BOSS Zhipin —— How to save 70% storage cost through OceanBase with an archive database of 1 billion rows per day?
Author: Zhang Yujie, Database Engineer with BOSS Zhipin
I. Background
BOSS Zhipin is the first "direct-hiring" online recruitment service in the world, and has become China's largest job searching platform. An important job of my team is to store the conversation records during the recruitment process into a database, which has held a tremendous amount of data and is taking in 500 million to 1 billion data records on a daily basis. However, these conversation records are rarely or never accessed or updated after they are written to the database. The growing volume of online data, especially the cold historical conversation records, has occupied petabytes of storage space of the online business database, resulting in serious waste of hardware resources and escalating IT costs. In addition to bloating the online business database, the increasing data volume also reduces the query efficiency, which hinders data changes and system scaling.
To address these issues, we need to separate hot data from cold historical conversation records. The hot data is stored in a sharded online database of multiple MySQL clusters. Expired data is regularly migrated to the archive database every month.
II. Database Selection
To build an archive database with a humongous capacity, we compared MySQL, ClickHouse, OceanBase Database, and an open-source distributed database (let's call it "DB-U") in terms of storage costs and high availability.
(I) Storage costs
We need to retain historical conversation data for three to five years and must control the cost of massive storage. First, we created a table in each of the databases to store historical messages. The table schemas are the same. See the following figure.
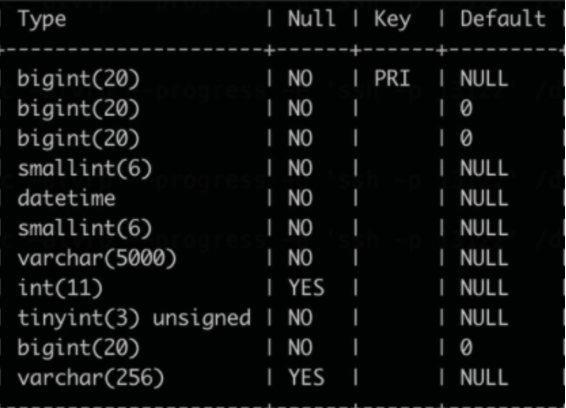
Then, we wrote the same 100 million data rows to each of the tables, and compared their disk usage. See the following figure.

Apparently, compared with MySQL and DB-U, columnar storage-based ClickHouse and OceanBase Database boasting an ultra-high compression ratio incur significantly lower storage costs. We then delved deeper into the storage engines of the two winners.
ClickHouse storage engine
ClickHouse uses smaller storage simply because of its column-based storage engine. Compared with a row-based storage engine, the data stored in the same column of the ClickHouse database is of the same type, and thus can be compressed more compactly. Generally, the compression ratio of columnar storage can reach 10 or higher, saving a lot of storage space and reducing the storage costs significantly.
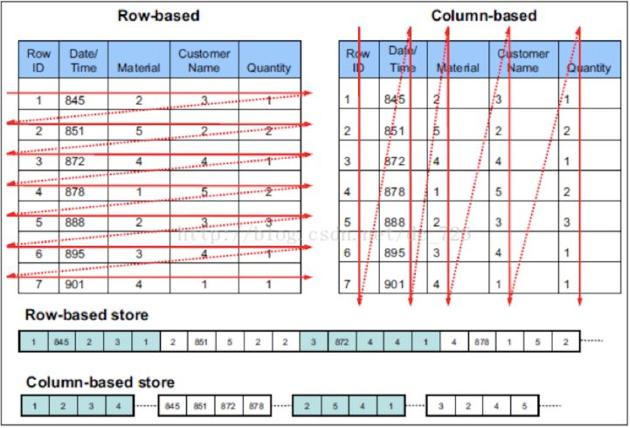
However, as an archive database often involves more writes and is rarely read, a pure column-based storage engine such as ClickHouse cannot bring its great query performance into full play. Instead, its lame write performance becomes intolerable.
OceanBase Database storage engine
1. Architecture
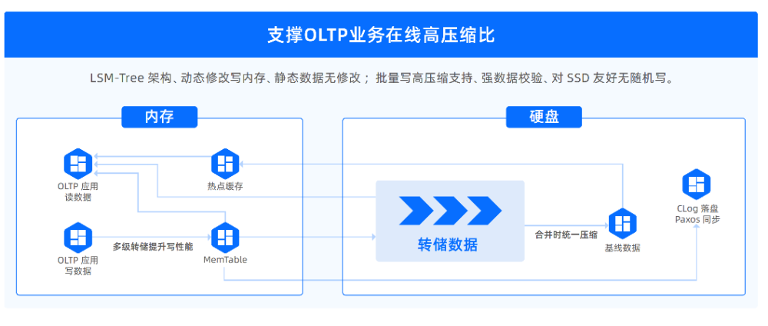
Based on the LSM-tree architecture, the storage engine of OceanBase Database stores baseline data in baseline SSTables and incremental data in MemTables and incremental SSTables. The baseline data is read-only and cannot be modified. Incremental data supports read and write operations.
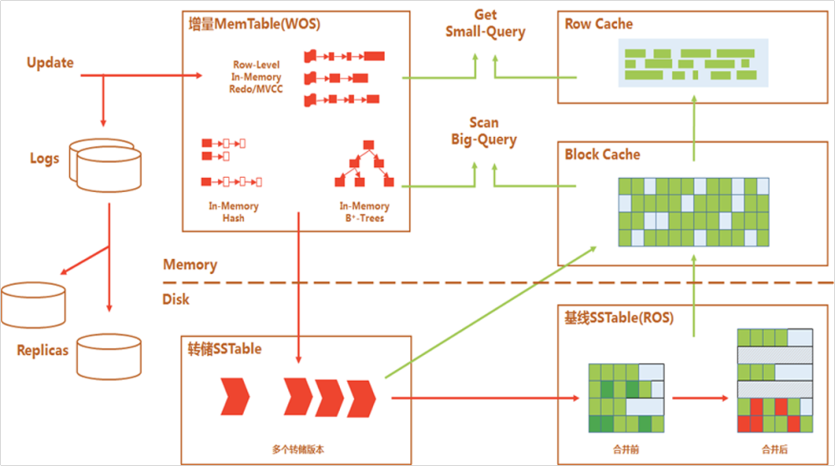
In OceanBase Database, DML operations such as INSERT, UPDATE, and DELETE are first written into MemTables in memory. This means that the data write performance is equivalent to that of an in-memory database, which agrees with the write-intensive scenario of our archive database. When the size of a MemTable reaches the specified threshold, data in the MemTable is dumped to an incremental SSTable on the disk, as shown by the red chevrons in the preceding figure. The dumping process is performed sequentially in batches, delivering much higher performance compared with the discrete random writing of a B+ tree-based storage engine.
When the size of an incremental SSTable reaches the specified threshold, incremental data in the SSTable is merged with the existing baseline data to produce new baseline data. This process is referred to as a major compaction. Then, the new baseline data remains unchanged until the next major compaction. OceanBase Database automatically performs a major compaction during off-peak hours early in the morning on a daily basis.
A downside of the log-structured merge-tree (LSM-tree) architecture is that it causes read amplification, as shown by the green arrows in the preceding figure. Upon a query request, OceanBase Database queries SSTables and MemTables separately, merges the query results, and then returns the merged result to the SQL layer. To mitigate the impact of read amplification, OceanBase Database implements multiple layers of caches in memory, such as the block cache and row cache, to avoid frequent random reads of baseline data.
2. Data compression technology
Given the optimized storage architecture, OceanBase Database compresses data during the major compaction, when data is written to the baseline SSTable. This way, online data updates are independent of the major compaction.
OceanBase Database supports both compression and encoding. Compression does not consider data characteristics, while encoding compresses data by column based on data characteristics. The two methods are orthogonal, meaning that we can first encode a data block and then compress it to achieve a higher compression ratio.
OceanBase Database also supports batch persistence. This feature allows it to adopt more aggressive compression strategies. OceanBase Database uses the Partition Attributes Cross (PAX) storage mode, which features a hybrid row-column storage architecture based on microblocks. In a microblock, a group of rows are stored and encoded based on data characteristics by column, fully leveraging the locality and type characteristics of data in the same column. Variable-length data blocks and batch-compressed continuous data allow OceanBase Database to guide the compression of the next data block by using the prior knowledge derived from the compressed data blocks in the same SSTable, so that it can compress as many data rows as possible into a data block by selecting a better encoding algorithm.
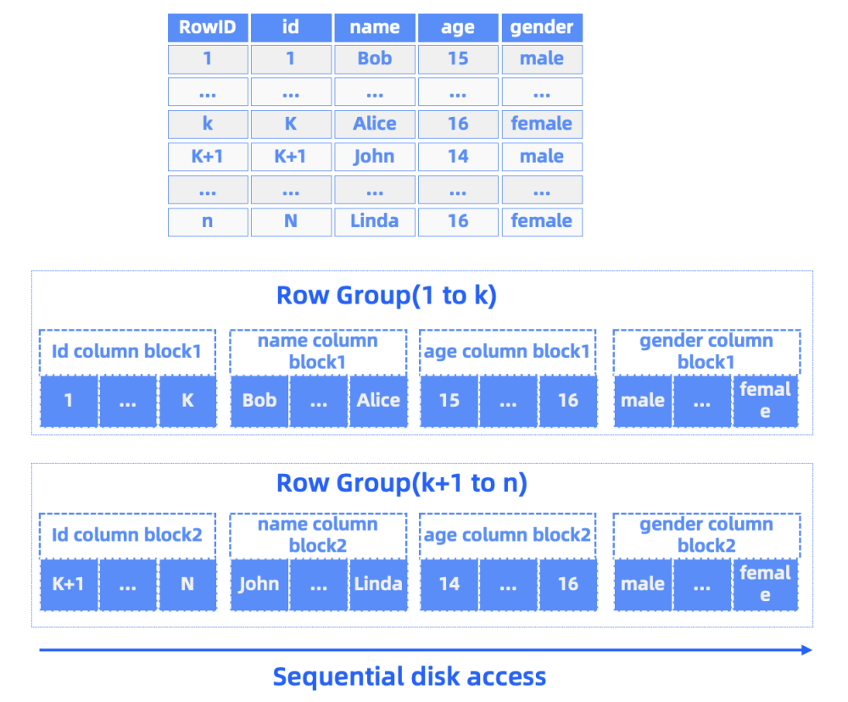
Unlike some database implementations that specify data encoding on the schema, OceanBase Database employs adaptive data encoding, which works without manual intervention, reducing the workload of users and storage costs. We just need to adjust a couple of compression and encoding parameters for the archive database to start working.
(II) High availability and stability
We also compared the high availability and stability of ClickHouse and OceanBase Database.
ClickHouse
We fully tested the automatic data synchronization performance of the ClickHouse database through data replication across different servers in the cluster to ensure high availability and fault tolerance. ZooKeeper was used to coordinate the replication process, track the status of replicas, and guarantee data consistency among them. This way, multiple data replicas are hosted on different servers to minimize the risk of data loss.
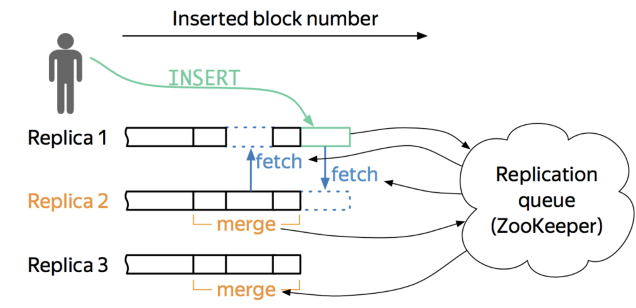
However, we noticed some drawbacks of this ClickHouse-based high availability solution in handling massive amounts of data. During data replication between multiple replicas, a lot of information was stored on ZooKeeper. The problem is that, ZooKeeper does not support linear scaling, which means its performance is limited by the capacity of a server. As more data was written to the archive cluster, ZooKeeper services soon became unavailable.
In fact, when working with ClickHouse, ZooKeeper is more like a multitasker than just a coordination service. For example, it works as a log service and stores information such as behavior logs. It also plays the role of a catalog service, verifying the schema information of tables. As a result, the data volume handled by ZooKeeper increases linearly with that of the database. Given the expected data growth rate of our archive database, this ClickHouse + ZooKeeper solution cannot survive the full data archiving over a time span of three to five years.
Furthermore, data replication in the ClickHouse database depends heavily on ZooKeeper, which, as an external coordination service, introduces additional complexity in terms of system configuration and maintenance. Exceptions of ZooKeeper are likely to affect the replication process in the ClickHouse database. This high availability solution also prolongs troubleshooting paths, making it more difficult to locate a fault. The recovery process becomes more complicated, requiring manual intervention. Data loss was common in the test.
OceanBase Database
OceanBase Database is a native distributed database system that guarantees the data consistency between multiple replicas based on the Paxos distributed consensus protocol. The Paxos protocol ensures that a unique leader is elected to provide data services only when the majority of replicas in the OceanBase cluster reach a consensus. In other words, OceanBase Database guarantees high database availability by using multiple replicas and the Paxos protocol.
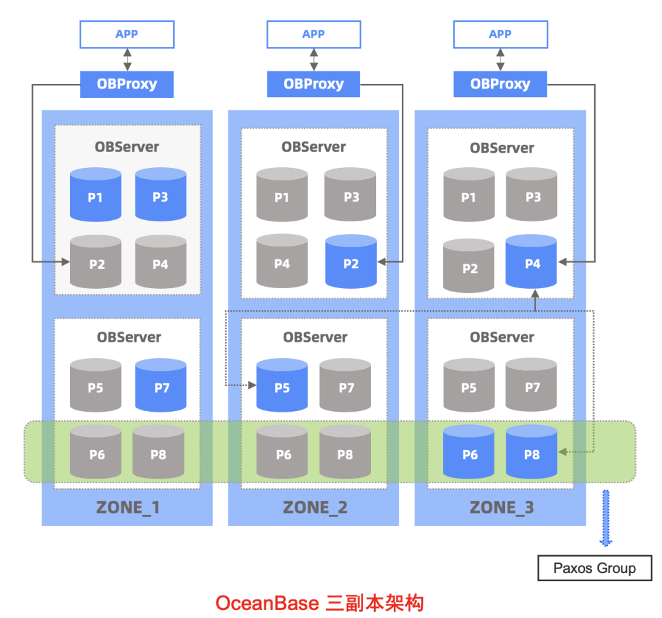
Compared with MySQL and ClickHouse, the high availability solution based on OceanBase Database makes our database O&M and business updates easier. OceanBase Database also supports multireplica and multiregion architecture, so that data replicas can be stored in IDCs in the same city or different regions for the purpose of geo-disaster recovery.
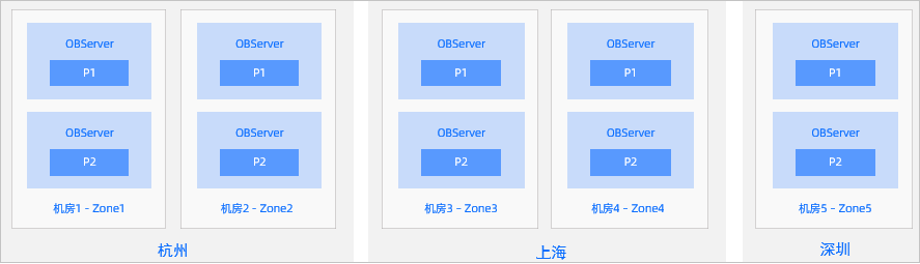
Featuring a distributed architecture, OceanBase Database inherently supports dynamic data storage scaling. As the data volume of the archive database keeps growing, our database administrators (DBAs) only need to run a command or two to scale up a node by modifying the quota of hardware resources, or scale out a cluster by adding more nodes. After a new node is added to the cluster, OceanBase Database automatically balances the workload among the new and old nodes. The scaling process is smooth without business interruptions or downtime. This feature also saves the costs of database scale-out and data migration in response to business surges, leading to a great reduction of the risk due to insufficient database capacity.
The best part is, when we want to increase the capacity of a single node, add more nodes into a zone, or add a new zone to reach higher availability, we can perform these operations on OceanBase Cloud Platform (OCP), a GUI-based OceanBase Database management tool. The following figure shows a page of OCP in the process of scaling a single-zone cluster to a three-zone one.
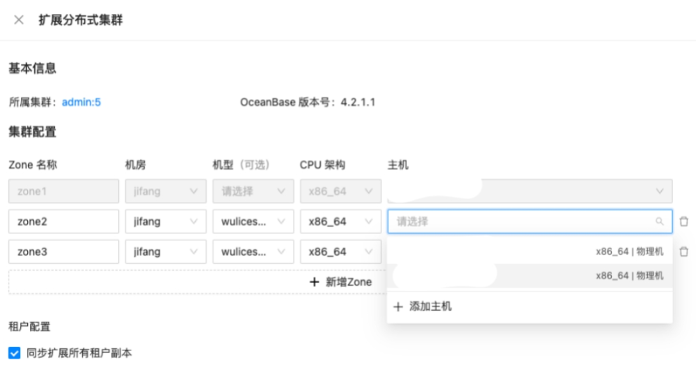
Compared with a command-line tool, OCP is more user-friendly for the deployment and O&M of OceanBase Database, according to our DBAs, who recommended OCP.
To sum up, unlike MySQL and ClickHouse, OceanBase Database natively guarantees strong storage consistency. It does not compromise the eventual consistency for other capabilities, or rely on miscellaneous complex peripherals to ensure data consistency. Multi-replica disaster recovery is applicable to individual clusters. Transaction logs are persisted, and logs are synchronized between multiple replicas. The Paxos protocol guarantees log persistence for the majority of replicas. OceanBase Database provides high availability with a recovery point objective (RPO) of 0 and a recovery time objective (RTO) of less than 8s when a minority of replicas fail. In the test, OceanBase Database outperformed MySQL, ClickHouse, and DB-U, demonstrating higher system stability.
Based on a comprehensive assessment, factoring in the storage costs, high availability, and O&M difficulty, we decided to build our archive database by using OceanBase Database.
III. Implementation
Our online database is a MySQL cluster deployed in primary/standby mode. We use it to store hot data, mainly user conversation records in the last 30 days. Our archive database consists of several OceanBase clusters, which are managed by OCP. We regularly migrate expired data from the MySQL database to the archive database on a monthly basis using our internal data transmission service (DTS) tool. The following figure shows the overall architecture.
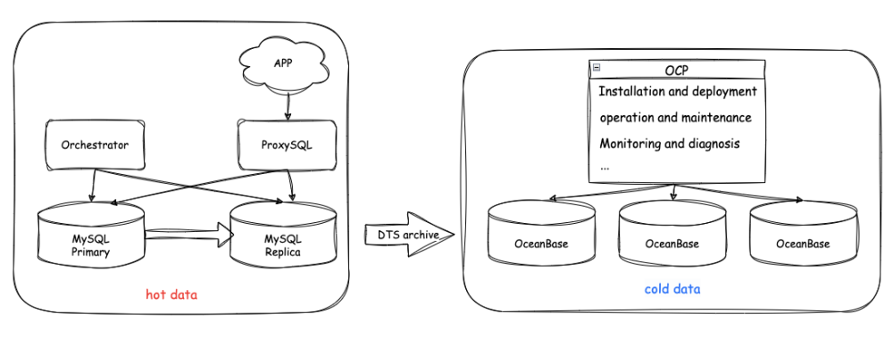
So far, eight OceanBase archive clusters, comprising more than 20 tenants, are managed on OCP. And, our app keeps writing data by user ID hash to the MySQL database, which has hosted more than 10,000 table shards. Expired data is directly imported into the OceanBase archive database.
Our old ClickHouse archive cluster is still in use to support reads of some historical data. However, considering the stability and security issues of ClickHouse, we will gradually replace it with OceanBase Database.
IV. Benefits
To begin with, the powerful compression capability of OceanBase Database helps us archive cold data with ease, and saves storage resources by more than 70%.
In addition, OceanBase Database is a native distributed system with great scalability. It provides high availability with an RPO of 0 and an RTO of less than 8s when a minority of replicas fail, making the database more stable.
Last but not least, OceanBase Database comes with GUI-based OCP, which is a lifesaver for our DBAs in handling deployment and O&M tasks. OCP allows us to manage objects such as clusters, tenants, hosts, and software packages over their entire lifecycle, including their installation, O&M, performance monitoring, configuration, and upgrade. OCP of the latest version supports custom alerts. For example, we can set custom disk and memory usage thresholds. Once the usage exceeds the thresholds, we receive alerts immediately. OCP also supports backup and restore, as well as automated diagnostics during O&M.
V. Outlook
1. Support for online distributed database capabilities
As mentioned above, we still use a MySQL online database. Compared with using a single table in a distributed database, performing database and table sharding in the MySQL database is more complex. If the data in multiple data tables or databases is associated, the difficulty of maintaining data consistency increases drastically.
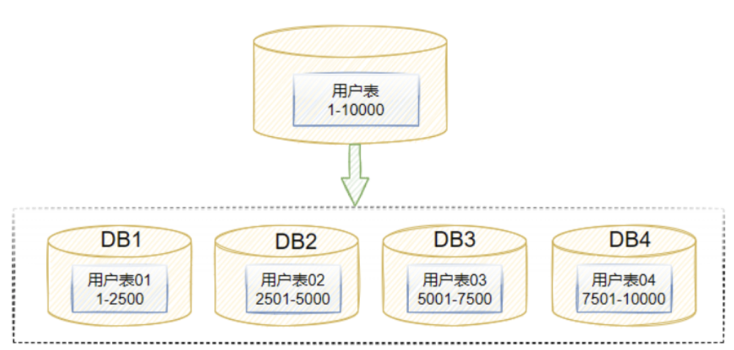
In addition to data consistency challenges, the complexity of O&M and management of multiple database and table shards also makes system troubleshooting and maintenance a headache. As data is stored in multiple database and table shards, it is hard to trace historical data in this online MySQL database.
At present, many of our upper-level business modules rely on the online MySQL database, and it may take some time for us to replace it with OceanBase Database.
The good news is, after the introduction of OceanBase Database, we have improved our capabilities to support natively distributed database tables, and developed more convenient and feasible solutions for transforming business modules with large storage capacity and complex sharding logic.

2. ODC and Binlog service
We learned that since V4.2.2, OceanBase Developer Center (ODC), a GUI-based database development tool tailored for OceanBase Database, supports data archiving from MySQL to OceanBase Database and within OceanBase Database. It also supports configuration of automatic tasks at multiple levels. Considering the high compression ratio of OceanBase Database and the data archiving capabilities of ODC, it is quite easy to build an archive database based on OceanBase Database.
Currently, our business team mainly uses the internal RDS platform to call the DTS tool for data archiving. ODC is used as a supplement to the DTS tool. We will continue to learn other features of ODC to strengthen our capabilities in database O&M.
OceanBase Database V4.2.1 and later provide the Binlog service, which allows downstream services, such as data warehouses, of the sharded MySQL database to subscribe to binlogs in a unified way, rather than separately subscribing to binlogs of each MySQL shard, making the binlog subscription easier.
3. Exploration of best practices
The introduction of the new database system brings more challenges to our DBAs. To better tap the potential of OceanBase Database, they must select hardware of proper specifications and continuously optimize service configurations, while maintaining the stability of the database. We will keep working with the OceanBase team to figure out the most efficient and cost-effective way in using OceanBase Database, and provide strong support for the rapid and stable development of our business.