社区版 OMS 问题排查手册
为什么要搞一个社区版工具问题排查手册?
一是因为 OceanBase 官网的工具文档,大多是商业版本的内容。类似于 OMS,商业版和社区版是两个完全独立的工具,所以需要一个社区版用户专用的 OMS 问题排查手册。
二是类似于 OBD 这种轻量的运维工具,目前是社区版数据库内核的专用工具(马上就会支持商业版的数据库内核),而且官网缺少比较详细的 OBD 问题排查手册,所以也有这种需求。
OCP 这种商业版和社区版几乎没有区别,共用同一套代码的工具,问题排查就详见官网文档吧,哈哈~
这个排查手册是 OMS 社区版的研发负责人刘彻老哥亲手为大家写的,堪称 OMS 问题排查 “宝典”。欢迎阅读和收藏。
今天和 OBD 研发负责人谐云老哥聊天,他说有大量社区版用户都在使用 OBD 对集群进行运维管理。所以预计在 2024.12 内,也会出一份类似的 OBD 社区版问题排查手册,大家后续可以关注下。
OMS 问题排查思路
OMS 社区版发生报错时,请先确认是否存在因官网文档中已提到的使用限制导致的异常。
下图为 OMS 社区版数据迁移或数据同步任务发生报错时的整体排查思路。
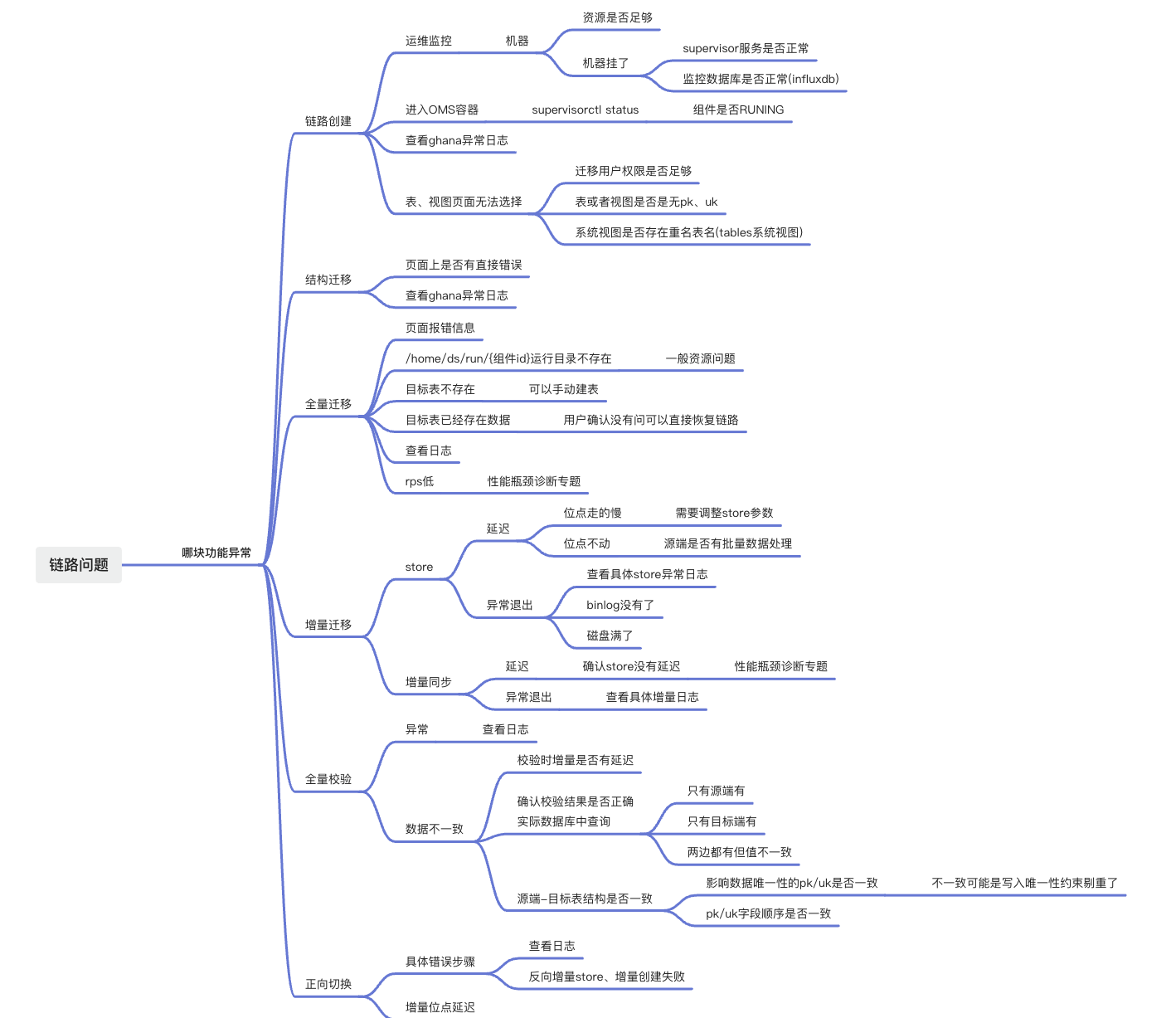
产品功能、组件和日志位置说明
说明:
所有日志文件均会自动归档压缩。您在查看日志时,请根据时间来确定具体的日志文件。
结构迁移
| 类型 | 描述 |
|---|---|
| 组件 | Ghana |
| 日志目录 | /home/admin/logs/ghana/Ghana |
| 结构转换相关日志(调用 DBCat 组件) | dbcat.log |
| 通常异常日志 | common-error.log |
| 通常输出日志 | common-default.log |
| 一些查询日志 | check_query.log |
| 任务步骤日志 | oms-step.log |
| 后台调度日志 | oms-scheduler.log |
全量迁移
| 类型 | 描述 |
|---|---|
| 组件 | Connector |
| 日志目录 | /home/ds/run/ {组件 ID} /logs |
| 错误日志 | error.log |
| 程序运行日志 | connector.log |
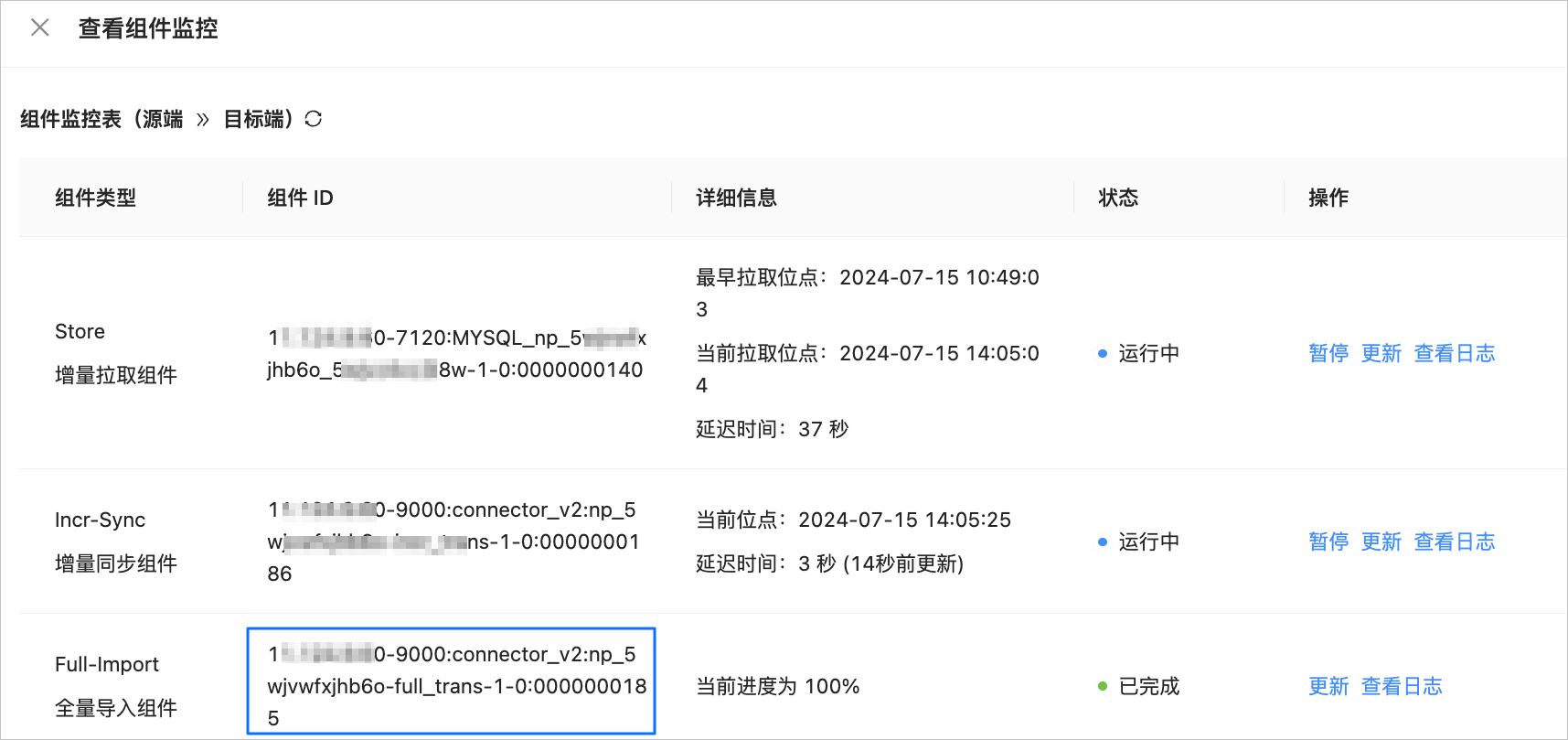
查看组件 ID 的操作如下:
-
登录 OMS 社区版控制台。
-
在左侧导航栏,单击 数据迁移。
-
在 数据迁移 页面,单击目标数据迁移任务的名称,进入详情页面。
-
单击页面右上角的 查看组件监控。

-
在 查看组件监控 对话框,查看 Full-Import 全量迁移组件的 组件 ID。
增量同步
增量拉取组件 Store
| 类型 | 描述 |
|---|---|
| 组件 | Store |
| 日志目录 | /home/ds/store/store{port}/log |
| obstore(源库为 V3.x) | liboblog.log |
| obstore(源库为 V4.x) | libobcdc.log |
| mysqlstore(Java 实现的 xlog) | connector/connector.log |
查看 store{port} 的操作如下:
-
登录 OMS 社区版控制台。
-
在左侧导航栏,单击 数据迁移。
-
在 数据迁移 页面,单击目标数据迁移任务的名称,进入详情页面。
-
单击页面右上角的 查看组件监控。
-
在 查看组件监控 对话框,查看 Store 增量拉取组件的 组件 ID。
组件 ID 的格式为
{ip}-{port}:{subtopic}:{seq},您可以从组件 ID 中获取 Store 组件的{port}。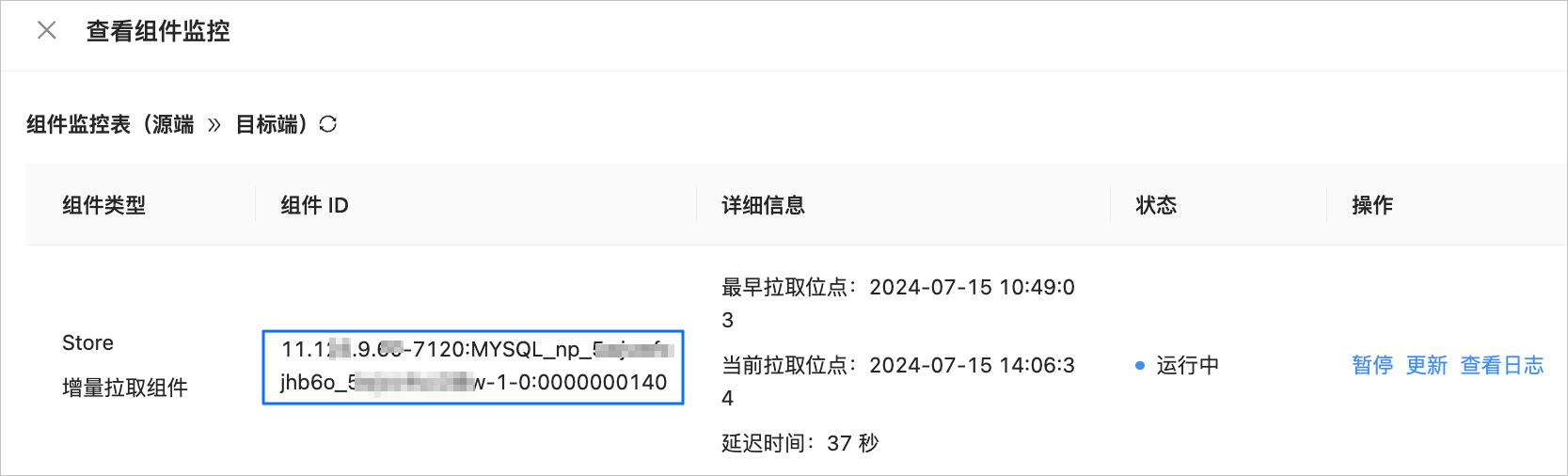
增量同步组件 Incr-Sync
| 类型 | 描述 |
|---|---|
| 组件 | Incr-Sync |
| 日志目录 | /home/ds/run/{组件 ID}/`logs |
| 错误日志 | error.log |
| 程序运行日志 | connector.log |
| 增量 Source 读取到的数据(仅有 PK) | msg/connector_source_msg.log |
| 增量 Sink 写入的数据(仅有 PK) | msg/connector_sink_msg.log |
| 增量过滤的数据 | msg/connector_filter_msg.log |
全量校验
| 类型 | 描述 |
|---|---|
| 组件 | Full-Verification |
| 日志目录 | /home/ds/run/{组件 ID}/logs |
| 错误日志 | error.log |
| 程序运行日志 | task.log |
| 校验结果文件目录 | /home/ds/run/{组件 ID}/verify/{subid}/ |
| 不一致数据以及原因文件 | /home/ds/run/{组件 ID}/verify/{subid}/{schema}/diff/{table_name}.diff |
| 可以在目标端执行的订正 SQL 文件 | /home/ds/run/{组件 ID}/verify/{subid}/{schema}/sql/{table_name}.sql |
{subid}:从 1 开始,每次重新校验会自动加 1。
正向切换
正向切换在管控组件中完成。如果您选择了反向增量,则会创建反向 Store 和反向的增量。
| 类型 | 描述 |
|---|---|
| 组件 | Ghana |
| 日志目录 | /home/admin/logs/ghana/Ghana |
| 通常异常日志 | common-error.log |
| 通常输出日志 | common-default.log |
| 链路步骤日志 | oms-step.log |
| 后台调度日志 | oms-scheduler.log |
反向增量
除组件 ID 命名有区别外,其它内容和增量同步一致。反向增量组件 ID 的名称中包含 reverse 关键字。
管控相关组件
| 组件 | 描述 |
|---|---|
| oms_console | Ghana 组件,日志目录为 /home/admin/logs/ghana/Ghana。 |
| oms_drc_cm | CM 组件,日志目录为 /home/admin/logs/cm。 |
| oms_drc_supervisor | Supervisor 组件,日志目录为 /home/admin/logs/supervisor。 |
安装阶段问题
进入 OMS 社区版容器,先查看 OMS 社区版组件是否正常。对于不正常的组件,请查看相关日志。
supervisorctl status
在安装阶段,通常会出现如下问题:
-
端口被占用
-
给 OMS 社区版提供的元数据库权限存在问题
-
部分操作系统 Docker 环境有问题,出现文件权限 ??? 的情况,导致服务无法启动。请更换系统安装 OMS 社区版。
-
用户系统为 cgroup2,导致 OMS 社区版机器转态不正常。OMS V4.2.4 之后版本解决该问题。
全量/增量迁移性能调优
关于全量迁移和增量同步性能调优的详情,请参见 全量/增量数据迁移性能调优。
并发、JVM 内存、每个分片记录数等问题
该部分内容可以解决大部分性能问题。
| 问题类型 | 解决方式 |
|---|---|
| 并发 | 源端并发 source.workerNum,目标端并发 sink.workerNum。通常全量迁移时,源端并发和目标端并发的设置相同,增量同步 Source 中无需设置。并发度和机器 CPU 核数量相关,最大可以设置为 CPU*4,同时需要查看机器中是否存在其他迁移任务在执行。 |
| JVM 内存 | coordinator.connectorJvmParam。主要调整 -Xms8g(初始内存)、-Xmx8g(最大内存)和 -Xmn4g(新增的内存),调整规则如下:
|
| 每个分片记录数 | source.sliceBatchSize,默认值为 600。对于大表通常 10000 即可,如果设置太大会消耗内存较多。您可以根据 logs/msg/metrics.log 中的 slice_queue 决定是否需要修改。如果是 0,则需要增加每个分片的记录数,原因是 Source Worker 线程会从 slice_queue 拉取分片,0 表示没有分片,Source Worker 便会等待空转。 |
全量迁移通常需要后建索引,提高全量迁移效率。对于目标库为 OceanBase 数据库的情况,您可以通过系统参数 struct.transfer.config 配置中的 ob.parallel 来配置创建索引的并发度。
增量同步
事务分片:source.splitThreshold。当源端存在批量操作导致增量延迟时,您可以进行调整,默认值为 128。批量操作类型为 INSERT 时,调整越大越好,上限为 512。批量操作 UPDATE 和 DELETE 时,调整值越小越好,下限为 1。
metrics.log 分析
判断瓶颈在哪里
slice 分片-> source 读取源端-> dispatcher 数据分发-> sink 写入目标
-
slice_queue大于 0,表示瓶颈不在这里。slice_queue等于 0,表示分片慢,增加source.sliceBatchSize每个分片的记录数,多表场景也可以增加source.sliceWorkerNum分片工作线程。 -
source_worker_num小于 source_worker_num_all`,表示瓶颈不在 Source 读取。 -
sink_worker_num小于sink_worker_num_all,表示瓶颈不在 Sink 写入。 -
dispatcher.ready_execute_batch_size等于 0,表示写入没有瓶颈,ready_execute_batch_size大于 0,表示写入慢。 -
dispatcher.wait_dispatch_record_size等于 0,表示分发没有瓶颈。wait_dispatch_record_size大于 0,表示 OMS 内部计算数据归属分区存在瓶颈(分区表情况下一般都会有积压,分区计算比较耗时)。旁路场景下可以关闭分区计算sink.enablePartitionBucket=false,也可能存在热点数据,详情请参见 疑似热点问题 的内容。 -
在 JVM 内存不够的情况下,可能发生 fullgc 情况,从而导致整个效率降低很多,也会出现数据库断链等容易误判的异常。您可以登录 OMS 社区版容器,查看进程 gc 情况。
-
如果源端在进行批量操作,建议您控制批量操作流量。
su - ds
ps -ef|grep "组件 ID"
/opt/alibaba/java/bin/jstat -gcutil {pid} 1s
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 18.27 64.08 0.90 97.11 93.45 7 0.374 0 0.000 0.374
0.00 18.27 64.08 0.90 97.11 93.45 7 0.374 0 0.000 0.374FGC 不断增加,则表示需要增加 JVM 内存。
{
"jvm": {
"JVM": "{\"heapMemoryMax\":7782,\"heapMemoryInit\":8192,\"heapMemoryUsed\":1072,\"heapMemoryCommitted\":7782,\"noHeapMemoryMax\":0,\"noHeapMemoryInit\":2,\"noHeapMemoryUsed\":78,\"noHeapMemoryCommitted\":83,\"gcInfoList\":[{\"name\":\"ParNew\",\"count\":6,\"costMs\":770},{\"name\":\"ConcurrentMarkSweep\",\"count\":1,\"costMs\":362}],\"threadCount\":34}"
},
"dataflow": {
"slice_queue": 0
},
"os": {
"OS": "{\"cpu\":0.5210029306414848,\"sysCpu\":62.941847206385404}"
},
"sink": {
"sink_worker_num": 0,
"ob_watermark_detect_times": 231,
"sink_request_time": 198.43,
"source_iops": 0.0,
"sink_total_transaction": 2384.0,
"ob_exceed_mem_high_watermark_times": 0,
"sink_total_record": 23383.0,
"paused_time_ms": 0.0,
"sink_commit_time": 3363.16,
"sink_worker_num_all": 8,
"shardTime": 0.0,
"sink_total_bytes": 8739678.0,
"sink_delay": 1717642529661,
"paused_total_time_ms": 0.0,
"ob_free_memory": 92,
"rps": 41.42,
"tps": 3.1,
"ob_exceed_cpu_high_watermark_times": 0,
"iops": 3921.59,
"sinkSlowRoutes": "",
"sink_execute_time": 17.25,
"ob_free_cpu": -1
},
"source": {
"source_read_time": 0.0,
"source_rps": 0.0,
"source_slice_time": 0.0,
"source_worker_num_all": 8,
"source_worker_num": 0
},
"dispatcher": {
"wait_dispatch_record_size": 0,
"ready_execute_batch_size": 0
},
"frame": {
"SourceTaskManager.createdSourceSize": 0,
"queue_slot1.batchAccumulate": 0,
"frame.throttle.throttle_memory_remain": "2.14748365E9",
"queue_slot1.batchCount": 3715.0,
"queue_slot1.tps": 0.0
}
}
增量延迟-疑似热点问题
详情请参见 疑似热点问题 的内容。
全量校验
-
请参考全量迁移。
-
通过
task.sourceMasterSection.excludeColumn排除 LOB 类型的大字段和无需校验的字段,具体设置请参见 Full-Verification 组件参数说明。
全量校验数据问题
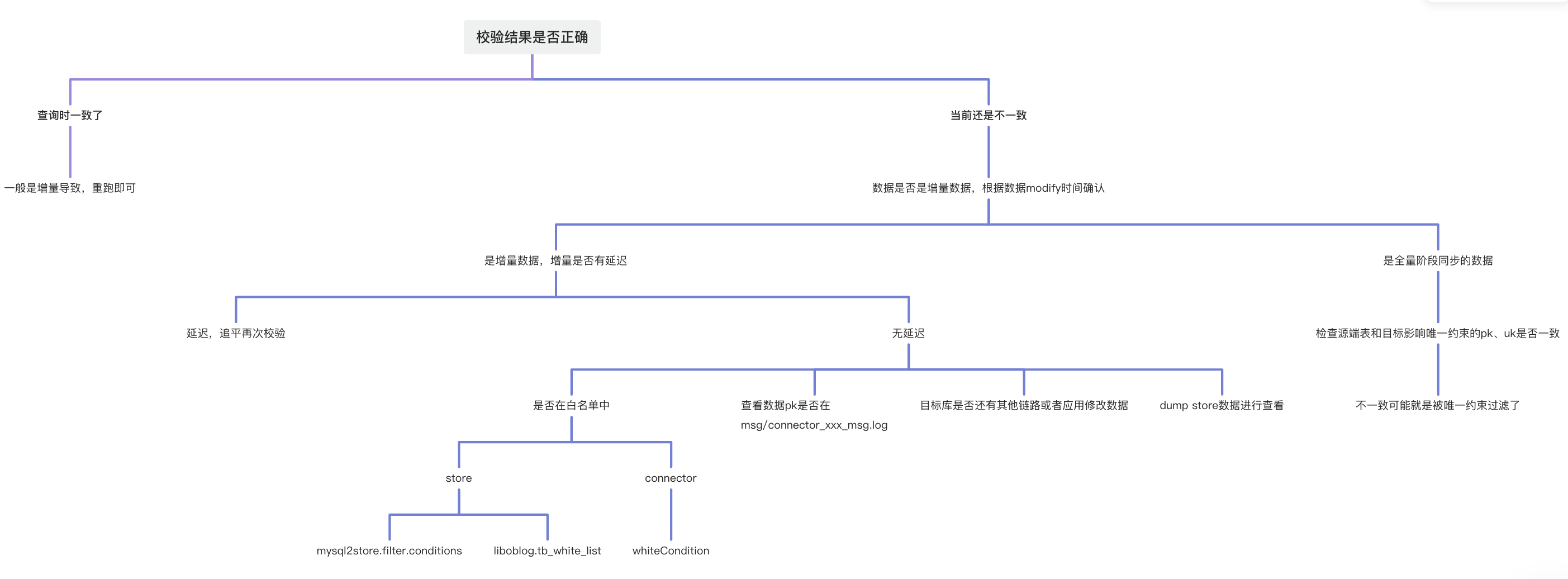
如何从 Store 中 dump 数据
# checkpoint 是 unix 时间戳
# 17006 和 p_47qaxxxu8_source-000-0 看下图
# 可以根据表名、时间和字段内容定位到具体数据
wget 'localhost:17006/p_47qaxxxsu8_source-000-0' --post-data 'filter.conditions=*.*.*&checkpoint=1667996779'
典型使用场景和功能
多表汇聚
源端分库分表迁移到目标端单表或者分区表,示例如下:
-- 源表、主键 ID、UK 字段 uk_id
CREATE TABLE test_01(id bigint not null AUTO_INCREMENT,uk_id bigint not null,...);
CREATE TABLE test_02(id bigint not null AUTO_INCREMENT,uk_id bigint not null,...);
-- 目标表
CREATE TABLE test(id_new bigint not null AUTO_INCREMENT,uk_id bigint not null,...,
PRIMARY KEY (id_new,uk_id),
unique key(uk_id))
PARTITION BY HASH(uk_id)
PARTITIONS 4;
常见问题如下:
-
创建数据迁移任务时,源端分表批量重命名
-
使用 匹配规则 配置
-
使用配置
src_schema.test_*=dst_schema.test
-
-
源端 ID 自增字段,在源端多表中重复,目标表使用新的字段名称作为自增主键
-
源表 ID 字段无需迁移到目标表,目标表中 id_new 字段为新的自增列
-
全量迁移时需要设置参数
sink.ignoreRedunantColumnsReplicate=true,全量迁移时 ID 字段将忽略 -
增量同步时需要设置
sink.ignoreRedunantColumnsReplicate=true,忽略 ID 字段
-
-
目标端为分区表,OceanBase 数据库中 PK 字段必须包含分区字段,如何进行数据校验
-
全量校验设置
task.sourceMasterSection.matchAllColumn=false,源表 ID 字段将不参与校验。此处要求源表具备不允许为 NULL 的 UK,否则无法校验。 -
全量校验设置
inmod模式:filter.verify.inmod.tables=.*;.*;.*,详情请参见 Full-Verification 组件参数说明。
-
OceanBase 无主键迁移-隐藏列
OceanBase 社区版作为源端时,对于无中间件表,OMS 社区版迁移会使用隐藏列作为主键迁移 __pk_increment,结构迁移时在目标表中会多出一列 OMS_PK_INCRMT。
-
如果用户经过正向切换后,OMS_PK_INCRMT 最终会被删除
-
如果用户没有经过正向切换,并且该目标库作为下个任务的源库,此时会存在异常问题,需要您手动删除
OMS_PK_INCRMT才能避免异常。
OceanBase 旁路导入
旁路性能相关的参数,除了常用的并发外,还有一个额外的服务端并发参数可以设置:sink.serverParallel,默认值为 8。该参数会影响 OceanBase 服务端用于旁路任务的工作线程和并发。
反向增量
用户希望有回滚能力或者将原来的库作为备库使用。对于该类需求,建议您在创建数据迁移任务时勾选 反向增量。另外对于 MySQL 数据库作为源端时(例如 MySQL->OceanBase 社区版),请您在 MySQL 数据库中手动创建 OMS 社区版需要使用的事务库 omstxndb。如果不创建该事务库,会出现异常提示 omstxndb 库不存在。
容灾双活
用户应用在需要双写或者灰度切换的情况下,可以使用 OMS 社区版的容灾双活功能。目前支持 MySQL->OceanBase 社区版、OceanBase 社区版-> OceanBase 社区版的双活,OMS 社区版会自动设置防循环复制参数。请注意双活场景下,所有表必须都要有 PK 或者 UK。
-
有两个库 A、B
-
应用按照一定规则将数据分别写入 A、B 库
非双写:应用写入 A 的数据,不会再写入 B,同样应用写入 B 的数据,不会再写入 A。
-
A、B 需要保留应用所有数据
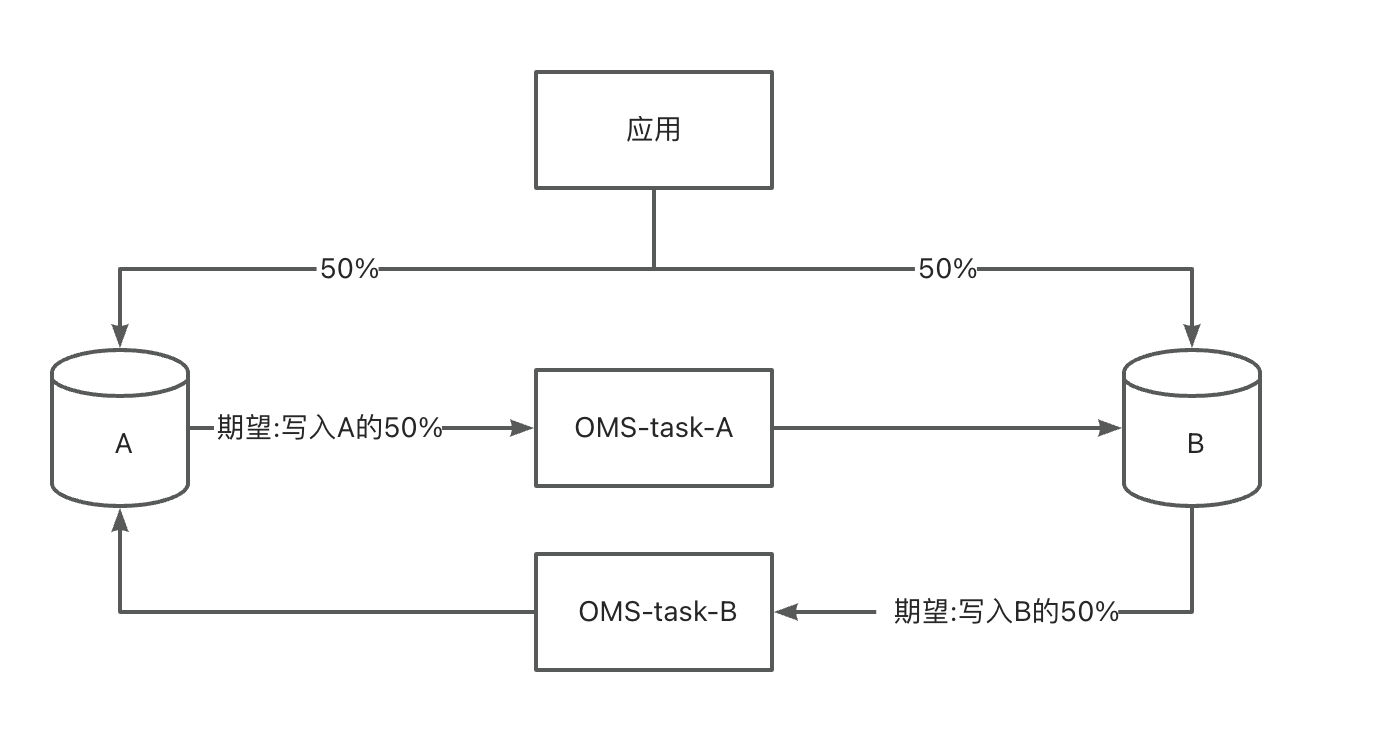
全量校验
全量校验有两种模式:
-
默认模式:源端和目标端都使用分片范围查询
-
inmod 模式:源端使用分片范围查询,目标端使用源端查询出来数据中的 PK/UK 再去目标端查询目标数据,配置项
filter.verify.inmod.tables示例如下:
-
配置当前任务的所有表均使用 inmode 校验:
filter.verify.inmod.tables=.*;.*;.* -
配置 D1 库下的 T1 表使用 inmode 校验:
filter.verify.inmod.tables=D1;T1;.* -
配置 D1 库下的 T1 和 T2 表使用 inmode 校验:
filter.verify.inmod.tables=D1;T1;.*|D1;T2;.* -
配置 D1 库下的 T1、T2 表和 D2 库下的 T3、T4 表使用 inmode 校验:
filter.verify.inmod.tables=D1;T1;.*|D1;T2;.*|D2;T3;.*|D2;T4;.*
-
OMS 社区版使用到的系统视图-创建任务时选表、视图
MySQL
系统表列表
| 表/视图 | 描述 |
|---|---|
| information_schema.SCHEMATA | Schema 信息 |
| information_schema.tables | 表信息 |
| information_schema.columns | 字段信息 |
| information_schema.STATISTICS | 索引信息 |
查询 SQL
SET TIME_ZONE='%s';
SET sql_mode='';
SET names 'utf8mb4';
SET foreign_key_checks = off;
SELECT version();
SELECT 1;
-- 查询所有 Schema
SELECT CATALOG_NAME, SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME, SQL_PATH
FROM `information_schema`.`SCHEMATA`
-- 查询所有表
SELECT NULL,TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS, TABLE_COLLATION, ENGINE
FROM information_schema.tables WHERE TABLE_TYPE='BASE TABLE' AND TABLE_SCHEMA NOT IN('mysql','information_schema','performance_schema')
-- 查询表的数据库引擎信息
SELECT `ENGINE` FROM `information_schema`.`tables` WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
-- 查询表的字符集
SELECT TABLE_COLLATION FROM information_schema.tables WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
-- 查询字段信息
SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
FROM information_schema.columns WHERE table_schema=? AND table_name=? ORDER BY ORDINAL_POSITION ASC
-- 查询所有视图
SELECT TABLE_NAME, TABLE_SCHEMA, VIEW_DEFINITION FROM information_schema.views
WHERE TABLE_SCHEMA IN ('xx');
-- 存在记录 5.7 之后的
-- 只查询正常列,不含生成列
SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
FROM information_schema.columns WHERE table_schema=? AND table_name=? AND (GENERATION_EXPRESSION='' or GENERATION_EXPRESSION is null) ORDER BY ORDINAL_POSITION ASC
-- 索引
SELECT INDEX_NAME,NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,SUB_PART FROM information_schema.STATISTICS WHERE table_schema=? AND table_name=?
AND concat(index_schema,'.',index_name) NOT IN (
SELECT concat(index_schema,'.',index_name) FROM information_schema.STATISTICS
WHERE table_schema=? AND table_name=? AND upper(nullable)='YES')
ORDER BY INDEX_NAME ASC, SEQ_IN_INDEX ASC
-- 查询分区
SELECT TABLE_SCHEMA, TABLE_NAME,PARTITION_NAME,SUBPARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS
-- 查看约束情况
SELECT REFERENCED_TABLE_SCHEMA, REFERENCED_TABLE_NAME, TABLE_SCHEMA, TABLE_NAME, CONSTRAINT_NAME,REFERENCED_COLUMN_NAME, COLUMN_NAME FROM information_schema.KEY_COLUMN_USAGE
OceanBase 数据库 MySQL 租户
系统表列表
| 表/试图 | 描述 |
|---|---|
| information_schema.SCHEMATA | Schema 信息 |
| information_schema.tables | 表信息 |
| information_schema.columns | 字段信息 |
| information_schema.STATISTICS | 索引信息 |
| information_schema.PARTITIONS | 分区信息 |
| oceanbase.gv$memstore | 内存使用信息 |
| oceanbase.gv$sysstat | CPU 使用信息 |
| oceanbase.gv$table | tableid |
| oceanbase.__tenant_virtual_table_index | 索引 |
| 以下是宏块切片需要使用到的系统表 | |
| oceanbase.__all_tenant | 租户信息 |
| oceanbase.__all_database | 20200 之前版本,数据库信息 |
| oceanbase.__all_table | 20200 之前版本,表信息 |
| oceanbase.__all_part | 20200 之前版本,分区信息 |
| oceanbase.__all_meta_table | 20200 之前版本,表的元数据信息 |
| oceanbase.__all_virtual_database | 20200 之后版本,数据库信息 |
| oceanbase.__all_virtual_table | 20200 之后版本,表信息 |
| oceanbase.__all_virtual_proxy_partition | 20200 之后版本,分区信息 |
| oceanbase.__all_meta_table | 20200 之后版本,表的元数据信息 |
| oceanbase.__all_virtual_partition_item | 二级分区信息 |
| oceanbase.__all_virtual_partition_sstable_macro_info | 宏块信息表 |
说明
宏块信息需要使用系统租户查询
查询SQL
-- 查询所有 Schema
SELECT CATALOG_NAME, SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME, SQL_PATH
FROM `information_schema`.`SCHEMATA`
-- 查询所有表
SELECT NULL,TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS, TABLE_COLLATION, ENGINE
FROM information_schema.tables WHERE TABLE_TYPE='BASE TABLE' AND TABLE_SCHEMA NOT IN('mysql','information_schema','performance_schema')
-- 查询表的数据库引擎信息
SELECT `ENGINE` FROM `information_schema`.`tables` WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
-- 表的字符集
SELECT TABLE_COLLATION FROM information_schema.tables WHERE TABLE_SCHEMA = '%s' AND TABLE_NAME = '%s'
-- 字段信息
SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
FROM information_schema.columns WHERE table_schema=? AND table_name=? ORDER BY ORDINAL_POSITION ASC
-- 存在记录 5.7 之后的
-- 只查询正常列,不含生成列
SELECT `COLUMN_NAME` ,upper(`COLUMN_TYPE`) ,`CHARACTER_MAXIMUM_LENGTH` ,`NUMERIC_PRECISION`,`NUMERIC_SCALE`
FROM information_schema.columns WHERE table_schema=? AND table_name=? AND (GENERATION_EXPRESSION='' or GENERATION_EXPRESSION is null) ORDER BY ORDINAL_POSITION ASC
-- 索引
SELECT INDEX_NAME,NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,SUB_PART FROM information_schema.STATISTICS WHERE table_schema=? AND table_name=?
AND concat(index_schema,'.',index_name) NOT IN (
SELECT concat(index_schema,'.',index_name) FROM information_schema.STATISTICS
WHERE table_schema=? AND table_name=? AND upper(nullable)='YES')
ORDER BY INDEX_NAME ASC, SEQ_IN_INDEX ASC
-- 查询分区信息
SELECT PARTITION_NAME,SUBPARTITION_NAME FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA='{}' AND TABLE_NAME='{}'
-- 分区字段表达式
SELECT DISTINCT PARTITION_EXPRESSION,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=? AND TABLE_NAME=?
-- 以下 SQL 通过宏块信息切片 __all_virtual_partition_sstable_macro_info 相关的
-- 查询租户信息
SELECT tenant_id FROM oceanbase.__all_tenant WHERE tenant_name = '%s'
-- 查询表的索引
SELECT key_name, NON_UNIQUE,SEQ_IN_INDEX,COLUMN_NAME,`null` nullable FROM oceanbase.__tenant_virtual_table_index WHERE table_id = ?
-- 获取表id
-- 20200 之前版本
SELECT %s b.table_id FROM oceanbase.__all_database a, oceanbase.__all_table b WHERE a.database_id = b.database_id AND a.tenant_id = %d AND a.database_name = '%s' AND b.table_name = '%s'
-- 20200 之后版本
SELECT %s b.table_id FROM oceanbase.__all_virtual_database a, oceanbase.__all_virtual_table b WHERE a.database_id = b.database_id AND a.tenant_id = %d AND a.database_name = '%s' AND b.table_name = '%s'
-- 获取分区信息
-- 20200 之前版本
SELECT %s part_id,part_name FROM oceanbase.__all_part WHERE table_id = %d AND part_name IS NOT NULL AND part_name<>''
-- 20200 之后版本
SELECT %s part_id,part_name FROM oceanbase.__all_virtual_proxy_partition WHERE table_id = %d AND part_name IS NOT NULL AND part_name<>''
-- 获取子分区信息
SELECT %s partition_id,case when subpart_name is null then concat(part_name,'sp',subpart_id) ELSE subpart_name END subpart_name FROM oceanbase.__all_virtual_partition_item WHERE table_id = %d AND partition_level>1
-- 查询 tableid
SELECT table_id FROM oceanbase.gv$table WHERE database_name=? AND table_name=?
-- 宏块信息查询,store_type=1正常的信息,store_type=4表示转储
-- 20200 之前版本
SELECT %s partition_id OMS_PARTITION_ID,data_seq OMS_DATA_SEQ,macro_range OMS_MACRO_RANGE,row_count OMS_ROW_COUNT FROM oceanbase.__all_virtual_partition_sstable_macro_info
WHERE tenant_id=%d AND table_id = %d AND store_type=1 AND macro_range NOT LIKE '%%]always true' AND macro_range<>'(MIN ; MAX]' AND macro_range LIKE '%%]'
AND (svr_ip,svr_port,partition_id) IN (SELECT svr_ip, svr_port,partition_id FROM oceanbase.__all_meta_table
WHERE tenant_id=%d AND table_id = %d AND ROLE = 1)
ORDER BY partition_id,data_seq
-- 20200 之后版本
SELECT %s partition_id OMS_PARTITION_ID,data_seq OMS_DATA_SEQ,macro_range OMS_MACRO_RANGE,row_count OMS_ROW_COUNT FROM oceanbase.__all_virtual_partition_sstable_macro_info
WHERE tenant_id=%d AND table_id = %d AND store_type=1 AND macro_range NOT LIKE '%%]always true' AND macro_range<>'(MIN ; MAX]' AND macro_range LIKE '%%]'
AND (svr_ip,svr_port,partition_id) IN (SELECT svr_ip, svr_port,partition_id FROM oceanbase.__all_virtual_meta_table
WHERE tenant_id=%d AND table_id = %d AND ROLE = 1)
ORDER BY partition_id,data_seq
-- 内存防爆
SELECT /*+query_timeout(5000000)*/ total, freeze_trigger,mem_limit FROM oceanbase.gv$memstore
-- CPU 防爆
SELECT min(100-round(cpu_usage.value * 100 / cpu_limit.value)) cpu_free_percent
FROM oceanbase.gv$sysstat cpu_usage, oceanbase.gv$sysstat cpu_limit
WHERE cpu_usage.name = 'cpu usage' AND cpu_limit.name = 'max cpus'
AND cpu_usage.svr_ip = cpu_limit.svr_ip
其他
热更 OceanBase 增量 CDC 库
OceanBase 数据库的不同版本可能需要对应的 CDC 库才能拉取到增量日志数据,OMS 社区版的 Store 组件通过加载 CDC 动态库的方式来拉取 OceanBase 数据库的增量数据。
下表为 OMS 社区版 Store 组件和 OceanBase CDC 库相关的目录 /home/ds/lib64/reader。
| OMS 社区版 Store 组件 | OceanBase CDC 库 |
|---|---|
| ob-ce-reader | 不可热更 |
| ob-ce-4.x-reader | OceanBase 数据库 V4.0.0 及之后,V4.2.1 及之前版本 |
| ob-ce-4.2.2-reader | OceanBase 数据库 V4.2.2 及之后,V4.3.0 及之前版本 |
| ob-ce-4.3-reader | OceanBase 数据库 V4.3.0 及之后版本 |
热更步骤如下:
-
下载 CDC rpm 包:增量数据获取工具(OB CDC)。
-
解压 rpm 包:
rpm2cpio oceanbase-ce-cdc-x.x.x.x-xxxx.el7.x86_64.rpm|cpio -idmu --quiet。 -
解压后,当前目录
./home/admin/oceanbase/lib64会出现下述文件。libobcdc.so.x.x.x.x
libobcdc.so.x -> libobcdc.so.x.x.x.x
libobcdc.so -> libobcdc.so.x -
进入 OMS 社区版容器,并通过
cd命令进入目录/home/ds/lib64/reader,根据 OceanBase 数据库的版本号进入上述表格中的ob-ce-xxx-reader目录。 -
备份
ob-ce-xxx-reader目录中的原文件。 -
将 rpm 包解压的
./home/admin/oceanbase/lib64下面的文件复制到ob-ce-xxx-reader目录中。
上述步骤完成后,新建的 Store 组件均会使用热更后的 CDC 库。如果已经存在的 Store 组件需要热更,请执行下述操作。
-
进入 Store 组件的运行目录
/home/ds/store/store{port}/lib64/reader,��下面的目录结构和/home/ds/lib64/reader下的目录一致。 -
将 rpm 解压的
./home/admin/oceanbase/lib64下面的文件复制到/home/ds/store/store{port}/lib64/reader/ob-ce-xxx-reader。 -
在 OMS 社区版控制台,暂停 Store 组件。详情请参见 暂停 Store 组件。
-
执行下述命令,确认 Store 进程已经停止。如果 Store 进程未停止,则可以执行
kill -9。ps -ef | grep store{port} -
在 OMS 社区版控制台,启动 Store 组件。