From OLTP to OLAP: Exploration and practice of the OceanBase SQL engine
On March 25, 2023, we held the first "OceanBase Developer Conference" to explore cutting-edge database trends such as the standalone distributed architecture, cloud native architecture, and hybrid transaction/analytical processing (HTAP), share new product roadmaps, and communicate about scenario exploration and best practices with developers. In the "Product Technology Session", Senior Technical Expert Zhu Tao from OceanBase gave a presentation on the topic "From TP to AP: Exploration and Practices of the OceanBase Database SQL Engine". This blog post is compiled based on the presentation.
First, what is the OceanBase Database SQL engine and what does it do? Second, OceanBase Database was first designed to serve internal businesses of Ant Group. What have we done to make SQL execution faster in Internet TP scenarios for the database to better serve such scenarios?

After that, OceanBase Database was commercialized to gradually serve some external customers in fields such as finance, securities, telecom operators, and insurance. At that time, we noticed that external customers used SQL queries in a quite different way from that inside Ant Group. This posed a new challenge in SQL execution and optimization in our product. Confronting new business scenarios and SQL scenarios, what have we done?
Finally, as the TP capabilities of OceanBase Database were constantly enhanced and optimized and its execution capabilities were accumulated, the database became AP-capable. What efforts and optimizations have we made for AP scenarios?
01. Overview of the OceanBase Database SQL engine
The following figure shows the overall framework of the OceanBase Database SQL engine. After a query is initiated in OceanBase Database, it first enters into the parser, a module where the kernel figures out the purpose and requirement of the query.
Then, the query enters into the optimizer, which will select the best among a variety of implementation methods for the executor.
The executor contains all details for executing the method. It will faithfully execute the query based on the plan recommended by the optimizer and return the result to the user.
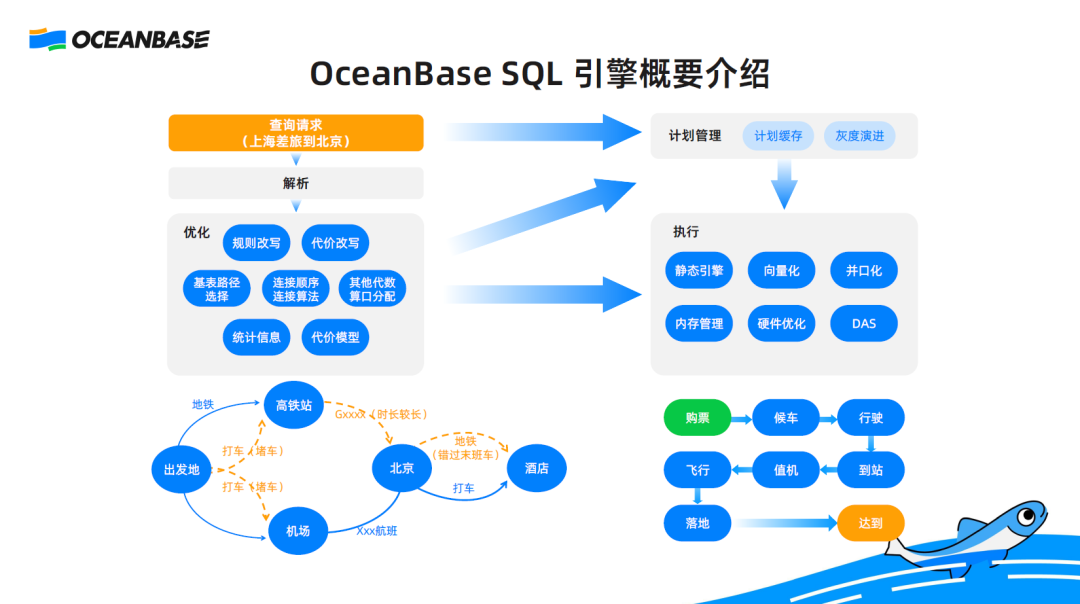
Here is an example for you to understand the process:
Assume that my requirement is to go on a business trip from Shanghai to Beijing to attend OceanBase Developer Conference the next day. What will the optimizer do?
There are two choices to travel from Shanghai to Beijing, by high-speed rail or airplane. After arriving at Beijing, I can take subway or taxi from the airport hub to the hotel. Similarly, I can take subway or taxi from my home to the airport hub in Shanghai. A number of execution plans will be generated for my requirement. The optimizer will evaluate the execution plans to find out the optimal one based on a cost estimation system.
As for my business trip, time consumption is the main factor to consider. Specifically, when I leave for the airport hub in Shanghai, taxi is a more comfortable choice but the time taken is uncontrollable due to the traffic jam during busy hours. Therefore, the optimizer chooses subway for this part. Generally, flying to Beijing is faster than taking high-speed rail, so the optimizer chooses the former. I may arrive at Beijing late at night. Theoretically, I can take subway from the airport hub to the hotel, but I may have missed the last train by then. Therefore, the optimizer chooses taxi for this part. For the entire trip, the optimizer generates an optimal plan as follows: subway from home to the airport hub in Shanghai, airplane from Shanghai to Beijing, and taxi from the airport hub in Beijing to the hotel.
Two key capabilities of the optimizer are required during this process:
First, the capability in plan enumeration. The optimizer needs to enumerate a variety of different plans, which are the "plan space" for optimization. The more plans, the higher probability to find a quick execution strategy.
Second, the capability in accurately selecting the optimal plan. The optimizer needs to single out the optimal plan based on an accurate cost model.
What is also important is that the executor will faithfully execute the selected execution plan. In this example, the executor has to consider all the details, including buying subway tickets, waiting for the subway, taking the subway, checking in for the flight, taking the flight, and landing at the destination. What are the key points in execution?
First, good implementation. Each part of the trip must be efficient. As the time taken in each part is shortened, the entire trip will be faster.
Second, design and production of various transport tools. For example, subways, airplanes, or more efficient and convenient transport tools need to be designed and produced for the executor to choose, which enriches the execution modes.
So, what are our challenges in actual business scenarios?
02. Speed up TP SQL queries in Internet scenarios
First, I want to share with you an Internet scenario (a TP scenario inside Ant Group) to illustrate the challenges facing us.
I have been serving OceanBase and observing the business model of Ant Group for years. I notice that most Internet SQL queries on databases are single-table short queries. For a single-table short query, the only key point is to accurately select an index.
For example, for a short query that needs to read 100 rows, an appropriate index can obtain the query result by reading over 100 rows. However, an inappropriate index may need to read 10,000 rows to obtain the query result, which is unacceptable. Assume that the system can read a maximum of 2 million rows per second. If the system can obtain the query result by reading 100 rows, the theoretical queries per second (QPS) is 2,000,000/100. If the system needs to read 10,000 rows to obtain the query result, the theoretical QPS is 2,000,000/10,000, which is much lower. The optimization for single-table short queries seems simple but is actually difficult.

The preceding figure shows two cases. The first case is an actual scenario inside Ant Group. The table in this case contains more than 30 indexes. In this case, when I query data from this table, there may be more than 30 execution plans. It is difficult to find an appropriate index.
The second case shows two single-table queries whose predicate or SQL syntax is more complex. The first query does not use an AND condition but an OR predicate on two columns. Both of the columns may have an index. However, if no optimization is made for this query, no index can be used.
The second query is more complex. After filtering, the filter conditions and filtering performance may be poor and a large number of rows may be retrieved. However, to ensure that a large amount of data is retrieved, the data will be paginated and sorted by the gmt_create field, and the first 20 rows will be displayed. To optimize this query, the best choice is to push down the WHERE, ORDER BY, and LIMIT operators to an index, to scan 20 rows from a specific row and then return the result.
What can we do for the two scenarios from the O&M perspective? You can bind each SQL query with an index. If the optimizer cannot select an appropriate index, select it manually.
For the second case, it is not easy to use hints. To accelerate the execution of these queries, you may need to split the first query into two queries combined by the UNION operator and execute the two queries by using different indexes. For the second query, you also need to split the STATUS IN condition into two queries, obtain the first 20 rows sorted by the gmt_create field respectively, merge the two result sets, and return the first 20 rows in the final result set. SQL query rewrite is not easy, especially from the O&M perspective. Database personnel will receive complaints if they cannot handle the issue and kick it to business personnel.
In OceanBase Database, an appropriate index is automatically selected in most scenarios. For a single query, many indexes are totally irrelevant. For the query in the first case, OceanBase Database will prune irrelevant indexes to decrease the number of indexes from 30 to 5, and then find an appropriate index based on cost estimation.
For queries in the second case, the kernel optimizer of OceanBase Database provides a rewrite module to accurately translate the queries. It splits the OR condition in the first query and ORDER BY ... LIMIT in the second query into conditions in queries combined by the UNION operator.
However, the optimizer may still make a wrong choice in index selection. The optimizer selects an index based on statistics or historical data. If the data is not real, the selected index may be inappropriate. To address this issue, OceanBase Database provides an automatic eviction strategy. If an execution plan of an SQL query has been used multiple times but the execution performance is not as expected, OceanBase Database will evict this execution plan and generate a new one.
Internet SQL queries are relatively simple and can be optimized at the business layer. This is not the focus of my presentation today. Next, let's see what SQL queries are like when OceanBase Database serves external customers such as insurance and telecom operator customers.
03. Speed up TP SQL queries in conventional business systems
Multi-table (outer) joins: the join order is essential
The first scenario I want to share is a join scenario. In Internet scenarios, SQL queries are usually manually restricted to single-table queries. In most industrial business systems, SQL queries are not restricted. In such a business system, an SQL query may join a large number of tables to get a small result set. I have encountered a complex scenario where an SQL query joins 17 tables. To improve the performance of such a multi-table outer join, selecting an appropriate index is far from enough. An appropriate join order is also a must.
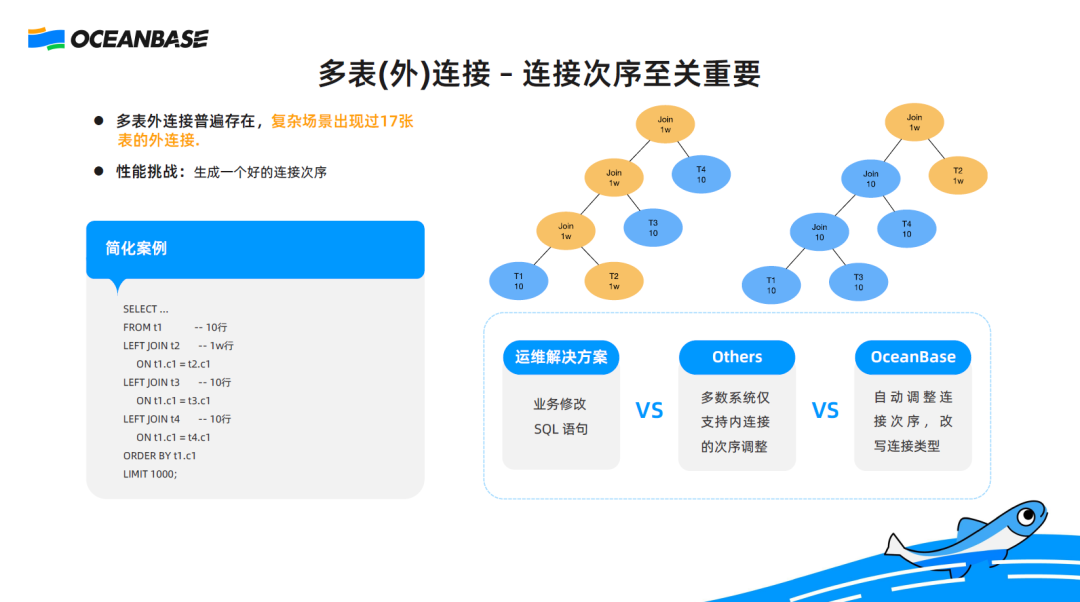
What is an appropriate join order?
In the example shown in the preceding figure, four tables T1, T2, T3, and T4 are joined. Among them, T2 is a large table and others are small tables. According to the join order specified in the query, T1 is joined with T2 first and then with T3 and T4. Three of the joins are performed between a small table and a large table, resulting in a high overhead. To simplify the join query, allow T1 to join with the small tables first and then with the large table T2 to achieve higher performance.
From the O&M side, the SQL query needs to be rewritten to manually adjust the write sequence of the outer join. It is difficult to rewrite the query from the business side because you have to determine which are large tables, which joins need to be moved backward, and which joins need to be moved forward. The whole process is complex, let alone that 17 tables are involved.
Can hints be used to enable the optimizer to generate such an execution plan with a more appropriate join order? It is uncertain. Many database systems support changing the order of inner joins but do not support such change for outer joins. This is because the behavior of outer joins is more complex, making them unqualified for order change in many scenarios. The optimizers of many databases are incapable of generating an execution plan shown on the right side of the preceding figure, even though hints are used to instruct the optimizers to do so.
OceanBase Database provides a complete set of join enumeration algorithms for adjusting the join order of inner joins and outer joins. It can automatically adjust the join order of outer joins, anti-joins, and semi-joins, or convert an outer join into an inner join or anti-join.
Ubiquitous subqueries
The second scenario is of subqueries, which are interesting. Business personnel like to write subqueries because their semantics are intuitive.

In external business systems, the usage mode of subqueries is more complex, for example, subqueries appear in unusual positions. Subqueries commonly appear in a FROM or WHERE clause. However, in Case 1 in the preceding figure, a subquery is used as the right operand in an assignment. In other words, the value of the left operand equals the result of the subquery. In Case 2, a subquery is used in a WHERE clause. It is not directly used as the root predicate but nested in an OR condition. If it is a root predicate, the EXISTS subquery will be converted into a semi-join for optimization in many databases. Since it is nested in an OR condition in this case, it cannot be optimized. Case 3 is more complex. Many subqueries are used in projected items. It is simplified but still has six subqueries.
What can the business side do to address the issue of slow queries?
The answer is also to rewrite the queries. Generally, the semantics of a subquery are similar to those of a join, so a subquery can be rewritten into a join. However, it is difficult for business personnel to correctly rewrite a subquery into a join because the two still have slight differences in semantics. An error may easily occur.
The rewrite module of OceanBase Database provides a wide range of subquery optimization strategies. It can rewrite any subquery that is not nested in a deep structure into a join, which can then be optimized by using different join enumeration algorithms.
Another quite interesting point of Case 3 is that the S1, S2, and S3 subqueries are similar in structure. They read the same table by using the same WHERE condition. The only difference is the function used for calculating the projected item. OceanBase Database can rewrite these subqueries into a join to combine the three subqueries as one to reduce the calculations by 2/3, thereby achieving high performance.
04. Speed up AP SQL queries
As OceanBase Database is constantly optimized to accommodate different TP scenarios, we have accumulated a lot of experience in optimizing and executing TP queries. As for the kernel, AP and TP have no substantial differences. For example, multi-table joins in TP scenarios also appear in AP scenarios, and join enumeration for optimizing multi-table joins in TP scenarios is also applicable to AP scenarios. Based on our accumulated experience, we can now probe and practice the optimization in AP scenarios.
Here are the topics we are going to talk about next:
- What are SQL queries like in AP scenarios?
- What are the challenges?
- What targeted optimizations have we made for AP scenarios?
Data skew and load skew: advocate collaboration and avoid slacking off
I want to share with you a typical AP scenario.
What are the characteristics of an AP SQL query? An AP SQL query usually involves a large amount of data to read and massive calculations. The most intuitive solution is to use multiple threads for parallel execution. If one thread needs 1 hour to execute the query, can 10 threads take only 6 minutes to execute the query? If each thread does their own job, multi-thread parallel execution can indeed achieve linear efficiency. However, this is impossible in practice. In the case of data skew or load skew, if only one thread is fully devoted and the other nine threads slack off, it will still take 1 hour to execute the query.
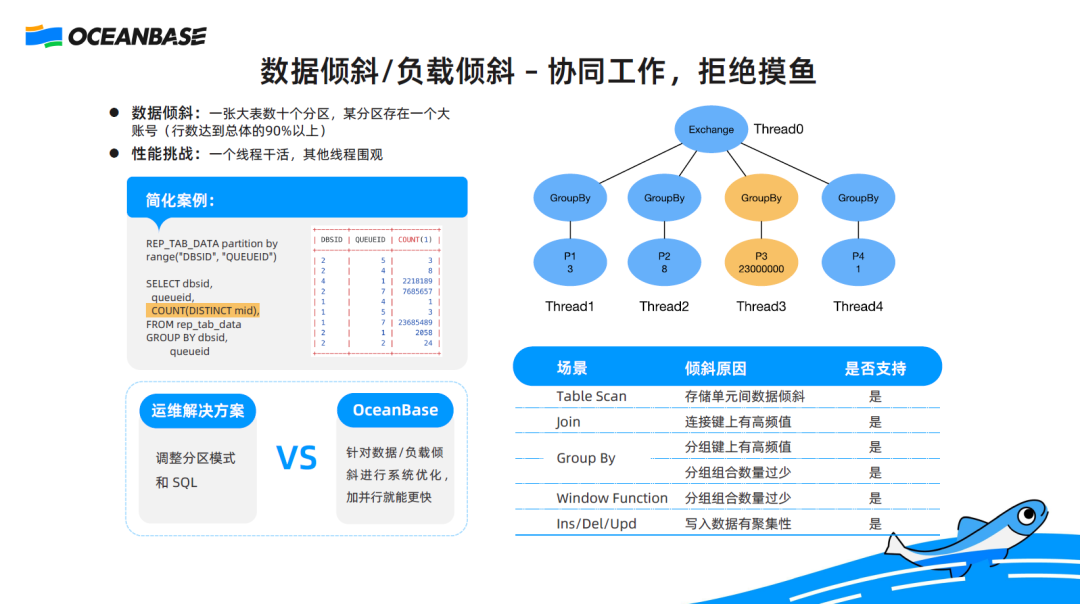
Here is an actual case of data skew in a telecom operator. This is a large table with dozens of partitions. A large account that owns 90% of the total data is located in a single partition. Here is the result set, in which a row contains more than 23 million records. To measure the number of distinct values in a specific field of each partition, I can use multiple threads, with each thread calculating the results in specific partitions, and then summarize the results. For partitions with small amounts of data, the threads can easily complete the calculations and report the results. The thread responsible for the partition with a large amount of data needs to take a long time in calculations. Other threads have to wait for this thread to complete calculations. In such a scenario, parallel execution cannot gain expected benefits because some threads slack off due to unbalanced load.
To resolve this issue from the O&M perspective, we can adjust the partitioning mode and rewrite the query, which is theoretically feasible. However, the specific implementation method varies based on scenarios, making this strategy infeasible. To effectively improve the query performance, we need to optimize the parallel execution algorithm in the kernel for data skew and load skew scenarios, so as to evenly distribute fine-grained calculations to each thread to leverage the capabilities of each thread.
OceanBase Database is also optimized for scenarios such as table scan, joins, window function-based calculations, as well as data skew and load skew after parallel execution of data add, delete, and modify operations. After that, more threads can be added for parallel execution to accelerate such calculation tasks.
Large table aggregation: a smart execution engine
The following figure shows a large table aggregation scenario, which is common in business. For example, we usually need to scan a large table and aggregate the data to report to the boss on today's performance.
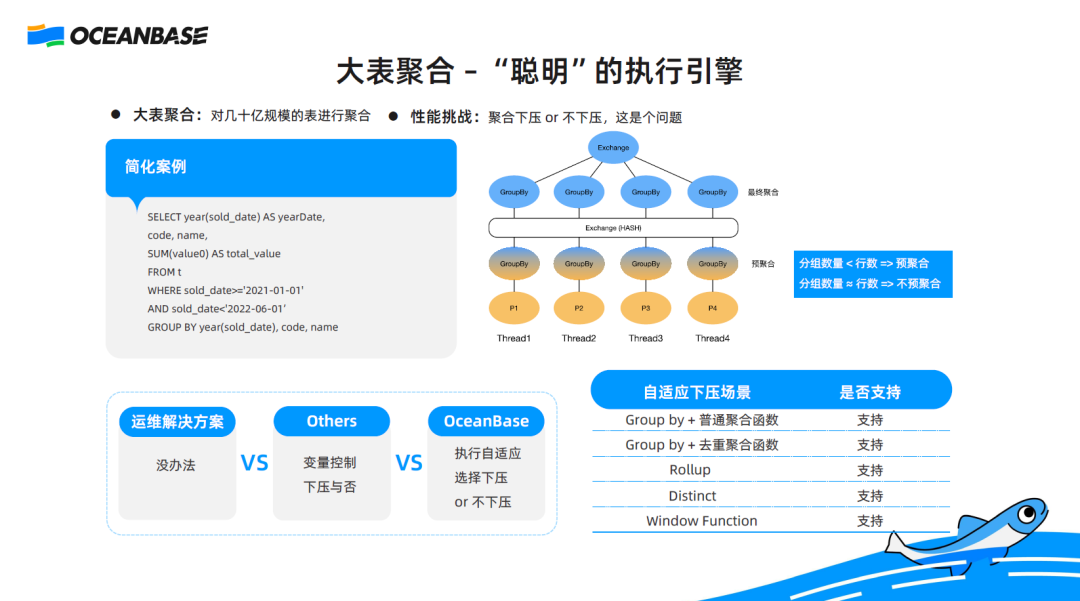
Generally, in a large table aggregation scenario, the table contains a huge amount of data. A common optimization method is pre-aggregation. Specifically, the system splits the data in the large table into multiple pieces and arranges different threads to group and aggregate the data to obtain partial aggregation results. Then, the threads exchange their data and hand over data in the same group to a specific thread. The threads summarize the data to obtain and report the final results. This is a typical optimization method.
What are the benefits? Assume that a large table contains 1 billion rows and that the data can be divided into 100 groups. Theoretically, the initial grouping and aggregation results of each thread will not exceed 100 rows, and the cost of summarizing the 100 groups will not be high. Therefore, this optimization method is commonly used in many database systems. However, this optimization method still has a drawback. If most data is not duplicate, grouping is not effective. For example, 1 billion rows may only change to 0.9 billion rows after grouping. In this scenario, if grouping is performed for optimization, the performance may be compromised.
What can we do?
On the O&M side, we can choose whether to instruct the optimizer to perform pushdown.
On the kernel side, the optimizer automatically determines whether to perform optimization based on statistics. This practice is common but not very effective. In a typical data skew scenario, pushdown may be required by large accounts but not by small accounts. But the preceding strategy is global, that is, the optimizer will perform pushdown for all or none of the accounts.
To resolve this issue, OceanBase Database does not allow the optimizer to make a decision on pushdown, but makes the executor smarter. OceanBase Database allows the executor to determine whether to perform pre-aggregation based on the actual situation during calculations in all scenarios such as grouping, deduplication, and window function-based calculations.
The next scenario is about batch statement execution.
Batch statement execution in an AP task: reads and writes in parallel
In most scenarios, an AP task contains more than one SQL statement. The first statement operates data and generates a result set, which is a temporary table, for the second statement. The second statement calculates and analyzes the data in the temporary result set and generates another temporary result set for the third statement. The third statement reads data from the second temporary result set, aggregates the data for analysis, and writes the analysis results to the final result set.
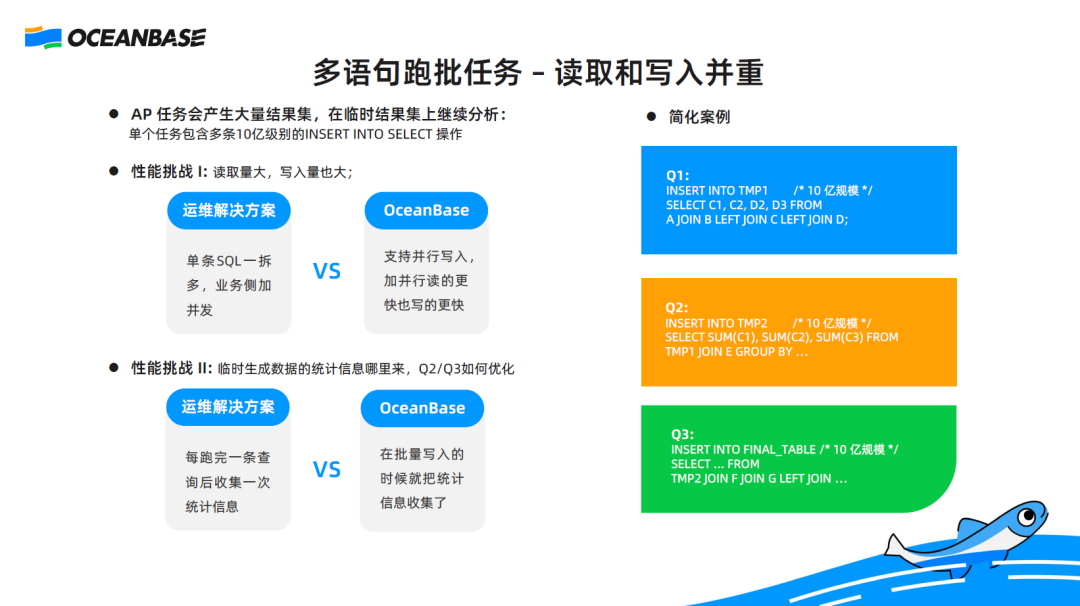
The preceding figure shows a simplified case that involves three queries: Q1, Q2, and Q3. The first challenge is that a huge amount of data is operated during the entire process. Large amounts of data is read, calculated, and written.
The second challenge is about statistics. The tables that Q1 depends on have statistics. Therefore, an appropriate execution plan can be selected for this query based on statistics. Q2 and Q3 need to use the temporary table generated by its previous query. A temporary table has no statistics. As a result, an inappropriate execution plan with low performance will be probably generated for Q2 and Q3 due to the absence of statistics on temporary tables TMP2 and TMP3.
To cope with the first challenge, OceanBase Database supports parallel write since V3.x. Multiple threads can write data to the database in parallel.
For the second challenge, a solution from the O&M perspective is to add statements for statistics collection in a batch execution task. However, this is unimaginable for a large table. Statistics collection is time-consuming and may increase the total execution time of the task. OceanBase Database V4.x supports online statistics collection. In this case, statistics collection starts as early as when Q1 inserts data into TMP1. After data is successfully inserted, statistics on TMP1 have been collected. Then, Q2 can be optimized based on the statistics. Similarly, statistics on TMP2 starts when Q2 inserts data into TMP2.
The last scenario is not an actual business scenario but an insight into the complexity of optimization from the kernel perspective. Therefore, it will be a little abstract.
Complexity in distributed and parallel queries
In some AP tasks, tables are usually large partitioned tables on multiple servers, and parallel execution is enabled, making the queries distributed and parallel ones. In this case, the optimization is not about optimizing serial plans in a standalone database but parallel plans in a distributed scenario. The difference is brought by data partitioning. Partitioning means an explosive increase in the number of execution plans.
For example, 10 execution plans are generated in a serial scenario. However in a distributed scenario, 100 execution plans may be generated considering parallel execution. It is difficult to select the best one among 100 plans. In many databases or conventional research, a compromise strategy will be used for optimization in such a scenario. Specifically, the system will generate the optimal serial plan based on the assumption that all tables are non-partitioned tables located on the same server, and then convert the serial plan into a distributed and parallel plan.
If we do so, what will happen?
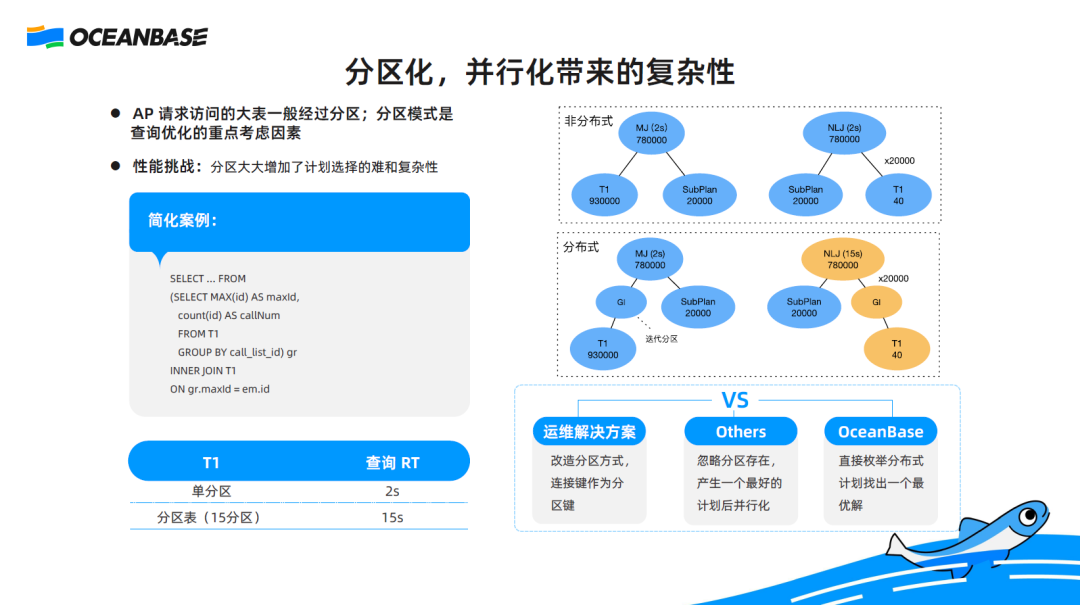
Let's see an actual case in a banking business scenario. In a two-table join, the referenced tables are both T1 and a subquery is used for grouping and aggregation for T1. If T1 is a non-partitioned table, the query performance is stable, with a response time (RT) of 2s. If T1 is a partitioned table, slow queries with an RT of 15s will occasionally occur. Why is that?
Analytics show that in a serial scenario (the first chart on the right), the two optimal execution plans respectively perform a merge join or nested loop join on the two tables. The performance of the two plans is very close, with an RT of about 2s. The performance of the merge join is slightly higher. After T1 is partitioned, a partition-level iteration will be incorporated into execution plans. Then, the RT of the merge join is still about 2s. For the nested loop join, the number of executions of the right branch is subject to the number of rows in the left-side table. Since the left-side table in the join contains 20,000 rows, data in the right-side table needs to be calculated for 20,000 times. This means the partition-level iteration is amplified by 20,000 times, increasing the RT to 15s.
We find that conventional optimization is not suitable for distributed scenarios. OceanBase Database V4.x provides a new distributed plan enumeration mechanism. The optimizer will not select the optimal serial plan, but generate all possible distributed execution plans and select the best one for the executor.
05. Summary
The development of the SQL engine is accompanied by business development. The optimization and execution capabilities of the SQL engine evolve as the SQL mode of business systems changes.
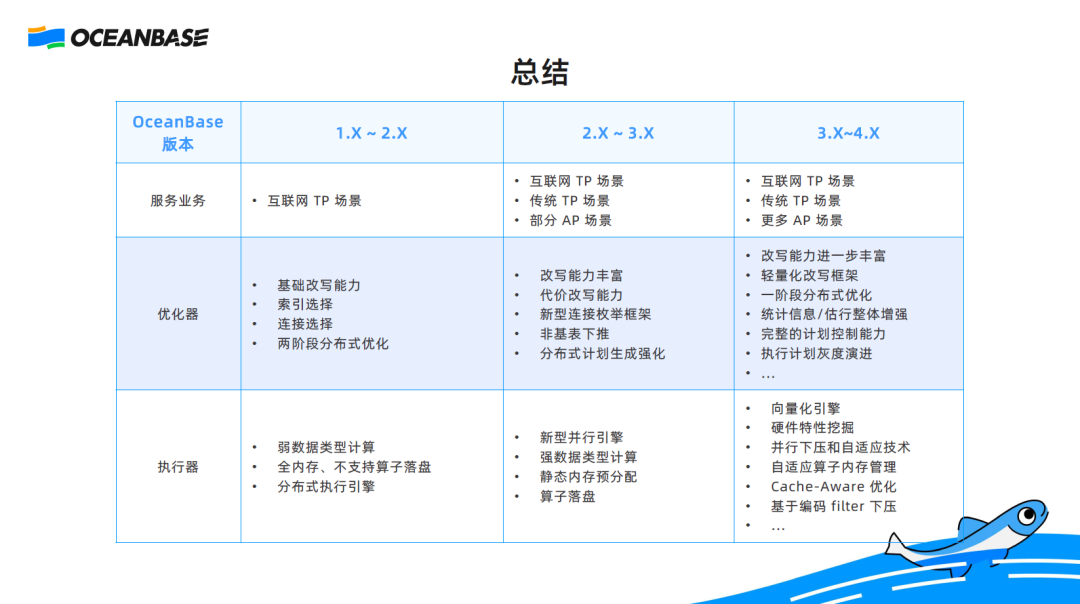
OceanBase Database V1.x and V2.x are mainly intended for Internet TP scenarios. In such scenarios, the optimizer focuses on index selection or simple join enumeration, and the executor focuses on executing queries instead of speeding up queries.
OceanBase Database V2.x and V3.x start to serve more conventional TP scenarios, where the optimizer needs to have strong join enumeration and query rewrite capabilities, and the executor needs to provide higher performance and requires new execution strategies.
In OceanBase Database V3.x and V4.x, the optimizer needs to enhance the optimization capabilities in AP scenarios while selecting a more appropriate execution plan to ensure stable performance in TP scenarios. To do so, OceanBase Database provides features, such as grayscale evolution of execution plans and more powerful hints, to enable business personnel to better control execution plans generated by the optimizer. For the execution engine, OceanBase Database provides features such as vectorized optimization, hardware feature mining, parallel execution pushdown, and adaptation technologies.