From MySQL to a Native Distributed Architecture: Sunvega‘s Roadmap of Full Migration to OceanBase Database
Sunvega Information Technology Co., Ltd. ("Sunvega" or "we" for short), a company that has been steadily growing for 11 years, specializes in the development and application of cloud modeling, cloud rendering, and AI-powered 3D vectorization. Sunvega is dedicated to providing the manufacturing industry with next-generation cloud-based, AI-powered, and integrated design/display/processing solutions, helping enterprises on their road to successful digital transformation and system upgrades. Over the past decade, we have earned widespread recognition for our technical excellence and service quality, establishing us as a leader in our niche market.
We focus on solving the industrial challenges of frontend and backend integration, using cloud-based software to drive industry upgrades. On the frontend, users can easily design their interior spaces on our web pages. On the backend, we make sure that their designs are seamlessly connected to manufacturers, enabling data to flow directly to the production line. This allows for smooth material cutting and final product delivery to customers for installation. With our industrial software, users can effortlessly turn their designs into reality.

Background: A Database Architecture Based on MySQL Sharding
For a modern enterprise like Sunvega, built on cutting-edge technology and digital capabilities, the importance of databases to our business cannot be overstated.
Before adopting OceanBase Database, we deployed our database in a conventional architecture. Initially, we deployed a relational database. However, as the data volume grew rapidly, that database struggled to meet our performance expectations. A few years ago, we adopted a MySQL sharding strategy to cope with the increasing business volume.
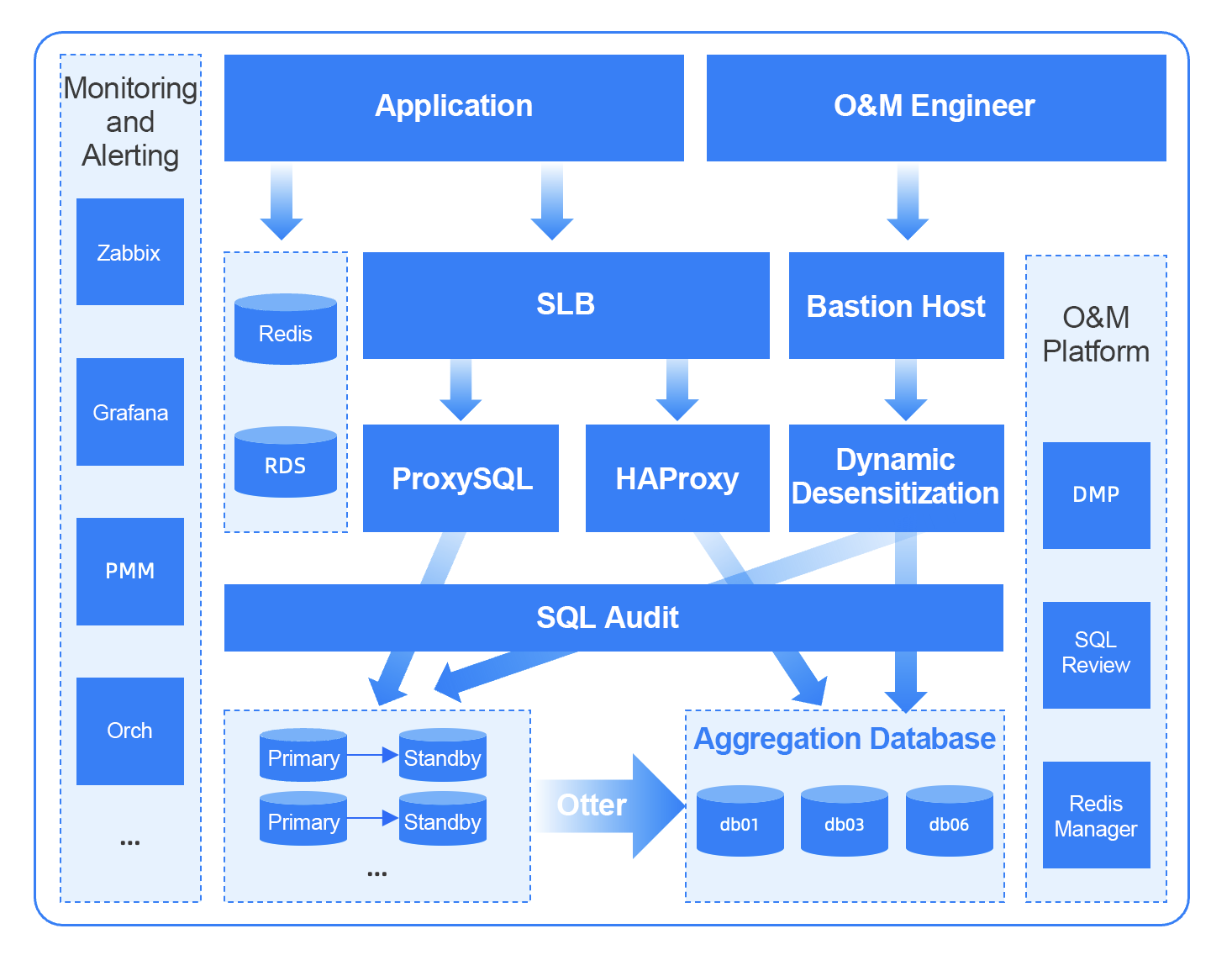
From the architecture diagram, you can see that we deployed a monitoring module and an O&M platform to maintain system stability. The core parts sitting in the middle provide key features of the system. Incoming application requests are first distributed by a load balancer to various middleware for processing, and then routed to MySQL databases and an aggregation database, where data write and read operations are handled separately.
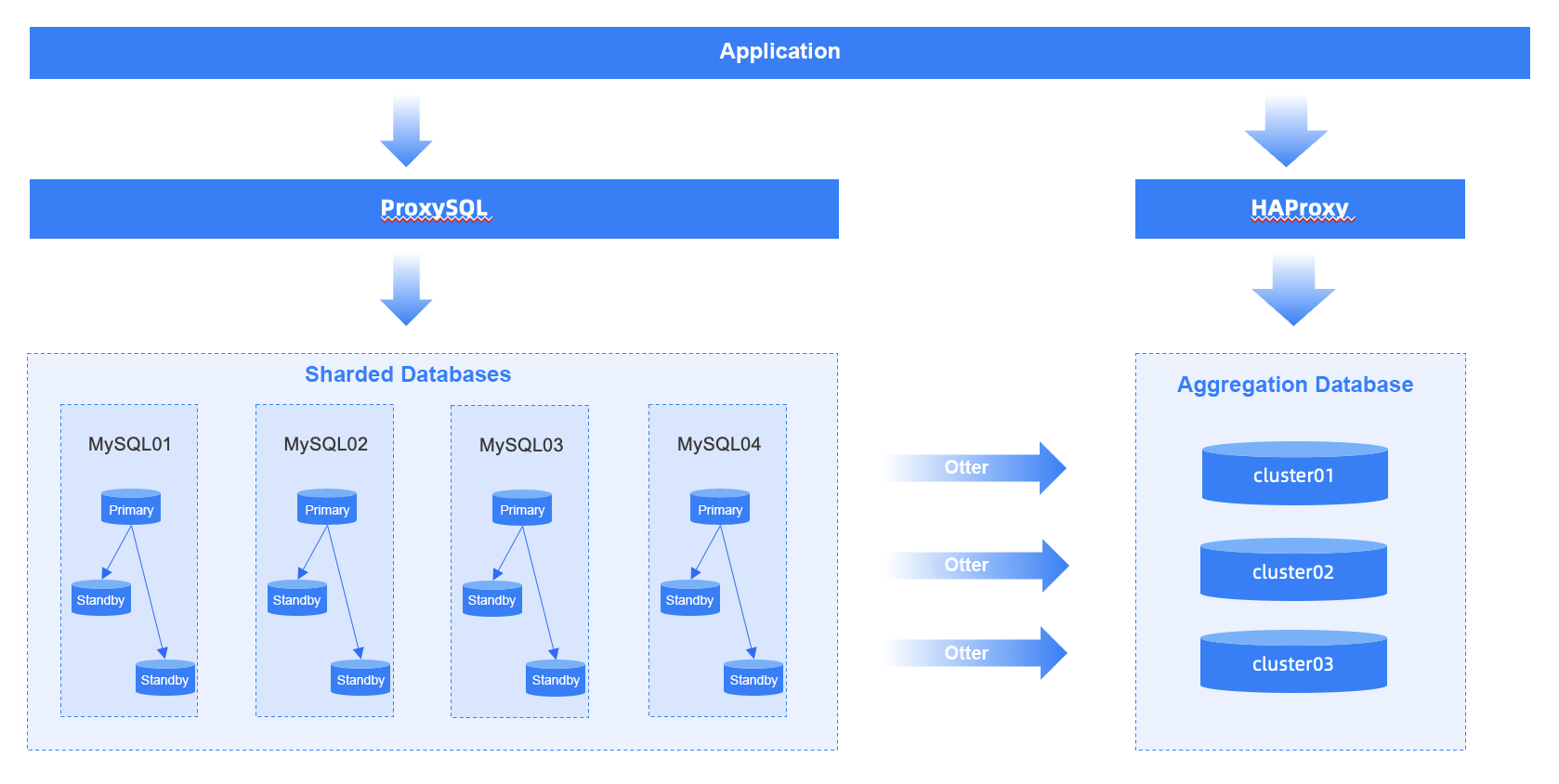
In this architecture, application requests are routed to sharded MySQL databases by the middleware ProxySQL, a common practice when dealing with large tables. However, such sharded MySQL databases could not process real-time requests forwarded by HAProxy with expected performance in a distributed environment, so we deployed an aggregation database of a well-known Chinese vendor to handle read operations.
In short, this architecture handled write and read requests separately. Read requests that involved global operations, had high requirements for real-time performance, and could not be handled directly by the big data backend were forwarded by HAProxy to the aggregation database for fast processing.
Business Challenges: Why Sunvega Switched from MySQL Sharding to a Native Distributed Database Solution
While the MySQL sharding strategy helped relieve the increasing database workload in the short term, it posed challenges in terms of performance, O&M, and costs.
Performance issues: As the data volume grew, MySQL databases hit significant performance bottlenecks in handling large tables. Complex queries also led to inefficiency.
O&M drawbacks: The architecture was complex. It consisted of sharded databases, with multiple standby databases for each primary database, making schema changes particularly difficult. For example, altering a table schema could require changes across hundreds of tables, a time-consuming and risky process.
Additionally, the large number of instances and nodes required more third-party middleware for read-write splitting and data synchronization, increasing potential failure points. Data synchronization, in particular, could be stuck if schema change operations were performed on a large table, resulting in prolonged data read latency that might affect the service stability.
Cost concerns: The sharding strategy significantly increased the number of upstream servers. Besides, more servers are required to deploy middleware components and high availability features, driving up overall costs.
These challenges compelled an alternative database solution. To address the growing data volume and increasingly complex business requirements, a native distributed database became the preferred choice.
Why Sunvega Chose OceanBase Database
We adhered to the following principles in database selection:
-
Technical excellence: The database must provide strong technical capabilities.
-
Long-term viability: We wanted a solution that would meet our needs for the foreseeable future, avoiding repeated selection and investment.
-
Smooth migration: Compatibility with MySQL was crucial to minimize development efforts and ensure a seamless migration.
Then, we conducted comprehensive tests on several popular distributed databases in typical scenarios. Based on their actual performance, we decided to upgrade our database system to OceanBase Database. Now, let's learn more about the test results:
Test 1: DDL operations
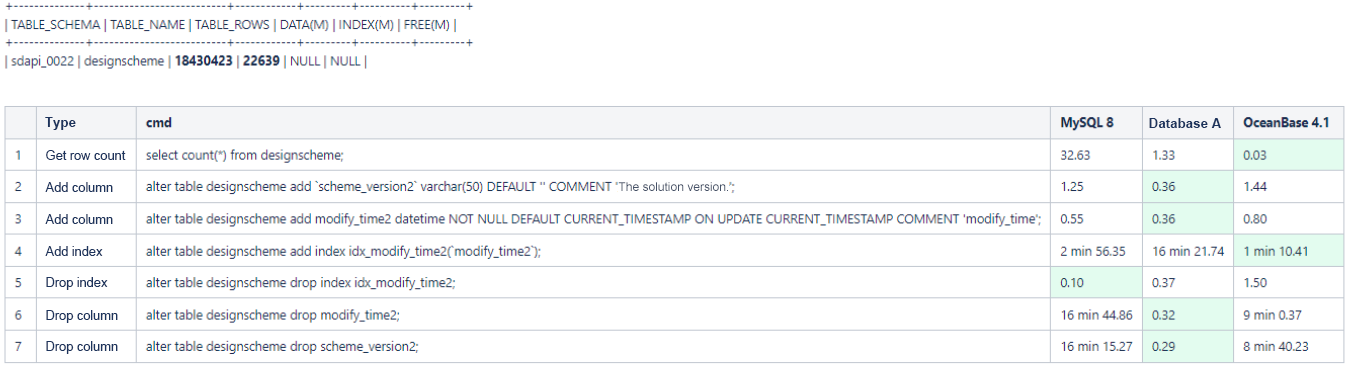
First, we tested operations like adding columns, deleting columns, and adding indexes on large tables.
-
Adding columns: After comparison, we found that both MySQL and our previous domestic distributed database (let's call it database A) showed significant performance improvements in adding columns, without requiring complex operations such as creating temporary tables like a few years ago. All tested databases could now complete this task in seconds.
-
Deleting columns: This operation is rare in our business scenarios. We didn't take it as a major focus in the assessment.
-
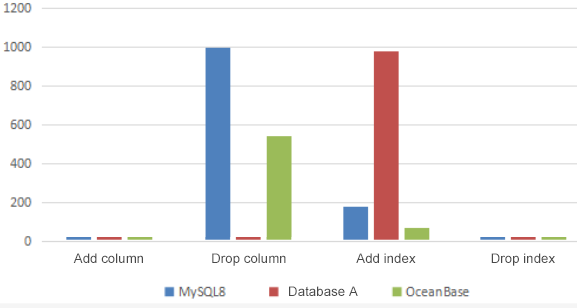
Adding indexes: This operation is performed more frequently than adding columns, especially when new business features are launched. We placed great importance on its performance. In our business practice, we noticed that OceanBase Database performed index operations twice as fast as MySQL 8.0 and over 15 times faster than database A. The results not only met our expectations but surprised us in some aspects.
Test 2: Data compression
Data compression is one of the standout features of OceanBase Database. In the test, the storage usage of OceanBase Database was less than one-third that of MySQL and one-fifth that of database A. The figure below shows the measured storage usage, providing strong evidence that OceanBase Database is quite cost-saving.

Test 3: QPS performance
We tested their QPS performance with our actual online traffic data. Database A consisted of four servers (each with 96 CPU cores, 192 GB of memory, and 1.5 TB of storage space), while OceanBase Database consisted of two servers (each with 62 CPU cores, 400 GB of memory, and 1.5 TB of storage space). The test results are shown in the figure below.
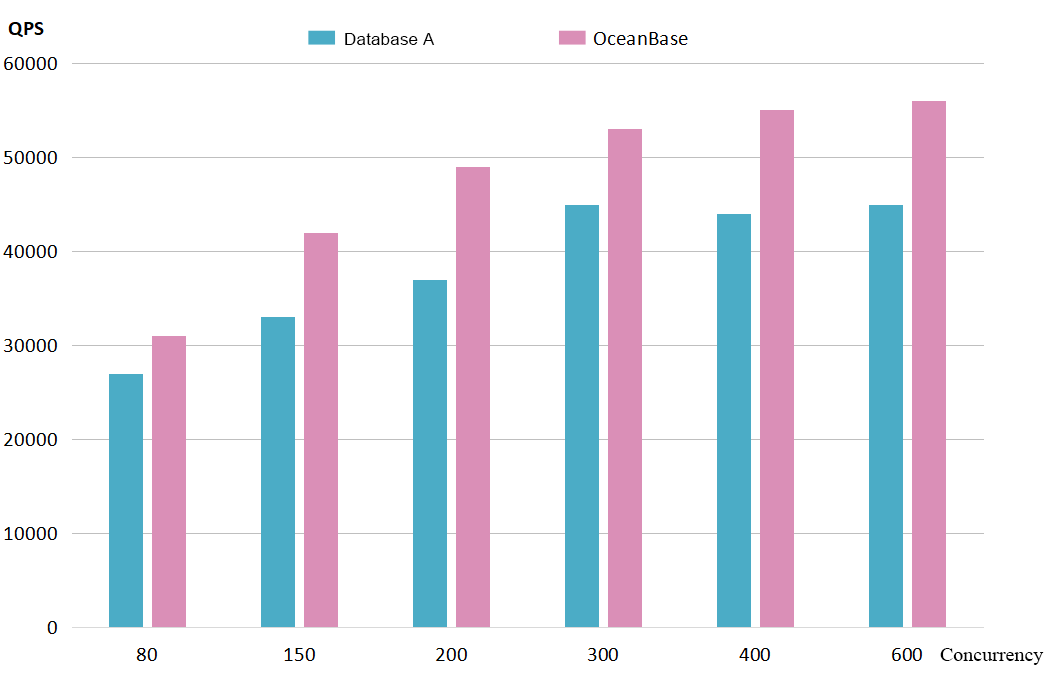
You may have noticed that we configured slightly more memory resources for OceanBase Database. This is because fewer CPU cores were configured for it. The test results also indicated that OceanBase Database required half the hardware resources of database A. As shown in the preceding figure, as the concurrency increased from 80 to 600, OceanBase Database outperformed database A in both performance and efficiency.
Test 4: Linear scalability
To better observe the linear scalability of OceanBase Database, we also tested its performance under our actual business traffic with different tenant resource specifications, ranging from 8 CPU cores and 35 GB of memory (8C35G) to 62C400G.
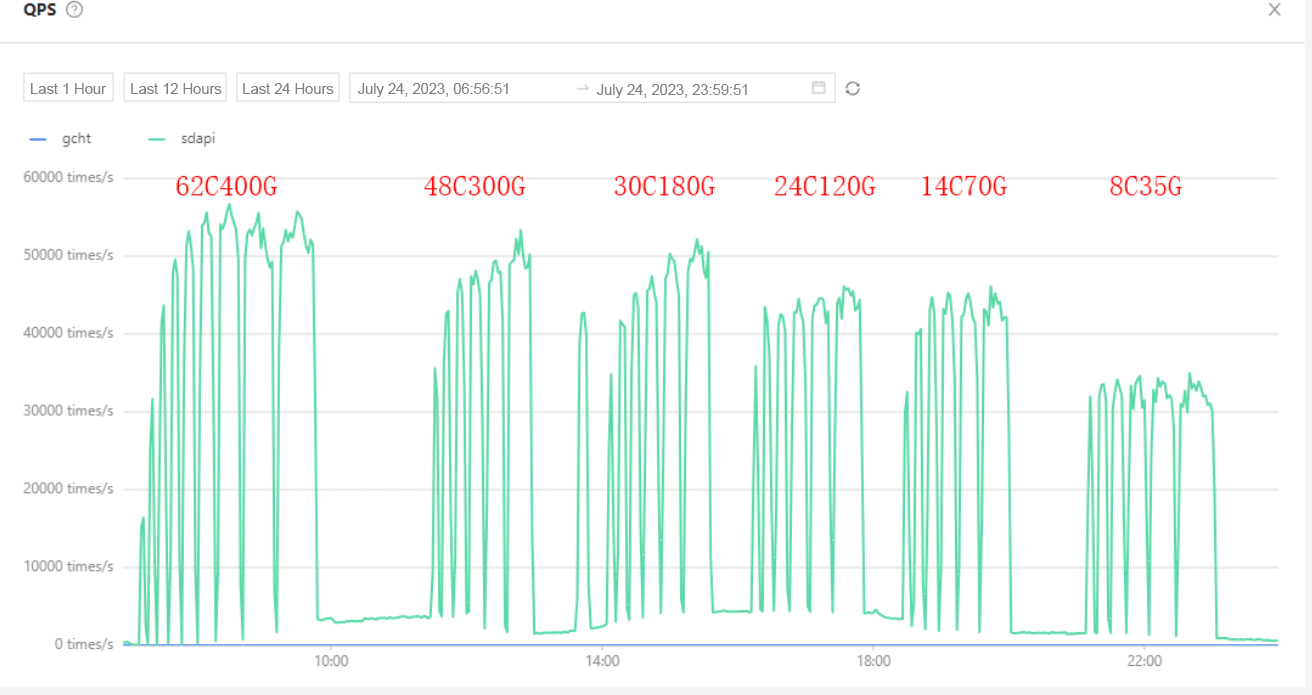
The results showed that as tenant resources increased, the performance of OceanBase Database improved steadily. The performance increment from 48C300G to 62C400G was less noticeable because the stress testing client had reached its performance limit and couldn’t provide higher traffic. Our goal was to find a product that could meet our business needs and adapt to different requirements as our business grew.
Test 5: Traffic replay
We were more concerned with the performance of OceanBase Database in real business scenarios rather than its theoretical limits in TPC-C benchmarks. We selected a real business interface and replayed its daily traffic with different multiples to test the maximum QPS supported by OceanBase Database and verify whether it could handle our current online traffic. In the test, OceanBase Database could handle our peak QPS when the concurrency was set to 40, and its performance improved significantly as the concurrency increased. Its performance was three times the peak of our previous database when the concurrency was set to 400. When the concurrency was set to 600 or greater, the performance plateaued because the stress testing client had reached its limits. Since the peak performance had far exceeded our expectations, we didn’t scale up the client for further tests.
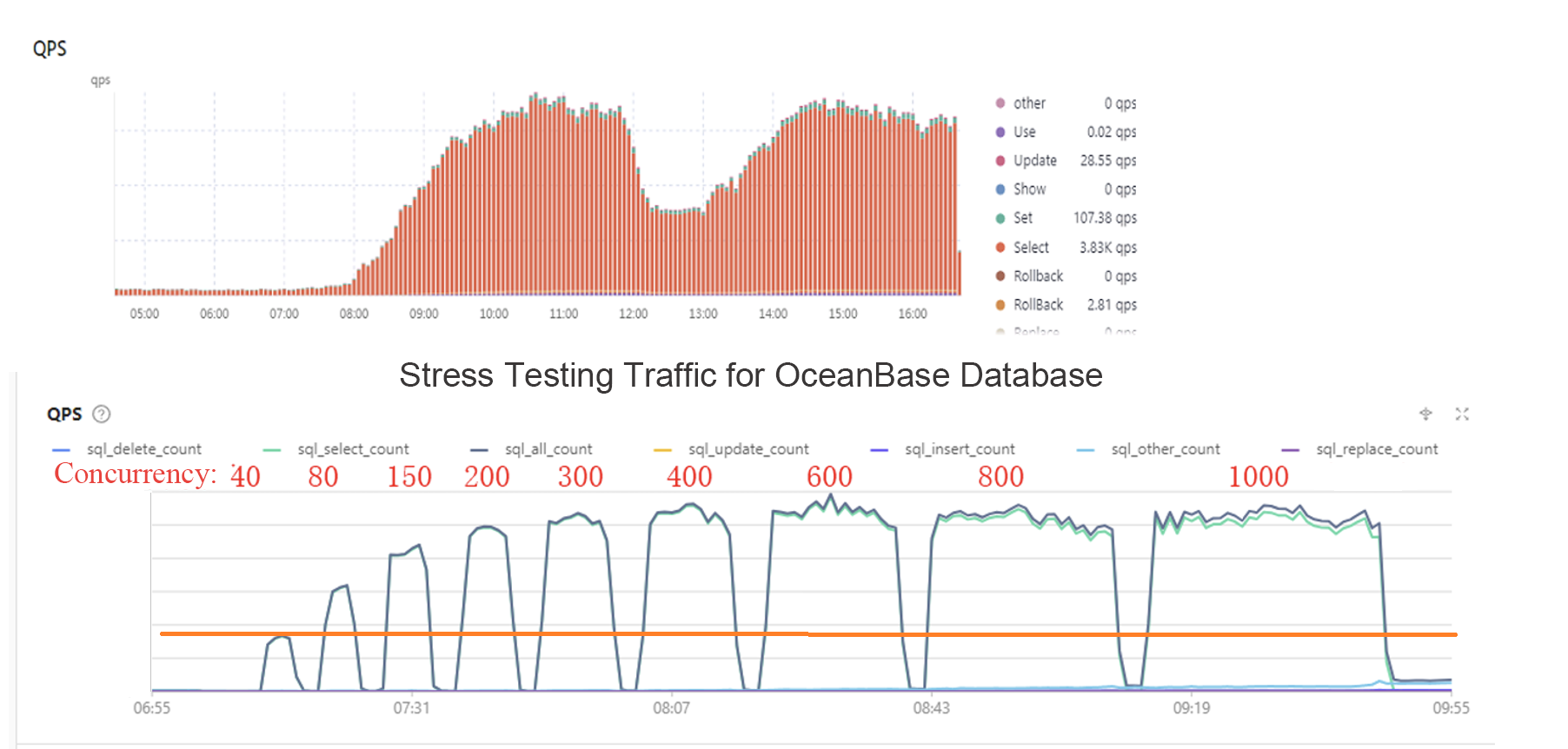
Given the test results, we concluded that OceanBase Database could handle our business traffic.
Full Migration to OceanBase Database
In fact, we started testing OceanBase Database in October 2022.
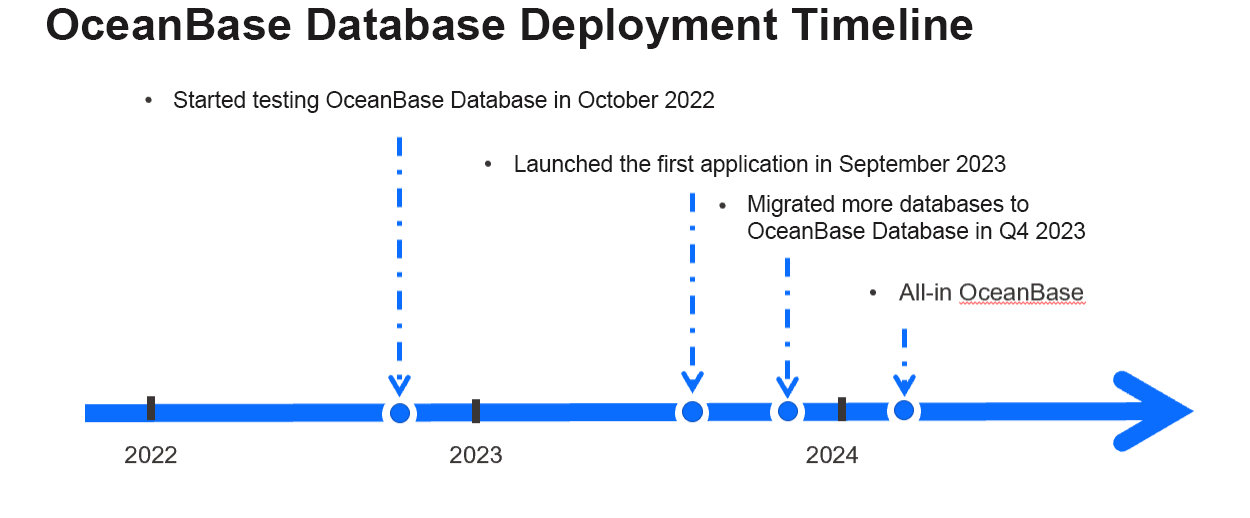
At the time, OceanBase Database just became open-source not long ago, and we thought it was worth a shot. Then, we spent a year or so testing it extensively, just to be assured of its stability and reliability.
In September 2023, we deployed OceanBase Database for a pilot project, and built confidence in its performance after months of stable operation. We then gradually migrated more databases to OceanBase Database. By the beginning of 2024, we had migrated all core business systems to OceanBase Database.
Here are some hiccups during our migration process. OceanBase Database provides various tools to meet user needs, such as system assessment, data synchronization, and data collection. However, we needed some unique tools for real-time traffic replay and continuous optimization during the migration process.
During testing, we needed an application to provide all data during a period at a time, but also replay traffic in real-time. Facing this challenge, we decided to automate the process using an in-house traffic capture tool. It could capture and analyze the traffic, extract key information in real time, and then forward the traffic to the new database.
Given the differences between the new and old databases, we had to optimize SQL statements while doing traffic replay. We must also test SQL performance and prepare indexes in advance to ensure migration performance. After rounds of preparation, we began switching our production traffic. The following screenshot shows the real process back then. Since this pilot project involved only read traffic, we were able to switch it in batches to ensure a successful result.
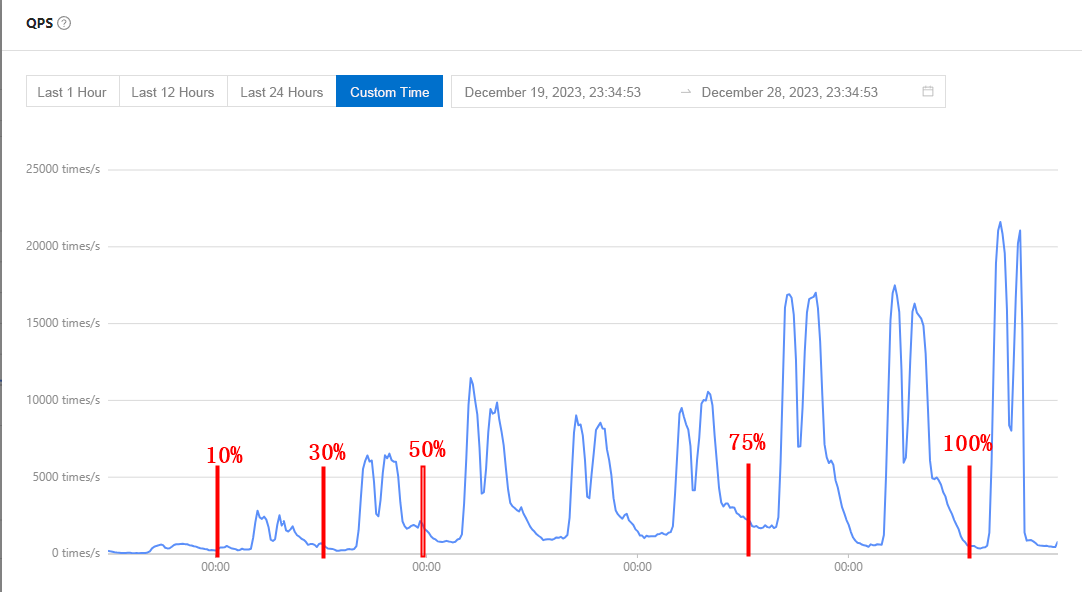
We started with 10% and observed the performance for a day, and then increased it to 30% the next day, followed by 50% and 75%. After about a week, we switched 100% of the traffic to OceanBase Database.
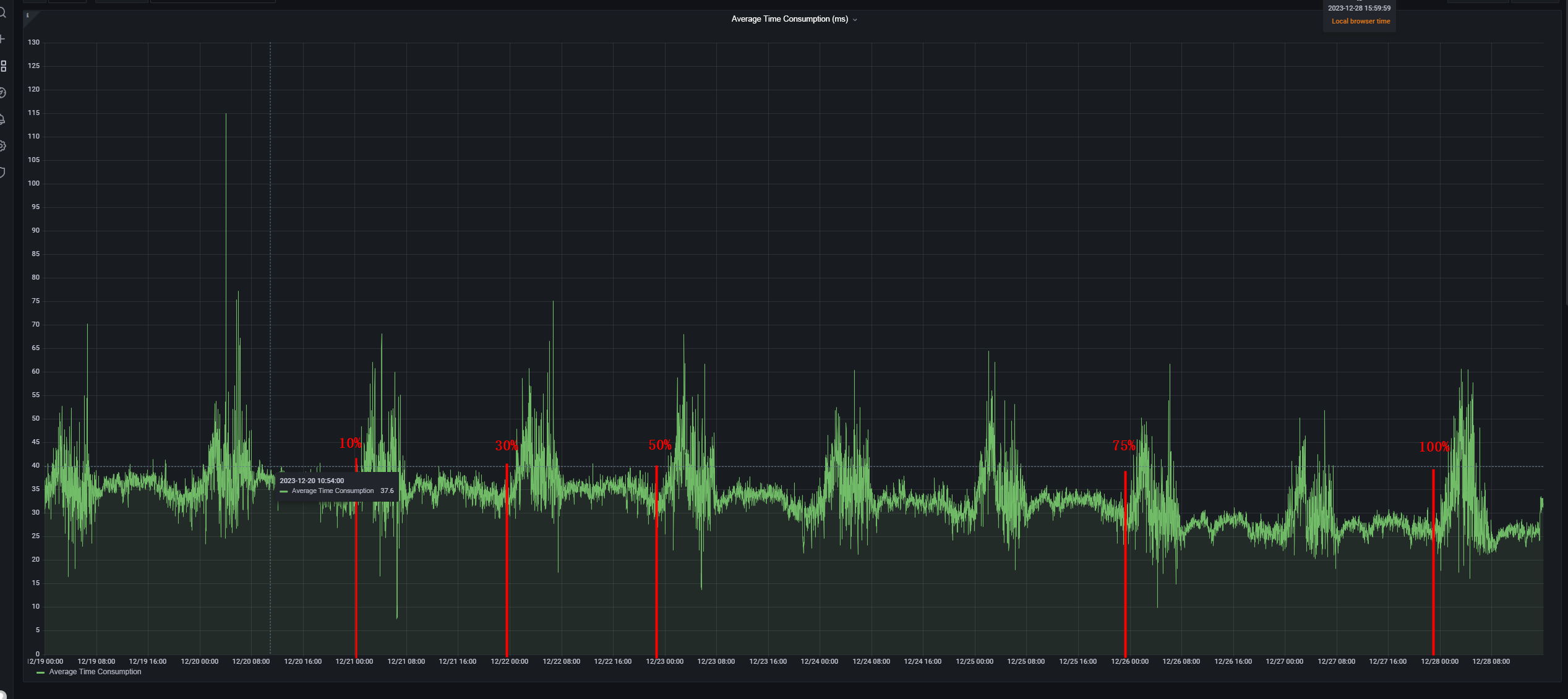
To test the application response time, we also embedded a tracking checkpoint into the application. You can see from the following screenshot that the response time decreased gradually. This indicated that, after switching to OceanBase Database, application performance improved significantly with faster response.
Why We Migrated Our Full Stack to OceanBase Database
OceanBase Database has brought us transformative benefits.
As we removed most middleware and integrated the monitoring module into OceanBase Database, we now have a streamlined architecture that is easier to maintain with reduced failure points.
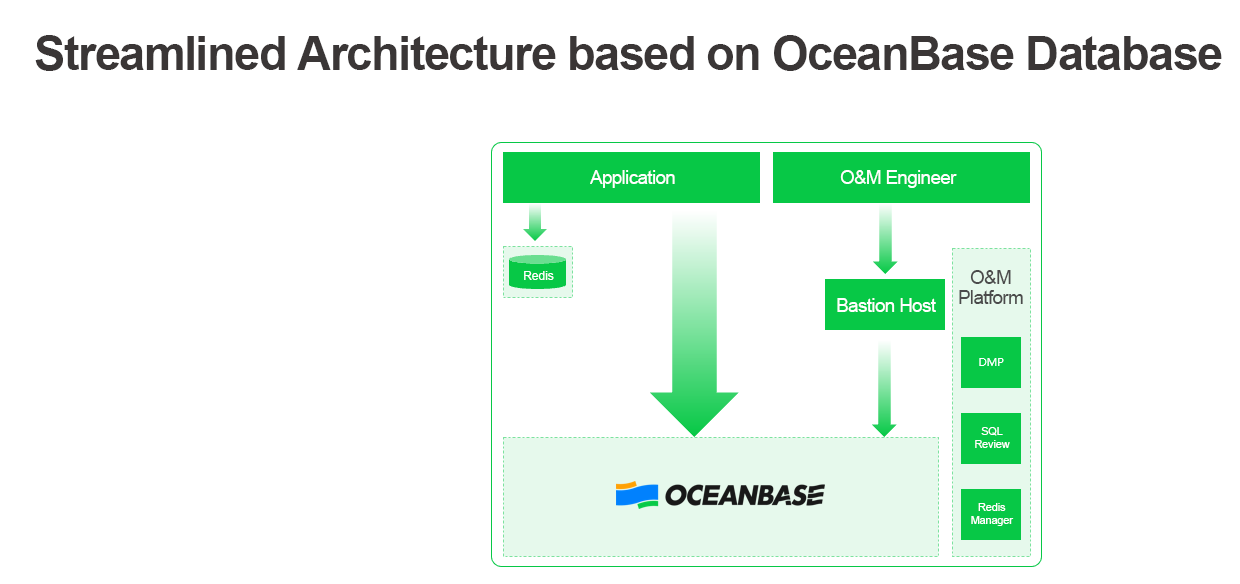
In addition to high performance and auto-scaling, OceanBase Database also provides native failover capabilities. In our test, we manually shut down a node to verify automatic failover. The results met our high-availability requirements.
Furthermore, the overall cost of OceanBase Database is about 30% less than that of the previous architecture. This is attributed to its powerful distributed data processing capabilities.
Having noticed frequent cloud service failures lately, we have put forward the multi-cloud strategy, which aims to spread risk and ensure business continuity and stability.
Specifically, we need to deploy resources also on Cloud B instead of relying solely on Cloud A. This way, we can immediately switch to Cloud B, if our services on Cloud A fail.
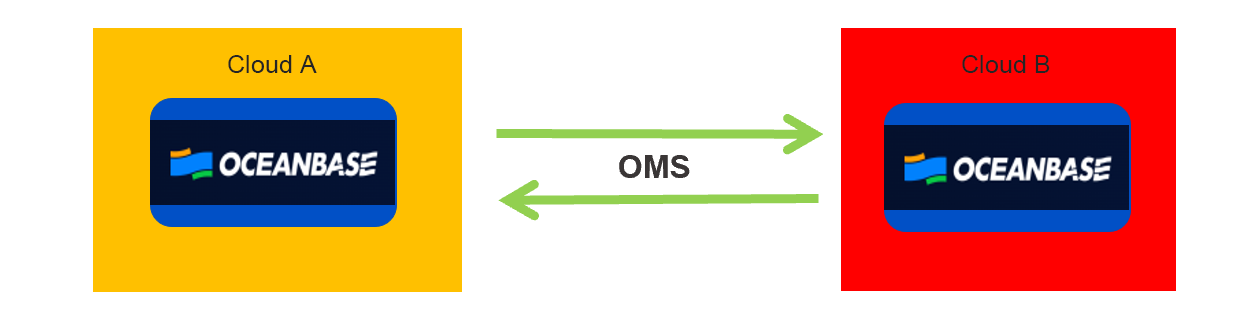
This strategy can hardly be applied on our previous sharded architecture, which consisted of numerous middleware, components, and servers. On the contrary, the architecture based on OceanBase Database is greatly streamlined, making it much easier to achieve our goals. OceanBase Migration Service (OMS), a powerful and user-friendly data migration tool, further simplifies the implementation of the strategy. We have already begun building this multi-cloud architecture, which is expected to work within the next six to twelve months.
Summary
During the migration, we encountered some minor issues and bugs, most of which have been fixed. I'd like to talk about our solutions for your reference.
Issue 1: Columns involved in the ORDER BY clause are pre-validated in MySQL and OceanBase Database.

This issue was a bug due to incompatibility with database A. If the ORDER BY clause was executed in database A, and it involved a column with equal values existing in two tables, database A simply extracted and sorted data without validating which table the column belonged to. In MySQL of a later version or OceanBase Database, however, the system validates the column before SQL execution. The good news is that this issue rarely occurs.
Considering that heterogeneous architectures or products can never be fully compatible, I strongly recommend performing traffic replay to identify compatibility issues, which may occur not only when switching to a database of a different vendor, but also during version upgrades of the same database, such as from MySQL 5.7 to 8.0.
Issue 2: During database migration or cross-database operations, if two columns from two databases are declared of the same type and have same values, calling the same function in the application to process the values might yield different results in the two databases.
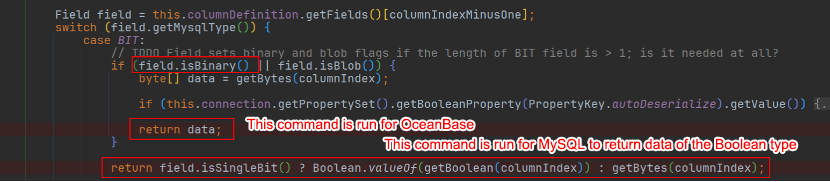
For example, a database calls the field.isBinary() function to check whether the retrieved value is binary data, and then executes different logic depending on the result. A MySQL database considers TINYINT(1) as the BIT type, so the field.isBinary() function returns false for TINYINT(1). OceanBase Database considers TINYINT(1) as a binary type, so the field.isBinary() function returns true for TINYINT(1). In other words, the same input to the same function may result in different return values in different databases.
Issue 3: OceanBase Database uses too many IN operators, and is likely to trigger full table scans. To address this, execution plans need to be bound.
We recommend you perform continuous traffic replay, because the same SQL statement may return different values in different databases, which is inevitable. By replaying traffic, we can identify and address performance issues in business logic.
In a MySQL database, for example, you may encounter complex SQL queries involving complex logic. These queries may affect tens of thousands of rows due to inappropriate logic design, which is usually avoided in well-managed companies. However, undertrained developers may write such code, leading to differences in SQL execution plans and index selection. During traffic replay, it’s essential to intervene early, binding execution plans and selecting indexes to ensure the efficiency and accuracy of SQL queries.