Handling Two Trading Scenarios with One OceanBase Cluster
"Making Technology Visible | The OceanBase Preacher Program" is a yearly technical writing contest hosted by OceanBase, and co-sponsored by Modb.pro, ITPUB, and CSDN, three major tech media platforms. Four rounds are organized to assess articles quarterly. Each year, we award the best writer, or preacher. This article, by Zhang Xiao, is among the most promising pieces of round 1.
Scenarios and Requirements
If you've ever traded stocks, you might know that daily trading doesn't settle in real time. Instead, everything gets collectively cleared at the end of the day. This approach reduces transaction costs, simplifies operations, improves fund efficiency, and ultimately lowers risk. But, during the clearing process, positions and balances of user accounts can change. This introduces data inaccuracies. Different brokerage firms handle this challenge differently. Some prevent user queries during clearing, while others provide pre-clearing data and only show final, correct data after clearing completes. The latter approach is becoming more and more popular.
The complexity doesn't stop at day-end clearing. Intra-day queries are extremely frequent too. Many brokerage firms are trying to ensure query data accuracy and real-time updates without disrupting trading activities. This requires minimal trading and query latencies and read/write splitting.
The scenarios boil down to two requirements.
1. Clearing data queries: When users query data before the day-end clearing, brokerage firms can provide pre-clearing data, and clearly indicate that clearing is in progress and that the data is subject to change.
2. Read/write splitting. Database requests for user trading and query operations are separated to prevent mutual interference, and fresh data is returned for queries.
Oh, and let's not forget the unspoken requirement: high availability across different geographical regions and Internet data centers (IDCs), regardless of the deployment mode. To meet all these requirements, a database must provide diverse features with very high performance.
Original Solution
When I worked at a multinational brokerage firm, we cooperated with the same core trading system supplier, and faced the same business scenarios. Our solution was an architecture based on Oracle Real Application Clusters (RAC) 11g, including a 4-node production RAC cluster, a 2-node disaster recovery RAC cluster deployed in the same region, and a remote 2-node disaster recovery RAC cluster. To support customer queries during clearing, we also deployed a dedicated 2-node RAC cluster with fewer resources in one-primary two-standby mode. The architecture looked roughly like this (network gateways and firewalls omitted for simplicity):
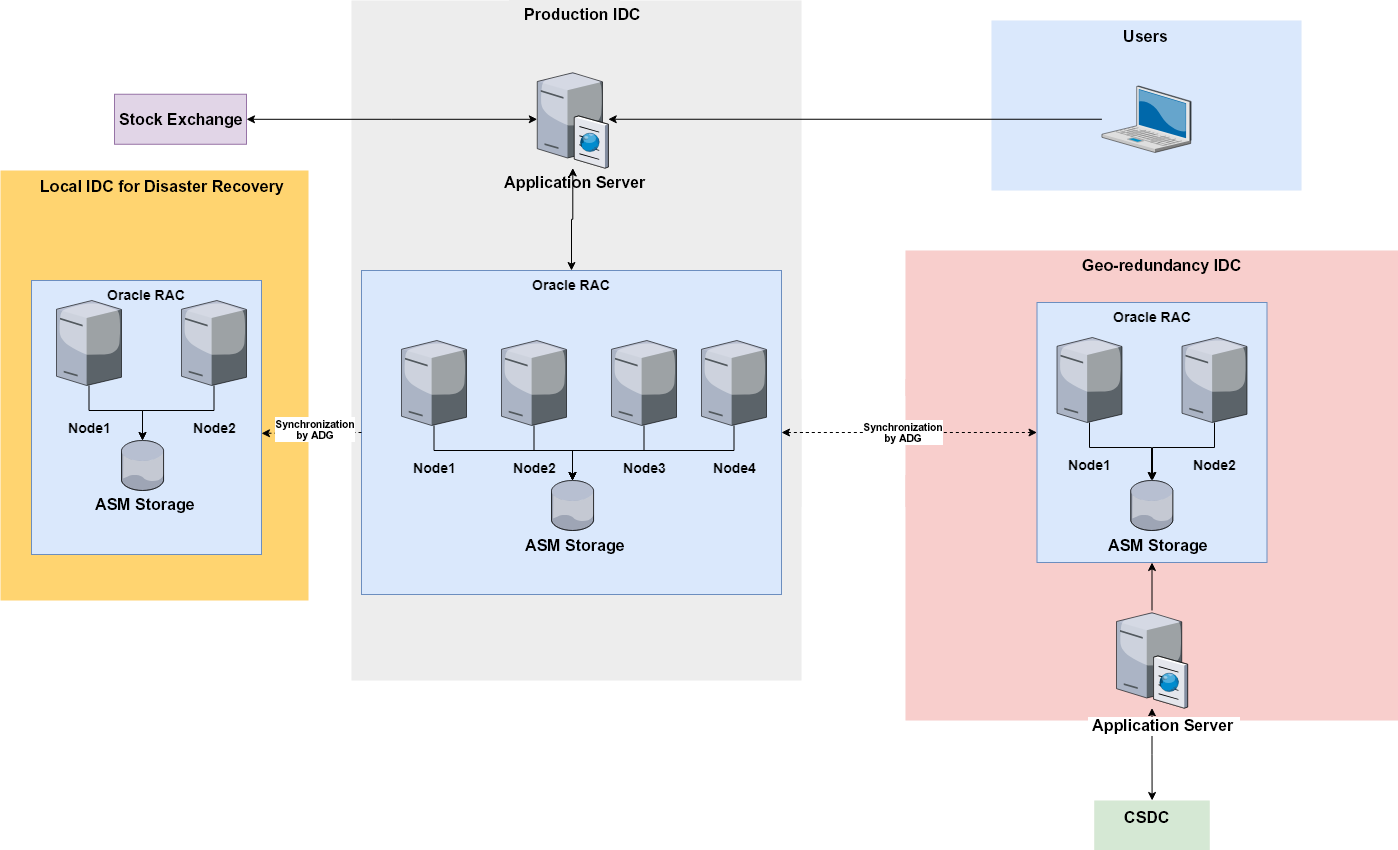
1. The production RAC cluster contained the primary trading database and the standby clearing database, and was connected to the remote RAC cluster by Advanced Data Guard (ADG) for bidirectional data synchronization. The primary trading database handled customers’ trading requests, while the standby clearing database not only served for disaster recovery, but also fetched clearing result data from the primary clearing database. Read/write splitting was achieved at the physical level: Two of the four nodes were dedicated to writing trading data and the other two were dedicated to handling data read queries.
2. Data was synchronized from the production RAC cluster to the disaster recovery RAC cluster in the same region through ADG.
3. The remote disaster recovery RAC cluster also contained two databases: the primary clearing database and the standby trading database. The primary clearing database retrieved data from the standby trading database, and completed day-end clearing with China Securities Depository and Clearing Corporation Limited (CSDC). The standby trading database also played a role in disaster recovery.
The trading and clearing databases were connected by DBlinks for data exchange, as shown in the following figure, with arrows indicating data flow directions but not the DBlink direction.
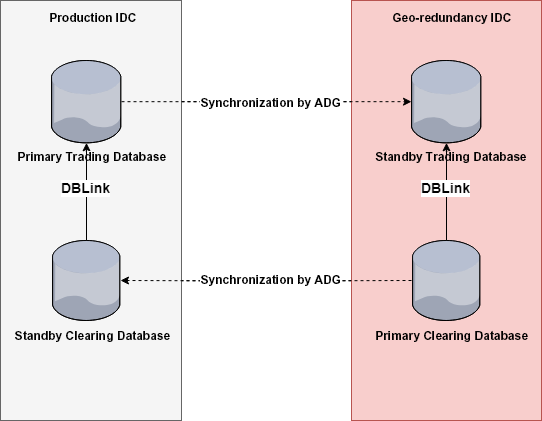
1. Before day-end clearing, data was synchronized by ADG from the production cluster to the disaster recovery cluster. The primary clearing database would directly fetch data from the standby trading database through a DBlink, where data was transferred between different disk groups managed by Oracle Automatic Storage Management (ASM) within the same IDC, without using a cross-city network.
2. After day-end clearing, likewise, data was synchronized by ADG from the disaster recovery cluster to the production cluster. The primary trading database would directly fetch data from the standby clearing database through a DBlink, where data was also transferred between different ASM disk groups without using a cross-city network.
The advantages of this solution were quite apparent.
1. Trading and clearing data was separated. This ensured that customers could query their positions and account information during both trading and clearing. And the clearing result was rapidly written to the trading databases.
2. Read/write splitting. The production RAC cluster consisted of four nodes, with two dedicated to trading and two to querying. This ensured zero interference of their computing resources.
3. High availability. RAC provided the high availability of instances. In addition, the architecture was deployed with three IDCs across two regions based on ADG, which also provided high availability. I believe that no one in this industry would argue about the reliability of RAC and ADG.
4. Data isolation. The trading and clearing databases were managed in different Oracle instances. Their permissions and memory resources were completely independent of each other.
However, the solution wasn't without noticeable drawbacks.
1. Usage costs. The entire solution used three Oracle RAC clusters, which incurred high software licensing and hardware costs.
2. Scalability. While we could dynamically add nodes to Oracle RAC clusters, the operational risks were considerable.
3. Hidden performance bottlenecks. Although we separated computing and storage resources, the storage bandwidth of the ASM service had limits, and the same ASM service was used for computing and storage during trading hours.
4. Resources waste. The disaster recovery RAC cluster in the same region as the production cluster undertook no other tasks, representing considerable resource waste.
An Alternative based on OceanBase Database
First and foremost, OceanBase Database is compatible with Oracle syntax, so we won't delve too deeply into that aspect. Our goal is to design an alternative solution that meets the requirements of the trading and clearing scenarios with high availability. As a former product manager, I would like to start with business needs.
Scenario 1: Customers can query data during clearing.
The solution based on Oracle 11g provided instance-level resource isolation. If you use Oracle 12c and later, you can deploy Pluggable Database (PDB) for resource isolation, which is achieved by the multitenancy feature in the case of OceanBase Database. In OceanBase Database, we can create two tenants.
Tenant A is dedicated to trading and querying, which involves highly frequent operations that are extremely sensitive to system latency. Therefore, Tenant A has a higher priority in resource allocation.
Tenant B is used for day-end clearing. It handles less frequent operations when Tenant A is not loaded, and has a lower resource allocation priority.
These two tenants are equivalent to the trading and clearing databases, achieving full isolation of resources and permissions. The tenants exchange data also by using a DBlink. In addition, OceanBase Database uses a similar authentication method, requiring a username and its password.
Scenario 2: Read/write splitting.
We first need to introduce several OceanBase components and features, starting with OceanBase Database Proxy (ODP).
ODP is a proxy server service dedicated for OceanBase Database. OceanBase Database stores replicas of user data on multiple OBServer nodes. When ODP receives an SQL statement from a user, ODP forwards the statement to the optimal OBServer node and returns the execution result to the user.
From the official documentation, one of ODP's critical purposes is forwarding SQL statements to the optimal OBServer node. As the first essential component for implementing read/write splitting, ODP separates requests at the statement level.
Furthermore, OceanBase Database supports weak-consistency reads - a feature we can leverage to obviate the need for SQL queries to read the latest data. By combining this with the multi-replica feature, OceanBase Database separately stores replicas for data writes and those for data reads. By configuring the obproxy_read_consistency and proxy_route_policy parameters, we can prioritize the use of follower replicas for user SQL queries.
However, it's important to note that data synchronization between replicas inevitably involves latency. Data queries also introduce latency, which is at the level of milliseconds according to the official documentation. Given the feedback of their users, such latency is generally acceptable. Of course, to meet the needs of institutional or high-frequency trading clients requiring extremely low latency, we can allocate dedicated resources to support strong-consistency reads.
Now, let’s talk about the regulatory requirements for geo-disaster recovery.
As someone who regularly consults regulatory requirements, I've observed a clear trend in recent years. Regulatory expectations for system availability are continuously increasing, gradually transitioning from the earlier three IDCs across two regions mode towards architectures with multiple active IDCs, which are precisely what OceanBase Database can do best as a cloud-native distributed system. We can create multiple zones to host physical IDCs at different locations, which is a proven strategy. Let me outline a basic plan for the deployment mode of three IDCs across two regions:
-
Zone 1 hosts the primary production IDC, and is connected to the Shanghai Stock Exchange (SSE) and the Shenzhen Stock Exchange (SZSE). It supports trading operations and customer queries, and serves as a disaster recovery center for CSDC.
-
Zone 2 is deployed in the same region as Zone 1. It is capable of handling the same business load as Zone 1. This way, this solution provides two active IDCs.
-
Zone 3 hosts the remote disaster recovery IDC. It is connected to CSDC and serves as a backup for Zone 1.
Benefits of the OceanBase-based Solution
Now, let me design a comprehensive substitute solution that meets all aforementioned three business needs. Here is the architecture.
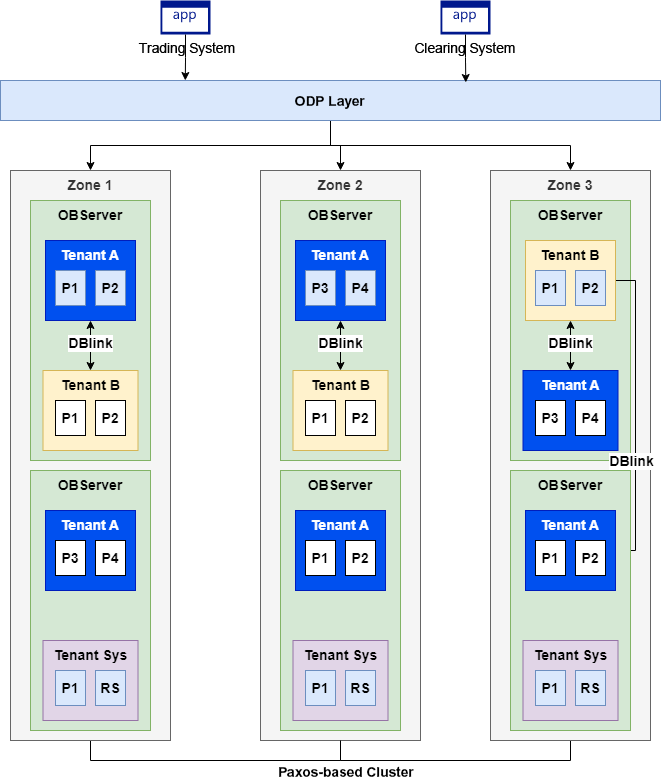
-
The ODP layer serves as the access point of business systems, provides load balancing capabilities, and forwards SQL requests.
-
Tenant A handles trading requests and data queries in place of the primary trading database.
-
Tenant B handles day-end clearing tasks in place of the primary clearing database. Still, the two tenants exchange data by using a DBLink.
-
Zone 1, replacing the primary production IDC, now hosts the active IDC 1. It stores the leader replicas P1 and P2 (blue) of Tenant A, follower replicas P3 and P4 (white) of Tenant A, and follower replicas of Tenant B.
-
Zone 2, replacing the disaster recovery IDC, now hosts the active IDC 2 in the same region. It stores the leader replicas P3 and P4 (in blue) of Tenant A, follower replicas P1 and P2 (in white) of Tenant A, and follower replicas of Tenant B.
-
Zone 3, replacing the remote disaster recovery IDC, maintains its original role. It stores the leader replicas P1 and P2 (in blue) of Tenant B, and follower replicas P1, P2, P3, and P4 (in white) of Tenant A.
During market hours, trading requests and queries are forwarded by ODP to the most appropriate OBServer nodes in Zone 1 or Zone 2, and operate directly on the leader replicas. All other queries are forwarded by ODP to the most appropriate OBServer nodes in Zone 1 or Zone 2, and read data directly from follower replicas. Note that reading follower replicas causes a slight latency.
Before clearing begins after market hours, Tenant B directly reads follower replicas of Tenant A in Zone 3. Since this data read occurs after market hours, latency is no longer a significant concern.
During the clearing hours, user queries are still forwarded to Tenant A in Zone 1 or Zone 2, and read data from follower replicas first because weak-consistency read is configured. This feature fulfills the need of allowing customers to query their positions during clearing.
After clearing is completed, Tenant A synchronizes the clearing results to the follower replicas of Tenant B in Zone 1 and Zone 2. The actual time difference depends on the bandwidth between remote and local IDCs. After the data synchronization, customers will read the post-clearing data.
As to high availability, both Tenant A and Tenant B have three replicas in three IDCs across two regions. If any IDC is down, the other two can continue to support read/write splitting and queries in clearing hours, though performance may not be guaranteed. If two IDCs experience downtime, the system ensures data integrity, but the performance of read/write splitting and queries in clearing hours may be compromised. In this case, we can add more nodes to help maintain service.
Compared to the Oracle-based solution, the OceanBase Database-based architecture has the following benefits and drawbacks.
Benefits:
1. Higher resource utilization. The new architecture boasts three active IDCs in different regions. No IDC is deployed purely for redundancy purposes, which leads to low resource idleness.
2. High availability. As long as no major issues occur simultaneously to all three IDCs, the service availability is ensured.
3. Automatic scaling. From my perspective, an OceanBase cluster has better scalability than an Oracle RAC cluster, because more OBServer nodes can be added responsively to eliminate resource bottlenecks.
4. Costs. More moderately priced hardware is used in this distributed cluster in place of higher-specification servers.
Drawbacks:
1. A longer learning curve. For me, the Oracle RAC architecture is simpler and more straightforward, while OceanBase Database involves ODP and multiple replicas, nodes, and zones. It requires a certain level of expertise to truly understand and comprehensively design the system.
2. Data latency. In the Oracle-based solution, read/write splitting relies on a series of computing nodes that are backed by the same ASM disk group. OceanBase Database, however, uses leader and follower replicas that synchronize data with a latency of several hundred milliseconds. During high-frequency trading operations or intense market fluctuations, this latency can be a real concern.
To be honest, no solution or architecture is perfect. We can only try to make it better. I believe that the drawbacks will be eliminated over time. We just need to invest some time in learning and analysis.
My motivation for writing this article stems from the new regulations regarding the building of financial data centers. The conventional three IDCs across two regions mode will inevitably be replaced by architectures with multiple active IDCs. New regulatory requirements will undoubtedly bring technological iterations, making the exploration of a new technological roadmap important. In addition, a technological feature is meaningless if it does not play a role in a business scenario. I find that many features of OceanBase Database are developed to address real-world pain points through continuous exploration, research, and verification. These features make me marvel that if I were their product manager, I probably would not have conceived such comprehensive solutions.
This article may contain misinterpretations, and I am open to corrections at any time. Please do not hesitate to give your suggestions. I will optimize this article from time to time, hoping to eventually bring my thoughts into reality.