Columnar Storage Engine: Your Ticket to OLAP
Recently, the OceanBase team has rolled out OceanBase Database V4.3.0. According to the official website, "This update leverages the log-structured merge-tree (LSM-tree) architecture of OceanBase Database to combine row-based and columnar storage, introducing a new vectorized engine and a cost evaluation model based on columnar storage. These enhancements significantly boost the efficiency of processing wide tables, improve query performance in AP scenarios, and cater to TP business requirements."
This article kicks off a series on AP performance. It covers basic tests of the columnar storage feature based on the official description and extracts practical usage tips from the test results.
Background
Let's begin with the concepts of "baseline data" and "incremental data" in the storage architecture of OceanBase Database.
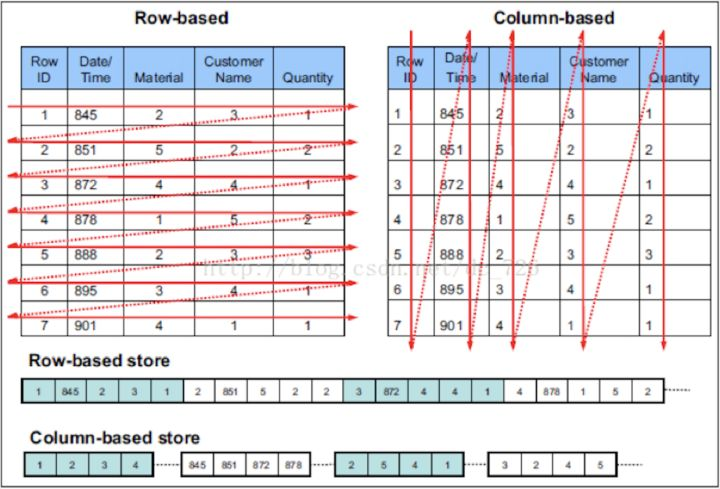
The storage architecture of OceanBase Database is as follows.
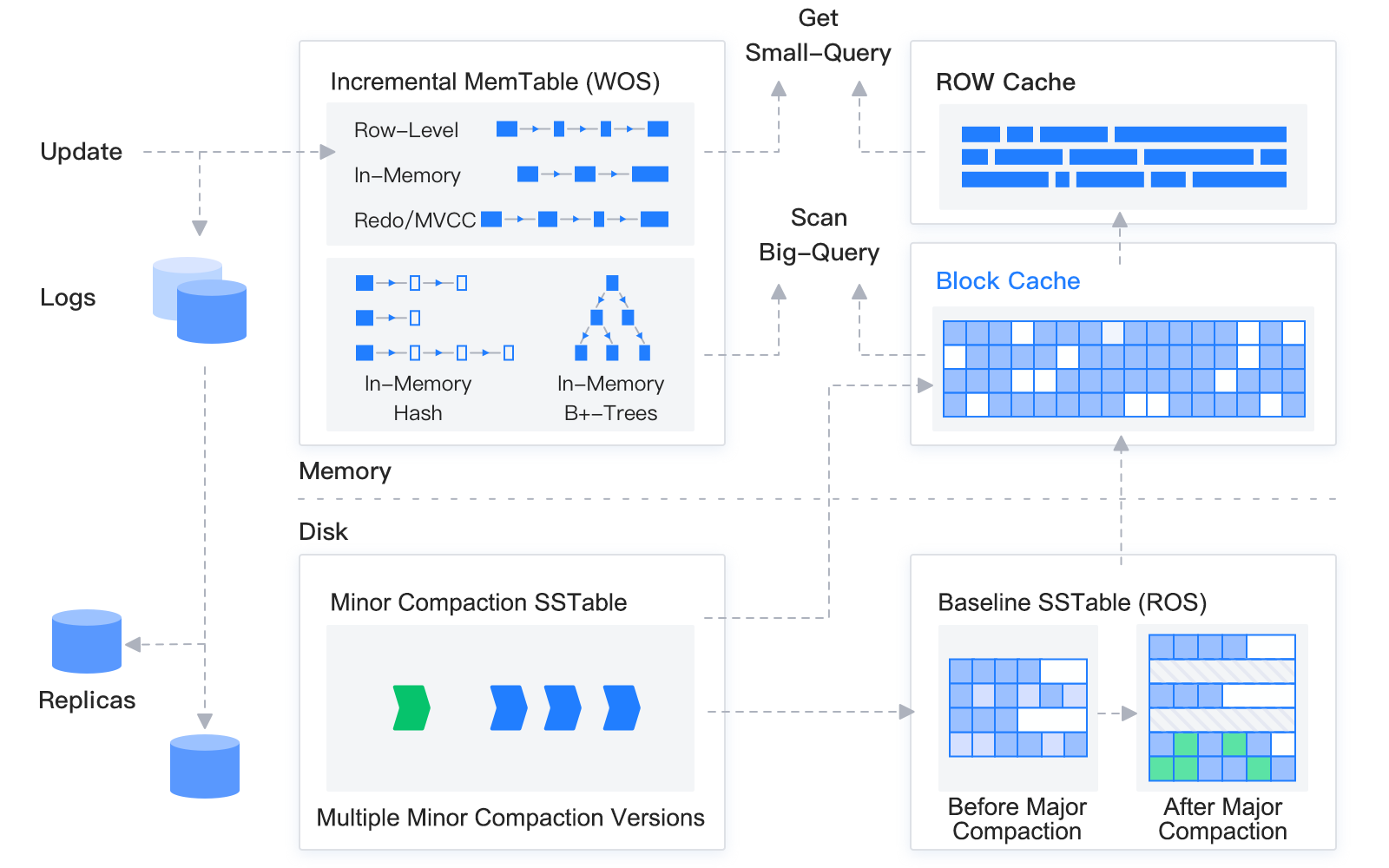
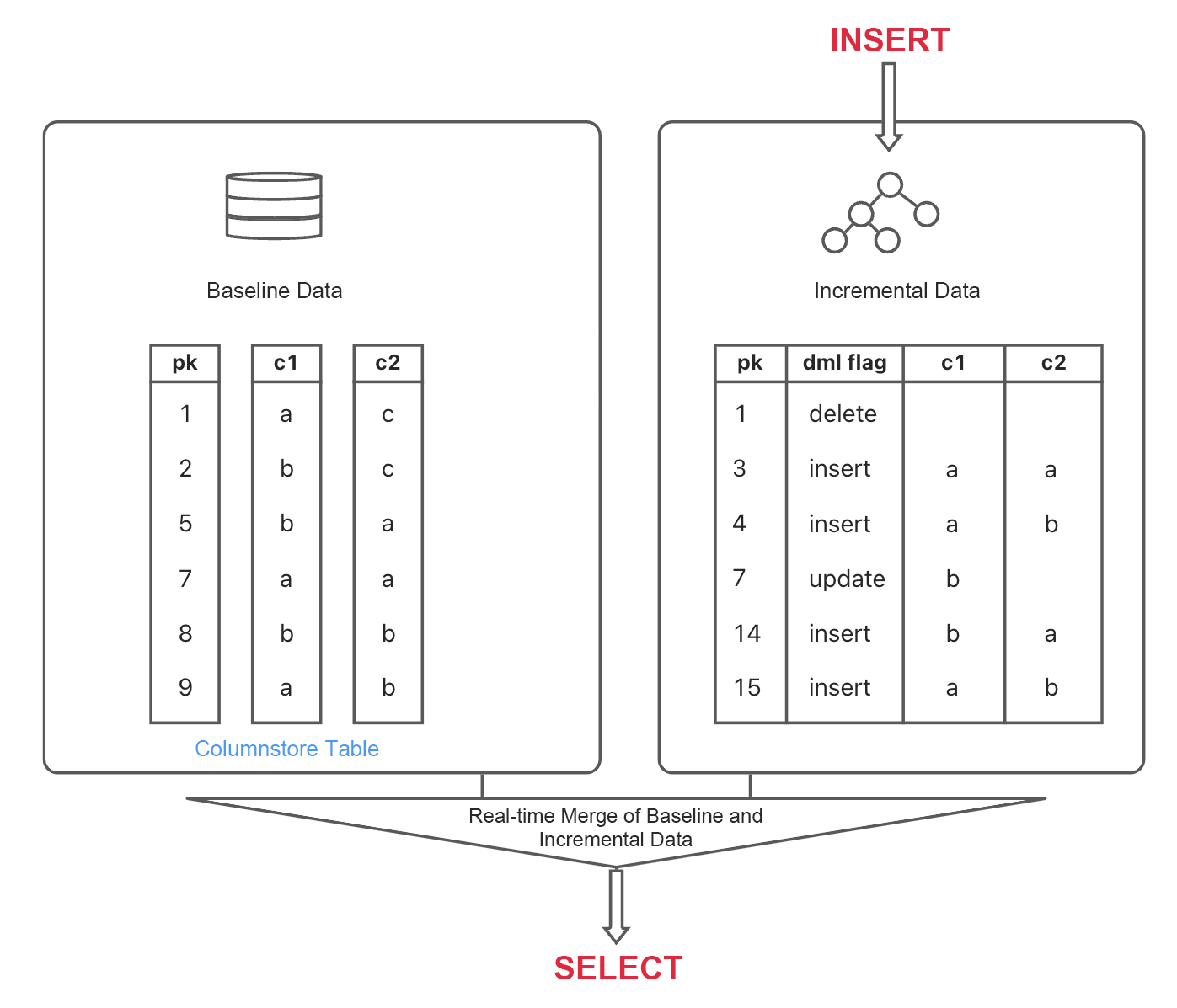
The storage engine of OceanBase Database, built on the LSM-tree structure, divides data into static baseline data and dynamic incremental data.
Data manipulated by DML operations, such as INSERT, UPDATE, and DELETE, is first written into MemTables. After reaching the specified size, the MemTables are compacted into SSTables on the disk. Data in the MemTables and SSTables is referred to as incremental data. When the incremental data reaches a certain size, it is compacted with the baseline data of the old version to form the baseline data of a new version, namely, the baseline SSTables of a new version. In addition, the system performs a daily compaction during idle hours every night.
When receiving a user query, OceanBase Database queries both the incremental data and the baseline data, merges the query results, and then returns the results to the SQL layer. OceanBase Database implements both block cache and row cache in the memory to avoid random read of the baseline data.
Overall Columnar Storage Architecture
Columnar storage greatly boosts the performance of AP queries and is key to the excellence of OceanBase Database in hybrid transactional/analytical processing (HTAP). Data used for AP is typically static and rarely updated in place. The baseline data in the LSM-tree architecture of OceanBase Database is also static, making it ideal for implementing columnar storage. Incremental data is dynamic. Even in columnstore tables, the incremental data and synchronized logs at the storage layer remain rowstore, which avoids impacts on TP, log synchronization, and backup and restore. This enables OceanBase Database to balance the performance of both TP and AP queries.
When creating tables in OceanBase Database V4.3, you can select among the rowstore, columnstore, and hybrid rowstore-columnstore formats. Whatever format you choose, the incremental data in the tables remains rowstore. Therefore, the DML operations, transactions, and upstream-downstream data synchronization of columnstore tables are not affected.
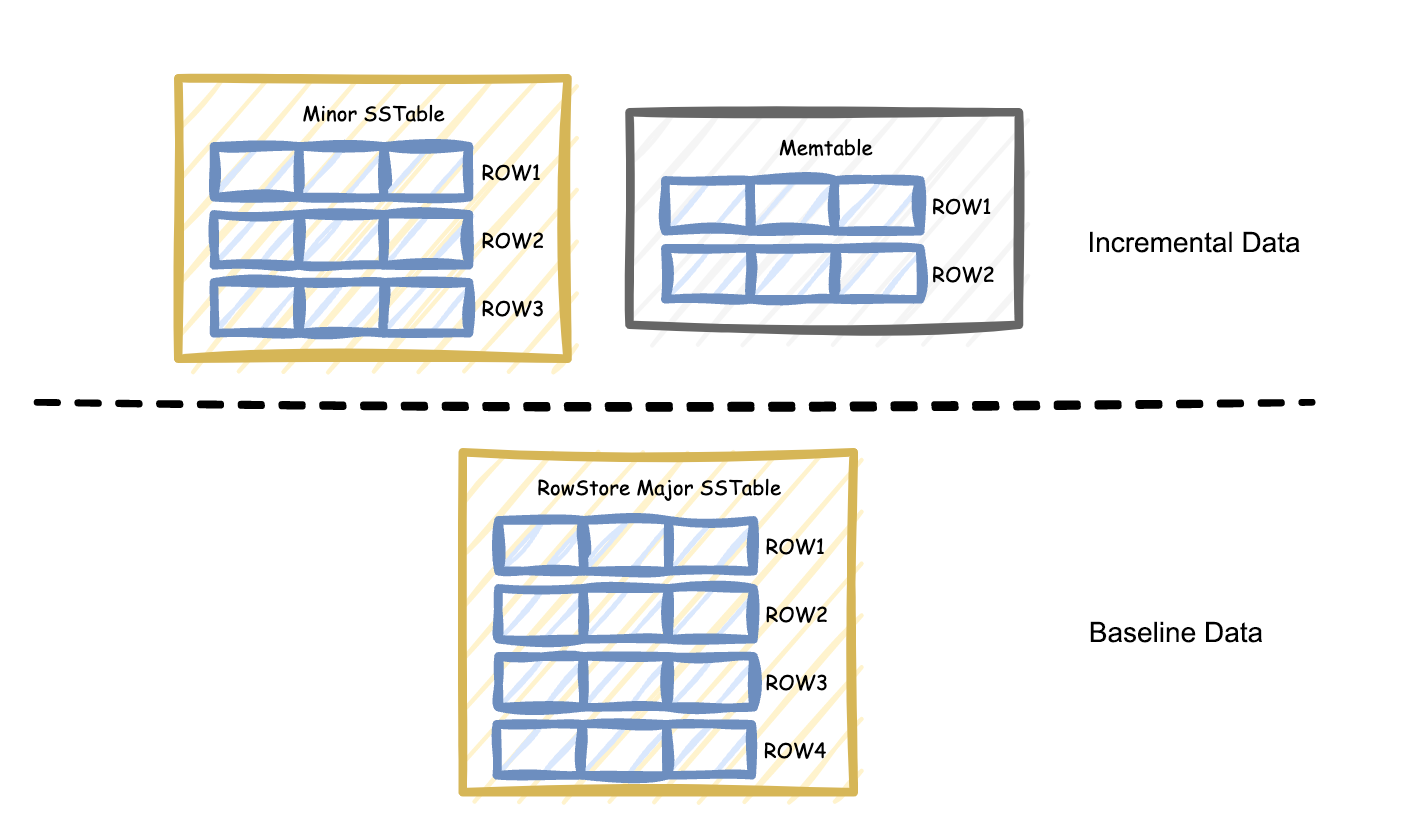
The key difference between columnstore and rowstore tables at the storage layer is the format of the baseline data. Based on the storage format that you specify when creating a table, the baseline data is stored by row, column, or both row and column (with redundancy).
In rowstore mode, the baseline data is stored by row, as shown in the following figure.
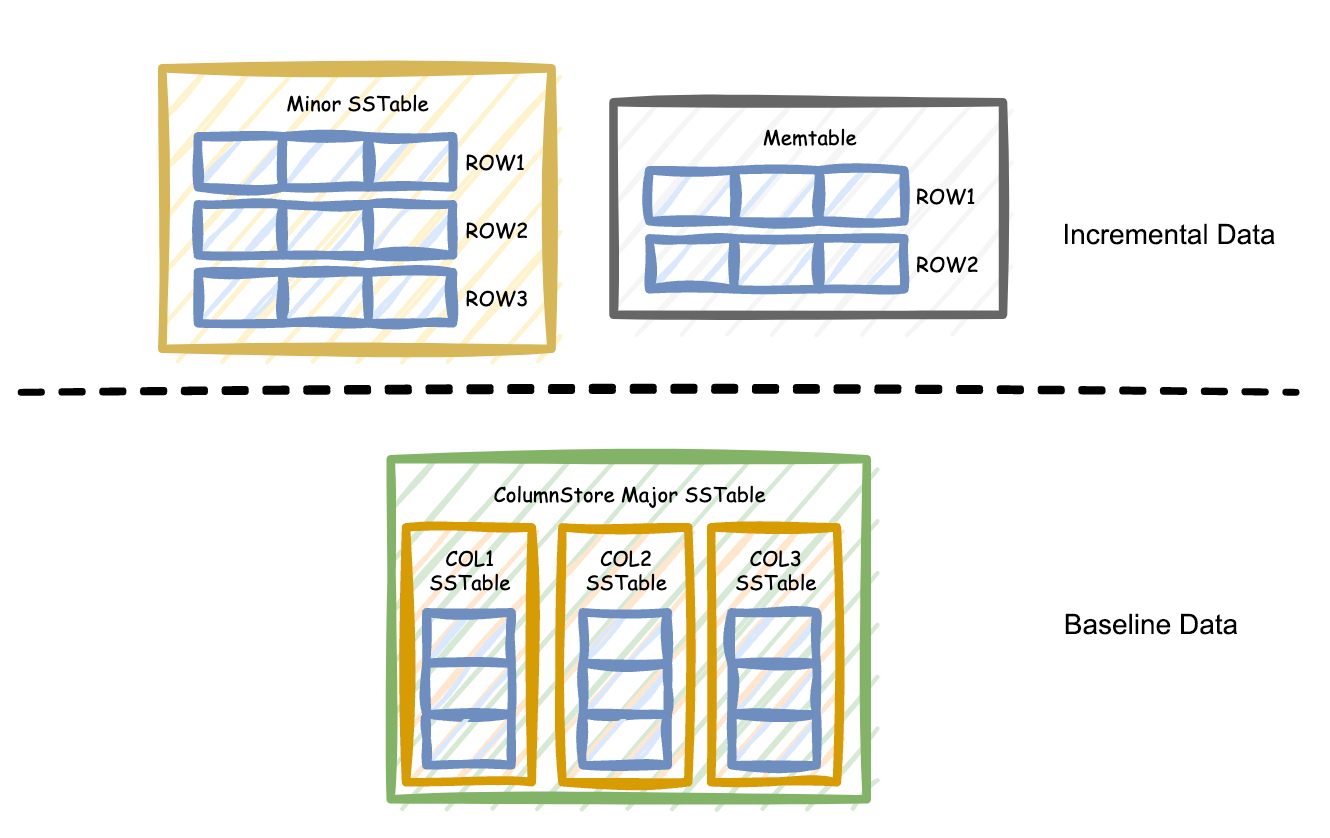
In columnstore mode, each column of the baseline data is stored as an independent baseline SSTable, as shown in the following figure.
In hybrid rowstore-columnstore mode, the baseline data is stored as both columnstore SSTables and rowstore SSTables, as shown in the following figure.
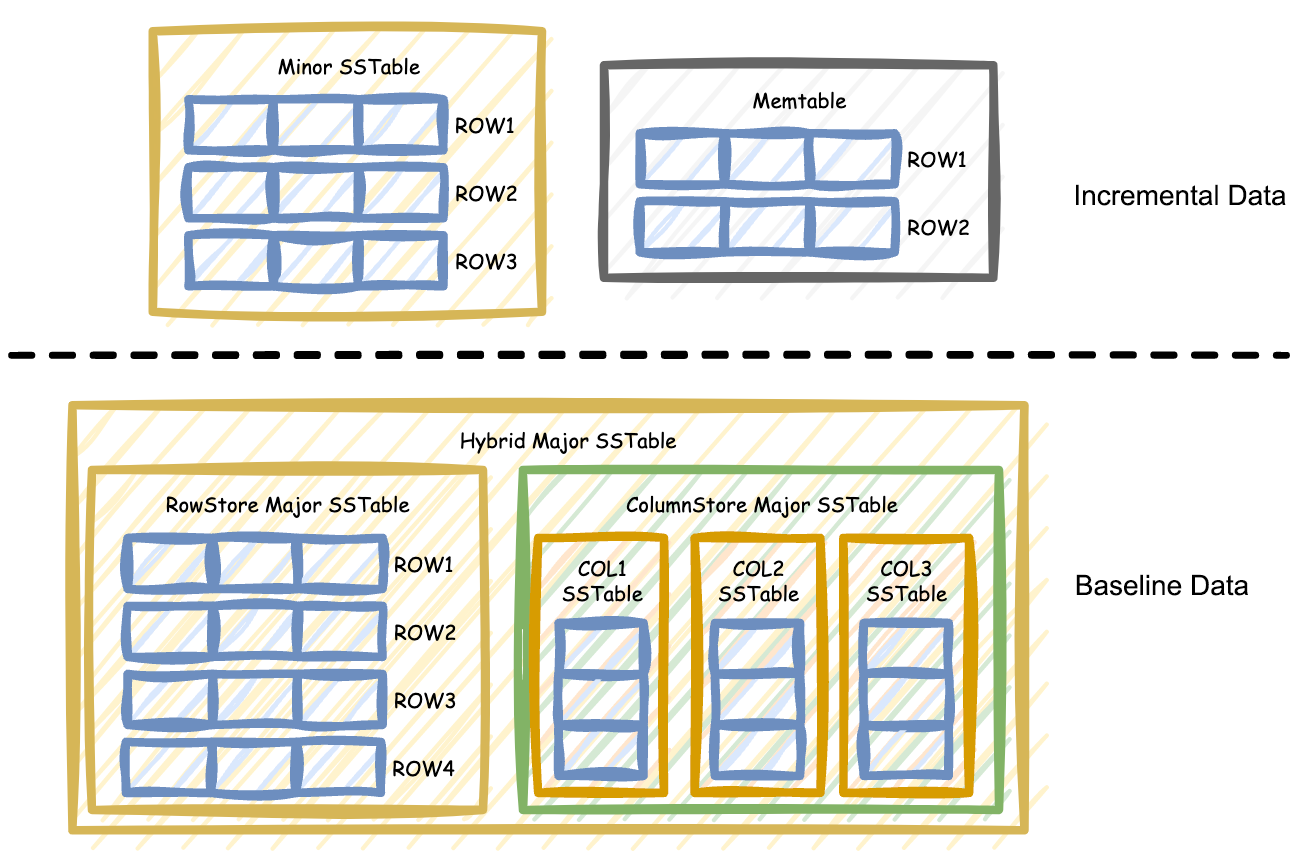
In this mode, the optimizer automatically chooses whether to scan columnstore or rowstore SSTables based on access costs.
Take creating a hybrid rowstore-columnstore table named t_column_row as an example. In the CREATE TABLE statement, with column group (all columns, each column) specifies the hybrid rowstore-columnstore mode for the table, where each column represents columnstore and all columns represents rowstore.
create table tt_column_row(
c1 int primary key, c2 int , c3 int)
with column group (all columns, each column);
If we query all the data in a column without specifying any filter conditions, the following execution plan will be generated. The COLUMN TABLE FULL SCAN operator in the execution plan indicates that the optimizer has chosen to scan the columnstore baseline data based on the cost model. Compared to scanning rowstore data, scanning columnstore data reduces the additional I/O overhead at the storage layer for the c2 and c3 columns.
explain select c1 from t_column_row;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| ============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|t_column_row|1 |3 | |
| ============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t_column_row.c1]), filter(nil), rowset=16 |
| access([t_column_row.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t_column_row.c1]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------+
If we query all the data in a table without specifying any filter conditions, the following execution plan will be generated. The TABLE FULL SCAN operator in the execution plan indicates that the optimizer has chosen to scan the rowstore baseline data. When both incremental data and baseline data are rowstore, merging them is faster. In this case, the optimizer produces an execution plan that scans rowstore data.
explain select * from t_column_row;
+-----------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------+
| ======================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------- |
| |0 |TABLE FULL SCAN|t_column_row|1 |3 | |
| ======================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t_column_row.c1], [t_column_row.c2], [t_column_row.c3]), filter(nil), rowset=16 |
| access([t_column_row.c1], [t_column_row.c2], [t_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t_column_row.c1]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------------------------------------+
Basic Performance Testing on Columnar Storage
We compared the compression ratios between columnar storage and row-based storage and tested the query performance of columnar storage based on the TPC-H 100 GB test set. The OceanBase Database version we used is Community Edition V4.3.0.1.
Compression Ratio Test
We first tested the compression ratio of columnstore tables in OceanBase Database V4.3.0 and compared it with that of rowstore tables.
We imported test set data respectively into a set of pure rowstore tables and a set of pure columnstore tables, and chose lineitem, the largest table, to calculate the storage overhead. The imported lineitem.tbl data is about 76 GB in size, occupying a storage space of 22.5 GB as a rowstore table and a storage space of 15 GB as a columnstore table.
-- Definition of the columnstore table lineitem
CREATE TABLE lineitem (
l_orderkey BIGINT NOT NULL,
l_partkey BIGINT NOT NULL,
l_suppkey INTEGER NOT NULL,
l_linenumber INTEGER NOT NULL,
l_quantity DECIMAL(15,2) NOT NULL,
l_extendedprice DECIMAL(15,2) NOT NULL,
l_discount DECIMAL(15,2) NOT NULL,
l_tax DECIMAL(15,2) NOT NULL,
l_returnflag char(1) DEFAULT NULL,
l_linestatus char(1) DEFAULT NULL,
l_shipdate date NOT NULL,
l_commitdate date DEFAULT NULL,
l_receiptdate date DEFAULT NULL,
l_shipinstruct char(25) DEFAULT NULL,
l_shipmode char(10) DEFAULT NULL,
l_comment varchar(44) DEFAULT NULL,
PRIMARY KEY(l_orderkey, l_linenumber))
row_format = condensed
partition by key (l_orderkey) partitions 4
with column group(each column);
For the lineitem table, the storage space occupied in columnstore mode is about two-thirds of that in rowstore mode. The reason is simple. Compared to rowstore tables, columnstore tables store data of the same type in each column, allowing for more efficient compression.
Why is the compression ratio of columnstore tables not as high as expected compared to rowstore tables? This is because OceanBase Database already excels in compressing rowstore tables. However, even though we have optimized compression for rowstore tables, compressing columnstore tables is slightly more effective than compressing rowstore tables. The larger the number of columns in a columnstore table, the more noticeable the compression effect for the table.
Query Performance Test
We conducted all subsequent tests on three machines, each with 6 CPU cores and 35 GB of memory, to compare the query performance between rowstore and columnstore tables.
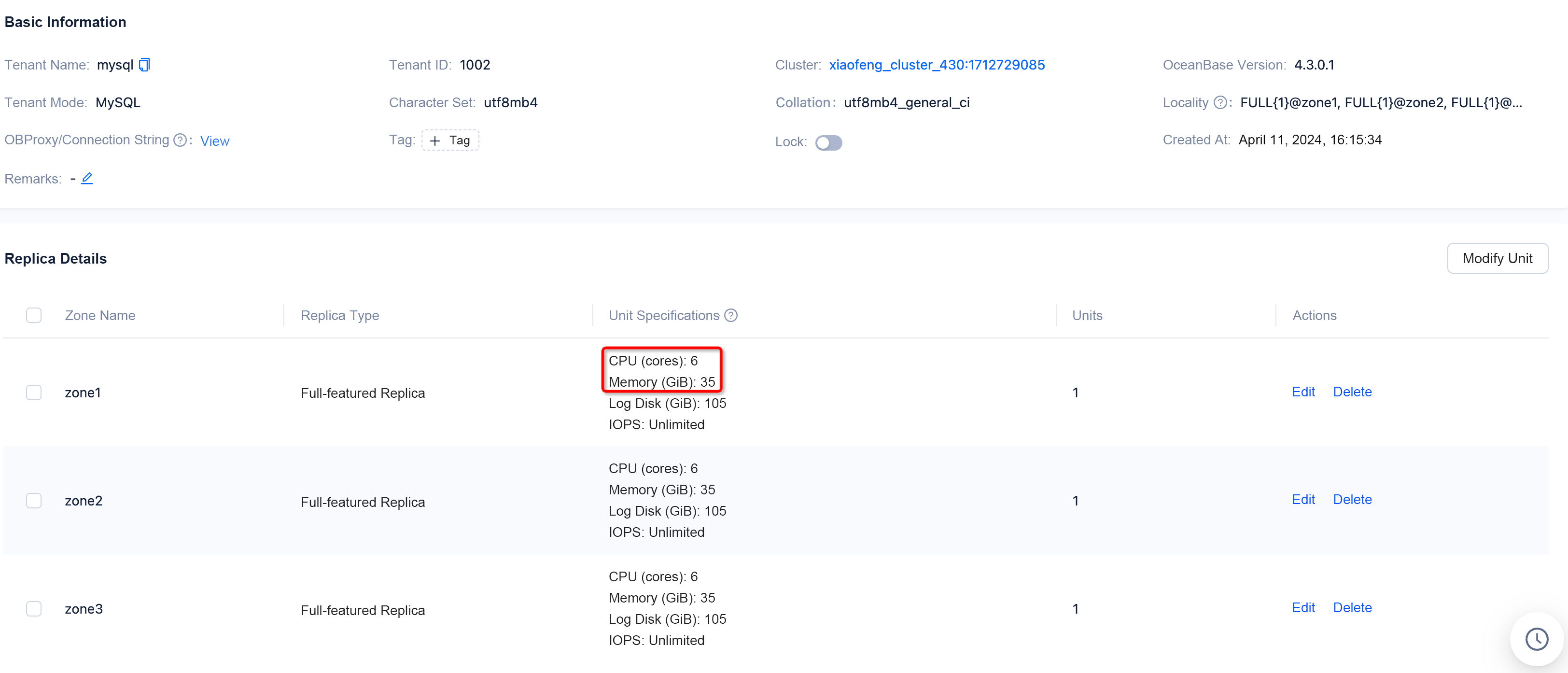
We created one rowstore table named lineitem_row and one columnstore table named lineitem_column and imported the TPC-H 100 GB test set to both tables.
Point queries with a primary key
We tested the performance of the point queries with a primary key on the columnstore and rowstore tables by executing the following SQL statements:
-- Columnstore table
select * from lineitem_column where l_orderkey = 7 and l_linenumber = 1;
1 row in set (0.035 sec)
select * from lineitem_column where l_orderkey = 7;
7 rows in set (0.036 sec)
-- Rowstore table
select * from lineitem_row where l_orderkey = 7 and l_linenumber = 1;
1 row in set (0.044 sec)
select * from lineitem_row where l_orderkey = 7;
7 rows in set (0.044 sec)
The execution duration of the point queries with a primary key on the columnstore table and that on the rowstore table were both about 0.04 seconds, demonstrating similar performance. For brevity, only the execution duration of the SQL statements was displayed.
Full table scans without any index
We respectively executed the following SQL statements without specifying a primary key or index on the columnstore and rowstore tables:
-- Columnstore table
select * from lineitem_column where l_extendedprice = 13059.24;
102 rows in set (0.467 sec)
-- Rowstore table
select * from lineitem_row where l_extendedprice = 13059.24;
102 rows in set (2.306 sec)
Each statement returned 102 rows. The execution duration for the SQL statement on the rowstore table was about 2.31 seconds, and that on the columnstore table was about 0.47 seconds. For lineitem, a wide table with a dozen columns, the performance of the columnstore table was five times that of the rowstore table.
If you do not use a primary key or index as a filter condition, scanning a columnstore table is more time-consuming than scanning a rowstore table because the results of each column must be combined for the columnstore table. However, a columnstore table incurs much less I/O overhead than a rowstore table because the rowstore table requires a full scan.
If you use a single column as the filter condition without specifying a primary key or index, the more columns a columnstore table has, the better the query performance of the columnstore table than that of a rowstore table. In this example, to increase the performance of the rowstore table by reducing the I/O overhead, you must create an index on the l_extendedprice column. In certain scenarios, columnstore tables reduce the overhead of creating and maintaining indexes compared to rowstore tables.
Without specifying a primary key or index, we made the filter condition more complex by including the calculation of multiple columns in it.
-- Columnstore table
select * from lineitem_column where l_partkey + l_suppkey = 20999999;
7 rows in set (5.091 sec)
-- Rowstore table
select * from lineitem_row where l_partkey + l_suppkey = 20999999;
7 rows in set (6.254 sec)
The columnstore table still outperformed the rowstore table, but only slightly.
We continued to include the calculation of more columns in the filter condition.
-- Columnstore table
select * from lineitem_column where l_partkey + l_suppkey +
l_extendedprice + l_discount + l_tax = 19173494.34;
1 row in set (15.675 sec)
-- Rowstore table
select * from lineitem_row where l_partkey + l_suppkey +
l_extendedprice + l_discount + l_tax = 19173494.34;
1 row in set (15.837 sec)
We can observe a pattern: As the number of columns involved in the filter condition increases, the performance of a rowstore table gradually approaches that of a columnstore table.
In simple terms, in a columnstore table, the corresponding rows from different columns must be combined based on the primary key value before any calculations between columns can be performed. When the additional overhead incurred by the combination and calculation operations approaches the additional column I/O overhead of a rowstore table, the difference in performance between the columnstore and rowstore tables diminishes.
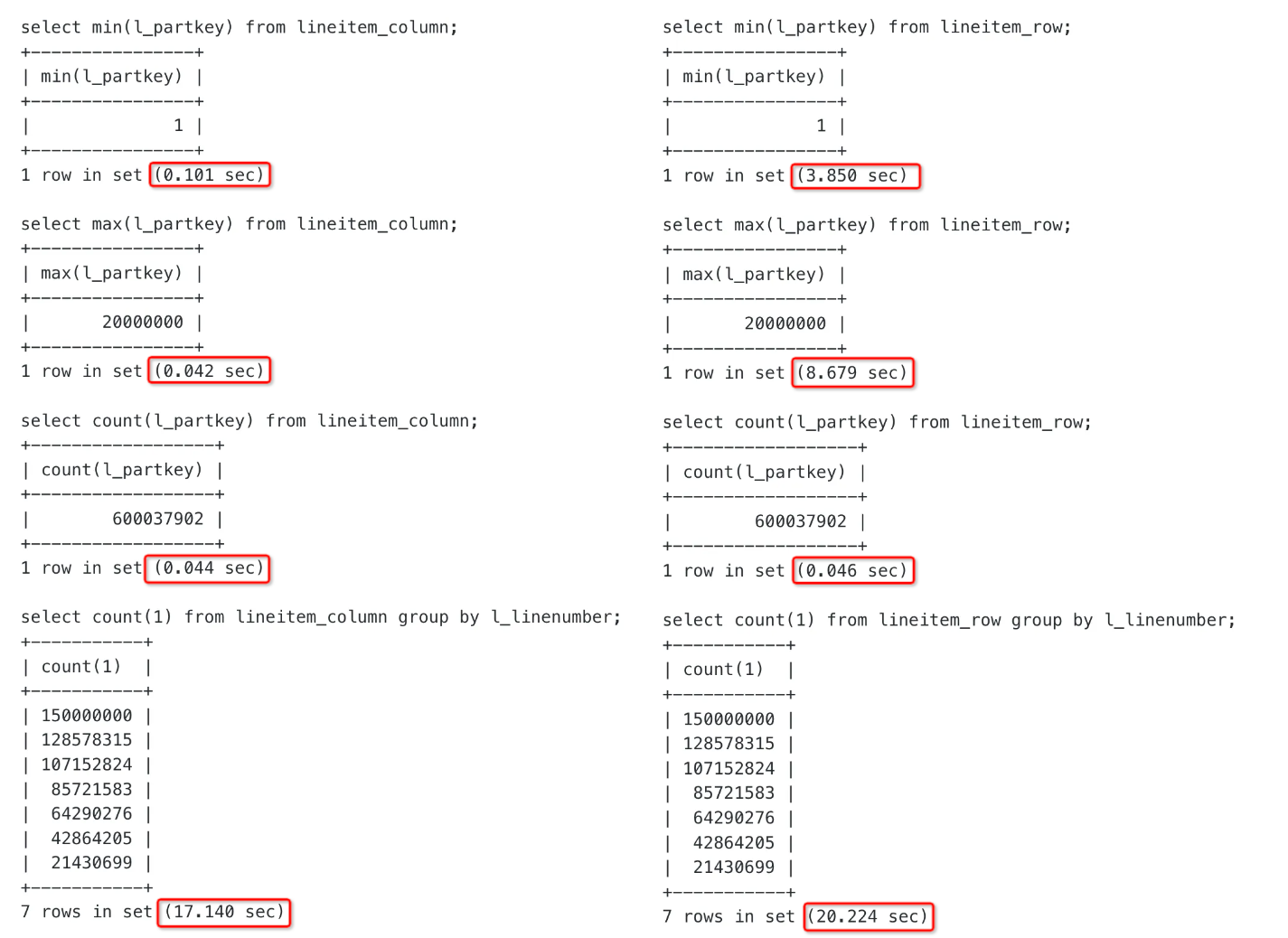
Aggregations
In terms of simple aggregations, the columnstore table outperformed the rowstore table. As shown in the following figure, the columnstore table lineitem_column is on the left and the rowstore table lineitem_row is on the right.
In terms of complex aggregations such as max(l_partkey + l_suppkey), the performance of the columnstore and rowstore tables is as follows:
-- Columnstore table
select max(l_partkey + l_suppkey) from lineitem_column;
+----------------------------+
| max(l_partkey + l_suppkey) |
+----------------------------+
| 20999999 |
+----------------------------+
1 row in set (19.302 sec)
-- Rowstore table
select max(l_partkey + l_suppkey) from lineitem_row;
+----------------------------+
| max(l_partkey + l_suppkey) |
+----------------------------+
| 20999999 |
+----------------------------+
1 row in set (4.833 sec)
In tests involving aggregations with expressions, the performance of the columnstore stable was inferior to that of the rowstore table. One reason, as mentioned earlier, is that in a columnstore table, the rows corresponding to the l_partkey and l_suppkey columns must be combined before any addition operation can be performed. The combination and calculation operations between columns incur additional overhead for the columnstore table. Another reason is that V4.3.0.1 focuses on optimizing vectorized execution for columnstore expression filtering, while optimizations on columnstore expression aggregations are planned for future versions.
We can conclude that multi-column expression calculations in aggregate functions are not a strength of the current columnar storage version. However, as a wider columnstore table saves more I/O overhead compared to a rowstore table than the lineitem table in the same scenario, the test results may differ if we use a table with hundreds or thousands of columns.
Impact of updating columnstore data at different percentages on query performance
A columnstore table uses different formats for baseline and incremental data. In scenarios involving substantial incremental data, querying a columnstore table requires format conversion and integration for column and row data during the merge of incremental and baseline data, and thus inevitably incurs more overhead than querying a rowstore table.
We tested updates to continuous columnstore data at different percentages. As the l_orderkey column was evenly distributed, we controlled the percentages by using different l_orderkey ranges as follows:
-- l_orderkey is evenly distributed from 1 to 600,000,000.
-- Update 1% of the data by using the condition "where l_orderkey <= 6000000."
-- As l_orderkey is the primary key column, the data to update is continuous.
update lineitem_column set
l_partkey = l_partkey + 1,
l_suppkey = l_suppkey - 1,
l_quantity = l_quantity + 1,
l_extendedprice = l_extendedprice + 1,
l_discount = l_discount + 0.01,
l_tax = l_tax + 0.01,
l_returnflag = lower(l_returnflag),
l_linestatus = lower(l_linestatus),
l_shipdate = date_add(l_shipdate, interval 1 day),
l_commitdate = date_add(l_commitdate, interval 1 day),
l_receiptdate = date_add(l_receiptdate, interval 1 day),
l_shipinstruct = lower(l_shipinstruct),
l_shipmode = lower(l_shipmode),
l_comment = upper(l_comment)
where l_orderkey <= 6000000;
Query OK, 6001215 rows affected (4 min 2.397 sec)
Rows matched: 6001215 Changed: 6001215 Warnings: 0
-- Execute queries with a primary key multiple times.
select * from lineitem_column where l_orderkey = 7;
select * from lineitem_column where l_orderkey = 600000000;
(0.036 sec)
-- Execute queries without a primary key multiple times.
select * from lineitem_column where l_suppkey = 825656;
(31.722 sec)
The following table displays the execution duration of queries with and without a primary key after we updated different percentages of data of the columnstore table.
| Update percentage (%) | Execution duration for the query with a primary key (s) | Execution duration for the query without a primary key (s) |
|---|---|---|
| 0 | 0.03 | 0.5 |
| 1 | 0.03 | 32 |
| 2 | 0.03 | 54 |
| 3 | 0.03 | 80 |
| 5 | 0.03 | 126 |
| 10 | 0.03 | 245 |
| 20 | 0.03 | 495 |
| 30 | 0.03 | 733 |
| 40 | 0.03 | 1075 |
| 50 | 0.04 | 1453 |
| 60 | 0.04 | 1636 |
| 70 | 0.04 | 1916 |
| 80 | 0.04 | 2195 |
| 90 | 0.04 | 2468 |
| 100 | 0.04 | 2793 |
Based on the preceding table, we created the following line chart. The x-axis shows the percentages of incremental data, and the y-axis represents the execution duration of queries without a primary key or index. In the columnar storage scenario, updating different percentages of incremental data without compacting data during the tests resulted in a query performance curve that was almost straight.
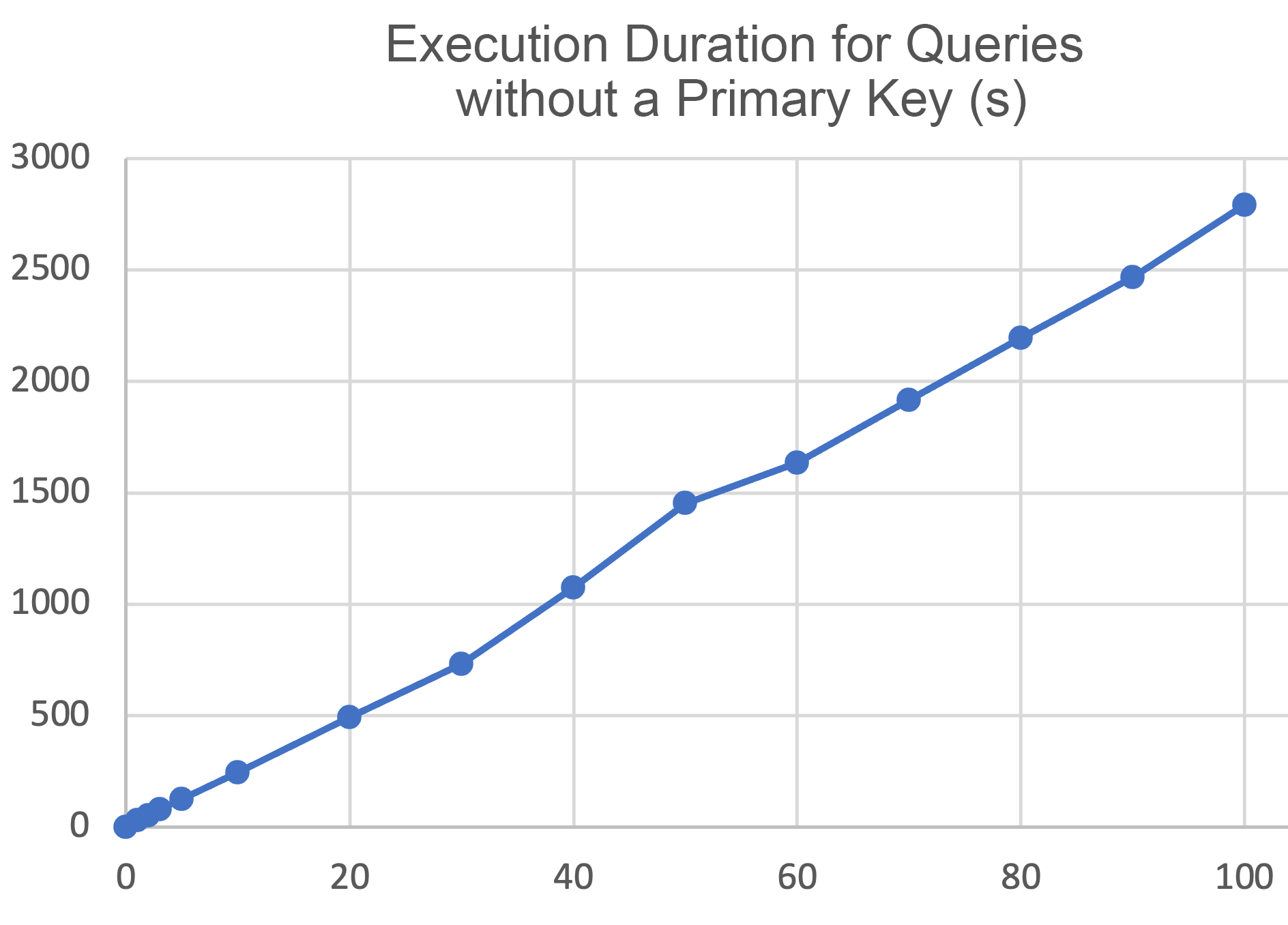
It is important to note that all the preceding tests updated continuous data.
If you randomly update a certain percentage of discontinuous data, the performance will deteriorate compared to updating continuous data. In OceanBase Database, the smallest I/O unit for reading data files is a variable-length data block of 16 KB, which we refer to as a microblock. If the data is discontinuous, even a small update to the table can cause changes to a large number of microblocks. Therefore, modifying 10% of the table data may impact 100% of the table microblocks. In this case, the query performance does not differ much from the performance of modifying 100% of the table data.
From the preceding tests, we can draw the following conclusion: If you perform a large number of update operations on a columnstore table without performing a major compaction in a timely manner, the query performance will be compromised. Therefore, we recommend that you initiate a major compaction after batch data import to achieve optimal query performance.
Scenarios of Columnar Storage
Based on the preceding test results, we can conclude that columnstore tables in OceanBase Database are suited to the following two types of scenarios:
-
Wide table scenarios
-
When a query scans only a single column or a few columns of a wide table, a columnstore table can significantly reduce disk I/O overhead. For a wide rowstore table, an index needs to be created on specific columns so that the query can scan the index rather than the primary table with more columns. Compared to a rowstore table, a columnstore table eliminates the overhead of creating, storing, and maintaining indexes for specific columns.
-
Read-intensive AP data warehouse scenarios
-
In data warehouse scenarios, complex analytical queries are frequently executed but often involve only specific columns. Storing data by column, columnstore tables can efficiently support such AP queries and reduce unnecessary I/O overhead.
-
To support frequent small transaction writes in columnstore tables and avoid significant impact of data updates on the performance of columnstore tables, OceanBase Database stores the incremental data of columnstore tables in the rowstore format. In other words, a columnstore table uses different formats for baseline and incremental data. In scenarios involving substantial incremental data, querying a columnstore table requires format conversion and integration for column and row data during the merge of incremental and baseline data, and thus incurs more overhead than querying a rowstore table. The time required for scanning column data increases proportionally to the amount of incremental data, making columnstore tables more suitable for read-intensive scenarios.
Basic Syntax of Columnar Storage
This section introduces the columnar storage syntax, which is also well-documented on the official website of OceanBase Database.
Set the Relevant Tenant-level Parameter
For OLAP scenarios, we recommend that you set the parameter to row as follows so that rowstore tables are created by default:
-- Modify the parameter, which takes effect for the current tenant.
alter system set default_table_store_format = "column"; // Columnstore tables are created by default.
alter system set default_table_store_format = "row"; // Rowstore tables are created by default.
alter system set default_table_store_format = "compound"; // Hybrid rowstore-columnstore tables are created by default.
-- View the value of the parameter. The default value is row.
show parameters like 'default_table_store_format';
Create a Columnstore Table
The new syntax for creating a columnstore table is with column group. If you specify with column group (each column) at the end of a CREATE TABLE statement, a columnstore table will be created.
-- Create a columnstore table.
create table t1 (c1 int, c2 int) with column group (each column);
-- Create a partitioned columnstore table.
create table t2(
pk int,
c1 int,
c2 int,
primary key (pk)
) partition by hash(pk) partitions 4
with column group (each column);
If you want to balance between AP business and TP business and can accept a specific degree of data redundancy, you can add all columns in the with column group syntax to enable rowstore redundancy.
-- Create a hybrid rowstore-columnstore table.
create table t2 (c1 int, c2 int) with column group(all columns, each column);
The options in the with column group syntax are described as follows:
- all columns: groups all columns together as a single wide column to store data by row.
- each column: stores data by column.
- all columns, each column: stores data both by row and by column, with each replica storing two sets of baseline data.
Create a Columnstore Index
You can also use the with column group syntax to specify the attribute of an index the same way you create a columnstore table. Note that creating an index for a columnstore table differs from creating a columnstore index. For a columnstore index, the index table is in the columnstore format. Compared to rowstore indexes, columnstore indexes reduce the I/O overhead at the storage layer.
-- Create a columnstore index on the c1 and c2 columns of the t1 table.
create index idx1 on t1(c1, c2) with column group(each column);
-- Create a hybrid rowstore-columnstore index on the c1 column of the t1 table.
create index idx2 on t1(c1) with column group(all columns, each column);
-- Create a columnstore index on the c2 column of the t1 table and store the data of the non-indexed c1 column in the index.
alter table t1 add index idx3 (c2) storing(c1) with column group(each column);
In the preceding example, the purpose of specifying storing(c1) to store an additional column in the index is to optimize the performance of specific queries. This avoids retrieving c1 values from the primary table and reduces the cost of indexing and sorting the c1 column. As the c1 column is redundantly stored in the idx3 index but not indexed, only the c2 column needs to be sorted. If the c1 column is indexed, both the c1 and c2 columns need to be sorted.
explain select c1 from t1 order by c2;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|t1(idx3)|1 |5 | |
| ========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=16 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c2], [t1.__pk_increment]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
In the preceding SQL execution plan, no SORT operator is assigned because the idx3 index eliminates the need to sort the c2 column. As the non-indexed c1 column is redundantly stored in the index, table access by index primary key (is_index_back=false) is not required.
Conversion between Rowstore and Columnstore Tables
The syntax for conversions between storage formats is complex.
Convert a table from the rowstore format to the columnstore format:
create table t1(c1 int, c2 int);
-- This syntax is somewhat confusing because the add keyword gives the impression that it converts a table from the rowstore format to the hybrid rowstore-columnstore format.
alter table t1 add column group(each column);
Convert a table from the columnstore format to the rowstore format:
alter table t1 drop column group(each column);
Convert a table from the rowstore format to the hybrid rowstore-columnstore format:
create table t1(c1 int, c2 int);
alter table t1 add column group(all columns, each column);
Convert a table from the hybrid rowstore-columnstore format to the rowstore format:
alter table t1 drop column group(all columns, each column);
Note: After
drop column group(all columns, each column);is executed, all columns will be put in the default group namedDEFAULT COLUMN GROUPfor storing data. The storage format ofDEFAULT COLUMN GROUPis determined by the value of the tenant-level parameterdefault_table_store_format, which defaults torow. If you do not modify the default value, the t1 table is converted into a rowstore table after the statement is executed.
Convert a table from the columnstore format to the hybrid rowstore-columnstore format:
create table t1(c1 int, c2 int) with column group(each column);
alter table t1 add column group(all columns);
Convert a table from the hybrid rowstore-columnstore format to the columnstore format:
alter table t1 drop column group(all columns);
Hints Related to Columnar Storage
For a hybrid rowstore-columnstore table, the optimizer determines whether to perform a rowstore or columnstore scan based on costs. You can also forcibly perform a columnstore scan by specifying the USE_COLUMN_TABLE hint or forcibly perform a rowstore scan by specifying the NO_USE_COLUMN_TABLE hint.
explain select /*+ USE_COLUMN_TABLE(tt_column_row) */ * from tt_column_row;
+--------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------+
| =============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------- |
| |0 |COLUMN TABLE FULL SCAN|tt_column_row|1 |7 | |
| =============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), filter(nil), rowset=16 |
| access([tt_column_row.c1], [tt_column_row.c2], [tt_column_row.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------------+
explain select /*+ NO_USE_COLUMN_TABLE(tt_column_row) */ c2 from tt_column_row;
+------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------+
| ======================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------- |
| |0 |TABLE FULL SCAN|tt_column_row|1 |3 | |
| ======================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([tt_column_row.c2]), filter(nil), rowset=16 |
| access([tt_column_row.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tt_column_row.c1]), range(MIN ; MAX)always true |
+------------------------------------------------------------------+
To check whether a columnstore scan is performed in an execution plan, view the output of the explain command. If TABLE FULL SCAN is displayed, a rowstore scan has been performed. If COLUMN TABLE FULL SCAN is displayed, a columnstore scan has been performed.
Suggestions on Using Columnar Storage
After testing the columnar storage feature of OceanBase Database and learning about its basic syntax, we have several suggestions for using the feature.
- For a newly created cluster of OceanBase Database V4.3.0 or later used in OLAP data warehouse scenarios, we recommend that you change the tenant-level parameter
default\_table\_store\_formatfrom its default valuerowtocolumn. - For a cluster upgraded from an earlier version to OceanBase Database V4.3.0 or later, you can use the new columnar storage feature to optimize old rowstore tables in one of the following ways:
-
Create a columnstore index.
-
Advantage: As creating a columnstore index is an online DDL operation, you can create a columnstore index on some columns of a wide table without affecting business.
-
Disadvantage: Incremental data is written to both the original and index tables, which increases memory and disk usage.
-
Use the
ALTER TABLEstatement to change the storage format of the original table. -
Advantage: As incremental data is in the rowstore format, it is written only to the original table.
-
Disadvantage: Changing the storage format is an offline DDL operation, during which the table is locked and cannot be updated.
- Hybrid rowstore-columnstore tables are suited only to HTAP scenarios. The optimizer determines, based on estimated costs, whether to scan a hybrid rowstore-columnstore table by row or by column. In AP scenarios, we recommend that you use columnstore tables.
- If you perform a large number of update operations on a columnstore table without performing a major compaction in a timely manner, the query performance will be compromised. Therefore, we recommend that you initiate a major compaction after batch data import to achieve optimal query performance. The major compaction speed of columnstore tables is lower than that of rowstore tables. To initiate a major compaction, execute
alter system major freeze;in the current tenant. To check whether a major compaction is completed, executeselect STATUS from CDB_OB_MAJOR_COMPACTION where TENANT_ID = Tenant ID;in the sys tenant. If theSTATUSvalue becomesIDLE, the major compaction is completed. You can also complete a major compaction by using OceanBase Cloud Platform (OCP). - We recommend that you collect statistics once after a major compaction. You can collect statistics in the following way:
- Execute the following command to start 16 threads to concurrently collect all table statistics of a tenant:
CALL DBMS_STATS.GATHER_SCHEMA_STATS ('db', granularity=>'auto', degree=>16);
- Check the
GV$OB_OPT_STAT_GATHER_MONITORview to observe the collection progress.
6. You can use direct load to batch import data to a table. This allows you to achieve the optimal columnstore scan performance of the table without performing a major compaction. The obloader tool and the native load data command support full direct load.
7. For large tables, hot runs outperform cold runs in most cases.
8. In scenarios involving no wide tables, you can achieve comparable performance even if you do not use columnar storage. This is because the row-based storage versions of OceanBase Database adopt a hybrid row-column storage architecture at the microblock level.
9. Here are some practical suggestions to further increase the performance of columnstore tables in AP scenarios.
- If appropriate, use binary instead of utf8mb4 as the character set when creating a table. Here is a sample statement:
create table t1(c1 int, c2 int) CHARSET=binary with column group (each column);
-
If the character set must be utf8mb4 or if appropriate, use the utf8mb4_bin collation when creating a MySQL tenant by specifying, for example,
locality = 'F@z1', collate = utf8mb4_bin. Alternatively, specify utf8mb4_bin as the character set when creating a table by addingCHARSET = utf8mb4 collate=utf8mb4_binto theCREATE TABLEstatement. -
Recommended columnar storage configurations for PoC testing:
-- Use the utf8mb4_bin collation.
set global collation_connection = utf8mb4_bin;
set global collation_server = utf8mb4_bin;
set global ob_query_timeout=10000000000;
set global ob_trx_timeout=100000000000;
alter system set_tp tp_no = 2100, error_code = 4001, frequency = 1;
alter system set _trace_control_info=''
alter system set _rowsets_enabled=true;
alter system set _bloom_filter_enabled=1;
alter system set _px_message_compression=1;
set global _nlj_batching_enabled=true;
set global ob_sql_work_area_percentage=70;
set global max_allowed_packet=67108864;
set global parallel_servers_target=1000; -- We recommend that you set the value of this parameter to 10 times the number of CPU cores.
set global parallel_degree_policy = auto;
set global parallel_min_scan_time_threshold = 10;
set global parallel_degree_limit = 0;
alter system set _pushdown_storage_level = 4;
alter system set _enable_skip_index=true;
alter system set _enable_column_store=true;
alter system set compaction_low_thread_score = cpu_count;
alter system set compaction_mid_thread_score = cpu_count;
Vision for the Future
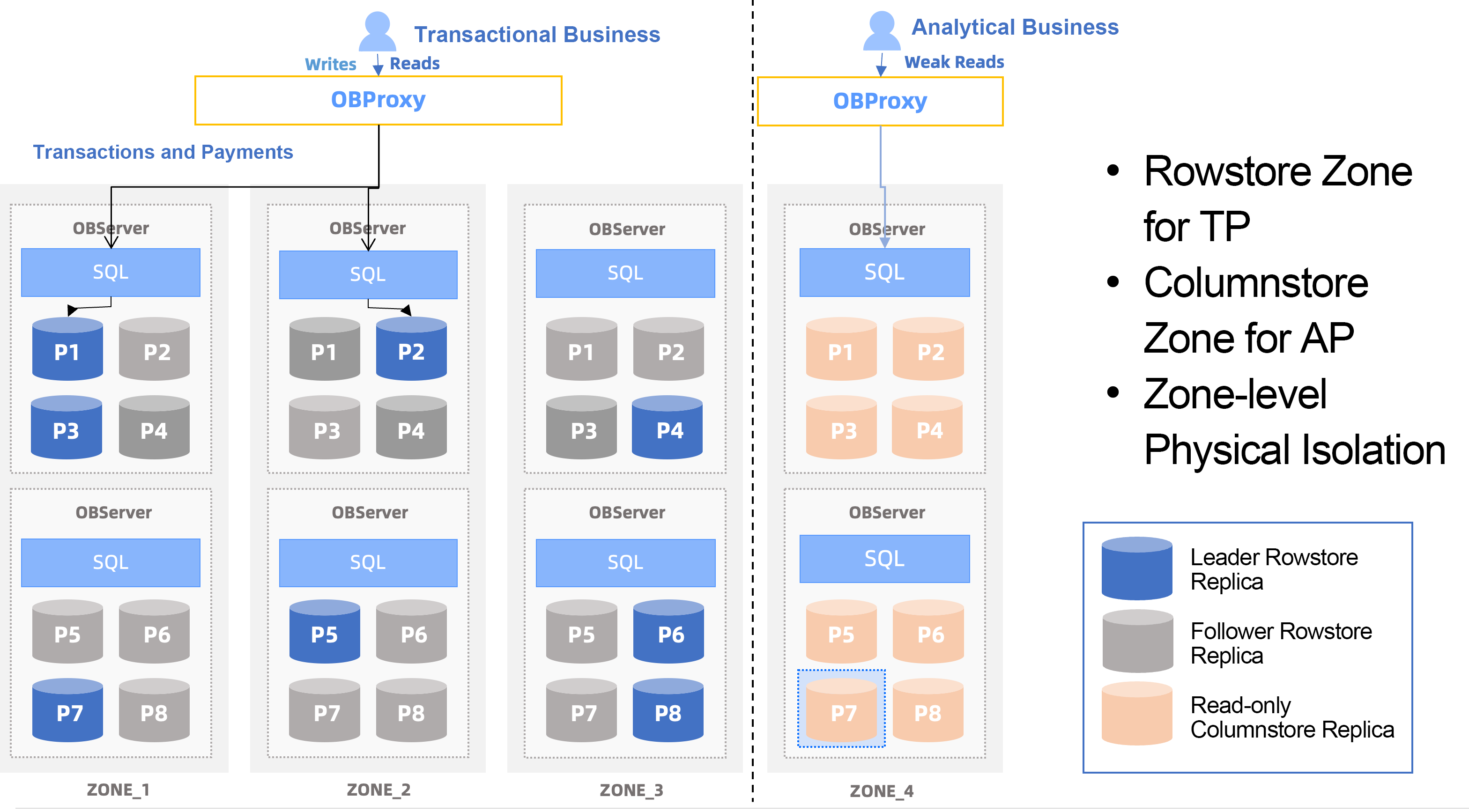
OceanBase Database V4.3.x will support columnstore replicas to reduce storage overhead from hybrid rowstore-columnstore tables in HTAP scenarios.
As shown in the following figure, read-only columnstore replicas can be deployed in a separate zone. This deployment mode ensures physical resource isolation between TP and AP workloads and enables independent major compactions between columnstore and rowstore tables, making it ideal for HTAP scenarios with highly concurrent reads and writes.
For most users, learning about the preceding content is all that is needed to effectively use the columnar storage feature of OceanBase Database.
I had planned to cover the complex technical principles behind the columnar storage feature. Given the fact that I worked on only one optimization called decimal int, I had to abandon this unrealistic idea.
Special thanks to my colleagues Xiaochu and Hanhui. Without their help, I would not have completed this first AP article on columnar storage.