CPU 负载异常
业�务及数据库表现
业务表现:业务出现偶发卡顿,接口调用失败率上升。
数据库表现:收到 CPU 使用率高的告警,SQL 响应延迟突然变高,监控中 CPU 使用率飙升.
排查方向和流程
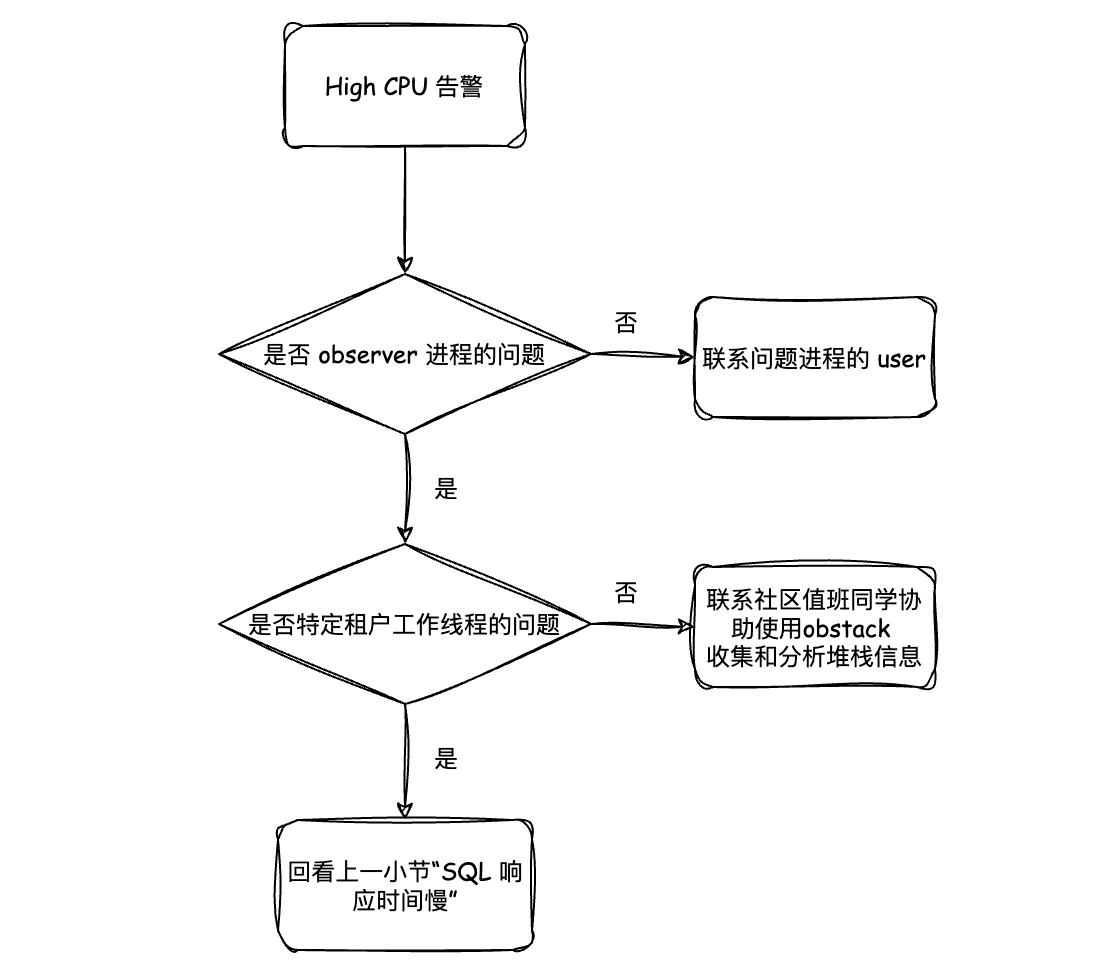
排查节点上是否有 CPU 使用率高的进程
通过 ps 或者 top 命令,确认节点上 CPU 使用率高的进程是否是 observer 进程。
ps -eo pid,user,%cpu,cmd --sort=-%cpu
PID USER %CPU CMD
124648 user_a 99.9 other_process
1332 user_b 50.5 observer
如果是其他 user 在节点上开了其他 CPU 占用较高的进程,需要联系相关 user 进行调整。
排查 OBServer 中的可疑线程
如果 CPU 占用高的进程只有 observer,先通过 top -H 看下是否是租户工作线程占用的
top -p `pidof observer` -H
如果是工作线程的 CPU 占用大
对于 99% 的场景,我们只需要关心普通线程(即租户工作线程,而非后台线程),即 TNT_L0_G0_1001(3.1 版本) 或 T1001_L0_G0(4.x 版本)。
By the way:这里多解释一句,4.x 给工作线程改名,是因为 3.1 版本太容易 grep 错。比如想 grep TNT_L0_G0_1 的时候,很容易 grep 出一大堆 TNT_L0_G0_1001 之类的线程。
例如有某个租户执行的 SQL 占用了超多 CPU,导致其他租户受影响了,可以直接通过 top -H 结果中的 T1002_L0_G100 看出具体是哪个租户在整幺蛾子。
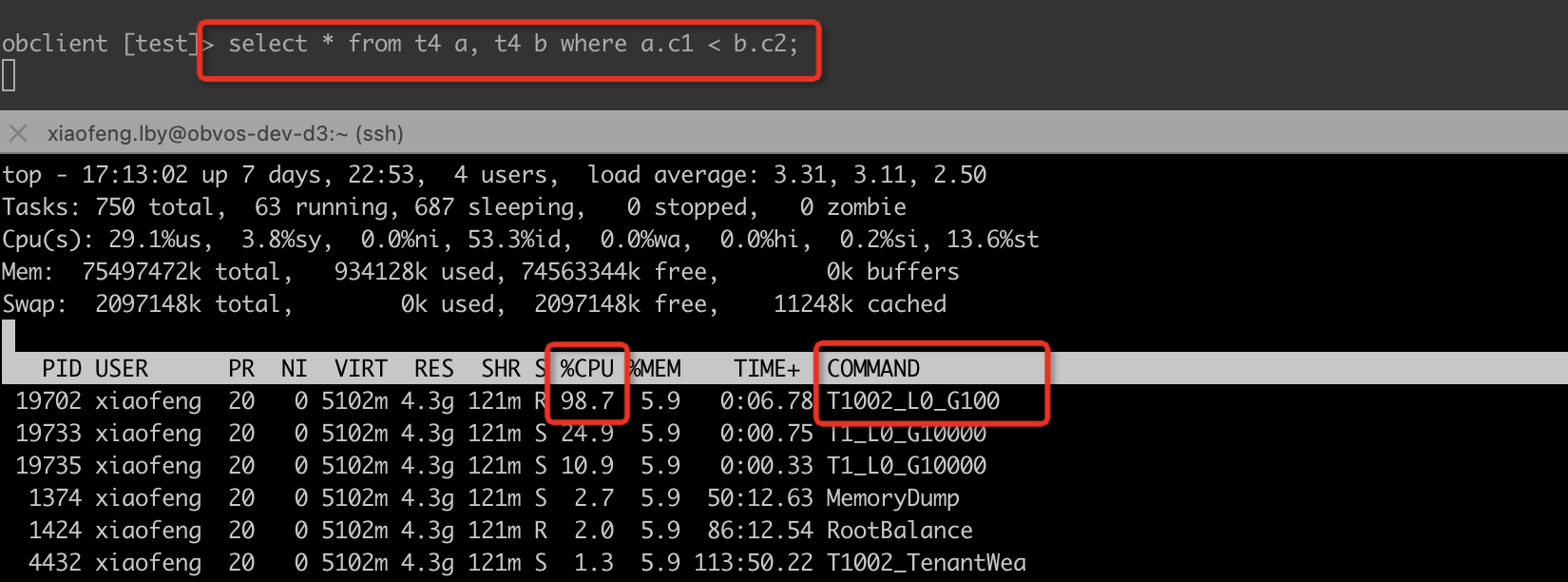
上面的示例就可以通过 T1002_L0_xxxx 看出来是 1002 号租户在犯坏。
然后就可以去 OCP 上去看看这个 1002 号租户在执行什么把 CPU 吃完的 SQL 了。
这里就又回到了上一小节的内容,需要分析下为啥这条 SQL 这么特殊了。
如果是后台线程的 CPU 占用大
如果 top -H 看到占用 CPU 的是 T1_HBService、RootBalance、IO_GETEVENT0 这类看不懂的线程 CPU 占用高,建议去社区论坛发帖,联系在论坛中值班的技术支持同学,让他们协助你留下 obstack 或者 pstack 的堆栈信息,进一步分析原因。
What' more ?
这一小节的第一版,其实到这里就结束了。后面都是再版时补充的内容。
写完之后,突然想起我老大在一段时间之前好像跟我简单提过一句,说有机会的话,希望能够向用户介绍如何充分利用 OCP 的白屏监控。
一直没写 OCP 监控的内容,原(jiè)因(kó)是,白屏操作太易用了,自己随意拿鼠标点一点,大概率也就玩儿明白了。大多数情况下,连官网文档都不需要。
这里测试一下不看官方文档,直接通过 OCP 来分析 CPU 负载异常吧,顺便做个记录,正好向大家证明 OCP 白屏监控的易用性。
-
首先在 2024/11/21 20:37 左右,给数据库加一点儿压力。
-
然后在 OCP 首页的 “性能监控” 中的 “OBServer 性能” 里,就能看到对应集群 CPU 使用率一下子就快跑满了(“性能监控” 四个字就在首页,不需要到处找)。
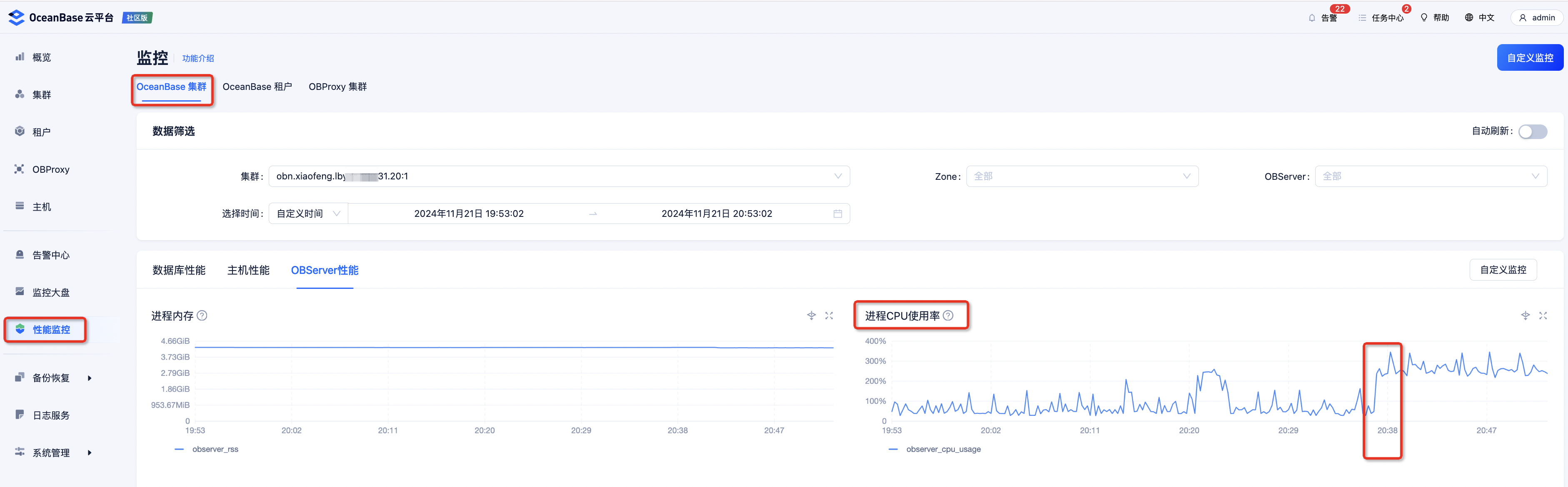
-
再然后,在 “数据库性能” 里,可以看到这个集群的 SQL 响应时间也大幅上升。
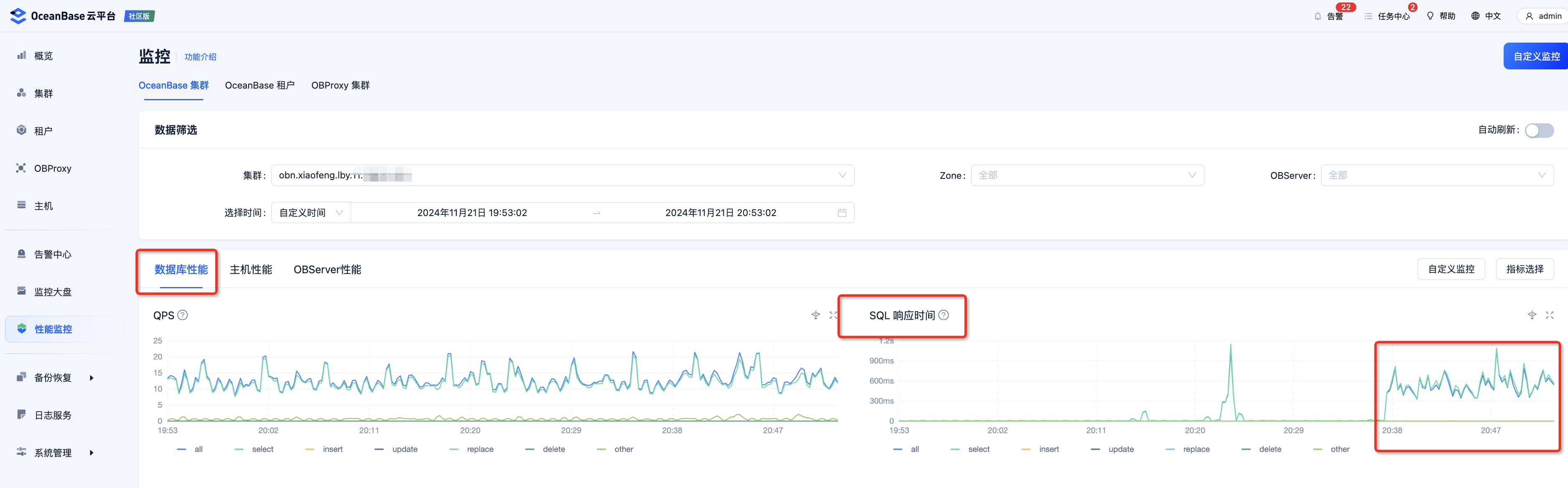
-
再再然后,就可以去看下这个集群里各个租户的情况,发现一个叫做 mysql 的用户租户,情况比较特殊,CPU 使用率很高。
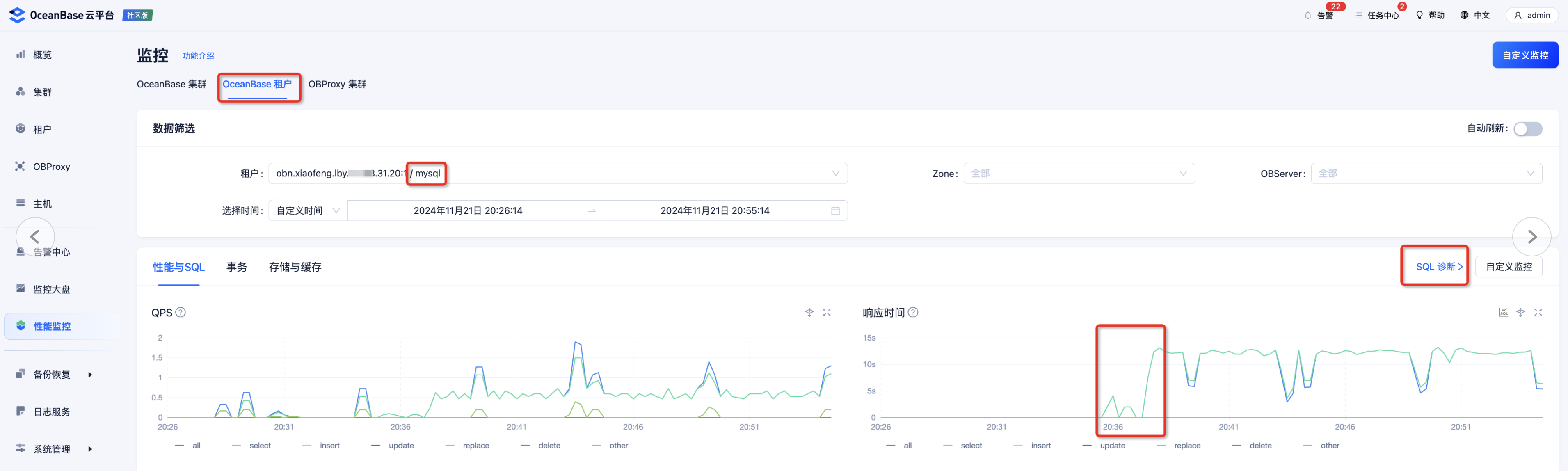
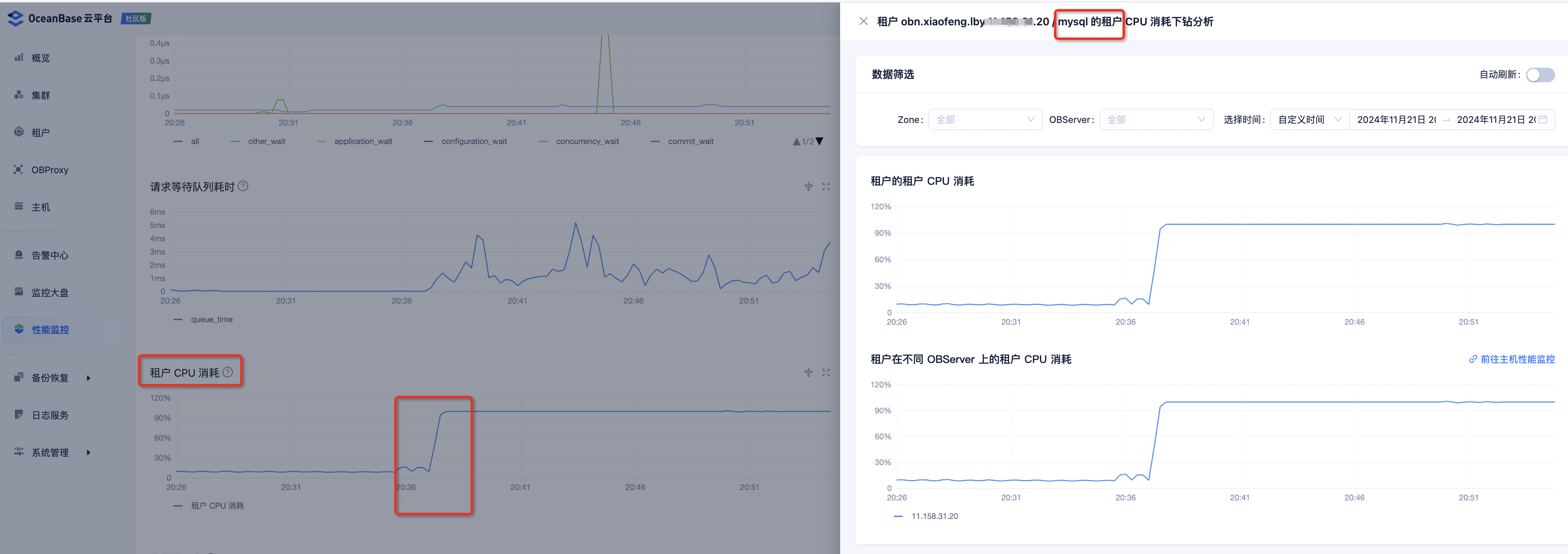
-
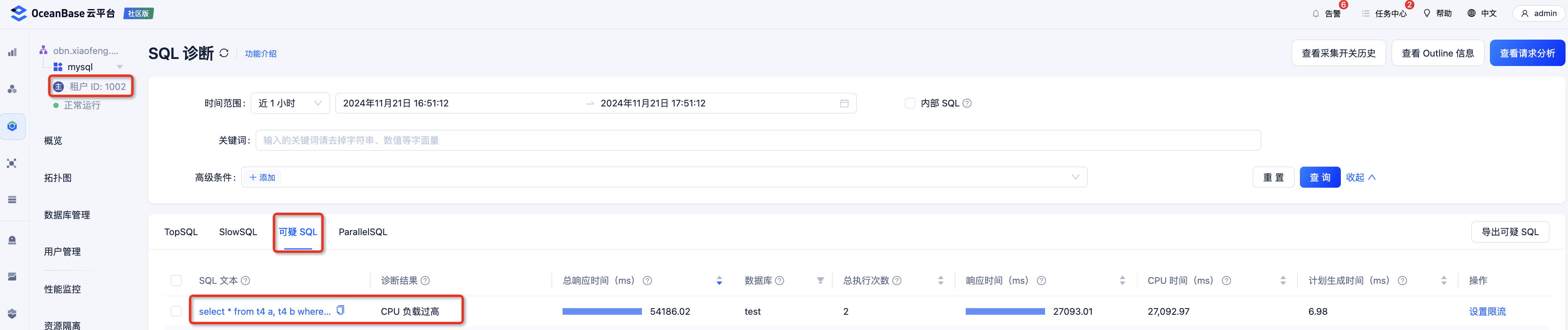
点一下 “SQL 诊断”,就可以看到是这个集群里,一个叫 mysql 的租户,正在疯狂重复执行一条计算逻辑超级复杂的 SQL。
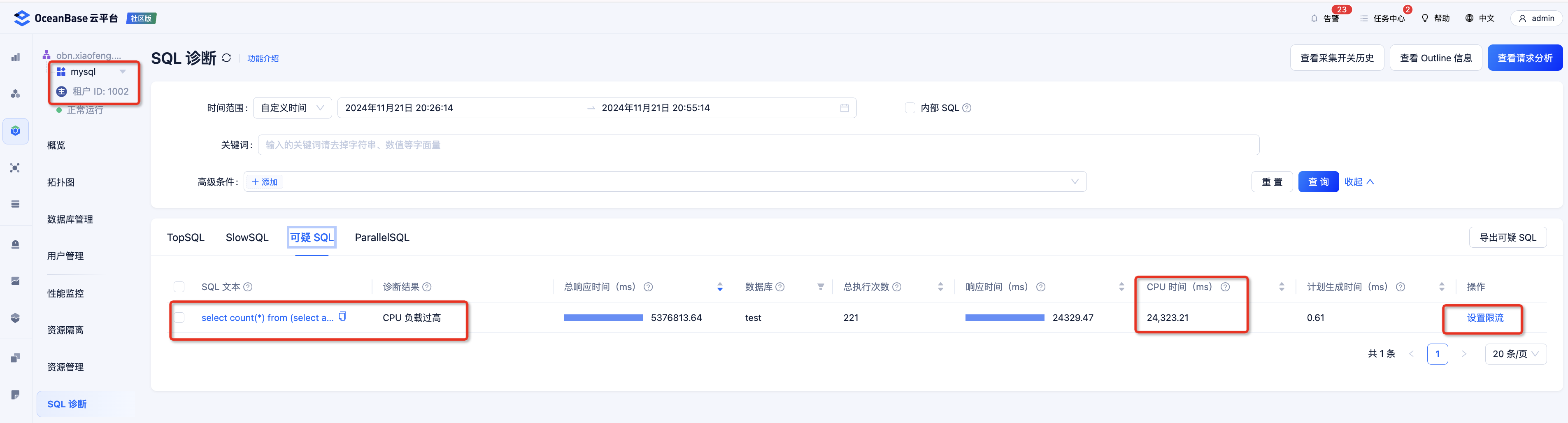
-
到此为止,问题定位。
虽然我这个是先知道答案,再展示解题过程。不过,这里想证明的其实是,不看官网的 OCP 文档,大家也能轻松利用 OCP 的白屏监控来分析 CPU 使用率异常的问题,只要自信地去用就好了(希望别被我老大看到)~