数据库对象设计及使用规范
说明:
本小节红字部分的内容为用户 “必须” 遵循的行为。
其余内容仅供参考,只是 “推荐” 用户做的内容,并不 “强制” 用户必须遵循。大家根据真实业务需求决定是否采取这些建议即可。
对象名定义规范
各种对象的命名规范就不再老生常谈了,无非就是名字长度不要超级长,要能够望文生义,表示出特定的对象类型以及对应的业务含义等等,例如 tbl_student_id。大家的命名风格都有所不同,个人觉得没有所谓的正确和错误,也没必要强行统一。
这里只建议大家:除��非有特殊原因,尽量不要使用特殊字符或者关键字作为对象名。原因是看着别扭,用着更别扭,纯属自己给自己找别扭。
之前见过有个别的用户给表命名为: table(保留关键字),给列命名为: `(表示转义的特殊字符)。看着就跟加密过似的。自己人用着舒不舒服暂且不提,如果出了问题,技术支持同学排查起来也要吐上几升血。
obclient [test]> create table `table` (```` int);
Query OK, 0 rows affected (0.050 sec)
obclient [test]> insert into `table` values(123);
Query OK, 1 row affected (0.007 sec)
obclient [test]> select ```` from `table`;
+------+
| ` |
+------+
| 123 |
+------+
1 row in set (0.000 sec)
因为各种对象名 rename 都很方便,所以这部分就直接略过了。
tenant(租户)使用规范
租户的概念可以类比为 MySQL 的一个实例,概念详见这个教程的《租户背景知识》小节。
禁止在生产环境中使用 sys 租户存放用户数据!需要创建新的用户租户来使用!
sys 租户是被设计用来存放其他用户租户元信息的租户,不提供完整的数据库功能,误用可能会带来严重后果!
database(库)使用规范
禁止在生产环境中使用 information_schema、oceanbase 等系统自带元数据库来存放用户数据。误用可能会带来严重后果!
obclient [test]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| obproxy |
| oceanbase |
| test |
+--------------------+
5 rows in set (0.007 sec)
table(表)设计规范
为了建立出冗余更小、结构更合理的表,在进行数据库创建的时候要遵循一定的原则,在关系型数据库中这种规范被称为范式。请大家先自行了解数据库的三大范式。
-
表结构设计应该在三大范式思想的基础上,以业务性能为指导,适当进行数据冗余存储,以减少表的关联从而提升业务性能。冗余字段应遵循:
-
不是频繁修改的字段。
-
不是超长的字符串类型字段。
-
-
建表时应该设定主键。
-
建议使用业务字段做主键或做联合主键,不建议使用自增列做主键。
-
OceanBase 数据库的表存储模型为索引聚集表模型(
IOT),如果用户未指定主键,系统会自动生成一个隐藏主键。
-
-
表、字段建议有
COMMENT属性。 -
表中字段如果需要保证非空,建议显式指定
NOT NULL属性 -
表中建议根据需要定义
DEFAULT值。 -
不同表中的相同列,尽量保证列定义完全一致,避免在计算时产生不必要的隐式转换。
-
进行
join的关联字段,数据类型保证一致,避免在计算时产生不必要的隐式转换。除了数据类型,还要关注 collation、precision、scale 等数据类型的附属属性,这里属性不同很容易会造成索引失效、计划不优等问题。
column(列)设计规范
-
建议在创建自增列字段时使用 bigint 类型。如果使用 int 类型,则容易达到 max value。
-
建议根据业务需求,选择合适的字符串长度、以及数字的 precision、scale。可以节约存储空间,并能够提升查询性能。
-
对不同类型的列进行比较时,会发生隐式类型转换。隐式类型转换时,由标准 SQL 定义的转换方向大致是:字符串类型 -> 数字类型 -> 时间类型。为了明确业务真实需要的类型转换方向,以及为了充分利用索引加速查询,建议在比较前,使用 cast 或 convert 等方式来进行显式类型转换。
partition(分区)设计规范
分布式数据库的优势在于对于空间问题和请求访问问题分而治之。针对每个分区的访问,由该分区所在的节点响应即可。 即使该 SQL 并发很高,由于访问的是不同的分区,分别由不同的节点提供服务。每个节点自身也有一定能力满足一定的 QPS,所有节点集中在一起就能提供更大的 QPS。这个时候如果扩容节点数量,该 SQL 总的 QPS 也能获得相应的提升,这是分布式数据库里最好的情形。
分区的目标是将大量数据和访问请求均匀分布在多个节点上,一是想充分利用资源进行并行计算,消除查询热点问题;二是想利用分区裁剪来提升查询效率。 如果每个节点均匀承担数据和请求,那么理论上 10 个节点就应该能承担 10 倍于单节点的数据量和访问量。然而如果分区是不均匀的,一些分区的数据量或者请求量会相对比较高,出现数据偏斜(skew),这个可能导致节点资源利用率和负载也不均衡。偏斜集中的数据我们又称为热点数据。避免热点数据的直接方法就是数据存储时随机分配(没有规则)给节点,缺点是读取的时候不知道去哪个分区找该记录,只有扫描所有分区了,所以这个方法意义不大。实际常用的分区策略都是有一定的规则。
用户必须在业务查询条件明确的情况下,根据真实业务场景进行分区规划,不要在场景不明确的情况下随意进行分区规则。 在规划分区时,建议尽量保证各个分区的数据量相对均衡。
最常用的三种分区方式如下:
-
HASH 分区:一般适用于分区列 NDV(不同值的种类)较大,且难以划分出明确范围的情况。优点是容易让没有特定规则的数据也能够在不同的分区内均匀分布,缺点是在范围查询时难以进行分区裁剪。
-
RANGE 分区:一般适用于分区键容易划分出明确的范围的情况,例如可以把记录流水信息的大表,根据表示信息时间的列做 RANGE 分区。
-
LIST 分区:一般适用于需要显式控制各行数据如何映射到具体的某一个分区时,优点是可以对无序或无关的数据集进行精准分区,缺点是在范围查询时难以进行分区裁剪。
为了�更好地支持并行计算和分区裁剪,OceanBase 还支持二级分区。OceanBase 数据库 MySQL 模式目前支持 HASH、RANGE、LIST、KEY、RANGE COLUMNS 和 LIST COLUMNS 六种分区类型,二级分区为任意两种分区类型的组合。
例如在用户账单领域,数据库往往需要按照 user_id 做 HASH 一级分区,然后再在各个一级分区内部,继续按照账单创建时间做 RANGE 二级分区。
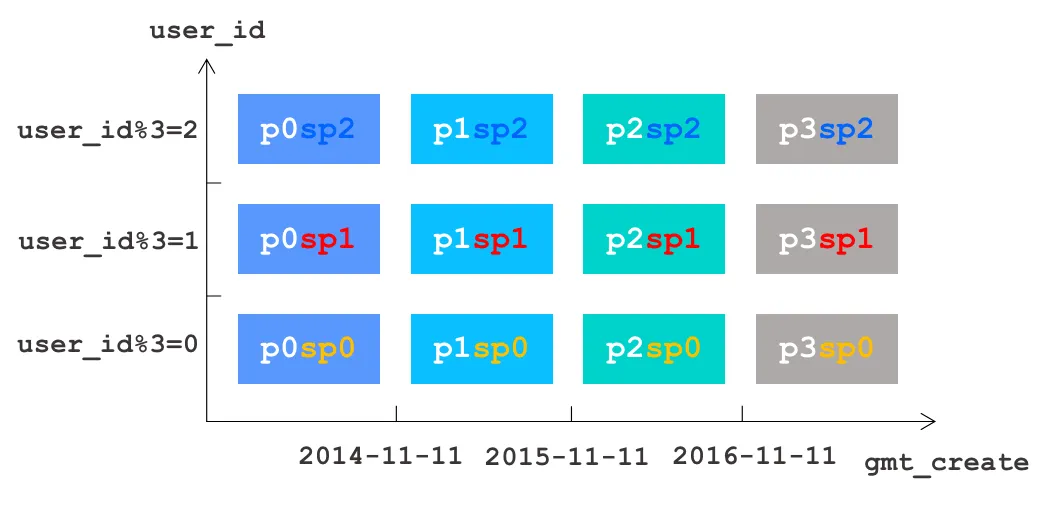
尽管 OceanBase 数据库在组合分区上支持 RANGE + HASH 和 HASH + RANGE 两种组合,但是对于 RANGE 分区的分区操作 add / drop,必须是 RANGE 分区做为一级分区的方式。所以针对例如数据量较大的流水表,为了维护方便(新增和删除分区),建议使用 RANGE + HASH 组合方式。
推荐阅读
-
分区相关内容,推荐大家阅读 OceanBase 官网文档《创建和管理分区》章节。
-
当分区划分后,数据在各个分区不均衡时,可能会因为数据倾斜导致查询性能不优的问题。推荐大家通过 OceanBase 的 SQL plan monitor 这个工具,来确认查询性能不优是否是由于数据倾斜造成的。工具的使用方法详见:《试用 obdiag 进行信息收集和问题诊断》这篇博客的 “收集 sql_plan_monitor 信息” 部分。
index(索引)设计规范
索引创建的规则
详见《OceanBase DBA 入门教程》中 “常见的 SQL 调优方式” 小节的 “索引调优” 部分。
全局索引的概念及适用场景
OceanBase 的 MySQL 租户下,索引被分为两种类型:本地索引和全局索引。
两者之间的区别在于:本地索引与主表分区方式保持一致,全局索引可单独设置索引的分区规则。MySQL 模式的租户,不显式指定索引类型时,默认的创建的是本地索引(local index)。
全局索引可以理解为是在 MySQL 上的一种扩展功能,概念及适用场景详见《OceanBase DBA 入门教程》中 “OceanBase 数据库在 MySQL 模式租户下的扩展功能” 小节的 “全局索引” 部分 。
索引设计的建议�
-
先看完上面的 “索引创建的规则” 和 “全局索引的概念及适用场景”。
-
非必要情况下不要使用全局索引(需要先了解上面的全局索引适用场景):
- 全局索引在查询时的回表代价非常高,是本地索引代价的十倍左右。
- 全局索引增删改的维护代价也比较高,在一定程度上会降低 DML 的性能。
- 创建全局索引时,建议指定分区规则,不指定时默认不分区。指定分区规则时,建议选择 NDV(列中不同值的数量)高的字段作为全局分区索引的分区键。
-
多表关联查询时,建议要保证被关联的字段上建有索引,这样可以提升 join 性能。需要 join 的字段,数据类型尽量保持一致,这样可以避免需要进行隐式类型转换而无法利用索引的问题。
-
可以考虑通过创建覆盖索引,来避免索引回表带来的开销。被索引覆盖的冗余列,尽量不要是大对象。
-
如果索引包含多个列,NDV(列中不同值的数量)高的列,建议放在前面。例如过滤条件是
where a= ? and b= ?,b 列的 NDV 远高于 a 列,那么索引可以创建为 idx(b, a)。 -
若存在
where a= ? and b= ?这样的过滤条件,建议使用组合索引 idx_ab(a,b)。不要分别在 a、b 字段上建立 idx_a(a),idx_b(b) 多个索引,因为同一张表上的过滤条件,无法同时使用多个索引。
索引使用的建议
索引修改流程为:新建索引时,必须确认新索引创建完成(即新索引已经生效),并确保旧索引不会被使用后,�再删除旧索引。
by the way:这条建议,有点儿像高考前建议大家带好准考证。虽然看似简单且容易理解,但是在蚂蚁集团内部,每年都会有个别同学在新索引还没建好时,就把旧索引给删了,然后造成支付宝在某个业务上一段时间处于不可用状态,产生大量资损,最后不得不处罚几个 DBA 来平息民愤。
希望各位 OceanBase 社区版的用户,在创建索引时,千万不要犯这个低级且可能会产生重大影响的错误!
increment column(自增列)设计规范
详见《OceanBase DBA 入门教程》中 “OceanBase 数据库在 MySQL 模式租户下的扩展功能” 小节的 “序列” 部分 。
- 先看完上面这个推荐大家阅读的小节。
- 创建自增列时,默认为 ORDER 属性(为了和 MySQL 行为兼容)。
- 如果不要求序列值递增,只要求唯一,建议将这个属性设置为 NOORDER,可以大大提升性能。
- 如果需要避免 NOORDER 模式在分布式场景下,在不同的的节点上申请自增值导致的自增值跳变的问题,需要将该属性调整为 ORDER。
recycle bin(回收站)设计规范
详见《OceanBase DBA 入门教��程》中 “OceanBase 数据库在 MySQL 模式租户下的扩展功能” 小节的 “回收站” 部分 。
- 先看完上面这个推荐大家阅读的小节。
- 对于 table 对象,虽然支持通过被删除前的原名(ORIGINAL_NAME)进行 flashback 和 purge,并且看上去很易用。但还是建议大家尽量通过可以作为唯一标识的新名字(OBJECT_NAME)对回收站对象进行还原和清空,这样可以避免由于记错通过对象原名进行操作的规则而造成的损失。
tablegroup(表组)设计规范
因为表组是扩展功能(即 MySQL 没有的功能),所以单独拿出来再提一句。
详见《OceanBase DBA 入门教程》中 “OceanBase 数据库在 MySQL 模式租户下的扩展功能” 小节的 “表组” 部分 。