Performance of Beike’s Real-time Dimension Table Service Improved by 3-4 Times Based on a Flink + OceanBase Solution
Beike, operated by KE Holdings Inc., is an industry-leading digital housing service platform in China. It is committed to promoting the digitalization and intelligentization of China's housing service industry, aiming at pooling and empowering resources to provide Chinese families with all-in-one, premium, and efficient services, from new home and resale transactions to leasing, decoration, local life, and handyman services.
OceanBase Database is a distributed relational database system developed fully in-house by Ant Group and Alibaba Group in 2010. It provides a native distributed architecture that handles enterprises' complex data processing needs with high performance, reliability, and scalability. As one of Alibaba Group's independent innovations in the database industry, OceanBase Database has been deployed group-wide to support Alipay and other core business lines.
Beike has deployed OceanBase Database to support its real-time dimension table service, among things. Replacing HBase, OceanBase Database has improved the performance of the real-time dimension table service by 3-4 times, halved the hardware costs, and greatly reduced the O&M costs.
Drawbacks of an HBase-based Dimension Table Solution and Alternative Solution Selection
In a typical real-time warehouse or real-time business scenario, Flink often associates a fact table with an external dimension table during real-time stream processing, so as to query the dimension table and supplement the information in the fact table. For example, Beike needs to associate the information of an order with the product information in the dimension table involved in real time. Given the fact that a conventional database, such as a MySQL database, can hardly cope with the large data volume of a dimension table and the high real-time QPS of Flink, Beike used to host dimension tables on HBase, which features a distributed columnstore NoSQL architecture. HBase delivers pretty good query performance, but has some drawbacks.
Drawback 1: No support for secondary indexes
In many scenarios, Flink associates dimension tables not only by their primary keys, but also by some other columns. However, HBase supports only a single index based on row keys, and it supports secondary indexes only with the help of extra features provided by, for example, Apache Phoenix, leading to higher development and maintenance costs.
Drawback 2: Multiple dependencies, complex deployment, and high costs
Built on top of the Hadoop ecosystem, HBase relies on Hadoop Distributed File System (HDFS) for persistent data storage, and ZooKeeper for jobs like election, node management, and cluster metadata maintenance. Users must deploy and configure Hadoop, ZooKeeper, and several other components before deploying HBase in the production environment, leading to higher O&M and hardware costs. In some special circumstances, these components even require separate HBase clusters.
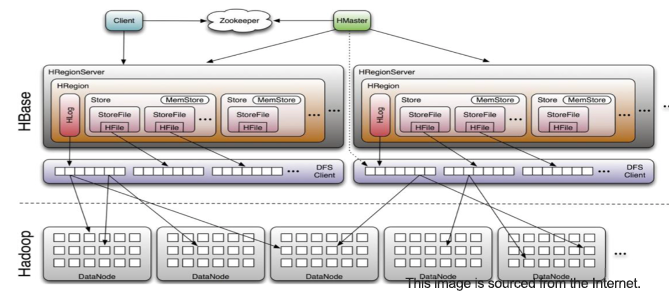
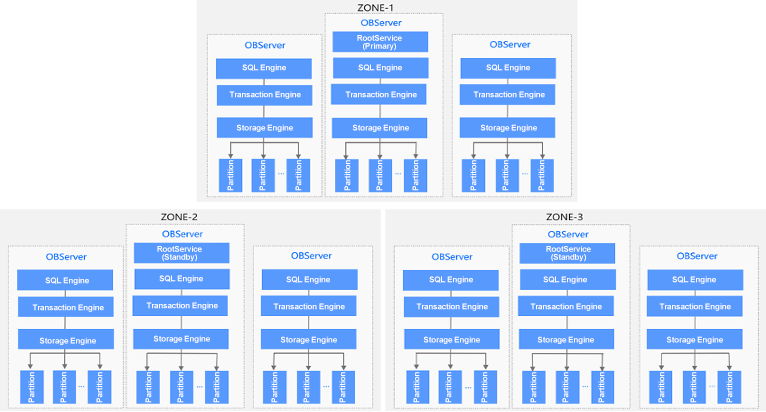
For the above reasons, Beike turned to distributed databases and was attracted by OceanBase Database for its open source architecture, high performance, high reliability, and scalability. Besides, OceanBase Database is a great solution to Beike's business challenges. First, OceanBase Database natively supports secondary indexes. Users can directly create additional indexes on a dimension table to improve its query performance. Second, OceanBase Database relies only on OBServer instead of any external components. It is inherently highly available and is quite easy to deploy. Third, users can quickly install supporting tools for convenient O&M. For example, users can install tools on GUI-based pages of OceanBase Cloud Platform (OCP) or deploy a cluster by using the command line interface (CLI) of OceanBase Deployer (OBD).
The hardware cost of the HBase-based solution is about 2 times that of a solution based on OceanBase Database. HBase requires two HRegionServer nodes to ensure high availability, and stores three data replicas in Hadoop storage, which means that an HBase cluster usually maintains six data replicas. If the cluster is small, the use of ZooKeeper and Hadoop will leave many redundant servers. On the contrary, OceanBase Database stores three data replicas, reducing the hardware cost by half.
Therefore, Beike intended to substitute OceanBase Database for HBase to support its real-time computing platform. Before hammering out a decision, however, Beike ran a test to comprehensively compare the performance of OceanBase Database and HBase in 1-to-1 and 1-to-N association of real-time dimension tables.
Performance Comparison between OceanBase Database and HBase
1. Prepare the environment
The OceanBase and HBase clusters for the test were respectively deployed on three Dell EMC PowerEdge R740 servers, each with 80 CPU cores, 188 GB of memory, and a 2.9 TB NVMe SSD. All test tasks were executed in the same real-time Hadoop cluster. HBase 1.4.9 was used, and the HBase cluster was deployed and configured by the HBase database administrator. OceanBase Database V3.1.2 was used, with all parameters set to the default values.
2. Test plan
To verify the impact of dimension table size on query performance, datasets of 100 million, 20 million, and 100 thousand rows were prepared and inserted into the OceanBase and HBase clusters respectively. The values of the primary key of the table in the OceanBase cluster (rowkeys in the HBase cluster) were the sequential values from 1 to the number of the last test data row. The following example shows the CREATE TABLE statement and sample data:
show create table tb_dim_benchmark_range_partitioned;
create table tb_dim_benchmark_range_partitioned
(
t1 bigint(20) NOT NULL,
t2 varchar(200) DEFAULT NULL,
……
t30 varchar(200) DEFAULT NULL,
)
PRIMARY KEY (t1)
) DEFAULT CHARSET = utf8mb4
ROW_FORMAT = COMPACT
COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE =
134217728 PCTFREE = 0
partition by range(t1)
(partition PT1 values less than (10000000),
partition PT2 values less than (20000000),
partition PT3 values less than (30000000),
partition PT4 values less than (40000000),
partition PT5 values less than (50000000),
partition PT6 values less than (60000000),
partition PT7 values less than (70000000),
partition PT8 values less than (80000000),
partition PT9 values less than (90000000),
partition PT10 values less than (100000000));
select * from tb_dim_benchmark_range_partitioned limit 1;

To prevent the impact of dependent components (such as physical sources and sinks) on the performance of dimension table association during the test, the DataGen SQL connector (supporting the generation of random or sequential records in memory) and BlackHole SQL connector (taking in all input data for performance testing) were installed as data sources for SQL testing.
CREATE TABLE data_gen_source (t1 BIGINT, t2 VARCHAR, proctime AS PROCTIME()) WITH (
3. Test results
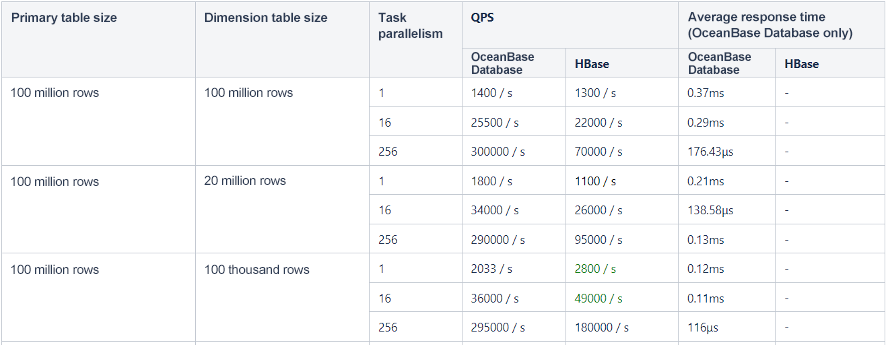
- The following table shows the test data of 1-to-1 dimension table association, where the random values generated by DataGen were associated with index columns in the OceanBase cluster and rowkeys in the HBase cluster.
- The following table shows the test data of 1-to-N dimension table association, where the random values generated by DataGen were associated with secondary index columns in the OceanBase cluster.

Four conclusions can be drawn from the test results:
- For the dimension table with 20 million or 100 million rows (a large data volume), OceanBase Database outperforms HBase in terms of QPS if the task parallelism is low, and the performance of OceanBase Database is 3-4 times higher than that of HBase given a high task parallelism, which is a significant improvement.
- For the dimension table with 100 thousand rows (a small data volume), the QPS of HBase is slightly higher than that of OceanBase Database if the task parallelism is low, and OceanBase Database has obvious advantages given a high task parallelism.
- OceanBase Database delivers unsatisfactory performance in association by non-indexed columns. In a production environment, therefore, columns to be associated should be indexed for the association of a large dimension table. The functionality of Beike's real-time computing platform can be optimized. For example, if a user has associated non-indexed columns, the SQL diagnostics feature will prompt the user to create indexes.
- OceanBase Database exhibits great performance in 1-to-N association by secondary index columns, which means it meets high QPS requirements.
Summary
The test results indicate that, in the same environment, OceanBase Database shows better overall performance than HBase, let alone its native support for secondary indexes, simple deployment, and lower hardware and O&M costs. Eventually, Beike chose OceanBase Database to store dimension tables for its real-time computing platform.
Beike first deployed OceanBase Database Community Edition V3.1.2 and found that it does not support Time to Live (TTL) for regular relational tables. The good news is that OceanBase Database V3.1.4 and later support API models such as TableAPI and the HBase API, and OceanBase Database V4.0 supports global secondary indexes. Beike also suggested that OceanBase further strengthen its connections with the big data ecosystem to better support the import/export of big data to and from OceanBase Database.