Release of OceanBase Database V4.3.3: The First GA Version for Real-time Analytics
We're excited to announce that OceanBase Database V4.3.3, a General Availability (GA) version, was officially released. We unveiled this new version at this year's product launch in the last week. As the first GA version targeted at real-time analytical processing (AP) scenarios, OceanBase Database V4.3.3 is significantly optimized and improved in many aspects. Its integrated capabilities can better meet users' needs in real-time analysis and diversified business scenarios.
In early 2024, we released OceanBase Database V4.3.0, marking a critical step toward real-time analytics with its log-structured merge-tree (LSM-tree)-based columnar storage engine. Forged in the crucible of dozens of real-world business scenarios, OceanBase Database V4.3.3 further advances AP performance and features. By providing the hybrid transaction/analytical processing (HTAP) capabilities, it helps users shorten the response time and improve the throughput for complex workloads.
Multiple breakthroughs have been made in OceanBase Database V4.3.3. We have remarkably improved the system performance for complex workloads, especially for AP workloads. We have also optimized the columnar storage engine and extended its application scenarios, including columnstore tables, columnstore indexes, hybrid rowstore-columnstore tables, and columnstore replicas.
In addition, the system presents more flexibility in processing diversified schema types and data types, such as materialized views, external tables, RoaringBitmaps, and arrays, with the introduction of vectorized engine 2.0. With columnstore replicas in a new form, resources for transaction processing (TP) and AP workloads are physically isolated to avoid interference between the two types of workloads. This way, high performance and stability can be ensured in complex scenarios such as real-time data analytics and decision.
The TPC-H benchmark results show that compared with the 99 seconds taken by V4.3.0, the GA version of OceanBase Database V4.3.3 spent only 60 seconds querying a dataset of 1 TB, improving the performance by 64%. OceanBase Database V4.3.3 meets diverse needs for data storage and analysis in different business scenarios, while ensuring faster response to massive data analysis requests at a higher throughput.
In terms of AI features, OceanBase Database V4.3.3 introduces vector retrieval to support vector data and indexes. By leveraging powerful multi-model integration and distributed storage, this version noticeably simplifies the AI application technology stack and helps enterprises construct AI-powered applications efficiently.
The release of V4.3.3 symbolizes that OceanBase Database makes significant progress in the integration of real-time AP and AI-powered vectorized engine. Next, let's take a deeper dive into the main features and highlights of the GA version of OceanBase Database V4.3.3.
-
Columnar storage
-
Vectorized engine 2.0
-
Materialized view
-
External table
-
Data import and export
-
Complex data types
-
Vector search
-
Full-text index
-
Reliability improvement
1. AP Features
1.1 Columnar storage
In scenarios involving large-scale data analytics or extensive ad-hoc queries, columnar storage stands out as a crucial feature of an AP database. Columnar storage is a way to organize data files. Different from row-based storage, columnar storage physically arranges data in a table by column. When data is stored by column, the system can scan only the columns involved in the query and calculation, instead of scanning the entire row. This way, the consumption of resources such as I/O and memory is reduced, and the calculation is accelerated. In addition, columnar storage naturally has better data compression conditions and usually offers a higher compression ratio, thereby reducing the required storage space and network transmission bandwidth.
OceanBase Database supports the columnar engine based on the LSM-tree-based architecture, implementing integrated columnar and row-based data storage on an OBServer node with only one set of code and one architecture, and ensuring the performance of both TP and AP requests. We provide several columnar storage solutions to meet users needs in different business scenarios.
- Columnstore table: This solution applies only to AP business, which features higher analytic performance. On this basis, if users want to perform point queries on a table at high performance, they only need to create rowstore indexes on the table.
- Columnstore index: This solution mainly targets TP business. If a few analytic needs are involved, users can create columnstore indexes only on the columns to be analyzed in a rowstore table.
- Hybrid rowstore-columnstore table: This solution applies only when the boundary between TP and AP businesses is not clear, namely when both online transaction processing (OLTP) and online analytical processing (OLAP) workloads exist in a business module. In this case, users can create hybrid rowstore-columnstore tables to store business data, and the optimizer determines whether to store the data by row or column based on the costs. Resource groups can be created to isolate resources at the user or SQL statement level.
- Columnstore replica: Users can configure dedicated zones to store read-only columnstore replicas based on their TP clusters if they want to physically isolate resources in HTAP scenarios. This way, TP business can access only rowstore zones, while AP business can access columnstore zones in weak-consistency read mode.
1.2 Vectorized engine 2.0
Earlier versions of OceanBase Database have implemented a vectorized engine based on uniform data format descriptions, offering performance significantly better than that of non-vectorized engines. However, the engine still has some performance deficiencies in deep AP scenarios. The new version of OceanBase Database implements the vectorized engine 2.0, which is based on column data format descriptions, avoiding the memory usage, serialization, and read/write access overhead caused by ObDatum maintenance. Based on the new column data format descriptions, OceanBase Database optimizes the implementation mechanisms of operators and expressions, remarkably increasing the computing performance in case of a large data volume.
1.3 Materialized views
By precomputing and storing the query results of materialized views, real-time calculations are reduced to improve query performance and simplify complex query logic. Materialized views are commonly used for rapid report generation and data analysis scenarios.
Materialized views need to store query result sets to optimize the query performance. Due to data dependency between a materialized view and its base tables, data in the materialized view must be refreshed accordingly when data in any base tables changes. Therefore, the materialized view refresh mechanism is also introduced in the new version, including complete refresh and incremental refresh strategies. Complete refresh is a more direct approach where each time the refresh operation is executed, the system will re-execute the query statement corresponding to the materialized view, completely calculate and overwrite the original view result data. This method is suitable for scenarios with relatively small data volumes. Incremental refresh, by contrast, only deals with data that has been changed since the last refresh. To ensure precise incremental refreshes, OceanBase Database has implemented a materialized view log mechanism similar to that in Oracle databases, which tracks and records incremental update data of the base table in detail through logs, ensuring that the materialized view can be quickly incrementally refreshed. Incremental refresh is suitable for business scenarios with substantial data volumes and frequent data changes.
Non-real-time materialized views can be refreshed on a regular basis or manually to handle queries in most analysis scenarios. However, real-time materialized views are more suitable in business scenarios requiring high real-time performance. Therefore, OceanBase Database provides real-time computing capabilities based on materialized views and materialized view logs (mlogs) outperforming common views.
The new version also allows users to rewrite a query based on a materialized view. When the system variable QUERY_REWRITE_ENABLED is set to True, users can enable automatic rewriting in the materialized view creation statement. After automatic rewriting is enabled, the system can rewrite table queries into materialized view-based queries without requiring users to specify the materialized view name in the SQL statement, thus reducing the rewrite costs.
To support PRIMARY KEY constraints on materialized views, OceanBase Database allows users to specify a primary key for a materialized view to optimize the performance in scenarios such as single-row query, range query, or association based on the primary key.
1.4 External table
OceanBase Database has supported external tables in the CSV format since a very early version and introduces more supported formats including GZIP, DEFLATE, and ZSTD in the new version. As the AP business develops, the need for reading external data sources in the Parquet format is increasing in some data lake scenarios. Therefore, the new version of OceanBase Database supports external tables in the Parquet format. Users can import data into internal OceanBase tables through external tables or directly use external tables for cross-data source joint queries and analysis.
The new version also supports external table partitioning, which is similar to the LIST partitioning for common tables, and provides syntax for both manual and automatic partitioning. In automatic partition creation mode, the system groups files by partition based on the definition of the partitioning key. In manual partition creation mode, users need to specify the path to the data file of each partition. In this case, the system implements partition pruning based on the partitioning conditions for an external table query, thereby reducing the number of files to scan and improving the query performance.
Meanwhile, to ensure the timeliness of the file directories scanned by external tables, the new version introduces the automatic refresh feature. With this feature, users can use the AUTO_REFRESH option to specify the directory refresh method (manual, real-time, or periodic) during external table creation, and manage scheduled refresh tasks by using the DBMS_EXTERNAL_TABLE.REFRESH_ALL_TABLE(interval int) subprogram together with the preceding option.
1.5 Data import and export
While TP business mainly involves data insert operations, batch data import and data processing that require high performance are more common in AP business. OceanBase Database supports the following import methods: direct load, external table import, partition exchange, overwriting, import from the client, and regular import.
- Direct load: This feature simplifies the data loading path and skips the SQL, transaction, MemTable, and other modules to directly persist data into SSTables, which significantly improves the data import efficiency. Direct load supports the import of both full data and incremental data. Data in tables needs to be rewritten during full direct load, which means it is better to import an empty table by using this method. If users need to import data into a table multiple times, they can use the incremental direct load feature. With this feature, the database writes only new data rather than repeatedly writing all existing data. This ensures high import performance.
- External table import: To achieve better analysis performance in the current stage, users can use the INSERT INTO SELECT statement to import an external table into the internal OceanBase database. Direct load can be used together with this method to improve the import performance.
- Partition exchange: This feature allows users to modify the partition and table definitions in the data dictionary to migrate data with minimal delay from one table to a partition in another table without physically replicating the data. This method applies to scenarios where cold data needs to be archived and distinguished from hot data.
- Overwriting: In data warehouses, overwriting is common in periodic data refresh, data conversion, data cleansing, and data correction. OceanBase Database supports table- and partition-level overwriting. Specifically, the database can empty old data and write new data in a table or partition in an atomic manner. Based on the full direct load capability, executing the INSERT OVERWRITE statement can improve the import performance.
- Local import from the client using the LOAD DATA LOCAL INFILE statement: This feature enables the import of local files through streaming file processing. Based on this feature, developers can import local files for testing without uploading files to the server or object storage media, improving the efficiency of importing a small amount of data.
- Regular import: Different from direct load, regular import needs to be optimized by the SQL engine, which applies to scenarios where multiple constraints exist.
Real-time data import is supported in multiple methods, as described above. However, real-time data import requires the session to wait until the import is complete and cannot be interrupted during this process, which is inconvenient when a large amount of data is to be imported. To address this issue, OceanBase Database provides the asynchronous job scheduling capability. Users can use the SUBMIT JOB, SHOW JOB STATUS, and CANCEL JOB statements to respectively create an asynchronous import job, query the job status, and cancel a job.
In terms of data export, the kernel of OceanBase Database enables users to execute the SELECT INTO OUTFILE statement to export text files, and supports parallel table data reading and external file writing. It also allows data export based on user-defined partitioning rules. We will strive to fully support the external table export feature, which is implemented by using the INSERT OVERWRITE statement, in later versions of OceanBase Database.
1.6 Complex data types
In the era of big data, enterprises are increasingly keen on data mining and analysis. Featuring efficient computing with less storage space, RoaringBitmap plays a key role in business scenarios such as user profiling, personalized recommendations, and precise marketing. The MySQL mode of OceanBase Database supports the RoaringBitmap data type and improves performance in the calculation and deduplication of a large amount of data by storing and operating a group of unsigned integers. To meet multi-dimensional analysis needs, the new version of OceanBase Database supports more than 20 expressions for cardinality calculation, set calculation, bitmap judgment, bitmap construction, bitmap output, and aggregate operation.
ARRAY is a common complex data type in AP business scenarios. An array can store multiple elements of the same type. If you need to manage and query multi-valued attributes that cannot be effectively represented by relational data, the ARRAY data type is an appropriate choice. OceanBase Database supports the ARRAY data type in MySQL mode. During table creation, you can define a column as an array of numeric or character values, which can also be an embedded array. You can also create an expression for querying or writing array objects. The array_contains expression and ANY operator can be used to verify whether an array contains a specific element. Moreover, you can also use operators, such as +, -, =, and !=, to calculate and judge the elements in an array.
The multi-valued index feature applies to JSON documents and other collection data types, effectively facilitating element retrieval. OceanBase Database in MySQL mode supports the multi-valued index feature for JSON data. You can create an efficient secondary index on a JSON array of multiple elements. This enhances the capabilities to query complex JSON data structures while ensuring the data model flexibility and data query performance.
2. AP Performance Improvement
2.1 Benchmark tests
2.1.1 TPC-H (1 TB): a decline from 99s to 60s
The TPC-H (1 TB) benchmark test results show a great performance increase in OceanBase V4.3.3 compared with V4.3.0. The execution time of queries is 99s in V4.3.0, which is reduced to 60s in V4.3.3, improving performance by 64%. As shown in the following figure, V4.3.3 presents obviously higher performance than V4.3.0 in multiple query tasks, further demonstrating the optimization effects of OceanBase Database in real-time analysis scenarios.
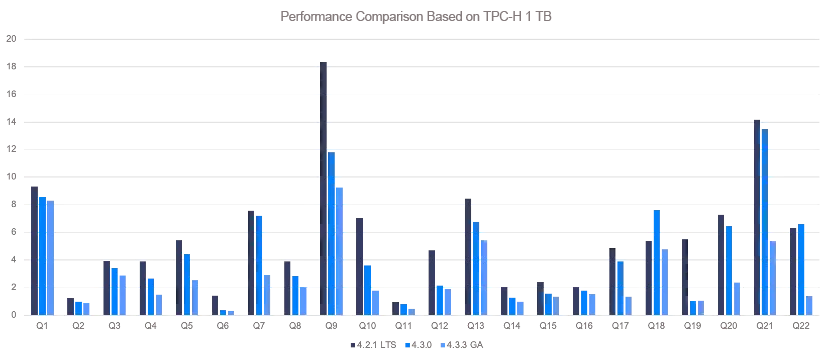
| 4.2.1 LTS | 4.3.0 | 4.3.3 | |
|---|---|---|---|
| Time consumed (s) | 126.32 | 99.14 | 60.41 |
| Performance improvement | 27% | 64% |
2.1.2 Better performance in ClickBench tests
The ClickBench test results show that, in cold run scenarios, ClickHouse spent 139.57s executing queries, while OceanBase Database V4.3.3 spent 90.91s, 54% higher than the query performance of ClickHouse. In two hot run scenarios, the execution times of ClickHouse were 44.05s and 36.63s, respectively, while OceanBase improved the query performance by 26% (34.92s) and 6% (34.08s), respectively. These figures indicate a great performance increase of OceanBase Database in multiple query executions.

2.2 Scenario-specific parameter initialization
As an integrated database, OceanBase Database supports multiple business types, including express OLTP, complex OLTP, OLAP, HTAP, and KV. Default system settings may be unable to suit all scenarios. For example, the recommended I/O read method varies depending on business scenarios. Therefore, OceanBase Database provides recommended settings of key parameters based on different business types by leveraging cloud platforms and OceanBase Cloud Platform (OCP), in order to achieve the optimal out-of-the-box performance.
3. Enhanced AP Stability
When an SQL query involves a large amount of data, the memory may be insufficient. In this case, the temporary intermediate results of some operators must be materialized. The execution of the SQL query fails if the disk space is fully occupied by the materialized data. OceanBase Database supports compressing temporary results of SQL queries. This feature effectively reduces the disk space occupied temporarily, so as to support query tasks with higher computing workload.
4. Vector Search
The development and popularization of AI applications have triggered explosive growth in unstructured data such as images, videos, and texts. With embedding algorithms, unstructured data can be represented as high-dimensional vectors for analysis and processing. Vector databases emerged during this process. A vector database is a fully managed solution for processing unstructured data, which is used for storing, indexing, and retrieving embedding vectors. Vector indexes are an essential capability of a vector database. They convert a keyword-based search into a vectorized retrieval to turn a deterministic search into a similarity search, meeting the requirements for retrieving large-scale, high-dimensional vectors.
OceanBase Database in MySQL mode supports vector type storage, vector indexes, and embedding vector retrieval. It supports the storage of float vectors with at most 16,000 dimensions, basic operations such as addition, subtraction, multiplication, comparison, and aggregation, as well as Approximate Nearest Neighbor Search (ANNS), along with Hierarchical Navigable Small World Network (HNSW) indexes for at most 2,000 dimensions. It can be used for Retrieval-Augmented Generation (RAG) to adapt to business scenarios such as image and video retrieval, behavior preference recommendation, security and fraud detection, and ChatGPT-like applications.
Currently, OceanBase Database has integrated some application frameworks like LlamaIndex and DB-GPT to allow quick construction of AI-powered applications. Adaption to other frameworks is under planning as well.
5. Full-text Retrieval
In relational databases, indexes are often used to accelerate queries based on precise value matching. Common B-tree indexes cannot be applied to scenarios where a large amount of text data needs to be queried in fuzzy search mode. In this case, full table scans can only query data row by row, failing to meet performance requirements in case of a large volume of text data. On top of this issue, SQL rewriting also fails to support queries in complex scenarios such as approximate matching and correlation sorting.
To address these issues, OceanBase Database supports the full-text index feature. This feature allows users to preprocess text content and create keyword-based indexes to effectively improve full-text retrieval efficiency. MySQL-compatible full-text retrieval has been supported now and will be extended to support more complex retrieval logic features for higher performance.
6. Reliability Improvement
OceanBase Database V4.3.3 supports tenant cloning. Users can quickly clone a specified primary or standby tenant by executing an SQL statement in the sys tenant. After a tenant cloning job is completed, the created tenant is a standby tenant. Users can convert the standby tenant into the primary tenant to provide services. The new tenant and the source tenant share physical macroblocks in the initial state, but new data changes and resource usage are isolated between the tenants. Users can clone an online tenant for temporary data analysis with high resource consumption or other high-risk operations to avoid risking the online tenant. In addition, users can also clone a tenant for disaster recovery. When irrecoverable misoperations are performed in the source tenant, they can use the new tenant for data rollback.
In addition, OceanBase Database V4.3.3 provides a quick restore feature. In OceanBase Database of earlier versions, physical restore is a process of restoring the full data. A physical restore is completed only after all the data (minor compaction data and baseline data) and logs are restored. Then, users can log in to and use the restored tenant. If a large amount of data is to be restored to a tenant, the restore will take a long time and users need to reserve sufficient disk space for the tenant at the very beginning to ensure a successful restore. In some scenarios, a tenant is restored only for query and verification purposes and will be destroyed later. If only a few tablets are involved during the query, a full restore costs too high and is a waste of storage space, time, and network bandwidth.
The quick restore feature supported in the new version allows users to implement read services by restoring only logs rather than data to the local server. In addition, the data backup feature allows users to build an intermediate-layer index for a backup SSTable based on the backup address. With this index, OBServer nodes can randomly read data from the backup SSTable like reading local data.
7. Summary
The GA version V4.3.3 is an important breakthrough of OceanBase Database in real-time analysis and AP scenarios, signifying a stride toward building a modern database architecture. In later 4.3.x versions, we will keep optimizing and enhancing AP features and build integrated product capabilities to meet diversified needs in different business scenarios.
We'd like to extend thanks to every user and developer who has provided support and made contributions to OceanBase Database V4.3.3. Your feedback and suggestions give impetus to our product upgrades and help us thrive on challenges. We hope to join hands with users to build a more efficient and powerful distributed database product in the future.
You can read What's New to learn more about the general availability of OceanBase Database V4.3.3.