Vector capabilities of OceanBase Database: find similar images in a blink
Basic capabilities of a vector database
Generally, AI technologies are applied in a database storage system for the following two purposes:
First, approximate search. In this application architecture, unstructured data is transformed into vectors and stored in a database with the help of Large Language Model (LLM) embeddings. This way, the database can perform vector operations and similarity search, and supports search recommendations and queries of unstructured data.
Second, retrieval-augmented generation (RAG). It's true that LLMs provide general capabilities such as natural language conversation, text summarization, agents, and coding assistants. However, they are trained using limited knowledge and often perform awkwardly in dealing with the humongous amount of fresh knowledge generated online. A common solution, for example, is to build a database to host a Q&A corpus and provide a corpus-based information retrieval service for LLMs. This process is called RAG.
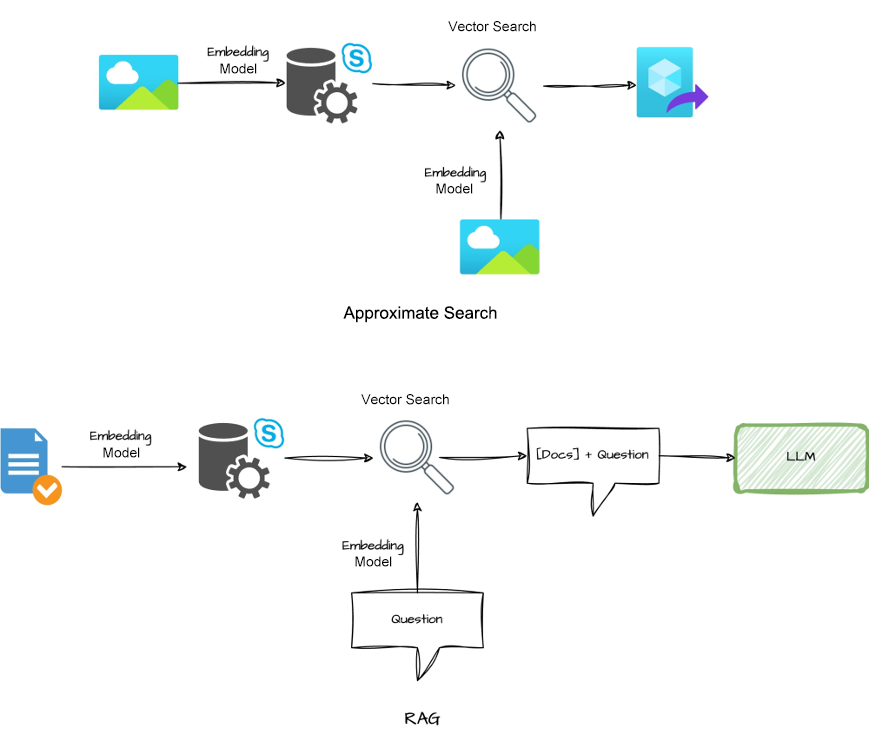
OceanBase Database Community Edition supports the following basic capabilities of a vector database. For more information, see the vector_search branch on GitHub.
- Definition and storage of the VECTOR data type.
- Creation of an approximate nearest neighbor (ANN) index on a vector column. Supported indexing algorithms include Inverted File with Flat Compression (IVFFlat) and Hierarchical Navigable Small World (HNSW).
- Parallel creation of ANN indexes on partitions.
- Parallel execution of ANN search on partitions.
These capabilities enable OceanBase Database to support the aforesaid two AI application architectures as the underlying storage system. In the following example, a reverse image search application is used to demonstrate the vector storage capability of OceanBase Database based on the approximate search architecture.
Vector storage capability of OceanBase Database
1. Deploy an OceanBase vector database in Docker
Run the following command to install the vector database:
docker run -p 2881:2881 --name obvec -d oceanbase/oceanbase-ce:vector
The database is ready to work when the docker container returns the boot success! message. You can test the vector processing capability of OceanBase Database using its SQL APIs based on the following example. Run the following command to open a shell on the docker container:
docker exec -it obvec bash
Connect to OceanBase Database:
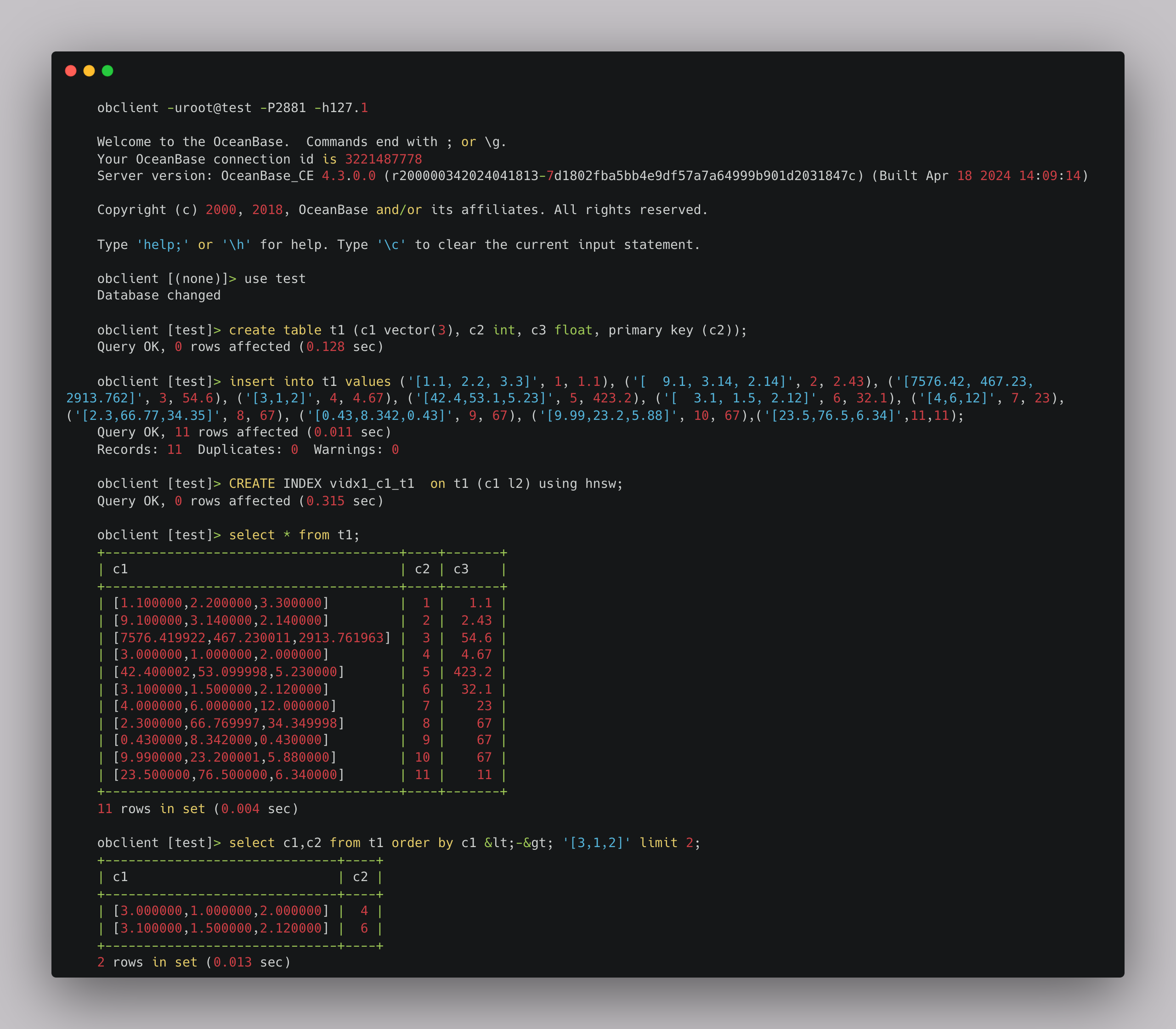
- A vector data table named
t1is created. It contains a vector columnc1. - Vector data is into the table. Note how vector data is defined by constant values in OceanBase Database.
- An
HNSWvector index is created on this vector data table. AnIVFFlatindex is also supported. - A full table scan is performed on the vector data table.
- Typical ANN search is performed by the following statement:
select XXX from XX order by XXX limit XX. - <->: specifies to calculate the Euclidean distance between two vectors.
- <@>: specifies to calculate the inner product between two vectors.
- <~>: specifies to calculate the cosine distance between two vectors.
2. Process image data
You can use any categorized image library as the dataset. In this example, an image library is downloaded from the following link:
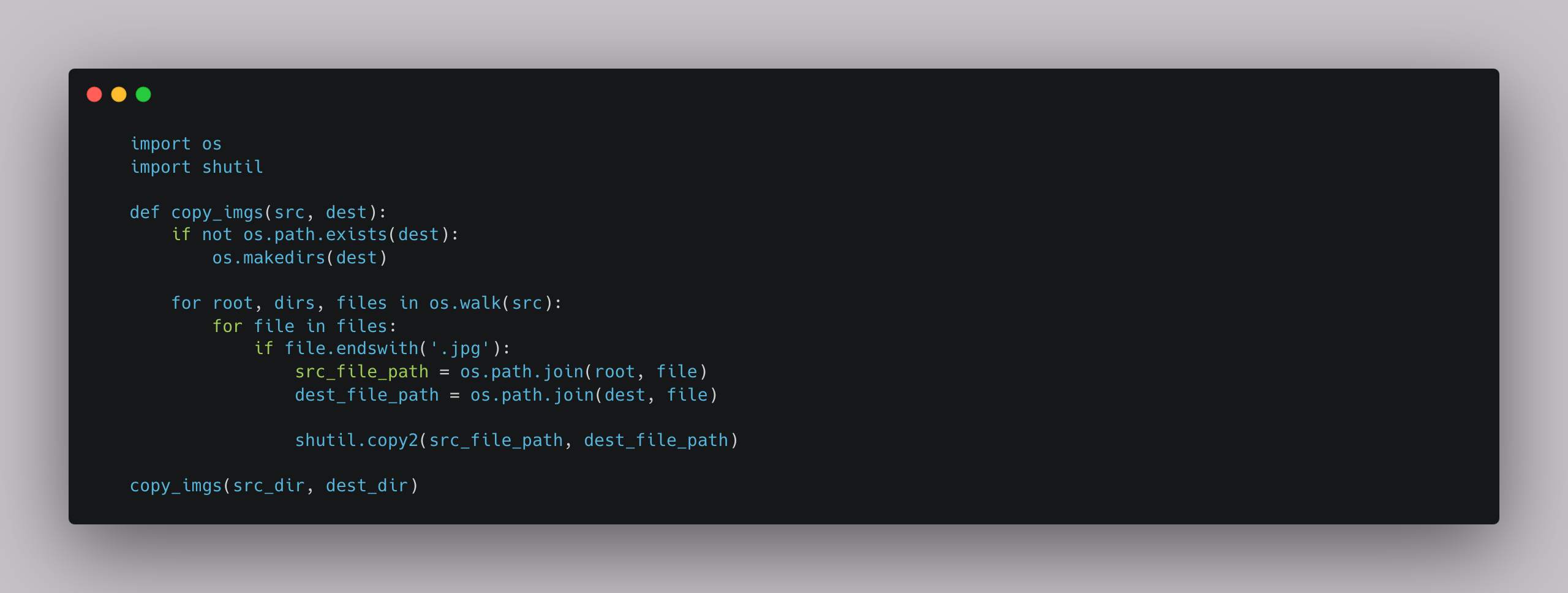
This library contains images of different sizes, which makes it unsuitable for conventional machine learning applications that require uniform image sizes. This is not a problem here, as an embedding model is used for vector search. However, it is necessary to move all the images from their respective categorized directories to a single directory:
3. Connect to OceanBase Database by using a Python library
The following example connects to OceanBase Database by using the sqlalchemy library. The VECTOR type is not supported in the MySQL dialect, so a custom Vector class is defined to implement a method that converts the VECTOR type to a Python list type, and then to constants supported by the OceanBase vector database:
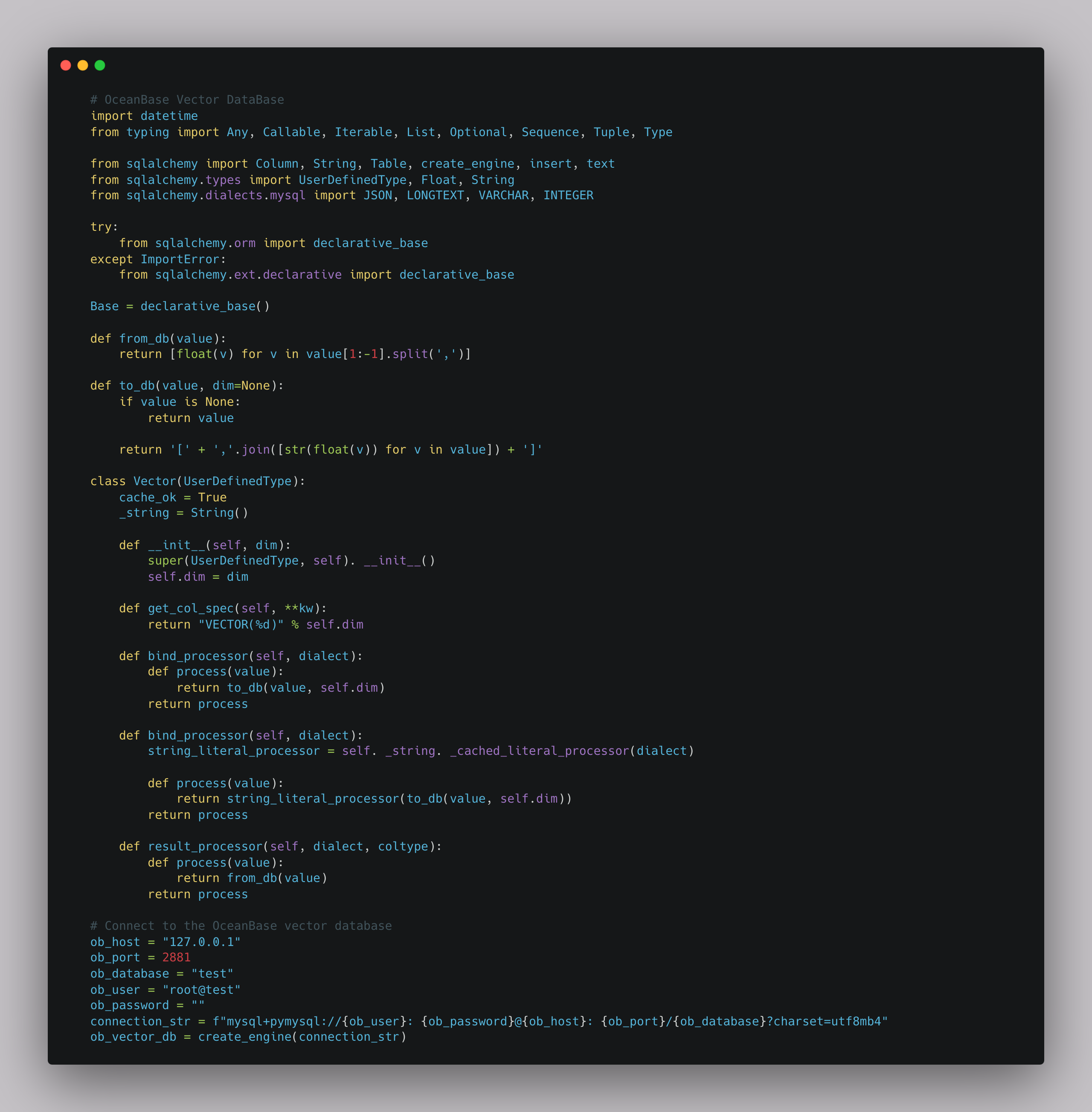
When the docker image of OceanBase Database starts, it automatically creates a test tenant and enables port 2881 for MySQL services. You can construct a connection string to create a connection.
4. Define a vector processing interface
Define a Python interface for processing vectors in OceanBase Database:
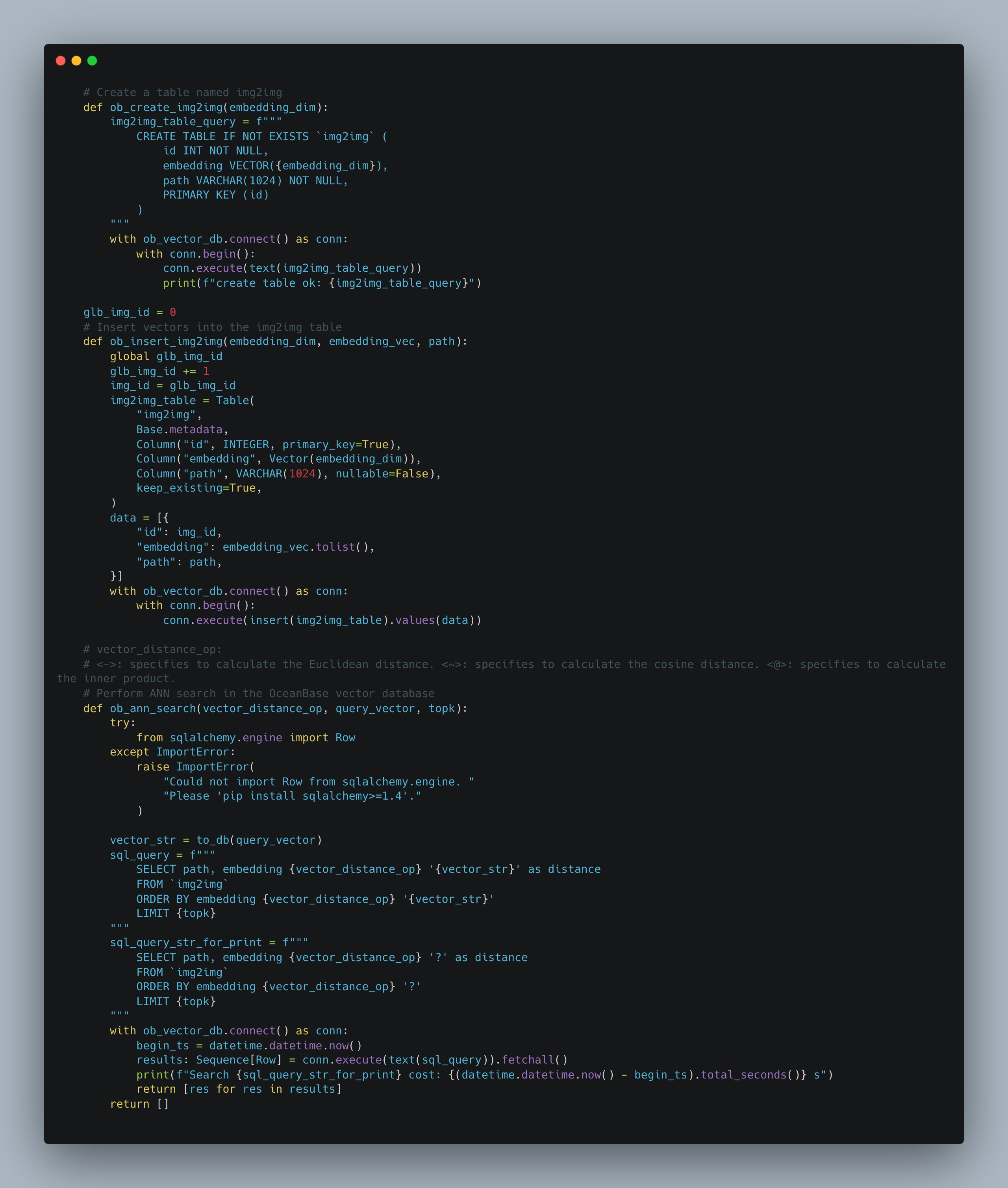
-
ob_create_img2img: Creates a vector data table. You need to pass in the vector dimension. OceanBase Database allows you to insert only vectors with the fixed dimension to a vector data table. For the reverse image search application, the table schema is defined as follows: -
id: the unique id number that is assigned to an image, and is used as the primary key of the vector data. -
embedding: stores the vector data embedded in an image for ANN search. -
path: the path of an image. After similar vectors are found based on theembeddingfield, thepathfield is used to display the images. -
ob_insert_img2img: inserts vector data into the vector data table. -
ob_ann_search: executes ANN search and calculates the time consumed in the search.
5. Import images into OceanBase Database
We use the Contrastive Language-Image Pretraining (CLIP) model to convert images to vectors. You can download the CLIP model from Towhee as follows:
You can run the following command to obtain vectors:

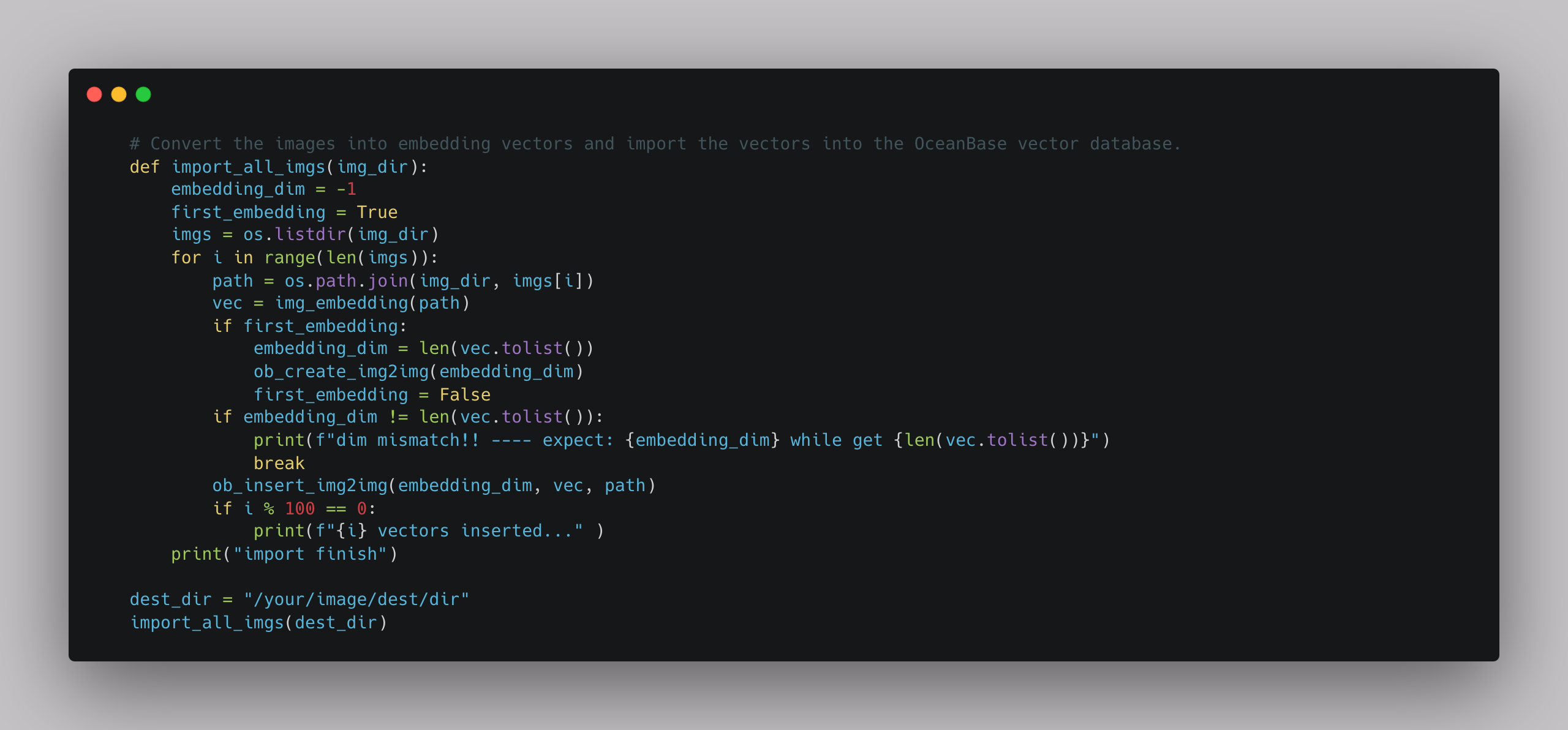
Then, you can use the following commands to combine the whole pipeline, convert all images in the image library to vectors, and then insert the vectors into OceanBase Database. Note that you need to run the vector data table creation command for the first insertion:
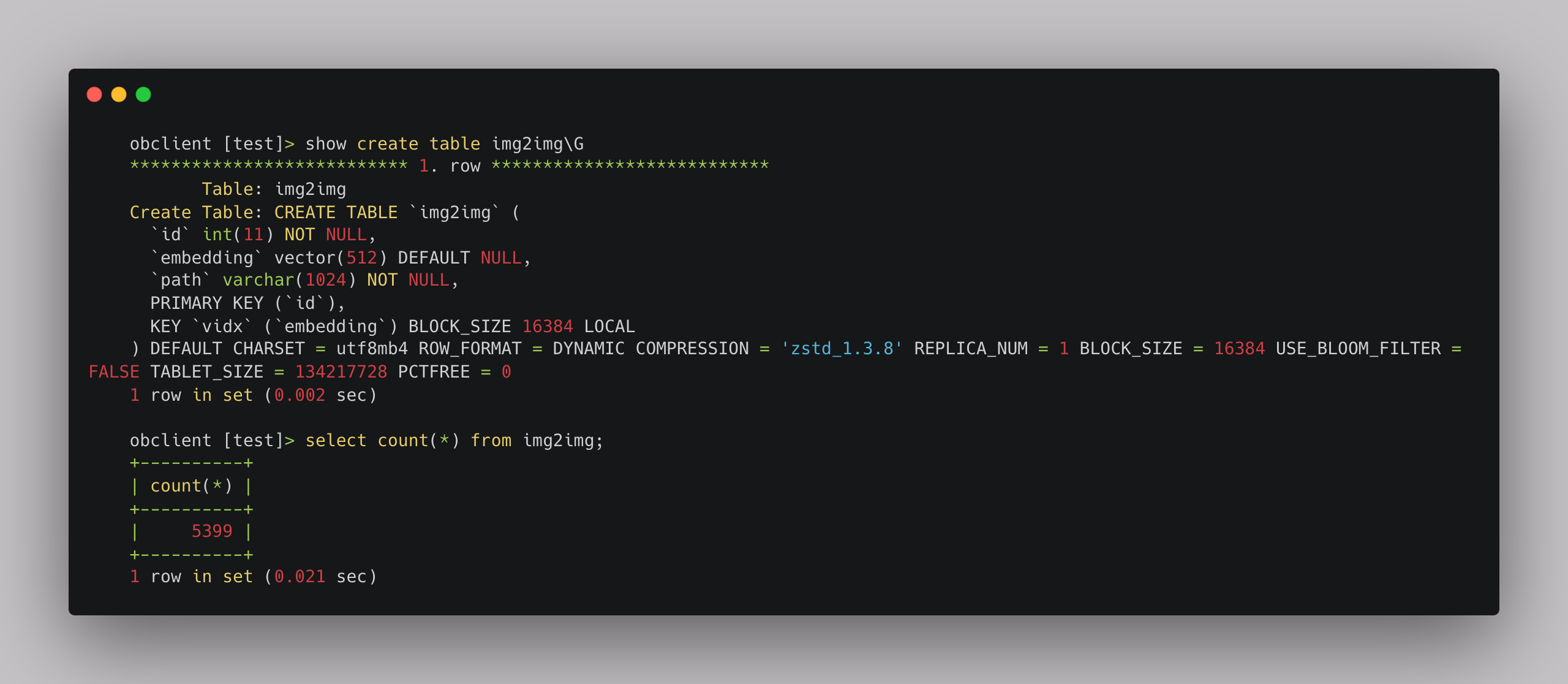
Create a MySQL connection and query the number of vectors. In this example, 5,399 vectors with 512 dimensions are imported:
6. Perform reverse image search
We use Gradio to create a simple web UI that provides the following two inputs:
Image upload component: uploads the image to be queried.topK slider: sets the top K values for ANN search.
During the search, the uploaded image is written to a temporary directory and converted to a vector. Then, the pre-defined ob_ann_search function is called to obtain paths of the nearest images. At last, similar images are displayed by the gallery component:
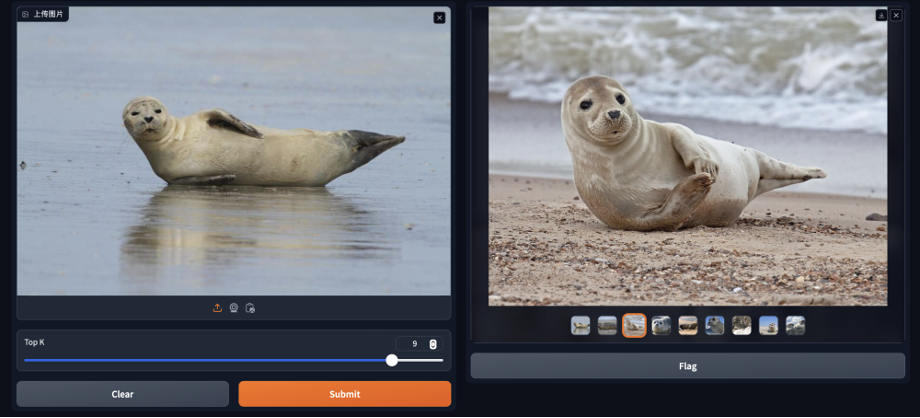
Upload an image for a test. The results are as follows:

Images in the results are all about seals.
7. Create a vector index
Create a MySQL connection and then create an IVFFlat index:

Optimized by the vector index, the time required to obtain the top 9 results is shortened from 39 ms to 7.6 ms:


Use AI technologies to empower vector capabilities
OceanBase Database adopts a native distributed architecture and stores data with a high compression ratio. Leveraging AI technologies, OceanBase Database will gain stronger storage and retrieval capabilities:
- The distributed storage engine of OceanBase Database will be able to store massive amounts of vector data.
- Parallel query execution on partitions can be enhanced to provide efficient vector-based approximate retrieval.
In other words, OceanBase users will enjoy lower storage costs, faster query speed, and more accurate query results.
Moreover, compared to storing unstructured data directly, converting unstructured data into vector data through embeddings and storing vector data brings two benefits to AI applications: First, unstructured data is not directly presented to database administrators, which means higher data security. Second, it is easier for a database system to understand semantics. Vector-based approximate retrieval works on semantics. Vector values of similar text, image, and video information are close, which means that users can get accurate results with similar keywords, saving search costs and improving search efficiency.
OceanBase Database now supports the approximate search and RAG application architectures.
Approximate search is applicable to many scenarios, such as:
- Search recommendations
- Data classification and deduplication
- Vector input for generative models, such as a style transfer model
- ...
RAG is also applicable to a range of scenarios, for example:
- Q&A based on a private knowledge base
- Text2SQL
- ...
We will continue to optimize the vector capabilities of OceanBase Database, including but not limited to simplifying the SQL syntax of ANN search, supporting GPU acceleration and more vector operation functions and vector retrieval algorithms, improving hybrid scalar/vector query performance, and providing more AI interfaces to support, for example, Matrix, which allows you to perform image transformation operations using SQL interfaces.