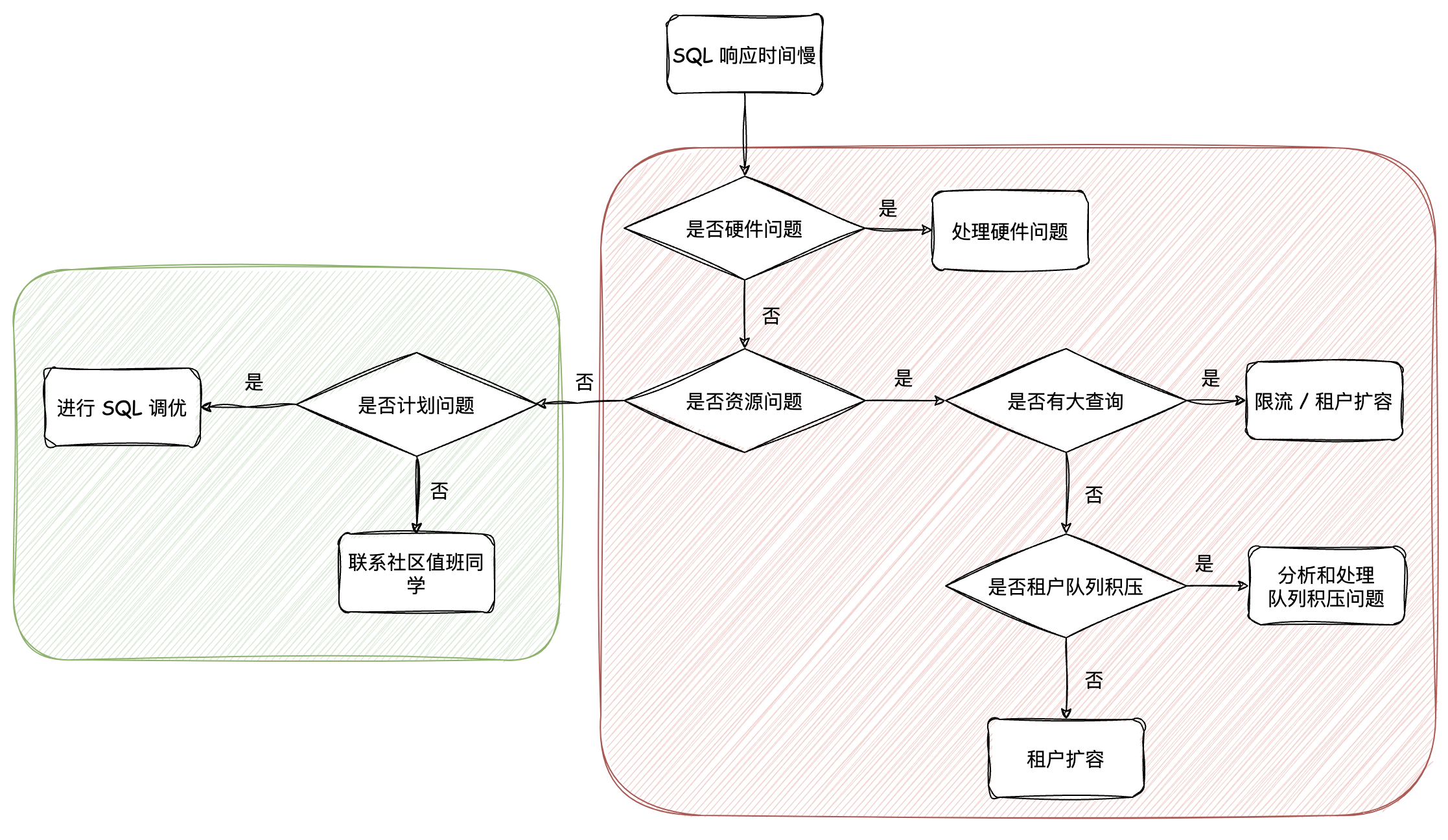
系统响应时间不符合预期
业务及数据库表现
业务表现:业务响应由快变慢,或者直接超时报错。
数据库表现:SQL 执行时间变长,响应曲线陡升,SQL 响应延迟 (RT) 明显变高。
排查方向和流程
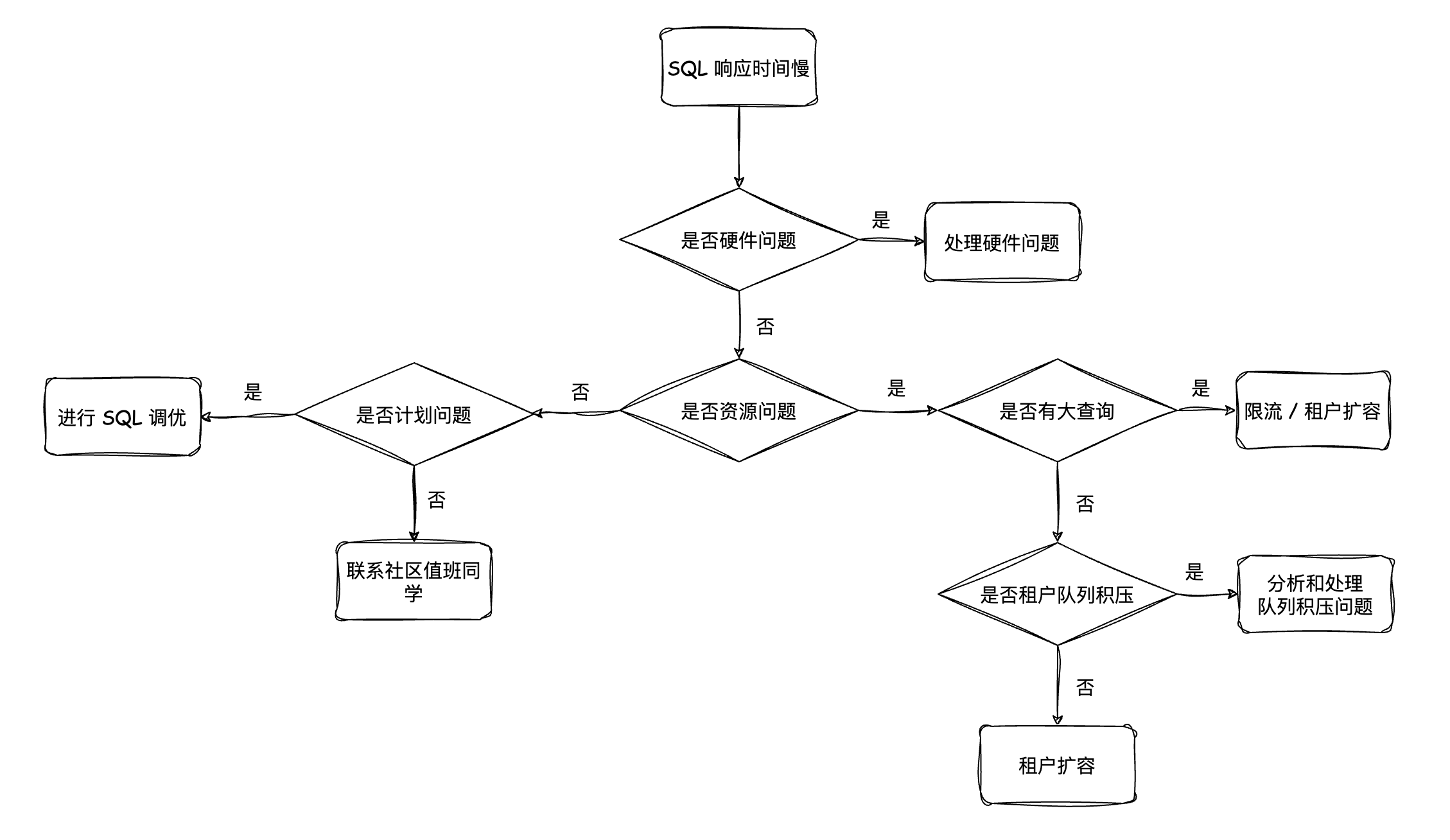
排查硬件问题
首先需要排除一下是否由网络、磁盘 IO 等硬件问题导致的 SQL 响应延迟,这里不多啰嗦。
排查大查询(slow query)问题
直接通过 OCP 排查是否存在 “可疑 SQL”。

如果存在某个大查询(或者叫大请求)占用了过多资源,导致大量短请求无法及时得到响应,可以考虑以下方法:
-
通过 OCP 对占用过多资源的大请求进行限流。
-
通过 large_query_worker_percentage(默认 30%) 来设置大查询可以使用的系统资源占比。
-
通过 large_query_threshold (默认 5s)来设置大查询的判定阈值。这个时间阈值修改之后对系统影响可能会比较大,在不了解参数含义时,不建议用户随意修改。
-
通过 OCP 添加主机,并对租户进行扩容(Zone 内增加节点)。
排查租户队列积压问题
排查方法
资源问题这里除了某几个大查询占用了过多资源,还有一种租户队列积压的情况。排查方式有以下几种:
-
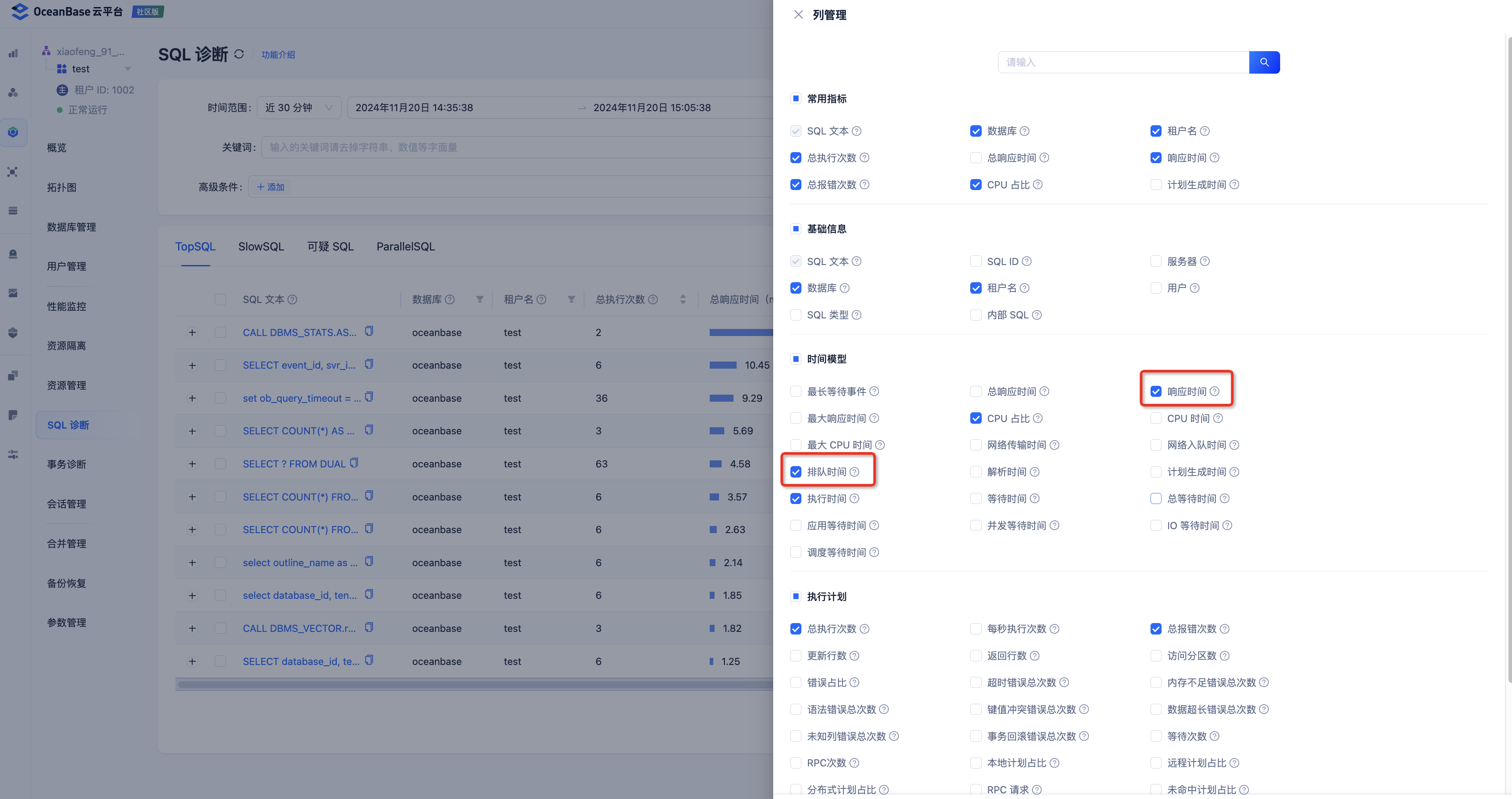
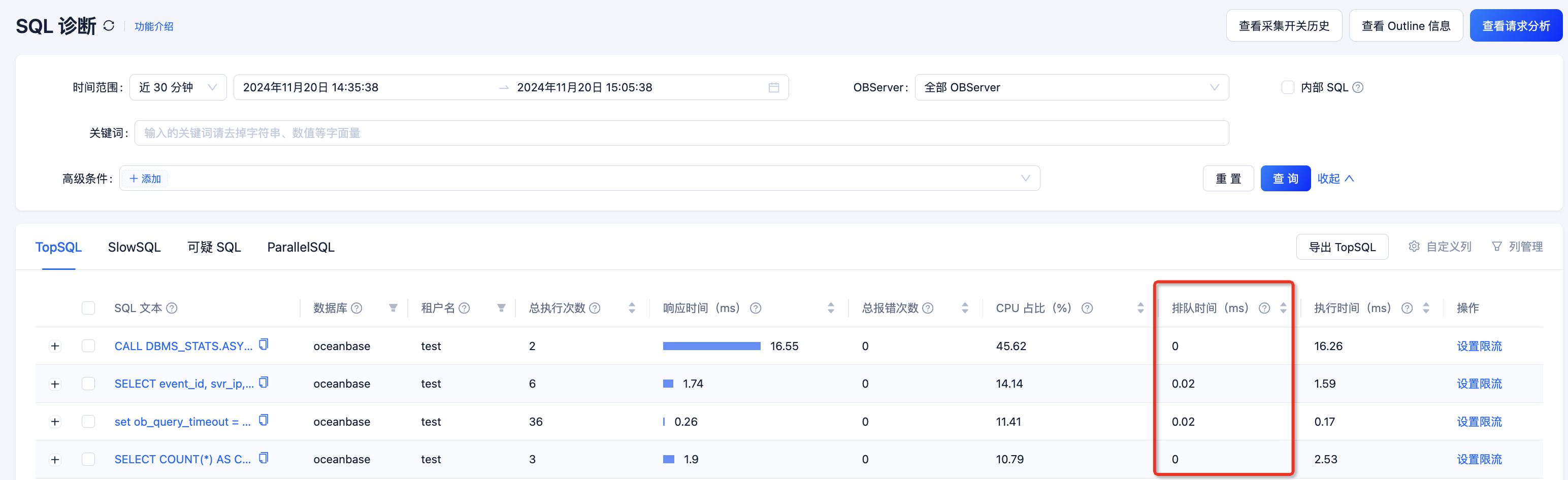
可以通过 OCP 观察单条 slow query 的平均 queue_time(排队时间)在 elapsed_time(响应时间) 中的占比是否符合预期,如果 queue_time 超长,则可能是租户队列积压。
-
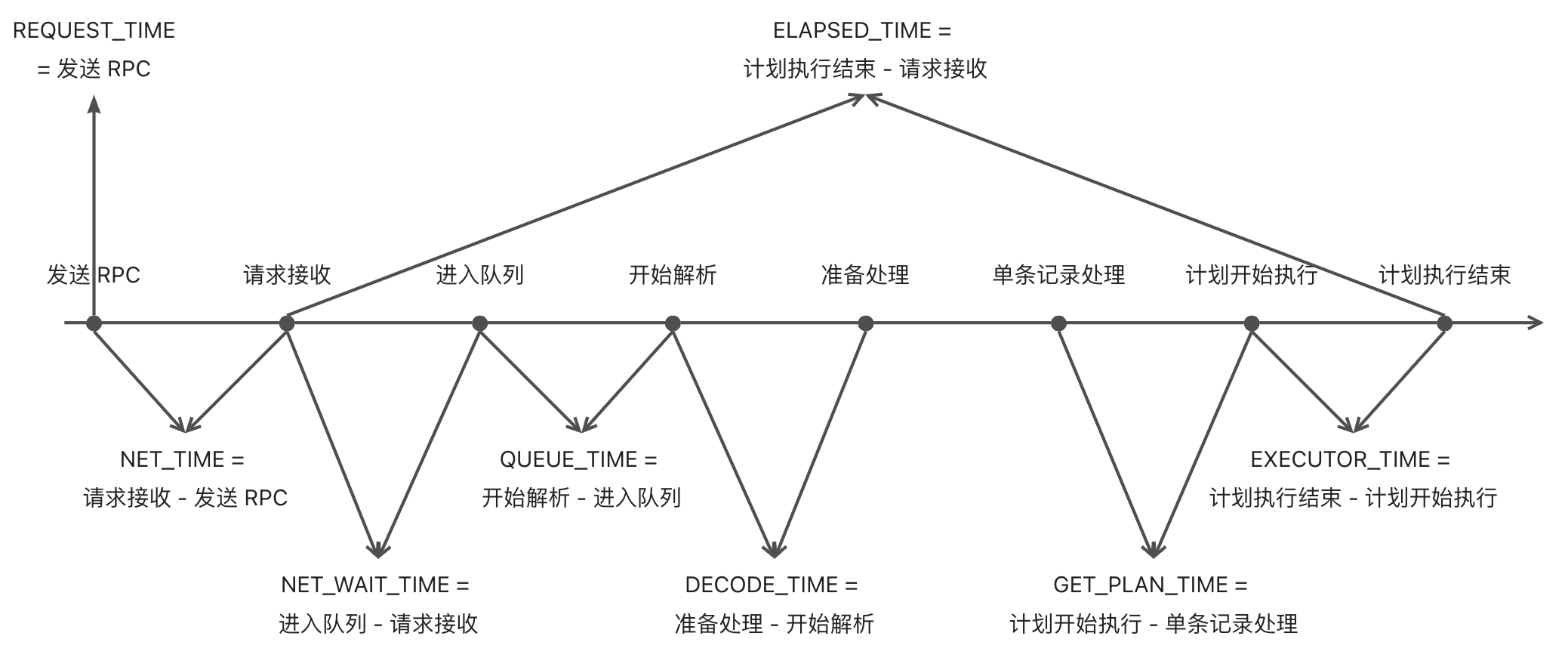
或者可以通过 GV$OB_SQL_AUDIT 视图查询 slow query 各种维��度的信息,详见:《DBA 入门教程》中的 “分析 SQL 监控视图” 小节。一些重要的事件间隔如下:
-- 这个例子中查询的是:tenant id 为 1002 的租户,在 2024-11-20 12:00:00 之后
-- query 执行时间超过 100 ms 的其中一条 SQL
select
tenant_id,
request_id,
usec_to_time(request_time),
elapsed_time,
queue_time,
execute_time,
query_sql
from
oceanbase.GV$OB_SQL_AUDIT
where
tenant_id = 1002
and elapsed_time > 100000
and request_time > time_to_usec('2024-11-20 12:00:00')
order by
elapsed_time desc
limit 1 \G
*************************** 1. row ***************************
tenant_id: 1002
request_id: 13329994
usec_to_time(request_time): 2024-11-20 15:14:58.765564
elapsed_time: 153118
queue_time: 34
execute_time: 139873
query_sql: select * from xxxx where xxxx;
1 row in set (0.11 sec) -
如果需要观察特定租户的队列积压情况,可以通过日志中的 'dump tenant info' 来实现,这个是最通用的方法:
grep 'dump tenant info' observer.log*

日志中,有几个关键字可参考:
-
req_queue,表示普通请求队列
-
total_size=n,n 表示优先级队列中总共的排队请求数。
-
queue[x]=y,y 表示每个优先级子队列中的排队请求数(x 越小队列优先级越高)。
-
-
multi_level_queue,表示嵌套请求队列
-
total_size=n,n 表示优先级队列中总共的排队请求数。
-
queue[x]=y,y 表示每个层级子队列中的排队请求数。
-
queue0: 存放无嵌套的请求,由于无嵌套请求有优先级队列来存放,因此常为空。
-
queue1: 存放1层嵌套的请求(如 sql 触发的 rpc)
-
queue2: 存放2层嵌套的请求(如 sql 触发的 rpc 再次触发的 rpc)
-
……
-
-
-
group_id = x, queue_size = y 中的 y 表示分组队列排队请求数。
- group 是用来处理特定种类 rpc 请求的,关于每个 group id 对应哪种 rpc 请求。可以参考开源代码 ob_group_list.h。
在日志中搜索 dump tenant info,好处是可以看到历史,可以同时看到队列和线程的大致情况,缺点是日志会周期性打印,实时性不强。
- 或者通过登录 sys 租户,执行以下 SQL 观察租户队列积压情况:
obclient [oceanbase]> select * from oceanbase.__all_virtual_dump_tenant_info where tenant_id = 1002\G
*************************** 1. row ***************************
svr_ip: 11.158.31.20
svr_port: 22602
tenant_id: 1002
compat_mode: 0
unit_min_cpu: 2
unit_max_cpu: 2
slice: 0
remain_slice: 0
token_cnt: 10
ass_token_cnt: 10
lq_tokens: 0
used_lq_tokens: 0
stopped: 0
idle_us: 0
recv_hp_rpc_cnt: 99
recv_np_rpc_cnt: 2226
recv_lp_rpc_cnt: 0
recv_mysql_cnt: 5459
recv_task_cnt: 5
recv_large_req_cnt: 0
recv_large_queries: 3661
actives: 10
workers: 10
lq_waiting_workers: 0
req_queue_total_size: 0
queue_0: 0
queue_1: 0
queue_2: 0
queue_3: 0
queue_4: 0
queue_5: 0
large_queued: 0
1 row in set (0.001 sec)
这张虚拟表,可以实时地查看队列信息,好处是实时性强,缺点是不记录历史信息。
解决方法
这里先多说几句,OceanBase 的线程模型,是一个典型的生产者消费者模型,当请求的生产速度长期大于消费速度时,租户的工作队列就会被打爆,并返回错误码 -4019。
即使没有打满,也会表现出请求排队耗时长的情况,如租户中存在大量自增列的场景(详见:《DBA 入门教程》中的 “扩展功能” 的 “序列” 部分)。
解决方法如下:
-
如果租户队列已经爆了,只能通过重启恢复(停压力也不行)。 建议去社区论坛发帖,联系在论坛中值班的技术支持同学,让他们协助你留下 obstack 或者 pstack 的堆栈信息,否则很难诊断具体原因。
-
一般租户队列爆的问题较少,更常见的是租户队列积压。
-
如果出现租户队列积压,请优先检查是否有 order 属性的自增列。
-
如果不是有大量自增列集中写入数据,需要联系社区论坛的值班同学通过 obstack 或者 pstack 分析堆栈信息。
-
分析的结论如果不是死锁引起的队列积压,可以通过调大特定租户的规格来缓解特殊场景下的队列积压。这里的 “特殊场景” 指有大量写入导致线程等锁开销,或者操作极耗 cpu(可以通过 top 或者tsar 来验证)。
-
排查计划问题
如果资源问题这个分支的嫌疑被排除了,大概率就是计划问题了。
如果 SQL 执行效率是 “由快变慢”,那么可以重点怀疑以下几个常见问题:
-
第一个是计划缓存(plan cahce)的 bad case,也被人称为 “大小账号问题”。问题描述、排查思路、解决方法都详见:《DBA 入门教程》中的 “常见的 SQL 调优方式” 的 “计划缓存的 bad case” 部分,这里不再赘述。简而言之,“大小账号问题” 分两种:
- 一种就是《入门教程》中说的,SQL 中只有常量不同时,会共享 plan cache 中的同一个计划,这种场景可能会有问题;
再多说一句,算是偷偷做个预告:OceanBase 后续的版本会在某些合适的场景中支持为 SQL 中的不同常量,缓存不同的计划,以消除现在这个烦人的问题。
- 另一种是 SQL 涉及的表对象的统计信息发生了较大变化,但依然使用的是统计信息发生变化前 plan cache 中缓存的计划。
这个问题也会在后续版本的 plan cache 中得到缓解。
- 一种就是《入门教程》中说的,SQL 中只有常量不同时,会共享 plan cache 中的同一个计划,这种场景可能会有问题;
-
第二个是 Buffer 表问题。也详见蓝色链接,不再赘述。
这里也只多说一句,《DBA 入门教程》中只给了大家一个解决问题的思路,就是想办法提高特定表的合并频率。除了手动合并,OceanBase 数据库从 V4.2.0 版本开始支持自适应合并,通过修改 table_mode 为 queue 模式,来缓解该问题。
-
第三个是在版本升级后,在低版本中好的计划,在高版本中回退成了差的计划。
- 一般来说,升级之后,绝大多数的计划都会变成更优的计划,这种回退只是极其个别的情况。这种情况在《入门教程》中没有为大家介绍,可以直接通过 OCP 观察对应 SQL 的历史趋势及计划变化来判断。
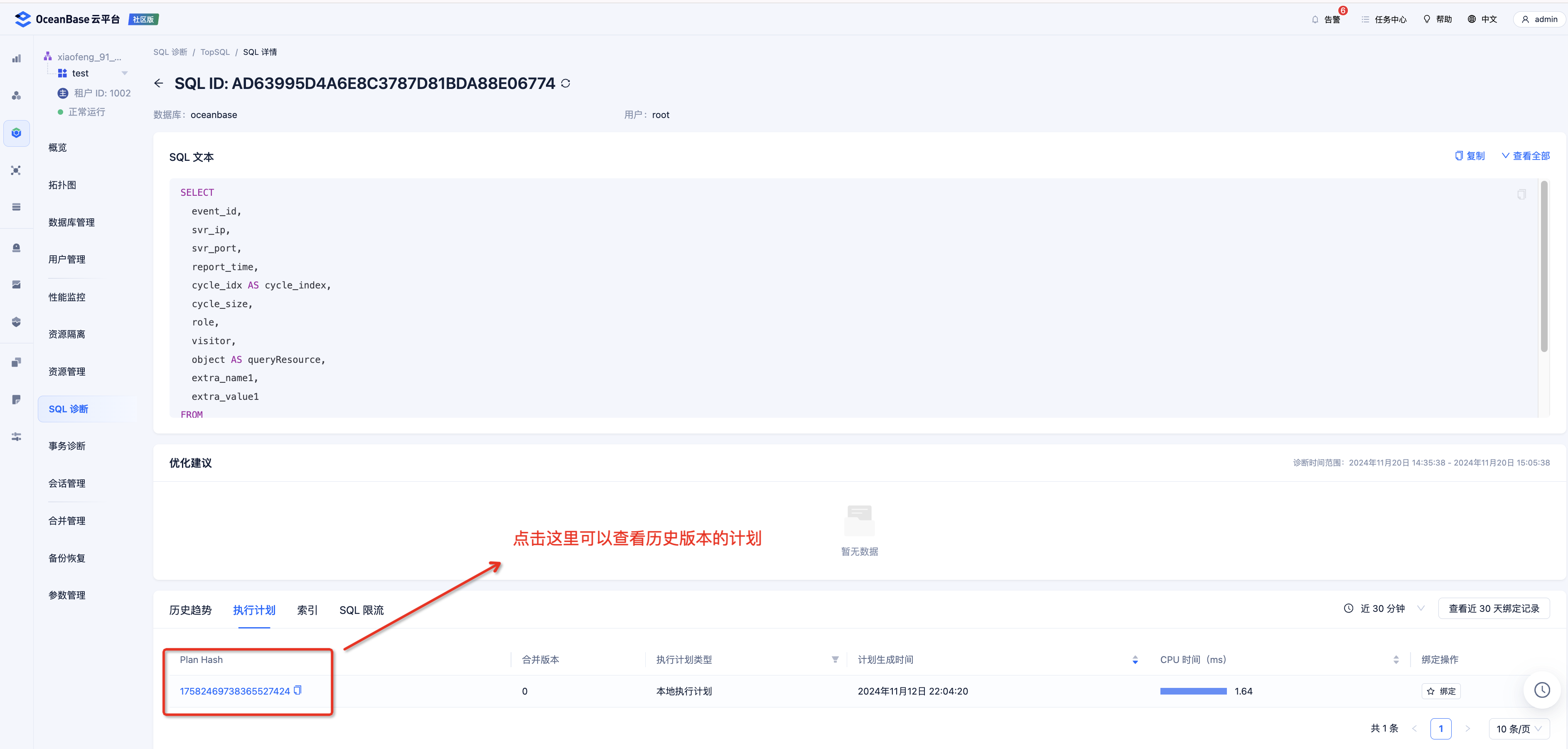
- 解决方法详见《入门教程》中的 “通过 Hint 生成指定计划” 以及 “通过 Outline 进行计划绑定”。
- 一般来说,升级之后,绝大多数的计划都会变成更优的计划,这种回退只是极其个别的情况。这种情况在《入门教程》中没有为大家介绍,可以直接通过 OCP 观察对应 SQL 的历史趋势及计划变化来判断。
-
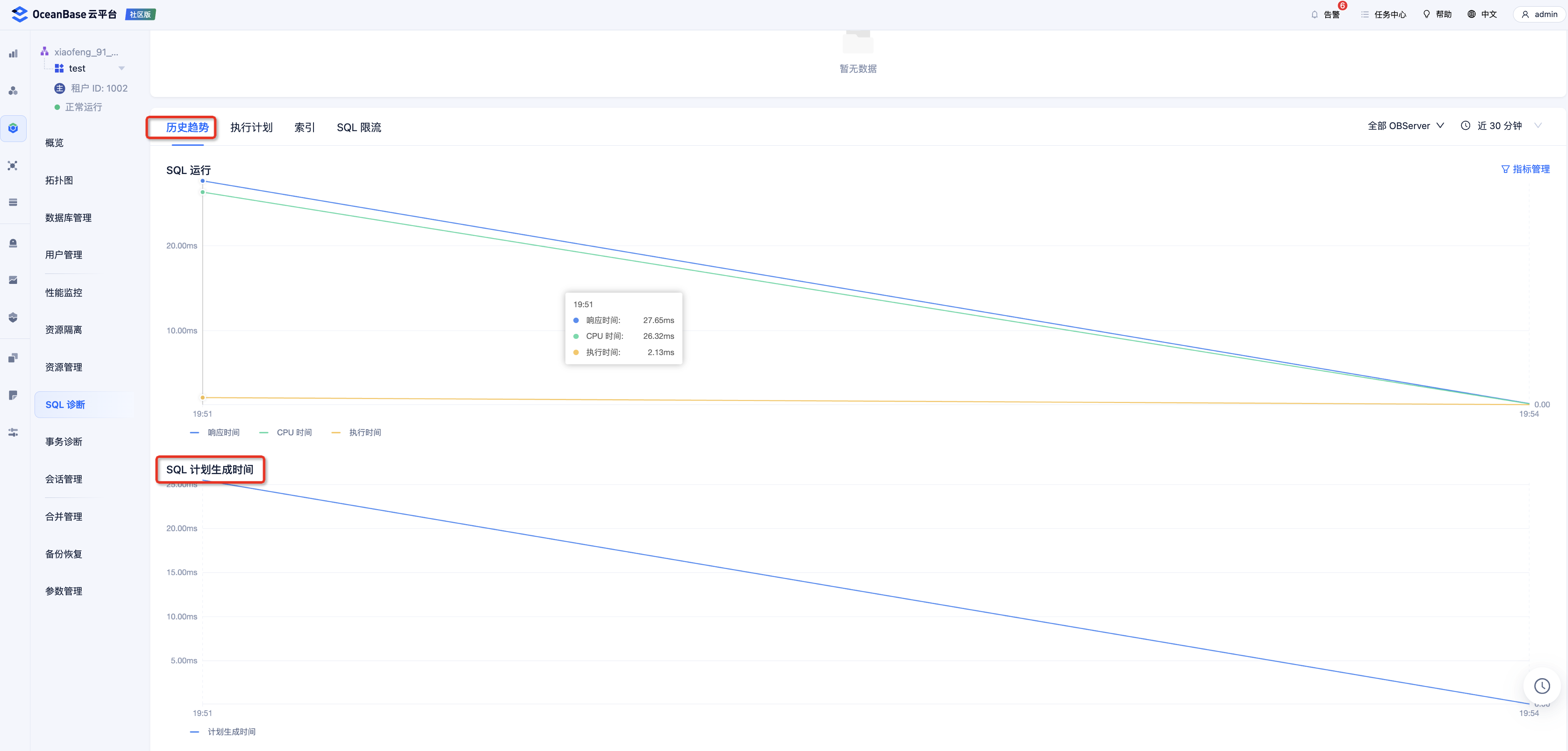
第四个是硬解析问题,也可以直接通过 OCP 观察对应 SQL 计划生产时间的历史趋势来判断。解决方法详见《入门教程》中的 “硬解析问题”。
如果 SQL 执行效率不是由快变慢,而是 “一如既往的慢”,那就去看这本《DBA 进阶教程》中的 “SQL 性能诊断和调优” 小节吧,哈哈~