7.2 Principles of ODP SQL routing
OceanBase Database Proxy (ODP) is a dedicated proxy server for OceanBase Database. The data of OceanBase Database users is stored in multiple replicas on OBServer nodes. ODP receives SQL requests from users, forwards the requests to the optimal target OBServer node, and returns the execution results to users.
Features of ODP
Although ODP adds a hop to the database access link, ODP serves as a proxy server that provides various features and benefits. The following figure shows a sample deployment architecture where ODP is used.
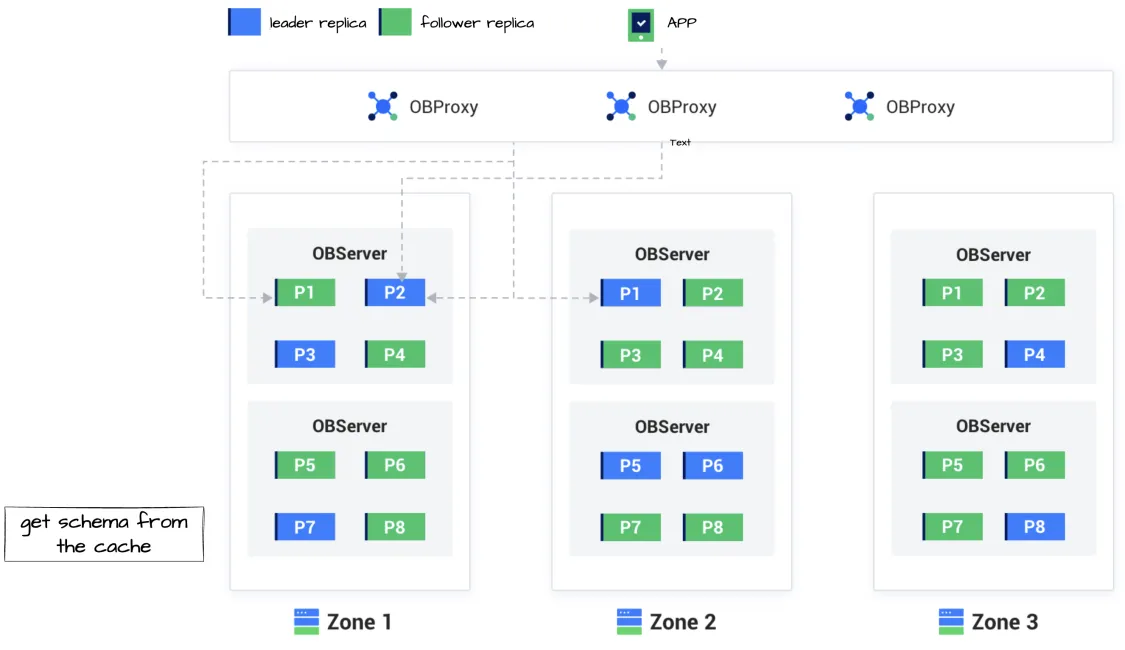
As shown in the preceding figure, the application is a business application and is allocated with three ODP nodes that run obproxy processes. In actual deployment, a load balancer such as F5, LVS, or Nginx is deployed between the ODP nodes and the application to distribute requests to multiple ODP nodes, to which OBServer nodes are connected. Six OBServer nodes are deployed in the sample deployment architecture.
The reasons why ODP is required are as follows:
-
Data routing
ODP can obtain information about data distribution on OBServer nodes and forwards an SQL statement of a user to the OBServer node where the required data is located. This improves execution efficiency. Here is an example: As shown in the preceding figure, the data of the
t1,t2, andt3tables is inP1,P2, andP3, respectively. ODP can forward the SQL statementinsert into t1to the OBServer node that contains theP1leader inZone 2and the SQL statementupdate t2to the OBServer node that contains theP2leader inZone 1. -
Connection management
An OceanBase cluster containing a large number of OBServer nodes is highly susceptible to connection status changes caused by maintenance and OBServer node problems. If one of the preceding exceptions occurs when a client is directly connected to an OBServer node, the connection will be closed. ODP masks the complexity of distributed OBServer nodes. If a client is connected to ODP, ODP can ensure the stability of the connection and manage the status of OBServer nodes in complex business scenarios.
Based on ODP, a distributed database can be used in a similar manner as a standalone database.
Benefits of ODP
ODP is a key component of OceanBase Database and provides the following benefits:
-
High-performance forwarding
ODP is fully compatible with the MySQL protocol and supports the proprietary protocol of OceanBase. It adopts the multi-threaded asynchronous framework and transparent streaming forwarding to ensure high-performance data forwarding. In addition, it consumes minimal cluster resources.
-
Optimal routing
ODP fully considers the location of replicas that are included in each user request, read/write split routing strategy configured by each user, optimal procedure for multi-region deployment of OceanBase Database, and the status and load of each OBServer node. ODP routes a user request to the optimal OBServer node and ensures the performance of OceanBase Database operations.
-
Connection management
For the physical connections of a client, ODP maintains its connections to multiple OBServer nodes at the backend. It also adopts the incremental synchronization solution based on version numbers to maintain the session status of connections to each OBServer node. This ensures efficient client access to each OBServer node.
-
Security and reliability
ODP supports data access by using SSL and is compatible with the MySQL protocol to meet the security requirements of users.
-
Easy O&M
ODP is stateless and supports unlimited horizontal scale-out. It allows you to access multiple OceanBase clusters at the same time. You can monitor the status of OceanBase Database in real time by using various internal commands. This allows you to perform routine O&M in an efficient manner.
ODP Community Edition is fully open source under Mulan Public License, Version 2 (Mulan PubL v2). You can copy and use the source code free of charge. You must follow the requirements outlined in the license when you modify or distribute the source code.
High performance based on ODP routing
High performance is an important characteristic of OceanBase Database. Routing affects performance mainly in terms of network communication overheads. ODP reduces network communication overheads and improves overall performance by perceiving data distribution and geographic locations of servers. This section describes routing strategies in terms of performance.
This section answers the following three questions:
-
What is the implementation logic of ODP routing?
-
What types of SQL execution plans are supported by ODP?
-
How can I view resource distribution information?
Implementation logic of ODP routing
As an important feature of OceanBase Database, routing enables quick data access in a distributed architecture.
A partition is a basic unit of data storage in OceanBase Database. After a table is created, mappings between the table and its partitions are generated. A non-partitioned table is mapped to one partition. A partitioned table is mapped to multiple partitions.
Based on the routing feature, a query can be accurately routed to the OBServer node where the desired data is located. In addition, a read request without high consistency requirements can be routed to an OBServer node where a replica is located. This maximizes the usage of server resources. During the routing process, SQL statements, configuration rules, and OBServer node status are used as the input, and an available OBServer node IP address is generated as the output.
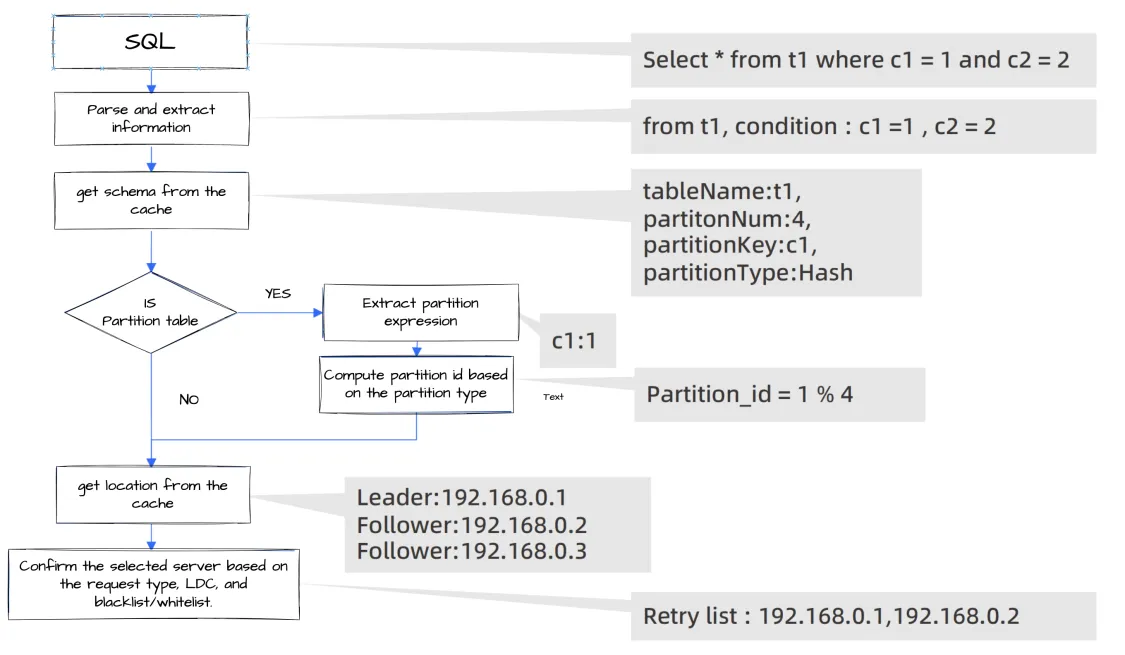
The following figure shows the routing logic.
-
Parse the SQL request and extract information.
The custom parser module of ODP is used to parse SQL statements. ODP needs only to parse the database names, table names, and hints in DML statements. No complex expression analysis is required.
-
Obtain location information from the location cache.
ODP obtains the location of the replica involved in the SQL request. ODP attempts to obtain the routing table first from the local cache and then from the global cache. If the preceding operations fail, ODP initiates an asynchronous query task to query the routing table from the OBServer node. ODP uses the trigger mechanism to update the routing table. ODP forwards SQL requests to corresponding OBServer nodes based on the routing table. If an OBServer node finds that it cannot process an SQL request, it places the feedback in the response packet and sends the packet to ODP. ODP determines whether to forcibly update the routing table in the local cache based on the feedback. Generally, the routing table changes only when an OBServer node undergoes a major compaction or when leader switchover is caused by load balancing.
-
Determine routing rules.
ODP must determine the optimal routing rule based on the actual situation. For example, DML requests for strong consistency reads are routed to the OBServer node where the partition leader is located, whereas DML requests for weak consistency reads and other requests are evenly distributed to the OBServer nodes where the leader and followers are located. If an OceanBase cluster is deployed across regions, ODP provides logical data center (LDC)-based routing to preferentially route requests to an OBServer node in the same IDC, then an OBServer node in the same region, and finally an OBServer node in a different region. If the OceanBase cluster adopts the read-write splitting mode, ODP provides rules such as RZ-first, RZ-only, and non-major-compaction-first. You can set these rules based on your business needs. Here, RZ refers to read-only zone. In practice, the previous rules can be combined to generate a specific routing rule.
-
Select a target OBServer node.
ODP selects an OBServer node from the obtained routing table based on the determined routing rule and forwards the request to the OBServer node after the OBServer node passes the blocklist and graylist checks.
Types of SQL execution plans
A partition is a basic unit for data storage. When you create a table, mappings between the table and its partitions are automatically created. A non-partitioned table is mapped to one partition, and a partitioned table can be mapped to multiple partitions. Each partition contains one leader and multiple followers. By default, data is read from and written to the leader.
In OceanBase Database, an execution plan is generated before an SQL statement is executed, and the executor schedules different operators for evaluation based on the execution plan. OceanBase Database supports local, remote, and distributed plans.
This section describes how to read data from a partition leader in strong consistency mode based on the three types of execution plans.
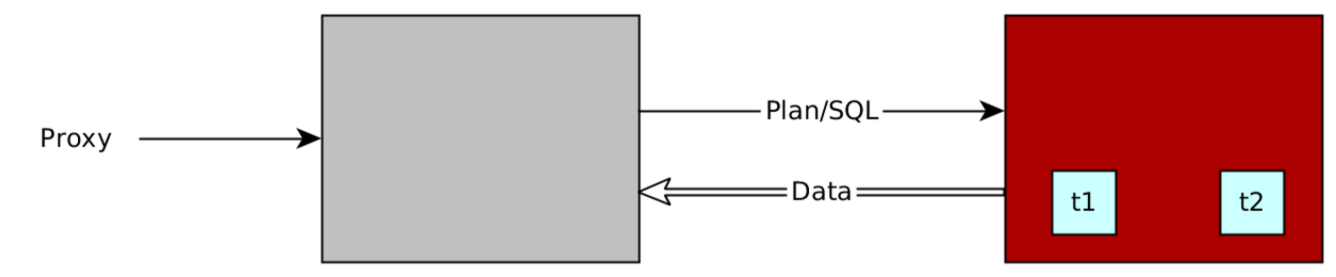
Local plan
All partition leaders involved in an SQL statement with a local plan are stored on the OBServer node where the current session resides. The OBServer node does not need to interact with other nodes during execution of the SQL statement.

You can execute the EXPLAIN statement to query a local plan. The output is as follows:
========================================
|ID|OPERATOR |NAME|EST. ROWS|COST |
----------------------------------------
|0 |HASH JOIN | |98010000 |66774608|
|1 | TABLE SCAN|T1 |100000 |68478 |
|2 | TABLE SCAN|T2 |100000 |68478 |
========================================
Remote plan
All partition leaders involved in an SQL statement with a remote plan are stored on an OBServer node other than the one where the current session resides. The current OBServer node must forward the SQL statement or subplan.
You can execute the EXPLAIN statement to query a remote plan, which contains EXCHANGE REMOTE operators. The output is as follows:
==================================================
|ID|OPERATOR |NAME|EST. ROWS|COST |
--------------------------------------------------
|0 |EXCHANGE IN REMOTE | |98010000 |154912123|
|1 | EXCHANGE OUT REMOTE| |98010000 |66774608 |
|2 | HASH JOIN | |98010000 |66774608 |
|3 | TABLE SCAN |T1 |100000 |68478 |
|4 | TABLE SCAN |T2 |100000 |68478 |
==================================================
In the preceding plan, Operator 0 EXCHANGE IN REMOTE and Operator 1 EXCHANGE OUT REMOTE execute operations on different OBServer nodes.
The OBServer node where Operator 0 resides generates a remote plan for an SQL statement forwarded by ODP, and forwards the SQL statement or the subplans generated by Operators 1 to 4 to the OBServer node where the partition leader resides.
The OBServer node where Operators 1 to 4 reside executes the HASH JOIN operation, and returns the result to the OBServer node where Operator 0 resides through Operator 1.
Finally, the OBServer node where Operator 0 resides receives the result through Operator 0, and further returns the result to the upper layer.
Distributed plan
A distributed plan does not define the relationship between partition leaders involved in the SQL statement and the current session. You can create a distributed plan for an SQL statement that needs to access multiple partitions with their leaders distributed on different OBServer nodes.
A distributed plan is scheduled in parallel execution mode and divided into multiple steps during scheduling. Each step is called a data flow operation (DFO).
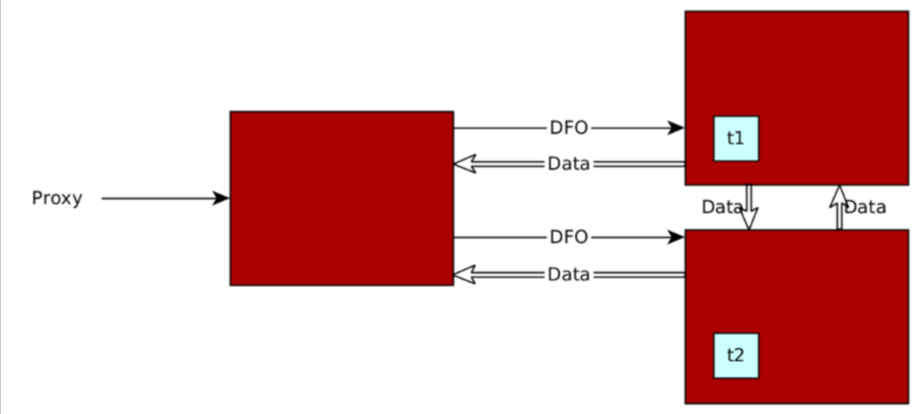
You can execute the EXPLAIN statement to query a distributed plan, which contains EXCHANGE DISTR operators. The output is as follows:
================================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
----------------------------------------------------------------
|0 |PX COORDINATOR | |980100000|1546175452|
|1 | EXCHANGE OUT DISTR |:EX10002|980100000|664800304 |
|2 | HASH JOIN | |980100000|664800304 |
|3 | EXCHANGE IN DISTR | |200000 |213647 |
|4 | EXCHANGE OUT DISTR (HASH)|:EX10000|200000 |123720 |
|5 | PX BLOCK ITERATOR | |200000 |123720 |
|6 | TABLE SCAN |T1 |200000 |123720 |
|7 | EXCHANGE IN DISTR | |500000 |534080 |
|8 | EXCHANGE OUT DISTR (HASH)|:EX10001|500000 |309262 |
|9 | PX BLOCK ITERATOR | |500000 |309262 |
|10| TABLE SCAN |T2 |500000 |309262 |
================================================================
All partition leaders involved in a local or remote plan reside on a single OBServer node. ODP is designed to use better-performing local plans instead of remote plans as much as possible.
Without ODP, an OBServer node must generate a remote plan for an SQL statement and then forward the remote plan. In this case, the SQL statement must be processed by the parser and the resolver, and the optimizer must rewrite the SQL statement and select an optimal execution plan. Even so, the forwarded plan may still be a subplan with high network transmission costs.
However, ODP can forward an SQL statement by simply parsing the SQL statement and obtaining partition information. For more information, see “Implementation logic of ODP routing”. The overall process is much simpler than that of the preceding method.
If you have a large number of SQL statements whose table-based routing types are remote plans, the routing of the SQL statements may be abnormal. You can check the plan_type field in the oceanbase.GV$OB_SQL_AUDIT view for verification. You can query the number of execution plans by type. Here is a sample SQL statement:
MySQL [oceanbase]> select plan_type, count(1) from gv$ob_sql_audit where
request_time > time_to_usec('2021-08-24 18:00:00') group by plan_type;
The output is as follows:
+-----------+----------+
| plan_type | count(1) |
+-----------+----------+
| 1 | 17119 |
| 0 | 9614 |
| 3 | 4400 |
| 2 | 23429 |
+-----------+----------+
4 rows in set
The value of plan_type can be 1, 2, or 3, indicating a local plan, remote plan, or distributed plan, respectively. Generally, 0 indicates an SQL statement without a plan, for example, set autocommit=0/1 and commit.
Resource distribution information
OceanBase Database uses ODP to provide SQL routing. This section first describes how to view the data locations for you to better understand the SQL routing strategies.
View the locations of tenant resource units
ODP must know the locations of tenant resources before it can accurately route SQL statements to optimal OBServer nodes. The locations are stored in the location cache. You can find the locations of tenant resources by using either of the following methods:
-
Query resource locations from the
systenantselect
t1.name resource_pool_name,
t2.`name` unit_config_name,
t2.max_cpu,
t2.min_cpu,
round(t2.memory_size / 1024 / 1024 / 1024) max_mem_gb,
round(t2.memory_size / 1024 / 1024 / 1024) min_mem_gb,
t3.unit_id,
t3.zone,
concat(t3.svr_ip, ':' , t3.`svr_port`) observer,
t4.tenant_id,
t4.tenant_name
from
__all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id = t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id = t4.tenant_id)
order by
t1.`resource_pool_id`,
t2.`unit_config_id`,
t3.unit_id;The output is as follows:
+------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
| resource_pool_name | unit_config_name | max_cpu | min_cpu | max_mem_gb | min_mem_gb | unit_id | zone | observer | tenant_id | tenant_name |
+------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
| sys_pool | config_sys_zone1_xiaofeng_sys_lpj | 3 | 3 | 6 | 6 | 1 | zone1 | xx.xxx.xx.20:22602 | 1 | sys |
| pool_for_tenant_mysql | 2c2g | 2 | 2 | 2 | 2 | 1001 | zone1 | xx.xxx.xx.20:22602 | 1002 | mysql |
| pool_mysql_standby_zone1_xcl | config_mysql_standby_zone1_S1_xic | 1.5 | 1.5 | 6 | 6 | 1002 | zone1 | xx.xxx.xx.20:22602 | 1004 | mysql_standby |
+------------------------------+-----------------------------------+---------+---------+------------+------------+---------+-------+--------------------+-----------+---------------+
3 rows in set -
Query resource locations from a user tenant
select * from GV$OB_UNITS where tenant_id=1002;When you query resource locations from a business tenant, the
WHERE tenant_id=1002clause can be omitted. This is because you can view only the information about the current tenant from a business tenant. The output is as follows:+--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
| SVR_IP | SVR_PORT | UNIT_ID | TENANT_ID | ZONE | ZONE_TYPE | REGION | MAX_CPU | MIN_CPU | MEMORY_SIZE | MAX_IOPS | MIN_IOPS | IOPS_WEIGHT | LOG_DISK_SIZE | LOG_DISK_IN_USE | DATA_DISK_IN_USE | STATUS | CREATE_TIME |
+--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
| 1.2.3.4 | 22602 | 1001 | 1002 | zone1 | ReadWrite | sys_region | 2 | 2 | 1073741824 | 9223372036854775807 | 9223372036854775807 | 2 | 5798205850 | 4607930545 | 20971520 | NORMAL | 2023-11-20 11:09:55.668007 |
+--------------+----------+---------+-----------+-------+-----------+------------+---------+---------+-------------+---------------------+---------------------+-------------+---------------+-----------------+------------------+--------+----------------------------+
1 row in set
View the locations of partition replicas
According to the implementation logic of ODP routing, ODP parses SQL statements to obtain table and partition information, and then obtains the locations of corresponding partition leaders based on the information.
OceanBase Database 4.x supports tenant-level replica management strategies. All tables of a tenant conform to the same primary zone rule. In the sys tenant, you can query tenant information from the oceanbase.DBA_OB_TENANTS view. Here is a sample statement:
select * from oceanbase.DBA_OB_TENANTS;
The output is as follows:
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
| TENANT_ID | TENANT_NAME | TENANT_TYPE | CREATE_TIME | MODIFY_TIME | PRIMARY_ZONE | LOCALITY | PREVIOUS_LOCALITY | COMPATIBILITY_MODE | STATUS | IN_RECYCLEBIN | LOCKED | TENANT_ROLE | SWITCHOVER_STATUS | SWITCHOVER_EPOCH | SYNC_SCN | REPLAYABLE_SCN | READABLE_SCN | RECOVERY_UNTIL_SCN | LOG_MODE | ARBITRATION_SERVICE_STATUS | UNIT_NUM | COMPATIBLE | MAX_LS_ID |
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
| 1 | sys | SYS | 2024-04-10 10:48:59.526612 | 2024-04-10 10:48:59.526612 | RANDOM | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1 |
| 1001 | META$1002 | META | 2024-04-10 10:49:30.029481 | 2024-04-10 10:50:27.254959 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1 |
| 1002 | mysql | USER | 2024-04-10 10:49:30.048284 | 2024-04-10 10:50:27.458529 | zone1 | FULL{1}@zone1 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1717384184174664001 | 1717384184174664001 | 1717384184174664001 | 4611686018427387903 | NOARCHIVELOG | DISABLED | 1 | 4.2.3.0 | 1001 |
+-----------+-------------+-------------+----------------------------+----------------------------+--------------+---------------+-------------------+--------------------+--------+---------------+--------+-------------+-------------------+------------------+---------------------+---------------------+---------------------+---------------------+--------------+----------------------------+----------+------------+-----------+
3 rows in set
In the sys tenant, you can query the partition locations of all tables under each tenant from the oceanbase.cdb_ob_table_locations view. Here is a sample statement:
select * from oceanbase.cdb_ob_table_locations where table_name = 't1';
The output is as follows:
+-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
| TENANT_ID | DATABASE_NAME | TABLE_NAME | TABLE_ID | TABLE_TYPE | PARTITION_NAME | SUBPARTITION_NAME | INDEX_NAME | DATA_TABLE_ID | TABLET_ID | LS_ID | ZONE | SVR_IP | SVR_PORT | ROLE | REPLICA_TYPE | DUPLICATE_SCOPE | OBJECT_ID | TABLEGROUP_NAME | TABLEGROUP_ID | SHARDING |
+-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
| 1 | oceanbase | t1 | 500010 | USER TABLE | NULL | NULL | NULL | NULL | 200003 | 1 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500010 | NULL | NULL | NULL |
| 1002 | test | t1 | 500087 | USER TABLE | NULL | NULL | NULL | NULL | 200049 | 1001 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500087 | NULL | NULL | NULL |
| 1004 | test | t1 | 500003 | USER TABLE | NULL | NULL | NULL | NULL | 200001 | 1001 | zone1 | xx.xxx.xx.20 | 22602 | LEADER | FULL | NONE | 500003 | NULL | NULL | NULL |
+-----------+---------------+------------+----------+------------+----------------+-------------------+------------+---------------+-----------+-------+-------+--------------+----------+--------+--------------+-----------------+-----------+-----------------+---------------+----------+
3 rows in set
In a user tenant, you can query the partition locations of all tables under the current tenant from the oceanbase.dba_ob_table_locations view.
select database_name, table_name, table_id, table_type, zone, svr_ip, role from oceanbase.dba_ob_table_locations where table_name = 't1';
The output is as follows:
+---------------+------------+----------+------------+-------+--------------+--------+
| database_name | table_name | table_id | table_type | zone | svr_ip | role |
+---------------+------------+----------+------------+-------+--------------+--------+
| test | t1 | 500087 | USER TABLE | zone1 | xx.xxx.xx.20 | LEADER |
+---------------+------------+----------+------------+-------+--------------+--------+
1 row in set
View and modify LDC settings
LDC-based routing can resolve the issue of latency caused by remote routing when multiple IDCs are deployed across multiple regions in a distributed relational database.
As a typical high-availability distributed relational database system, OceanBase Database uses the Paxos protocol for log synchronization. OceanBase Database natively supports multi-region and multi-IDC deployment to ensure high disaster tolerance and reliability. However, every database deployed across multiple regions and IDCs has a latency issue caused by routing. OceanBase Database provides the LDC routing feature to address this issue. If the region and IDC attributes are specified for each zone in an OceanBase cluster and the IDC name attribute is specified for ODP, when a data request is sent to ODP, ODP will select an OBServer node in the following sequence: an OBServer node in the same IDC, an OBServer node in the same region, and a remote OBServer node. For more information, see Strategy-based routing.
OceanBase Database allows you to modify the system variables to change the default routing strategies. For more information, see SQL routing.
High availability based on ODP routing
High availability means that OceanBase Database is tolerant of server faults, which makes the faults transparent and imperceptible to applications. When ODP finds that an OBServer node is faulty, it excludes the faulty node and selects a healthy node during routing. ODP also allows failed SQL statements to be retried. High availability is implemented by using fault detection, the blocklist mechanism, and the retry logic. As shown in the following figure, ODP adds the faulty OBServer node 1 to the blocklist and selects a healthy node during routing.
You can design routing strategies based on the factors affecting data routing and the principles of data routing. In principle, the status and data distribution of OBServer nodes must be monitored in real time. However, this is almost impossible in practice. Therefore, the routing strategies must achieve a balance between functionality, performance, and high availability to make OceanBase Database easier to use.
Routing features and strategies of ODP
ODP allows you to access different servers of different tenants in different clusters through cluster routing, tenant routing, and intra-tenant routing. This section describes the routing features of ODP in terms of these three aspects.
Cluster routing
Cluster routing allows you to access different clusters. The key to cluster routing is to obtain the mapping between a cluster name and a RootService list.
-
In the startup method in which the RootService list is specified by using a startup parameter, the mapping between a cluster name and the RootService list is also specified by using a startup parameter.
-
In the startup method in which the
config_server_urlparameter is specified, the mapping between a cluster name and a RootService list is obtained from the access URL.
Note that the RootService list does not need to contain all the cluster servers. ODP obtains the list of servers in a cluster from a view. Generally, the RootService list contains servers where RootService is located.
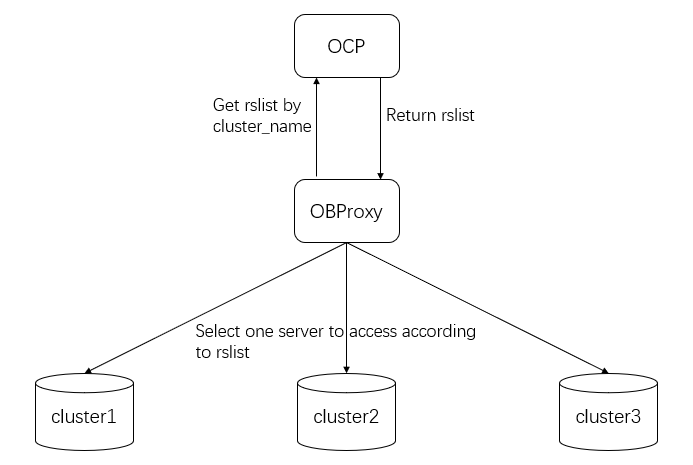
As can be seen from the preceding figure, OceanBase Cloud Platform (OCP) is a key module in cluster routing. If cluster routing issues occur in your production environment, check whether OCP operates properly.
ODP obtains the RootService list when you log on to access a cluster for the first time. ODP then saves the RootService list to the memory. In subsequent access to the cluster, ODP can obtain the RootService list from the memory.
Cluster routing allows you to access different clusters. Therefore, when you use ODP to connect to a cluster, you must specify user_name, tenant_name, as well as cluster_name in the command. If OceanBase Developer Center (ODC) is deployed, you must use ODP to connect to clusters. When you configure a connection string in ODC, you must also add cluster_name to the connection string. Here is an example (assuming that the IP address and port number of ODP are 127.0.0.1 and 2883, respectively):
mysql -h 127.0.0.1 -u user_name@tenant_name#cluster_name -P2883 -Ddatabase_name -pPASSWORD
If you directly connect to an OBServer node without using ODP, you need to specify only user_name and tenant_name in the command, without specifying cluster_name. Here is an example (assuming that the IP address and port number of the OBServer node are 1.2.3.4 and 12345, respectively):
mysql -h 1.2.3.4 -u user_name@tenant_name -P12345 -Ddatabase_name -pPASSWORD
Tenant routing
In OceanBase Database, a cluster has multiple tenants. The tenant routing feature of ODP allows you to access different tenants. Different from other tenants, the sys tenant is similar to an administrator tenant, and is related to cluster management. This section separately describes routing for the sys tenant and routing for a user tenant.
Routing for the sys tenant
After completing cluster routing, ODP obtains the RootService list of the cluster. In this case, ODP logs on to a server in the RootService list with the proxyro@sys account and obtains all the servers in the cluster from the DBA_OB_SERVERS view.
In the implementation of OceanBase Database, the sys tenant is distributed on each node. Therefore, the result retrieved from the DBA_OB_SERVERS view is the routing information of the sys tenant.
ODP accesses the DBA_OB_SERVERS view every 15 seconds to maintain the latest routing information and to perceive node changes in the cluster. In addition to the cluster server list, ODP also obtains information such as the partition distribution information, zone information, and tenant information from the sys tenant.
Routing for a user tenant
Unlike the routing information of the sys tenant, the routing information of a user tenant is about the servers where the tenant resources are located.
ODP does not obtain routing information of a user tenant from a unit-related table, but by using the special table name __all_dummy, which indicates a query for the tenant information. ODP obtains the server list of the tenant from the internal table __all_virtual_proxy_schema. For ODP to access the __all_virtual_proxy_schema table, you must specify the table name __all_dummy and the tenant name to obtain the node information of the tenant.
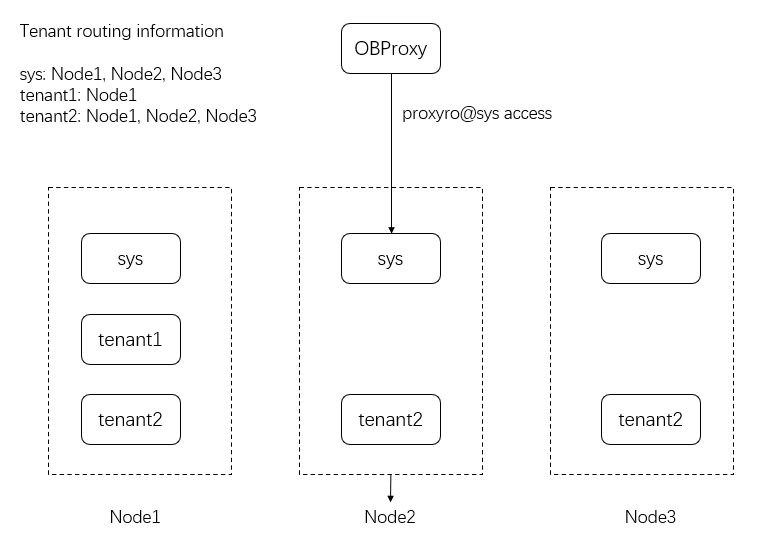
ODP stores the obtained tenant information in the local memory and updates the cache information according to certain strategies. For the sys tenant, ODP initiates a pull task every 15 seconds to obtain the latest information. For user tenants, ODP refreshes the routing cache in accordance with the following strategies:
-
Creation: When you access a user tenant for the first time, ODP accesses the
__all_virtual_proxy_schematable to obtain the routing information of the tenant and creates the routing cache. -
Eviction: ODP disables the cache when the OBServer node returns the
OB_TENANT_NOT_IN_SERVERerror code. -
Update: ODP accesses the
__all_virtual_proxy_schematable again to obtain the routing information of the user tenant when the cache is disabled.
In summary, in the multi-tenant architecture, ODP obtains metadata information from the sys tenant. The routing information of the sys tenant is a list of servers in the cluster. Then, ODP obtains the routing information of tenants from the metadata information. With the tenant routing feature, ODP supports the multi-tenant architecture of OceanBase Database.
Intra-tenant routing
SQL routing strategy for strong consistency reads
ODP supports many routing strategies. This section describes a part of them from simple ones to complex ones.
-
In the strong consistency read strategy, ODP routes SQL statements to the node that hosts the leader replica of the accessed table partition. This strategy is easy to understand, but the routing of SQL statements can be complicated.
-
If an SQL statement accesses two tables, ODP will identify the node that hosts the leader replica of the accessed partition in the first table based on the first accessed table and its partitioning conditions. If the identification fails, ODP routes the SQL statement to a random node. Therefore, in an SQL statement that joins multiple tables, the order of tables can affect the routing strategy, which in turn affects the database performance.
-
When ODP needs to identify the node that hosts the leader of the accessed partition in a partitioned table, ODP checks whether the partitioning key is specified as an equivalence condition in the SQL statement. If not, ODP cannot identify the partition to be accessed. In this case, ODP routes the SQL statement to a random node that hosts a partition of the table.
-
When a transaction starts, the node to which the first SQL statement in the transaction is routed serves as the destination node of subsequent SQL statements in the transaction until the transaction is committed or rolled back.
-
After ODP routes an SQL statement to a node, the execution of the SQL statement is divided into the following three cases:
-
Local execution: If the leader of the partition to be accessed exists on that node, the SQL statement is executed on that node based on a local execution plan. The value of the
plan_typeparameter is1. -
Remote execution: If the leader of the partition to be accessed does not exist on that node, the SQL statement is forwarded by the OBServer node, and is executed on another node based on a remote execution plan. The value of the
plan_typeparameter is2. -
Distributed execution: If replicas of the partition to be accessed are distributed on multiple nodes, the SQL statement is executed based on a distributed execution plan. The value of the
plan_typeparameter is3.
-
-
If a transaction contains an SQL statement that reads a replicated table, and the SQL statement is routed to a node where a follower of the replicated table exists, the SQL statement can read the local follower. This is because all followers of the replicated table are strongly consistent with the leader. The SQL statement is executed based on a local execution plan.
In real-world scenarios, complex SQL statements are often used. As a result, ODP uses complex routing strategies. Therefore, the routing result may be inaccurate. If the routing does not meet the design requirements, bugs will occur. However, the bugs may also be triggered by design. After all, the current version of ODP can parse only simple SQL statements, while OceanBase Database can parse complete execution plans.
When many complex business SQL statements are involved, remote and distributed SQL executions are unavoidable. In this case, you must note the proportions of remote and distributed SQL executions. If the proportions are large, the overall execution performance of business SQL statements will not be good. To improve the execution performance, you need to minimize remote and distributed SQL executions by using methods such as creating table groups, using replicated tables, and setting the PRIMARY_ZONE parameter.
SQL routing strategy for weak consistency reads
By default, OceanBase Database uses the strong consistency read mode, which is also known as read-after-write consistency. This mode allows you to view changes right after you make the changes. In the strong consistency read strategy, ODP routes SQL statements first to the node that hosts the leader replica of the accessed table partition.
Weak consistency read is the opposite of strong consistency read, which means that you cannot view the data right after you write the data. In the weak consistency read strategy, ODP routes an SQL statement that accesses a table partition to a node that hosts the leader or follower replicas of the partition. Generally, ODP routes the SQL statement to a node that hosts three or more replicas.
However, if the LDC feature is enabled for both OceanBase Database and ODP, the SQL routing strategy for weak consistency reads may change and an SQL statement is routed to a node in the following order:
-
A node in the same IDC or region and not in the In Major Compaction state
-
A node in the same region and in the In Major Compaction state
-
A node in another region
ODP prefers nodes that are not in the In Major Compaction state. However, if you disable rotating major compaction for an OceanBase cluster by setting the enable_merge_by_turn parameter to false, ODP cannot avoid nodes in the In Major Compaction state because all nodes are involved in major compaction.
In addition to SQL statements that are used for data access, some SQL statements are used for viewing or setting variable values. Here is an example:
set @@autocommit=off
show variables like 'autocommit';
These SQL statements are routed to a random node. In the random routing strategy, if the LDC feature is enabled for OceanBase Database and ODP, SQL statements are also routed in the preceding order.
Generally, weak consistency reads are used in scenarios where data reads and writes are separated. However, if the PRIMARY_ZONE parameter of a tenant is set to RANDOM, the leaders of all partitions of the tenant are distributed across all zones. In this case, the weak consistency read strategy does not make much difference.
However, if you use read-only replicas and deploy the node that hosts read-only replicas in a separate IDC, you can deploy ODP in the same IDC to route SQL statements to the node that hosts the read-only replicas.
Other routing strategies
ODP supports many routing strategies. This section briefly describes a part of them. You can focus on the ODP routing strategies for strong consistency reads and weak consistency reads.
ODP supports the following intra-tenant routing strategies:
-
IP address-based routing
In this mode, an OBServer node is specified by using the
target_db_serverparameter of ODP or by using a hint in the statement. ODP routes the statement to the specified OBServer node. This routing mode has the highest priority. If an IP address is specified, ODP will ignore other routing modes. For more information, see IP address-based routing. -
Partitioned table-based routing for strong-consistency reads
In this mode, the partitioning key, partitioning key expression, or partition name is provided in a strong-consistency read statement on a partitioned table. ODP accurately routes the statement to the OBServer node that hosts the leader of the partition where the data resides. For more information, see Partitioned table-based routing for strong-consistency reads.
-
Global index table-based routing for strong-consistency reads
In this mode, the column value, value expression, or index partition name of the global index table is provided in a strong-consistency read statement on the primary table. ODP accurately routes the statement to the OBServer node that hosts the leader of the index partition where the data resides. For more information, see Global index table-based routing for strong-consistency reads.
-
Replicated table-based routing for strong-consistency reads
For a strong-consistency read statement on a replicated table, ODP routes the statement to the OBServer node nearest to ODP. For more information, see Replication table-based routing for strong-consistency reads.
-
Primary zone-based routing for strong-consistency reads
In this mode, the primary zone is configured by using an ODP parameter. ODP routes a strong-consistency read statement for which routing calculation cannot be performed to an OBServer node in the primary zone. For more information, see Primary zone-based routing for strong-consistency reads.
-
Strategy-based routing
ODP routes statements based on rules of the configured routing strategy. For more information, see Strategy-based routing.
-
Distributed transaction routing
After distributed transaction routing is enabled by using the ODP parameter
enable_transaction_internal_routing, statements in a transaction do not need to be force routed to the OBServer node that starts the transaction. For more information, see Distributed transaction routing. -
Rerouting
Rerouting is enabled by using an ODP parameter. After a statement is routed to an OBServer node, if no partition is hit or the distributed transaction cannot be executed on this OBServer node, ODP can accurately reroute the statement. For more information, see Rerouting.
-
Forcible routing
ODP decides whether to perform forcible routing. Forcible routing is performed in the following cases. For more information, see Forcible routing.
-
For non-distributed transaction routing, statements in a transaction are force routed to the OBServer node that starts the transaction.
-
For session-level temporary table-based routing, a query is force routed to the OBServer node where the temporary table is queried for the first time.
-
Session reuse-based routing: If routing calculation fails and the
enable_cached_serverparameter is set toTrue, ODP force routes a query to the OBServer node where the session resides the last time. -
Cursor/Piece-based routing: When the client uses cursors/pieces to obtain/upload data, all requests are force routed to the same OBServer node.
-
ODP provides a wide range of intra-tenant routing modes. You can select a routing mode as needed. If you encounter any problems, you can view the routing process in ODP by using the routing diagnostics feature. For more information about the routing diagnostics feature, see Routing diagnostics.