字符集使用规范
说明:
目前 DBA 进阶教程的内容暂时对应的是 OceanBase 社区版本 MySQL 模式的租户,本小节的架构部分不涉及商业版 Oracle 模式下的内容。社区版和商业版的能力区别详见:官网链接。
基础知识
先简单介绍几个和数据库相关的基础知识,就是 charset(字符集)和 collation(字符排序规则或者叫比较规则)的概念,已经了解的同学可以直接跳过这段内容。
charset
简单来说,charset 会定义字符如何被编码和存储。例如:
- 当 charset 为 utf-8 时,大写字母 "A" 会被编码为 1 个字节:0100 0001(也就是十六进制的 0x41);
- 当 charset 为 utf-16 时,大写字母 "A" 被编码为 2 个字节:0000 0100 0000 0001(也就是十六进制 0x0041)。
不同的字符集支持存储的字符种类和范围也有所不同,例如 utf-8 字符集可以存储 Unicode 字符,而 latin1 字符集只能存储西欧语言字符。
collation
collation 是 charset 的一个属性,用来定义字符的比较和排序方式。例如当 charset 被设置为 utf8mb4 时,可选的 collation 就会有 utf8mb4_general_ci、utf8mb4_bin、utf8mb4_unicode_ci 等等。
- utf8mb4_general_ci:不区分大小写的通用排序规则(ci 是 case insensitive 的意思,即不区分大小写);
- utf8mb4_bin:基于二进制比较,区分大小写的排序规则;
- utf8mb4_unicode_ci:基于 Unicode 的,不区分大小写的排序规则。
- utf8mb4 下还有很多针对各种不同语言的排序规则,例如根据汉语拼音排序的 utf8mb4_zh_pinyin_ci 等等。
charset 和 collation 是一对多的关系,一种 collation 属于且仅属于一种 charset。例如定义一个列为 c3 varchar(200) COLLATE utf8mb4_bin 时,这个列的 charset 就会自动被设置为 utf8mb4。
设置数据库对象的字符集
本文介绍在 OceanBase 中进行字符集选择的规范。
用户可以在 tenant 级、database 级、table 级、 column 级、session 级设置字符集。目前 OceanBase 支持 utf8mb4、gbk、gb18030、binary 、utf16 、latin1 等字符集。
obclient [test]> show charset;
+--------------+-----------------------+-------------------------+--------+
| Charset | Description | Default collation | Maxlen |
+--------------+-----------------------+-------------------------+--------+
| binary | Binary pseudo charset | binary | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| gbk | GBK charset | gbk_chinese_ci | 2 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 2 |
| gb18030 | GB18030 charset | gb18030_chinese_ci | 4 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| gb18030_2022 | GB18030-2022 charset | gb18030_2022_chinese_ci | 4 |
+--------------+-----------------------+-------------------------+--------+
7 rows in set (0.008 sec)
obclient [test]> show collation;;
+-------------------------+--------------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+-------------------------+--------------+-----+---------+----------+---------+
| utf8mb4_general_ci | utf8mb4 | 45 | Yes | Yes | 1 |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 |
| utf16_general_ci | utf16 | 54 | Yes | Yes | 1 |
| utf16_bin | utf16 | 55 | | Yes | 1 |
| gb18030_chinese_ci | gb18030 | 248 | Yes | Yes | 1 |
| gb18030_bin | gb18030 | 249 | | Yes | 1 |
| latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 |
| latin1_bin | latin1 | 47 | | Yes | 1 |
| gb18030_2022_bin | gb18030_2022 | 216 | | Yes | 1 |
| gb18030_2022_chinese_ci | gb18030_2022 | 217 | Yes | Yes | 1 |
| gb18030_2022_chinese_cs | gb18030_2022 | 218 | | Yes | 1 |
| gb18030_2022_radical_ci | gb18030_2022 | 219 | | Yes | 1 |
| gb18030_2022_radical_cs | gb18030_2022 | 220 | | Yes | 1 |
| gb18030_2022_stroke_ci | gb18030_2022 | 221 | | Yes | 1 |
| gb18030_2022_stroke_cs | gb18030_2022 | 222 | | Yes | 1 |
+-------------------------+--------------+-----+---------+----------+---------+
18 rows in set (0.007 sec)
说明:
为支持无缝迁移,OceanBase 在语法上将
UTF8视为UTF8MB4的同义词。数据库字符集暂不支持修改。
以 gbk 字符集为例:
-
在创建租户时设置字符集
-
当通过 OCP 创建租户时,直接选择字符集为 gbk 即可。
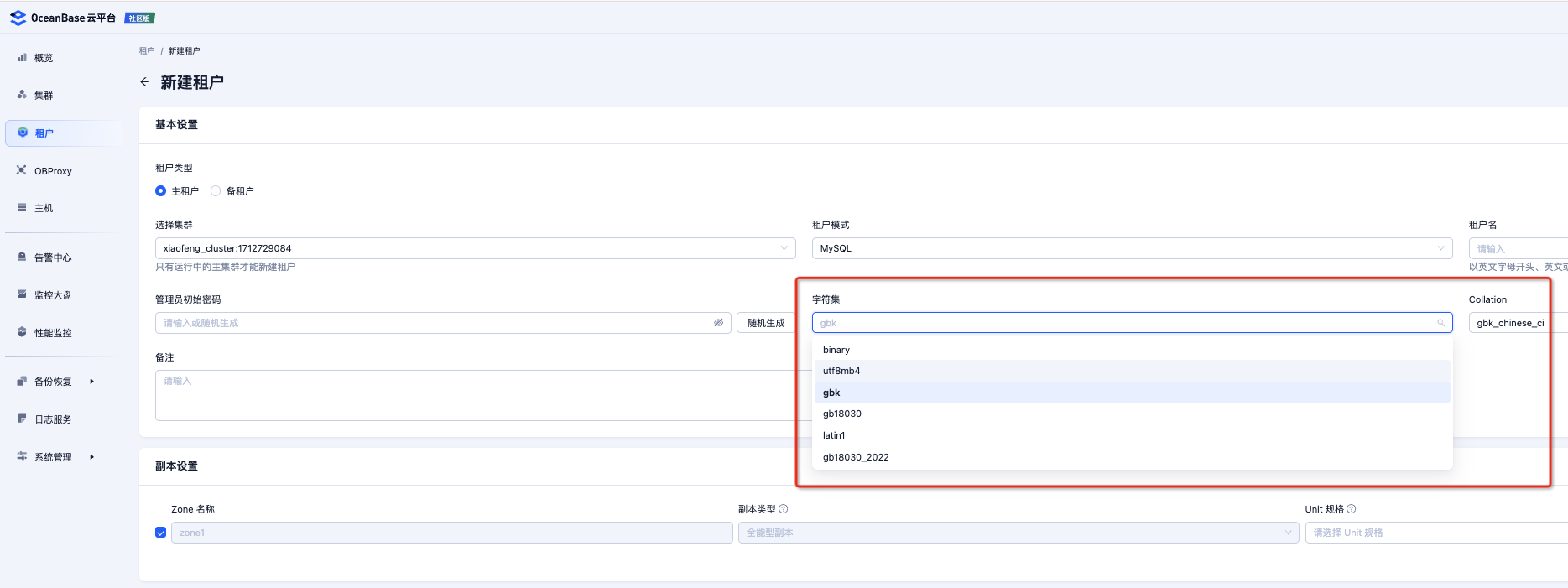
-
当通过命令行创建租户时,可以在 create tenant 语句添加 charset 设置,添加
"charset=gbk"。create tenant zlatan replica_num = 1,
resource_pool_list =('pool1'),
charset = gbk
set
ob_tcp_invited_nodes = '%',
ob_compatibility_mode = 'mysql',
parallel_servers_target = 10,
ob_sql_work_area_percentage = 20,
secure_file_priv = "";
-
除了 tenant,在创建 database、table、column 时,也都支持指定 charset 和 collation。如果不指定,就默认使用上级数据库对象的 charset 和 collation。对象级别从高到低分别是 tenant、database、table、column。
创建这些数据库对象的语法就不再一一展示了。
设置客户端(链路)字符集
客户端(链路)字符集是配置 Client 和 Server 之间交互使用的字符集设置。
Client 将 SQL 字符串的发给 Server 执行,Server 将执行结果返回给 Client。
在这个过程中,Server 需要明确知道 Client 使用的字符集是什么,才能正确的解析,执行和返回结果。
在不同环境下,Client 可以是 OBClient、jdbc 或 OCI 等,因此有时候也会叫做链路字符集。
-
租户字符集与客户端字符集没有直接关系,是相互独立配置的。
GBK 租户可以被 GBK 的客户端连接,也可以被 UTF8 的客户端连接。
-
当客户端字符集为 GBK 时,Server 会按照 GBK 解析和执行接收到的 SQL 语句。
-
当客户端字符集为 UTF8 时,Server 会按照 UTF8 解析和执行收到的 SQL 语句。
-
-
配置方法
-
永久性修改
set global character_set_client = gbk;
set global character_set_connection = gbk;
set global character_set_results = gbk;- character_set_client:客户端字符集。
- character_set_connection:连接字符集。
- character_set_results:Server 返回给 Client 结果的字符集。
一般来说,客户端发给服务器,和服务器返回给客户端字符串的字符集是统一的。MySQL 模式使用 3 个变量的作用是可以更灵活地进行配置,一般推荐大家将三个变量都统一配置成客户端的字符集。
-
临时修改(仅对本 Session 生效)
- 方法一:
set character_set_client = gbk;
set character_set_connection = gbk;
set character_set_results = gbk;- 方法二:
set names gbk;
-
设置客户端字符集
-
使用 jdbc 连接 OceanBase 数据库,GBK 链路一般在 url 里修改参数设置,添加
characterEncoding=gbk。String url = "jdbc:oceanbase://xxx.xxx.xxx.xxx:xxxx?useSSL=false&useUnicode=true&characterEncoding=gbk&connectTimeout=30000&rewriteBatchedStatements=true"; -
使用 OBClient 客户端连接数据库,GBK 链路 bash 环境变量推荐使用
zh_CN.GBK的超集zh_CN.GB18030。-
修改 bash 环境变量
export LANG=zh_CN.GB18030
export LC_ALL=zh_CN.GB18030 -
修改终端的编码设置,将当前窗口设置为 gbk 编码。请根据终端界面指示进行操作。
-
注意
除了将数据库(observer 进程)配置成 GBK 链路之外,客户端、驱动也要做相应的配置,若环境配置错误,可能会显示乱码。
不同 collation 的字段联接(join)时索引失效问题
社区里经常会有一些用户遇到这类问题:join 的两个列都是 varchar 类型,charset 也相同,为何无法利用索引?
原因往往是表和列是由不同 DBA 分别创建的,所以设置了不同的 collation。其实 collation 不同也会导致索引失效,分析过程和几种解决方法详见这篇博客:《SQL 调优实践记�录 —— 分析一个在不同 collation 的列联接时,无法利用索引的问题》,这里不再赘述了。
需要大家特别注意的是:如果生产环境里的表是由不同的 DBA 分别创建的,用的时候一定记得看清 collation 被设成了什么,不然可能会导致计划不优,进而影响查询性能。
如无特殊需求,建议在最初创建列时,就提前将需要联接的列的 collation 进行统一。