Principles of ALTER TABLE in OceanBase Database
Foreword
Today, databases come in diverse varieties with rich functionalities. They typically fall into two types: relational and non-relational databases. Relational databases organize data in tables and adhere to relational constraints. For example, a table can consist of multiple columns, each with a different data type. When modifying the table schema, such as creating indexes, altering the primary key, adding or removing columns, or repartitioning the table, you are performing a DDL operation. OceanBase Database supports a variety of DDL operations to meet the production needs of users. So what are the forms and principles of DDL operations? In this article, we use the execution of ALTER TABLE as an example to delve into how DDL statements work. Note that the following content only applies to OceanBase Database V4.x.
DDL Process
Let's begin our exploration of DDL with an SQL statement that changes the type of a column. Assume that we have a table named t1, which contains a column of the int type named c1. We perform the following DDL operation:
alter table t1 modify column c1 bigint;
If we have an OBProxy deployed in the cluster, the SQL statement is first sent to the OBProxy. After brief parsing and routing calculations, the OBProxy forwards the SQL statement to an OBServer node, referred to as the intermediate OBServer node, in the cluster. On receiving the SQL statement, the intermediate OBServer node parses the syntax and semantics of the statement, identifying it as an ALTER TABLE DDL statement. After the statement is processed by the optimizer and executor and a physical plan is generated for the statement, the intermediate OBServer node forwards the statement through a remote procedure call (RPC) to the OBServer node that hosts RootService (RS). When receiving the RPC request from the intermediate OBServer node, RS parses the request to get the schema modification data, stores the data in the inner table, and initiates a DDL task for corresponding OBServer nodes to execute. Once the task is completed, RS returns the task status to the intermediate OBServer node. For a long-running DDL operation, RS identifies it and returns the task ID to the intermediate OBServer node after creating the task. The intermediate OBServer node polls the task status to decide when to finalize the response. At last, the intermediate OBServer node updates the OBProxy with the task status, and the OBProxy returns the task status to the client, completing the DDL operation. Here is the flowchart.

ALTER TABLE
Having understood the execution process of DDL statements, let's look at the operations that ALTER TABLE triggers internally.
When receiving the request from the intermediate OBServer node, RS knows it is a DDL statement for changing the type of a column. After some calculations, RS identifies the DDL statement as an offline DDL statement that requires data reorganization for the table. Therefore, RS creates a DDL task from the parsed information and adds it to the DDL task queue. Then, the DDL scheduler retrieves the task from the queue, executes the task, and stores the execution result in the inner table. Finally, the intermediate OBServer node checks the real-time task status from this table to decide whether to conclude the process. Here is the simplified flowchart.
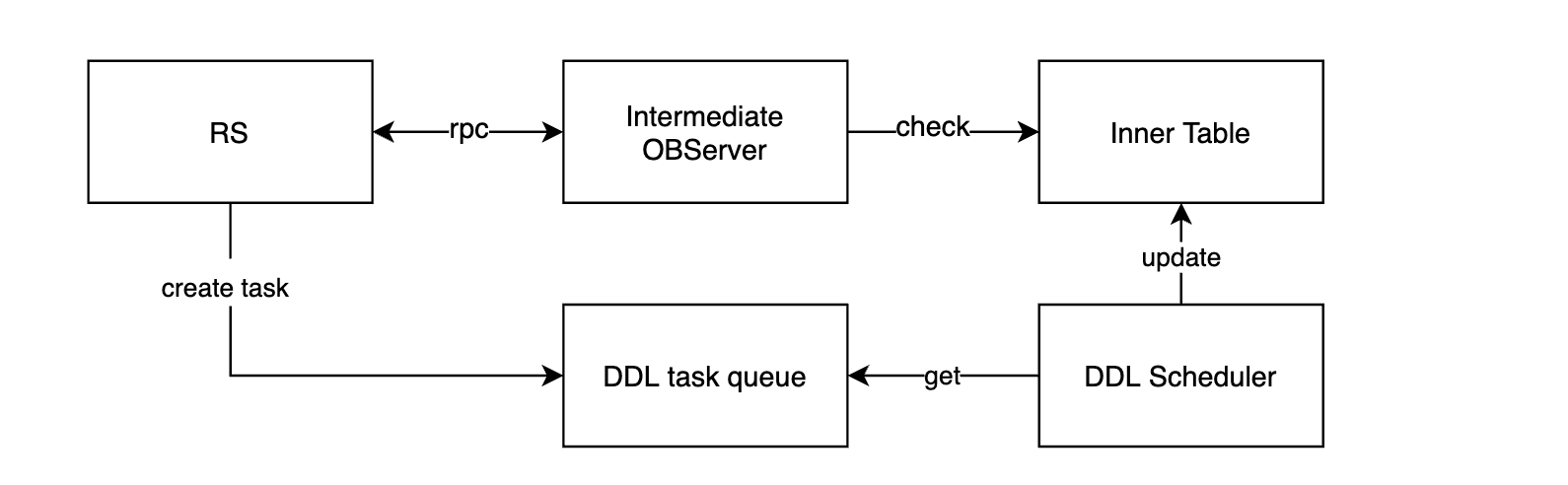
During the process, the DDL scheduler handles the heaviest workload because it keeps retrieving and executing tasks from the DDL task queue.
Some may ask, "If my DDL task runs for a long time, will it block the scheduler from executing other tasks?" The answer is no. First, the DDL scheduler has more than one thread available. Second, every DDL task is divided by state for segmented execution. The task completes a state transition each time the DDL scheduler schedules it. The DDL scheduler relies on these state transitions to advance the task until it reaches the final success state.
What if a task gets stuck in a certain state? That's a great question. We use a retry mechanism for fault tolerance, usually with a 72-hour timeout for a DDL task. In scenarios where a DDL task takes a longer time during the data completion phase due to large data volumes, we wait for the data completion to finish. In other scenarios, such as failures in obtaining the table entry or lock conflicts, we retry. From our experience, a 72-hour timeout is sufficient for fault tolerance.
If a leader switchover occurs to RS when it is handling a DDL operation, how do we restore the lost in-memory task queue information of the original leader? This is easy to resolve as we have considered scenarios such as restart upon failure and leader switchover. While RS creates a DDL task, we persist the task state in the inner table. In the event of a leader switchover, RS restores the task state from the inner table and resumes the execution from the previous state.
DDL Task States and Progressions
Since OceanBase Database advances DDL tasks using a state machine, let's look at the key states and progressions of a DDL task that changes the type of a column.

Wait_trans_end
Wait for transactions to end. When performing a DDL operation for column type conversion, OceanBase Database writes two tables. In other words, the database creates a hidden table with the schema specified in the DDL statement, and replicates all data from the old table to the new one. However, as some transactions before the DDL operation may be ongoing after the table is created, it is necessary to wait for them to end and obtain a global snapshot point for subsequent operations.
Obtain_snapshot
Obtain a snapshot point. After the transactions end, we obtain a global snapshot point. It serves as the basis for replicating data from the old table to the new one. At this point, you only need to complete the data prior to the snapshot to ensure that the new table has full data. It is worth noting that some transactions before the snapshot may have inserted data into the new table. However, idempotence ensures that the data read from the table is correct.
Redefinition
Complete data. After the preceding state ends, we get a global snapshot point. If the DDL operation modifies a non-primary key column and involves no change to the partitioning key, the macroblocks related to the modified column do not need to be re-sorted. This is easy to understand. Since the partitioning key remains unchanged, the new table has the same partitioning rules and partition locations as the original one. To better understand the logic of data completion, we briefly introduce its types.
Data completion falls into three types:
-
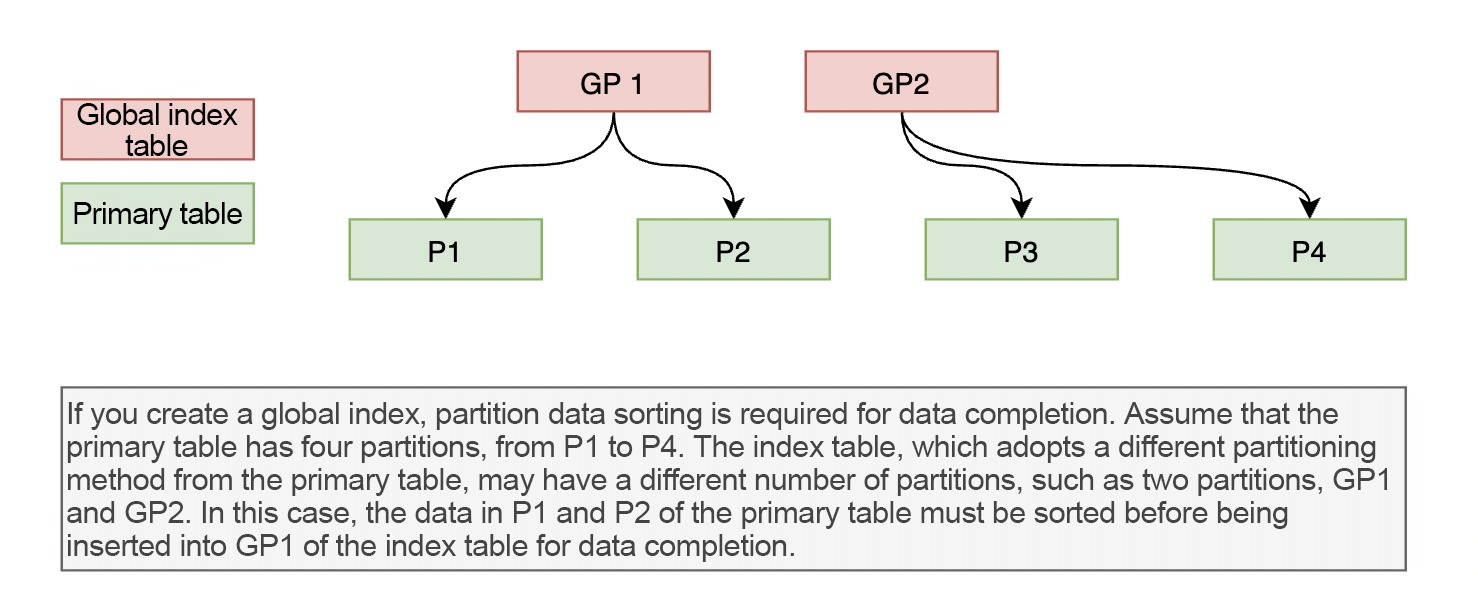
The first type requires partition data sorting while the source and destination tables have different partitioning rules, such as data completion after you create a global index. Sorting refers to rearranging the data in primary table partitions before populating it into the global index table.
-
The second type requires partition data sorting while the source and destination tables have the same partitioning rules, such as data completion after you modify the primary key or create a local index. This is easy to understand. Modifying the primary key or creating a local index does not change how the old and new tables are partitioned, but it affects the order of the data in the partitions. Sorting refers to rearranging the data before populating it into the partitions of the new table.
-
The third type does not require partition data sorting, such as data completion after you change the type of a non-primary key column. This is even more easy to understand. If the primary key (rowkey) remains unchanged, changing the type of a column does not affect the order in which data is stored, and thus does not require re-sorting.
To visualize how data in partitions is sorted, we demonstrate the data completion process after the creation of a global index.
Copy_table_dependent_object
Rebuild objects and constraints related to the original table. For example, after changing the type of a column in the index table, we must rebuild the index table. In this case, RS creates a rebuild task, which follows a similar process to a DDL operation on the primary table.
Take_effect
Apply the new table. After the data completion, the new table is ready to serve with full data. As the table is locked throughout the data completion phase, it is protected from concurrent DML and DDL operations. Therefore, we can directly change the name of the new table to that of the old table. Then, perform the final tasks, such as restoring partition read/write access, dropping the old table, and clearing temporary data.
Online and Offline DDL Operations
Here we briefly clarify the aforementioned terms "online" and "offline". OceanBase Database writes two tables during an offline DDL operation, creating a hidden table and reorganizing the data in the primary table. As OceanBase Database writes data to the new table, the execution time increases proportionally with the table data volume. During the execution of an offline DDL operation, DML operations are blocked. The underlying principle is simple. A lock is created for the table on which the DDL operation is performed. When a DML operation tries to obtain the lock and finds it held by another transaction, the DML operation keeps retrying until it exits due to a timeout. On the contrary, during the execution of an online DDL operation, DML operations are allowed. The implementation is that a DDL operation, such as renaming a table or adding a column, only modifies the metadata of the schema. Once the schema is modified, other transactions can immediately operate the new table, while data in the original table does not need to be reorganized right away.
For more information about the types of online DDL operations that OceanBase Database supports, see OceanBase Database V4.0: Our Designs of and Thoughts on Efficient and Transparent DDL Operations.
Afterword
Reading through the preceding sections, you probably have had a general understanding of the ALTER TABLE process in OceanBase Database. DDL operations can be divided into diverse types. We have discussed only the one type of offline DDL operations used for changing column types, in the hope of offering you an overview. Although the overall DDL process in OceanBase Database is relatively simple, it involves many details because of its interactions with transactions, RS, replications, and migrations, as well as its impacts on CPU and disk I/O. If you are interested, read the code for implementation details or join the discussion in the comments section.