A Brief Analysis of Frequently Asked Questions about Partition Creation
In OceanBase Discord Community, a new module of the OceanBase community forum, a post has introduced how to set partitioning strategies and manage partitioning plans in OceanBase Developer Center (ODC). In that post, I noticed several users asking questions about partition management.
I have encountered one of the mentioned restrictions on partition creation many times but never stopped to consider why it exists. Since a user has raised this question, I will take the opportunity to briefly analyze it and share my insights.
Why Must the Primary Key of a Partitioned Table Include All Partitioning Keys of the Table?
The first user question is as follows: I have a large order table and want to partition the data by year. Currently, the primary key contains only the ID column. I tried to partition the data by date but failed. Must I combine the date and ID columns into a composite primary key?
The answer is yes. The primary key of a partitioned table must include all partitioning keys of the table. The primary key uniqueness check is performed within each partition. If the primary key does not include all partitioning keys, the check may fail. This is why MySQL and other databases also have this restriction.
-- If the primary key does not include all partitioning keys, the table creation operation fails with a clear error message.
create table t1(c1 int,
c2 int,
c3 int,
primary key (c1))
partition by range (c2)
(partition p1 values less than(3),
partition p1 values less than(6));
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function
Here is an example:
create table t1(c1 int,
c2 int,
c3 int,
primary key (c1, c2))
partition by range (c2)
(partition p0 values less than(3),
partition p1 values less than(6));
Query OK, 0 rows affected (0.146 sec)
obclient [test]> insert into t1 values(1, 2, 3);
Query OK, 1 row affected (0.032 sec)
obclient [test]> insert into t1 values(1, 5, 3);
Query OK, 1 row affected (0.032 sec)
obclient [test]> select * from t1;
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
| 1 | 5 | 3 |
+----+----+------+
2 rows in set (0.032 sec)
We created a table, with the c1 and c2 columns as the primary key and the c2 column as the partitioning key. Values smaller than 3 are in the p0 partition, while values greater than or equal to 3 but smaller than 6 are in the p1 partition. We then inserted two rows, with the first row in the p0 partition and the second row in the p1 partition.
obclient [test]> select * from t1 PARTITION(p0);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
+----+----+------+
1 row in set (0.033 sec)
obclient [test]> select * from t1 PARTITION(p1);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 5 | 3 |
+----+----+------+
1 row in set (0.034 sec)
If the primary key includes only c1, the uniqueness check for c1 passes in both p0 and p1 because the c1 values are unique within each partition. As a result, the inserted data is considered to meet the primary key constraint. In reality, duplicate values exist across partitions, and the data violates the primary key constraint. That is why all databases require the primary key to include all partitioning keys during table partitioning.
Why Does Partitioning Speed Up Queries?
The second user question is as follows: Does partitioning by date speed up queries?
My personal understanding is that partitioning not only balances data from large tables across different database nodes but also speeds up queries. During the execution of a query, the partitioning key in the filter condition is used for partition pruning. Here are two examples.
If a partitioning key is included in the filter condition, you can find partitions(p0) in the plan, indicating only data in p0 is scanned.
obclient [test]> explain select * from t1 where c2 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.034 sec)
If no partitioning key is included in the filter condition, you can find partitions(p[0-1]) in the plan, indicating data in p0 and p1 is scanned. The PX PARTITION ITERATOR operator is used to iterate through and scan all partitions.
obclient [test]> explain select * from t1 where c3 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |6 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |6 | |
| |2 | └─PX PARTITION ITERATOR| |1 |5 | |
| |3 | └─TABLE FULL SCAN |t1 |1 |5 | |
| ============================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| force partition granule |
| 3 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c3 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p[0-1]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
19 rows in set (0.038 sec)
RANGE Partitioning Does Not Support the DATETIME Type. What Should I Do?
The third user question is as follows: RANGE partitioning does not support the DATETIME type. What should I do?
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE(UNIX_TIMESTAMP(a))(
PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),
PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),
PARTITION pn VALUES less than MAXVALUE);
ERROR 1486 (HY000): Constant or random or timezone-dependent expressions in (sub)partitioning function are not allowed
I tested the MySQL mode of OceanBase Database and found that it has imposed some restrictions on random expressions for compatibility with MySQL. I first considered using generated columns as a workaround, only to find that OceanBase Database disallows the use of the UNIX_TIMESTAMP expression in them, which is also for compatibility with MySQL.
CREATE TABLE ff01 (a datetime , b timestamp as (UNIX_TIMESTAMP(a)))
PARTITION BY RANGE(b)(
PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),
PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),
PARTITION pn VALUES less than MAXVALUE
);
ERROR 3102 (HY000): Expression of generated column contains a disallowed function
UNIX_TIMESTAMP is disallowed in generated columns probably because it is a nondeterministic system function. As a nondeterministic function, UNIX_TIMESTAMP() may return different results when executed at different times, even one second apart. Therefore, nondeterministic functions are not allowed in expressions for partitions, expressions for generated columns, or expressions in check constraints.
Here is a simple example to clarify the meaning of "random" shown in ERROR 1486 and the meaning of "nondeterministic:"
obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008180 |
+------------------+
1 row in set (0.042 sec)
obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008419 |
+------------------+
1 row in set (0.041 sec)
-- Now you see why UNIX_TIMESTAMP is so special that it is disallowed almost everywhere.
It is undeniable that OceanBase Database offers impressive compatibility with MySQL, accommodating not only usage restrictions but also bugs. While this may cause some inconvenience, migration from MySQL should be much smoother.
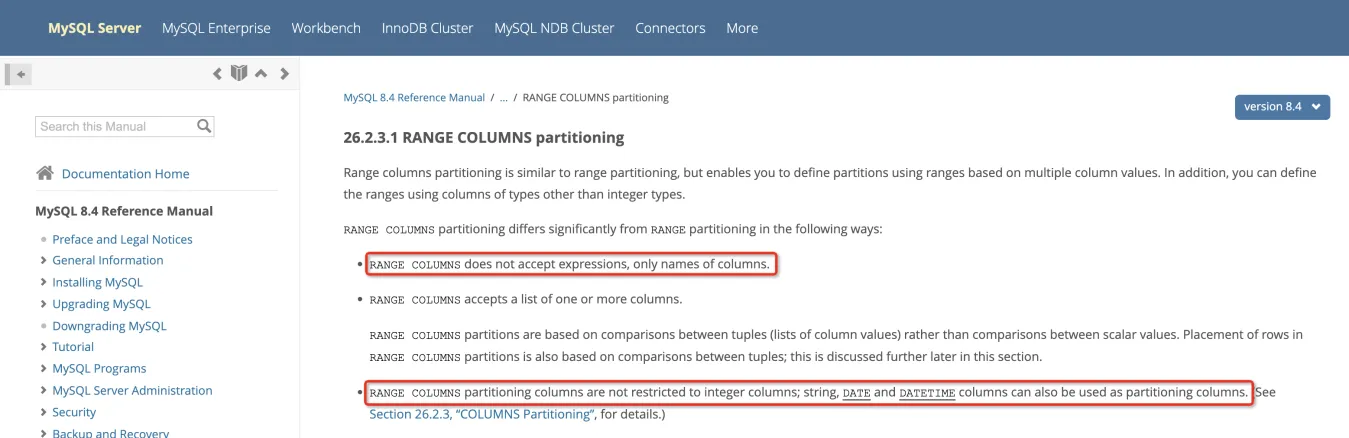
After checking the documentation of OceanBase Database on the official website, I found RANGE COLUMNS partitioning is similar to RANGE partitioning. Compared to RANGE partitioning, RANGE COLUMNS partitioning supports more data types, including DATETIME, but does not support the use of expressions in partition definitions.
Therefore, users can replace RANGE partitioning with RANGE COLUMNS partitioning to use nondeterministic functions such as UNIX_TIMESTAMP. Here is an example:
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE COLUMNS(a)(
PARTITION p0 VALUES less than ('2023-01-01'),
PARTITION p1 VALUES less than ('2023-01-02'),
PARTITION pn VALUES less than MAXVALUE);
Query OK, 0 rows affected (0.101 sec)
Actually, I never realized the difference between RANGE partitioning and RANGE COLUMNS partitioning until today.
If you are interested, see MySQL official documentation for a better understanding.
What Else?
In terms of the third user question, a colleague has suggested replacing the UNIX_TIMESTAMP function with the to_days function. This eliminates the need to switch from RANGE partitioning to RANGE COLUMNS partitioning. Here is an example:
## Create a RANGE-based partitioned table.
-- The partitioning key column is start_time, whose data type is DATETIME.
CREATE TABLE dba_test_range_1 (
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'primary key',
`name` varchar(50) NOT NULL COMMENT 'name',
start_time datetime NOT NULL COMMENT 'start time',
PRIMARY KEY (id, start_time)
) AUTO_INCREMENT = 1 CHARSET = utf8mb4 COMMENT 'test range'
PARTITION BY RANGE (to_days(start_time)) (
PARTITION M202301 VALUES LESS THAN (to_days('2023-02-01')),
PARTITION M202302 VALUES LESS THAN (to_days('2023-03-01')),
PARTITION M202303 VALUES LESS THAN (to_days('2023-04-01'))
);