Mastering Parallel Execution in OceanBase Database: Part 1 - Introduction
Message from the Author:
This is a long-expected systematic guide on parallel execution (PX).
Since 2019, parallel execution has been widely implemented in various scenarios, playing an increasingly more important role.
This guide is here to help business teams master the parallel execution feature.
Parallel execution enables OceanBase Database to execute an SQL statement using multiple CPU cores and I/O threads. This article introduces how parallel execution works, as well as how to control, manage, and monitor parallel execution in OceanBase Database.
This is the first article of a seven-part series on parallel execution.
Part 1
Part 2
Part 3
Concurrency Control and Queuing
Part 4
Part 5
Part 6
Troubleshooting and Tuning Tips
Part 7
1 Introduction
Parallel execution splits a query task into multiple subtasks and allows them to run on multiple processors in parallel to improve the execution efficiency of the query task. In modern computer systems, multi-core processors, multithreading, and high-speed network connections are widely used, which makes parallel execution an efficient query technology.
This technology significantly reduces the response time of compute-intensive large queries, and comes in handy in fields such as batch data import/export and quick index table creation. It is widely applied in business scenarios such as offline data warehouses, real-time reports, and online big data analytics.
Parallel execution is well suited for the following scenarios:
- Scanning and joining of large tables, and sorting or aggregation of a large amount of data
- DDL operations on large tables, such as changing the primary key or column type and creating indexes
- Table creation based on existing big data, such as creating a table by using the
CREATE TABLE AS SELECTstatement - Batch data insertion, deletion, and updates
In this article, you will learn about:
-
Scenarios where parallel execution is applicable
-
Scenarios where parallel execution is inapplicable
-
Hardware requirements
-
Technical mechanism of parallel execution
-
Worker threads of parallel execution
-
Performance optimization through load balancing
1.1 Scenarios Where Parallel Execution Is Applicable
Parallel execution makes full use of multiple CPU cores and I/O resources to reduce the SQL execution time.
Parallel execution outperforms serial execution in the following circumstances:
- A large amount of data to access
- Low SQL concurrency
- A need for low latency
- Sufficient hardware resources
Parallel execution uses multiple processors to concurrently handle the same task. This can improve the system performance if your system has the following characteristics:
- Symmetric multiprocessing (SMP) system and cluster
- Sufficient I/O bandwidth
- Enough memory resources for memory-intensive operations such as sorting and hash table creation
- Appropriate system load or system load with peak-valley characteristics, such as a system load that remains below 30%
Otherwise, parallel execution delivers little improvement in performance. It results in poor performance in a system with a high load, small memory size, or insufficient I/O bandwidth.
In addition to analytical systems such as offline data warehousing, real-time report, and online big data analytics systems, parallel execution can also be used to accelerate DDL operations and batch data processing in the online transaction processing (OLTP) field. However, parallel execution is inapplicable to general SELECT and DML statements in an OLTP system.
1.2 Scenarios Where Parallel Execution Is Inapplicable
In serial execution, a single thread is used to execute database operations. Serial execution outperforms parallel execution in the following circumstances:
-
A small amount of data to access
-
High concurrency
-
A query execution time less than 100 ms
Parallel execution is inapplicable in the following scenarios:
-
Typical SQL queries in the system are executed within milliseconds. A parallel query has a millisecond-level scheduling overhead. For a short query, the benefit of parallel execution is completely offset by the scheduling overhead.
-
The system load is high. Parallel execution is designed to make full use of idle system resources. For a system with a high load, parallel execution may fail to bring extra benefits but compromise the overall system performance.
1.3 Hardware Requirements
Parallel execution does not have special requirements on the hardware. However, the number of CPU cores, memory size, storage I/O performance, or network bandwidth can become a bottleneck that affects the parallel execution performance.
1.4 Technical Mechanism of Parallel Execution
Parallel execution splits an SQL query task into multiple subtasks and schedules these subtasks to multiple processors.
This section covers the following content:
-
Parallel execution of SQL statements
-
Producer-consumer pipeline model
-
Granules of parallel execution
-
Data distribution methods between the producer and the consumer
-
Data transmission mechanism between the producer and the consumer
1.4.1 Parallel Execution of SQL Statements
When a parallel execution plan is generated for an SQL query, the query is executed in the following steps:
-
The main thread, which is responsible for receiving and parsing SQL queries, allocates the worker threads required for parallel execution in advance. These worker threads may come from multiple servers in the cluster.
-
The main thread enables the PX coordinator.
-
The PX coordinator parses the execution plan into multiple steps and schedules the steps from bottom up. Each operation is designed to be eligible for parallel execution.
-
After all operations are executed in parallel, the PX coordinator receives the calculation results and transfers the results to the upper-layer operator (such as the Aggregate operator) for serial execution of operations ineligible for parallel execution, such as the final SUM operation.
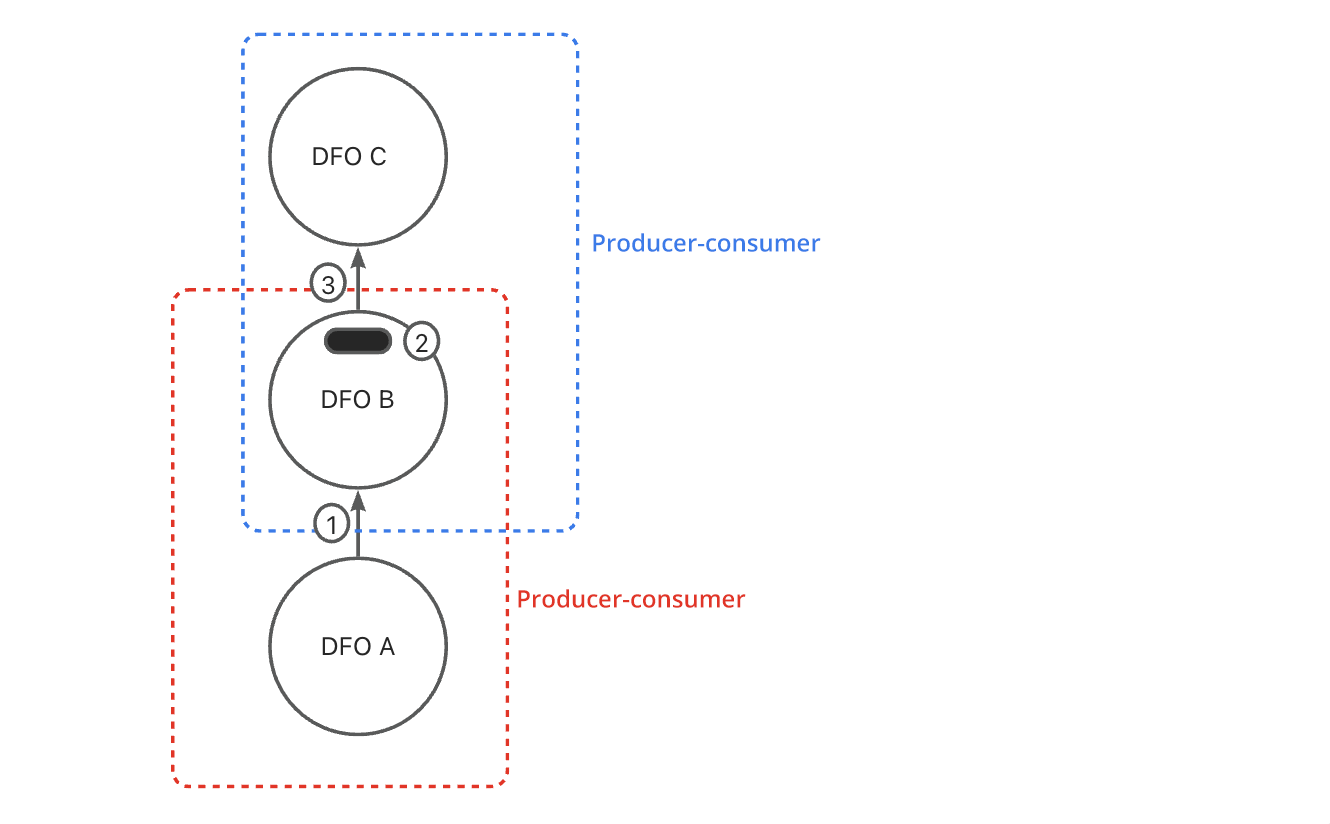
1.4.2 Producer-consumer Pipeline Model
The producer-consumer model is used for pipelined execution. The PX coordinator parses the execution plan into multiple steps. Each step is called a data flow operation (DFO).
Generally, the PX coordinator starts two DFOs at the same time. The two DFOs are connected in producer-consumer mode for inter-DFO parallel execution. Each DFO is executed by a group of threads. This is called intra-DFO parallel execution. The number of threads used for a DFO is called the degree of parallelism (DOP).
A consumer DFO in a phase will become a producer DFO in the next phase. Under the coordination by the PX coordinator, the consumer DFO and producer DFO are started at the same time.
As shown in the following figure:
-
The data generated by DFO A is transmitted in real time to DFO B for calculation.
-
After calculation, DFO B stores the data in the current thread and waits for the upper-layer DFO C to start.
-
When DFO B is notified that DFO C has been started, it switches to the producer role and starts to transmit data to DFO C. After DFO C receives the data, it starts calculation.
Here is a sample query:
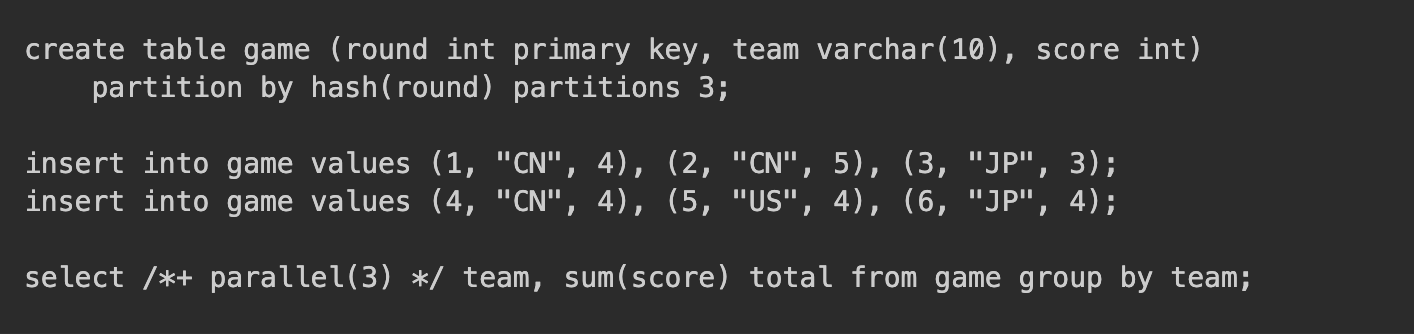
The execution plan for the query statement is as follows:
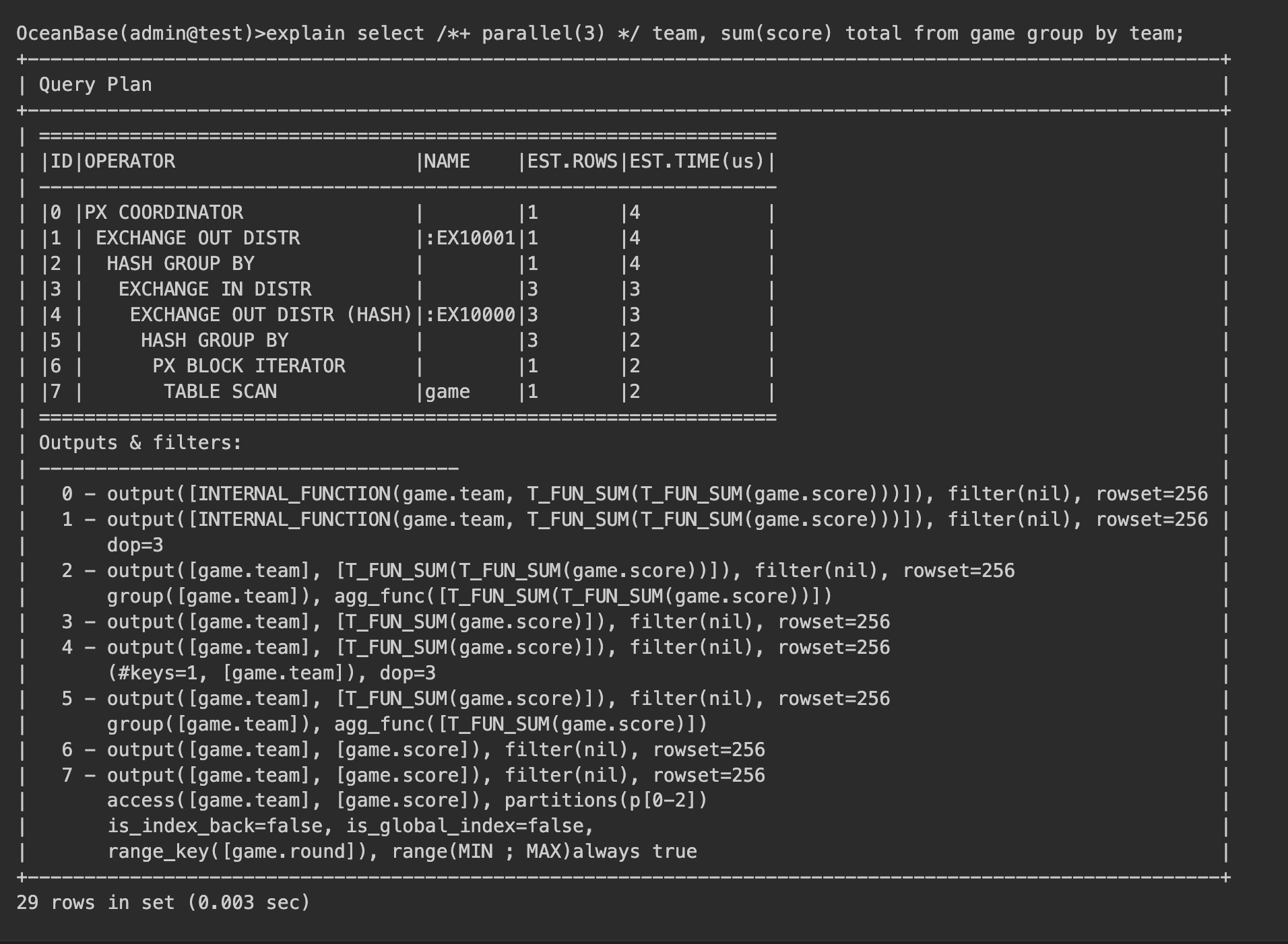
The execution plan of the SELECT statement first performs a full-table scan on the game table to group the data by team, and then calculates the total score of each team. The following figure demonstrates the query execution process.
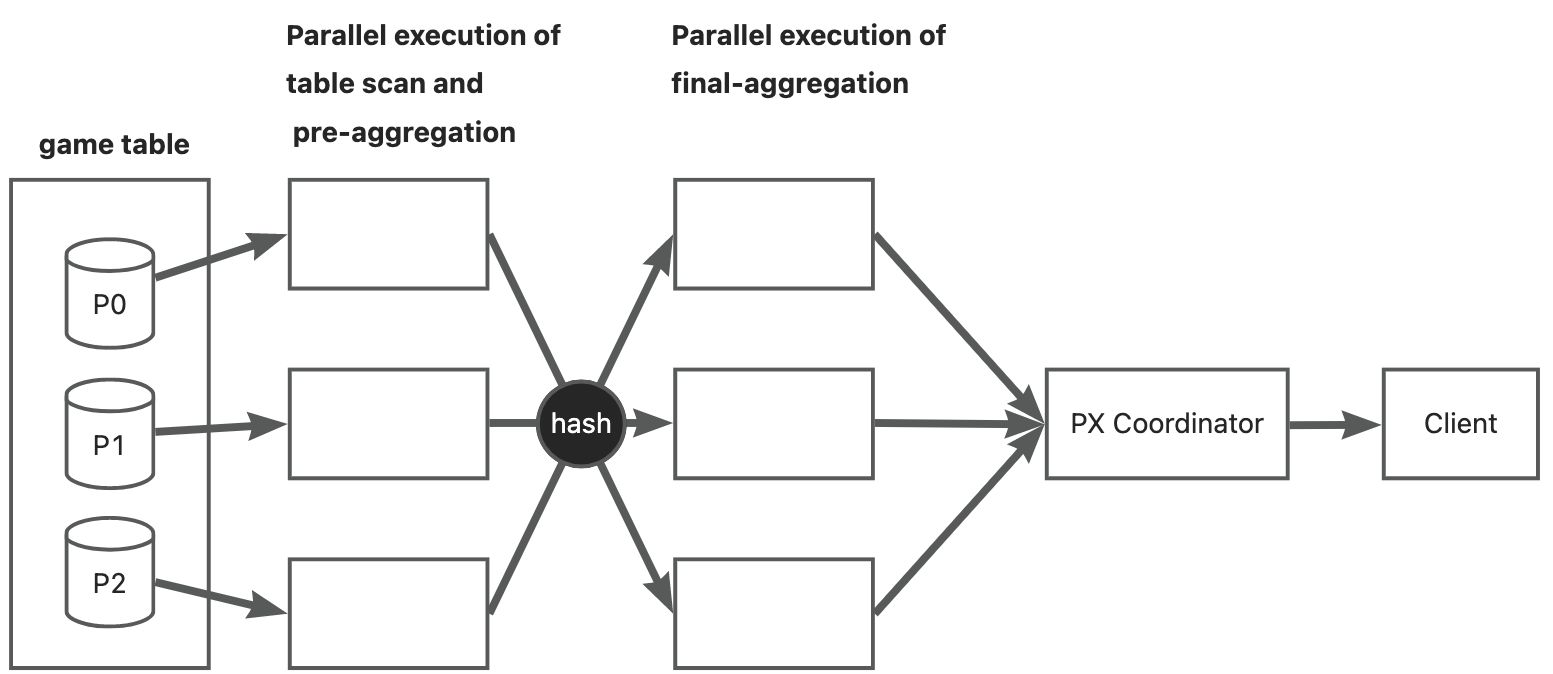
As shown in the preceding figure, six threads are used for the query.
- Step 1: The first three threads are responsible for scanning the
gametable. They separately pre-aggregate thegame.teamdata. - Step 2: The rest three threads are responsible for the final aggregation of the pre-aggregated data.
- Step 3: The PX coordinator returns the final aggregation results to the client.
The data sent from Step 1 to Step 2 is hashed by using the game.team field to determine the thread to which the pre-aggregated data is to be sent.
1.4.3 Granules of Parallel Execution
Granule is the basic working unit for parallel data scan. OceanBase Database divides a table scan task into multiple granules. Each granule describes a part of the table scan task. As a granule cannot span across table partitions, it is confined to one partition.
Two types of granules are supported:
- Partition granule
A partition granule describes a whole partition. Therefore, the number of partition granules of a scan task is equal to the number of partitions involved in the scan task. Here, a partition can be one in a primary table or an index table.
Partition granules are often used in partition-wise joins, where the partition granules ensure that the corresponding partitions of two tables are processed by the same worker thread.
- Block granule
A block granule describes a segment of continuous data in a partition. Generally, block granules are used to divide data in a data scan scenario. Each partition is divided into multiple blocks. The blocks are concatenated based on specific rules to form a task queue, which will be consumed by PX worker threads.
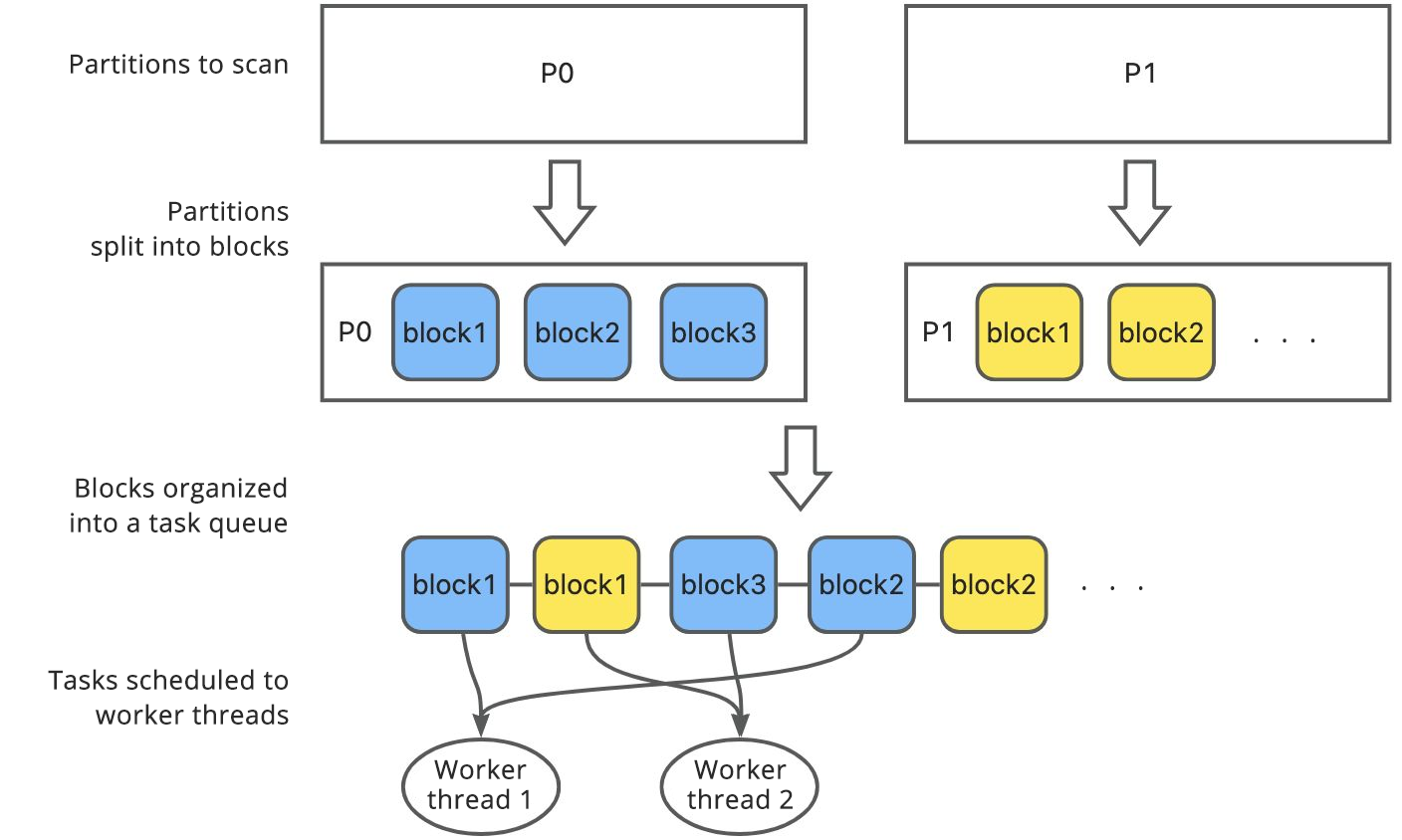
Given a DOP, the optimizer will automatically choose to divide data into partition granules or block granules for balancing of scan tasks. If the optimizer chooses block granules, the parallel execution framework divides data into blocks during running and ensures that each block is of an appropriate size, which is not too large or small. An excessively large block size can lead to data skew, where some threads cannot be fully used. An excessively small size can lead to frequent scans, which increase the switching overhead.
After partition granules are divided, each granule corresponds to a scan task. The TABLE SCAN operator handles the scan tasks one by one.
1.4.4 Data Distribution Methods between the Producer and the Consumer
A data distribution method is the method used by a group of PX worker threads (producers) to send data to another group of PX worker threads (consumers). The optimizer selects a data redistribution method based on a series of optimization strategies to achieve the optimal performance.
General data distribution methods in parallel execution include:
- Hash distribution
In hash distribution, the producer hashes the data based on the distribution key and obtains the modulus to determine the consumer worker thread to which the data is to be sent. In most cases, this method can evenly distribute data across multiple consumer worker threads.
- Pkey distribution
In pkey distribution, the producer determines through calculation the partition in the target table to which a data row belongs and sends the row data to a consumer thread responsible for this partition.
Pkey distribution is commonly used in partial partition-wise joins, where you can perform partition-wise joins between the consumer data and the producer data without the need to redistribute the consumer data. This method reduces network communication and improves performance.
- Pkey hash distribution
In pkey hash distribution, the producer first calculates the partition in the target table to which a data row belongs and hashes the data based on the distribution key to determine the consumer thread to which the data is to be sent.
Pkey hash distribution is commonly used in parallel DML scenarios where a partition can be concurrently updated by multiple threads. Pkey hash distribution can ensure that rows with identical values are processed by the same thread and that rows with different values are evenly distributed to multiple threads.
- Broadcast distribution
In broadcast distribution, the producer sends all data rows to each consumer thread so that each consumer thread has the full data of the producer.
Broadcast distribution is commonly used to copy data from small tables to all nodes involved in a join. Then, joins are executed locally to reduce network communication.
- Broadcast to host distribution
In broadcast to host distribution, the producer sends all rows to each consumer node so that each consumer node has the full data of the producer. Then, the consumer threads on each node process the data in a collaborative manner.
Broadcast to host distribution is commonly used in NESTED LOOP JOIN and SHARED HASH JOIN scenarios. In a NESTED LOOP JOIN scenario, each consumer thread obtains a part of the shared data as the driver data for the join operation on the target table. In a SHARED HASH JOIN scenario, the consumer threads jointly build a hash table based on the shared data. This avoids the situation where each consumer thread independently builds a hash table identical to that of others, thereby reducing the overhead.
- Range distribution
In range distribution, the producer divides data into ranges for different consumer threads to process.
Range distribution is commonly used in sorting scenarios. Each consumer thread only needs to sort the data allocated to it. This ensures that the data is globally ordered.
- Random distribution
In random distribution, the producer randomly scatters the data and sends the data to the consumer threads so that each consumer thread processes an almost equal amount of data, thereby achieving load balancing.
Random distribution is commonly used in multithreaded parallel UNION ALL scenarios, where data is scattered only for load balancing and the scattered data is not associated.
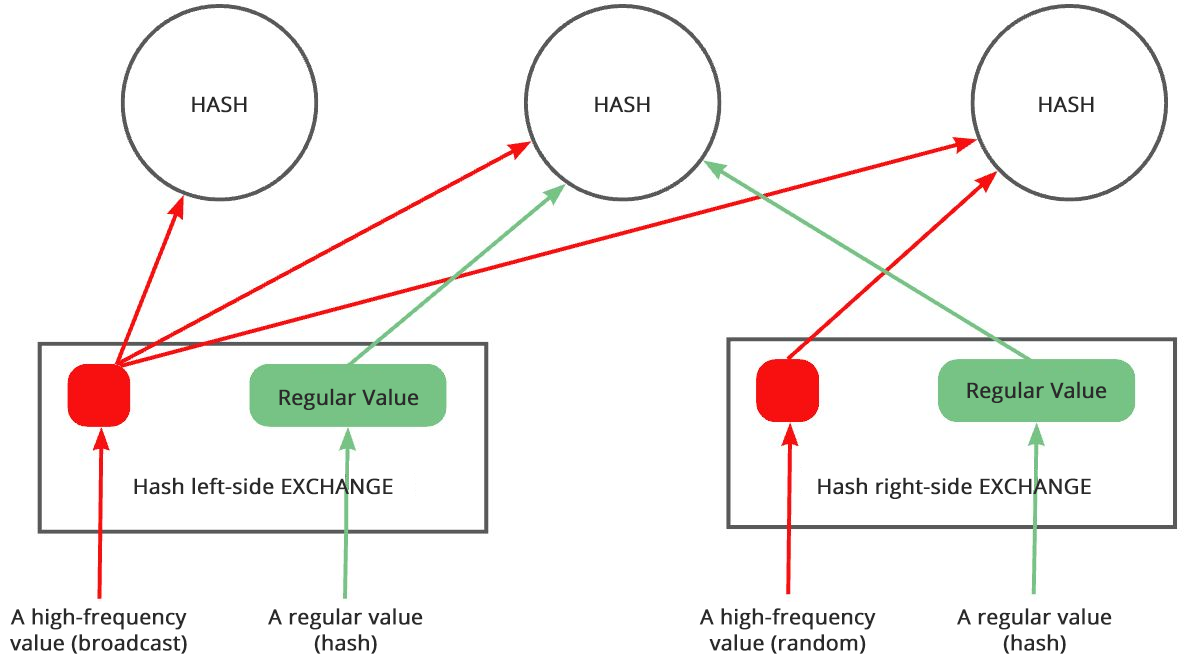
- Hybrid hash distribution
Hybrid hash distribution is an adaptive distribution method used in join operations. Based on collected statistics, OceanBase Database provides a group of parameters to define regular values and frequent values. In hybrid hash distribution, hash distribution is used for regular values on both sides of a join, broadcast distribution is used for frequent values on the left side, and random distribution is used for frequent values on the right side.
1.4.5 Data Transmission Mechanism between the Producer and the Consumer
The PX coordinator starts two DFOs at the same time. The two DFOs are connected in producer-consumer mode for inter-DFO parallel execution. A transmission network is required for transmitting data between the producer and the consumer.
For example, if the producer DFO uses two threads (DOP = 2) for data scan and the consumer DFO uses three threads (DOP = 3) for data aggregation, each producer thread creates three virtual links to the consumer threads. Totally six virtual links are created, as shown in the following figure.
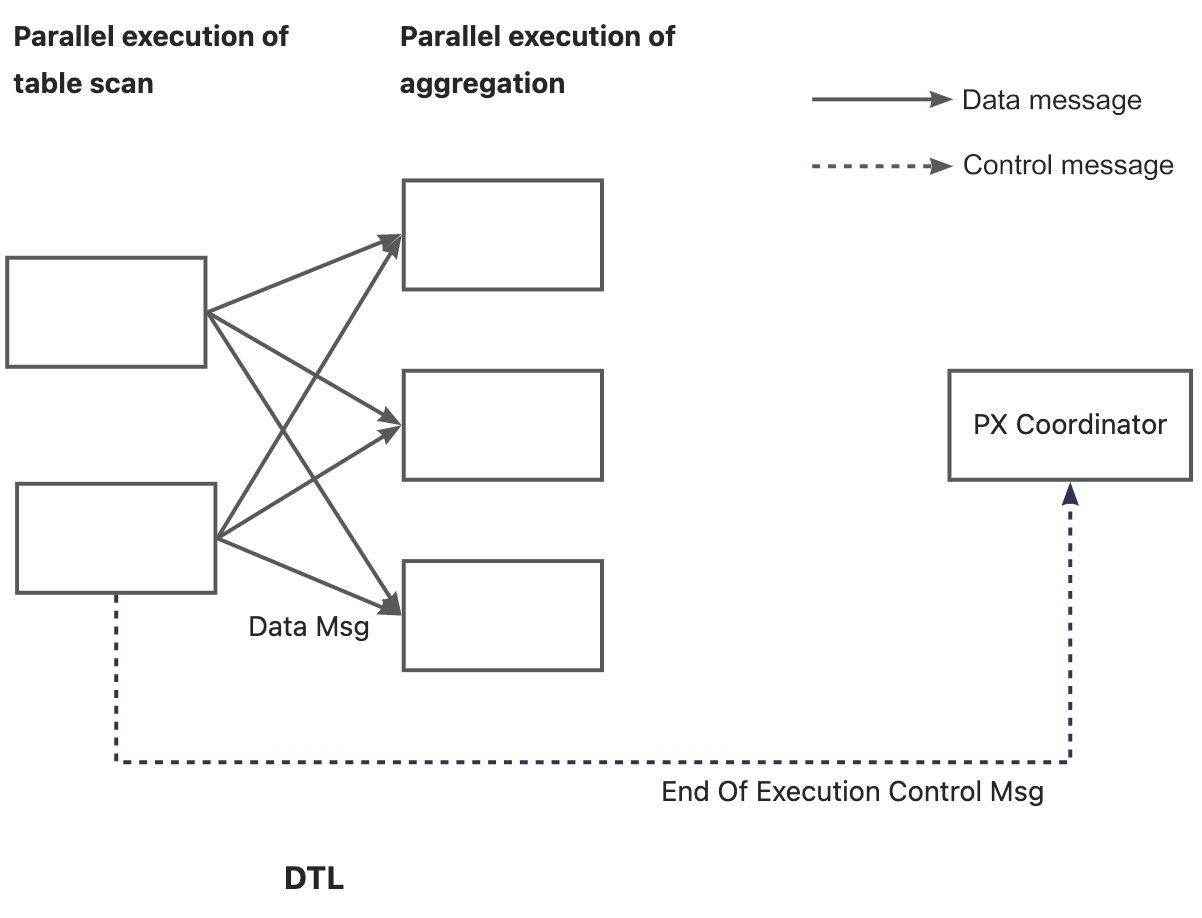
The virtual transmission network created between the producer and the consumer is called the data transfer layer (DTL). In the parallel execution framework of OceanBase Database, all control messages and data rows are sent and received over the DTL. Each worker thread can establish thousands of external virtual links, providing high scalability. The DTL also provides features such as data buffering, batch data sending, and automatic throttling.
If the two ends of a DTL link are on the same node, the DTL transfers messages through memory copy. If the two ends of a DTL link are on different nodes, the DTL transfers messages through network communication.
1.5 Worker Threads of Parallel Execution
A parallel query uses two types of threads: one main thread and multiple PX worker threads. The main thread uses the same thread pool as threads for normal transaction processing (TP) queries. PX worker threads come from a dedicated thread pool.
OceanBase Database uses a dedicated thread pool model to allocate PX worker threads. Each tenant has a dedicated PX thread pool on each of its nodes. All PX worker threads are allocated from this thread pool.
Before the PX coordinator schedules each DFO, it requests threads from the thread pool. After a DFO is executed, the threads for the DFO are immediately released.
The initial size of the thread pool is 0. It can be dynamically scaled out without an upper limit. To avoid excessive idle threads, the thread pool introduces the automatic reclamation mechanism. For any thread:
- If the thread is left idle for more than 10 minutes and the number of remaining threads in the thread pool exceeds 8, the thread will be reclaimed and destroyed.
- If the thread is left idle for more than 60 minutes, it will be destroyed unconditionally.
Theoretically, the thread pool has no upper limit in size. However, the following mechanisms actually contribute to an upper limit:
-
Threads must be requested from the Admission module before parallel execution. Parallel execution can start only after threads are successfully requested. This mechanism can limit the number of parallel queries. For more information about the Admission module, see Mastering Parallel Execution in OceanBase Database: Part 3 - Concurrency Control and Queuing.
-
To process a query, N threads can be requested from the thread pool at a time, where N = Value of
MIN_CPUof the unit config for the resource units of the tenant × Value ofpx_workers_per_cpu_quota. At most N threads are allocated even if more than N threads are requested.px_workers_per_cpu_quotais a tenant-level parameter whose default value is10. Assume that the value ofMIN_CPUis4and the value ofpx_workers_per_cpu_quotais10, N = 4 × 10 = 40. In this case, if a DFO with a DOP of 100 requests 30 threads from Node A and 70 threads from Node B, the DFO can actually request 30 threads from Node A and 40 threads from Node B. Its actual DOP is 70.
1.6 Performance Optimization through Load Balancing
To achieve the optimal performance, allocate the same number of tasks to each worker thread as far as possible.
If data is divided based on block granules, the tasks are dynamically allocated to worker threads. This can minimize the imbalance in workloads. In other words, the workload of each worker thread does not significantly exceed those of others. If data is divided based on partition granules, you can optimize the performance by ensuring that the number of tasks is an integral multiple of the number of worker threads. This is very useful for partition-wise joins and parallel DML.
Assume that a table has 16 partitions and that the amount of data in each partition is almost the same. You can use 16 worker threads (DOP = 16) to finish the job with 1/16 of the time otherwise required, 5 worker threads to finish the job with 1/5 of the time otherwise required, or 2 threads to finish the job with 1/2 the time otherwise required.
However, if you use 15 worker threads to process the data of 16 partitions, the first thread will start to process the data of the 16th partition after it finishes processing the data of the first partition. Other threads will become idle after they finish processing the data of their respective allocated partition. If the amount of data in each partition is close, this configuration will result in poor performance. If the amount of data in each partition varies, the actual performance depends on the actual situation.
Similarly, assume that you use 6 threads to process the data of 16 partitions and that each partition has a close amount of data. Each thread will start to process the data of a second partition after it finishes processing the data of the first partition. However, only four threads will process the data of a third partition while the other two threads will become idle.
Given N partitions and P worker threads, you cannot simply calculate the time required for parallel execution by dividing N by P. You need to consider the situation where some threads may need to wait for other threads to complete data processing for the last partition. You can specify an appropriate DOP to minimize the imbalance in workloads and optimize the performance.