Database Object Design and Usage Specifications
Note:
You must follow the specifications highlighted in red in this topic.
The specifications that are not highlighted in red are optional but recommended. You can determine whether to follow these specifications based on your business requirements.
Object Naming Specifications
This section will not discuss object naming specifications in detail because they have been frequently mentioned. Essentially, the name of an object cannot be excessively long and must reflect the object type and corresponding business meaning, such as tbl_student_id. You may have your own naming styles. I think there is no right or wrong, and unified specifications are unnecessary.
We recommend that you do not use special characters or keywords in object names unless you have special requirements. This is because such names are awkward to read and use.
For example, a user once used the reserved keyword table as a table name and the escape character backtick (`) as a column name. The names look as if they have been encrypted. This not only makes internal users uncomfortable but also creates a headache for the technical support team when they troubleshoot issues.
obclient [test]> create table `table` (```` int);
Query OK, 0 rows affected (0.050 sec)
obclient [test]> insert into `table` values(123);
Query OK, 1 row affected (0.007 sec)
obclient [test]> select ```` from `table`;
+------+
| ` |
+------+
| 123 |
+------+
1 row in set (0.000 sec)
This section does not describe how to rename an object because it is a simple operation.
Tenant Usage Specifications
In OceanBase Database, each tenant is similar to a MySQL instance. For more information, see Tenants.
You are not allowed to store data in the sys tenant. To store data, you must create a user tenant.
The sys tenant is designed to store the metadata of user tenants and does not provide database services. Misuse of the sys tenant may cause serious impact.
Database Usage Specifications
You are not allowed to store user data in built-in metadatabases such as information_schema and oceanbase. Misuse of the metadatabases may cause serious impact.
obclient [test]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| obproxy |
| oceanbase |
| test |
+--------------------+
5 rows in set (0.007 sec)
Table Design Specifications
To build a table with smaller redundancy and a more reasonable schema, you must follow specific rules when you design a database. In a relational database, these rules are called paradigms. You need to understand three paradigms for database design.
-
Consider business performance in table schema design based on the aforementioned three paradigms. Design data redundancy in storage to reduce table associations and improve business performance. A redundant column cannot be:
-
A column subject to frequent modifications
-
An excessively long column of the string type
-
-
Specify a primary key when you create a table.
-
We recommend that you use a business column rather than an auto-increment column as the primary key or federated primary key.
-
Tables in OceanBase Database are index-organized tables (IOTs). If you do not specify a primary key for a table, the system automatically generates a hidden primary key for the table.
-
-
We recommend that you specify the
COMMENTattribute for tables and columns. -
To ensure that columns do not contain null values, we recommend that you explicitly specify the
NOT NULLattribute for the columns. -
We recommend that you specify default values for columns in a table by using the
DEFAULTclause as needed. -
Try to ensure that the same column in different tables has the same definition. This prevents implicit data type conversions during computation.
-
The columns to be joined must be of the same data type. This prevents implicit data type conversions during computation. Attention should also be given to auxiliary attributes of the data type, such as collation, precision, and scale. Differences in these attributes may cause issues such as invalid indexes and non-optimal execution plans.
Column Design Specifications
-
We recommend that you create an auto-increment column of the BIGINT type. If the column is of the INT type, the maximum value of the column can be easily reached.
-
We recommend that you specify a proper length for strings and a suitable precision and scale for numbers based on your business requirements. This saves storage space and improves query performance.
-
When comparing columns of different types, the system performs implicit data type conversions. Based on the general implicit conversion order defined in SQL, a string is first converted to a number and then to a time. To clarify the requirements for data type conversions and use indexes for accelerating queries, we recommend that you use the CAST or CONVERT function to explicitly convert data types before column comparison.
Partition Design Specifications
The advantage of a distributed database is that large tables can be split and stored on multiple nodes so that requests can be distributed to multiple nodes for processing. Access requests to a partition are processed by the node on which the partition resides. As high-concurrency SQL requests access different partitions, the requests are processed by different nodes, and the total queries per second (QPS) of all nodes can be quite tremendous. In this case, you can add more nodes to improve the QPS for processing SQL requests. This is the best case in using a distributed database.
The goal of partitioning is to evenly distribute large amounts of data and access requests to multiple nodes. This way, you can make full use of resources for parallel computing and eliminate overloads caused by frequent queries on hotspot data. You can also use the partition pruning feature to improve query efficiency. Theoretically, if each node processes data and requests evenly, 10 nodes can process 10 times the amount of a single node. However, if the table is unevenly partitioned, some nodes will process more data or requests than others, resulting in data skew, which may lead to uneven resource utilization and load among nodes. Intensively skewed data is also known as hotspot data. The straightforward method for preventing hotspot data is to randomly distribute data to different nodes. A problem is that all partitions must be scanned to find the desired data. Therefore, this method is infeasible. In practice, partitioning strategies are often defined based on specific rules.
You must plan partitions based on clear business query conditions and actual business scenarios. Do not partition a table arbitrarily. When you plan partitions, try to make sure that the data distributed to each partition is relatively equal in amount.
The three most common partitioning methods are as follows:
-
HASHpartitioning: This method is suitable when the partitioning column has a large number of distinct values (NDV) and it is difficult to clearly define ranges for partitioning. This method can evenly distribute data without specific rules to different partitions. However, this method does not support partition pruning for range queries. -
RANGEpartitioning: This method is suitable when ranges can be clearly defined based on the partitioning key. For example, you can use theRANGEpartitioning method to partition a large table that records bank statements based on the column that represents time. -
LISTpartitioning: This method is suitable when you want to explicitly distribute data to specific partitions. It can precisely distribute unordered or irrelevant data to specific partitions. However, it does not support partition pruning for range queries.
To support parallel computing and partition pruning, OceanBase Database supports subpartitioning. OceanBase Database in MySQL mode supports the HASH, RANGE, LIST, KEY, RANGE COLUMNS, and LIST COLUMNS partitioning methods, and a combination of any two partitioning methods as the subpartitioning method.
For example, the database needs to partition a bill table based on the user_id column by using the HASH partitioning method, and then subpartition each partition based on the bill creation time by using the RANGE partitioning method.
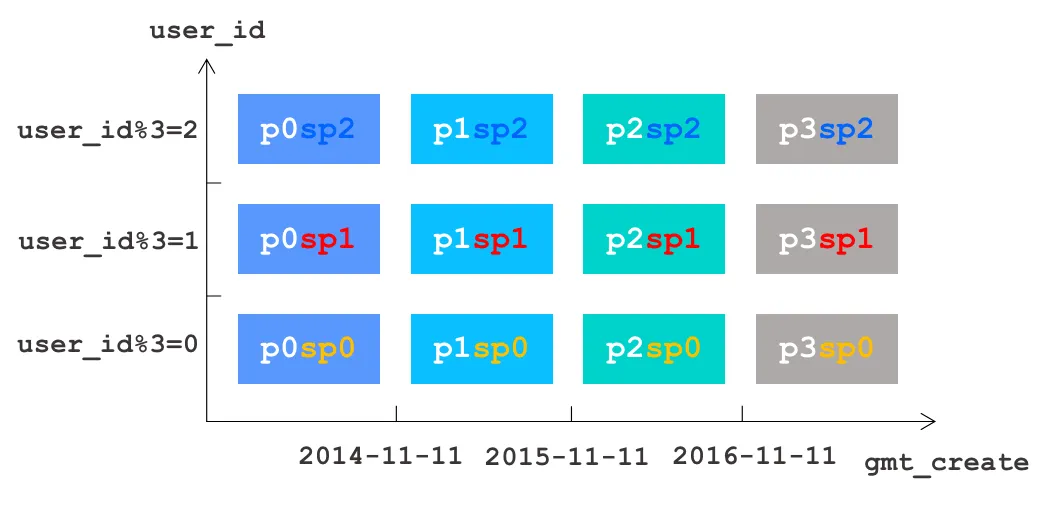
OceanBase Database supports RANGE-HASH and HASH-RANGE composite partitioning. However, ADD and DROP operations can be performed on a RANGE partition only when the table is first partitioned by using the RANGE partitioning method. Therefore, for large tables, we recommend that you use RANGE-HASH partitioning to facilitate maintenance such as partition addition and dropping.
References
-
For more information about partitions, see Create and manage partitions.
-
If data is not evenly distributed to partitions in a partitioned table, query performance may be compromised due to data skew. We recommend that you use the SQL plan monitor tool of OceanBase Database to check whether query performance is compromised due to data skew. For more information about how to use the tool, see the "Collect sql_plan_monitor" section in Use obdiag to Collect Information and Diagnose Issues.
Index Design Specifications
Index creation rules
For more information about the index creation rules, see the "Index tuning" section in Common SQL tuning methods.
Global indexes and their application scenarios
In MySQL tenants of OceanBase Database, indexes are divided into two types: local indexes and global indexes.
The difference between the two is that a local index uses the same partitioning method as the primary table, whereas a global index can use a partitioning method different from that of the primary table. If the index type is not explicitly specified within a MySQL tenant, a local index is created by default.
A global index can be recognized as an extended feature of MySQL. For more information, see the "Global index" section in Extended features of a MySQL tenant of OceanBase Database.
Index design suggestions
-
Read the preceding "Index creation rules" and "Global indexes and their application scenarios" sections before you continue.
-
Do not use global indexes unless necessary. To use global indexes, you must understand the application scenarios of global indexes.
- The cost of table access by index primary key for a global index-based query is high, approximately ten times that for a local index-based query.
- The costs of creating, dropping, and modifying global indexes are high, which compromises DML performance.
- When you create a global index, we recommend that you specify a partitioning method. Otherwise, the global index is not partitioned by default. Select a column with a larger NDV as the partitioning key for the global partitioned index.
-
When you perform multi-table join queries, the joined columns must be indexed. This can improve join performance. Try to ensure that the data types of the joined columns are the same. This prevents implicit data type conversions, allowing indexes to be used.
-
You can create a covering index to avoid table access by index primary key. Try to ensure that redundant columns covered by an index are not of large object (LOB) data types.
-
If an index contains multiple columns, we recommend that you place the column with a larger NDV before others. For example, if the NDV of column
bis larger than that of columnaand the filter condition isWHERE a= ? AND b= ?, you can create theidx(b,a)index. -
For the filter condition
WHERE a= ? AND b= ?, we recommend that you use the composite indexidx_ab(a,b)instead of creating indexesidx_a(a)on columnaandidx_b(b)on columnb. This is because the indexes created respectively on columnsaandbcannot be used at the same time.
Index usage suggestions
To modify an index, create a new one, ensure that the new index has taken effect, and drop the old index once it is confirmed that it is no longer needed.
By the way, this suggestion is somewhat like advising students to bring their exam admission tickets when taking the exam. Simple as it may seem, the suggestion is necessary. In Ant Group, there are always a few database administrators (DBAs) who drop old indexes before new ones take effect every year. As a result, certain services of Alipay become unavailable, leading to significant losses. Finally, we have to penalize the DBAs to calm public anger.
We hope that you strictly follow this suggestion. Otherwise, a great impact may be caused.
Auto-increment Column Design Specifications
For more information, see the "Sequences" section in Extended features of a MySQL tenant of OceanBase Database.
- Read the aforementioned "Sequences" section before you continue.
- To be compatible with MySQL databases, an auto-increment column is created in ORDER mode by default.
- If the sequence values do not need to be incremental but must be unique, we recommend that you set the increment mode to NOORDER. This improves performance.
- To avoid value hopping in NOORDER mode while applying for auto-increment values from different nodes in distributed scenarios, set the increment mode of the auto-increment column to ORDER.
Recycle Bin Design Specifications
For more information, see the "Recycle bin" section in Extended features of a MySQL tenant of OceanBase Database.
- Read the aforementioned "Recycle bin" section before you continue.
- While it seems easy to perform FLASHBACK or PURGE operations on tables in the recycle bin by their original names specified by the
ORIGINAL_NAMEparameter, we recommend that you use their unique new names specified by theOBJECT_NAMEparameter to avoid losses due to your misremembering of the operation rules.
Table Group Design Specifications
This section describes the table group feature because it is an extended feature that is not supported by MySQL.
For more information, see the "Table groups" section in Extended features of a MySQL tenant of OceanBase Database.