Beike: Practice of Cost Reduction and Efficiency Improvement Based on the Real-time Dictionary Service of OceanBase Database
Beike, operated by KE Holdings Inc., is an industry-leading digital housing service platform in China. It is committed to promoting the digitalization and intelligentization of China's housing service industry, aiming at pooling and empowering resources to provide Chinese families with all-in-one, premium, and efficient services, from new home and resale transactions to leasing, decoration, local life, and handyman services.
Beike needed a real-time dictionary service to precisely deduplicate a great number of its business metrics in real time. This posed high requirements on the storage service, which must handle read/write operations of over 100,000 records per second, ensure data persistence, and guarantee data uniqueness. Considering the characteristics of the adopted storage system and Beike’s business needs, Beike shortlisted candidates and chose OceanBase Database over HBase. After deploying OceanBase Database, Beike achieved higher query performance and stability, while cutting down on both hardware and O&M costs.
Build a Real-time Dictionary Service to Solve the Bottleneck of Precise Deduplication
When it comes to data analytics, the COUNT DISTINCT function is often used to get the exact count of unique values for precise deduplication. Many business metrics of Beike, such as the number of accompanied visits, number of clients, daily active users (DAU), and monthly active users (MAU), rely on the precise deduplication service. For any online analytical processing (OLAP) engine worth its salt, supporting unique value counting for precise deduplication is a must-have feature.
A conventional database performs the counting flexibly based on raw data, keeping all the details. This method, however, is a real resource hog due to multiple data shuffles during a query. When dealing with high-cardinality data, its performance can go through the floor. To tackle this issue, big data folks often turn to approximate methods, such as HyperLogLog and Count-Min Sketch. These methods consume fewer computing resources, but they introduce approximation errors and do not support the counting. Bitmap is another popular trick for achieving precise deduplication. The idea is simple. Each element of the details is mapped to a bit in a bitmap. The bit value is 1 if the element exists, and 0 if it doesn't. When you need to perform the counting, just count the number of bits set to 1 in the bitmap. But here's the catch - this bitmap-based method only works with integer fields. If you want to perform the bitmap-based counting on other data types, such as strings, you'll need to build a global dictionary to map non-integer data to integers.
To support fast counting for non-integer data in real time, a real-time dictionary service is required, so that it converts non-integer data into unique integers in Flink jobs, and stores them in a downstream OLAP engine, such as StarRocks. Then, the OLAP engine, which supports the bitmap-based counting, can do the job.
In a nutshell, the real-time dictionary service is basically a translator that maps non-integer data to integers in real-time data streams. Here's what it does:
-
Receives non-integer data (key) from the caller and returns corresponding integers (key:value)
-
Ensures that the same key always gets the same value, keeping data persistent and unique
Since it's used in real-time data streams, the service needs to be lightning-fast with minimal latency in response to the caller.
The following figure shows the role of the real-time dictionary service in a data processing flow. During the real-time extract-transform-load (ETL) process, Flink calls the dictionary service, feeds in the raw data, gets the corresponding dictionary values, makes the swap, and writes the mapped values to the OLAP engine.
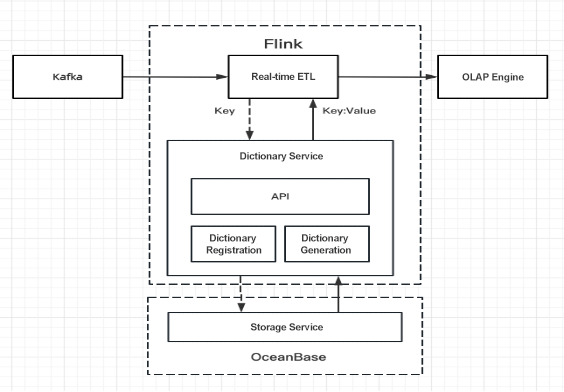
The dictionary service consists of computing and storage layers. The computing layer handles dictionary registration, data queries, and data processing, and interacts with the caller and the storage layer. The storage layer stores dictionary data and provides query services.
1. Computing layer
This layer handles dictionary registration and generation.
Dictionary registration: String fields must register with the dictionary, and each field gets its own dictionary table in the storage service. Dictionary data is stored and queried based on dictionary tables.
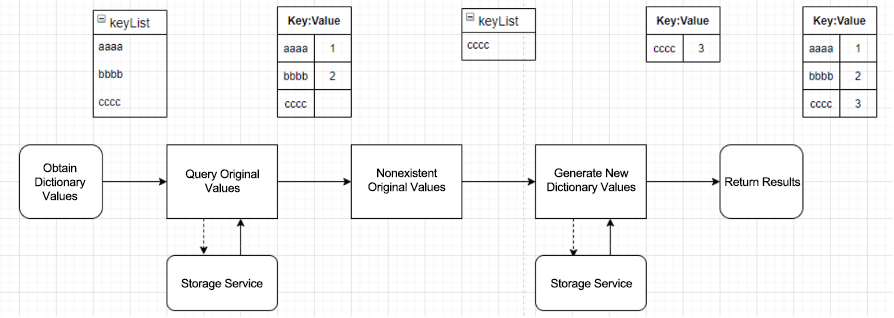
Dictionary generation: The caller gets dictionary values corresponding to their raw values using the dictionary ID and raw value list. The following figure shows the three steps of a query: 1) query the dictionary table based on the raw value list to get the mapped values, 2) generate new dictionary values for any nonexistent raw values, and 3) return results obtained in steps 1 and 2.
2. Storage layer
This layer handles dictionary data storage and queries and plays a fundamental role in enabling the dictionary service. The storage service needs rock-solid reliability to prevent data loss and duplication, plus the muscle to read/write over 100,000 data rows per second with low latency. Picking the right storage service is arguably a make-or-break factor.
Select a Real-Time Dictionary Storage Service to Prevent Data Loss or Duplication
To meet the storage requirements of the real-time dictionary service, the storage service must be able to read/write over 100,000 data rows per second, support data persistence, and guarantee data uniqueness. Data persistence and data uniqueness matter the most because the storage service must ensure zero data loss and zero data duplication (one key corresponding to multiple values, or the other way around). Given the characteristics of Beike's legacy storage system and its business needs, HBase and OceanBase Database were tested and compared.
1. Prepare the environment
The OceanBase and HBase clusters for the test were respectively deployed on three Dell EMC PowerEdge R640 servers, each with 48 CPU cores, 128 GB of memory, and a 1.5 TB NVMe SSD. All test tasks were executed in the same real-time Hadoop cluster. HBase 1.4.9 was used, and the HBase cluster was deployed and configured by the HBase database administrator. OceanBase Database V3.1.2 was used, with all parameters set to the default values.
2. Test data
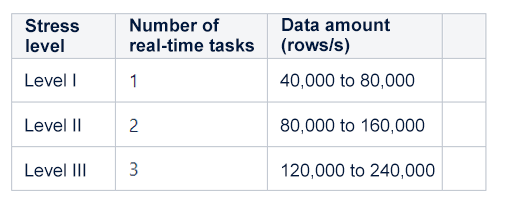
In the test, Spark Streaming real-time tasks consumed the starrocks-prometheus-metrics topic, which involves 40,000 to 80,000 data rows per second, to generate a UUID for each data row, and then batch called the dictionary service to generate dictionaries, with the batchDuration parameter set to 1 second. The amount of data and thus the stress on the storage service was increased by initiating more real-time tasks, and the throughput capacity of the storage service was evaluated by the latency of the real-time tasks.
The following table describes the three levels of the stress test, and each level lasted 10 minutes in the test.
3. Test process and results analysis
1) Test on HBase
HBase itself supports data persistence, which ensures zero data loss. In addition, HBase calls the get(List) operation to execute batch queries, the incrementColumnValue operation to prevent duplicated values, and the checkAndPut operation to guarantee key uniqueness.
HBase provides a dictionary service in the following procedure:
- Calls the get(List) operation to query dictionary tables in batches.
- Calls the incrementColumnValue operation to batch generate auto-increment unique IDs for data that does not exist in dictionary tables. This ensures that the dictionary values are unique.
- Calls the checkAndPut operation to write the key:value data into the dictionary tables. A successful write means that the corresponding dictionary value is generated, whereas a failed write means that the corresponding dictionary value already exists. This way, the same key will not be written twice.
- Calls the get(List) operation again, using the data that failed to be written in the previous step, to query the dictionary values.
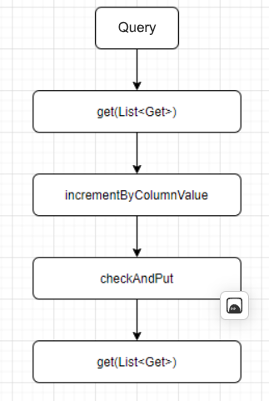
To improve the data read/write performance, the dictionary tables were pre-split into multiple regions using the HexStringSplit method as recommended by HBase database administrators, so that the data was evenly distributed across different region servers. The batch size of read/write operations was set to 100, an optimal value considering the response time of different sizes.
The following table shows the details of batch read/write operations.
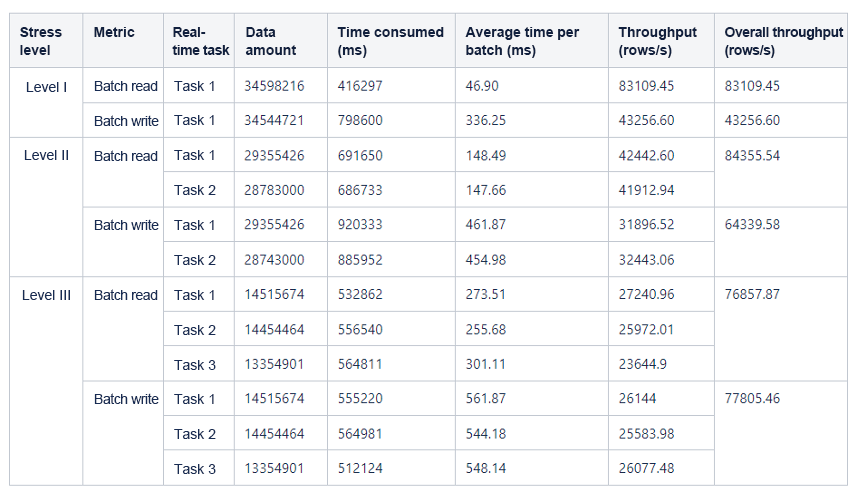
The following table shows the test results.
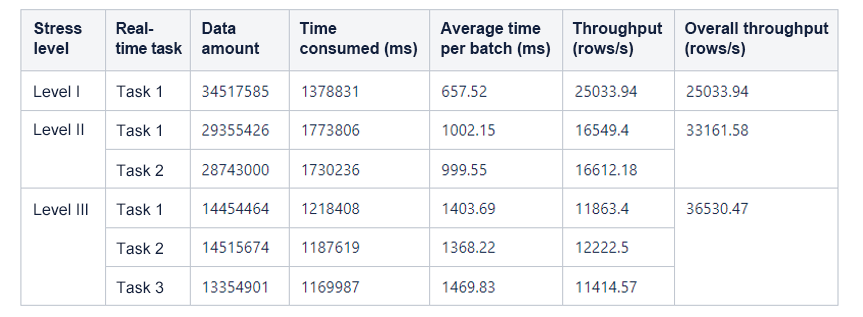
2) Test on OceanBase Database
OceanBase Database stores dictionary data in tables and ensures data uniqueness by using keys as the primary key and setting values to be auto-increment. The following sample statement shows how to create such a table:
CREATE TABLE t_olap_realtime_cd_measure_duid_dict (
dict_key VARCHAR(256) NOT NULL,
dict_val BIGINT(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (dict_key)
) DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(dict_key) PARTITIONS 10
Compared to HBase, this method simplifies data processing and can do the same job just by executing SQL statements. Here is an example:
-
Query existing dictionary values: select dict_key,dict_value from t_olap_realtime_cd_measure_duid_dict where dict_key in (...)
-
Insert the nonexistent dict_key values in the result of the previous step into the database: insert ingore into t_olap_realtime_cd_measure_duid_dict (dict_key) values (...)
-
Query the database again for the data inserted in the previous step: select dict_key,dict_value from t_olap_realtime_cd_measure_duid_dict where dict_key in (...)
Using OceanBase Database, Beike does not need to pay attention to preventing duplicated keys or auto-increment values at the code level, which is handled by built-in features of the database system. OceanBase Database not only simplifies the data processing flow, but also writes data in batches, which is more efficient compared with writing one data row at a time. The batch size of read/write operations was set to 500 for OceanBase Database.
The following table shows the details of batch read/write operations.
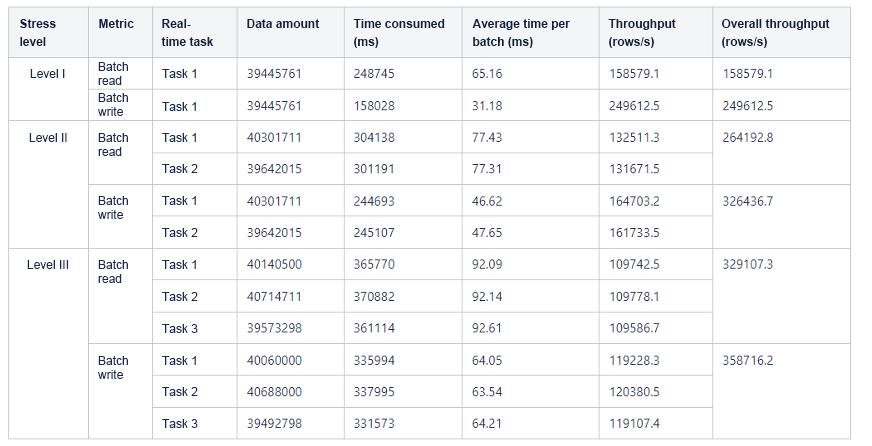
The following table shows the test results.
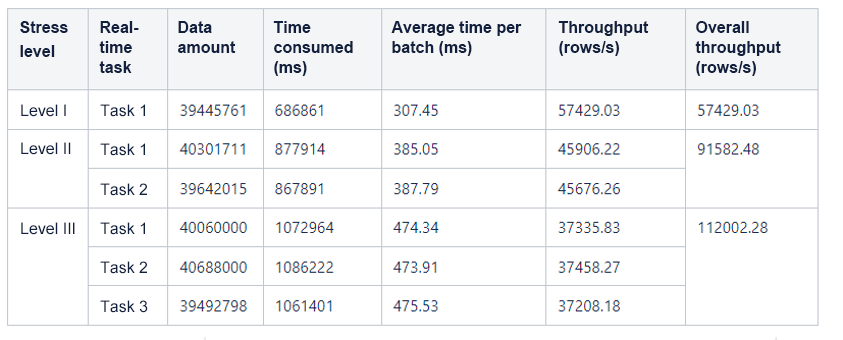
3) Data analysis and comparison
First, let's compare the batch read throughput (unit: row/s).
| Stress | HBase | OceanBase Database |
|---|---|---|
| Level I | 83109.45 | 158579.1 |
| Level II | 84355.54 | 264192.8 |
| Level III | 76857.87 | 329107.3 |
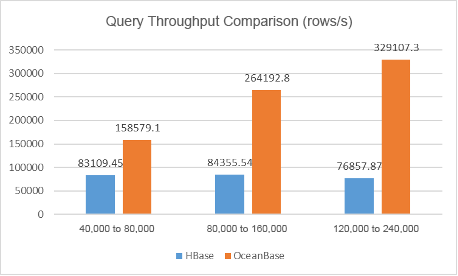
As mentioned above, the batch size was set to 100 for HBase and 500 for OceanBase Database based on their respective characteristics. The preceding figure shows that the query throughput of OceanBase Database was significantly higher than that of HBase at all three stress levels in the test, with the data volume ranging from 40,000 and 240,000 rows.
Now, let's compare the batch write throughput (unit: row/s).
| Stress | HBase | OceanBase Database |
|---|---|---|
| Level I | 43256.6 | 249612.5 |
| Level II | 64339.58 | 326436.7 |
| Level III | 77805.46 | 358716.2 |
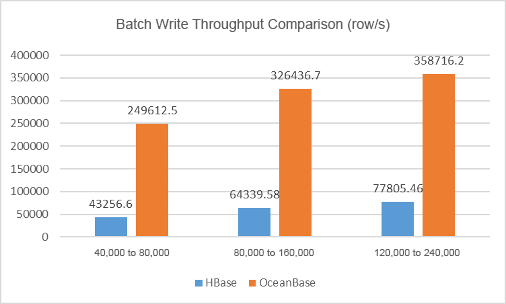
To ensure the uniqueness of keys, HBase uses the checkAndPut method to write one data row at a time, while OceanBase Database takes keys as the primary key, and writes data in batches, specifically, 500 rows at a time. This way, the batch write throughput of OceanBase Database was much higher than that of HBase in the test.
Now, let's look at the average time, in milliseconds, that each database system took to finish a complete processing cycle.
| Stress | HBase | OceanBase Database |
|---|---|---|
| Level I | 657.52 | 307.45 |
| Level II | 1000.85 | 386.42 |
| Level III | 1279.63 | 474.59 |
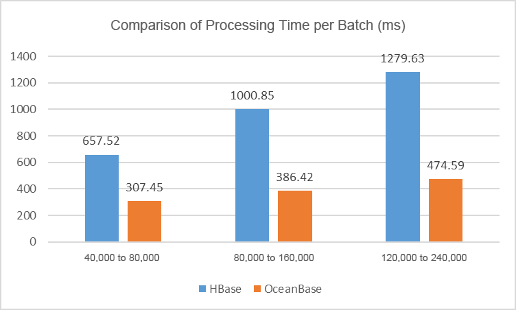
The comparison indicates that:
-
OceanBase Database spent 50% less time than HBase in finishing a complete data processing cycle.
-
Both HBase and OceanBase Database completed a real-time task involving 40,000 to 80,000 data rows within 1 second.
-
HBase took more than 1 second to handle two real-time tasks, involving 80,000 to 160,000 data rows. However, HBase did not show a significant latency due to uneven data volume.
-
HBase took 1.27 seconds on average to complete three real-time tasks, involving 120,000 to 240,000 data rows, showing an increasing latency of the real-time tasks.
-
OceanBase Database completed the data processing cycle within 0.5 seconds despite the increasing stress.
At last, let's compare the average throughput (unit: row/s).
| Stress | HBase | OceanBase Database |
|---|---|---|
| Level I | 25033.94 | 57429.03 |
| Level II | 33161.58 | 91582.48 |
| Level III | 35500.47 | 112002.3 |
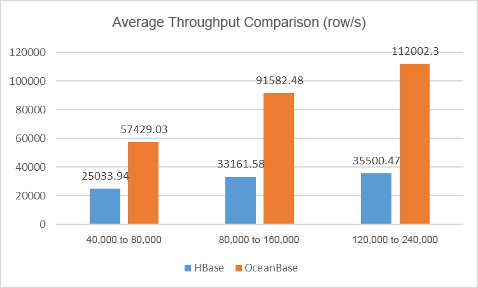
The throughput of OceanBase Database was 2 to 3 times higher than that of HBase in the test, and the advantage is getting bigger as the data volume increases.
Summary
After the dictionary service is deployed, it writes a great amount of data to the storage and handles frequent read requests in the early stage. As more dictionaries are created, along with their growing sizes, the dictionary service involves more read requests and fewer write requests. In this test, randomly generated UUID data was used, so all data rows were fully written and read during the entire data processing cycle. This means that the test was more stressful for the storage system than the real online environment.
The performance of HBase and OceanBase Database in handling tasks at three stress levels of the test is described as follows:
-
At level I, which involved 40,000 to 80,000 rows, both HBase and OceanBase Database completed data processing within 1 second. In this scenario, both HBase and OceanBase Database met the requirements.
-
At level II, which involved 80,000 to 160,000 rows, HBase took a bit more than 1 second to complete data processing, showing a slight latency. In this scenario, both HBase and OceanBase Database met the requirements.
-
At level III, HBase took 1.27 seconds to complete data processing, showing an increasing latency. In this scenario, only OceanBase Database met the requirements.
-
OceanBase Database showed a considerable latency when handling 280,000 to 560,000 data rows of seven real-time tasks, which took it 1.1 seconds to complete.
Given the test statistics, OceanBase Database has obvious advantages in batch reads, batch writes, and throughput. To ensure unique keys and auto-increment values, HBase only writes one data row at a time, making data writes a processing bottleneck. On the contrary, OceanBase Database inherently ensures unique keys and auto-increment values, and writes data in batches by executing SQL statements, supporting a higher write throughput.
Considering the data processing capability, resource usage, and data processing complexity, Beike chose OceanBase Database as the storage system for the real-time dictionary service. In the production environment, the deployment of OceanBase Database is simpler, and it has achieved higher query performance and stability, and lower hardware and O&M costs. Beike will apply OceanBase Database in more suitable scenarios.