Sichuan Hwadee —— The practice of lightweight data warehouse construction of health big data based on OceanBase
Introduction: This article introduces Sichuan Hwadee's practice of migrating its data computing platform from Hadoop to OceanBase Database. This case demonstrates the advantages of OceanBase Database in terms of performance and storage costs. With OceanBase Database, hardware costs are reduced by 60% and the O&M work is significantly cut down, relieving maintenance personnel from responsibility for the many Hadoop components. OceanBase Database enables Hwadee to meet the needs of hybrid transaction/analytical processing (HTAP) scenarios with just one system, simplifying O&M for the company.
About the author: Xiang Ping, the Technical Director of the Smart Healthcare and Elderly Care R&D Department of Sichuan Hwadee Information Technology Co., Ltd., is responsible for big data and AI architecture design and team management in the smart healthcare and elderly care sector.
I. Mining the value of medical data with a data computing platform
As the Chinese population grows older, care for the elderly is an increasingly important topic for our society. Providing healthcare for the elderly is a demanding job calling for wisdom, resources, and effort from society as a whole.
We, Sichuan Hwadee Information Technology Co., Ltd. (hereinafter referred to as "Hwadee"), have created a big data public service platform for smart medical care called Qijiale by integrating and innovating next-generation information technologies such as big data, cloud computing, Internet of Things, AI, and mobile Internet. We cooperate with the local governments and competent government departments with jurisdiction over project demo sites to explore and create a new smart healthcare model that joins efforts of institutions, communities, and enterprises. Through these efforts, we hope to provide professional, efficient, convenient, and safe healthcare services for the elderly by drawing on the collective efforts of residential communities, relatives of the elderly, elderly care institutions, medical institutions, medical schools, local governments, science and technology enterprises, life service institutions, and other groups.
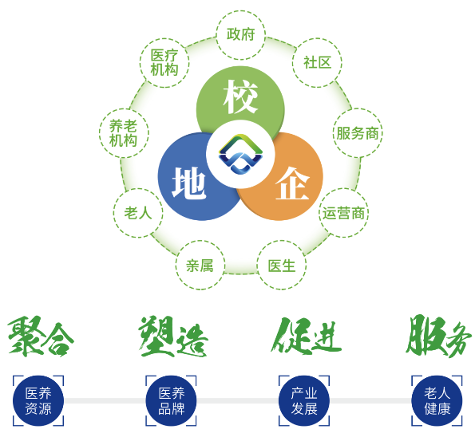
The Qijiiale platform is a resource integration platform that brings together medical and nursing services. It provides a work, service, and publicity platform for health information and warnings, assistance in chronic and geriatric disease diagnosis, integrated medical and nursing services, health knowledge learning, and other features. It establishes comprehensive and professional public service networks for healthcare and elderly care at the provincial, municipal, county (district), township (street), and village (community) levels and creates a multi-level intelligent healthcare service system that covers health data collection, big data analysis and early warning, intervention services, and performance evaluation. Qijiiale establishes a multi-scene healthcare service model that focuses on the elderly by combining efforts of families, communities, medical care institutions, hospitals, and governments. By providing intelligent modern community healthcare services in real time in a dynamic and continuous manner based on real names, the platform links healthcare information with healthcare resources by connecting people, data, and devices.
We have created a data resource pool based on the medical data, elderly care data, and industrial data collected by hospitals and governments, and uses a big data system to store and compute resources. We have also established a data computing platform with powerful processing capabilities and high scalability. The data computing platform can store, cleanse, process, model, and analyze massive data, making full use of every piece of data in the resource pool to aggregate data according to a wide range of metrics. The platform provides ample reference data for statistical decision analysis, algorithm analysis services, big data prediction, and other applications, helping the company mine more value from its medical data resources.
II. Technology selection to address pain points of Hadoop applications
Currently, we have accumulated a total of about 20 TB of data. The following figure shows our early-stage data computing platform that we built based on the Hadoop ecosystem.
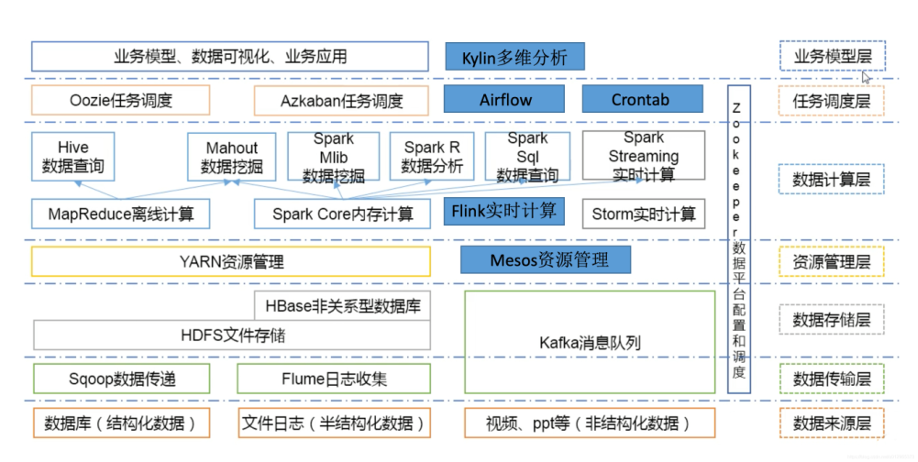
We encountered many problems in using and operating this data computing platform, such as excessive components, complex builds, and high O&M costs. The most critical problem was that this complex environment was difficult to promptly troubleshoot when a fault occurred.
To solve these pain points, we looked into distributed databases. By reading the OceanBase official documentation along with blogs and Q&A in the open source community, we learned that OceanBase Database supports thousands of OBServer nodes in a single cluster. It can support nearly a petabyte of data in a single cluster and trillions of rows in a single table. Real-time online transactions and real-time data analysis can be supported with the same set of data and the same engine. Multiple replicas of a dataset can be stored in different formats for different workloads. Moreover, OceanBase provides an automatic migration tool, OceanBase Migration Service (OMS), which supports migration assessment and reverse synchronization to ensure data migration security.
We found that the open source ecosystem products of OceanBase could meet our data scale and data computing platform needs, so we conducted preliminary tests. We immediately took note of the HTAP capabilities of OceanBase Database, and also the following five capabilities, which are critical to us.
-
Easy O&M
The OBServer nodes are peer-to-peer, and each contains a storage engine and a computing engine. OceanBase Database boasts a small number of components, simple deployment, and easy O&M. With OceanBase Database, we no longer need to add other components to the database to achieve high availability and automatic failover.
-
High compression ratio
OceanBase Database organizes data based on the Log-structured merge-tree (LSM-tree) architecture, where the full data consist of baseline data plus incremental data. Incremental data is first written to a MemTable in memory, achieving a write performance comparable to that of an in-memory database. The baseline data is static and will only change at a major compaction. Therefore, a more aggressive compression algorithm can be used, reducing the storage space required by at least 60%. After we migrated the data from Oracle Real Application Clusters (RAC) to OceanBase Database, the disk capacity required is only 1/3 the original size, even when we adopt a three-replica storage mode. For more information about the core data compression technologies of OceanBase, you can read Save at least 50% of the storage costs for history databases with core data compression technologies of OceanBase.
-
High compatibility
At present, OceanBase Database Community Edition is almost perfectly compatible with MySQL syntaxes and features. Most statistical analysis tasks can be completed by using SQL statements. OceanBase Database also supports advanced features that we commonly use, such as stored procedures and triggers.
-
High scalability
OceanBase Database provides linear scalability. DBAs can simply execute a single command to add server nodes and achieve linear performance scale-out. After new nodes are added to an OceanBase cluster, the system automatically rebalances the data among nodes. DBAs no longer need to migrate data manually.
-
High availability
OceanBase Database natively supports high availability. It uses Paxos to achieve high availability at the partition level. When a minority of nodes fail, it can still provide services, so your business is not affected.
III. Benefits and issues arising from migration from Hadoop to OceanBase Database
i. Changes in architecture
Our original data computing platform was a Hadoop environment that was deployed on 10 servers and used more than 20 different open source components. These components carried out tasks such as data import and export, data cleansing, and analytical processing. We first used the extract-transform-load (ETL) tool to transfer raw data to Hadoop Distributed File System (HDFS), then used Hive commands to load the data, and finally used Spark SQL for data analysis.
Under this architecture, data needed to be transferred back and forth. Moreover, we needed professionals to work intensively on version adaptation and performance tuning for these components. The key problem lay in troubleshooting. Due to the excessive components and long links, we had a hard time quickly finding the faulty component.
At first, we just wanted to use OceanBase Database to integrate and cleanse data: We used a dedicated line to pull data to the front-end machine (Oracle RAC) and then used the ETL tool DataX to pull data from the front-end machine to OceanBase Database. Then, we decrypted, cleansed, and integrated the data in OceanBase Database. Finally, we pulled the cleansed data from OceanBase Database to Hadoop for analytical processing. You can see the full process in the figure below.
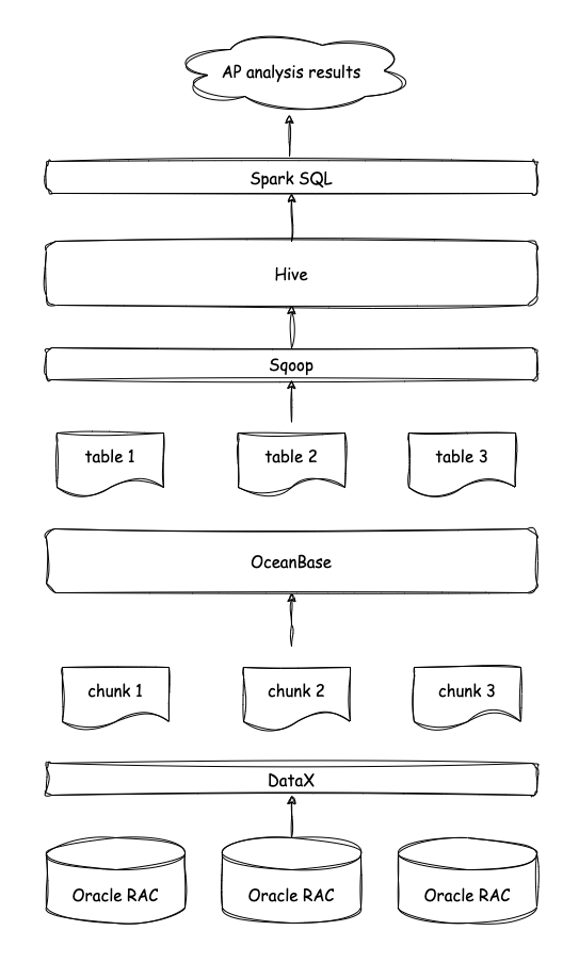
Later, from the OceanBase official website, we learned that OceanBase Database supported HTAP capabilities. So we tried analytical processing on the data directly in an OceanBase cluster with three nodes. We were surprised to see that even if the data was not partitioned in OceanBase and parallel execution was not used, we were able to complete analytical processing on 0.5 billion rows of data in less than a minute.
Analytical processing in an OceanBase cluster with three nodes outperformed Hadoop that had 10 servers of the same specification. To our surprise, OceanBase Database supports SQL syntax directly. We do not need to load the data into Hive and then use Spark SQL for analysis, nor do we need to use various open-source components. This simplifies the data computing platform link, as shown in the following figure.
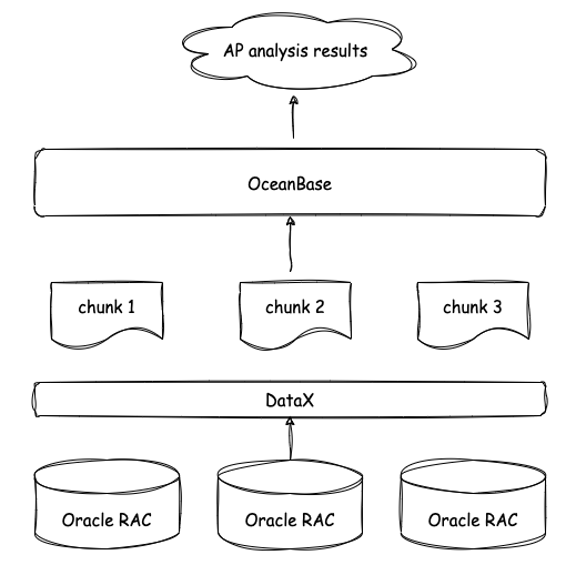
We initially planned to import data into OceanBase Database for data integration, and then import it back to Hadoop. However, we found that the entire downstream Hadoop cluster was useless. Moreover, as a distributed database, OceanBase Database supports horizontal scaling. This led us to abandon Hadoop completely.
We haven't yet done any performance tuning for OceanBase Database. In the future, we will use it to perform analytical processing on 10 billion data rows in more data environments, and then further study its partitioning and parallel execution features.
Also, we have changed our data computing platform to an OceanBase cluster consisting of 4 servers, with one OceanBase Cloud Platform (OCP) server and three OBServer nodes with the following specifications.
| Server | Operating system | Memory | CPU | Disk space |
|---|---|---|---|---|
| OCP | CentOS 7 (64-bit) | 64 GB | 20 vCPUs | 2 TB |
| OBServer node 1 | CentOS 7 (64-bit) | 64 GB | 20 vCPUs | 2 TB |
| OBServer node 2 | CentOS 7 (64-bit) | 64 GB | 20 vCPUs | 2 TB |
| OBServer node 3 | CentOS 7 (64-bit) | 64 GB | 20 vCPUs | 2 TB |
After data is imported to OceanBase Database by using the ETL tool, data decryption, cleansing, aggregation, and analytical processing are all completed in OceanBase Database, and some performance improvements are made for analytical processing. The OceanBase cluster consists of only the deployed cluster management tool OCP and OBServer nodes, and the OBServer nodes are completely equivalent to each other, greatly reducing the O&M complexity.
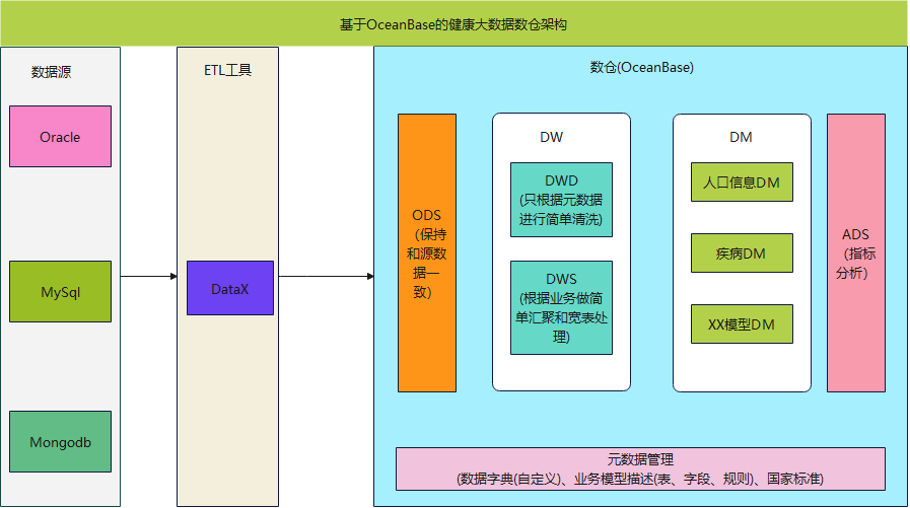
Terms:
1. Operational data store (ODS): The ODS layer stores and directly loads raw data without processing the data.
2. Data warehouse (DW): The DW layer stores structured and aggregated clean data to support decision-making and data analysis services for enterprises.
3. Data warehouse detail (DWD): The DWD layer cleanses data at the ODS layer by removing empty values, dirty data, and data that does not meet the metadata standards. It is used to store detailed, complete data that is used for cross-departmental and cross-system sharing and enterprise data query.
4. Data warehouse summary (DWS): The DWS layer provides business data summary and analysis services, and computes, aggregates, and processes raw data for enterprise decision-making.
5. Application data service (ADS): The ADS layer stores custom statistical metrics and report data for data products.
6. Data mart (DM): The DM is a collection of data that is focused on a single subject and separated from the data warehouse for a specific application. It provides a clear, targeted, and scalable data structure.
Figure: Overall technical architecture
ii. Storage costs
We tested the data import and export performance of an Oracle cluster and an OceanBase cluster each deployed on five servers of the same specifications, with a 372 GB data file containing 0.5 billion rows of data. For data import, we compared the storage space required by the imported data:
- The data file occupies 220 GB of storage space after it is imported to the Oracle cluster.
- After the same data file is imported to the OceanBase cluster by using OBLOADER, it occupies only 78 GB of storage space, even when it is stored in three replicas.
In short, even when storing data in three replicas, OceanBase Database requires only about 1/3 to 1/4 of the storage space required by Oracle Database.
iii. Ecosystem tools
OceanBase has a robust ecosystem that provides more than 400 upstream and downstream ecosystem products and in-house tools such as OCP and OBLOADER & OBDUMPER.
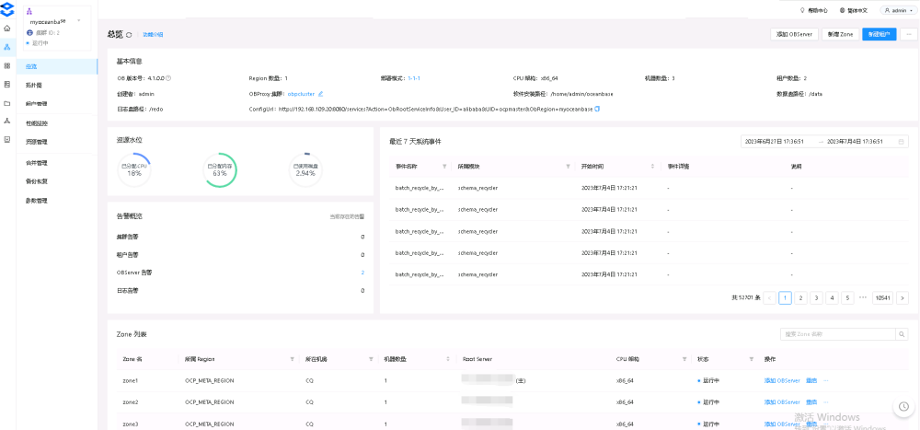
1. OCP
OCP is an O&M management tool that provides visual performance monitoring.
2. OBLOADER & OBDUMPER
OBLOADER & OBDUMPER is a data import and export tool for logical backup and restore of data. It takes OBDUMPER only several dozen minutes to generate a backup file for 0.5 billion rows of data, with the backup file sized about 400 GB. OBLOADER & OBDUMPER is easy to get started with, and allows you to import and export data with commands.
3. Integration and fusion with other open source products
OceanBase Database Community Edition has implemented in-depth integration and fusion with more than 400 upstream and downstream products in the ecosystem, such as Flink, Canal, Otter, and DataX. We find this very convenient. For example, we can use DataX to extract data to an OceanBase cluster. Our cluster runs a total of 168 ETL tasks in real time.
4. Some usage issues encountered
- When we manage stored procedures in OceanBase Developer Center (ODC), the
REPLACE PROCEDUREcommand is provided but unavailable. To replace a stored procedure, we have to drop it and then create a new one. However, we often need to modify only a small part of a large stored procedure, so we hope that ODC can supportREPLACE PROCEDUREto make it easier to modify stored procedures. - The earlier OceanBase Database Community Edition V3.x does not support DBlinks and does not allow access to and manipulation of tables, views, and data in another database. DBlinks are supported in OceanBase Database Community Edition V4.x.
- The deployment was cumbersome because OceanBase Database Community Edition did not provide the one-click installation package OceanBase All in One at that time.
IV. Summary
We have been paying close attention to OceanBase since 2021 and have used OceanBase Database Community Edition since its initial open source version V3.x. We have verified the feasibility of using OceanBase Database to directly analyze 20 TB of data in real business scenarios. A task that originally required 10 servers can now be completed with only 4 servers, reducing our hardware costs by 60% and freeing engineers from the demanding O&M work caused by the many components of Hadoop.
OceanBase Database supports online analytical processing (OLAP) and online transaction processing (OLTP) workloads with one set of engines. It not only meets our analytical processing performance requirements, but also simplifies O&M and greatly reduces the costs. The advantages of OceanBase Database in performance and storage costs are proven in our business environment.
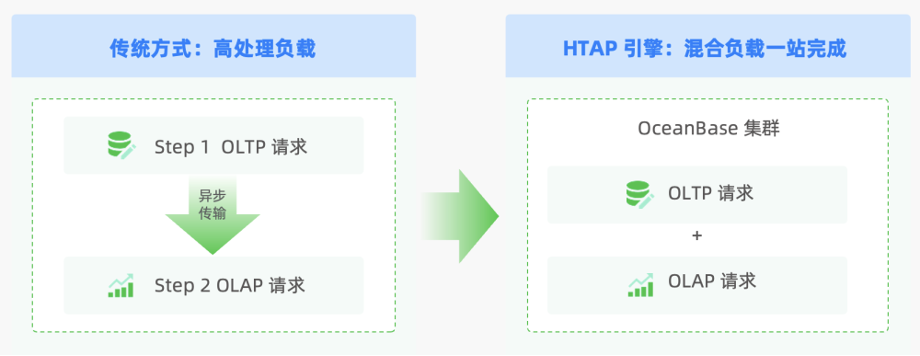
In the future, we will strengthen our cooperation with OceanBase and try to use the wide array of peripheral tools in the OceanBase open source ecosystem to create enterprise-level products.