query result shows that during the execution of the nested loop join, the t2 table had to perform a full table scan instead of using the idx index to quickly locate data for each row from the t1 left-side table, resulting in poor SQL execution performance.
Analysis
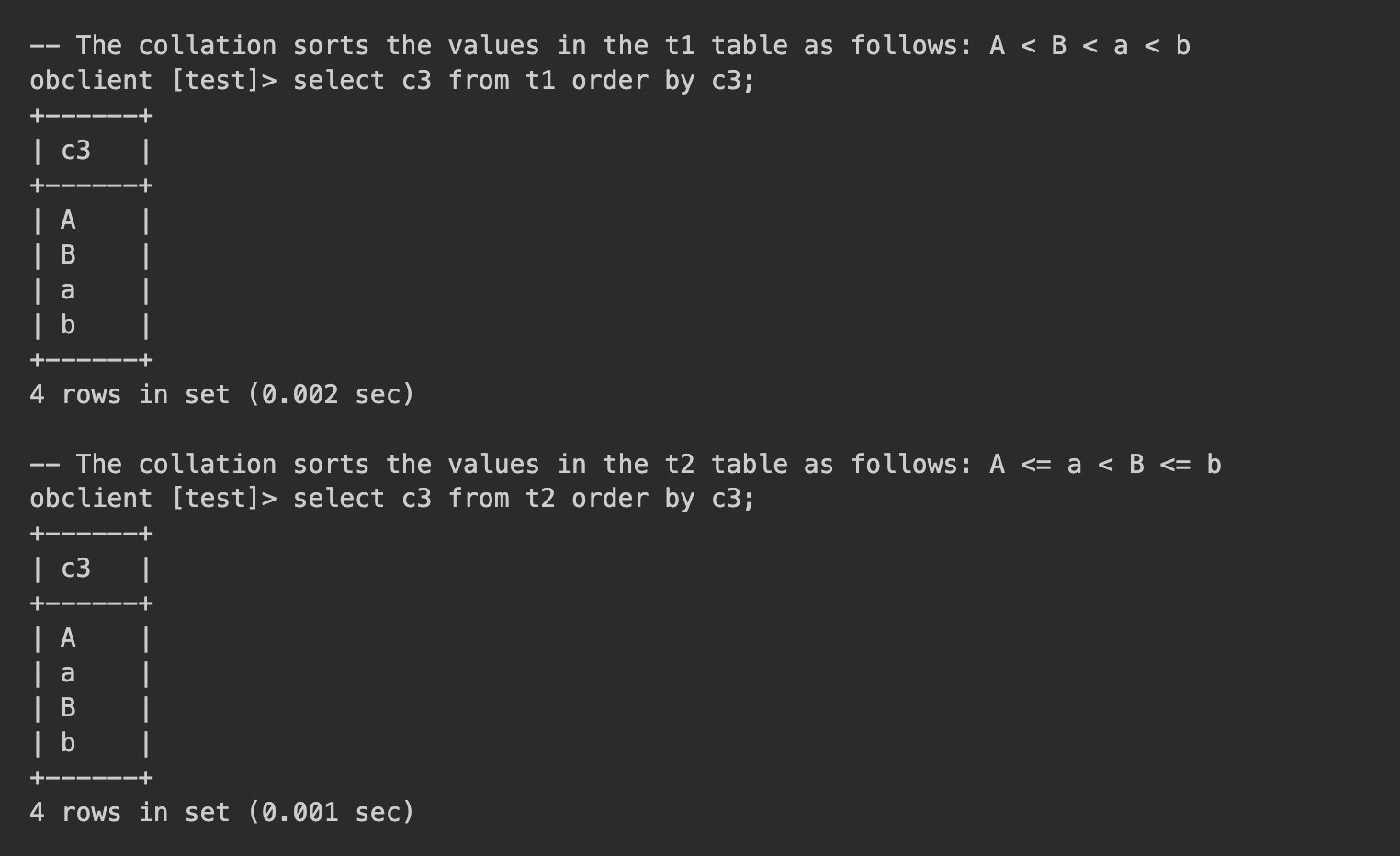
Although both c3 columns are of type VARCHAR and share the same character set, their different collations prevent the index from being used. For example, when you insert the same four rows, A, a, B, and b, into the t1 and t2 tables, the results are sorted differently due to the collation settings.
This discrepancy means that the values in the idx index on the t2 table are stored in the following order: A, a, B, b. If you use the value B in the t1 table to probe the idx index on the t2 table, the optimizer first compares the value B with the value A in the idx index. Since the value B is greater than the value A, the optimizer continues to compare the value B with the next value a in the index. According to the collation of the value B in the t1 table, the value B is smaller than the value a, so the optimizer returns a message indicating no value B is matched in the t2 table.
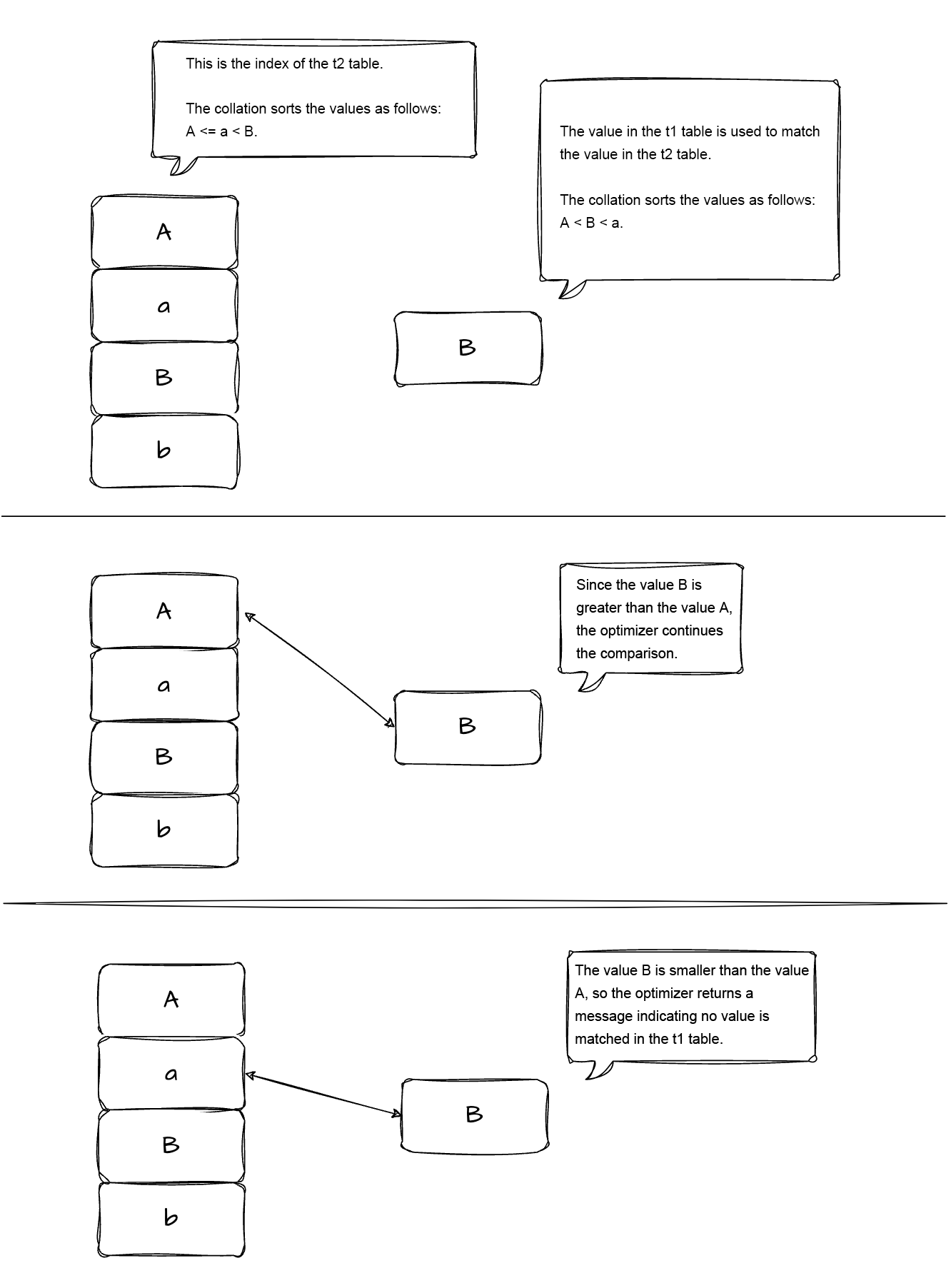
As a result, the optimizer cannot use the index on the t2 table to quickly locate data from the t1 table and resorts to a full table scan on the t2 table.
Solutions
Solution 1
A suggestion from an SQL tuning expert Xuyu is to use the CONVERT function to change the collation of the c3 column in the t1 table to match the utf8mb4_general_ci collation of the c3 column in the t2 table before performing the join. This helps unify the collation across both tables and allows the optimizer to use the index.
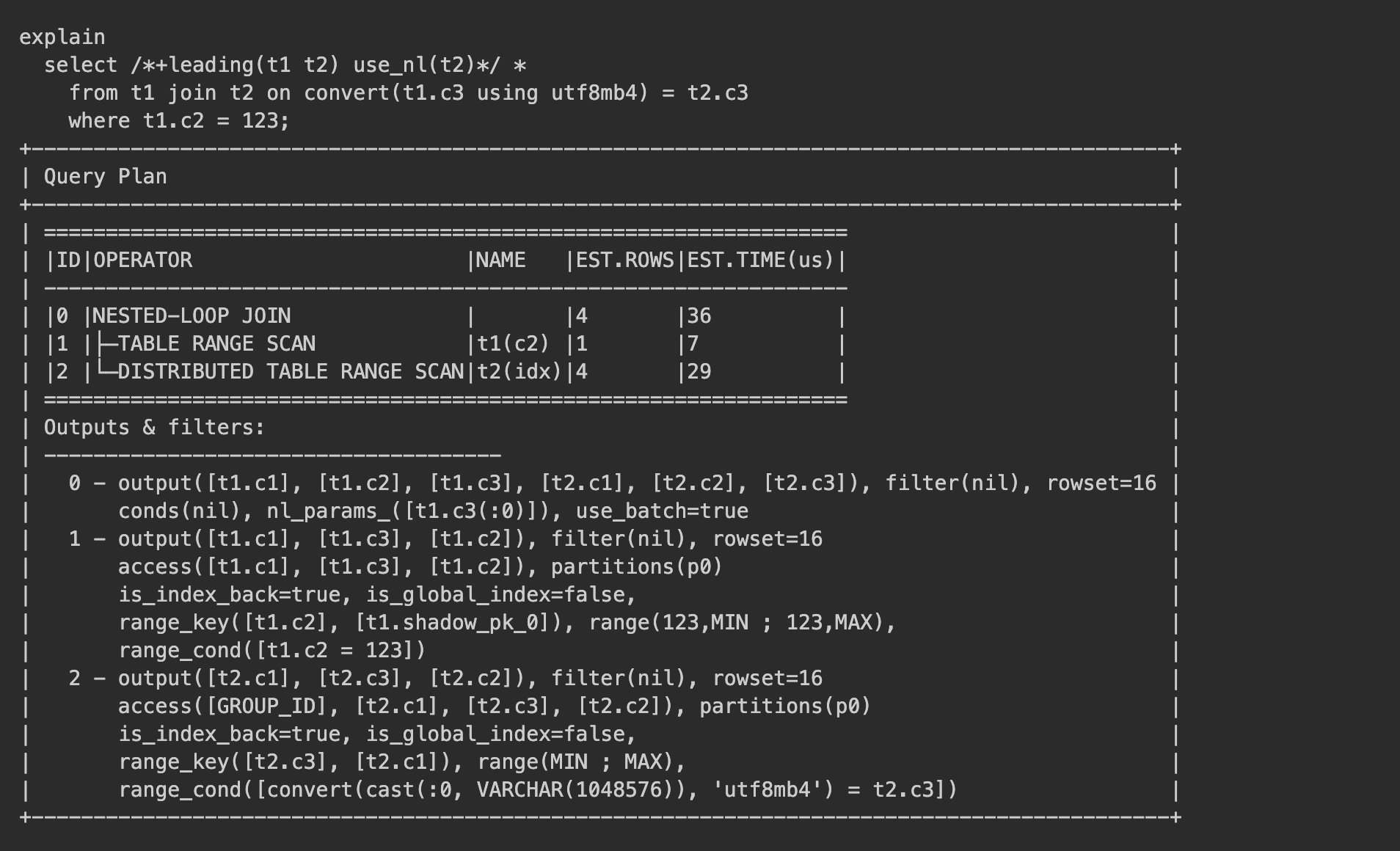
The plan shows that the index on the t2 table is used, replacing the previous full table scan.
Solution 2
While the first solution works in this specific case because the default collation of the utf8mb4 character set is utf8mb4_general_ci, it is not a universal solution. The CONVERT function only changes the character set and uses the default collation of the target character set. If you need a different collation, you can use the COLLATE keyword in the join condition to explicitly specify the collation of the c3 column in the t1 table as utf8mb4_general_ci.