OBServer 故障应急手册概述
咱们《OceanBase DBA 进阶教程》的内容已经持续更新了一段时间,终于来到了 “问题排查” 阶段。
前一段儿时间看到了 OceanBase 内部同学整理的一篇社区博客《OceanBase 应急三板斧》,以及文档团队的小伙伴们在官方文档中为大家提供的一些和应急处理相关的内容,内容都非常不错。
不过对于 OceanBase 社区版的用户来说,这些应急场景和应对手段,可能还不是十分完善,同时也不够体系化和图谱化。
同时考虑到用户意见收集中的 @oceanvoice 、@张雨齐 等老师的建议,准备《进阶教程》的这个章节中,为大家提供一份儿相对比较成体系,也更加全面的《故障应急手册》。
在《故障应急手册》中,会把用户在使用 OceanBase 的过程中可能遇到的问题,以及对应的解决方案进行汇总。问题肯定并不常见,但会是相对严重,且需要 DBA 同学进行初步分析和止血操作的。 目录大致会是:
-
故障应急手册概述
-
系统响应时间不符合预期
-
CPU 负载异常
-
节点宕机
-
硬件 & 基础环境故障应急处理
-
网络抖动
-
磁盘故障
-
-
负载变化导致的问题
- 日志盘 / 数据盘写满
-
……
OBServer 的故障排查脑图详见:
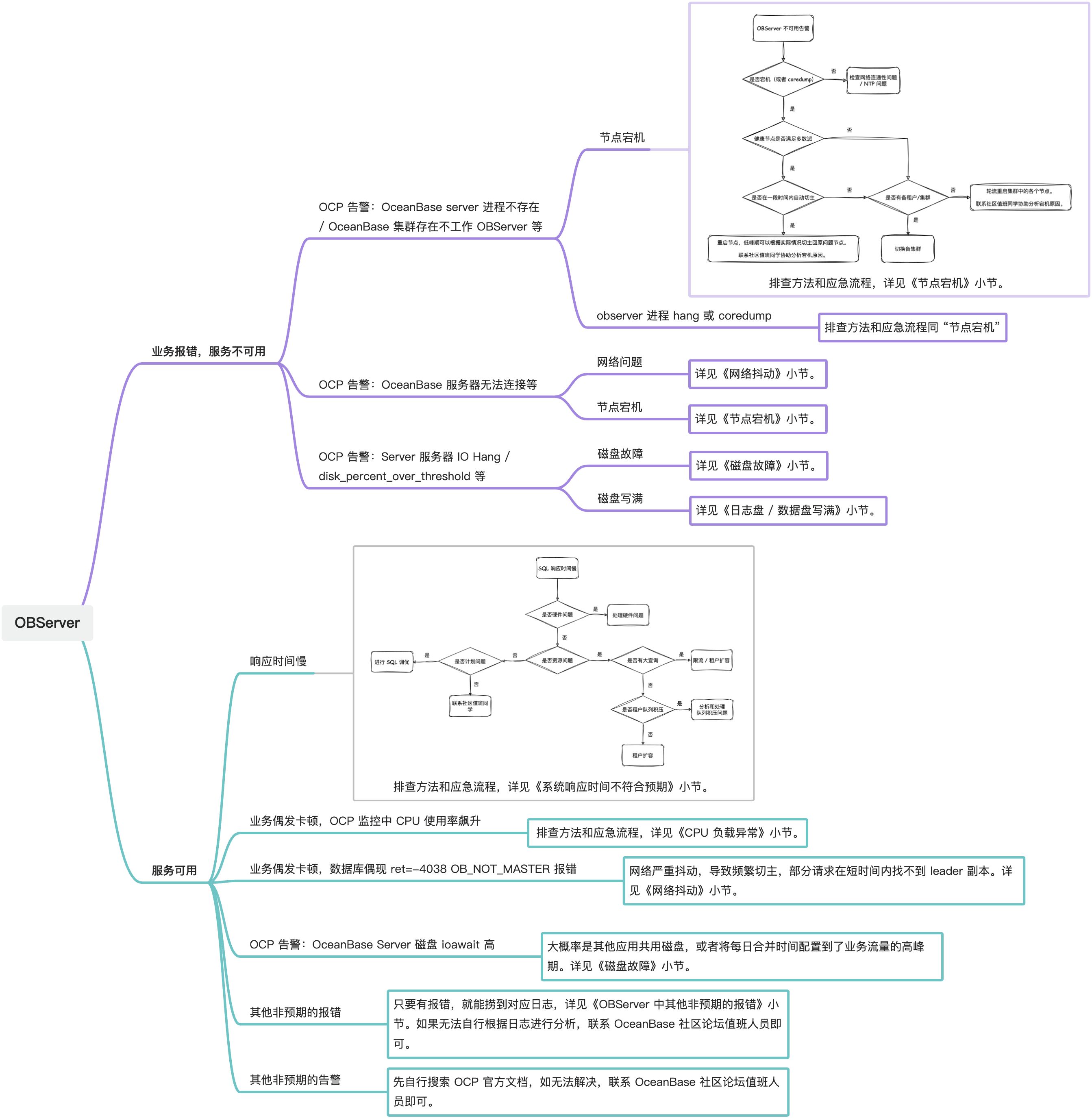
What's more ?
这一小节只有手册的内容介绍,没啥干货,有点儿过意不去。那就在最后附送一个 针对 OceanBase 严重故障(尤其是业务停服场景),进行快速止血恢复的通用方法 ,简单来说就是:切主 -> 隔离 -> 重启 -> 切备集群。
-
如果集群中只有一个租户有问题,那就切这个租户的主(通过 set tenant primary_zone 修改租户的 primary_zone)。
-
如果集群中只有一个节点有问题,那就 stop or isolate 这个节点。
-
如果整个集群都有问题,那就轮流重启集群中的各个节点。
-
如果轮流重启之后还有问题,那就进行 failover 操作,切换备集群。
-
分析问题永远放在止血和恢复之后。
未完待续
集群内部其他问题,一般都需要联系社区论坛的值班人员进行协助,可能并不需要运维同学深入了解。所以优先级放的低些,预计会在进阶教程完结之后,继续在 OceanBase 的社区论坛中的 “官方精选” 板块内进行更新。
-
SYS 租户/ RS 服务问题
-
内存泄漏
-
磁盘泄漏
-
长事务
-
悬挂事务
-
coredump
-
……
参考资料
-
官网文档中的应急处理相关内容