Best Practices for Archiving Historical Data
The content marked red in this topic is easily ignored when you use OceanBase Database in a test or production environment, which may lead to serious impact. We recommend that you pay more attention to such content.
Background Information
With the explosive growth of the data volume, enterprises and organizations are facing increasingly severe challenges in database management. Database performance declines, storage costs rise, and data O&M complexity increases, making data management more difficult for database administrators (DBAs) and developers.
To address these challenges, more refined management is required for data throughout the lifecycle, including four stages: online storage, nearline storage, archiving, and destruction. Among them, the nearline storage and archiving of historical data are key stages in history database management. In the archiving stage, data can be stored in a database or an offline file. For archived data that still needs to be queried from time to time, the history database solution is usually applied. The history database solution separates hot and cold data and improves the performance by reducing the load of the online database. Cold data in the history database is barely accessed. We recommend that you use a server with large disk space and low CPU configurations for the history database to reduce costs.
Note: The nearline storage stage is a specific stage between active data use (online storage stage) and long-term archiving or backup (archiving stage). In the nearline storage stage, the data access frequency is low but a high restore or access speed is still required to handle unexpected needs.
We introduced the history database feature to meet users' eager expectations for data management solutions, which brings new challenges to our database management system. In communication with users, we found that many users urgently need a solution that can effectively process large-scale historical data and reduce costs without affecting performance and data availability. These feedbacks have profoundly influenced our understanding of history databases. Therefore, we expect a history database to have the following characteristics:
-
Large storage space to support the storage of large amounts of data as well as efficient and continuous data import from the online database.
-
High scalability to process increasing amounts of data without adjusting the storage architecture.
-
Lower storage costs to store more data with less disk space and more economical storage media.
-
Efficient query capabilities for analytical queries and a small number of transactional queries.
-
Same access interface for applications and the online database to reduce application complexity.
OceanBase Database is the optimal choice to meet these demands. With its high integrated (standalone + distributed) scalability and hybrid transaction and analytical processing (HTAP) capabilities, OceanBase Database can efficiently support the online database and history database of the business system. More importantly, OceanBase Database can lower the storage costs by at least a half while meeting business needs. According to some customers, after they migrated their history database to OceanBase Database, the storage costs were reduced by about 80%. Lower storage cost is one of the reasons they chose OceanBase Database.
 We further consider the storage architecture design of the history database from the following aspects:
We further consider the storage architecture design of the history database from the following aspects:
-
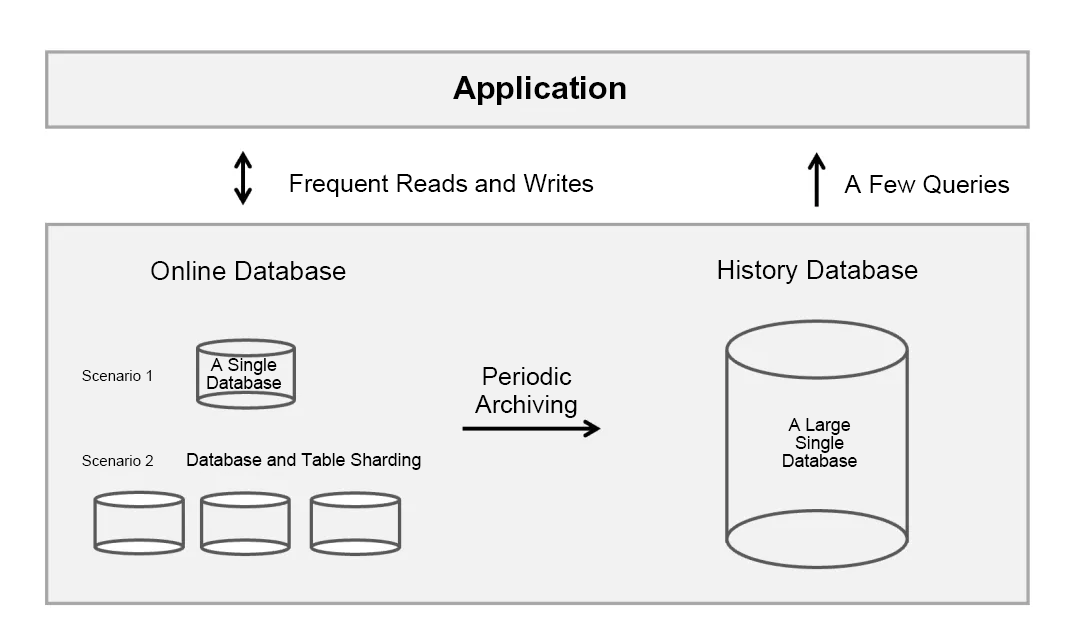
Whether the architecture of the history database needs to be consistent with that of the online database: We do not think this is necessary. The online database may adopt a sharding architecture to meet the requirements of data scale and performance, but the history database usually has low requirements for performance. The sharding architecture brings additional costs to the deployment, O&M, and backup and restore of the database. If OceanBase Database is used as the history database, a single table can easily carry tens of terabytes of data. Partitioned tables can be used when the data scale is large.
-
Whether the history database should support data updates: This is technically feasible. The history database can be either updatable or just read-only. To lower the overall costs of the history database, we recommend that you set the history database to read-only. The history database has fewer random reads and writes and can be deployed on economical storage hardware, such as Serial Advanced Technology Attachment (SATA) disks instead of SSDs. In addition, a read-only history database reduces its own backup costs, namely only one backup copy needs to be maintained.
-
Minimizing the impact of data archiving on the online database: This is essential. The online database is the key to the continuous and stable operation of enterprise business. In scenarios with a large data scale, the reading, computation, and deletion of large amounts of data will put pressure on the online database. Therefore, when choosing a data archiving method, make sure that the stability of the online database can be ensured.
The following section describes how to build data archive links to OceanBase Database by using archiving tools and migration/synchronization tools.
Archive Data by Using ODC (Recommended)
This section describes how to use OceanBase Developer Center (ODC) to archive data to and manage data in the history database. Compared with other migration/synchronization tools such as OceanBase Migration Service (OMS), ODC is adapted for data archiving scenarios and provides high usability.
Pay more attention to the first three subsections, which describe the key points that are easily ignored during installation and deployment, as well as the considerations for using the data archiving feature.
The data archiving feature of ODC is easy to use. The GUI-based operations described in the last two subsections are simple and therefore do not require much attention.
Cold data separated from hot data to improve the performance of the online database
Generally, part of the business data is barely or never accessed after a period of time. This part of data is called cold data. Cold data is archived to the history database, and the online database stores only recent data.
Conventional data archiving methods often consume large amounts of time and manpower and have risks such as misoperations and data loss. Moreover, the data management efficiency and flexibility are limited due to complex manual archiving operations.
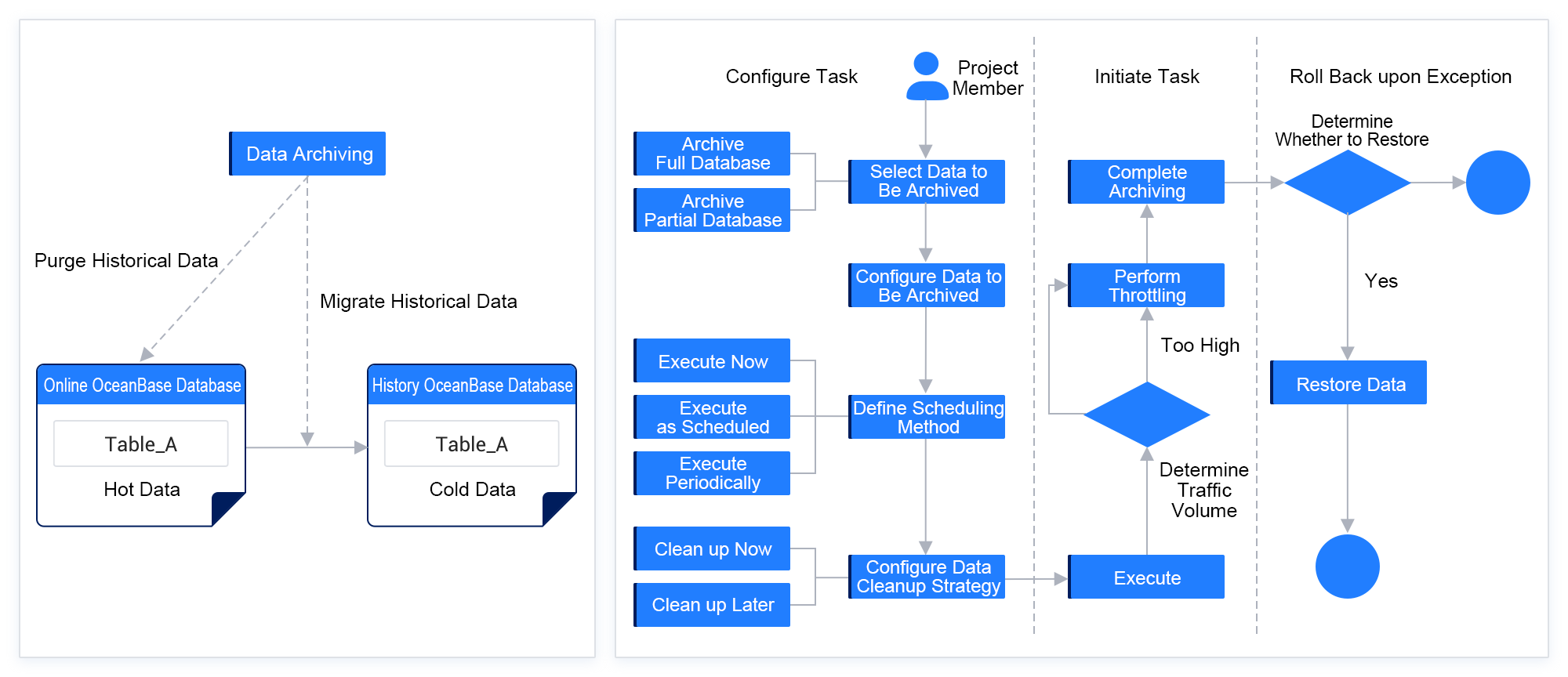
To address these issues, ODC introduces the data archiving feature since V4.2.0 to tackle the difficulties in data management and improve the work efficiency and data security. When the amount of data in an online database increases, the query performance and business operations may be affected. ODC allows you to periodically archive table data from one database to another to address this issue.
The following figure provides an overview of the data archiving capabilities of ODC.
Install and deploy ODC
For information about how to install and deploy ODC, see Deploy Web ODC.
Pay attention to the following points when you install and deploy ODC:- ODC is available in two editions: Client ODC and Web ODC. Client ODC does not support data lifecycle management (with data archiving included), project collaboration management, data desensitization, or auditing. Similar to GUI-based tools such as Navicat and DBeaver, Client ODC is more suitable for individual developers. If you need to use the data archiving feature, install Web ODC.
- The data archiving feature depends on OceanBase Database Proxy (ODP). When you start ODC, set
DATABASE_PORTin thedocker runcommand to the port number of ODP, rather than that of the OBServer node.
#!/usr/bin/env bash
docker run -v /var/log/odc:/opt/odc/log -v /var/data/odc:/opt/odc/data \
-d -i --net host --cpu-period 100000 --cpu-quota 400000 --memory 8G --name "obodc" \
-e "DATABASE_HOST=xxx.xx.xx.xx" \
-e "DATABASE_PORT=xxxxx" \
-e "DATABASE_USERNAME=[username]@[tenant name]#[cluster name]" \
-e "DATABASE_PASSWORD=******" \
-e "DATABASE_NAME=odc_metadb" \
-e "ODC_ADMIN_INITIAL_PASSWORD=******" \
oceanbase/odc:4.2.2
-
If a small amount of tenant resources such as 1.5 CPU cores and 5 GB of memory are allocated to ODC, it takes about 1.5 minutes for ODC to start. If you cannot log in to the web page of the ODC console, try running the
cd /var/log/odccommand first and then thetail -F odc.logcommand to observe the initialization process. The following information is displayed during the process:localIpAddress=xxx.xx.xx.xx, listenPort=8989. Log in to the ODC console by using the IP address and port number (8989 by default) in this information. If a message similar toStarted OdcServer in 96.934 secondsis displayed, the initialization is successful.
-
We recommend that you check in the official documentation whether required features have any limitations. If so, make preparations when you create a data source.
For example, the data archiving feature depends on ODP and you must use ODP to connect to the database when you configure a data source. The connection string is used for intelligent parsing, as shown in the following figure.
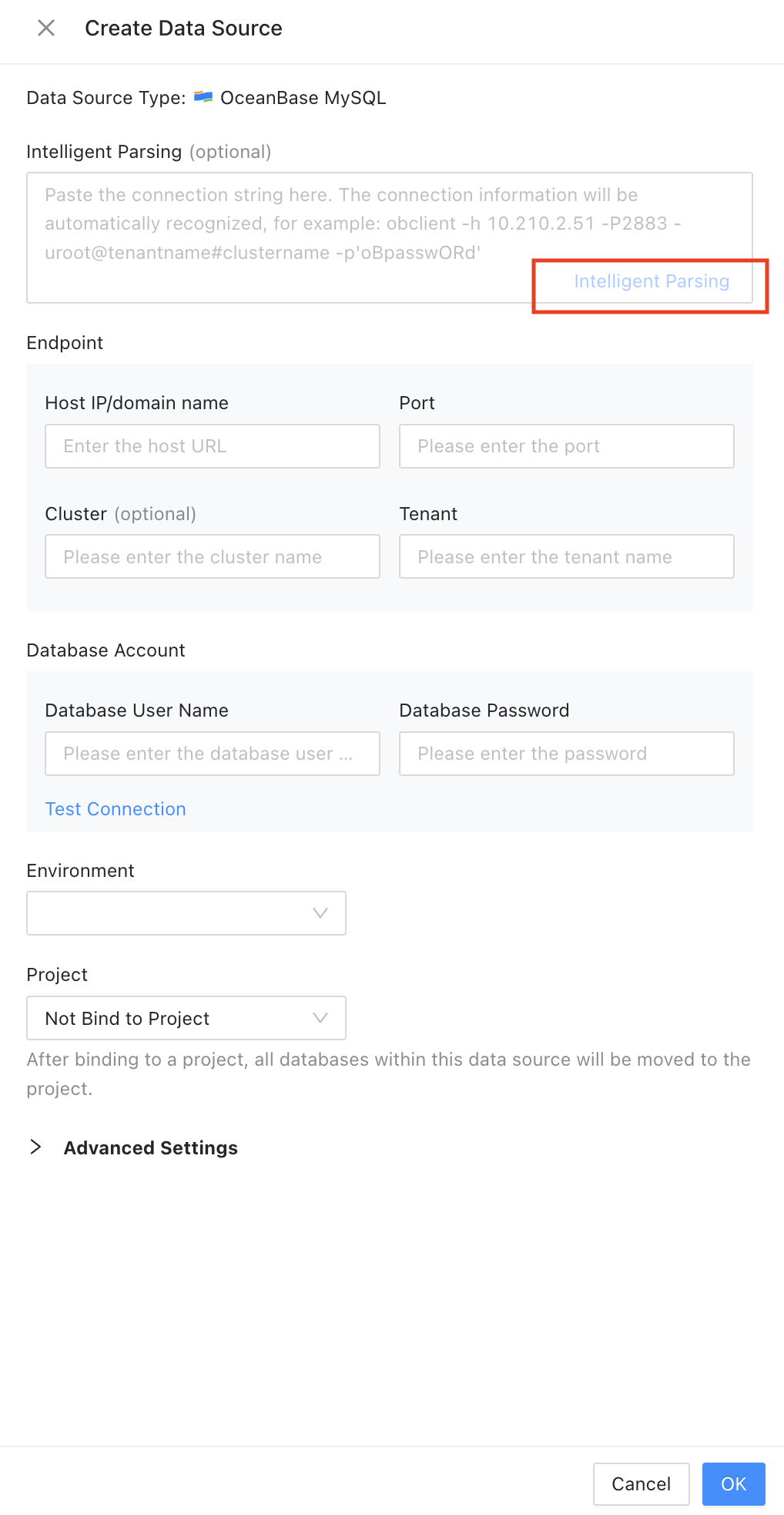
After installation, copy the database connection string, paste it into the Intelligent Parsing field, and click Intelligent Parsing to create a new data source. The parsed information is automatically populated, as shown in the preceding figure. You must also observe the following points:
- For a locally installed OceanBase cluster, select OceanBase MySQL and do not select other options such as MySQL Cloud. If you select MySQL Coud for a locally installed OceanBase cluster, the data source can be successfully created but may have unexpected issues. For example, the
systenant may be connected by default. - Click Test Connection to verify whether the username and password are correct.
- Select Query Tenant Views with sys Tenant Account. If you do not select this option, some features, such as data archiving, are unavailable.
I hope the preceding tips are helpful.
Considerations
-
Prerequisites:
- The table to be archived has a primary key.
-
Pay attention to the following rules:
-
Make sure that the columns in the source table are compatible with those in the destination. The data archiving service does not handle column compatibility issues.
-
CPU and memory exhaustion prevention is not supported for a MySQL data source.
-
Schema synchronization is not supported for subpartitions of homogeneous databases. Schema synchronization and automatic table creation are not supported for heterogeneous databases.
-
-
The following archive links are supported:
-
Links between MySQL tenants of OceanBase Database
-
Links between Oracle tenants of OceanBase Database
-
Links between MySQL databases
-
Links from a MySQL database to a MySQL tenant of OceanBase Database
-
Links from a MySQL tenant of OceanBase Database to a MySQL database
-
Links between Oracle databases
-
Links from an Oracle database to an Oracle tenant of OceanBase Database
-
Links from an Oracle tenant of OceanBase Database to an Oracle database
-
Links from a PostgreSQL database to a MySQL tenant of OceanBase Database
-
-
Data archiving is not supported in the following cases:
-
The source table in the MySQL or OceanBase MySQL data source does not have a primary key or non-null unique index.
-
The source table in the Oracle, OceanBase Oracle, or PostgreSQL data source does not have a primary key.
-
The source table in the OceanBase Oracle data source contains columns of the JSON or XMLType data type.
-
The source table in the PostgreSQL data source contains data of the following types: array, composite, enumeration, geometry, XML, HSTORE, and full-text retrieval.
-
The archiving condition contains a
LIMITclause. -
The source table contains a foreign key.
-
-
The following archive links do not support schema synchronization and automatic table creation:
- Links from an Oracle database to an Oracle tenant of OceanBase Database
- Links from an Oracle tenant of OceanBase Database to an Oracle database
- Links from a MySQL database to a MySQL tenant of OceanBase Database
- Links from a MySQL tenant of OceanBase Database to a MySQL database
- Links from a PostgreSQL database to a MySQL tenant of OceanBase Database
Create a data archiving ticket
In the ODC console, choose Tickets > Create Ticket > Data Archiving. On the page for creating a data archiving ticket, specify related parameters. This example creates a task to archive the tb_order table from the online database to the history database. Select Purge archived data from the source. Set the archive_date variable referenced in the filter condition to a value one year earlier than the current time. By doing this, you can archive data generated one year ago every time you execute an archiving task.
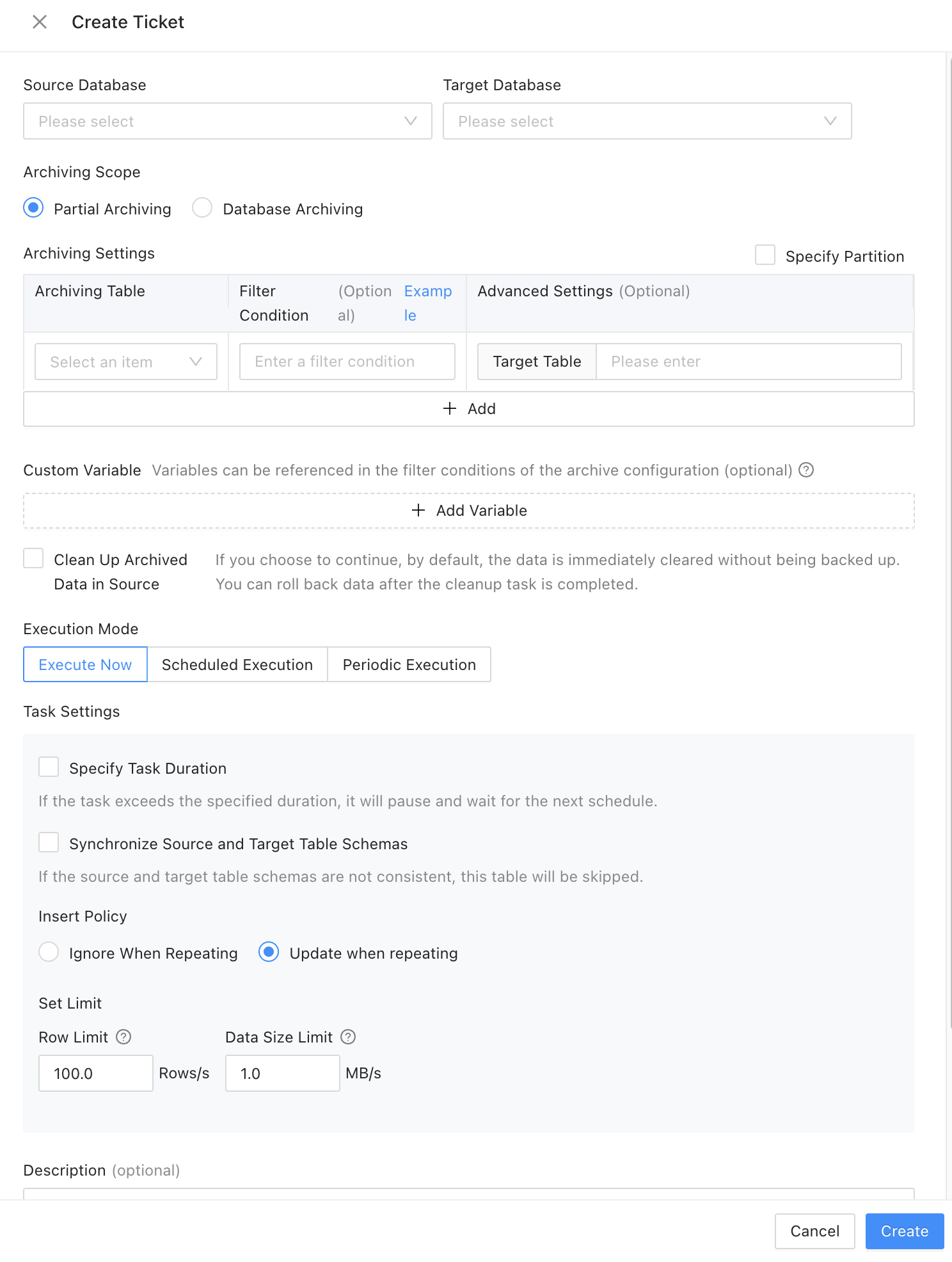
The data archiving feature of ODC supports various execution scheduling strategies. You can specify to schedule a data archiving task immediately, at a specified point in time, or periodically. You can also configure schema synchronization, data insertion, and throttling strategies. You can specify whether to synchronize partitions and indexes during schema synchronization. The history database and online database may use different partitioning methods and they have different query requirements. Therefore, you can use fewer indexes in a history database to further lower the storage costs.
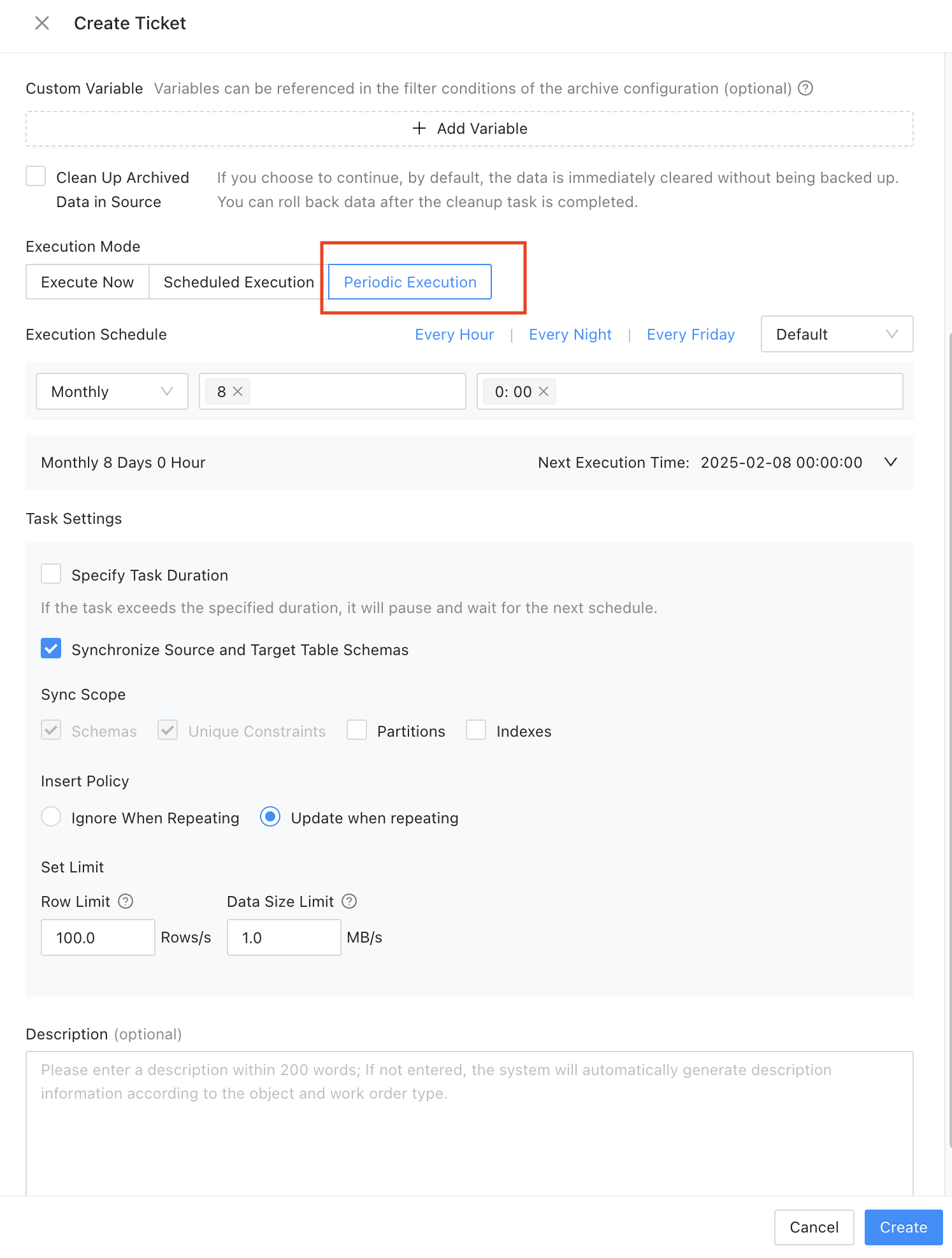
Click Create Task to preview the archiving SQL statement. Confirm the scope of data to be archived.
As you can see, you can simply configure a data archiving task in the ODC console to archive cold data from the online database to the history database, separating cold data from hot data in the online database. So is it enough to complete this process? What if we need to restore the data archived to the history database back to the online database due to business changes or misoperations? Creating a reverse archiving task is certainly possible, but we have to spend efforts to configure the new task and worry about issues resulting from configuration errors. To cope with such a situation, ODC provides the rollback feature. Let's take the previous task as an example. Now we need to roll back the archived data to the online database. We only need to click the rollback button in the Action column of the corresponding data archiving task record on the execution record page. Then, an archiving rollback task is initiated.
Clean up expired data to lower storage costs
The data archiving feature of ODC can separate cold data from hot data in the online database by migrating the cold data to the history database, thereby lowering costs and improving efficiency. However, you may be curious to know whether extra costs are required for maintaining a history database.
In fact, the cold business data in the history database does not necessarily need to be retained permanently. After a period of time, some cold data may be in the "expired" state and will not be used at all, such as log data. If the expired data can be cleaned up in a timely manner, the storage costs will be further reduced. To resolve this issue, ODC provides the data cleanup feature to regularly clean up expired data in the database and further optimize the utilization of storage resources.
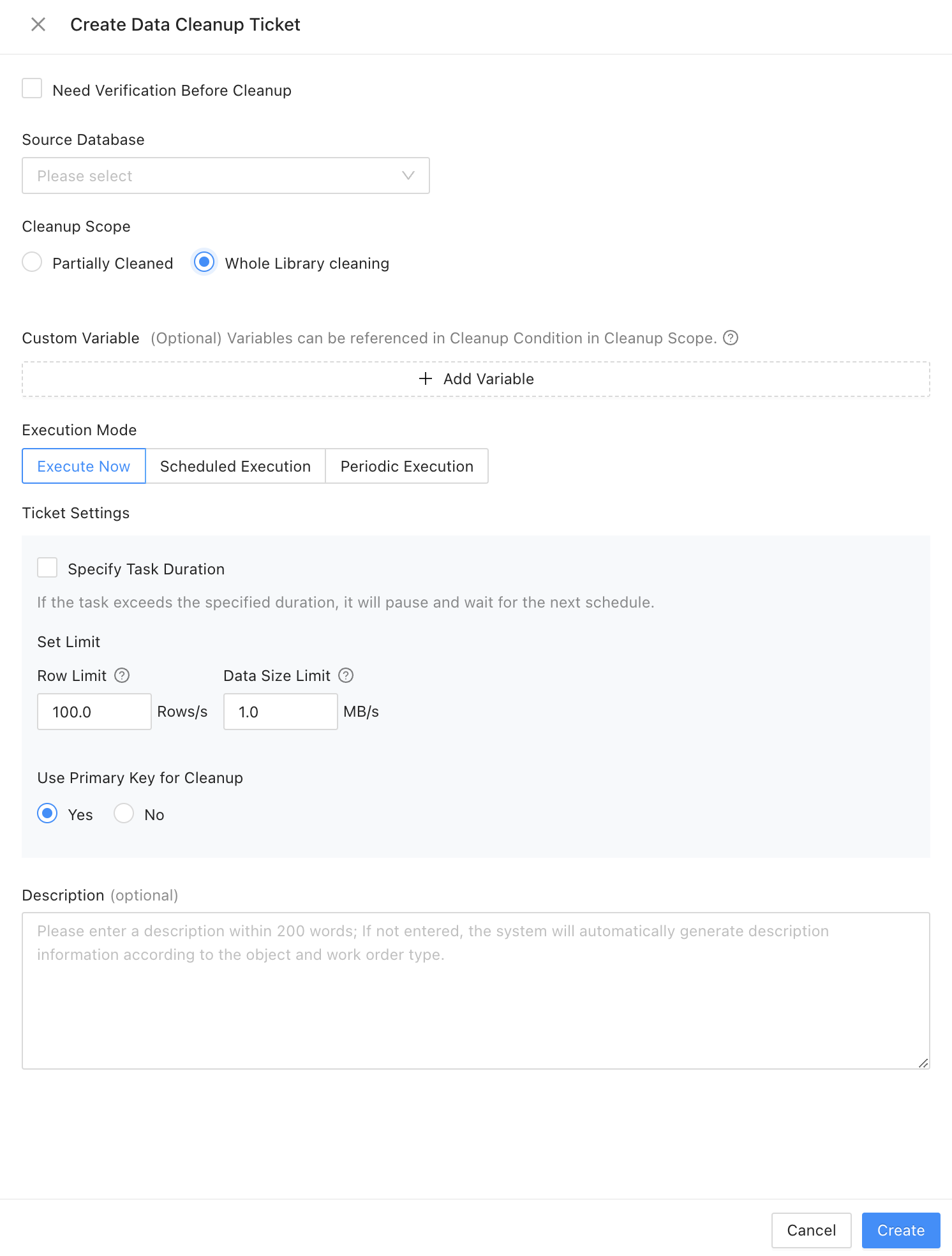
Create a data cleanup ticket
In the ODC console, choose Tickets > Create Ticket > Data Cleanup. The settings on the page for creating a data cleanup ticket are basically the same as those on the page for creating a data archiving ticket. This example creates a periodic cleanup ticket. ODC also supports data verification for the associated history database before cleanup.
Archive data by using OMS
For more information, see Use OMS for data migration and synchronization in the OceanBase Quick Starts for DBAs.
Pay special attention when using OMS for data archiving. We recommend that you enable only full migration and do not enable incremental synchronization. This is because if incremental synchronization is enabled, the cleanup operations performed on data in the source database will be synchronized to the target database. In this case, archive data may be mistakenly deleted.Archive Data by Using Other Migration Tools
For more information, see the following topics in the OceanBase Quick Starts for DBAs: