TAL‘s Multitenancy Practice: Solving Resource Isolation and Fragmentation in the Next-gen Data Architecture
Editor's note: As a leading educational technology company in China, Tomorrow Advancing Life (TAL) Education Group operates a variety of business lines and manages massive amounts of data. Its underlying data system involves many database services, such as MySQL, Redis, MongoDB, PikiwiDB, Relational Database Service (RDS), PolarDB, container database (CDB), and Cloud Native Database TDSQL-C (TDSQL-C for short), which are deployed and hosted by using multiple cloud services, such as Alibaba Cloud, Tencent Cloud, and Baidu AI Cloud. To address challenges brought by the multi-cloud architecture, such as database sharding, resource isolation, and fragmentation, the company has introduced the OceanBase technology stack. OceanBase Database was tested in some business lines. The test results show that it can improve business availability and resource utilization, make O&M easier, and bring a cost reduction of 50% for self-managed services and 40% for cloud services. In this article, Wang Xinran, TAL's database expert, shares his insights into and reflections on their solution.
Background: Why OceanBase Database?
Driven by its content creation and technological strengths, TAL Education Group (hereinafter referred to as TAL) has adheres to its strategies in academic education, scientific innovation, and general knowledge promotion, while shouldering a mission to assist lifelong personal development with the power of love and technology and envisioning to become an organization with sustainable innovation potential. In addition to Xueersi Literacy Center, Xueersi Online School, and other traditional educational brands that offer various courses in science, humanities, and technological innovation, TAL has also developed a series of smart hardware and software products, such as learning tablets and intelligent coaching systems. Also, I am very proud to announce that TAL has recently launched the MathGPT model, a home-grown fruit of our heavy investment in AI technology. Welcome to try it out.
Each of TAL's diverse business lines selects its database products based on its specific needs. As a result, TAL's database services are provided in a hybrid cloud architecture, comprising various self-managed database services hosted in our Internet data centers (IDCs) and a range of cloud databases from multiple cloud providers.
Why did we select OceanBase Database despite so many database products in use?
Three reasons:
MySQL bottlenecks: A large part of our self-managed services are based on MySQL, which is conventionally deployed in standalone mode, and easily hits performance and capacity limits. Additionally, the conventional middleware-based sharding solution is not well-suited for distributed transactions, making O&M harder.
Lack of resource isolation: Conventional databases are deployed in standalone mode with multiple instances and lack resource isolation, posing risks to the operation stability of online services. Furthermore, physical resources are not integrated, and resource allocation and recovery are achieved by modifying metadata. This inevitably leads to serious resource fragmentation.
Lack of scalability: Our original resource deployment mode did not support auto-scaling. Excessively redundant resource allocation resulted in low resource utilization and significant waste.

Is OceanBase Database the cure for all these pain points?
Database Selection: Exploring and Verifying the OceanBase Database Solution
When selecting a new database, we primarily look for these capabilities:
- Architecture design: This determines the database performance and disaster recovery capabilities.
- Multitenancy: This helps achieve resource isolation and auto-scaling.
- Data compression: This saves hardware costs.
- Ecosystem tools: These tools help build a new database O&M system at a minimal cost.
1. Architecture design
The figure below shows the architecture of an OceanBase Database version later than V4.0, which has the following characteristics:
-
Multiple replicas: Generally, three or five zones are deployed, and each zone consists of multiple servers, which are called OBServer nodes.
-
Peering nodes: Each OBServer node operates with its own SQL engine and storage engine, and manages its own data partitions. The nodes communicate with each other over TCP/IP and provide services collaboratively.
-
No sharing of storage: Data is distributed across nodes, without sharing storage devices or using a storage area network (SAN).
-
Partition-level availability: A partition is a basic unit for ensuring reliability and scalability. It supports automatic access routing, strategy-based load balancing, and autonomous fault recovery.
-
High availability and strong consistency: Efficient and reliable operation of multiple replicas and the Paxos protocol ensure successful persistence of data and logs on the majority of nodes.
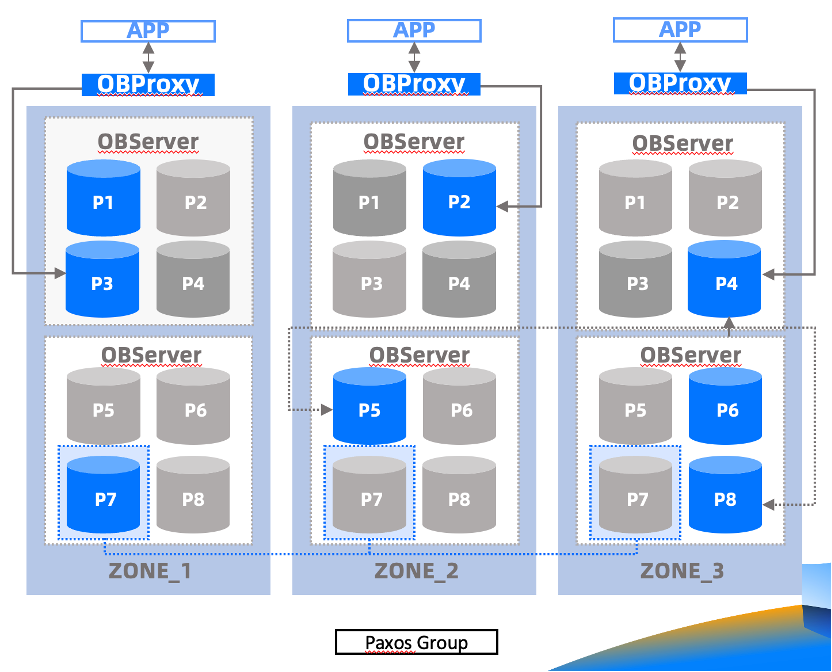
OceanBase Database supports integrated architecture for standalone and distributed modes. It allows most business requests to be executed locally as single-server transactions, avoiding the overhead for distributed transactions. Furthermore, if we set priorities for availability zones, all requests sent to an OceanBase Database tenant can be executed locally. This performance edge is highly welcome for business operations.
2. Multitenancy
OceanBase Database offers native multitenancy capabilities. It allows us to configure the number, type, and storage location of data replicas, as well as computing resources for each tenant. It also supports auto-scaling and dynamic configuration adjustments of each tenant. An automated O&M mechanism is provided within a cluster, ensuring complete resource isolation between tenants while keeping tenant data secure. This helps mitigate the risks associated with resource mixing in online environments.
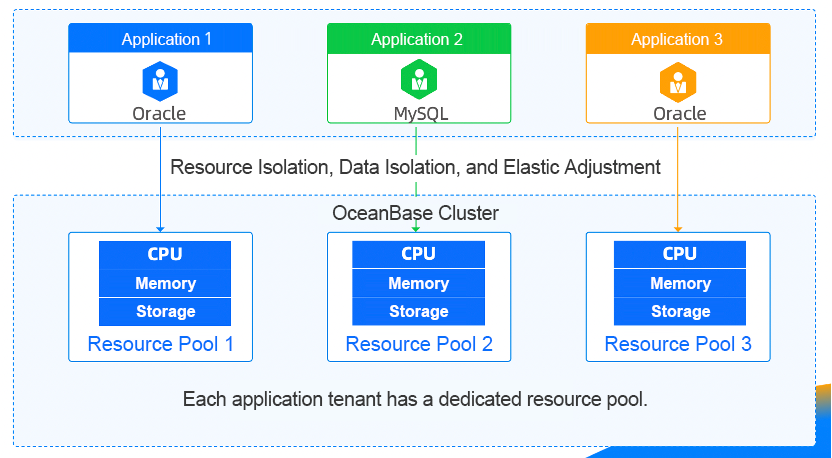
3. Data compression
OceanBase Database provides advanced data compression technologies, allowing us to not only address performance and availability issues but also achieve significant cost savings. Three key technologies are described as follows:
-
Variable- and fixed-length data compression: To reduce storage costs, OceanBase Database uses compression algorithms that can achieve a high compression ratio and decompress data fast. Its log-structured merge-tree (LSM tree)-based storage engine separates the storage spaces for data reads and writes, and supports row-level data updates. The updated data is stored in memory and then written to the disk in batches. Therefore, OceanBase Database achieves a write performance comparable to that of an in-memory database and stores data at costs not more than that of a disk-resident database. Also, OceanBase Database does not suffer the performance bottleneck of random disk writes and storage fragmentation as in a B+ tree architecture. It writes data faster than a conventional database that updates data blocks in real time.
-
Storage compression based on data encoding: OceanBase Database adopts Partition Attributes Across (PAX), a hybrid row-column storage model where disk data blocks are organized by column. To be specific, it develops an encoding method that performs encoding compression on rows and columns by using dictionary, delta, and prefix encoding algorithms before compressing the data by using general algorithms. This further improves the compression ratio.
-
Low-cost storage based on data-log separation: The classic Paxos protocol requires a system to run with three or five replicas. As OceanBase Database separates user data from logs, the logs can be stored with, for example, three or five replicas, while the user data can be stored with two to four replicas. This data-log separation mechanism costs 20% to 40% less in user data storage while providing the same system availability.
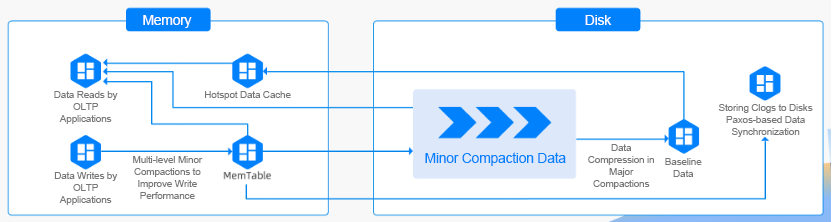
OceanBase Database also provides other awesome features, such as dynamic modifications written to the memory, no modifications to static data, the high compression ratio of batch writes, strong data consistency verification, and no random writes, which is friendly to SSDs.
4. Ecosystem tools
Besides its robust core capabilities, OceanBase Database offers a rich set of ecosystem tools that cover the entire lifecycle of our services, from assessment and transformation to real-time migration, development management, production operations, replication and subscription, security control, and autonomous diagnostics. With these powerful tools, we can establish an O&M system based on OceanBase Database at a very low cost.
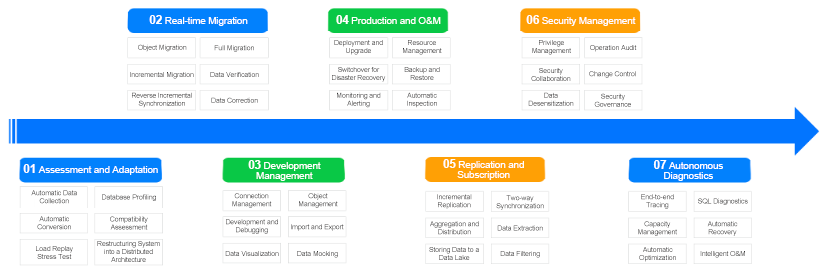
The tool we use most frequently is OceanBase Cloud Platform (OCP). It allows us to perform most of our daily O&M tasks on GUI-based pages. For example, we can create a cluster, add a zone, and add a tenant with just a few clicks in the OCP console. The entire process is simple and reliable. OCP also supports monitoring and alerting, performance analysis, and data backup, making database O&M a lightweight and enjoyable task.
We have noticed that OceanBase Database is highly compatible with the MySQL ecosystem. In MySQL mode, the binlog service can convert OceanBase Database logs into MySQL binlogs. This way, our business lines can continue using their MySQL-compatible data synchronization tools for data subscription tasks at minimal business adaptation costs.
Summary: Experience and Recommendations
Now, let me share with you the performance of OceanBase Database in our production environment.
We compared an OceanBase cluster (3 zones, each with 4 CPU cores and 16 GB of memory) with one of our cloud-native databases (1 master instance and 2 slave instances, each with 4 CPU cores and 16 GB of memory). The test revealed that:
- About 4.2 TB of data migrated from the cloud-native database was compressed to 1.9 TB in OceanBase Database, achieving a compression ratio of 10:4.5.
- OceanBase Database did not have a performance edge when the concurrency was low, but turned the tables when the concurrency exceeded 56.
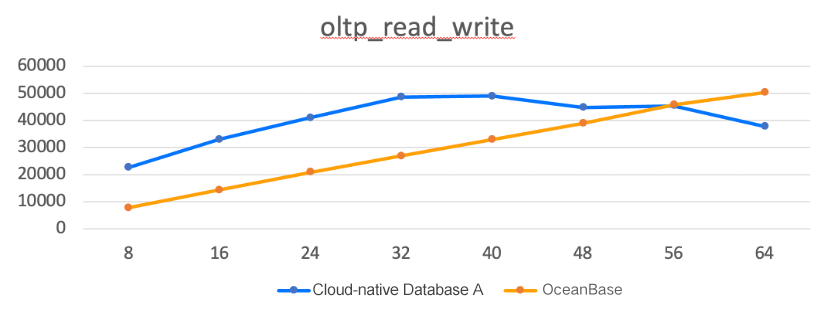
We also compared an OceanBase cluster (3 zones, each with 24 CPU cores and 96 GB of memory) with one of our MySQL databases (1 master instance and 2 slave instances, each with 24 CPU cores and 96 GB of memory). The test revealed that:
- OceanBase Database compressed 413 GB of data in MySQL down to 125 GB, achieving a compression ratio of 10:3.
- OceanBase Database was nip and tuck with MySQL when the concurrency was low, but gained its superiority when the concurrency exceeded 40.
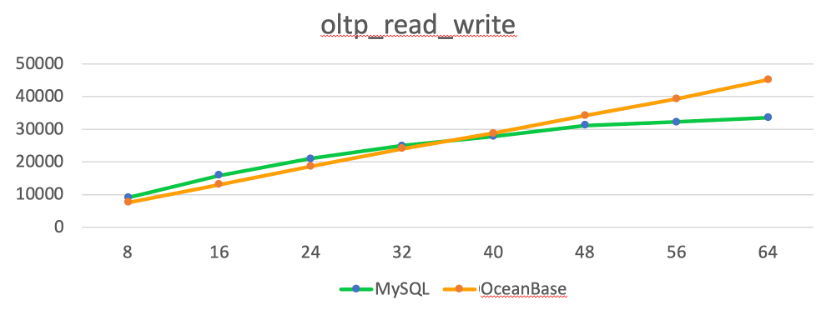
So far, we have migrated some self-managed services from cloud-native databases to OceanBase Database Community Edition, achieving a 50% reduction in storage costs. We have also migrated scattered RDS instances from a public cloud to tenants of a single large OceanBase cluster and migrated cloud database instances with high disk usage to OceanBase Database. By instance merging and data compression, we have saved cloud service costs by 40%.
Based on our experience with OceanBase Database, I would like to offer a few suggestions about the deployment.
First, use OCP to deploy your OceanBase clusters. We deployed our first OceanBase clusters quickly using OCP Express, which, however, lacked management features and could not meet our O&M needs. So we used OCP to take over these clusters later, and the process was not easy.
Second, deploy OCP and OceanBase clusters separately on different servers. OCP stores its own data. If you deploy OCP and your business system within the same OceanBase cluster, you will find that you just cannot log in to OCP to take remedial actions when your business OceanBase cluster encounters issues.
Third, manually set the values for the following parameters when deploying a cluster: log_disk_size, datafile_size, and memory. Otherwise, OCP uses default parameter values for resource allocation, which may consume up to 90% of your system resources. If the cluster also runs other services, the memory or disk resources can easily be exhausted.
Next Step: Exploring HTAP Capabilities
In summary, TAL's experience with OceanBase Database has been positive. OceanBase Database has not only addressed storage and performance bottlenecks and achieved resource isolation and auto-scaling, but also reduced costs and O&M workload. Going forward, we will use OceanBase Database to support more business lines.
In addition to self-managed services, we will also migrate our core business applications to OceanBase Database, hoping that the multitenancy capabilities of a distributed database solution can help address system availability challenges. Moreover, we will explore the hybrid transaction and analytical processing (HTAP) capabilities of OceanBase Database, and leverage its online analytical processing (OLAP) features to solve the issues caused by storing multiple replicas of the same data in different locations, thus eliminating cost waste.
As for public cloud services, we will merge more RDS instances into OceanBase Database, while migrating bulky cloud databases to OceanBase Database. This way, we can save more by resource integration and overprovisioning, along with utilizing high compression techniques.