Simplistic Yet Not Simple: The Upgrade to a Modern HBase Architecture with OceanBase Database
In the Internet era, HBase is undoubtedly a rising star in the database field. The exponential growth of massive data and the rise of semi-structured and unstructured data posed great challenges to conventional relational databases such as MySQL. As a result, NoSQL databases for managing unstructured data and distributed architecture technologies for storing massive data emerged. Exemplars include Hadoop, a framework for distributed systems, and HBase, a NoSQL database built on Hadoop.
Hadoop, whose emergence dates back to 2005, introduced the concept of distributed storage and computing, enabling users to build large-scale computing clusters with affordable hardware to efficiently store and process massive data. As a distributed computing framework initially designed for batch processing and offline computation, Hadoop was weak in real-time data access. To support real-time data access and interactive applications, HBase was introduced into the Hadoop ecosystem, addressing the need for large-scale data storage and high-concurrency read/write operations.
1 Why Did HBase Become Popular?
Born in the midst of the rapid growth of the Internet, HBase is designed to handle high-concurrency writes and simple queries for massive data in the Internet era. Over the past decade, with its unique architecture design, HBase has gained significant advantages in various Internet scenarios and has become widely popular worldwide.
1.1 Massive storage and flexible scalability
Conventional relational databases, such as Oracle and MySQL, face performance bottlenecks when storing and processing massive data, and are difficult to scale horizontally. Even if you expand them through sharding or middleware, challenges often arise in ensuring data consistency and reducing O&M complexity. As a NoSQL database, HBase supports millions to hundreds of millions of rows and columns per table. It implements distributed data storage based on HDFS, allowing you to scale out a cluster by adding nodes to store terabytes or even petabytes of data.
1.2 Exceptional OLTP capabilities
With its underlying log-structured merge-tree (LSM-tree) architecture and ordered rowkey design, HBase excels in high-concurrency, real-time batch writes in online transaction processing (OLTP) scenarios and performs well in simple reads of massive data such as random point reads and small-range scans. Therefore, it is widely used in log processing, real-time data collection, updates and instant queries, user profiling, and order storage. The columnar storage of HBase supports retrieving only the needed columns during a query, which further improves the random read/write efficiency.
1.3 Flexible data schemas
HBase supports flexible schemas, allowing dynamic table schema changes and column family adjustments without downtime. This makes it ideal for storing rapidly changing unstructured and semi-structured data to meet the ever-evolving demands of applications. Take user profiling as an example. During the creation of a profile database, user characteristics that need to be extracted vary with the ever-changing business needs and strategies. The flexible schema feature of HBase effectively meets these dynamic requirements.
1.4 Sparse columns
HBase supports sparse storage, where a large number of column values can be null. This efficiently handles semi-structured and sparse data without allocating space for null values. Compared to conventional databases, HBase greatly saves storage space in storing sparse data.
1.5 Support for multi-versioning
HBase implements multi-versioning through timestamp and version number control, allowing multiple versions of the same row to be stored in a table. This enables users to access different versions of a row at different points in time. For example, HBase is often used in risk control scenarios where historical data needs to be analyzed, such as historical behavior tracking and auditing, real-time risk assessment, and fraud detection.
2 HBase Is Not Perfect
Born in the Internet era, HBase appears well-suited for massive data storage and processing in most scenarios. However, it is not perfect.
2.1 Lack of support for complex queries
HBase adopts columnar storage, where a rowkey serves as the unique identifier and primary index for each row in the data table. Data in an HBase table is sorted lexicographically by rowkey, and can be retrieved only based on the rowkey during a query. Well-designed rowkeys boost query performance, but queries on other fields may not be as efficient. In addition, HBase does not support secondary indexes, making it unsuitable for complex queries such as joins and aggregations. At present, tools such as Apache Phoenix, an open source project, are evolving to enable SQL queries on HBase, including complex queries involving secondary indexes and aggregations.
2.2 Slow and unstable response
In fields such as consumer finance, online advertising, and social media, databases are expected to deliver fast and stable responses. P99 latency is a common metric for measuring response time (RT) stability, indicating that the RTs of 99% of requests within a given time window are below a specific value. Many scenarios require a P99 latency of under 100 milliseconds, or even 10 milliseconds.
A typical scenario is ad placement based on user characteristics. The process includes batch collecting and storing user behavior data, analyzing user profiles with big data components, and writing the analysis results back to the key-value (KV) user characteristic database for business access. During business access, continuous user browsing actions lead to frequent access to the user characteristic database. To ensure timely and consistent user experience, each access must be responded to quickly and stably.
This scenario presents two challenges for the database. Firstly, the database must support continuous writes and storage of massive data, as well as elastic scalability to handle large volumes of user characteristic data. Secondly, the database must deliver stable and acceptable RTs.
As mentioned earlier, HBase is often used for storing user profile data due to its flexible scalability, multiple column families, and sparse columns. However, in the preceding scenario, HBase exhibits poor RT stability. This is due to two reasons. On one hand, HBase is written in Java. Frequent memory allocation and release trigger excessive garbage collection (GC) in Java Virtual Machine(JVM), which consumes CPU resources and causes unpredictable latency fluctuations. On the other hand, the storage/computing splitting architecture of HBase leads to longer read paths and frequent RPC interactions between diverse components, which worsens P99 latency fluctuations.
2.3 Complexity in maintaining multiple components
In addition to struggling to provide consistent end user experience in certain scenarios, HBase also poses significant challenges for O&M engineers. HBase is an open source project within the Hadoop ecosystem, and its deployment requires a Hadoop cluster to be in place. A fully functional HBase cluster consists of multiple components, including ZooKeeper, HMaster, RegionServer, HBase Client, NameNode, DataNode, and HDFS Client. To implement advanced features such as complex queries and monitoring, additional tools are required. Therefore, O&M engineers are unable to deploy or maintain an HBase cluster unless they are skilled in managing and operating every component. This requires a lot of expertise from O&M engineers and involves a large amount of work. Once an issue arises, it is time-consuming to troubleshoot. Additionally, as an open source storage solution, HBase lacks user-friendly GUI tools to facilitate O&M.
2.4 Difficulty in ensuring business continuity
Business continuity is a key concern for many database users, especially in fields such as consumer finance, live streaming, and social media, where service interruptions can lead to significant losses. Due to its architecture, HBase is difficult to deploy for disaster recovery and inefficient in recovering services.
Firstly, an HBase cluster cannot be deployed across zones. This is because HBase relies on HLogs for asynchronous synchronization and cannot ensure consistency across zones. To achieve cross-region disaster recovery, multiple clusters need to be deployed, which incurs high expenses.
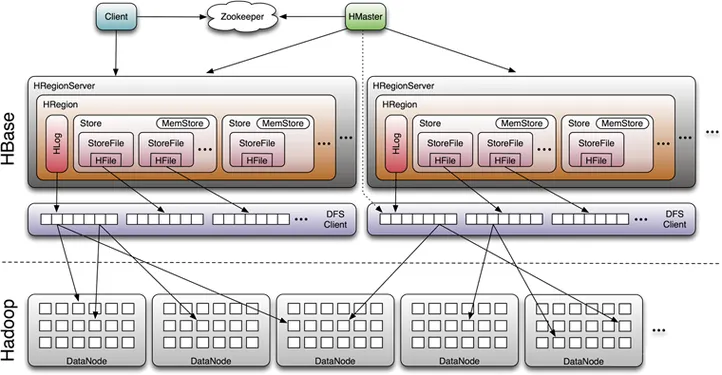
Secondly, HBase is inefficient in recovering interrupted services. As shown in the preceding figure, HBase adopts a storage/computing splitting architecture, where the HBase layer handles computation and the HDFS layer manages storage. At the HBase layer, a computing node is called a RegionServer, and a partition is referred to as a region. Each region maintains only one memory instance. When a RegionServer fails, regions on it cannot provide data access services until they are rescheduled by HMaster and their states are restored from HDFS. The time required for the restore ranges from 2 to 8 minutes, which is unacceptable in scenarios requiring high business continuity. Network issues, server failures, high concurrent loads, or problems with the coordination mechanism of HBase can cause regions undergoing management operations, such as splitting, merging, and moving, to stay in the Region in Transaction (RIT) state. This prevents the regions from responding to read and write requests and thus severely undermines the overall performance and availability of the cluster.
3 OceanBase Database Is a Better Replacement for HBase
Given these challenges, is there a better solution? When faced with massive unstructured data and increasingly complex demands, can we move beyond conventional SQL databases and distributed NoSQL databases such as HBase? Is it possible to build an integrated distributed system with massive storage and flexible scalability to suit complex needs based on various data models?
The multi-model capabilities of OceanBase Database are specifically designed to solve this problem. OceanBase Database builds an SQL engine and a multi-model KV system (OBKV) on its distributed storage engine. The SQL engine supports both conventional structured data and multi-model data types such as GIS, JSON, and XML. OBKV offers different product forms, including OBKV-HBase (compatible with the HBase APIs), OBKV-Redis (compatible with the Redis protocol), and OBKV-Table (based on the table APIs). Take OBKV-HBase as an example. Extensive tests and practices have shown that OBKV-HBase outperforms HBase in various scenarios in terms of performance and O&M architecture, making it a better replacement for HBase.
3.1 Architecture of OBKV-HBase
OBKV is a series of NoSQL products built based on the distributed storage engine of OceanBase Database. Currently, it supports three product forms: OBKV-Table, OBKV-HBase, and OBKV-Redis, which inherit OceanBase Database's basic capabilities such as high performance, transaction processing, distributed architecture, multitenancy, and high availability. Additionally, OceanBase Database's tool ecosystem, such as OceanBase Cloud Platform (OCP), OceanBase Migration Service (OMS), and OceanBase Change Data Capture (obcdc), provides native support for OBKV. You can use these tools to perform O&M operations on OBKV in different product forms as on OceanBase clusters. OBKV can help enterprises unify the technical stack, thereby simplifying database O&M while meeting the business needs for a multi-model NoSQL database.
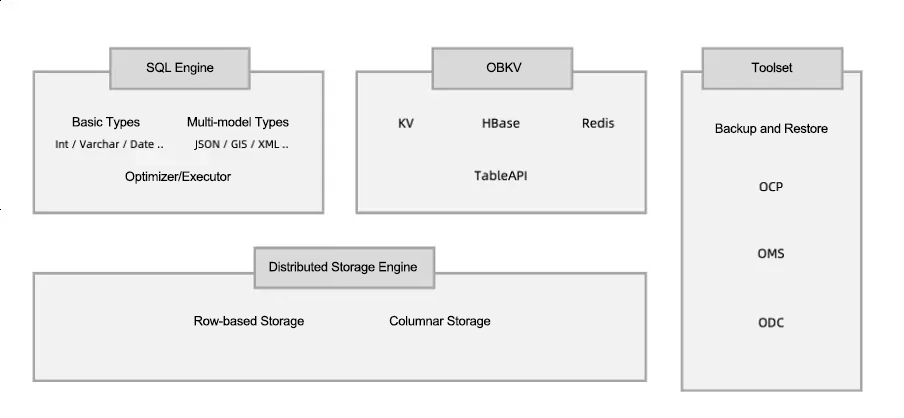
The multi-model architecture of OceanBase Database consists of three layers: the distributed storage engine layer, the KV layer, and the driver layer. The KV layer can be further divided into TableAPI Server Framework and the model layer. OBKV and the SQL engine are both built on the distributed storage engine. Between the distributed storage engine and the KV model layer lies TableAPI Server Framework, which provides the model layer with encapsulated storage and transaction call capabilities. The OBKV-HBase model layer implements HBase features such as multiple data versions, sparse columns, wide tables, filters, and row locks. It also maps operations performed on rows and cells in HBase as operations on rows in OceanBase Database. At the driver layer, OBKV-HBase implements HBase APIs. Business can call the APIs to interact with the OBKV server through the TableAPI client.
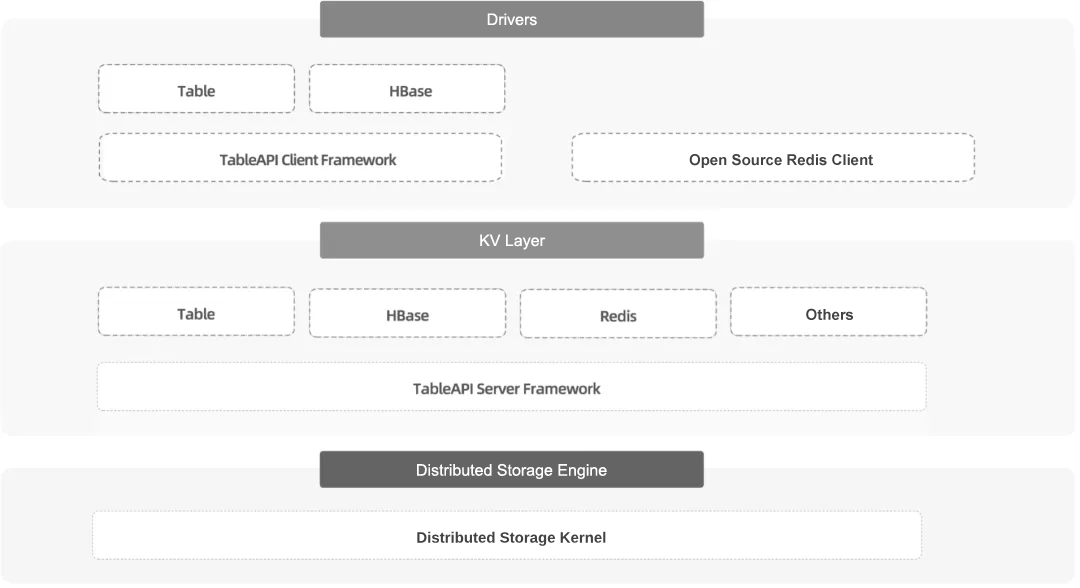
As OBKV bypasses the SQL layer by directly connecting to the storage engine, OBKV APIs outperform SQL APIs by about 30% in simple KV scenarios.
OBKV-HBase supports most features of HBase 0.94 and 1.1.13 in the form of APIs, including APIs, such as PUT, GET, EXISTS, DEL, APPEND, INCREMENT, and SCAN, as well as HBase row locks. In terms of P99 latency, hot replica, cross-zone disaster recovery, performance, and O&M, OBKV-HBase offers significant advantages over open source HBase.
3.2 Replacement of HBase with OceanBase Database for optimization and upgrades
With its integrated multi-model architecture and comprehensive toolset, OceanBase Database allows you to replace HBase in many scenarios for better user experience, lighter O&M burden, lower cost, higher efficiency, and system upgrades. Here are some typical upgrade scenarios:
(1) Improve read performance in scenarios involving frequent reads.
As mentioned earlier, HBase excels in high-concurrency batch writes but has weaker read performance. Compared to HBase, OBKV-HBase offers similar write performance but delivers about four times better read performance. Therefore, in scenarios involving intensive and frequent reads, replacing HBase with OBKV-HBase greatly improves performance and reduces computing costs.
This difference results from the architectural characteristics of HBase and OceanBase Database.
○ HBase: HBase adopts a storage/computing splitting architecture based on LSM-tree, where the HBase layer handles computation and the HDFS layer manages storage. For writes, data is written to HBase RegionServers. Therefore, the architecture has little impact on write performance. For reads, however, data is likely to be read from HDFS. A typical read is processed as follows: HBase Client sends a read request to a RegionServer. If the RegionServer finds no hit, HDFS Client sends a message to the HDFS cluster to load the data blocks to the RegionServer. The process consumes CPU resources, increases latency, and introduces jitter because it goes through a long path that involves RPC interactions between multiple system components, thus leading to poor read performance.
○ OceanBase Database: OceanBase Database adopts a shared-nothing architecture, which has a simpler read process than the storage/computing splitting architecture of HBase. In addition, OBKV-HBase uses a rich client that can directly route a request to the right OBServer node based on accurate route calculation, allowing data to be read locally. The entire path involves only one RPC interaction and one disk I/O operation, consuming significantly less time and enabling OBKV-HBase to deliver much better read performance than open source HBase.
(2) Facilitate fast and stable responses in scenarios requiring low P99 latency.
As mentioned earlier, fast and stable responses are required in fields such as consumer finance, risk control, advertising, and social media. Unstable responses can affect user experience, while frequent fluctuations may cause amplification and crashes.
Due to limitations in its programming language and architecture, HBase struggles to ensure stable RTs. Unlike HBase, OceanBase Database excels in scenarios requiring low P99 latency.
○ OceanBase Database is written in C++, and its independently developed memory management module directly requests huge pages from the operating system. This avoids latency fluctuations caused by frequent GC in Java-based HBase.
○ OceanBase Database adopts a shared-nothing architecture, avoiding latency fluctuations caused by RPC interactions between the components in the complex architecture of HBase.
In a real-world production environment where the data write speed reached 6kw/min, OBKV-HBase delivered fast and stable responses without significant fluctuations. The maximum query time was under 20 ms and the average query time was around 2 ms, with a P99 latency of less than 10 ms and a P999 latency of less than 15 ms. Under the same conditions, the P99 latency of HBase was more than 100 ms.
(3) Upgrade the architecture to reduce O&M costs in scenarios with high O&M load and the need for a simpler architecture.
The nodes in an HBase cluster have different roles and functions. It is complex to deploy and maintain an HBase cluster because numerous components are involved. Replacing HBase with OBKV-HBase greatly simplifies the system architecture and reduces O&M costs.
○ Simple architecture: Unlike HBase's complex architecture, which involves a dozen components across multiple systems, OceanBase Database features a simple architecture. OBKV consists of only two components: OBKV Client and OBServer. OBServer nodes are homogeneous, meaning only one OBServer node needs to be maintained on the server side, thereby reducing deployment and O&M burdens.
○ Comprehensive toolset: Unlike HBase, which lacks user-friendly GUI O&M tools, OceanBase Database offers a comprehensive toolset that natively supports OBKV. For example, OCP, a GUI O&M tool in the toolset, offers features such as full lifecycle O&M management, monitoring and alerting, disaster recovery management, and diagnostics and optimization, enabling you to efficiently manage and maintain OBKV-HBase.
(4) Enhance system reliability in scenarios requiring high business continuity.
In core business scenarios, system reliability and business continuity are top priorities. Due to the architectural characteristics of HBase, an HBase cluster cannot be deployed across zones for disaster recovery and does not support quick business recovery. OBKV-HBase, built on the high-availability architecture of OceanBase Database, overcomes the limitations inherent in HBase.
○ Reliable disaster recovery-oriented deployment: OceanBase Database adopts a multi-replica architecture based on Paxos, allowing you to deploy a cluster across zones. Take a simple cross-zone disaster recovery scenario as an example. As an HBase cluster cannot be deployed across zones, two HBase clusters are needed to achieve cross-zone disaster recovery. If each HDFS cluster is configured with three replicas, a total of six replicas are needed. If you deploy an OceanBase cluster with two full-featured replicas and one arbitration service node, a total of only two replicas are needed to achieve cross-zone disaster recovery.
○ Quick fault recovery: OceanBase Database adopts a native distributed shared-nothing architecture. When a partition fails, another replica is immediately used to provide services, achieving a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8 seconds. This offers a significant advantage over HBase, which typically takes 2‒8 minutes for fault recovery.
(5) Replace HBase with the SQL engine of OceanBase Database in structured data scenarios to boost efficiency at lower costs.
As a wide-column NoSQL database that supports multiple column families and sparse columns, HBase is well suited for unstructured, flexible data models. However, HBase has been used in many structured data scenarios. This is primarily because, in the earlier days, users chose HBase for its mature distributed storage capabilities compared to contemporary SQL databases to address the challenge of storing massive data.
In such cases, especially in analytical processing (AP) scenarios, SQL middleware such as Phoenix was often introduced to boost the performance of structured data operations, thereby enhancing data access and query capabilities and enabling developers to work with familiar SQL tools and IDEs. In these scenarios, you can directly replace the HBase and Phoenix combination with the SQL engine of OceanBase Database to fulfill the need for distributed, massive, and scalable storage while simplifying the system architecture and unifying the technology stack. In addition, the advanced compression and data encoding algorithms of OceanBase Database greatly reduce storage costs and improve cost-effectiveness.
3.3 Smooth migration from HBase to OBKV-HBase
To improve the migration experience from HBase to OBKV-HBase, OBKV is continuously improving its product compatibility and adapting to user habits through various designs to help users get started quickly. This allows you to quickly and smoothly switch from HBase to OBKV-HBase with simple operations and configurations.
○ In terms of migration, OBKV is compatible with HBase in APIs, including DML APIs and other data access APIs, enabling you to complete the adaptation with minimal and simple code changes.
○ In terms of usage, OBKV aligns with user habits in architecture and design, reducing the learning curve and enabling developers to work with OBKV-HBase in a familiar way. For example, an OBKV-HBase tenant is the same as a MySQL tenant. You can use the OBKV-HBase tenant after creating tables in it. Instead of using the SQL engine to support HBase the same way it did for multi-model types such as JSON and GIS, OceanBase Database chooses OBKV for compatibility with HBase APIs. This aligns with mainstream NoSQL databases, allowing you to use native APIs to access these data engines.
4 Replacement Cases
4.1 Beike: replace HBase with the SQL engine of OceanBase Database for the real-time dictionary service
Beike, operated by KE Holdings Inc., is an industry-leading digital housing service platform in China. It is committed to promoting the digitalization and intelligentization of China's housing service industry, aiming at pooling and empowering resources to provide Chinese families with all-in-one, premium, and efficient services, from new home and resale transactions to leasing, home decoration, home furnishing, and home services.
In real-time data warehouse or real-time business scenarios, Beike often uses Flink for real-time stream processing. This process involves typical dimension table join queries. For example, Beike needs to associate the information of an order with the product information in the dimension table involved in real time. Given the fact that a conventional database, such as a MySQL database, can hardly cope with the large data volume and the high real-time QPS of Flink, Beike used to host dimension tables on HBase. However, HBase does not support secondary indexes, making it unsuitable for joining non-primary key fields in Flink tasks. Its complex architecture also poses deployment and O&M challenges.
After thorough assessment and comparison, Beike decided to replace HBase with OceanBase Database. The SQL engine of OceanBase Database boosts dimension table query performance with its native support for secondary indexes and reduces deployment and O&M costs with its simple architecture.
The following figure shows a case where Beike replaced HBase with OceanBase Database for the real-time dictionary service.
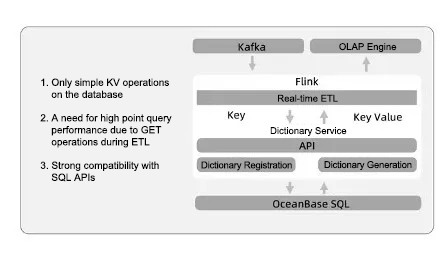
Many metrics of Beike require precise deduplication and counting before online analytical processing (OLAP) calculations. The most common method for precise deduplication and counting is based on bitmap, but this method works only with integer fields. To support fields of other data types such as string, you'll need to build a global dictionary to map non-integers to integers. This scenario involves only simple KV operations, requires high point query performance, and has SQL-friendly data models, making the SQL engine of OceanBase Database an ideal replacement.
To support the real-time dictionary service in Flink tasks, Beike tested both HBase and OceanBase Database. With a data volume of 40,000–80,000 rows or 80,000–160,000 rows, HBase and OceanBase Database both met requirements without any latency. However, with a data volume of 120,000–240,000 rows, HBase took 1.27 seconds to complete data processing and showed an increasing latency over time, while OceanBase Database consistently met the requirements. Only when the data volume reached 280,000-560,000 rows and the number of real-time tasks increased to 7 did OceanBase Database start to experience latency, with a data processing time of 1.1 seconds. During the tests, OceanBase Database also demonstrated obvious advantages in batch reads, batch writes, and throughput.
As a result, Beike replaced HBase with OceanBase Database. This change not only reduces system complexity and lowers deployment and O&M costs, but also improves the query performance by two to five times and the write performance by five times.
4.2 TargetSocial: replace HBase with OBKV-HBase for a boost in ingestion and query performance
Another typical case is the implementation of OBKV-HBase at TargetSocial.
TargetSocial is a well-known social media marketing company in China that specializes in utilizing big data and independently developed systems to help enterprises collaborate with key opinion leaders (KOLs) and manage private and public domain traffic.
Its business spans various areas, including user behavior analysis, tag management, fan management, targeted content delivery, viral marketing, trending topic detection, and brand sentiment analysis. Many of the business scenarios involve KV data. Initially, TargetSocial used HBase as its KV solution.
After comparing HBase and OceanBase Database in terms of performance, deployment, O&M, architecture, and data distribution, TargetSocial found that OceanBase Database was more efficient in reducing costs, simplifying O&M, writing hotspot data, and balancing data. As a result, TargetSocial switched from HBase to OBKV-HBase.
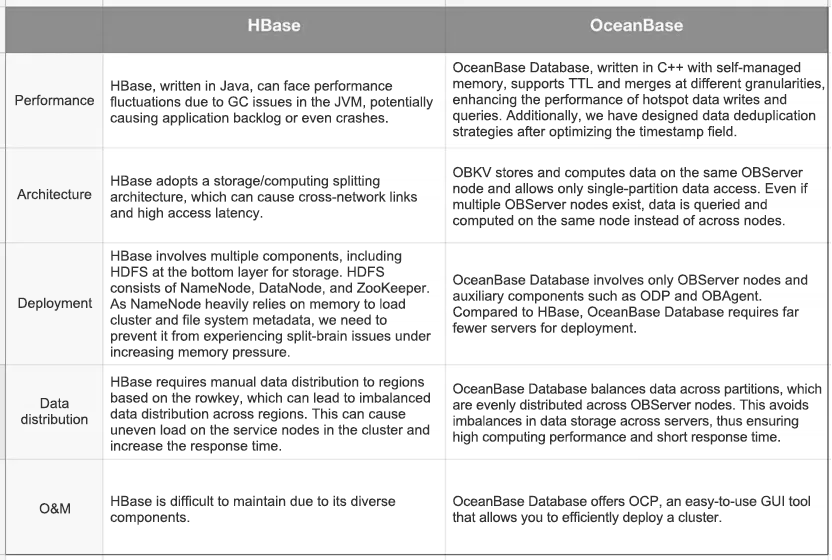
The following figure shows a typical application scenario of OBKV-HBase at TargetSocial, where raw user data and event data are streamed through Kafka to Flink for analysis. Due to the nested structure of the data in dimension and fact tables, Flink re-associates and completes events before passing them to the downstream. This requires the database to have exceptional point query performance, which is exactly what HBase struggles to deliver.
The implementation of OBKV helps TargetSocial achieve an average TPS of 60,000, meeting the demands for high-speed data ingestion and point queries. In the event of upstream data spikes, the peak TPS can reach 110,000 to avoid data backlog. With its simple architecture and the GUI tool of OCP, OceanBase Database helps TargetSocial reduce O&M burdens and management costs.
5 Afterword
In the future, we'll keep enhancing the multi-model capabilities of OceanBase Database for higher performance, better compatibility with different HBase versions, and native support for secondary indexes on OBKV-HBase. We'll also offer more features and tools, such as direct load, to improve usability, making OceanBase Database excel in multi-model scenarios and helping more businesses modernize and transform their systems.
*For more information about OBKV, see OBKV documentation.
