OceanBase Database: 2DFire‘s New Choice in the Post-sharding Era
Walking into any restaurant in China today, regardless of its size, you can order by scanning a QR code, using a self-service kiosk, or clicking on a dedicated mini-program. As digital intelligence transformation accelerates in the food and beverage industry, dedicated Software as a Service (SaaS) solutions have become a must-have for restaurants. 2DFire is one such solution.
In 2007, 2DFire launched the first version of its restaurant management system. After more than a decade of painstaking efforts in restaurant-dedicated SaaS, 2DFire has developed a comprehensive product matrix covering intelligent restaurant location, ordering, marketing, management, and supply chain services. It now serves over 490,000 merchants in more than 400 cities in China, with registered members exceeding 200 million.
One notable characteristic of restaurant-dedicated SaaS is the high concurrency at dining time, when the system must handle a massive influx of orders, requiring robust request processing performance. 2DFire is a long-time user of Cobar, which has been a big help to the stable development of 2DFire's business by eliminating single-point bottlenecks. However, as the limitations in applications and high availability became apparent, along with the increasing O&M complexity, 2DFire began to feel constrained in its business innovation and upgrades. Lately, 2DFire started hunting distributed databases that could meet its long-term business needs. In this article, 2DFire’s O&M Director, Sanqi, together with OceanBase’s Solutions Architect, Sun Peng, share the story behind 2DFire’s choice of OceanBase Database, starting from the concept of database sharding.
In the first decade of the 21st century, the internet industry flourished. Faced with the demand of storing and processing massive amounts of data, conventional commercial relational databases exposed their limitations in scalability. NoSQL databases like Redis and MongoDB, with their advantages in speed and scalability, became effective patches in some scenarios. However, they could not entirely replace relational databases.
As hardware development lagged behind business needs, and conventional commercial relational databases came with jaw-dropping license fees, leading internet companies started looking for new solutions.
Against this backdrop, sharding solutions emerged. As the name suggests, sharding entails splitting a database or table into parts and managing them separately. Building on top of Amoeba, the initial version of Cobar was completed in 2009 and deployed within Alibaba Group. In 2011, it underwent cluster transformation, and in June 2012, Cobar became open source.

Cobar architecture
Cobar is essentially a distributed processing system for relational databases, acting as middleware that provides distributed services for relational databases like MySQL. Like many others, 2DFire chose Cobar as middleware to build its business system for the following characteristics of Cobar:
-
It eliminates single-point performance bottlenecks.
-
It avoids excessive connections to a single instance.
-
It ensures high availability by switching business to a standby node when the master node fails.
-
It works with open source MySQL, exempting us from high costs associated with proprietary software and hardware.
In the second decade of the 21st century, with the internet industry still riding high on the demographic dividend, MySQL became the go-to choice and de facto standard for most internet companies building their platforms. Correspondingly, various sharding solutions mushroomed as many companies developed their distributed database middleware. Cobar evolved into MyCat, and Sharding-JDBC, a client-side sharding solution, was also widely deployed. Here are some popular middleware products for distributed databases.

Popular middleware for distributed databases
While this is not an exhaustive list, these solutions generally fall into two categories: middleware that runs as an independent process and plugins that operate on the client side. These solutions were designed to tackle single-point bottlenecks, but they often caused new troubles, such as:
-
Application limitations. Many support only simple SQL queries and must be modified for complex applications.
-
Non-sharding key queries.
-
Concerns about distributed transactions and data consistency.
-
High availability not guaranteed.
-
Complex O&M.
Entering the third decade of the 21st century, as the number of Chinese netizens reached its peak, plus the impact of the three-year black swan event, the market has shifted from growth to maintenance, and many companies have planned to improve efficiency at lower costs.
In the diverse database arena, numerous distributed and cloud database vendors have released their products, which beat sharding solutions in terms of architecture, design, and user experience. Aiming for higher efficiency at lower costs, 2DFire began seeking new databases as well.
The domestic database market mainly offers two types of products: enhanced distributed middleware and native distributed databases. Given our experience with Cobar, and in the expectation of moving away from the limitations of a sharding solution once and for all, we focused on the latter and chose OceanBase Database after thorough research. The primary reasons for this decision are as follows:
OceanBase Database natively supports strong consistency between multiple replicas to ensure data security. Each node of an OceanBase cluster supports read and write operations. Data replicas are synchronized across multiple nodes based on predefined rules. Multiple replicas of a single partition are strongly consistent based on the Paxos protocol. The primary partition holds the latest version of the data, and supports strong-consistency reads and writes, while secondary partitions support weak-consistency reads.
OceanBase Database supports multitenancy, a user-friendly and cost-effective feature. Specifically, multitenancy allows us to merge multiple conventional databases into a single large cluster, where the data of a tenant is isolated from others. Tenant resources can be configured respectively and scaled smoothly, which improves resource utilization at lower O&M costs.
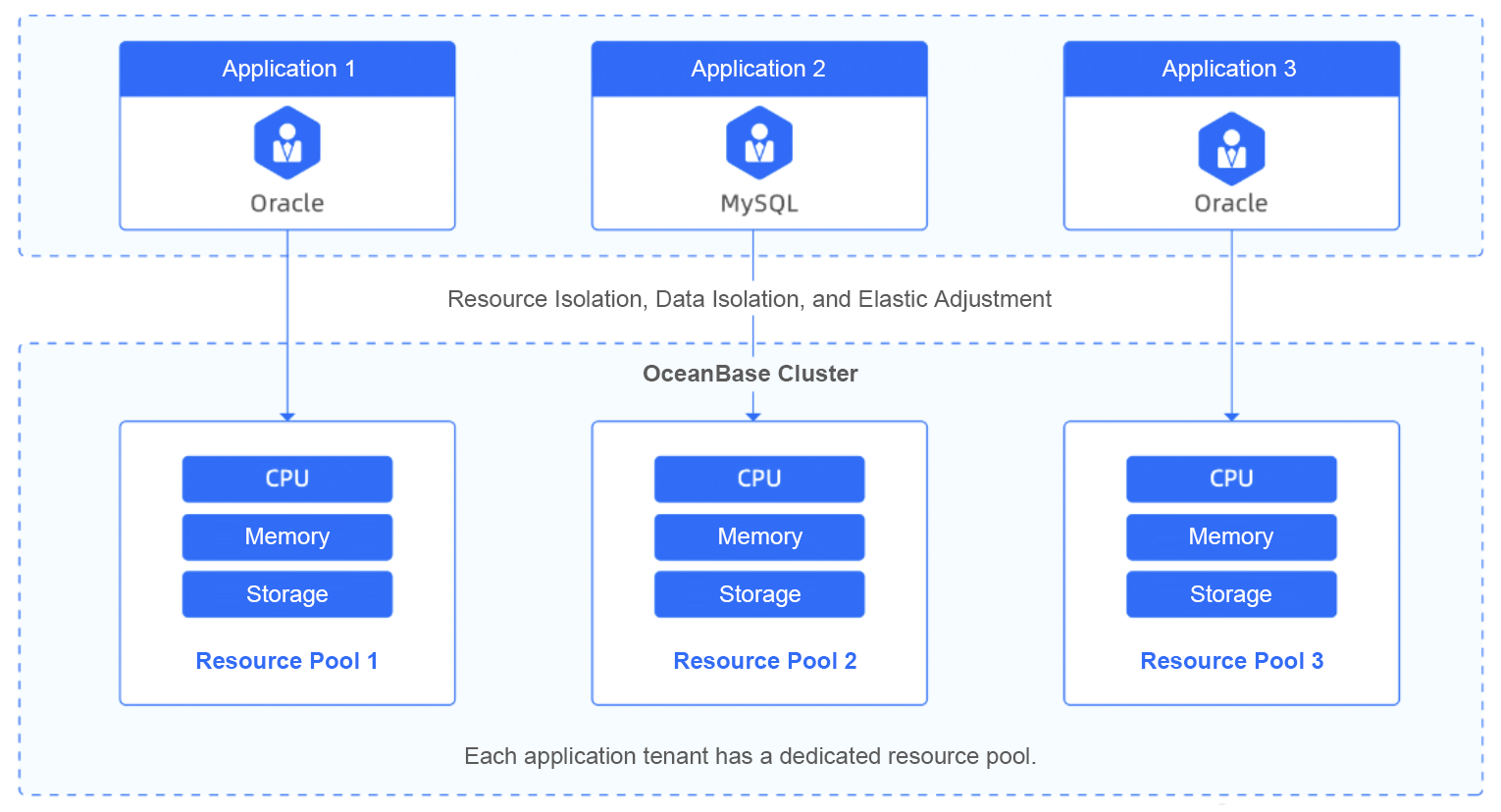
▲ The multitenancy mechanism of OceanBase Database
OceanBase Database adopts an advanced log-structured merge-tree (LSM-tree)-based storage engine. It writes data first to memory, and dumps static data to the baseline SSTables on disks, laying the groundwork for efficient data encoding and compression. OceanBase Database organizes data in hybrid row-column storage and uses the dictionary, run-length, delta, or constant encoding method to encode variable 16 KB micro-blocks. Then, it uses the ZSTD algorithm to compress the encoded data. This approach significantly shrinks the storage space, making it highly suitable for massive data scenarios. Combined with its multi-level caching mechanism consisting of block cache, row cache, and bloom filter, OceanBase Database also guarantees high cost effectiveness.

Typical table access process
One critical capability required to bring theory to practice was to perform gray-scale traffic switching and reverse incremental synchronization while migrating our Cobar-based application system. Obviously, we needed a comprehensive migration plan to ensure high availability and avoid unnecessary downtime.
From a business perspective, the capability guaranteed that we could roll back to the original system and minimize the impact on operations if any stubborn exceptions occurred after the system switchover.
From a technical standpoint, the migration program must distinguish between incremental business data in the target database and the data synchronized from the source during traffic switching, and accurately write incremental business data back to the source through the Cobar middleware to maintain data consistency between the two sides.
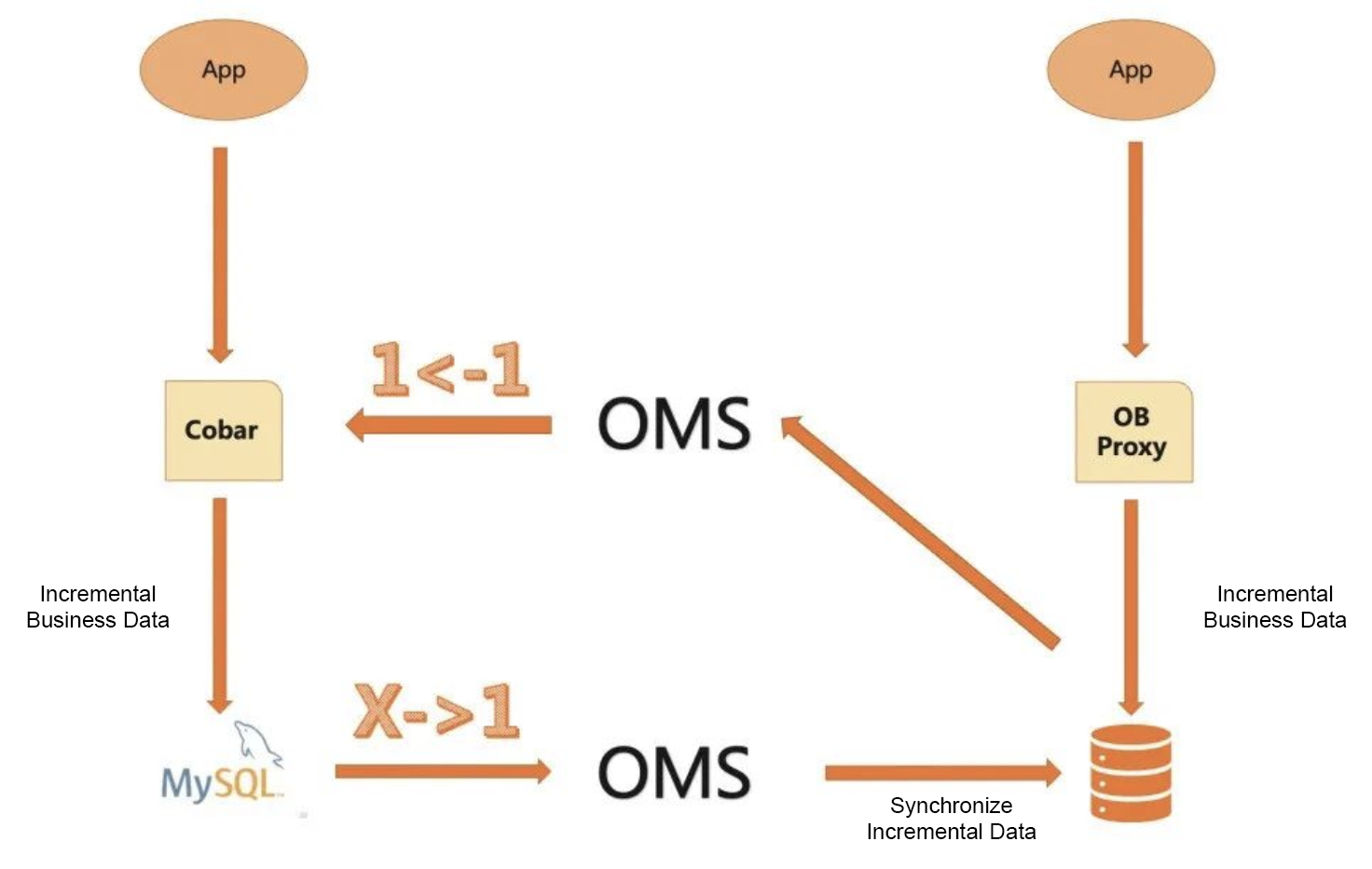
Migration from Cobar to OceanBase Database
Initially, OceanBase Migration Service (OMS), a dedicated data migration tool, did not support this capability. To our surprise, the OceanBase team developed, verified, and refined what we expected in just a few months.
So, as a trial, we picked our archive database, which stored a huge amount of data and involved more writes than reads, and migrated it to OceanBase Database. The process was smooth: We created a forward connection for each source physical MySQL instance to migrate/synchronize data to OceanBase Database, and a reverse connection to migrate data from OceanBase Database back to Cobar. The data verification of OMS ensured zero data loss and consistency during the process.
After verifying various business operations on OceanBase Database, we switched the data sources by performing rolling restarts of application servers, achieving seamless online switching.
The cost reduction was immediate. The archive database was compressed to 1/5 of its original size, thanks to OceanBase’s advanced compression techniques. Benefiting from the native distributed architecture of OceanBase Database, the performance of data archiving and history queries was improved substantially.
From theoretical analysis to practical verification, the entire process flowed seamlessly, giving us the confidence and determination to migrate other applications. Currently, we are upgrading our ordering, marketing, management, and supply chain services, so as to provide more efficient and intelligent services to merchants and assist them in achieving success. At the same time, we hope that OceanBase Cloud can support the binlog service soon. The service will eliminate the need for pre-migration adaptation and make our business upgrades more efficient.
Follow us in the OceanBase community. We aspire to regularly contribute technical information so that we can all move forward together.