DMALL —— a summary of database selection experience in SaaS scenarios
Feng Guangpu, head of the Dmall database team, is responsible for the stability of OceanBase, TiDB, MySQL, Redis, and other databases of Dmall and the construction of its database platform as a service (PaaS) model. Feng has a wealth of experience in multi-active database architecture and data synchronization schemes.
Yang Jiaxin, a senior DBA at Dmall, is an expert in fault analysis and performance optimization and loves exploring new technologies.
As the largest retail cloud solution and digital retail service provider in Asia and the only end-to-end service provider of omnichannel retail cloud solutions in China, Dmall conducts business in six countries and regions. Therefore, its model has been widely verified. The development of Dmall is a microcosm of the retail digitalization process in China and even the world.
However, the rapid business growth and impressive business achievements have been accompanied by many challenges in retail software as a service (SaaS) scenarios and business system bottlenecks. This article takes a look at the data processing pain points in retail SaaS scenarios from the business perspective. It gives a glimpse into how Dmall improves its read and write performance and lowers storage costs while ensuring the stability and reliability of its business database.
Characteristics and pain points of retail SaaS scenarios
Dmall markets its services across borders. In China, our customers include large supermarkets, such as Wumart and Zhongbai, as well as multinational retailers, such as METRO AG and 7-Eleven. Dmall also serves many Chinese and international brands. It links brand owners, suppliers, and retailers with smooth data and information flows so that they can better support and serve consumers.
The long service chain, from manufacturers, brand owners, and suppliers, to retailers in various shopping malls and stores, and finally to consumers, generates massive data volumes. The system complexity increases exponentially with the data volume. As a result, the retail SaaS system of Dmall faces three major challenges:
-
High O&M complexity
Dmall uses a microservice architecture that involves many business links in the overall process and a large system application scale. Dmall already has more than 500 databases. Moreover, as our system continue to iterate, the data scale continues to increase, and O&M management is becoming more and more difficult.
-
Fast business growth and frequent need for horizontal scaling
Dmall formulated a global expansion strategy to cope with its business growth. According to the requirements of regional data security laws, we need to deploy a new system to undertake business traffic outside China. It is hard to predict future business scale and data growth in the initial deployment phase. Therefore, database resource allocation in the initial deployment phase is quite difficult. The common practice is to deploy the system with limited resources at low costs. However, rapid business growth and exponential data increase will require quick scaling.
-
The need to serve a large number of merchants in the same cluster
The number of stock keeping units (SKUs) of different convenience stores and supermarket chains ranges from thousands to tens of thousands. Therefore, it is impossible for us to deploy an independent system for each customer. This means that our SaaS system must support hundreds of small and medium-sized business customers, and the data generated by all merchants share database resources at the underlying layer. Moreover, we have massive individual tenants in our system, such as large chain stores. We want to isolate the resources for these tenants from those for others.
In short, our database needs to support a huge data scale and cope with rapid data growth.
Why we chose a distributed database
To address the aforementioned issues and requirements, we started looking for a new database solution. A distributed database provides larger capacity, transparent scaling, financial-level data security, higher development efficiency, and lower O&M costs. Therefore, it can better support our business development. Due to these benefits and advantages, we believe that distributed databases will become the prevalent trend in the data field. This is why we only looked at distributed database products during our database selection process.
Business-based database selection considerations
First of all, we have many MySQL databases each with over 4 TB of data, and the data size is still growing rapidly. After we migrated our largest MySQL database to a distributed database, the data size increased to 29 TB. Our DBAs are very concerned about the capacity bottleneck of MySQL:
- We have a few choices. We can continue to push R&D for data cleanup and data archiving, but this may delay other R&D jobs such as upgrades to better address our business needs.
- Alternatively, we can continue to expand the disks. This method may be easier to carry out on the cloud. The size of a single cloud storage disk can reach 32 TB or even larger. However, as the data volume continues to grow, this method simply puts the problem off, rather than solving it. In the end, the problem will simply become more and more difficult to solve.
We can also choose the database and table sharding solution, but this is an intricate and highly risky solution, and requires several months for code reconstruction to guarantee SQL capabilities.
Therefore, we want to utilize the transparent scaling capabilities of distributed databases to smoothly support rapid business growth.
First, we aim to reduce the O&M complexity and costs while ensuring system stability. If we think of a MySQL database as an egg and a MySQL instance as a basket, how many MySQL instances should we deploy to house 1000 databases? Which databases should we put on the same instance? If we put two resource-demanding databases in the same instance, resource preemption may occur. In addition, some workloads have special requirements. For example, although payment transactions generate only a small amount of data, they have high business requirements. Therefore, a payment transaction database cannot be deployed in the same instance as other databases. Because of different businesses, different priorities, different data growth rates, and different QPS requirements, DBAs often need to "move eggs from one basket to another". This creates major O&M challenges, not to mention high resource costs. We hope that we can solve this problem with distributed databases, enabling automatic "egg relocation".

Second, we expect distributed databases to help us achieve high cluster availability. We mainly use MHA and Orchestrator to implement high availability for MySQL clusters. However, they are all in the form of "plug-ins", which does not solve the split-brain issue caused by network partitions. The database and high-availability component are two independent pieces of software. Therefore, they lack consistency and coordinated control. High-availability architectures like MySQL Group Replication are reliable because they are based on the Paxos or Raft distributed consensus protocol just like distributed databases such as OceanBase Database and TiDB. Such an architecture can achieve a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 30s.
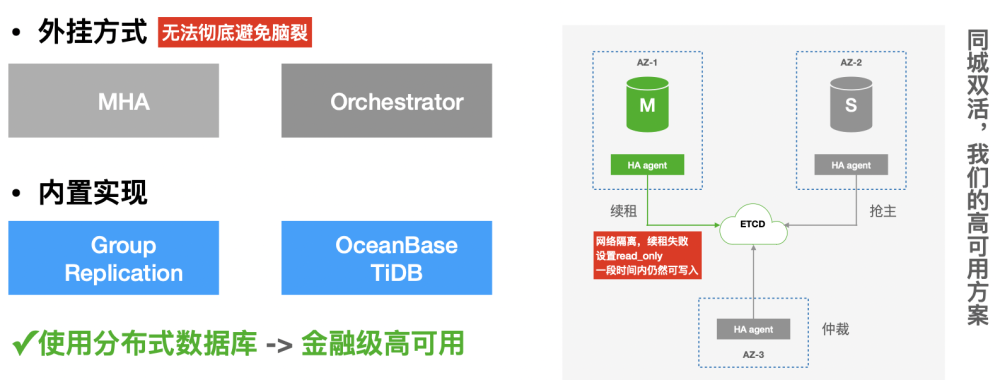
Database selection based on test data
Based on the above database selection considerations, we chose the native distributed database OceanBase Database. We then compared the storage costs and QPS performance of OceanBase Database with MySQL Database in terms of table reading and writing, table reading, and table writing. The following table shows the configurations used for this test.
| OceanBase Database | MySQL Database | |
|---|---|---|
| Community Edition | v4.1.0 | v5.7.16 |
| Memory | Tenant memory size: 16 GB | innodb_buffer_pool_size: 16 GB |
| Single-node configuration | 32C RAID10 SSD | 32C RAID10 SSD |
| Disk flush configuration | Forcible disk flush by default | sync_binlog = 1 and innodb_flush_log_at_trx_commit = 2 |
| Degree of parallelism (DOP) | 5, 10, 20, 30, 60, and 120 | 5, 10, 20, 30, 60, and 120 |
| Test modes | read_write, read_only, and write_only | read_write, read_only, and write_only |
| Duration of a single test | 300s, for a total of 18 tests (Concurrency x Number of test modes) | 300s, for a total of 18 tests (Concurrency x Number of test modes) |
| Test method | Run the obd test sysbench command (that comes with OBD), which will run the sysbench prepare, sysbench run, and sysbench cleanup commands in sequence. | Run the obd test sysbench command (that comes with OBD), which will run the sysbench prepare, sysbench run, and sysbench cleanup commands in sequence. |
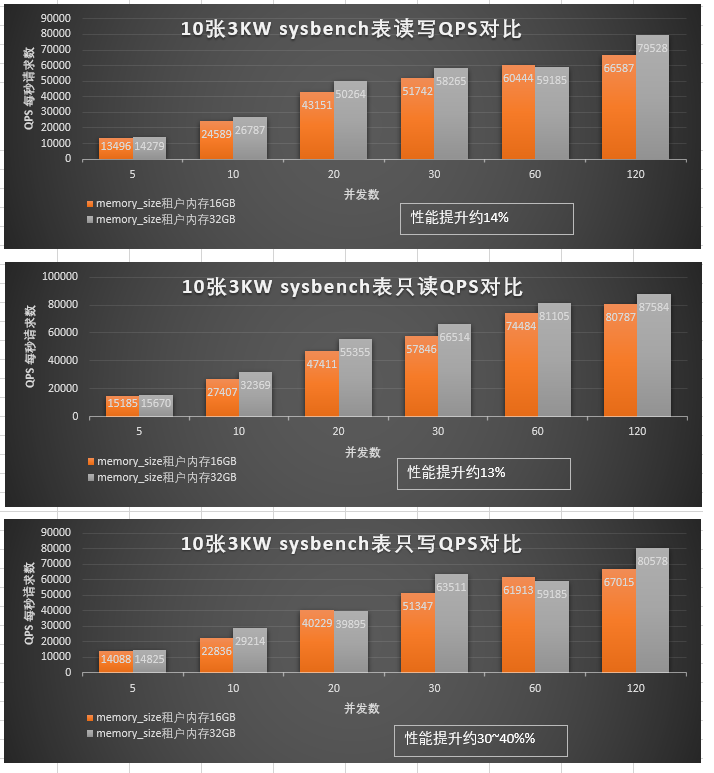
Given the same configurations, MySQL Database performs slightly better than OceanBase Database in the Sysbench test with ten tables, each containing 30 million data rows, when the DOP is less than 200. However, in terms of both QPS and latency, the performance of OceanBase Database approaches that of MySQL Database when the DOP increases.
OceanBase Database in different configurations
In the standalone deployment mode, the read and write performance is also affected by the mode of accessing the OBServer nodes.
The performance is 30% to 50% higher when the OBServer nodes are directly accessed than when they are accessed through OBProxy.
Therefore, for the standalone deployment mode, we recommend that you directly connect to OBServer nodes to avoid the extra costs of accessing OBServer nodes through OBProxy.

Performance also varies with tenant memory configurations. We can see that the performance of a tenant with 32 GB of memory is 14% higher than that of a tenant with 16 GB of memory.
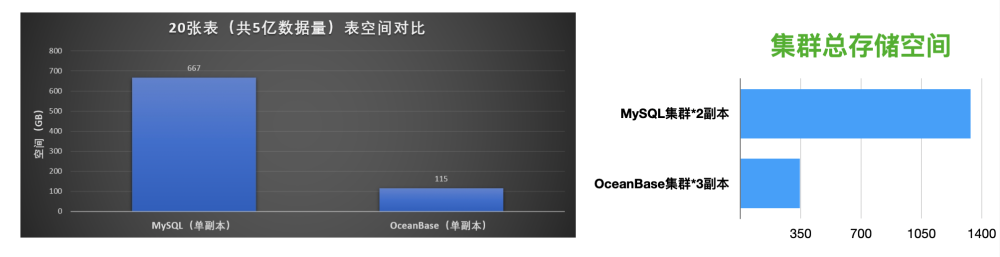
Tablespace comparison between OceanBase Database and MySQL Database
In the monitoring snapshot scenario in the production environment, after we migrated 20 tables with a total of 0.5 billion data rows from MySQL Database to OceanBase Database, the tablespace usage was reduced by a factor of six.

Based on the above test results, we decided to deploy OceanBase Database for the following considerations:
- In the monitoring snapshot scenario in the production environment, OceanBase Database shows excellent data compression performance, with the space required for a single replica in OceaBase storage being 1/6 that in MySQL storage.
- When OceanBase Database is deployed in standalone mode and is connected through OBProxy, it achieves a minimum QPS value of over 10,000 and a minimum average latency of 3 ms, which are slightly inferior to those of MySQL Database. However, the query performance of OceanBase Database increases as the memory size increases. Performance indicators of OceanBase Database show greater improvement than those of MySQL Database as the DOP increases. When the DOP exceeds 200, the performance of OceanBase Database approaches and can even exceed that of MySQL Database.
- The MySQL architecture has only one layer, while OceanBase has two, including the OBProxy layer and the OBServer node layer. In standalone deployment, the performance of OceanBase Database is 30% to 50% higher when the OBServer nodes are directly accessed than when they are accessed through OBProxy. This is because each additional layer incurs additional network latency.
Why did we choose OceanBase Database and what sets it apart?
First, OceanBase Database provides an integrated architecture that supports both standalone and distributed deployment modes. What does that mean? A standalone database, like MySQL, can achieve low latency and high performance, while a distributed database supports easy scaling. What problems can these two types of databases address?
In the early business stage, when your data volumes are relatively small, a standalone database like MySQL can offer outstanding performance. Then, when your business starts growing rapidly, a distributed database that supports transparent scaling with almost unlimited capacity can allow you to easily migrate data without code changes or downtime while ensuring high performance.
Second, OceanBase Database, as a native distributed database, naturally supports automatic sharding and migration, load balancing, and other scaling capabilities, enabling transparent scaling without interrupting or affecting your business. Based on the Paxos protocol, OceanBase Database V4.x is further optimized to achieve an RPO of 0 and an RTO of less than 8s, ensuring high system availability.
Third, compared to MySQL Database, OceanBase Database ensures high database performance by minimizing the overhead of the distributed architecture and reduces storage costs by over 80% with a high compression ratio. In addition, the multitenancy feature of OceanBase Database is perfectly suited to SaaS customers, offering easy resource isolation and capacity scaling.
In a distributed database, data processing involves the interaction of memory, disks, and networks. The latency of data reading and writing in memory is 0.1 microseconds, the latency of SSD reading and writing is about 0.1 milliseconds, and the network latency within an IDC is about 0.1 milliseconds, while the network latency across IDCs in the same city is about 3 milliseconds. On the whole, the latency of SSD reading and writing as well as the network latency are about 100 to 1000 times greater than the in-memory read and write latency. The in-memory read and write throughput can reach 100 Gbit/s, the SSD read and write throughput is about 1 Gbit/s to 2 Gbit/s, and the read and write throughput over a 10 Gigabit network is about 1.2 Gbit/s. The SSD and network read and write throughputs are about 100 times less than the in-memory read and write throughput, a difference of two orders of magnitude.
As a standalone database, MySQL places the InnoDB and Server layers in the same process, and therefore offers highly efficient data interaction, making it the undisputed leader in performance and latency. However, for distributed databases in a computing-storage separated architecture, network I/O overheads between the computing and storage layers are inevitable. It is very difficult to mitigate the resulting performance restriction. The unique architecture design of OceanBase Database implements the SQL engine, storage engine, and transaction engine in one process. That is, an OBServer node does both computing and storage. When an application is connected to the OceanBase cluster by using OBProxy, the OBServer nodes report the data routing information to OBProxy. After OBProxy receives an SQL statement from the application layer, it directly forwards the SQL statement to the most appropriate OBServer node for execution based on the routing information. If the data is on one OBServer node, the SQL statement is executed in standalone mode, just like MySQL. This minimizes the network I/O overhead.

Why does OceanBase Database perform better?
OceanBase Database significantly outperforms MySQL Database when working with large data volumes or high concurrency. To find out why, we conducted an in-depth study of its architecture. Here are the key points that contribute to the high performance of OceanBase Database:
First, OceanBase Database offers both low latency and high throughput. For production business data, the proportion of single-server transactions in OceanBase Database can reach more than 80%. This is because, in OceanBase Database, data sharding is performed at the table or partition granularity. Therefore, if we update a non-partitioned table, or a single partition of a partitioned table, OceanBase Database can implement single-server transactions with low latency. Moreover, transactions involving multiple tables in the same server are also executed in single-server mode.
Second, OceanBase Database allows users to use table groups to turn cross-server join operations into single-server transactions. The sound partition granularity design can ensure that 80% of transactions are single-server transactions. The proportion can be further improved by optimizing high-frequency cross-server join operations with table groups. The performance of the database will be superb if more than 90% of all business transactions are single-server transactions.
Third, OceanBase Database distinguishes query priorities. Small queries are given the top priority. Large queries occupy up to a percentage of the worker threads as defined in the large_query_worker_percentage parameter. When there are no small queries, large queries can take 100% of the worker threads. The overall mechanism is similar to highway traffic rules, with large vehicles allowed to take the rightmost lane only, allowing other vehicles to overtake them in the passing lanes. This mechanism can prevent slow SQL queries and large queries from congesting the system or causing it to crash.
These architecture designs and practical optimization ensure the high performance of OceanBase Database. So how does OceanBase Database offer higher performance at lower costs?
Why does OceanBase Database cost less while offering superior performance?
OceanBase Database uses the log-structured merge-tree (LSM-tree)-based storage engine, which supports both compression through encoding and general compression to offer a high compression ratio. As you can see in the following figure, our test data shows that it uses 75% less cluster storage space than MySQL Database.
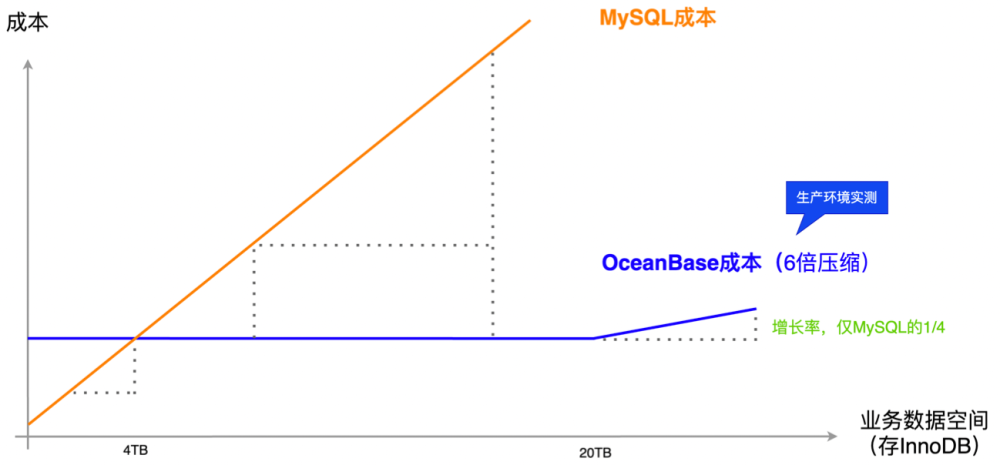
As the business of Dmall grows, our data is increasing rapidly, and the number of nodes is increasing exponentially. The costs of a MySQL system will soon exceed those of OceanBase Database. As shown in the figure below, the compression ratio of 6:1 is verified by the test conducted in our production environment. Our business data will continue to grow in the future. As OceanBase Database supports unlimited new nodes, its storage costs will grow much slower than those of MySQL Database.
Multitenancy and resource isolation capabilities of OceanBase Database
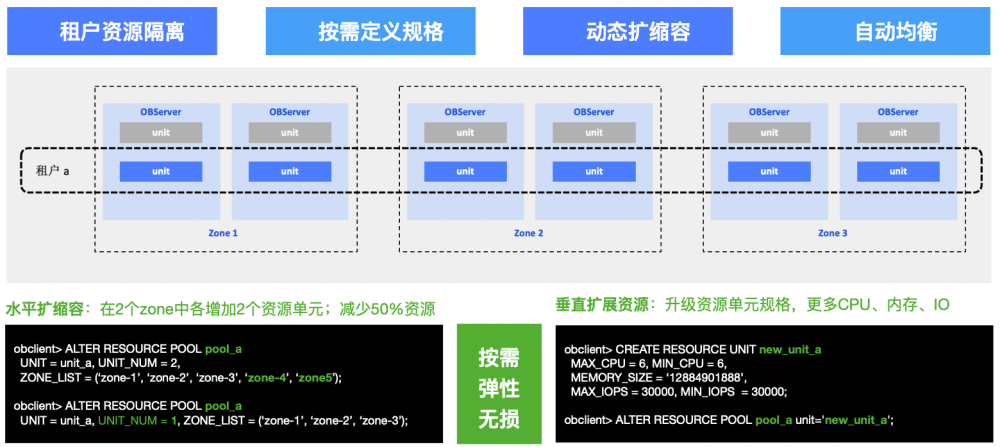
The multitenancy feature of OceanBase Database perfectly suits the SaaS scenario because it provides resource isolation among tenants and fast elastic scaling of tenants.
Resource isolation among tenants: OceanBase Database tenants are physically isolated from each other in terms of CPU, memory, and I/O resources. This ensures zero resource preemption among different businesses and ensures that issues in one business will not affect other tenants.
Fast elastic scaling for tenants: Assume that a tenant has three zones, with each zone having two nodes. The tenant has a total of six nodes, and each node has one resource unit. To scale up the tenant, you only need to execute one SQL statement. For example, you can add Zone 4 and Zone 5 to scale the tenant up from 6 resource units to 10, implementing horizontal scaling with ease. Vertical scaling is simple to carry out as well. For example, if you start out with 2 CPU cores and 8 GB of memory and do not want to add nodes, you can scale up the tenant to 6 CPU cores and 12 GB of memory without adding any nodes. The whole process is dynamic and lossless without affecting or interrupting your business. Vertical scaling requires the DBA to run only a single SQL statement, greatly reducing the workload. Therefore, the multitenancy feature perfectly meets our need for a new system for SaaS businesses that is cost-saving and easy to expand.
Summary
As a SaaS service provider, Dmall faces many pain points, such as massive databases, fast data growth, high resource costs, and complex O&M. Distributed databases provide excellent support for our business growth, improve development efficiency, and alleviate the DBA workload. Distributed databases are the path of advancement for database technology. We verified the advantages of OceanBase Database in scalability, performance, and cost effectiveness by running our own tests. Based on our current business development needs and the multitenancy capability that suits our retail SaaS scenario, we are sure that we will continue to expand our cooperation with OceanBase in the future.