Momo —— Exploration and practice of persistent cache based on OceanBase KV storage
About the author: Ji Haodong, head of the database division at Momo, part of the Hello Group. He is now responsible for the database teams of Momo and Tantan and the database storage and operation throughout the Hello Group. He has a wealth of professional experience and practical know-how in the fields of large-scale data source stability construction, team building, cost optimization, and IDC migration.
Business scenario characteristics of social media applications
Hello Group launched Momo in August 2011. This open-style mobile video social media application is based on geographical location services, unique among the social media platforms in China. As the mainstream social applications that allow strangers to interact, Momo and Tantan involve a variety of core business modules, including livestreaming, nearby events, instant messaging (IM), and value-added services. Each business scenario has its own unique characteristics and challenges.
In this article, Ji Haodong, the head of the database team of Momo, will focus on their experience in choosing a KV system architecture for Momo, giving an in-depth analysis of the decision-making process. He will further share the trials that the Momo team conducted in choosing and using OBKV of OceanBase and discuss their practical experience.
Livestreaming holds a prominent place among these business modules. The main characteristic of this module is the possibility of sudden traffic spikes. Due to the requirements for low latency and high concurrency, this module places high demands on the real-time processing capabilities of the database system. The platform needs to ensure that data is processed and distributed in a timely and accurate manner when a large number of users are simultaneously viewing content and interacting online.
The nearby events module involves complex data, including geographic location information, activity trajectories, and social relationships of users. This kind of data accumulates quickly and forms large-scale data sets over time. Data can be classified into hot data and cold data. For example, some data may become hot at a certain time, for example, when a user's post creates a lively discussion. This requires the system to effectively manage and quickly respond to hot data access needs.
The core features of IM business scenarios are highly concurrent communication requiring low latency. The delivery time of information must be accurate. Therefore, the requirements for real-time performance are extremely high. To ensure a sound user experience, the application needs to ensure that messages are delivered to users instantly and reliably.
Value-added services mainly focus on data consistency and real-time performance. When processing operations such as purchasing and giving virtual gifts or exercising member privileges, the system needs to ensure data accuracy and update user account statuses in a timely manner. At the same time, real-time performance of data is also essential for high-quality value-added services, such as real-time calculation of bonus points, grades, and benefits.
When operating these businesses, both Momo and Tantan need a powerful data processing and management system to deal with various characteristics and challenges in order to deliver an efficient, stable, and personalized social media experience to users. How should we choose an appropriate KV system for these business scenarios?
KV storage architecture in different business stages
Companies usually have different requirements for storage systems in different development stages.
In the initial stage, the main goal of a company is to start business operations. In the startup stage, the company often needs to carry out rapid iteration on a newly developed app. As a result, they do not have high requirements for the storage system. The storage system is only expected to meet the basic technical needs of the business and then evolve gradually. In this stage, the common choices include the Redis master-slave architecture, Redis Cluster, and other native architectures.
The advantage of the Redis master-slave cluster architecture is that you can quickly build master-slave clusters or sharded clusters and carry out many designs directly on the client. However, this simple operation mode may lead to a high degree of coupling between the design and the client service code, causing difficulties in elastic scaling in the future.
In contrast, the Redis Cluster architecture supports dynamic scaling and high availability. However, with Redis Cluster, the business relies on clients to perceive node changes. If the client fails to handle node changes correctly, service interruption or business performance degradation may occur. Therefore, for error-sensitive business, Redis Cluster may introduce additional complexity. Although Redis Cluster has the advantages of decentralization, fewer components, smart clients, and support for horizontal scaling, they also have some downsides, such as unfriendly batch processing and lack of an effective flow control mechanism.
In the second stage, as the company grows and gains more users, the architecture must support rapid scaling. Basic Redis sharding architectures, such as Codis and Twemproxy, are popular choices for companies in this stage. Among them, Codis provides server-side sharding, centralized management, automatic failover, horizontal node scaling (with 1024 slots), dynamic capacity scaling, and support for pipelines and batch processing. However, Codis only offers an outdated official version V3.2.9. Any updates require much repair and adaption work, and can consume many resources due to the large number of components involved.
In the third stage of company development, as the business further develops and becomes relatively stable, the company may identify issues introduced in the previous stages, such as excessive memory usage and lack of hot and cold data separation. These issues need to be re-examined and addressed. So in the third stage, optimization is the focus. In this stage, common choices are persistence architectures, including oneStore-Pika, Tendis, and Pika.
Finally, in the fourth stage, the business and technology of the company become more complex and advanced. Simple optimization and adjustments may no longer provide significant improvements, and further optimization may not be possible. At this point, a more stable architecture or solution may be introduced to respond to these challenges. We recommend that companies at this stage adopt a multi-modal architecture, which can accommodate multiple data types and workload types and thus provide greater flexibility and potential for optimization.
In general, companies must choose a storage system that suits their business needs, technology maturity, cost-effectiveness requirements, and future scalability and optimization demands in their development stages. As companies grow and business complexity increases, storage architectures need to evolve and adapt to ensure system stability, efficiency, and sustainability.
Momo's in-house KV storage architecture oneStore
In view of the current business situation of Momo, the most crucial challenge we face is the continuously growing cluster size. When the number of shards in a single cluster exceeded 1000, the data volume exceeded 10 TB, and the QPS exceeded 1 million, the Codis architecture and Redis Cluster architecture no longer met our growing capacity requirements.
In order to break through this bottleneck, we developed a proprietary storage product called oneStore. The following figure shows its architecture. This architecture has undergone a phased optimization and improvement process, aiming to overcome the original limitations to accommodate more shards, larger data volumes, and more intensive query requests. We strive to use the oneStore architecture to achieve seamless business expansion and performance improvement.
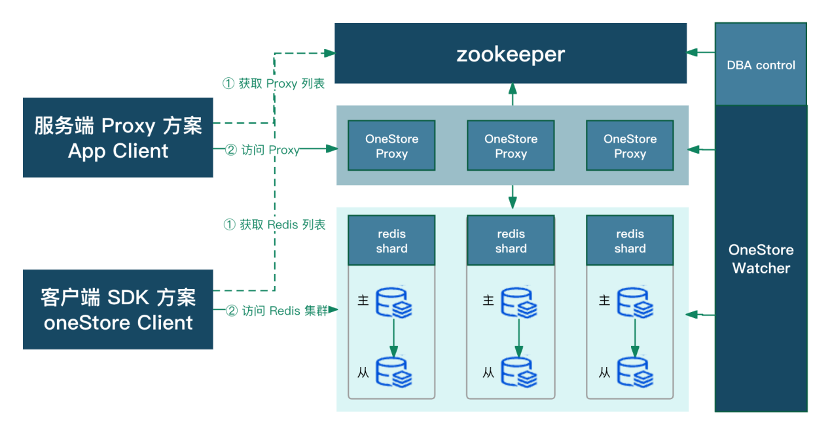
In the first phase, this architecture provides a server proxy scheme. Our proprietary oneStore Watcher sentinel component is used to streamline the architecture. In this way, only one sentinel cluster needs to be deployed to effectively manage a business domain.
In the second phase, the client SDK solution is provided. Although the server proxy solution performed well, as the company business stabilized, we aimed to reduce costs and increase efficiency throughout the company. The client SDK solution can be used directly to perceive cluster topology changes and directly connect to the backend Redis endpoint. In this way, the server proxy component can be eliminated, reducing our costs. However, we have not completely abandoned the server proxy scheme. This is because our client SDK solution currently only supports Java and C++, and users of other languages such as PHP and Python still need to access the data source through the server proxy. The successful application of these two solutions helped us unify access to Redis at the company level and significantly improved IDC migration efficiency.
As the business has further stabilized, we began to optimize the architecture in terms of cost. We used Pika to replace some Redis clusters with a low request volume, and then improved the persistence capability of the architecture, as shown in the following figure, while reducing storage costs. However, in this stage, Pika was mainly used to store some relatively cold data, and its performance in processing hot data needed to be further improved. We hope to further improve performance in this aspect.
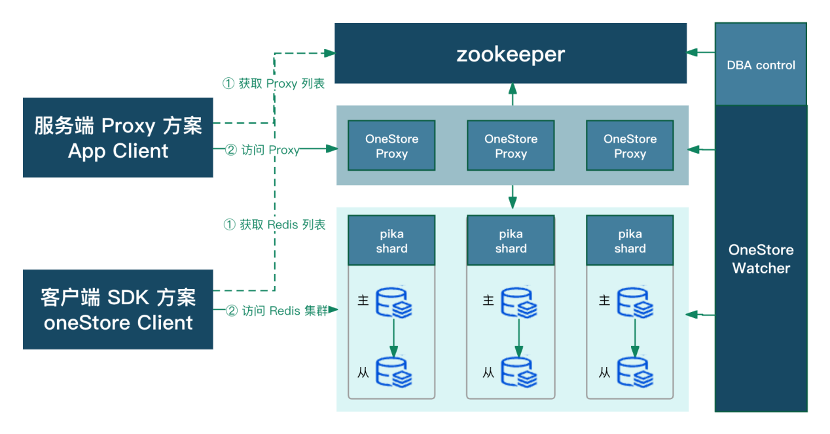
In short, the scenarios to be addressed and optimized include:
1. Reciprocal impact among multiple instances on a single server: We urgently need to eliminate the reciprocal impact among different instances on a single server to ensure the stable operation of and efficient cooperation among these instances. Such impact undermines the overall stability and synergy of the system, and must be addressed by targeted optimizations and adjustments.
2. Data persistence support: We plan to enhance data persistence support to form a comprehensive data persistence solution, to ensure data integrity and reliability not just for cold data, but also for a wider range of data types. It will be an important guarantee for the long-term stability of the system.
We need a simple, reliable, and scalable KV system to solve the above problems.
Reliable distributed KV system — OBKV of OceanBase
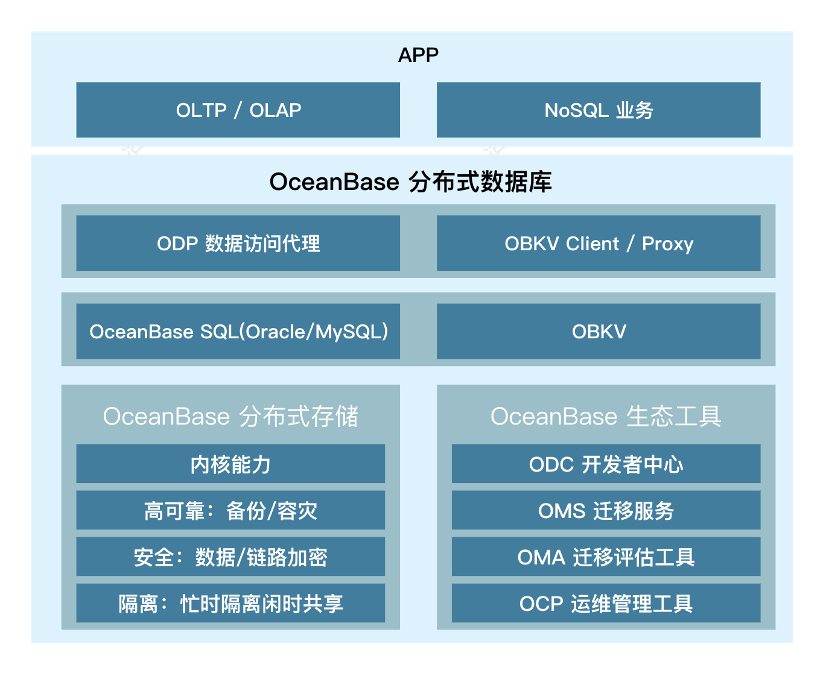
OBKV is a module that OceanBase provides for accessing the table and HBase models over APIs. We chose OBKV because it offers the following major advantages:
1. Better performance
OBKV is built based on a table model and matches the typical table model of the Redis data structure persistence solution. It has better performance than traditional persistent storage architecture and can build richer data structures.
The following figures show the performance of OBKV in different aspects in a massive data writing scenario (with a TPS value of 17000). The TPS curve is quite steep because tasks write data at different stages, and the response delay is within 2 milliseconds. The response time details of the transactions are as expected.
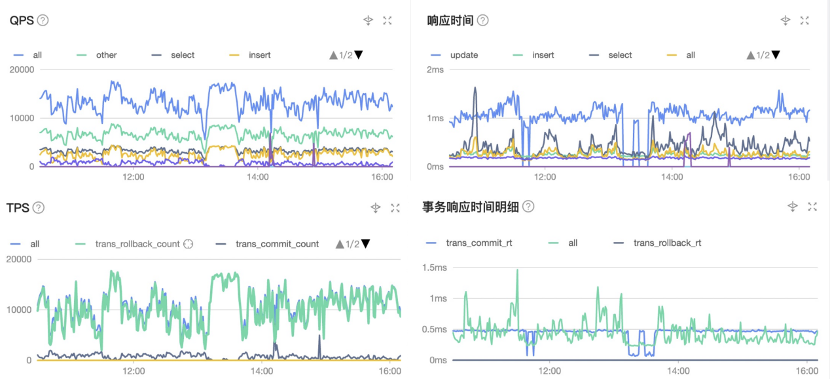
The following figures show the CPU performance. We can see the CPU utilization remains below 10% in a relatively stable state. The MemStore usage is also within the normal range of below 24% with small fluctuations as expected.
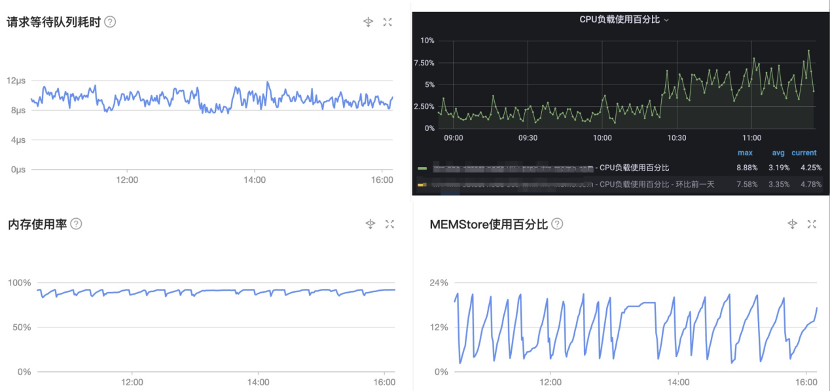
On the whole, OBKV achieves low fluctuations and stable resource usage in a production environment.
2. High stability
OBKV is based on OceanBase Database. The storage engine has been verified in a variety of large-scale TP scenarios and can provide high concurrency and low latency. The multitenancy feature ensures system stability, as shown in the following figure. The black curve represents the TPS of a tenant for which OBKV is implemented, while the blue curve represents the TPS of a regular MySQL tenant of OceanBase Database. After the stress test was initiated around 11:30, the tenant for which OBKV is implemented responded normally, and the MySQL tenant was not affected. At the server layer, the CPU load increased due to the stress test, while the MySQL tenant was not affected.
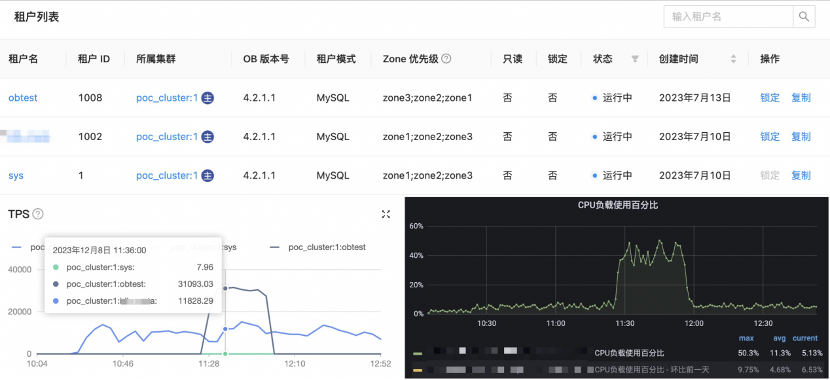
Therefore, it can be concluded that the multitenancy feature can effectively solve reciprocal impact among different instances on the same server.
The following figures show the performance of the online MySQL tenant in a production environment. The TPS value was 5000, and the overall performance was quite stable. The fluctuations in CPU utilization and memory usage were mild and in line with expectations.
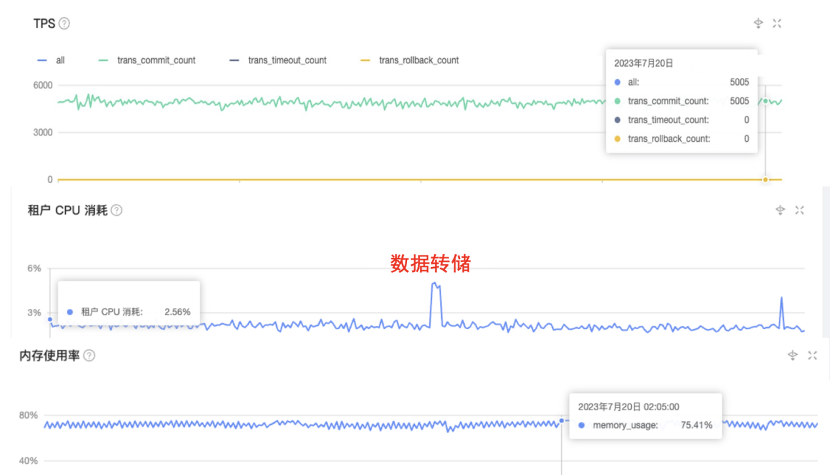
In addition, we can easily use the KV interface to store data in the database and use SQL statements to query data. OBKV further enhances this convenience by supporting secondary indexes and service-side TTL features to help simplify the upper-level service architecture. Nevertheless, OBKV has some limitations. For example, it only provides local transaction processing capabilities. If distributed transaction processing is enabled, it may affect the performance and increase the response latency of the system in a highly concurrent environment. However, in view of the current requirements of Momo's business, we believe that the local transaction processing capability of OBKV fully meets our needs. Therefore, we have built a storage solution that combines OBKV and Redis.
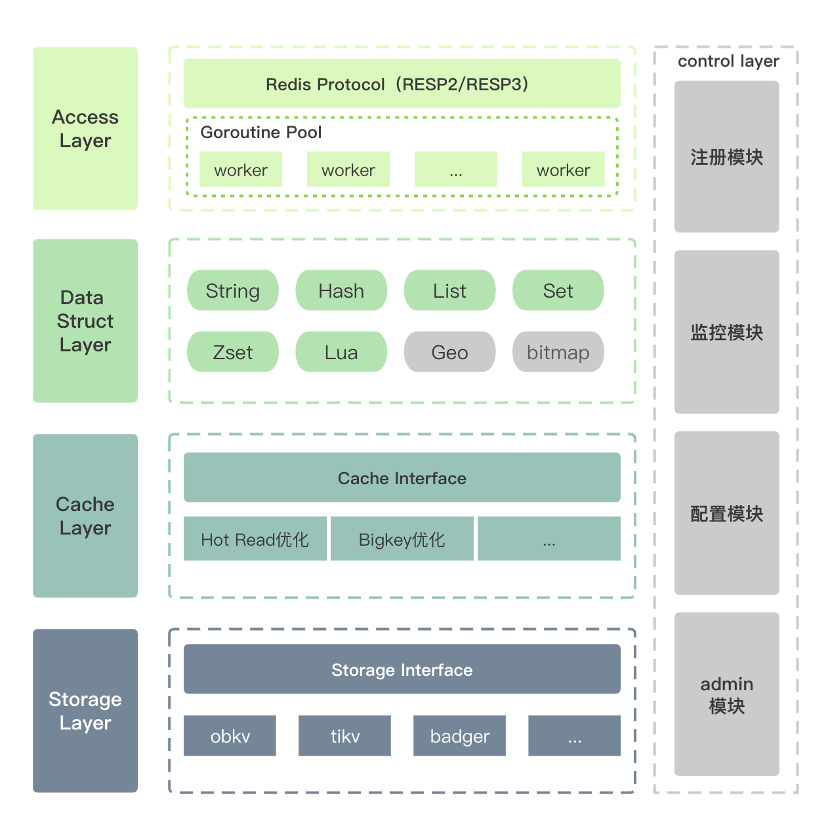
OBKV-Redis cluster architecture
We worked with the OceanBase open source team to create a project internally named Modis. The overall architecture of the project covers multiple layers, including the access layer, data structure layer, cache layer, storage layer, and management plane, as shown in the following figure. It is worth noting that the cache layer will be used to effectively cope with the challenges of hot reading and large-key issues in our future plans. At the storage layer, we will build standard storage structures based on the principles of standardization and abstraction, to allow flexible access to a variety of storage solutions, including OBKV.
During the test and evaluation process, after we successfully migrated about 158 GB of data from Pika to the OBKV-Redis cluster, the occupied storage space was significantly reduced to 95 GB. The migration cut storage costs by about 40%.
To assess the performance, we built a special test environment with the specifications shown in the figure to simulate various thread concurrency scenarios.
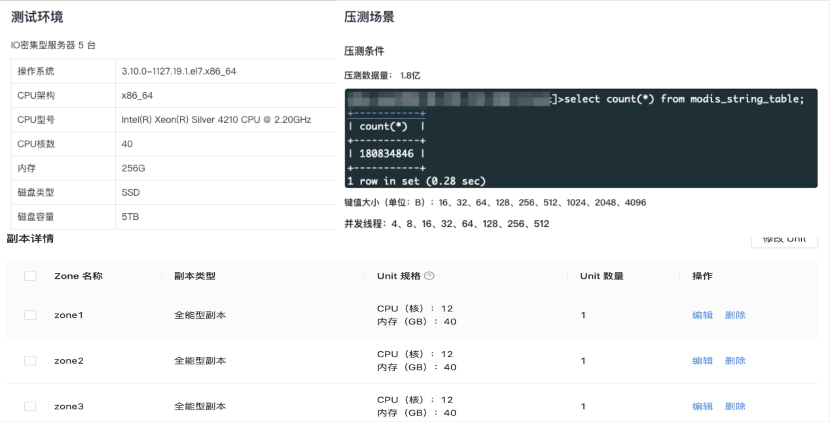
Based on the multitenancy management concept, we do not allocate excessive resources to a single tenant. Instead, we check for performance bottlenecks in each tenant in the test process to calculate the corresponding QPS value of a single core. Currently, the standard specification is 12 CPU cores and 40 GB of memory. To better adapt to future changes in business needs, we may release an architecture with lower specifications, such as 4 CPU cores and 8 GB of memory, or 8 CPU cores and 16 GB of memory, depending on the specific needs of the actual business.
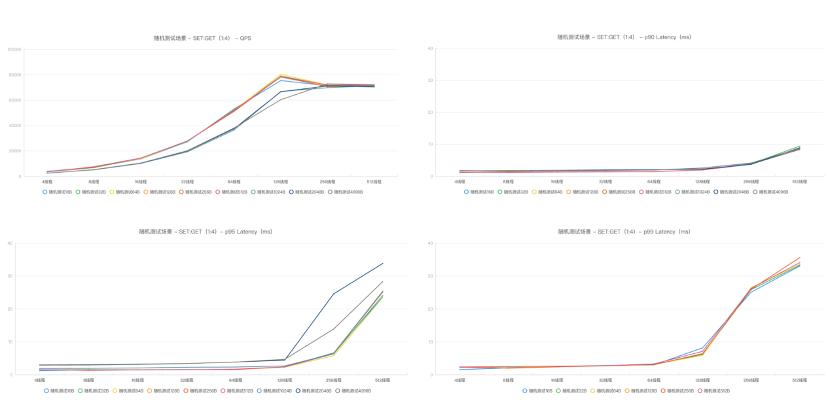
The following figure shows the performance of OBKV-Redis given 128 threads and a QPS value of 70000:
- P90 response latency: 1.9 ms;
- P95 response latency: 2.2 ms;
- P99 response latency: 6.3 ms;
On average, the single-core read-write ratio is 4:1, and the single-core capacity is close to 6000 QPS.
We also compared the O&M differences among OBKV, Pika, and TiKV. Currently, only OBKV provides native multitenancy support, which effectively solves the problem of reciprocal impact among different instances deployed on a single server. Notably, OBKV is a thoughtful and efficient solution for database O&M personnel because it provides GUI-based management tools and supports immediate effectiveness of parameter changes.
In summary, OBKV-Redis substantially improves performance, reduces disk usage, and greatly simplifies O&M management.
This is made possible by the following advantages of the solution:
- Multi-tenant isolation, which solves reciprocal impact among multiple instances on a single server.
- Lower storage costs from the encoding framework and common compression algorithms used for the storage of table models.
- Higher performance because request filters are pushed down directly to the storage, without serialization or deserialization, and the Time To Live (TTL) feature is supported for servers.
Vision for the future
At present, OBKV-Redis is integrated with strong support for core data structures, such as strings, hashes, and sets. It now supports 93% of Redis KV database commands, and is expected to provide full compatibility with common management commands and support containerized deployment and level-2 caches by the end of the first quarter of 2024. Moreover, we also plan to implement in-depth integration with the Capture Data Change (CDC) scheme. In the second quarter of 2024, our R&D team will further develop data migration features and introduce data tiering technology.
We have great confidence and high hopes for OBKV-Redis. We hope it will allow us to implement more refined data management throughout the data life cycle. As the company enters the fourth stage of our business development, where business and technological challenges deepen, we see stability and innovation as our key mission. Therefore, we have high anticipation of the multi-model ecosystem, and we believe it will empower enterprises by solving legacy problems and reducing costs.