Work with developers to create an all-in-one database

Good morning, OceanBase developers! I'm so glad to meet you again here in Shanghai for our second developers conference, after our first acquaintance in OceanBase DevCon 2023 in Wangjing, Beijing.

Let's first have a brief review of the architecture of OceanBase Database. The research and development of OceanBase Database started in 2010. It has been nearly 14 years. Throughout this period, we have made two major upgrades to the technical architecture and a key product upgrade.
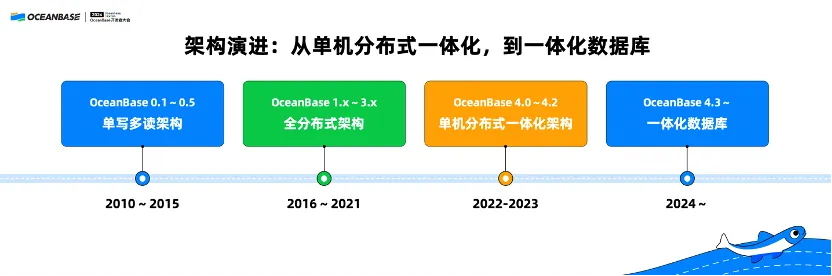
The first upgrade to the technical architecture took place in 2016, where the original OceanBase Database V0.5 in the single-write multi-read architecture was upgraded to OceanBase Database V1.0 in a fully distributed architecture. The second architecture upgrade was carried out in OceanBase Database V4.0 in 2022. This version introduced an integrated architecture that supports both standalone and distributed deployment modes. This way, OceanBase Database can be applied not only to large enterprises (SMEs), but also to small and medium-sized enterprises and even start-ups.
In the second half of 2023, we proposed the concept of all-in-one database based on the integrated architecture, enabling OceanBase Database to incorporate capabilities such as OLTP, OLAP, KV, OBKV, and even AI in the future, to cope with a wide variety of workloads.
I. The path to open source
OceanBase Database was officially available as an open source project on the Children's Day — June 1, 2021. Before OceanBase Database was launched open source, the open source community in China already had a prevailing native distributed database. Then, why another one?
Simply because we believed that users and developers would love it, for it has showed high stability, high performance, and high cost effectiveness in more than ten years' service in all core scenarios of Ant Group in Double 11 shopping festivals.
At that time, we were serious on turning OceanBase Database into open source, and real open source. Now I have a deeper understanding of "real open source". Is OceanBase Database really open-source? Statistics speak louder than our words.
OceanBase Database has been available as an open source project for two years. The last two years have seen rapid development. Up to now, the number of clusters deployed with OceanBase Database Community Edition has exceeded 10,000. We have seen phenomenal growth in OceanBase users and clusters after the release of OceanBase Database V4.0.
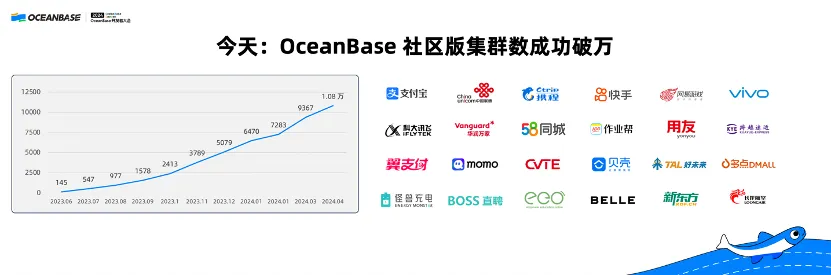
Today, mainstream Internet companies, including Ctrip, Kuaishou, Zhihu, Vivo, and NetEase, are using OceanBase Database Community Edition in various scenarios. In the open source community, OceanBase is recognized as the best open source distributed database with top technical feature performance.
OceanBase Database is widely recognized and has more than 1000 customers. According to the China Distributed Relational Database Vendors Report 2023 by IDC (Document number:# CHC50734323), OceanBase ranked in the industry leaders and was in a leading position in product capabilities. OceanBase also received an Honorable Mention in the 2023 Gartner Magic Quadrant for Global Cloud Database Management Systems, and has topped Modb China Database Rankings for 14 consecutive months.

i. OceanBase Database Community Edition in distributed OLTP scenarios
OceanBase Database was initially designed for mission-critical core business scenarios such as transaction processing and payment. Therefore, early open source users apply OceanBase Database to core business scenarios.
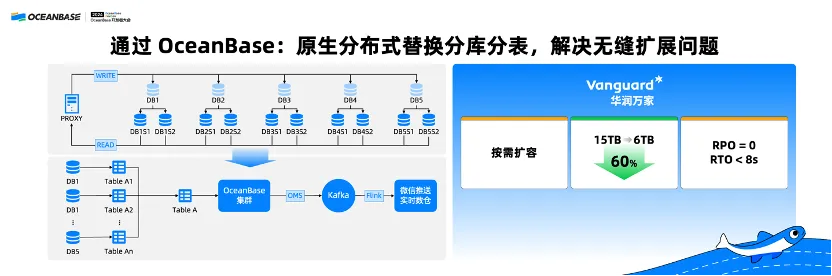
CR Vanguard originally used the sharding solution of MySQL Database, which does not support scaling. By deploying OceanBase Database, a native distributed database solution, in place of MySQL Database, Vanguard realizes on-demand scaling, reduces the required storage size by 60% from 15 TB to 6 TB, and achieves a recovery point objective (RPO) of zero.
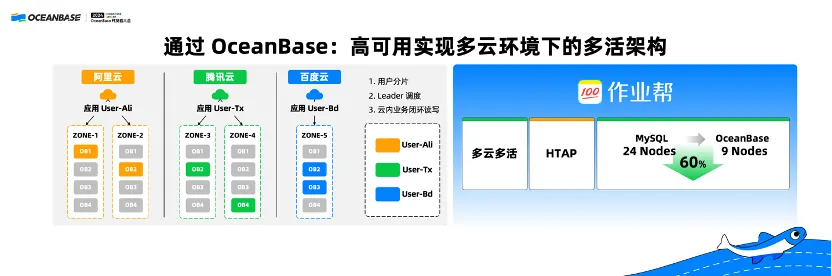
With its infrastructure, including the databases, built in Baidu Cloud, Alibaba Cloud, and Tencent Cloud, Zuoyebang is in dire need of a system that can tackle this multi-infrastructure environment. Against this backdrop, it replaces MySQL with OceanBase. Backed by the high availability and disaster tolerance capabilities of OceanBase Database, Zuoyebang now sets up a multi-active architecture in a multi-infrastructure environment, handling hybrid transaction/analytical processing (HTAP) loads with just one system. Moreover, with OceanBase Database, the number of servers required is reduced from 24 to 9, reducing hardware costs by 60%.
Dmall is a digital retail solution provider that serves many supermarkets in various sizes, such as Wumart. Dmall once used a large number of scattered MySQL servers, which do not support scaling and incur high O&M costs. The multitenancy capability of OceanBase Database enables database consolidation for Dmall, greatly reducing O&M costs. OceanBase Database also achieves a compression ratio of 6:1 while delivering higher performance even in standalone mode.
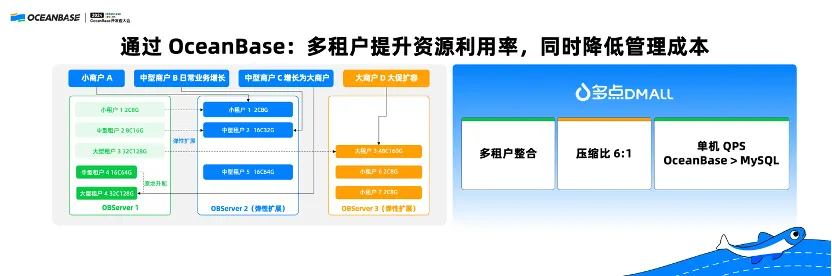
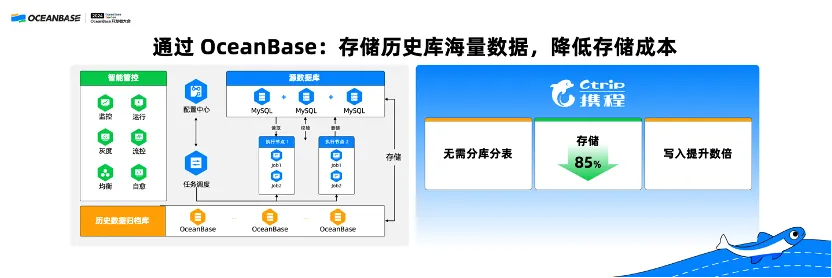
Ctrip is one of the earliest customers of OceanBase Database Community Edition. Ctrip had a history database that used the sharding solution of MySQL Database, which did not support dynamic online scaling, failing to cope with the drastic data volume increase of the history database. Therefore, they migrated their history database to OceanBase Database. The native distributed database solution of OceanBase avoids database and table sharding, reduces the required storage space by 85%, and improves write performance several times.
ii. OceanBase Database Community Edition in real-time AP and multi-model scenarios
Although OceanBase Database was initially designed to handle mission-critical core business scenarios, our developers also use OceanBase Database in real-time analytical processing (AP) and multi-model scenarios.
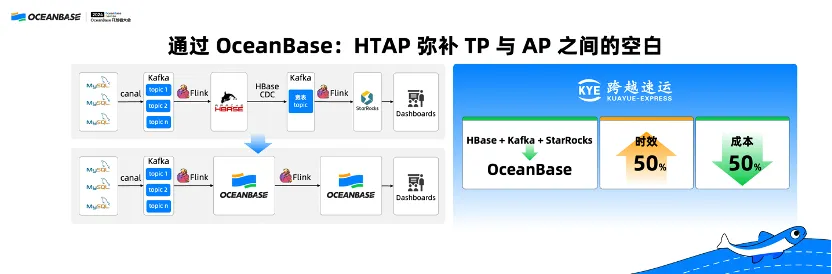
Kuayue Express once used the "HBase + Kafka + StarRocks" architecture for its analytics scenario. They developed a system called HBase CDC, which pulls data from HBase to Kafka and then synchronizes the data to StarRocks. This solution features high development costs and a complex link, which also results in a long data processing period. With OceanBase Database, Kuayue Express now needs only one system, reducing hardware costs by 50% while improving data processing efficiency by 50%.
Beike has a dictionary service that was once established on HBase, which is frequently criticized for two major issues:
○ Massive complex components due to its dependence on the Hadoop system
○ Lack of support for secondary indexes
In view of this, Beike replaced HBase with OBKV, which improves the query performance by 2 to 5 times and the write performance by 5 times with a simplified system complexity.

iii. All-in-one database driven by developers
Sometimes I wonder why developers would use a distributed database that was initially designed for mission-critical core business scenarios in real-time AP or multi-model scenarios as an all-in-one database. I believe the answer lies in the two initial design concepts of OceanBase Database.
○ Distributed architecture: The distributed architecture of OceanBase Database enables it to process massive data and support automatic scaling.
○ Log-structured merge-tree (LSM-tree)-based storage: This achieves a high compression ratio, enabling processing of massive data at a low cost.
With these capabilities, OceanBase Database is particularly suitable for scenarios involving massive data, including not only TP scenarios, but also AP and multi-model scenarios, which naturally involve large amounts of data.
Therefore, it is fair to say that it is the demand of developers and users that has driven OceanBase Database to grow from the early distributed TP system to the distributed AP system, and then into the present-day all-in-one database. With this integrated architecture, OceanBase Database will surely rise up to the future challenges posed by multi-model and AI scenarios, achieving lower IT costs for users.
What lies behind the all-in-one database is the integrated architecture, which includes not only the integrated storage engine, integrated transaction engine, and integrated SQL engine in the kernel, but also the multi-model engine built on the integrated architecture, and the capability to adapt to multiple infrastructures.
OceanBase Database is also a multi-cloud native all-in-one database, which can natively support both public and private clouds with different architectures in one system, including Huawei Cloud, Tencent Cloud, Alibaba Cloud, Amazon Web Services (AWS), Google Cloud Platform (GCP), and Azure. This means that developers can use OceanBase services in different clouds with the same experience.
II. Significance of integration for developers
i. Transparent deployment in standalone and distributed modes
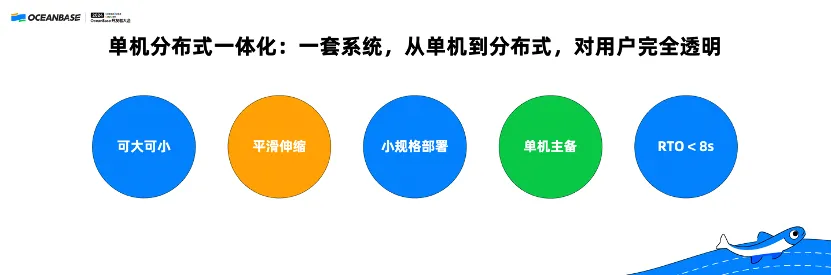
OceanBase Database supports an integrated architecture for standalone and distributed modes. The deployment is transparent to users. Today, the first question facing developers when choosing a database system is whether to choose a centralized or distributed one.
OceanBase Database resolves the dilemma by providing an integrated architecture that supports both standalone and distributed modes. This integrated architecture enables OceanBase Database to support smooth on-demand scaling and small-specification deployment, making OceanBase Database a stand-out choice for large enterprises, SMEs, and even start-ups. Moreover, OceanBase Database also supports three replicas based on Paxos and primary/standby synchronization, and achieves an RPO of 0 and a recovery time objective (RTO) of less than 8 seconds.
ii. OBKV: adding a query API rather than a database
SQL and non-SQL models are integrated to achieve multi-model integration. I believe that multi-model integration is not just about providing a new data model, but more about integrating different data models to combine their respective strengths.
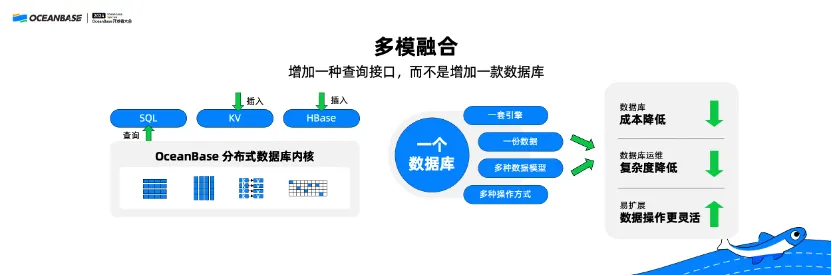
Take HBase, which has been well-explored by many developers, as an example. The write interface of HBase is relatively simple, efficient, and easy to use. However, HBase does not support SQL syntax, and therefore its query interfaces have limited features and are inconvenient to use. With OBKV, we can write data to OceanBase Database in an HBase-compatible way and query data from OceanBase Database by using standard SQL syntaxes, giving full play to technical advantages of both SQL and NoSQL systems.
iii. HTAP = OLTP Plus
Speaking of the integration of TP and AP systems, we often mention HTAP. As I have said in many occasions, HTAP is not omnipotent.
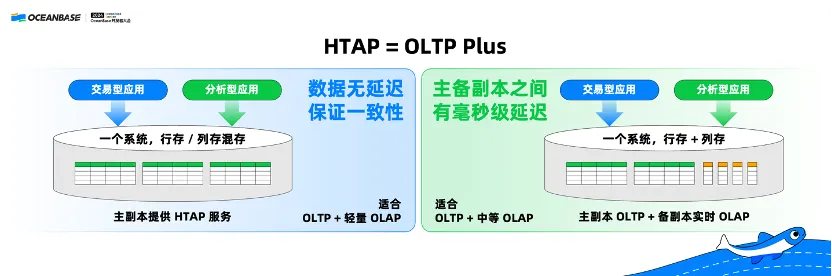
In most cases, HTAP is merely a plus version of online transaction processing (OLTP) that supports online analytical processing (OLAP) capabilities on the basis of OLTP. The following two deployment modes are supported:
(1) Based on the multi-replica distributed architecture of OceanBase Database, all replicas use the same storage architecture, either row-based storage or hybrid row-column storage, and the leader directly provides services. This deployment mode achieves zero data latency while ensuring data consistency, but provides only moderate support for AP capabilities due to the lack of columnar storage. Therefore, this deployment mode is suitable for "OLTP + lightweight OLAP" scenarios.
(2) The leader uses row-based storage or hybrid row-column storage, while one or multiple followers use columnar storage. This service mode incurs data latency between the leader and the followers, but can better support OLAP capabilities. Therefore, it is suitable for "OLTP + medium-load OLAP" scenarios.
To wrap up, HTAP is a solid option in scenarios involving hundreds of GB to hundreds of TB of data, but it is not omnipotent even with these two flexibly deployment modes. Many large companies with a larger data amount usually deploy separate TP and AP systems.
Take Haidilao as an example. Haidilao originally used PolarDB and PolarDB-X for OLTP and AnalyticDB for OLAP, and used Data Transmission Service (DTS) to synchronize data from PolarDB to AnalyticDB.

Haidilao often do promotions in holidays and need to make recommendations according to customer preferences in real time. The HTAP capabilities of OceanBase Database implement both TP and AP based on the same set of data, helping Haidilao reduce the total cost of ownership (TCO) by 35% and improving AP performance by 30%.
III. Use TP & AP integration to fuse core capabilities of distributed TP systems into AP systems
I've mentioned earlier that traditional HTAP is not omnipotent. Here is a new concept that I'd like to share with you: using TP & AP integration to fuse core capabilities of distributed TP systems into AP systems.
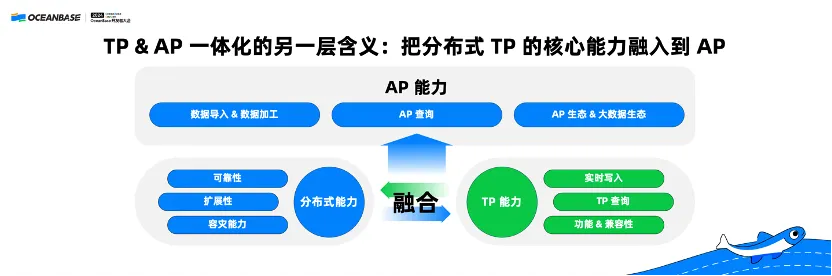
What does it mean? Instead of providing TP and AP services with one system, we can directly integrate TP capabilities into an AP system to build a new real-time analytical database that is easier to use for developers.
We all know that traditional OLAP systems often provide strong large query capabilities, while AP systems feature robust ecological adaptation but do not support real-time writing due to the lack of support for row storage. Therefore, traditional AP systems do not support real-time point queries or real-time serving. Moreover, AP systems are no match for TP systems in terms of syntax compatibility and functionality. Regardless of their diversity, AP systems today are rarely applied in core business scenarios, and therefore fall short of adequate testing in terms of reliability and stability.
OceanBase Database offers sound distributed capabilities, high reliability, and high availability with an RPO of zero. It also provides favorable TP capabilities and supports real-time writing and table access by secondary index primary key for point queries, achieving dynamic serving in AP scenarios. It is also compatible with MySQL Database. Besides, OceanBase also provides a GUI-based O&M tool called OceanBase Cloud Platform (OCP).
OceanBase combines these capabilities with traditional AP capabilities to offer you a new-generation real-time AP system. This system offers better realtimeness and allows you to directly perform both large queries and serving. It is compatible with MySQL Database and is easy to use. Moreover, you can directly use OceanBase control tools for integrated control.
IV. Release of OceanBase Database V4.3.0
Today, I'm honored here to announce the official release of OceanBase Database V4.3.0. This version launches three core technological upgrades:
○ Columnar storage engine
○ Further strengthened TP & AP integration
○ Near-petabyte-scale real-time analytical database that supports data sized [1TB, 1PB)
Let's dive into the core capabilities of OceanBase Database V4.3.0.
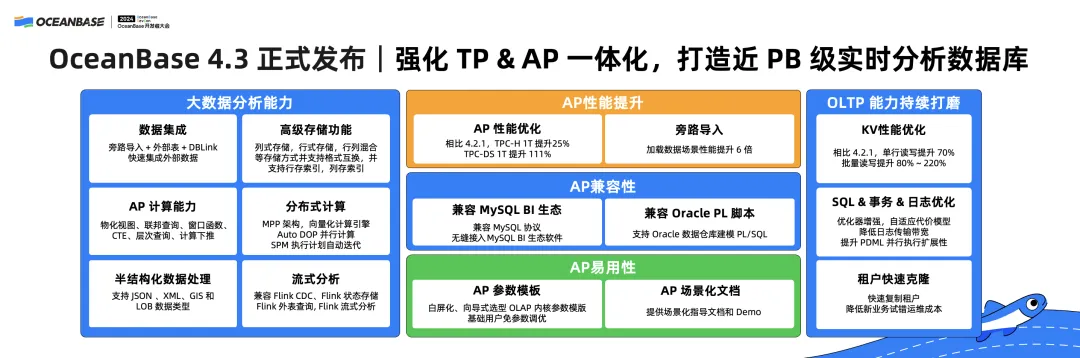
(1) Enhanced TP & AP integration and OLTP capabilities
In KV scenarios, OceanBase Database V4.3.0 greatly outperforms V4.2.1, with 70% higher single-row reading and writing performance and 80% to 220% higher batch reading and writing performance. This version is also optimized in terms of SQL, transaction, and log features.
This version also comes with the fast tenant cloning feature. I believe you would love it. The feature allows you to clone a tenant to generate a snapshot before performing risky operations, so that you can quickly restore the tenant if these operations go wrong.
(2) Enhanced real-time AP capabilities
The new version supports bypass import, external tables, columnar storage, and dynamic conversion between row-based storage and columnar storage.
Many features useful in OLAP scenarios are also provided, such as materialized views, federated queries, window functions, common table expressions (CTEs), hierarchical queries, and operator pushdown.
The distributed computing engine is also significantly enhanced with a Massively Parallel Processing (MPP) architecture and supports the vectorized engine and auto DOP. Moreover, this version also enhances support for semi-structured data, such as JSON and geographic information system (GIS) data. OceanBase Database V4.3.0 is compatible with most mainstream streaming databases in the industry, such as Kafka and Flink.
(3) Improved OLAP performance
Compared with OceanBase Database V4.2.1, the new version offers 25% higher TPC-H 1 TB test performance, 111% higher TPC-DS 1 TB test performance, and six times higher bypass import performance. Some may argue that the 25% TPC-H performance increase is but a mild one. I must remind you here that OceanBase Database has topped the TPC-H benchmark test. So, it's a laudable climb from the top.
(4) Improved AP compatibility
(5) Greater ease of use
This version provides AP parameter templates and scenario-based AP documents, greatly improving the ease of use. We believe that the scenario-based documents can be a great help during your exploration of the new version.
Although OceanBase Database V4.3.0 is officially released today, articles about experiencing the new version are already available on the Internet. You are welcome to learn more about OceanBase Database V4.3.0 in our exhibition area and on the official website.
i. Benchmarking based on analytical loads: OceanBase Database versus top-notch columnar databases in wide-table queries
As a routine of OceanBase launch events, here comes the benchmarking part, which is also one of my favorite parts of this conference. Now we will do the analytical load-based benchmark tests together.
In fact, before this event, we've already run benchmark tests on OceanBase Database and some mainstream real-time analytical databases in the industry and compared the test results. We will use ClickBench, a standard-bearer benchmark for analytical databases in the industry proposed by ClickHouse (which also tops the ClickHouse benchmark rankings), to evaluate the performance of OceanBase Database and ClickHouse.
We have run a benchmark test on OceanBase Database V4.3.0 Beta and ClickHouse 23.11 last year. We later commercialized and evolved OceanBase Database V4.3.0 Beta into V4.3.0. ClickHouse also issued a new release, namely release 24.4, in April this year, which outperforms its predecessor 23.11. Fortunately, we have OceanBase Database V4.3.x Beta.
So today, we will have four systems for the test: OceanBase Database V4.3.0 and V4.3.x Beta, as well as ClickHouse 23.11 and 24.4, which are respectively the latest two versions of OceanBase and ClickHouse.
Now the benchmark test has started. As you know, ClickBench has 43 queries, respectively named Q0 to Q42. In the test, each query is executed 3 times, and the result of the execution that takes the shortest time is taken as the final result of the query.
The systems in the test are displayed either in green or red. A green background indicates that the system runs faster, while a red one indicates slower running. Now that the benchmark test is done, you can see that OceanBase Database V4.3.0 takes 14.5 seconds, ClickHouse 23.11 takes 14.8 seconds, OceanBase Database V4.3.x Beta 12.85 seconds, and ClickHouse 24.4 14.26 seconds. In summary, OceanBase Database V4.3.0 outperforms ClickHouse 23.11, but is outshined by ClickHouse 24.4, while OceanBase Database V4.3.x Beta surpasses all, including ClickHouse 24.4. They are in close tie though.
According to the test results, we can see that under the same hardware conditions, OceanBase Database V4.3.0 achieves a wide table query performance comparable with that of ClickHouse, which is best in class in the real-time analytical database industry.

ii. Aspiring to build an omnipotent real-time analytical database for sub-petabyte-scale scenarios
I've mentioned earlier that the all-in-one architecture of OceanBase Database enables it to tackle various scenarios such as TP, AP, multi-model, KV, and AI scenarios. It sounds as if OeanBase Database suits all purposes. Then what are the scenarios that OceanBase Database is truly suitable for? The scenarios can be classified into the following categories:
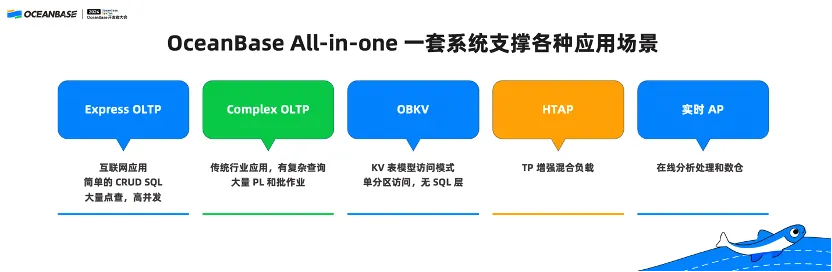
(1) Express OLTP
Such scenarios generally involve simple read and write operations at high concurrency in the Internet industry. MySQL Database usually fits these scenarios.
(2) Complex OLTP
Such scenarios involve some complex queries, batch operations, and stored procedures in addition to simple read and write operations. These scenarios are often encountered in conventional industries for which commercial databases such as Oracle are well-suited.
(3) OBKV
Systems such as HBase and Redis are apt for these scenarios.
(4) HTAP
An HTAP system processes both OLTP and real-time AP loads. In my opinion, HTAP is applicable to scenarios involving hundreds of GB to hundreds of TB of data.
(5) Real-time AP scenarios with larger data amounts
The difference between real-time AP and HTAP is that the data source for HTAP is a system, while the data source for real-time AP is not only the TP system of OceanBase Database, but also may be other databases, Kafka or Flink instances, files, or storage systems. The real-time AP system will further extend the AP capabilities of OceanBase Database.
Real-time AP is suitable for scenarios with a data amount of 1 TB to 1 PB. A scenario with a data amount of more than 1 PB can be taken as a large enterprise scenario. Large enterprises, such as Alibaba and Tencent, have their own in-house data lakes or big data analysis systems, which fall out of the application scenarios of OceanBase Database.
We can build a lightweight real-time analytical database directly based on the real-time AP capabilities of OceanBase Database. This analytical database supports diverse data sources, real-time writes, batch writes, and some batch updates. After the data arrives at OceanBase Database, it will be processed in layers, first by the operational data store (ODS) layer, and then by the data warehouse detail (DWD), data warehouse summary (DWS), and application data service (ADS) layers in sequence.
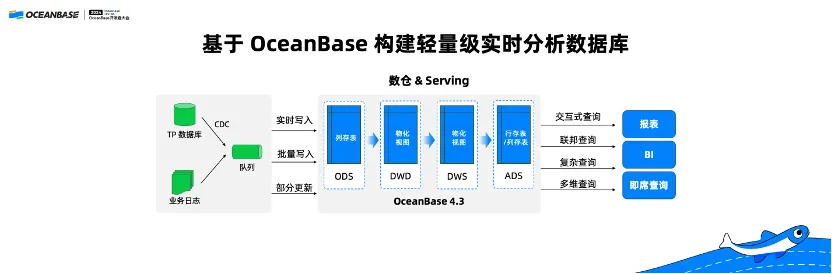
The ODS layer stores raw data, and the real-time data warehouse usually uses columnstore tables. DWD and DWS process raw data in two layers, usually by using materialized views. Then, the ADS layer carries out serving. It uses row-based storage for simple point queries and table access by index primary key. However, when the data amount of each query is large, it uses columnar storage for serving.
In OceanBase Database V4.3.0, we can carry out both large queries on the data warehouse and serving at the same time in one system, providing users with better real-time capabilities. In addition, the enhanced compatibility with MySQL makes it easier to use for developers.
We aspire to forge the real-time AP system of OceanBase Database into an omnipotent real-time analytical database for sub-petabyte-scale scenarios.
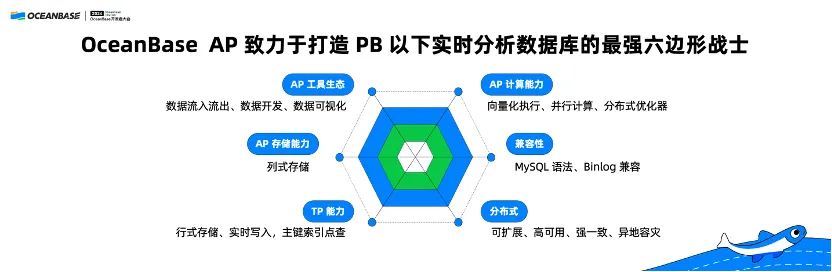
First, it is suitable for scenarios with a data amount of 1 TB to 1 PB. It is designed for users with real-time demands, whereas users with pure offline analytics demands have many other options. OceanBase Database provides strong TP capabilities, supports real-time writing, and directly provides AP services through point queries. OceanBase Database also has sound MySQL compatibility and good distributed capabilities for high availability. Moreover, it also offers high stability, with basically no bugs.
Second, OceanBase Database provides exceptional real-time AP capabilities, and realizes columnar storage and vectorization. Notably, it has topped both the ClickBench and TPC-H benchmark rankings. I believe that the combination of these two capabilities will make OceanBase Database an excellent choice of real-time analytical database for sub-petabyte-scale scenarios.
iii. What's next
We have a lot to do next. In the first quarter, we released OceanBase Database V4.3.0 in this developers conference. This version enhances the capabilities of columnar storage and the vectorized engine. In the months to come, we will continue to tap the potentials of OceanBase All-in-one, to improve its integration with and support for multi-model, search, and AI capabilities.

In the second quarter, we will develop full-text indexing and JSON multi-value indexing capabilities and strengthen database search capabilities. In the third quarter, we will further support vector database capabilities by using components. With support for vector databases, you can directly develop your own large model applications based on OceanBase Database. In the fourth quarter, we will implement storage-compute separation capabilities based on Amazon Simple Storage Service (S3).
OceanBase Database has many users in public clouds. As we all know, storage and computing are separated in a public cloud. However, currently, OceanBase Database implements storage-compute separation based on expensive cloud disks of public clouds. With the object storage capability based on S3, we can greatly improve the cost performance of OceanBase Database.
V. Improved ease of use
Many developers speak to me highly of OceanBase Database in the following aspects:
The first is its powerful technological capabilities. We enjoy running benchmark tests in our launch events. Sometimes we run TPC-C benchmark, sometimes TPC-H or ClickBench, and other times ClickHouse. It's a bit like having your excellent child competing for top universities and showing off their achievements in your neighborhood. This is the core technological capabilities of OceanBase Database.
The second is that OceanBase Database realizes high O&M efficiency for proficient developers or DBAs. One Alipay DBA can operate and maintain thousands of servers. However, you can fully explore the powerful features of OceanBase Database only after you gain profound knowledge about it.
Therefore, we have made a lot of effort to make OceanBase Database easier to use and get started with.
Next, let's take a look at some video clips from our users and developers concerning the ease of use of OceanBase Database.
We would like to extend our gratitude to Chunlei, Guangming, and Baishan. Thank you for your praise and encouragement. Your constructive comments are also highly appreciated. We will spare no efforts to meet your high expectations for OceanBase Database.
Speaking of ease of use, I often think of the technical books I have read. Such books are often titled something like "From Beginners to Experts", "Seven Days to Learn xxx", and "Learn a programming language in 21 days". That is why I named this presentation "OceanBase – From Beginners to Experts"
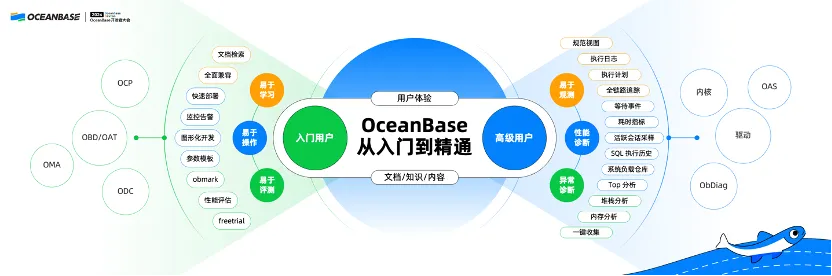
The ease-of-use feature is helpful for the following two types of users:
The first type is beginners. These users are more concerned about how to quickly deploy OceanBase Database, whether a GUI or CLI tool is available for quickly performing benchmark tests and basic demo tests, and whether reference documents are available.
The other type is users who have been using OceanBase Database for a while. For these users, all their requirements can be summarized into one question: What do I do when something goes wrong? This seemingly simple question is hard to answer. A situation going wrong may be caused by various exceptions, such as common exceptions like server failures, network failures, and disk failures, or underlying issues like system suspension or jitter caused by unknown reasons. Therefore, experienced users tend to look for answers in the debug logs of OceanBase Database.
In the previous videos, we can see some of the most basic GUI-based features of OceanBase Database. OCP is quite a standout in the industry. Guangming even said that OCP is the best ecological tool that he has ever used throughout his career. I'm thrilled to hear that. The credit goes to our OCP team.
However, OceanBase Database still entails some drawbacks. For example, the quickstart tutorial needs to be optimized. Many users may find it difficult to come by the relevant documents when they install and deploy OceanBase Database. In addition, no effective tools are available for diagnosing some underlying issues such as jitters and system suspension. The debug logs of OceanBase Database are also inferior to those of Oracle Database in terms of observability and ease of use.
In fact, we've invested considerable efforts to make relevant improvements last year, though some expectations are yet to be fulfilled.
i. Ease to learn: lowering the barrier for getting started
We have put in a great deal of work to lower the barrier for novice users from the following aspects:

(1) Installation and deployment
Chunlei has mentioned some issues related to installation and deployment in the video earlier. Last year, we achieved quick installation and deployment of OceanBase Database within two minutes by using OBD. However, OBD offers limited features. Though boasting rich and powerful features, OCP supports the installation of OceanBase Database only in an environment that meets specific hardware conditions. Neither of the two tools can fully meet the needs of developers.
In light of this, we combine OBD and OCP. You can use OBD to install OceanBase Database and then use OCP to run the database, so that you can tap the rich management and control capabilities of OCP after installation. This resolves the installation and deployment issues mentioned by Chunlei.
(2) Performance tests
OceanBase Database is renowned for its performance. Yet many developers told me that they must become OceanBase experts to bring out its full potential.
Therefore, we provide parameter templates based on scenarios, enabling developers to build OceanBase databases that can yield remarkable benchmark test results.
(3) Documentation
OceanBase documentation is voluminous. There are only slightly over 1,900 topics for OceanBase Database V2.x, and over 2,900 for V3.x, but over 3,900 for V4.x. Over 1,000 topics are added in each version upgrade.
Despite the substantial efforts invested into documentation optimization last year, there is still much room for improvement. We hope to receive more insights about documentation and ease of use from more developers like Baishan.
We position OceanBase Database as a globally popular database. To achieve this goal, we must deliver product documentation that meets world-class standards.
Besides documentation, the following two features can also be useful for developers:
One is online experience. It would be more constructive if we can experience first-hand the features described in the documentation. Therefore, we provide the online experience feature, which provides an environment for you to experience online the OceanBase knowledge described in the articles. With the online experience feature, you can copy an operation and check the effect directly in the cloud environment. We also have a documentation area here. You are welcome to try it out.
The other is the knowledge base. We enhanced the OceanBase knowledge base last year and added more than 1000 cases. These cases are based on many years' experience of OceanBase and Ant Group DBAs in mining and solving problems in customer scenarios. We hope it can be helpful for developers.
ii. Ease of diagnosis: improved diagnostic capabilities
We have also further improved the diagnostic capabilities of OceanBase Database.

OceanBase Database excels in handling simple exceptions based on OCP, such as some simple network failures, disk failures, and simple compaction issues. This is because OCP can detect the causes for such exceptions. However, as for deep-seated issues whose resolution requires profound understanding of OceanBase Database, OCP is found inadequate. Therefore, we provide the following tools as a complement:
(1) Active Session History (ASH): the perf-like tool of OceanBase Database
We all know the perf tool of Linux. When something goes wrong, we turn to perf to find the cause.
Last year, we developed a tool called ASH, an OceanBase version of perf. You can locate causes of issues by referring to ASH reports. Seemingly easy, developing ASH was actually very challenging for us.
We've set up a dedicated performance diagnostics team made up of many senior OceanBase kernel developers. They spent over a year developing a time model that ensures time accuracy for all backend tasks, locks, wait events, queue entry, queue exit, and so on.
(2) OceanBase Autonomy Service (OAS): for root cause analysis
OAS incorporates rules that are formulated based on years of customer service experience of Ant Group and OceanBase. After you locate the issue based on ASH reports, you can use OAS to identify the root cause.
(3) alert.log
OceanBase Database has long been criticized for its debug logs, which contain excess content, making it difficult for developers to find useful information.
This year, we launched the alert.log file based on suggestions from developers. This file is an extract from the debug logs, and records the common system events that occur during the operation of OceanBase Database. Developers can resolve 80% of the issues that they encounter by referring to alert.log, without the need to dig through the long-winded observer.log file.
iii. On-demand use of serverless instances, with a 1-month free trial
The concept of "serverless" is intrinsically linked with cloud native. Compared with common instances, serverless instances support more flexible scaling methods and full on-demand use, making them a cost-effective choice for developers.
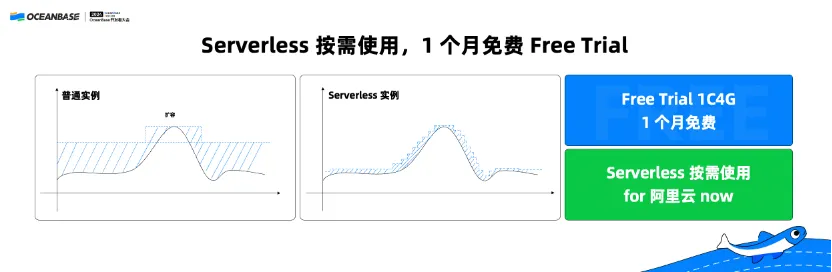
OceanBase Database serverless instances are now supported in ApsaraDB for OceanBase. A one-month free trial is provided for serverless instances with a specification of 1C4G on Alibaba Cloud and Huawei Cloud. We have a free trial demo here in the exhibition area. I was told that it is so popular that the quota is used up. Don't worry. We are applying for more quota.
VI. A more open technology ecosystem
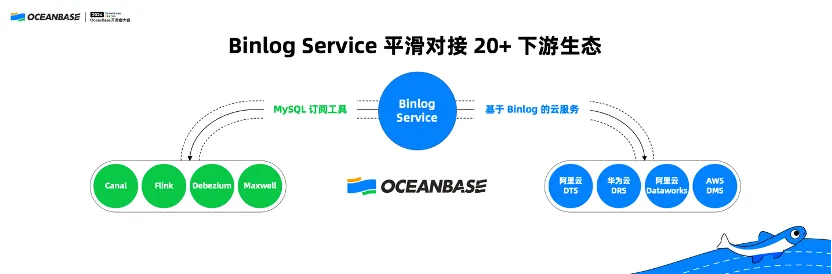
i. Smooth integration of binlog service with over 20 downstream services
Last year, we also developed a useful feature, a MySQL-compatible binlog service, which has been integrated with more than 20 downstream services, including some MySQL subscription tools and binlog-based cloud services.
I'd like to share some untold stories behind this feature. The OceanBase product R&D department will present a "Breakthrough Award" at the end of each year. It's the top award in our department. The final candidates of the award last year were the columnar storage project team and the binlog project team.
Well, as it turned out, the binlog project team won the award. I am glad that our department leaders voted for the binlog project team that is dedicated to improve ease of use, instead of the columnar storage project team that is set out to enhance core product capabilities. This is a testament that our production and research team has realized that improved ease of use means more to developers than modest performance enhancement.
ii. OceanBase landscape: from basic ecological adaptation to open technology ecosystem
This is the landscape of OceanBase ecological tools.
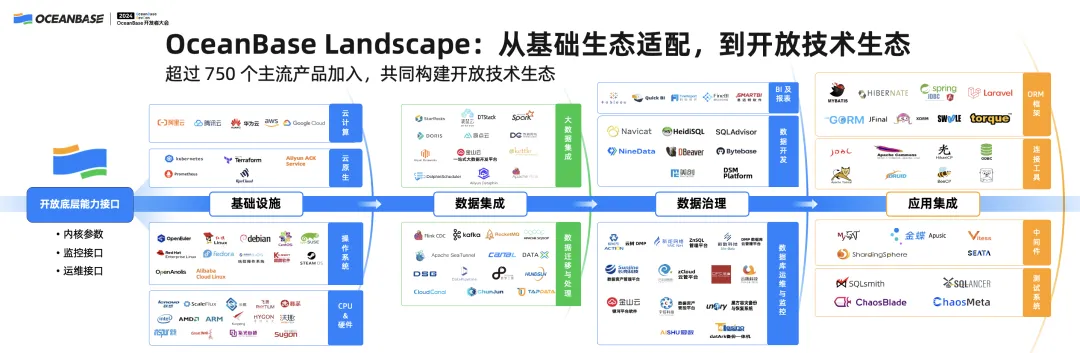
OceanBase ecological tools have gone through two main stages in their development.
The first stage is ecological adaptation, including the adaption of ecological tools to the OceanBase Database kernel and adaption of OceanBase Database as a database ecosystem to other database ecosystems, such as Kubernetes and big data.
The second stage is joint construction of the ecosystem based on open APIs. At present, more than 750 mainstream products have joined the OceanBase ecosystem, and joined forces with OceanBase to build the open ecosystem.
iii. Sustained efforts to lower entry barriers for developers based on open source
Finally, I'd like talk about the open source community of OceanBase.

The OceanBase open source community was originally positioned as a "responsive" community where user feedbacks will be responded in a timely manner. Now we have upgrade the community to be an interactive one.
I've always believed that open source is not just about opening up and sharing some source code of products or technologies, but more about the open source community being a bridge that brings together people interested in a certain product. This is one of the key insights I gained last year.
Gladly, our user organization OUG finally went on track last year. We've held a series of OUG city visit and enterprise visit events in concert with a bunch of enterprises such as 58, Zhihu, and Vivo in the open source community.
Many developers have shared their thoughts in the open source community. More than 118 developers opened their blog accounts and published more than 1,000 technical blogs. The community also boasts an impressive collection of co-developed open source projects, including six warehouses containing over 50,000 code lines built jointly by OceanBase and other companies or developers.
VII. Huge kudos to developers, who built a bridge for communication with inspired initiatives
Our special thanks go to the 108 developers entitled "Star of the Month". Your active participation has made our community a better place to learn about OceanBase. We also highly appreciate the efforts of the application developers and 315 OceanBase contributors for jointly building the OceanBase ecosystem and making the open source endeavor more fruitful.

Last but not least, I'd like to share with you a project case from the OceanBase community. It is an initiative made by a developer to build a vector engine plug-in to integrate SQL and AI in OceanBase Database.
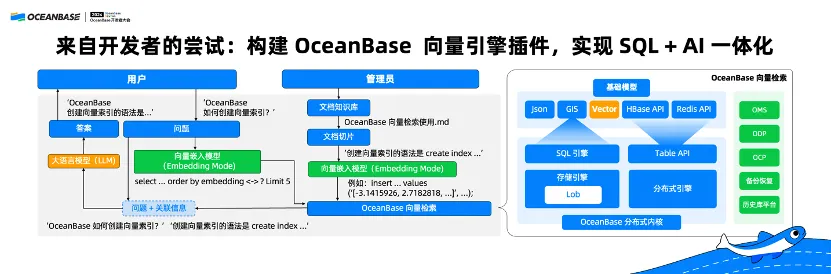
Though OceanBase Database currently does not support vector databases, he still spent months in writing a vector engine plug-in based on the open source code of OceanBase Database. He also built a personal knowledge base based on the vector engine plug-in that he wrote. This knowledge base supports natural language retrieval.
This initiative is fascinating. We look forward to more initiatives like this coming up in the OceanBase community. We sincerely hope that our open source community will become a warm haven where people can have fun and make friends.
That's all for my sharing today. Look forward to seeing you again at the 2024 Release Conference.