��排查 ODP 是否是性能瓶颈
当用户遇到 SQL 性能不符合预期问题时,一般首先需要通过全链路追踪(show trace)确认各阶段耗时占比,确认耗时长的阶段是什么。
这个小节就为大家介绍在 SQL 性能差时,如何通过 show trace 来为 ODP 洗脱罪名。如果大家已经能够熟练应用 show trace 对 SQL 性能问题进行初步分析,可以直接跳过本小节。
全链路追踪(show trace)
OceanBase 数据库的数据链路为 APPServer <-> OBProxy <-> OBServer。APPServer 通过数据库驱动连接 ODP 发送请求,由于 OceanBase 数据库的分布式架构,用户数据以多分区多副本的方式分布于多个 OBServer 节点上,ODP 将用户请求转发到最合适的 OBServer 节点执行,并将执行结果返回用户。每个 OBServer 节点也有路由转发的功能,如果发现请求不能在当前节点执行,则会转发请求到正确的 OBServer 节点。
当出现端到端的性能问题时(在数据库场景下,端到端表示在应用服务器上观察到 SQL 请求的 RT 很高),此时首先需要定位是数据库访问链路上哪个组件的问题,再排查组件内的具体问题。
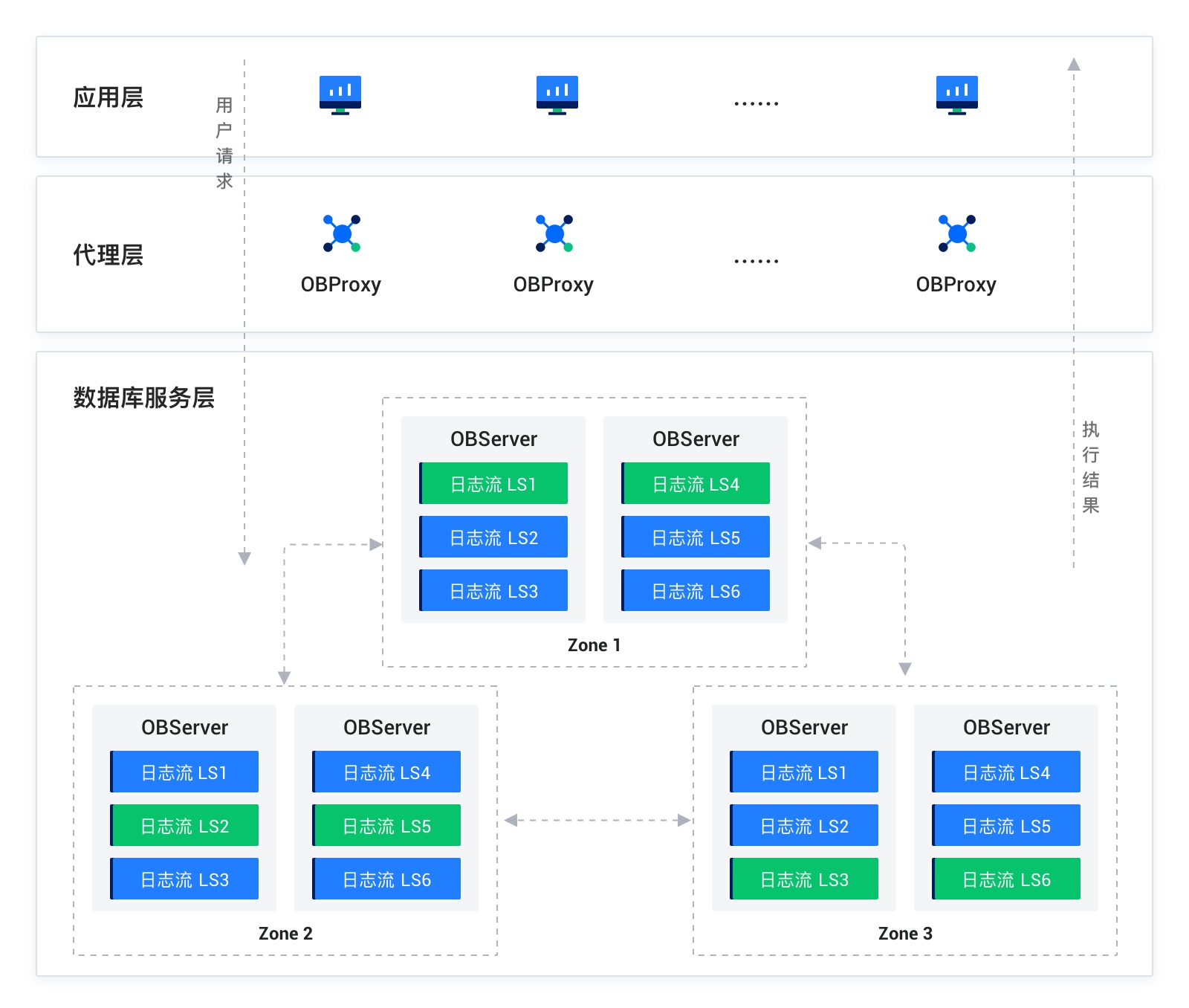
全链路追踪覆盖了两条主要的数据流路径:
-
一条是请求从应用出发,通过客户端(比如 JDBC 或 OCI)传递至 ODP(代理服务器),然后由 ODP 转发至 OBServer 节点,最终结果返回给应用程序。
-
另一条则是请求直接从应用程序通过客户端发送至 OBServer 节点,然后结果直接返回。
示例
接下来用这两条路径,分别举个一简单的例子。
-
通过 ODP 连接 OceanBase 数据库,创建表并插入数据。
create table t1(c1 int);
insert into t1 values(123); -
在当前 session 上开启全链路诊断的 show trace 功能。
SET ob_enable_show_trace = ON; -
执行一条简单的查询语句。
SELECT c1 FROM t1 LIMIT 2;输出如下:
+------+
| c1 |
+------+
| 123 |
+------+
1 row in set -
执行 show trace 语句。
SHOW TRACE;输出如下:
+-----------------------------------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-----------------------------------------------------------+----------------------------+------------+
| ob_proxy | 2024-03-20 15:07:46.419433 | 191.999 ms |
| ├── ob_proxy_partition_location_lookup | 2024-03-20 15:07:46.419494 | 181.839 ms |
| ├── ob_proxy_server_process_req | 2024-03-20 15:07:46.601697 | 9.138 ms |
| └── com_query_process | 2024-03-20 15:07:46.601920 | 8.824 ms |
| └── mpquery_single_stmt | 2024-03-20 15:07:46.601940 | 8.765 ms |
| ├── sql_compile | 2024-03-20 15:07:46.601984 | 7.666 ms |
| │ ├── pc_get_plan | 2024-03-20 15:07:46.602051 | 0.029 ms |
| │ └── hard_parse | 2024-03-20 15:07:46.602195 | 7.423 ms |
| │ ├── parse | 2024-03-20 15:07:46.602201 | 0.137 ms |
| │ ├── resolve | 2024-03-20 15:07:46.602393 | 0.555 ms |
| │ ├── rewrite | 2024-03-20 15:07:46.603104 | 1.055 ms |
| │ ├── optimize | 2024-03-20 15:07:46.604194 | 4.298 ms |
| │ │ ├── inner_execute_read | 2024-03-20 15:07:46.605959 | 0.825 ms |
| │ │ │ ├── sql_compile | 2024-03-20 15:07:46.606078 | 0.321 ms |
| │ │ │ │ └── pc_get_plan | 2024-03-20 15:07:46.606124 | 0.147 ms |
| │ │ │ ├── open | 2024-03-20 15:07:46.606418 | 0.129 ms |
| │ │ │ └── do_local_das_task | 2024-03-20 15:07:46.606606 | 0.095 ms |
| │ │ └── close | 2024-03-20 15:07:46.606813 | 0.240 ms |
| │ │ ├── close_das_task | 2024-03-20 15:07:46.606879 | 0.022 ms |
| │ │ └── end_transaction | 2024-03-20 15:07:46.607009 | 0.023 ms |
| │ ├── code_generate | 2024-03-20 15:07:46.608527 | 0.374 ms |
| │ └── pc_add_plan | 2024-03-20 15:07:46.609375 | 0.207 ms |
| └── sql_execute | 2024-03-20 15:07:46.609677 | 0.832 ms |
| ├── open | 2024-03-20 15:07:46.609684 | 0.156 ms |
| ├── response_result | 2024-03-20 15:07:46.609875 | 0.327 ms |
| │ └── do_local_das_task | 2024-03-20 15:07:46.609905 | 0.136 ms |
| └── close | 2024-03-20 15:07:46.610221 | 0.225 ms |
| ├── close_das_task | 2024-03-20 15:07:46.610229 | 0.029 ms |
| └── end_transaction | 2024-03-20 15:07:46.610410 | 0.019 ms |
+-----------------------------------------------------------+----------------------------+------------+
29 rows in set从上面这条 show trace 的结果里,大家可以分析出一些信息:
-
这条 SQL 一共花了 191.999 ms。
-
SQL 的整体的耗时主要在
ob_proxy_partition_location_lookup上,占了 181.839 ms,顾名思义,这一部分耗时是 ODP(即 proxy) 在寻找表t1的主副本的位��置信息。但是因为这张表刚刚创建,ODP 里暂时还没有对应的位置信息的缓存(也就是 location cache),所以第一次花的时间会比较久,不过之后 ODP 里就会缓存下这张表的 location cache 信息。 -
SQL 转发到合适的 OBServer 节点之后,在
com_query_process的耗时 8.824 ms。
-
这里再简单介绍 show trace 中其他几个重要点位:
ob_proxy: ODP 的起始点位,记录从 ODP 收到 SQL 请求到给客户端完整反馈响应的时间。
ob_proxy_server_process_req:表示发完 SQL 请求,到第一次收到 OBServer 节点返回响应的时间,等于 OBServer 节点处理时间 + 返回的网络耗时。
com_query_process:OceanBase 数据库的总点位,记录 OBServer 节点从收到 SQL 请求到转发响应完毕所需的时间。
-
在同一个 session 中再重新执行一遍
SELECT c1 FROM t1 LIMIT 2;这条 SQL,执行 show trace 语句查看有什么变化。SHOW TRACE;输出如下:
+-----------------------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-----------------------------------------------+----------------------------+------------+
| ob_proxy | 2024-03-20 15:34:14.879559 | 7.390 ms |
| ├── ob_proxy_partition_location_lookup | 2024-03-20 15:34:14.879652 | 4.691 ms |
| ├── ob_proxy_server_process_req | 2024-03-20 15:34:14.884785 | 1.514 ms |
| └── com_query_process | 2024-03-20 15:34:14.884943 | 1.237 ms |
| └── mpquery_single_stmt | 2024-03-20 15:34:14.884959 | 1.207 ms |
| ├── sql_compile | 2024-03-20 15:34:14.884997 | 0.279 ms |
| │ └── pc_get_plan | 2024-03-20 15:34:14.885042 | 0.071 ms |
| └── sql_execute | 2024-03-20 15:34:14.885300 | 0.809 ms |
| ├── open | 2024-03-20 15:34:14.885310 | 0.139 ms |
| ├── response_result | 2024-03-20 15:34:14.885513 | 0.314 ms |
| │ └── do_local_das_task | 2024-03-20 15:34:14.885548 | 0.114 ms |
| └── close | 2024-03-20 15:34:14.885847 | 0.190 ms |
| ├── close_das_task | 2024-03-20 15:34:14.885856 | 0.030 ms |
| └── end_transaction | 2024-03-20 15:34:14.885997 | 0.019 ms |
+-----------------------------------------------+----------------------------+------------+
14 rows in set从上面这条 show trace 的结果里,大家可以分析出一些信息:
-
第二次执行这条 SQL,时间变快了很多,从 191.999 ms 缩短到了 7.390 ms。
-
ODP 有了 location cache 信息,所以寻找路由信息和转发都变快了,从之前的 181.839 ms 缩减到了 4.691 ms。
-
SQL 转发到合适的 OBServer 节点之后,在
com_query_process的耗时从 8.824 ms 缩减到了 1.237 ms。这里多啰嗦两句,大家仔细看一下就会发现,SQL 分为编译阶段和执行阶段,编译阶段是优化器生成执行计划,执行阶段是执行引擎根据执行计划计算结果。第二次执行时,编译阶段的流程变短了,速度也变快了,大概是因为编译阶段在最开始的时候,先会去计划缓存里查询下有没有之前已经生成好并且缓存下来的计划(即上面的pc_get_plan),如果有的话,就不需要重新生成计划了,所以省了一个完整解析 SQL 并生成计划(即上面的hard_parse)的开销。
-
-
再通过直连 OBServer 节点登录 OceanBase 数据库,再重新执行一遍
SELECT c1 FROM t1 LIMIT 2;这条 SQL,执行 show trace 语句查看有什么变化。SHOW TRACE;输出如下:
+-------------------------------------------+----------------------------+------------+
| Operation | StartTime | ElapseTime |
+-------------------------------------------+----------------------------+------------+
| com_query_process | 2024-03-20 15:54:38.772699 | 1.746 ms |
| └── mpquery_single_stmt | 2024-03-20 15:54:38.772771 | 1.647 ms |
| ├── sql_compile | 2024-03-20 15:54:38.772835 | 0.356 ms |
| │ └── pc_get_plan | 2024-03-20 15:54:38.772900 | 0.143 ms |
| └── sql_execute | 2024-03-20 15:54:38.773209 | 1.052 ms |
| ├── open | 2024-03-20 15:54:38.773232 | 0.150 ms |
| ├── response_result | 2024-03-20 15:54:38.773413 | 0.421 ms |
| │ └── do_local_das_task | 2024-03-20 15:54:38.773479 | 0.192 ms |
| └── close | 2024-03-20 15:54:38.773857 | 0.379 ms |
| ├── close_das_task | 2024-03-20 15:54:38.773913 | 0.069 ms |
| └── end_transaction | 2024-03-20 15:54:38.774139 | 0.058 ms |
+-------------------------------------------+----------------------------+------------+
11 rows in set从上面这条 show trace 的结果里,大家可以分析出一些信息:
-
直连 OBServer 节点,没了 ODP,所以也就没了和 proxy 相关的开销。
-
这条 SQL 的计划,之前已经进了这台 OBServer 节点的计划缓存里,所以在多次执行时,编译阶段都不需要再走一遍完整的硬解析流程。
-
分析结束后,大家记得执行如下命令关闭 session 级别 show trace,避免对后续 SQL 的性能产生影响。
set ob_enable_show_trace='off';
总结
最后简单总结一下:对于性能不符合预期的一条 SQL,通过全链路追踪,可以看到耗时在什么阶段:是耗时在 ODP(proxy)转发阶段?还是耗时在计划生成阶段?亦或是耗时在执行阶段?在各个阶段中,我们还可以看到更加细节的耗时数据(上面那条 SQL 实在太简单,又利用到了计划缓存,所以看上去细节不多),然后我们就可以针对具体慢的地方做进一步的分析。
如果慢在 ODP 转发阶段,可以怀疑是不是 ODP 和 OBServer 节点之间的网络出现故障了,或者是不是 ODP 还没缓存位置信息等问题。
如果慢在 SQL 执行阶段,就可以怀疑是不是创建的索引不够优等问题,并进行相应的 SQL 调优,详见本教程的《SQL 性能诊断和调优》小节。