节点宕机
业务及数据库表现
业务表现:业务失败。
数据库表现:数据库服务器节点异常,出现节点宕机,OceanBase 数据库对应节点服务不可用。
排查方向和流程
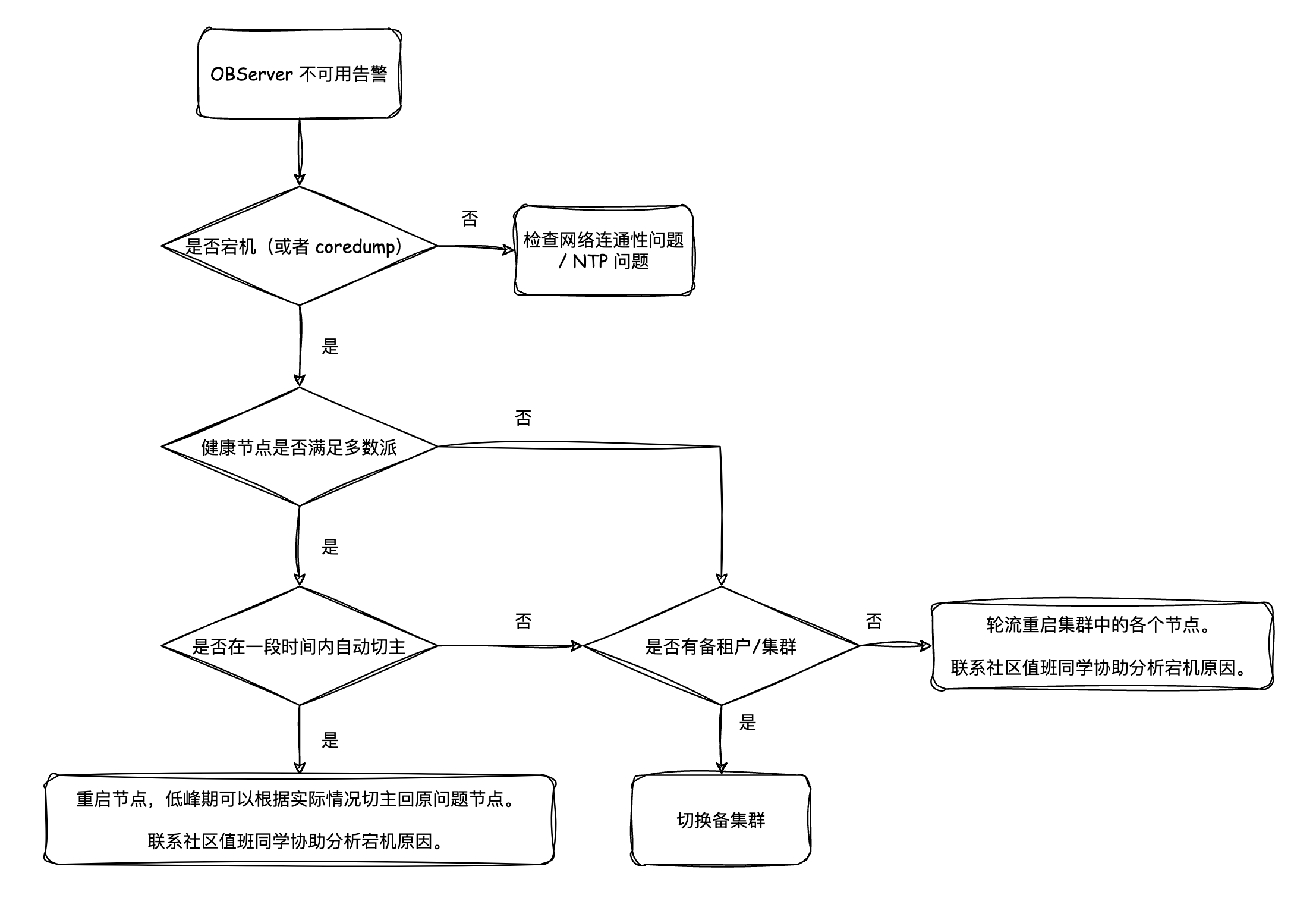
排查是否宕机
检查主机可用性,如果可以登录对应节点,执行 ps 命令看下 observer 进程是否存在。
$ps -ef | grep observer
03:55:52 /home/xiaofeng.lby/obn.obs0/bin/observer
00:00:00 grep --color=auto observer
如果进程依然存在,可以进一步检查节点所在主机的网络连通性,排除因为节点间网络隔离或者网络抖动等原因导致的误报。
如果健康节点已经不满足多数派
如果评估主机或网络问题无法及时恢复:
-
优先考虑使用 OCP 通过 物理备租户(集群) Failover 的方式来进行恢复。
-
其次考虑使用 OCP 通过物理备份恢复的方式来进行恢复。
-
如果没有物理备库及数据备份,尝试轮流重启集群各个节点的 observer 进程。
-
如果轮流重启之后依然无法恢复,联系社区论坛值班同学进行排查。
-
联系社区论坛值班同学分析故障根因。
生产环境中的重要数据和关键租户,建议大家启用备份,以防各种不可预期的故障! 推荐大家在生产环境中使用 OCP 进行白屏化的物理备份恢复��,以及搭建物理备租户/集群。
如果健康节点能构成多数派
-
如果健康节点可以构成多数派,依靠 OceanBase 集群自身的高可用能力(8 秒内选出新的主副本),就能够继续对外提供服务。重启或替换出问题的节点即可。绝大对数情况到这里就结束了。大家可以收藏一下下面这个命令。
-- 故障开始前
SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
FROM oceanbase.GV$OB_LOG_STAT
WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+---------------+----------+----------------------------+
| SVR_IP | ROLE | SCN_TO_TIMESTAMP(END_SCN) |
+---------------+----------+----------------------------+
| xx.xxx.xxx.1 | FOLLOWER | 2024-11-27 19:44:27.881516 |
| xx.xxx.xxx.2 | FOLLOWER | 2024-11-27 19:44:27.881516 |
| xx.xxx.xxx.3 | LEADER | 2024-11-27 19:44:27.881516 |
+---------------+----------+----------------------------+
-- 系统自动选主后
SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
FROM oceanbase.GV$OB_LOG_STAT
WHERE TENANT_ID = 1 order by LS_ID, ROLE;
+---------------+----------+----------------------------+
| SVR_IP | ROLE | SCN_TO_TIMESTAMP(END_SCN) |
+---------------+----------+----------------------------+
| xx.xxx.xxx.1 | FOLLOWER | 2024-11-27 19:44:38.737837 |
| xx.xxx.xxx.2 | LEADER | 2024-11-27 19:44:38.737837 |
+---------------+----------+----------------------------+
SCN_TO_TIMESTAMP(END_SCN) 会获取指定日志流副本的最新日志位点信息,并转换成时间戳形式。日志流的 Follower 副本和 Leader 副本的最新日志位点差距在 5 秒以内,即可以认为日志是同步的。
- 如果无法对外提供服务,先隔离有问题的节点。并考虑是否需要调大永久下线参数 server_permanent_offline_time 的值(默认一小时)。
-- 确认集群各节点状态
select SVR_IP, SVR_PORT, ZONE, WITH_ROOTSERVER, STATUS from oceanbase.DBA_OB_SERVERS;
+---------------+----------+-------+-----------------+----------+
| SVR_IP | SVR_PORT | ZONE | WITH_ROOTSERVER | STATUS |
+---------------+----------+-------+-----------------+----------+
| xx.xxx.xxx.3 | 2882 | zone3 | NO | INACTIVE |
| xx.xxx.xxx.2 | 2882 | zone2 | YES | ACTIVE |
| xx.xxx.xxx.1 | 2882 | zone1 | NO | ACTIVE |
+---------------+----------+-------+-----------------+----------+
-- 检查永久下线参数值
show parameters like "%server_permanent_offline_time%";
-- 停止节点,隔离故障节点
alter system stop server 'xx.xxx.xxx.3:2882';
STOP SERVER 是最安全的隔离命令。STOP SERVER 不但可以将业务流量从该节点上切走,实现该节点与业务流量隔离的效果,还能保证除被隔离节点以外的其他节点依然能够构成 Paxos 多数派,从而可以安全的对被隔离节点执行任何动作,例如 pstack / obstack、调整日志级别等,甚至停止进程。STOP SERVER 适用于需要故障隔离和停机运维的场景,是故障隔离和运维变更首选的隔离命令。
-
如果执行完上一步操作,两分钟之后依然无法恢复。手动选择一个不包含问题节点的 zone 进行切主。
ALTER TENANT tenant_name primary_zone='zone1';
-- 通过查询 GV$OB_LOG_STAT 中的 ROLE 字段判断切主是否成功。
SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
FROM oceanbase.GV$OB_LOG_STAT
WHERE TENANT_ID = 1 order by LS_ID, ROLE; -
如果切主三分钟之后,依然无法恢复服务,参考 “如果健康节点已经不满足多数派” 部分的内容进行恢复。
-
联系社区论坛值班同学分析故障根因。
参考资料
- 洪波大佬的社区博客:《OceanBase 应急三板斧》
- 官网文档:《集群常见故障处理》
- 官网文档:《隔离节点》
2024.12.04 补充内容
这里最后多补充一句,就是:
- �如果机器可以恢复,首先可以尝试在 OCP 中重启。
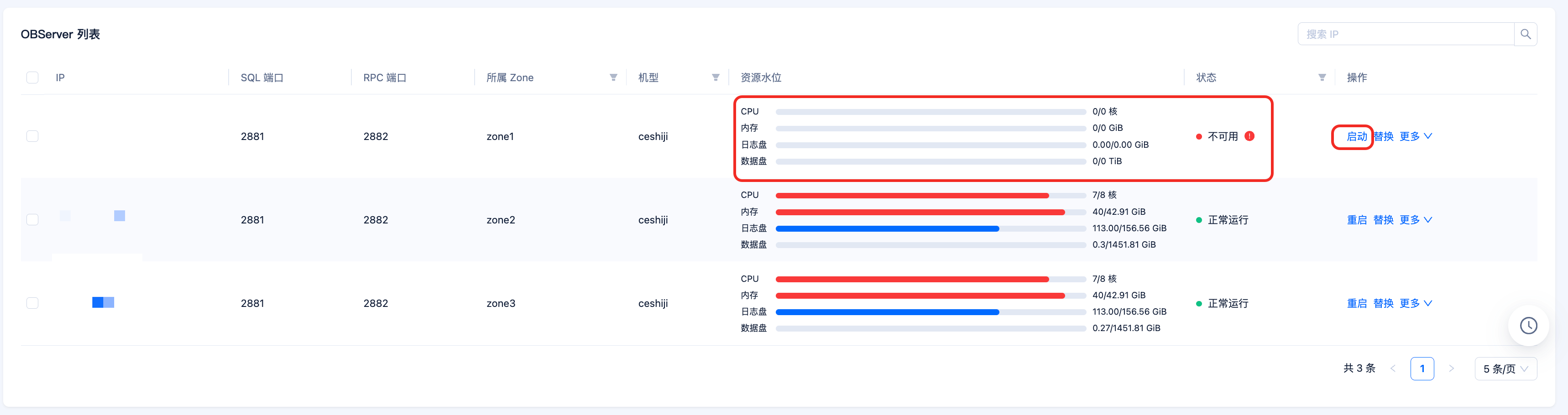
如果在 OCP 中无法立刻重启,可以手动进入安装目录去启动 observer 进程:
[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
$sudo su admin
[admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
$export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/xiaofeng.lby/oceanbase/lib
[admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
$./bin/observer
./bin/observer
注意这里需要在 /oceanbase/bin 的上级目录 /oceanbase 去执行 ./bin/observer 这个命令,估计是需要依赖 etc 目录里的一些配置文件。
[admin@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase]
$find . -name observer.config.bin
./etc/observer.config.bin
- 重启之后,在业务低峰期,可以再切回原来的主。防止 session 长期跨机房访问主副本。
ALTER TENANT tenant_name primary_zone='zone1';
-- 通过查询 GV$OB_LOG_STAT 中的 ROLE 字段判断切主是否成功。
SELECT SVR_IP, ROLE, SCN_TO_TIMESTAMP(END_SCN)
FROM oceanbase.GV$OB_LOG_STAT
WHERE TENANT_ID = 1 order by LS_ID, ROLE;
-
如果机器无法恢复,直接在 OCP 里添加新节点,并替换发生硬件故障的节点。添加节点后会自动完成补副本的动作。
-
如果没有新机器资源,在机器维修结束之前,也能够以两副本对外提供服务(但是这种方式对��高可用的保障较低,存在风险,需要尽快上线新的机器资源)。