Adaptive Techniques in the OceanBase SQL Execution Engine
I have been studying the book "An Interpretation of OceanBase Database Source Code" and noticed that it contains very little content about the SQL executor. The book focuses on parallel execution in the executor. This blog post introduces some common adaptive techniques in the executor of OceanBase Database. You can take it as a supplement to the executor part in this book.
Challenges facing AP performance improvement
If you want to improve the AP performance of a database, you will face three challenges:
- First, the optimizer cannot ensure that its estimates are always absolutely accurate. The reasons are complex. For example, the statistics are inaccurate in some scenarios, or the cost model is inconsistent with the actual model. These reasons will contribute to a non-optimal execution plan.
- Second, data skew often occurs in production and business scenarios, which will significantly affect the execution efficiency, especially the parallel execution efficiency.
- Third, the semantics of NULL are special. Characteristics of widespread NULL values are different from those of normal values in operations such as joins, but this is easily ignored. The executor must perform special processing on NULL values. Otherwise, various bad cases can occur.
Adaptive techniques enable the execution engine to dynamically adjust the execution strategy based on the actual situation, thereby improving the execution performance. In a word, adaptive techniques are introduced to address the preceding challenges. Next, let me introduce some typical adaptive techniques in the executor of OceanBase Database.
Adaptive join filter
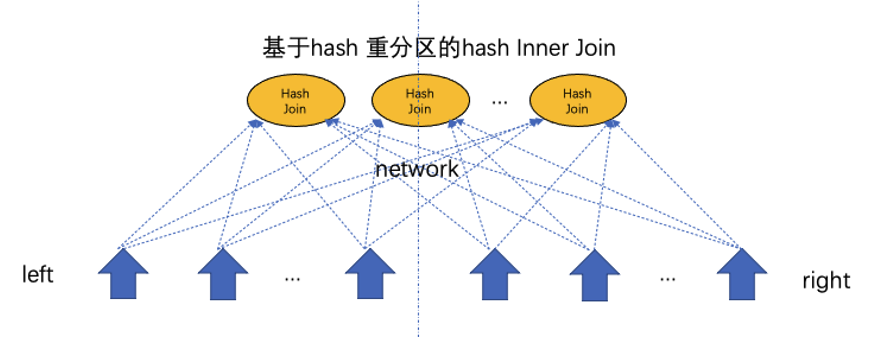
Let me take a hash join shown in the following figure as an example to introduce the background of join filters. The hash join involves two tables and uses hash repartitioning as the data shuffle mode. In other words, each row in the left-side and right-side tables will be repartitioned based on the hash value.
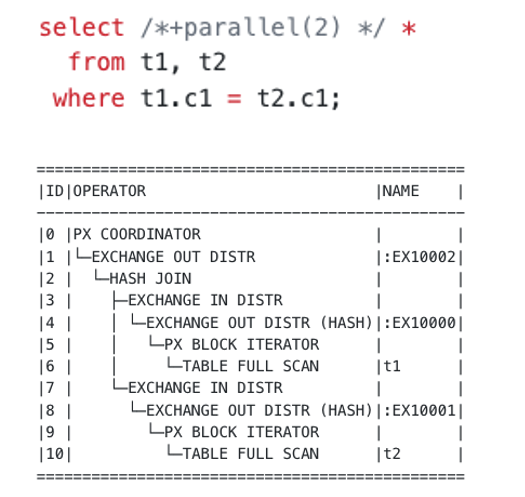
Generally, the right-side table of a hash join is very large in size, which will lead to a high cost in data shuffle. When the left-side table is read to build the hash table, a join filter can extract the data characteristics of the left-side table and send them to the right-side table. This can filter out some of the data in the right-side table before a shuffle. If the join filter has high filtering performance, this step can significantly reduce the network overhead.
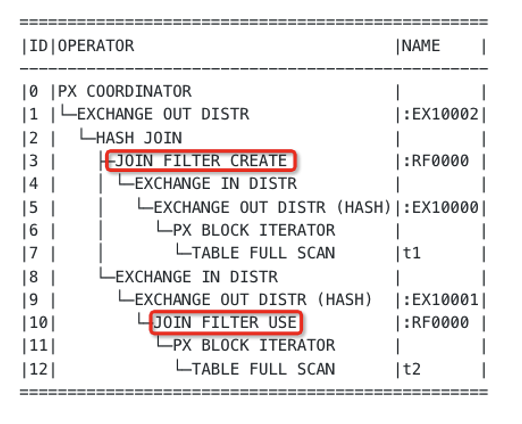
OceanBase Database has implemented join filters as early as in V3.x and has been undergoing join filter optimization ever since. The following figure shows the impact of join filters on the overall performance during the TPC-H benchmark run in 2021, in which OceanBase Database won the first place in the world.
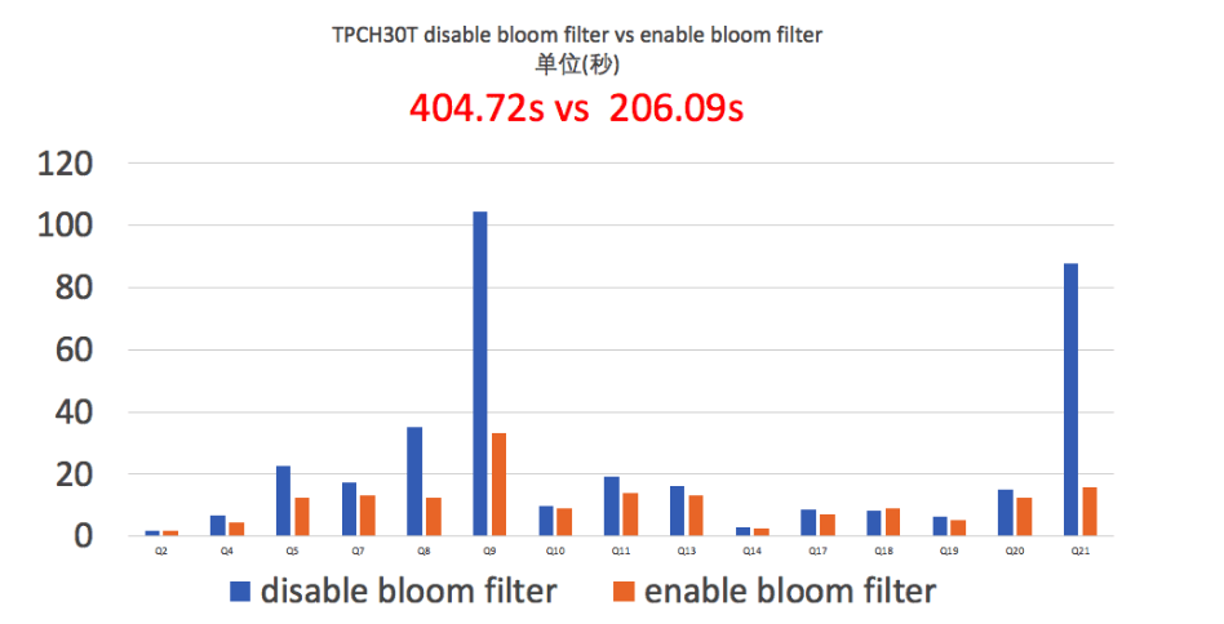
Join filters help significantly improve the performance for joins on large tables, such as Q9 shown in the preceding figure.
However, join filters cannot always bring positive benefits in all scenarios, such as Q18 shown in the preceding figure. The overhead of a join filter is used for three tasks:
- Create the join filter. This is to extract the data characteristics of the left-side table in a hash join when the left-side table is read to build the hash table.
- Send the join filter. This is to send the data characteristics of the left-side table to the right-side table.
- Apply the join filter. This is to apply the data characteristics of the left-side table on the right-side table for row filtering.
If the selectivity of the join filter is low, the reduced network overhead cannot make up the preceding overhead, and the overall performance will deteriorate.
The optimizer determines whether to allocate a join filter based on the cost. The optimizer can roughly estimate the selectivity of a join filter based on statistics such as the number of distinct values (NDV) and MIN/MAX values. However, the optimizer cannot provide accurate estimates of intermediate calculation results in the executor.
To resolve this issue, OceanBase Database V4.1 implements sliding window-based adaptive join filters. This algorithm aims to make up the performance loss when an incorrect join filter is applied.
This algorithm splits data into multiple sliding windows and collects statistics on the apply process of each window. If the algorithm detects that the filtering effects of a window are not as expected, it will not apply the join filter on the next window and pass this window. If the filtering effects of continuous windows are not as expected, the number of passed windows will also increase linearly to reduce the apply cost.

The following figure shows a bad case of join filter. Different strategies are used for performance tests. In the performance test where an adaptive join filter is used, the performance loss is made up by half. However, the performance after compensation is still lower than that achieved when the join filter is not allocated.
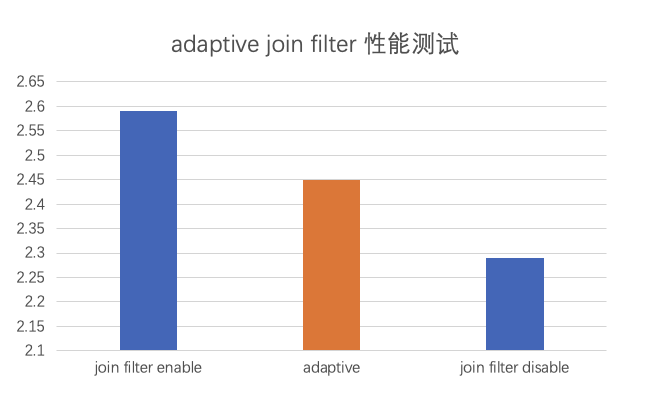
Although this solution makes up the performance loss caused by applying a join filter on the right-side table, the cost in creating and sending the join filter is not made up. OceanBase Database will enhance the capability for adaptive join filter creation in later versions.
Adaptive HASH GROUP BY
This section introduces the adaptive algorithm for HASH GROUP BY in OceanBase Database.
The following figures show the execution plans for HASH GROUP BY in a parallel scenario.
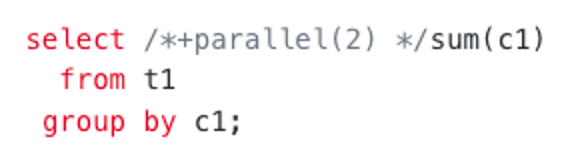
Here is the execution plan for two-phase HASH GROUP BY.

Here is the execution plan for one-phase HASH GROUP BY.

The difference is that two-phase HASH GROUP BY performs a partial GROUP BY operation on data before a shuffle. Like join filters, one-phase and two-phase HASH GROUP BY have their own advantages and disadvantages.
- Two-phase HASH GROUP BY applies to scenarios with a high data aggregation rate, where the amount of data to be shuffled can be decreased through pre-aggregation.
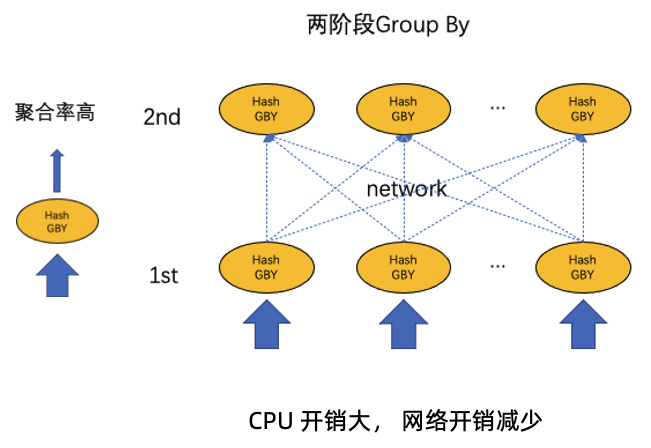
- One-phase HASH GROUP BY applies to scenarios with a low data aggregation rate.
If the data aggregation rate is low, the network overhead will still be high because a two-phase plan will consume extra CPU resources to probe the hash table, leading to poorer performance than a one-phase plan.
The following figure compares the performance of two-phase and one-phase plans for queries in ClickBench. It can be observed that some queries are suitable for two-phase execution while others are suitable for one-phase execution. Generally, the optimizer tends to select a two-phase plan to avoid serious performance deterioration.
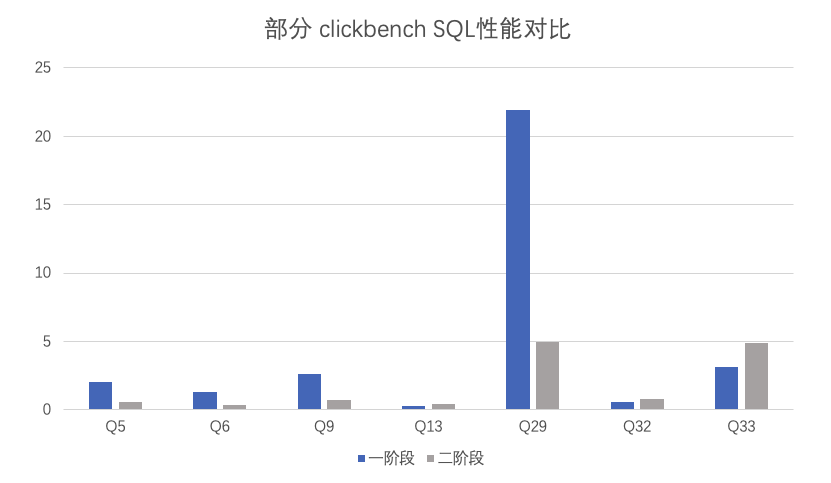
In versions earlier than OceanBase Database V4.x, the optimizer will determine whether to select a two-phase plan or one-phase plan based on the NDV value in the statistics. You can also use the session variable _GROUPBY_NOPUSHDOWN_CUT_RATIO to set the plan preference. If the ratio of the input data amount to the data amount after aggregation is greater than the specified value, a two-phase plan is generated. Otherwise, a one-phase plan is generated. In practice, it is difficult to use this variable. The input and output data amounts of GROUP BY are estimated by the optimizer based on statistics. Generally, it is challenging for O&M personnel to set this variable to an appropriate value, ensuring that the optimizer selects a better plan for GROUP BY.
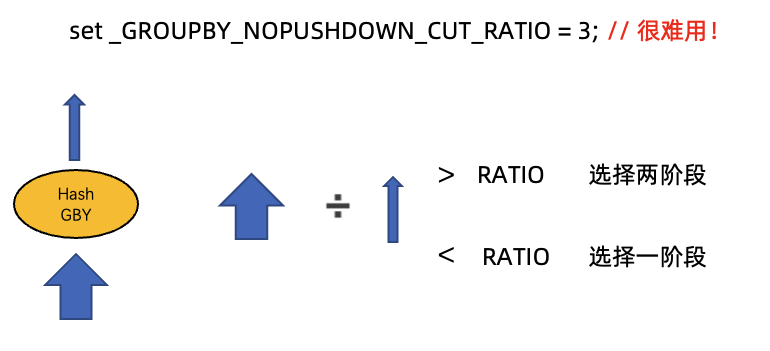
In OceanBase Database V4.x, the _GROUPBY_NOPUSHDOWN_CUT_RATIO variable is deprecated and the optimizer is forced to select a two-phase plan. In a two-phase plan in V4.x, the first phase must be adaptive GROUP BY.

The core idea of the adaptive GROUP BY technique is to determine whether to perform deduplication or directly send data based on an NDV value collected in real time. The technique splits data into multiple rounds and measures the aggregation rate of each round. If the deduplication rate of a round is not as expected, the technique will clear the hash table, flush all the data obtained in the first phase to the network, and aggregate the final data in the second phase.
Data is split into rounds based on the size of three-level CPU caches. This is because if the hash table can be accommodated in the L2 cache, the performance can be improved by more than 30% compared with that of a large hash table. A cache-aware mechanism is provided to increase the size of data in each round from the L2 cache size to the L3 cache size when the deduplication rate becomes low so that data will be accommodated in the L3 cache.
If the hash deduplication effects of multiple consecutive rounds are poor, the bypass strategy is used. Specifically, rows are directly delivered to the upper-layer operator without hash deduplication, which looks like a one-phase plan.
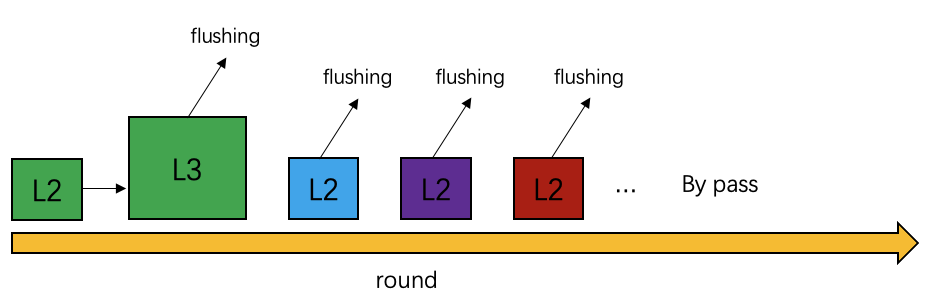
This strategy greatly improves the performance but also has bad cases where a large amount of data is involved while the overall deduplication rate is favorable. If the overall deduplication rate is estimated based on only a small part of the data, the estimate is probably inaccurate. In OceanBase Database V4.2, the NDV values of multiple data rounds are merged to improve the estimate accuracy.
The following figure compares the performance of one-phase, adaptive, and two-phase GROUP BY for queries in ClickBench.

The result shows that adaptive GROUP BY can select an appropriate execution strategy almost in all scenarios. With adaptive GROUP BY, one plan applies to different data models. This is the goal we aim to achieve. OceanBase Database V4.3 will support a global NDV estimate strategy to make adaptive decision-making more accurate.
Adaptive hybrid hash shuffling
Next, let me introduce some adaptive techniques we have developed based on data skew. The following figures show two common plans for a simple distributed hash join.
One is a broadcast plan, which broadcasts the left-side table to each thread of the right-side table. The threads will use data in the right-side table to probe data in the left-side table.

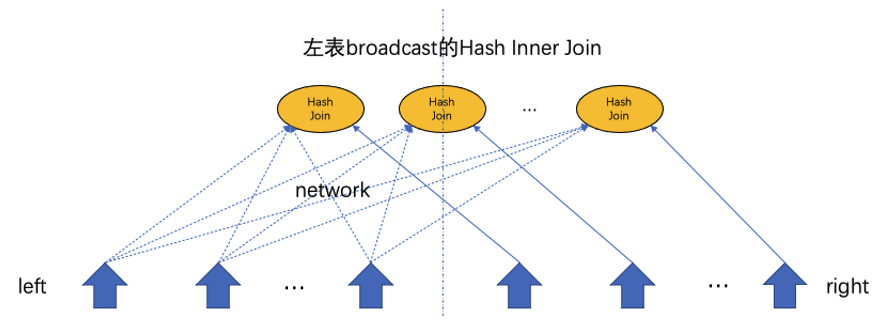
The other is a hash repartitioning plan, which distributes the data in the left-side and right-side tables to different threads based on the hash value. Each thread performs a join separately.
The two plans have their own advantages and disadvantages. Generally, the broadcast plan applies to a scenario where a large table is joined with a small table. In this scenario, the small table is broadcast to limit the broadcast cost. In a scenario where two large tables are joined and repartitioning based on the join key is not supported, hash-hash is almost the only choice. However, the hash-hash strategy also has bad cases in data skew scenarios. For example, the following figure shows a high-frequency value. Since data is distributed to different threads based on the hash value for hash repartitioning, all instances of the high-frequency value are distributed to the same hash join, leading to a long-tail situation of the hash join.

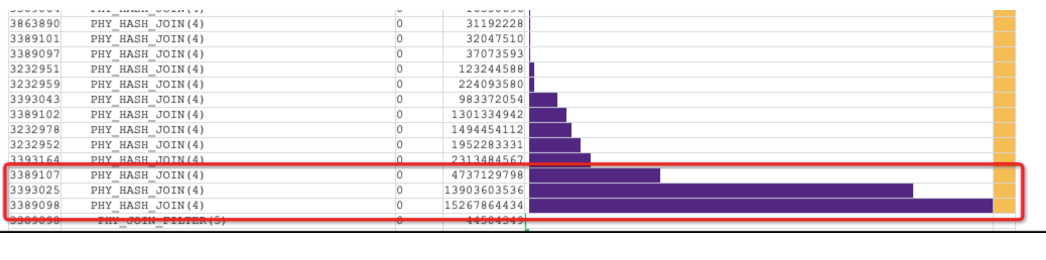
The following figure shows a similar business scenario as observed by the SQL plan monitor tool.
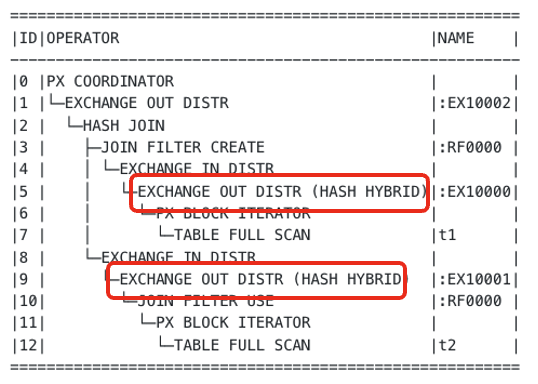
To resolve this issue, OceanBase Database V4.x implements the hybrid hash shuffling algorithm. The following figure shows an execution plan that uses this algorithm. It looks like a plan that uses the hash repartitioning algorithm. The only difference is that a HYBRID keyword is contained in the EXCHANGE operator.
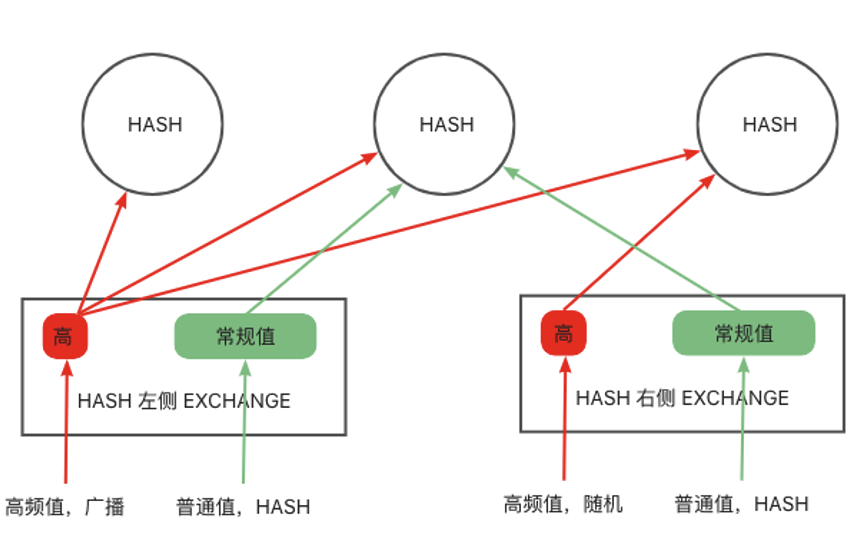
The hybrid hash shuffling algorithm will obtain related information about high-frequency values from the optimizer. For regular values, normal hash shuffling is used for hash repartitioning. For a high-frequency value, if it exists on the left side (hash join build side), the value will be broadcast to all threads to build the hash table. If it exists on the right side (hash join probe side), the instances of this value are randomly distributed to ensure the evenness. This algorithm can effectively resolve performance issues caused by hash repartitioning in data skew scenarios.
Adaptive NULL-aware hash join
Finally, let me briefly introduce some optimization techniques we have applied to handle NULL values. For a join, the return result of a NULL value is always NULL in an equal condition. However, the semantics of NULL vary based on the join method.
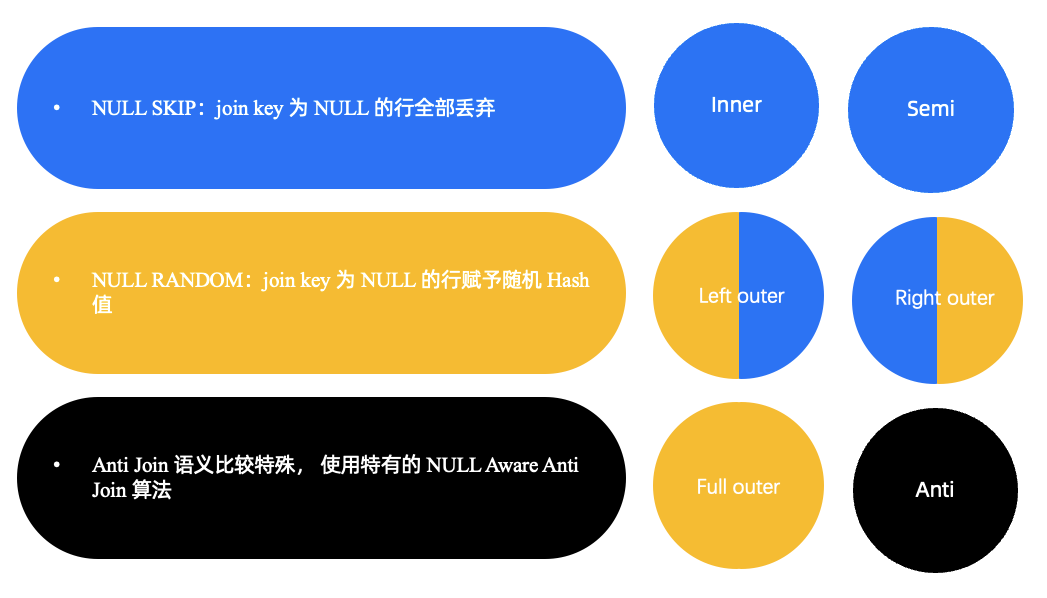
In inner joins and semi-joins, values whose join key is NULL can be ignored.
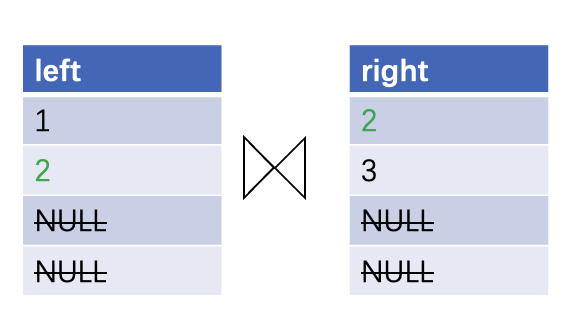
In left outer joins, NULL values on the left side also need to be output.
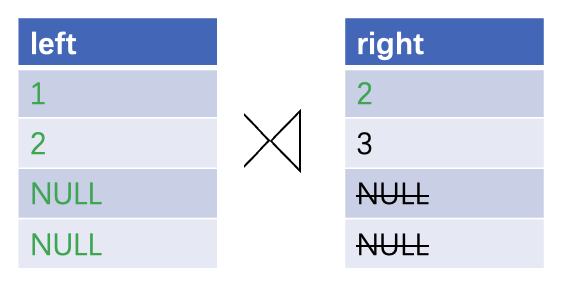
If NULL values are processed as normal values, correct results can be obtained. However, data skew of NULL values or a useless network shuffle of massive NULL values may occur. The following special measures are taken inside hash joins and during a hash join shuffle:
- Skip NULL values in join keys. This measure usually applies to inner joins and semi-joins, in which values whose join key is NULL will not be output.
- Randomly distribute NULL values to avoid data skew. Generally, for an outer join, specifically, the left side of a left outer join, right side of a right outer join, or both sides of a full outer join, if the NULL values of one side or both sides need to be output, these NULL values will not successfully match any value. In this case, random hash values are assigned to these NULL values and the NULL values are randomly distributed to different threads. A NULL value that does not need to be output will still be skipped.
- Use the NULL-aware anti-join algorithm, which will not be described in this post, to process anti-joins that contain NOT IN. The semantics of such anti-joins are special.
Preview of the next post
This post introduces some representative adaptive techniques in the executor of OceanBase Database, based on the assumption that you have a basic understanding of the two-phase pushdown technique for HASH GROUP BY. If you are unfamiliar with the multi-phase pushdown technique of the executor, please look forward to the next post Distributed Pushdown Techniques of OceanBase Database.