MiniOB 介绍
MiniOB 是 OceanBase 团队基于华中科技大学数据库课程原型,联合多所高校重新开发的、专为零基础的同学设计的数据库入门学习项目。我们的目标是为在校学生、数据库从业者、爱好者或对基础技术感兴趣的人提供一个友好的数据库学习项目。
MiniOB 整体代码简洁,容易上手,设计了一系列由浅入深的题目,帮助同学们从零基础入门,迅速了解数据库并深入学习数据库内核。MiniOB 简化了许多模块,例如不考虑并发操作、安全特性和复杂的事务管理等功能,以便更好地学习数据库实现原理。我们期望通过 MiniOB 的训练,同学们能够熟练掌握数据库内核模块的功能和协同关系,并具备一定的工程编码能力,例如内存管理、网络通信和磁盘 I/O 处理等, 这将有助于同学在未来的面试和工作中脱颖而出。
文档
MiniOB 提供了丰富的设计文档和代码注释。如果在阅读代码过程中遇到不容易理解的内容,并且没有相关的文档或文档描述不清晰,欢迎提出 issue,我们会尽快完善文档。
快速上手
为了帮助开发者更好地上手并学习 MiniOB,建议阅读以下内容:
为了帮助大家更好地学习数据库基础知识,OceanBase社区提供了一系列教程。更多文档请参考 MiniOB GitHub Pages。建议学习:
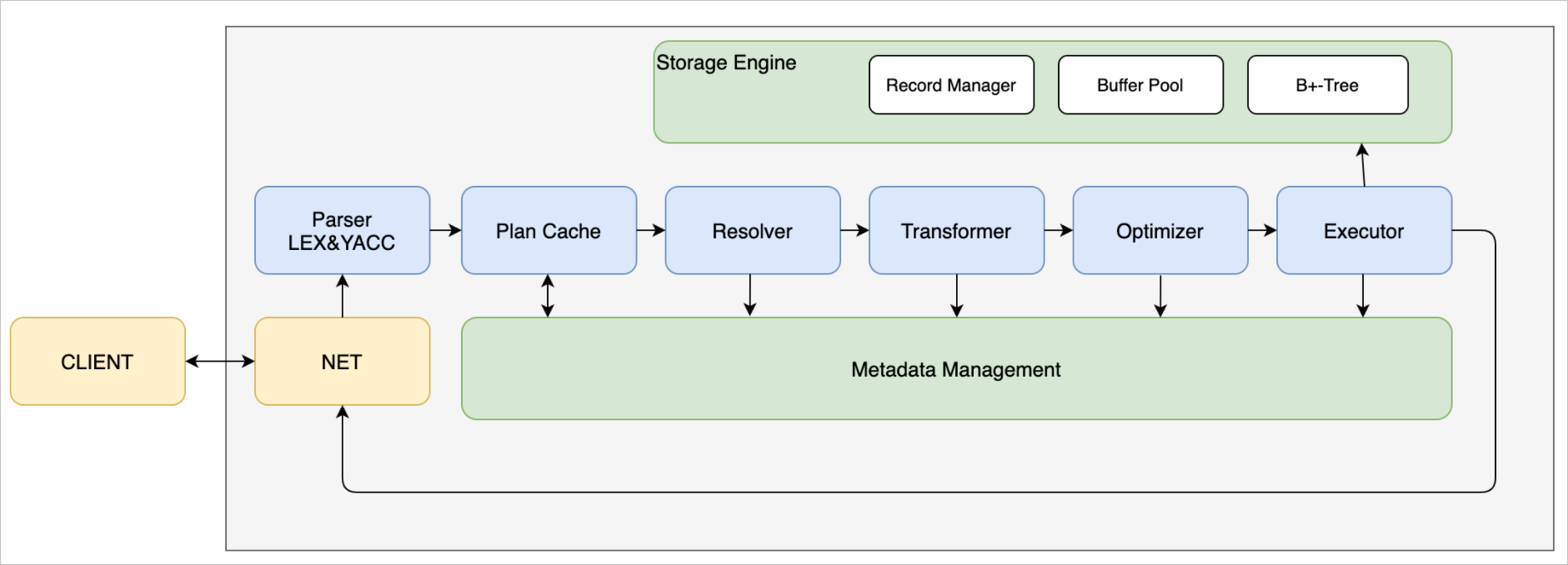
系统架构

其中:
- 网络模块(NET Service):负责与客户端交互,收发客户端请求与应答;
- SQL解析(Parser):将用户输入的SQL语句解析成语法树;
- 语义解析模块(Resolver):将生成的语法树,转换成数据库内部数据结构;
- 查询优化(Optimizer):根据一定规则和统计数据,调整/重写语法树。(部分实现);
- 计划执行(Executor):根据语法树描述,执行并生成结果;
- 存储引擎(Storage Engine):负责数据的存储和检索;
- 事务管理(MVCC):管理事务的提交、回滚、隔离级别等。当前事务管理仅实现了MVCC模式,因此直接以MVCC展示;
- 日志管理(Redo Log):负责记录数据库操作日志;
- 记录管理(Record Manager):负责管理某个表数据文件中的记录存放;
- B+ Tree:表索引存储结构;
- 会话管理:管理用户连接、调整某个连接的参数;
- 元数据管理(Meta Data):记录当前的数据库、表、字段和索引元数据信息;
- 客户端(Client):作为测试工具,接收用户请求,向服务端发起请求。
OceanBase 大赛
全国大学生计算机系统能力大赛(以下简称“大赛”)是由系统能力培养研究专家组发起,全国高等学校计算机教育研究会、系统能力培养研究项目示范高校共同主办、OceanBase 承办,面向高校大学生的全国性数据库大赛。 大赛面向全国爱好数据库的高校学生,以“竞技、交流、成长”为宗旨,搭建基于赛事的技术交流平台,促进高校创新人才培养机制,不仅帮助学生从0开始系统化学习 OceanBase 数据库理论知识,提升学生数据库实践能力,更能帮助学生走向企业积累经验,促进国内数据库人才的发展,碰撞出创新的火花。
OceanBase 初赛基于一套适合初学者实践的数据库实训平台 MiniOB,代码量少,易于上手学习,包含了数据库的各个关键模块,是一个系统性的数据库学习平台。基于该平台设置了一系列由浅入深的题目,以帮助同学们更好"零"基础入门。
为了帮助大家能在大赛中取得好成绩,我们提供了一系列的教程和指导,帮助大家更好地学习数据库基础知识,更好地完成大赛题目。 欢迎大家查看《从0到1数据库内核实战教程》 视频教程,视频中包含了代码框架的介绍和一些入门题目的讲解。
由于MiniOB是一个持续演进的产品,视频教程中有些内容会与最新代码有冲突,建议大家参考讲解中的思路。
大赛的初赛是在MiniOB上进行的,同学们可以在前几届的题目上进行提前训练,可以让自己比别人提前一步。大家在日常训练时可以在MiniOB 训练营 上提交代码进行测试。
在提交前, 请参考并学习 训练营使用说明。
如果大家在大赛中或使用训练营时遇到一些问题,请先查看大赛 FAQ。
如何编译
0. base
假设系统上已经安装了make等编译工具。
MiniOB 需要使用:
- cmake 版本 >= 3.13
- gcc/clang gcc建议8.3以上,编译器需要支持c++20新标准
- flex (2.5+), bison (3.7+) 用于生成词法语法分析代码
1. 环境初始化
如果是第一次在这个环境上编译miniob,需要安装一些miniob的依赖库,执行下面的命令即可安装:
bash build.sh init
脚本将自动拉取依赖库(可以参考 .gitmodules) 然后编译安装到系统目录。
如果执行用户不是root,需要在命令前加上 sudo:
sudo bash build.sh init
如果使用 GitPod 开发,可以跳过这步,会自动执行。
2. 编译
执行下面的命令即可完成编译:
bash build.sh
此命令将编译一个DEBUG版本的miniob。如果希望编译其它版本的,可以参考 bash build.sh -h,比如:
bash build.sh release
此命令将编译release版本的miniob。
3. 运行
参考 如何运行
FAQ
1. sudo找不到cmake
Q:
在“1. 环境初始化”中执行命令:
sudo bash build.sh init
时,报错:
build.sh: line xx: cmake: command not found
A:
1. 检查“0. base”中cmake版本要求是否满足。
cmake --version
2. 检查是否出现了“Linux系统下执行sudo命令环境变量失效现象”。
检查
在当前用户和root用户下均能找到cmake,而在当前用户下sudo cmake却找不到cmake,即:
[mu@vm-cnt8:~]$ sudo -E cmake --version
[sudo] password for mu:
sudo: cmake: command not found
则可能就出现了“Linux系统下执行sudo命令环境变量失效现象”,本例中具体是PATH环境变量实效(被重置),导致找不到cmake。
解决方法:建立软链接
- 找到执行sudo命令时的PATH变量中有哪些路径:
[mu@vm-cnt8:~]$ sudo env | grep PATH
PATH=/sbin:/bin:/usr/sbin:/usr/bin
- 找到cmake所在的路径:
[mu@vm-cnt8:~]$ whereis cmake
cmake: /usr/local/bin/cmake /usr/share/cmake
- 在PATH变量中的一个合适路径下建立指向cmake的软链接:
[root@vm-cnt8:~]# ls /usr/bin | grep cmake
[root@vm-cnt8:~]# ln -s /usr/local/bin/cmake /usr/bin/cmake
[root@vm-cnt8:~]# ll /usr/bin | grep cmake
lrwxrwxrwx. 1 root root 20 Sep 1 05:57 cmake -> /usr/local/bin/cmake
验证
$ sudo -E cmake --version
cmake version 3.27.4
发现sudo时能找到cmake了,此时再执行
sudo bash build.sh init
则不会因为找不到cmake而报错。
更多信息:
关于该问题的更多细节,请参考问题来源。 关于该问题的进一步分析,请参考Linux系统下执行sudo命令环境变量失效现象。 也可以将cmake所在路径添加到sudo的PATH变量中来解决上述问题,请参考sudo命令下环境变量实效的解决方法。
如何运行
编译完成后,可以在build目录(可能是build_debug或build_release)下找到bin/observer,就是我们的服务端程序,bin/obclient是自带的客户端程序。 当前服务端程序启动已经支持了多种模式,可以以TCP、unix socket方式启动,这时需要启动客户端以发起命令。observer还支持直接执行命令的模式,这时不需要启动客户端,直接在命令行输入命令即可。
以直接执行命令的方式启动服务端程序
./bin/observer -f ../etc/observer.ini -P cli
这会以直接执行命令的方式启动服务端程序,可以直接输入命令,不需要客户端。所有的请求都会以单线程的方式运行,配置项中的线程数不再有实际意义。
以监听TCP端口的方式启动服务端程序
./bin/observer -f ../etc/observer.ini -p 6789
这会以监听6789端口的方式启动服务端程序。 启动客户端程序:
./bin/obclient -p 6789
这会连接到服务端的6789端口。
以监听unix socket的方式启动服务端程序
./bin/observer -f ../etc/observer.ini -s miniob.sock
这会以监听unix socket的方式启动服务端程序。 启动客户端程序:
./bin/obclient -s miniob.sock
这会连接到服务端的miniob.sock文件。
并发模式
默认情况下,编译出的程序是不支持并发的。如果需要支持并发,需要在编译时增加选项 -DCONCURRENCY=ON:
cmake -DCONCURRENCY=ON ..
或者
bash build.sh -DCONCURRENCY=ON
然后使用上面的命令启动服务端程序,就可以支持并发了。
启动参数介绍
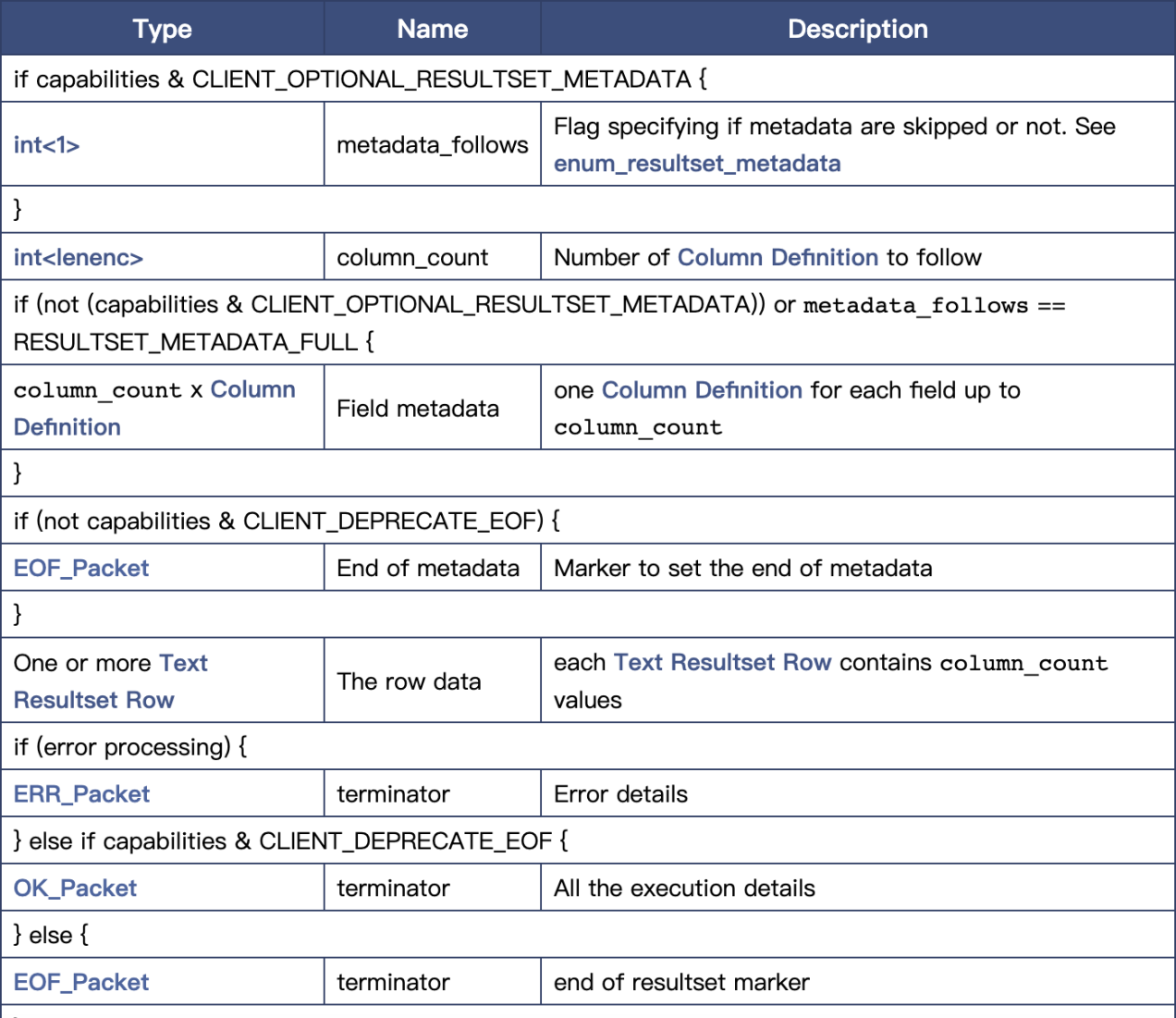
| 参数 | 说明 |
|---|---|
| -h | 帮助说明 |
| -f | 配置文件路径。如果不指定,就会使用默认值 ../etc/observer.ini。 |
| -p | 服务端监听的端口号。如果不指定,并且没有使用unix socket或cli的方式启动,就会使用配置文件中的值,或者使用默认值。 |
| -s | 服务端监听的unix socket文件。如果不指定,并且没有使用TCP或cli的方式启动,就会使用TCP的方式启动服务端。 |
| -P | 使用的通讯协议。当前支持文本协议(plain,也是默认值),MySQL协议(mysql),直接交互(cli)。 使用plain协议时,请使用自带的obclient连接服务端。 使用mysql协议时,使用mariadb或mysql客户端连接。 直接交互模式(cli)不需要使用客户端连接,因此无法开启多个连接。 |
| -t | 事务模型。没有事务(vacuous,默认值)和MVCC(mvcc)。 使用mvcc时一定要编译支持并发模式的代码。 |
| -T | 线程模型。一个连接一个线程(one-thread-per-connection,默认值)和一个线程池处理所有连接(java-thread-pool)。 |
| -n | buffer pool 的内存大小,单位字节。 |
更多
observer还提供了一些其它参数,可以通过./bin/observer -h查看。
FAQ
- 运行observer出现找不到链接库
A: 由于安装依赖时,默认安装在
/usr/local/目录下,而环境变量中没有将这个目录包含到动态链接库查找路径。可以将下面的命令添加到 HOME 目录的.bashrc中:
export LD_LIBRARY_PATH=/usr/local/lib64:$LD_LIBRARY_PATH
然后执行 source ~/.bashrc 加载环境变量后重新启动程序。
LD_LIBRARY_PATH 是Linux环境中,运行时查找动态链接库的路径,路径之间以冒号':'分隔。
将数据写入 bashrc 或其它文件,可以在下次启动程序时,会自动加载,而不需要再次执行 source 命令加载。
NOTE: 如果你的终端脚本使用的不是bash,而是zsh,那么就需要修改 .zshrc。
搭建开发环境
MiniOB 当前可以在Linux/MacOS上编译,所以开发环境最好是Linux或者MacOS。Windows上可以使用WSL2,或者使用Docker。这里有几个文档,大家可以参考并选择自己的开发环境。另外,很多同学喜欢使用visual studio code开发,MiniOB 中也将vscode的一些配置文件放在了仓库中,比如 .vscode/tasks.json 和 .vscode/launch.json,可以参考使用。
- 使用 GitPod 开发 MiniOB
- 开发环境搭建(本地调试, 适用 Linux 和 Mac)
- 开发环境搭建(远程调试, 适用于 Window, Linux 和 Mac)
- Windows 使用Docker开发MiniOB
- 手把手教你在windows上用docker和vscode配置环境
- 使用Docker开发MiniOB
- MiniOB 调试
MiniOB 是 OceanBase 联合华中科技大学推出的一款用于教学的小型数据库系统,希望能够帮助数据库爱好者系统性的学习数据库原理与实战。
本篇文章介绍如何使用 GitPod 开发 MiniOB。 也可以参考这篇文章了解如何使用 Visual Studio Code 来开发调试 MiniOB。
GitPod 简介
GitPod 是一个能让我们在任何地方都能方便开发自己代码的云平台。在开发时,GitPod会提供一个虚拟机一样的开发环境,开发平台是Linux,并且GitPod可以直接打开GitHub项目,支持很多IDE,比如Visual Studio Code、Clion、VIM等。

本篇文章将介绍如何在GitPod上使用Visual Studio Code(浏览器版)来开发MiniOB。
在 GitPod 上开发自己的 MiniOB
创建自己的GitHub项目
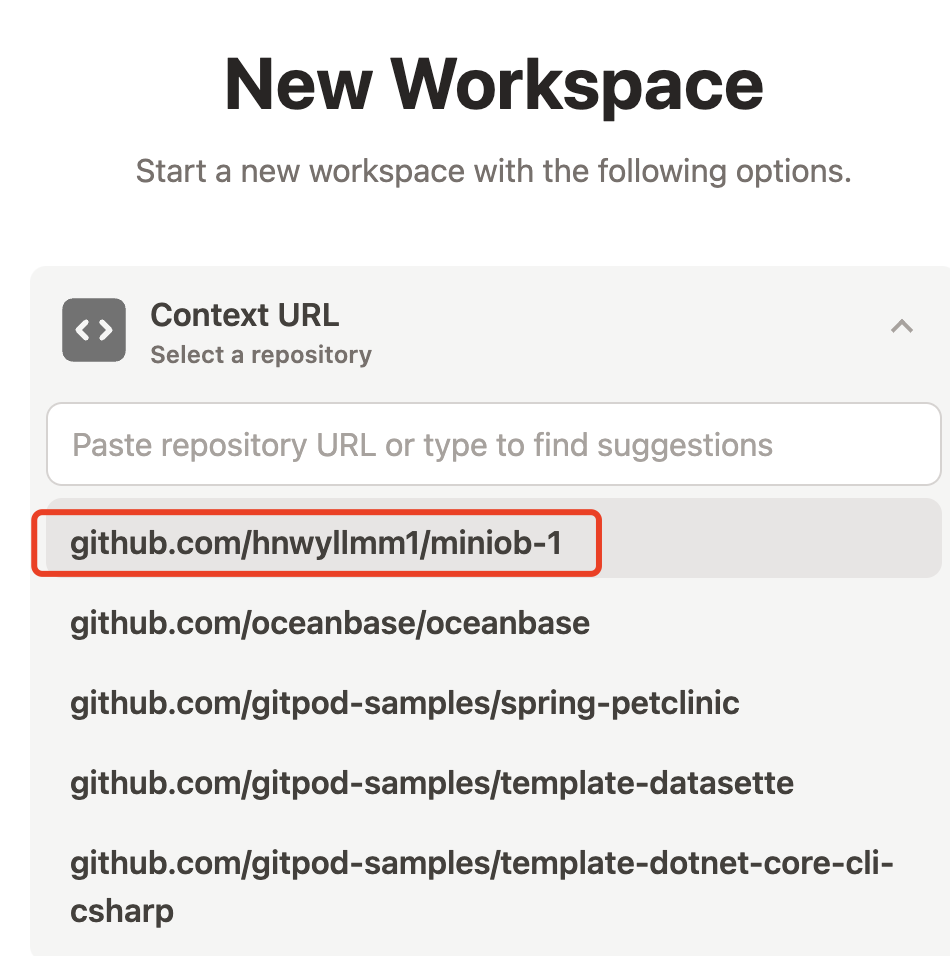
在开发MiniOB之前,应该先在GitHub上将MiniOB放在自己的私有仓库中。为了方便演示,我这里直接使用fork的方式,在自己的个人仓库中创建一个共有(public)仓库。
在浏览器中打开 MiniOB 然后fork仓库
fork后就会在自己的个人名下有一个miniob仓库代码
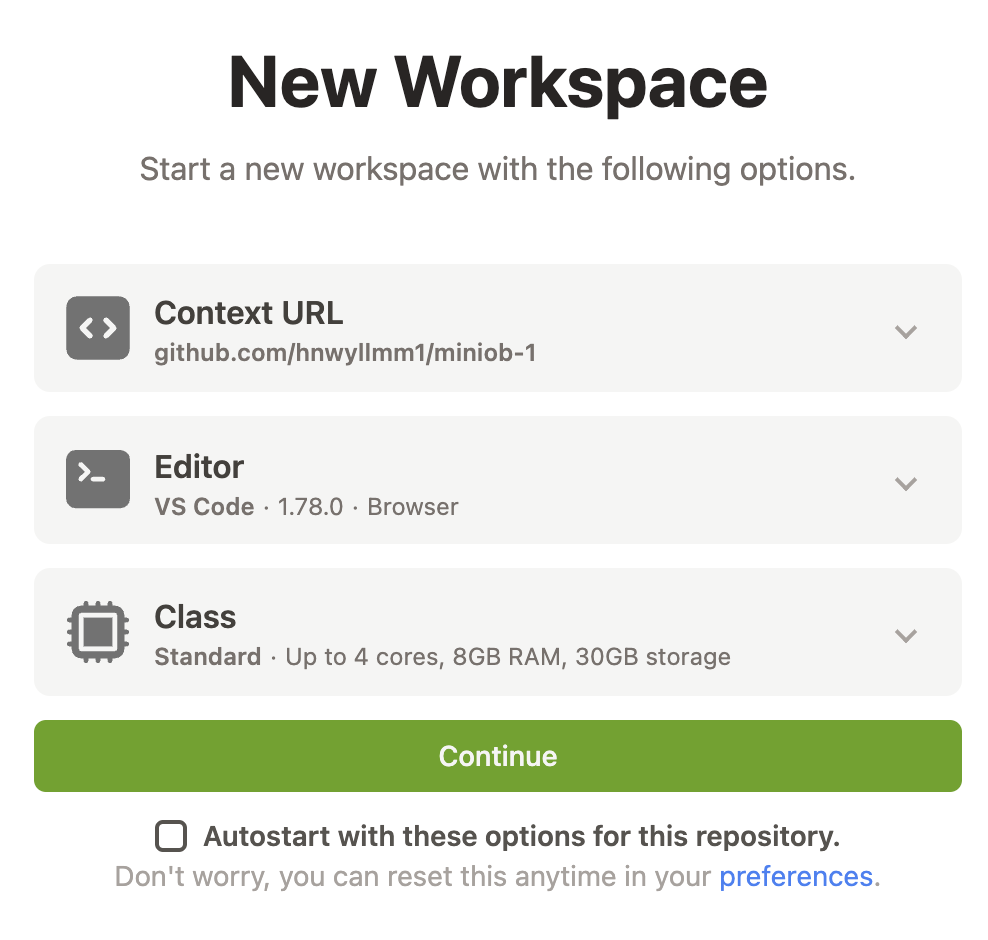
在 GitPod 上打开自己的项目
使用 GitPod 打开自己的项目
如果是第一次使用,需要输入一些额外的信息,按照GitPod的引导来走就行,最终会引导你打开你的项目。
这里选择自己的代码项目,并且使用vscode浏览器版本,容器规格也选择最小的(最小的规格对miniob来说已经非常充足)
如果以前已经操作过上面的步骤,可以直接从gitpod的首页找到自己的项目。

代码构建
环境初始化
因为MiniOB当前已经将.vscode文件加入到项目中,所以可以直接使用当前已有的一些命令(task)来构建代码。
如果是一个全新的机器环境,那么先要运行 init 任务。init 任务会在当前的机器上安装一些依赖,比如 google test、libevent等。
NOTE: gitpod 项目启动时,就会自动运行初始化。如果没有运行,可以手动执行一下。可以参考 .gitpod.yml 文件
编译miniob
初始化完成,可以运行 Build 任务,即可构建。
这些构建方法,也可以通过命令行的方式手动执行。
所有的任务都可以从这里找到入口。
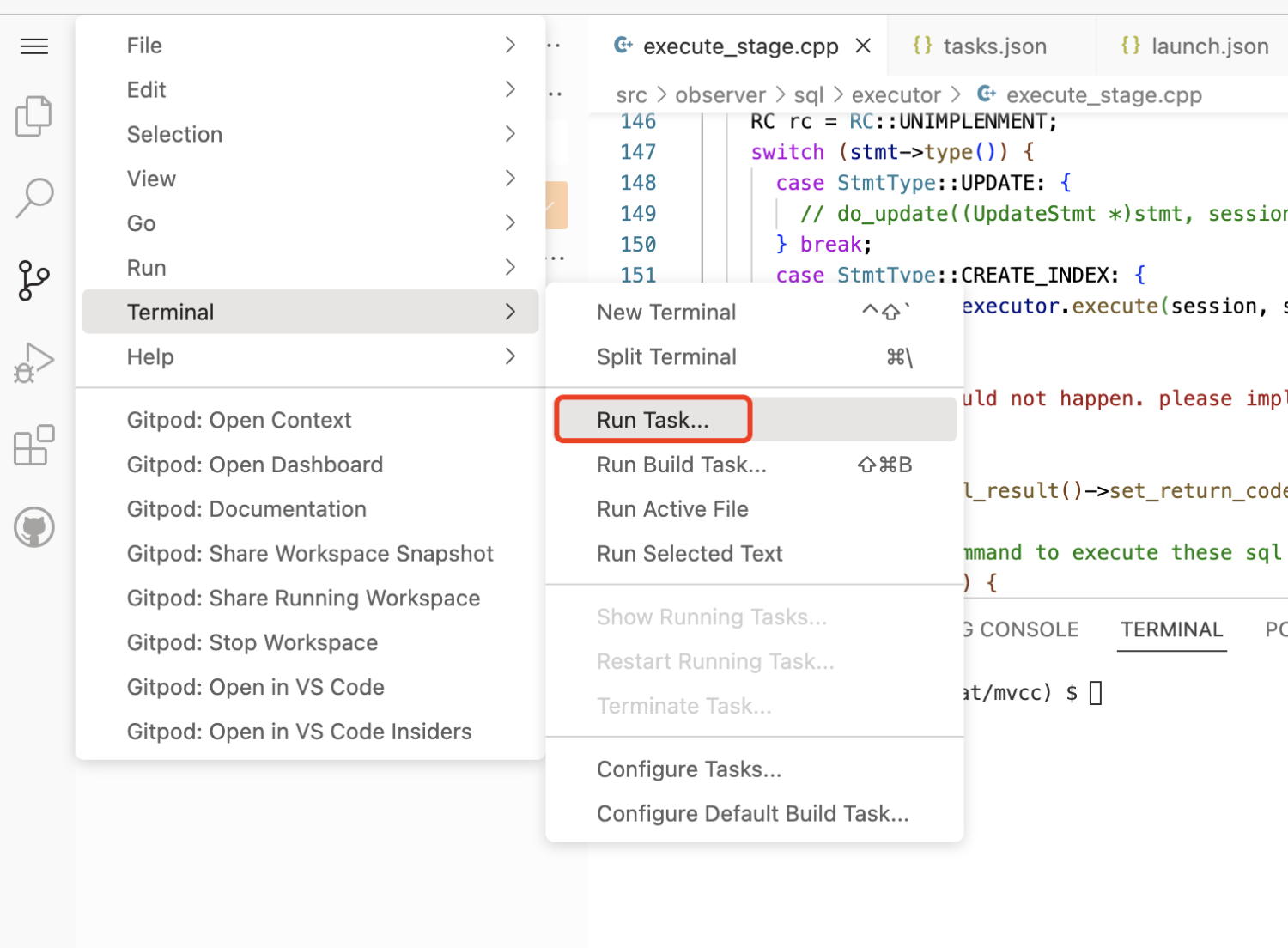
运行 init 命令的入口。
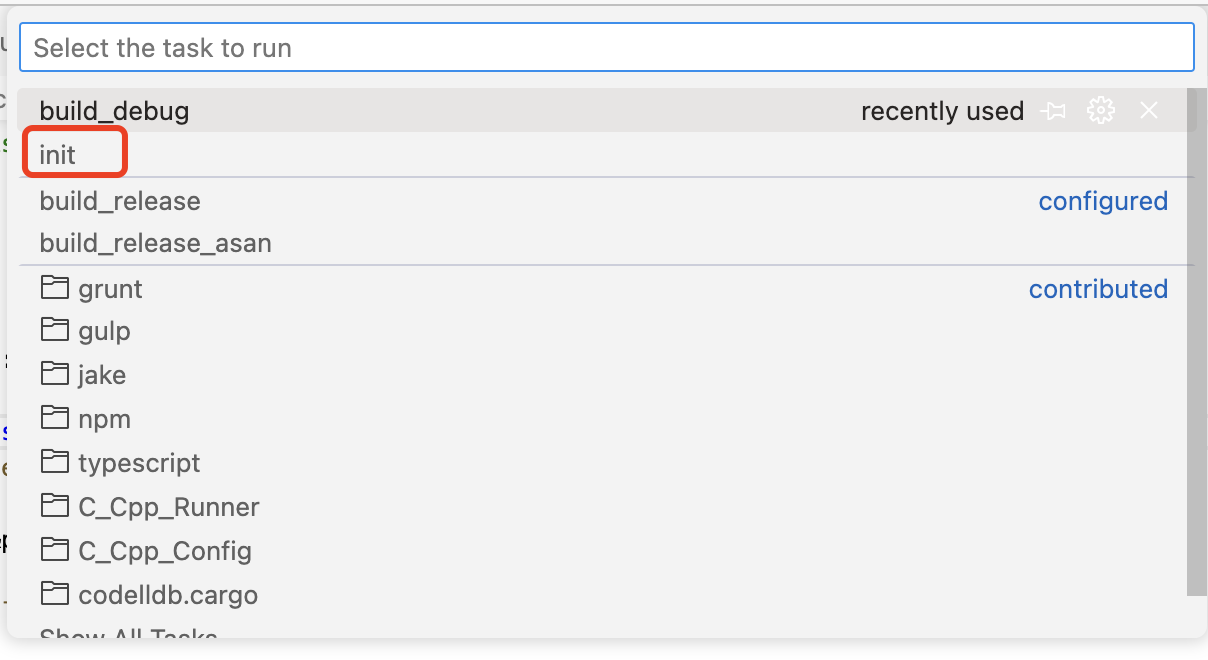
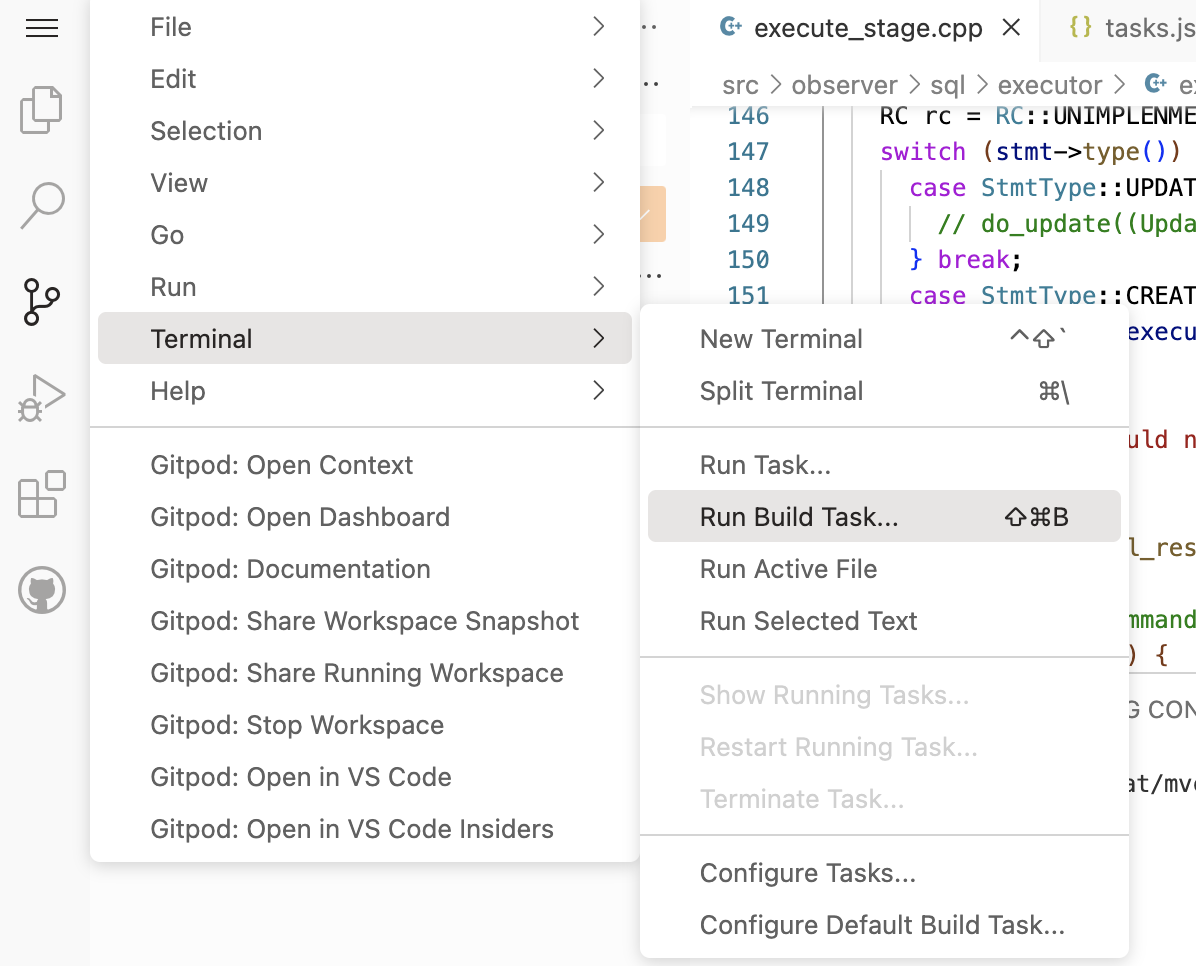
运行构建(编译)的入口。需要设置默认构建的任务,vscode才能运行。这里已经设置过了。
构建(编译)时,会有一些输出,如果有编译错误,也可以直接使用鼠标点击跳转到错误的地方。
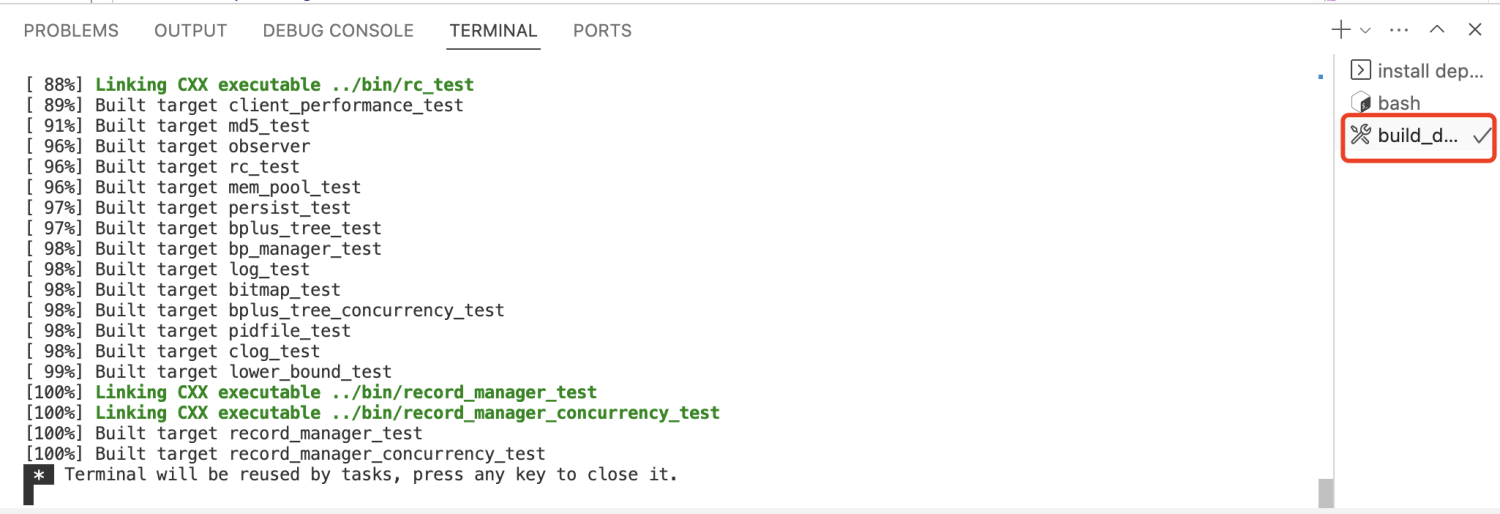
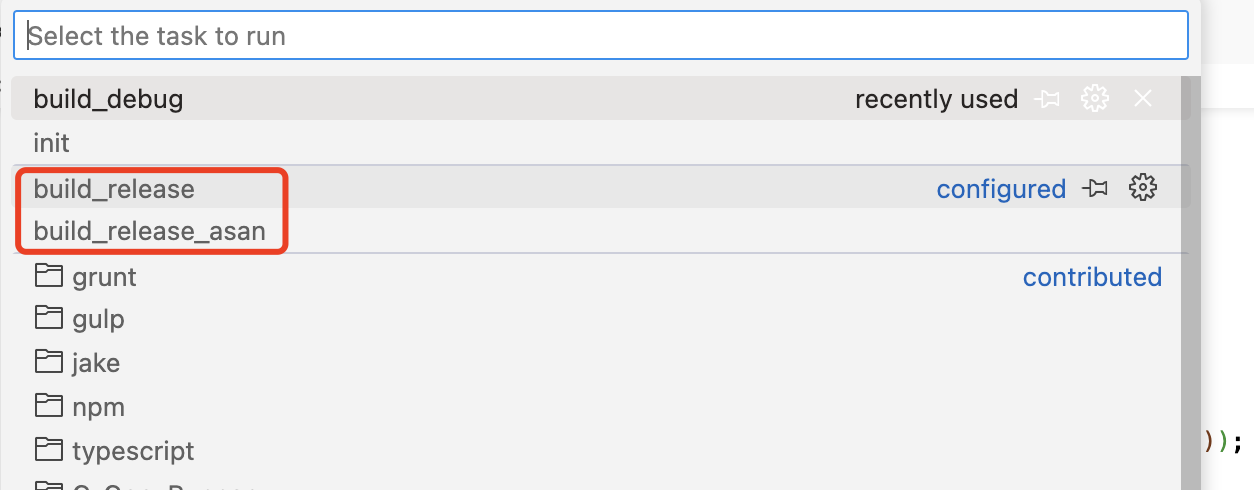
还可以构建其它模式。
WARNING: 不要在gitpod的终端上,执行 sh build.sh,而是执行 bash build.sh 或者直接运行 ./build.sh
miniob 虽然是cmake功能,可以使用vscode带的cmake配置,但是miniob在编译时,会使用一些变量来控制编译什么版本,比如是否编译UNITTEST,是否开启ASAN等。因此这里使用build.sh脚本来简化项目的编译命令。
代码调试
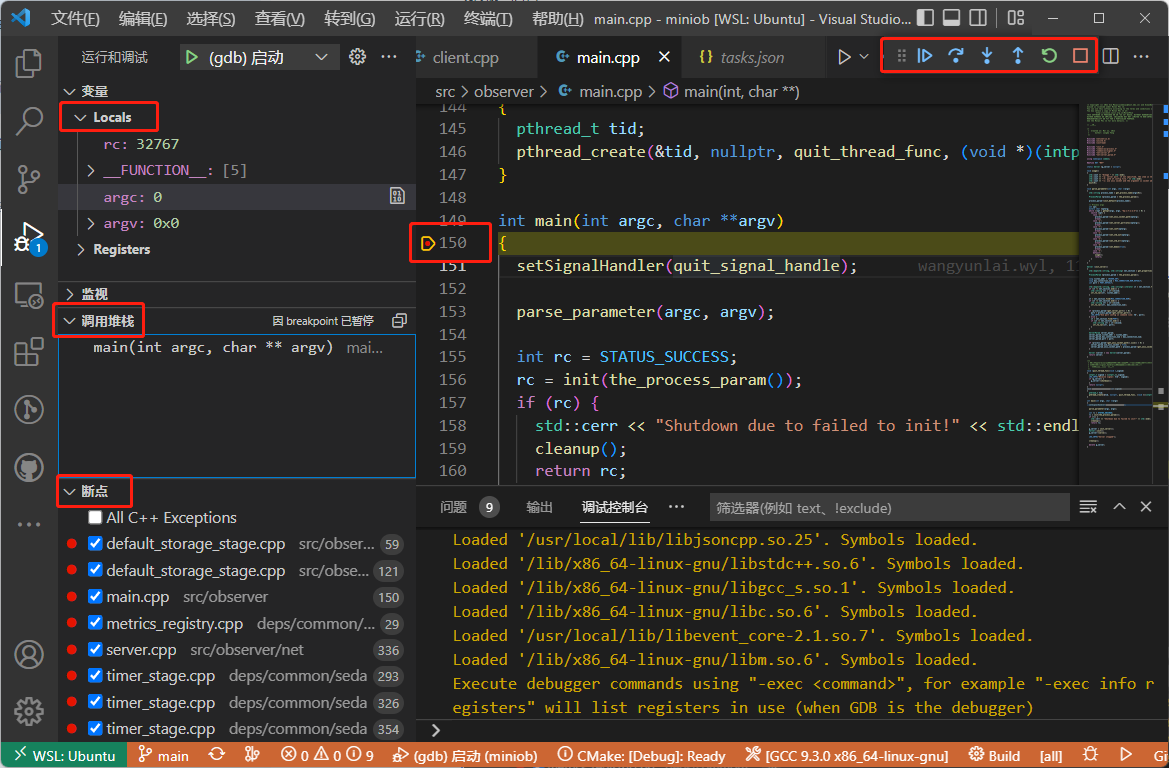
与代码构建类似,MiniOB 可以支持在vscode中直接启动调试程序。启动的调试程序为默认构建项目,当前是 debug 模式编译的miniob。 与普通的调试类似,可以自行设置断点。断点可以在运行程序之前也可以在其后。 启动调试服务端后,打开一个新的终端,来运行客户端,以便向服务端发起命令。
下断点
光标放到某一行,vscode编辑框的左边就会出现一个粉红色的圆点,点击圆点就可以下断点
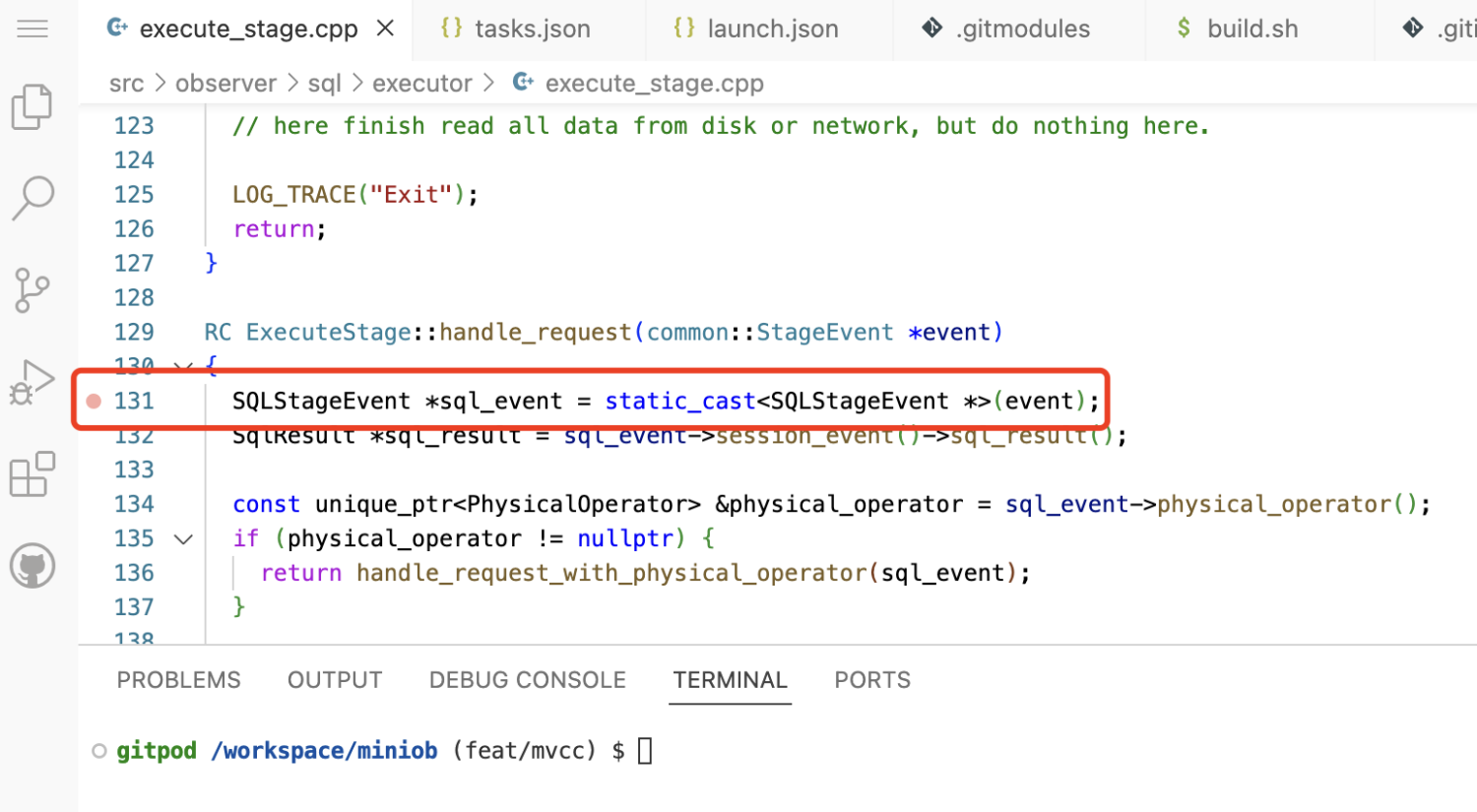
圆点变成红色,断点下成功了。
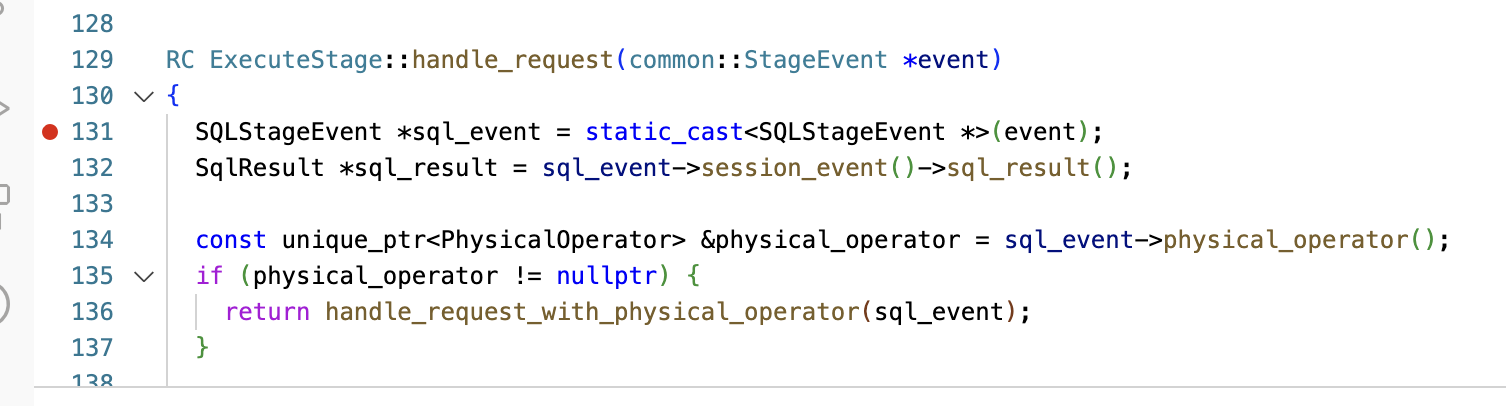
启动调试
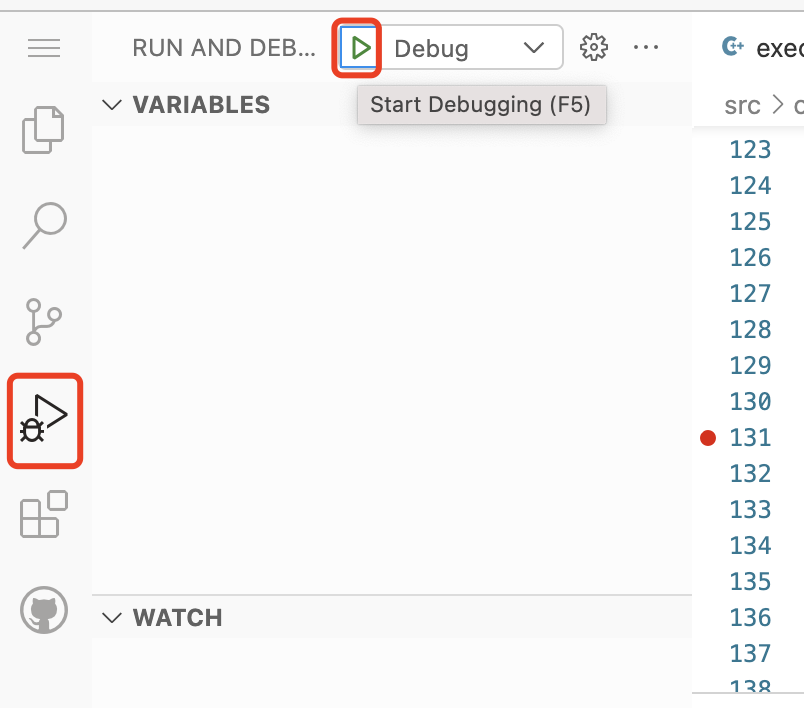

vscode 为调试进程也创建了一个终端,可以在这里看到observer运行期间在控制台上的输出。

调试时显示的界面。可以看到最上面中央处,有一个调试的界面,可以执行单步调试,或者跳转到函数内。这与普通的调试器界面类似。左边有一些变量的展示。
另外,我这里开了一个终端,运行客户端连接服务端发起命令请求。
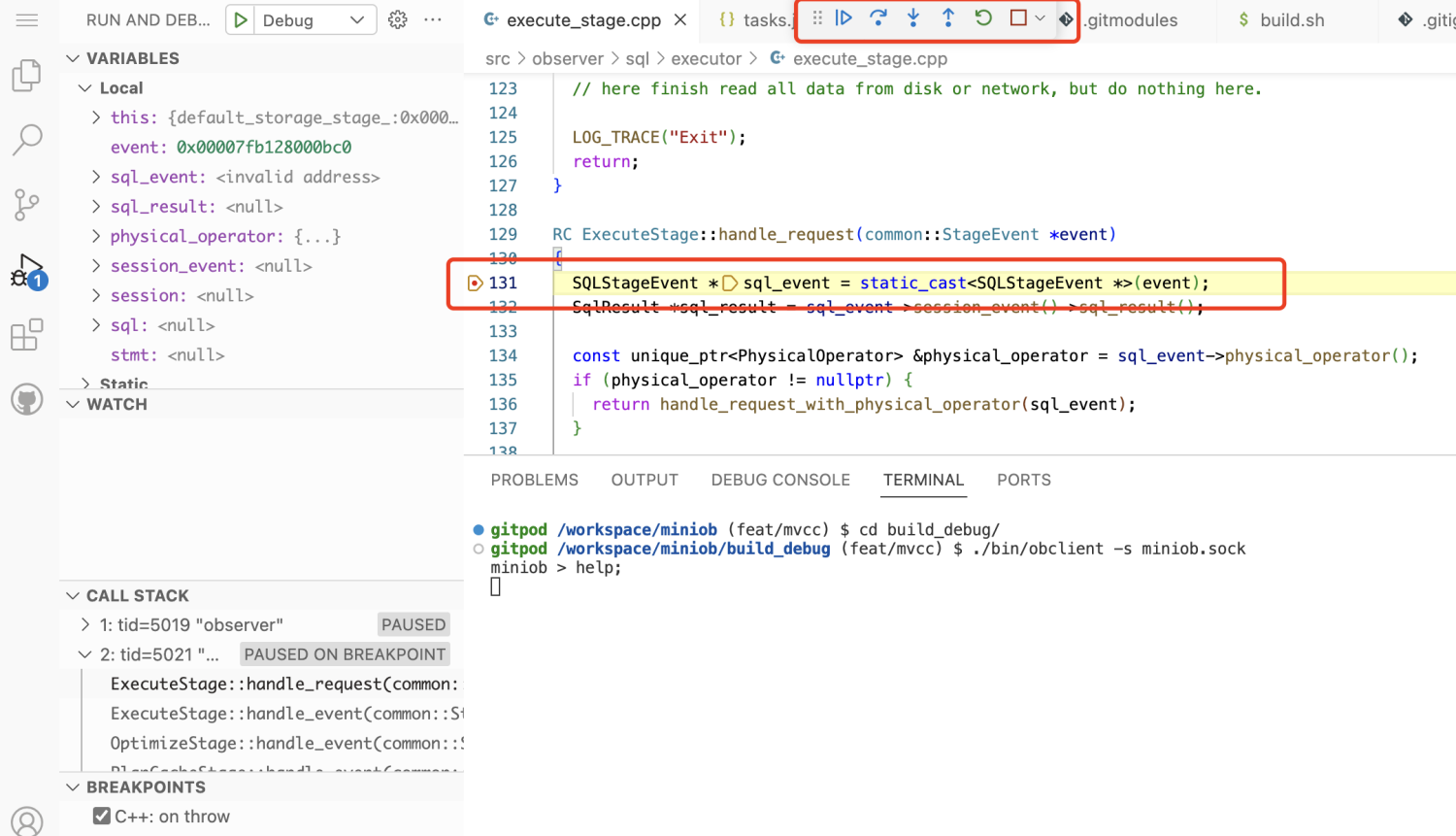
代码提交
作为一个GitHub项目,一个功能或者BUG开发完成后,需要将代码推送到远程仓库。vscode已经集成了GitHub和git插件,可以方便的进行操作。
完成一个功能,就提交一次。这里输入commit message后直接提交即可。
注意这里仅仅提交到了本地,如果要提交到GitHub(远程仓库),需要执行”推送“,即 git push。
Git的其它操作链接在这里
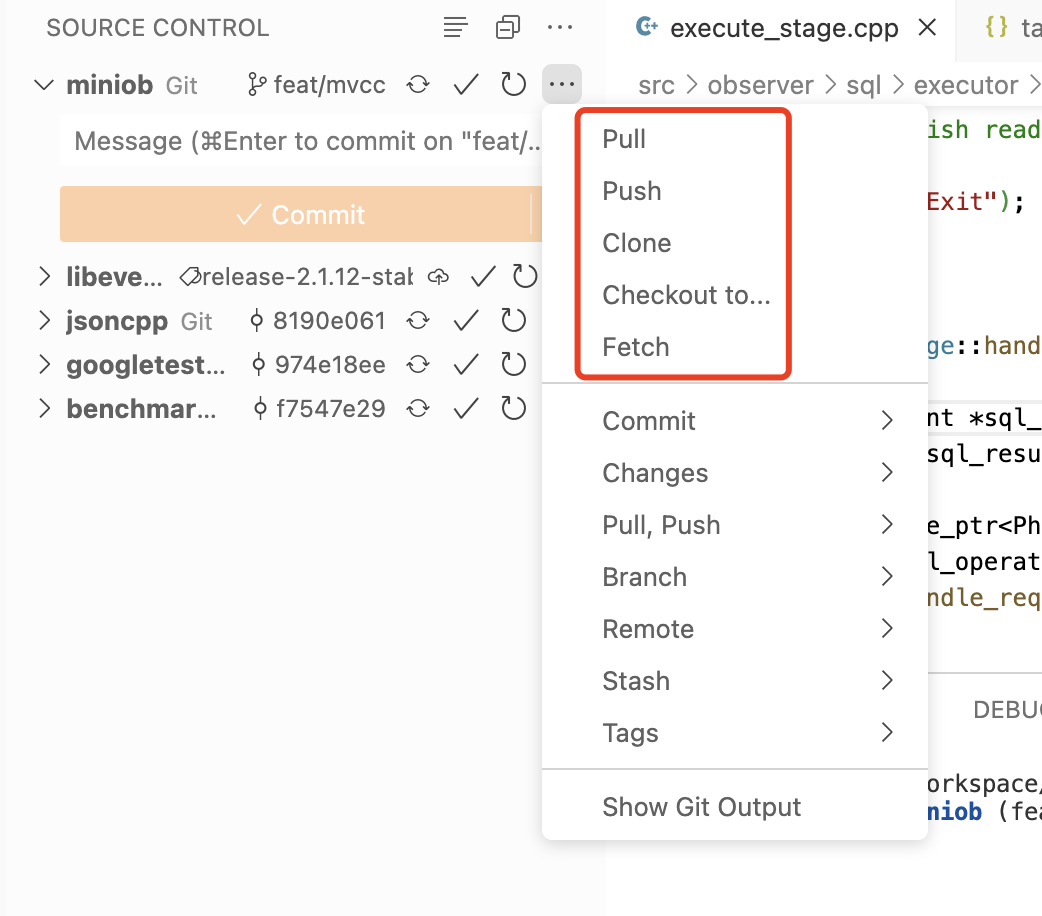
如果推送时出现这样的错误,可能是没有权限。gitpod 会自动提示然后跳转过去设置权限即可。
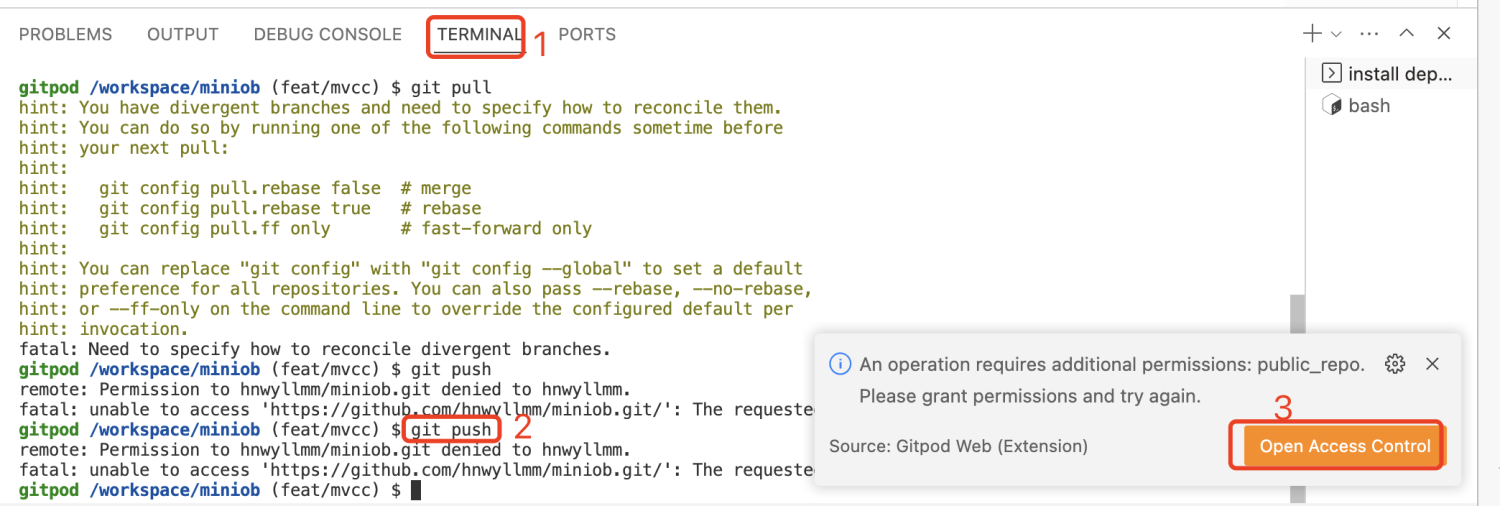
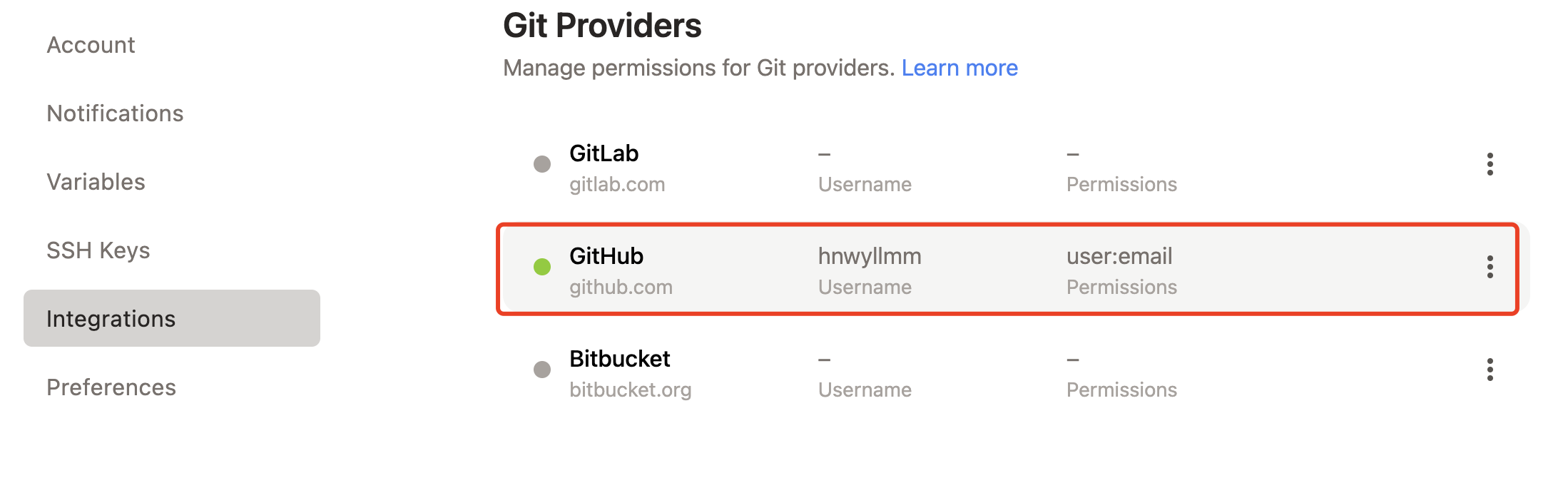
我这里就是没有写权限,所以无法推送到远程仓库。
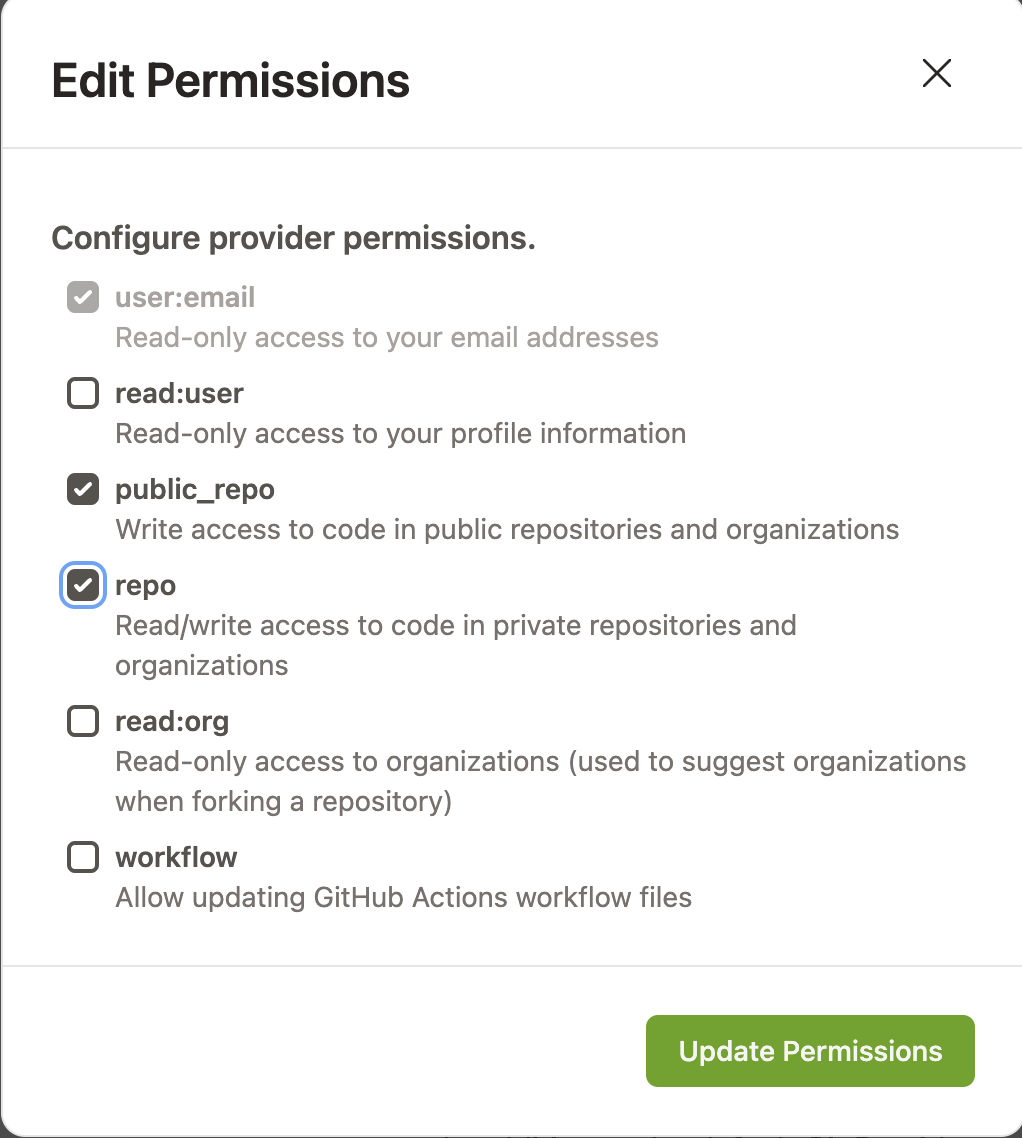
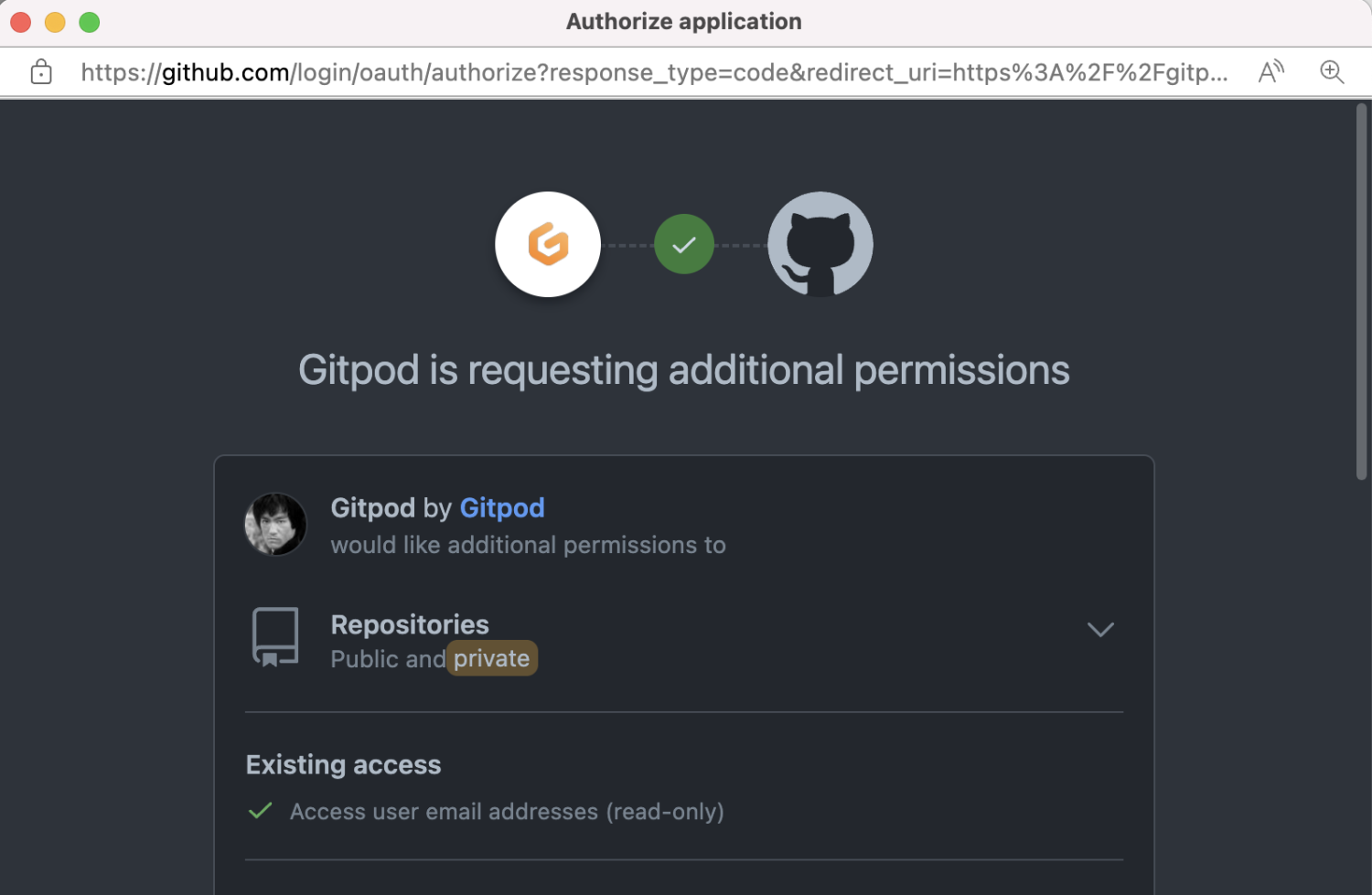
信息介绍
MiniOB 中的 tasks
vscode 可以非常方便的运行任务(task)来运行预配置的命令,比如shell。 miniob 的编译也可以通过脚本来执行(build.sh)。这里预配置了几个编译任务,可以按需自取,也可以按照需要,增加新的配置,运行自己的参数。
下面是一个 debug 模式编译的示例,也是vscode工程默认的Build配置。这里做个简单介绍,以方便大家有需要的时候,修改配置满足自己需要。 其中
label是一个任务名字,在Run task的时候,可以看到type表示任务的类型。这里是一个shell脚本command这里是一个shell脚本的话,那command就是运行的命令,跟我们在终端上执行是一样的效果problemMatcher告诉vscode如何定位问题。这里不用设置,vscode可以自动检测group使用vscode将此任务设置为默认Build任务时,vscode自己设置上来的,不需要调整。
{
"label": "build_debug",
"type": "shell",
"command": "bash build.sh debug",
"problemMatcher": [],
"group": {
"kind": "build",
"isDefault": true
}
}
MiniOB 中的 launch
很多同学不习惯使用gdb的终端界面来调试程序,那么在 vscode 中调试miniob非常方便,与Visual Studio、Clion中类似,都有一个操作界面。 vscode中启动调试程序是通过launch.json来配置的,这里简单介绍一下主要内容。
下面是截取的一段关键内容。这里介绍一些关键字段
type当前调试使用哪种类型。这里是lldb (我个人习惯了gdb,但是我没有找到,也不想找了)name这里会显示在vscode调试窗口启动时的名字中program要调试的程序。对miniob来说,我们通常都是调试服务端代码,这里就是observer的路径。workspaceFolder 是当前工程的路径,defaultBuildTask 是默认构建的任务名称,与我们的构建路径刚好一致。observer 是编译完成安装在构建路径的bin下。args启动程序时的命令行参数。在终端上,大家也可以这么启动observer: `./bin/observer -f ../etc/observer.ini -s miniob.sockcwdobserver 运行时的工作目录,就是在observer程序中获取当前路径时,就会是这个路径。
{
"type": "lldb",
"request": "launch",
"name": "Debug",
"program": "${workspaceFolder}/${defaultBuildTask}/bin/observer",
"args": ["-f", "${workspaceFolder}/etc/observer.ini", "-s", "miniob.sock"],
"cwd": "${workspaceFolder}/${defaultBuildTask}/"
}
注意,如果要调试 release 或者其它任务编译出来的observer,就需要调整这个文件,或者新增一个配置,因为这个配置文件指定的observer路径是默认的build。
环境准备
运行环境
- 操作系统
frank@DESKTOP-6NF3B9K:~/git/miniob$ cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.5 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.5 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
注:这里直接用的windows的WSL,
软件要求
- vscode
- cmake
- make
- gcc/g++
- libevent
- googletest
- jsoncpp
- git
获取代码
git clone https://github.com/oceanbase/miniob.git
安装软件
可以参考miniob/docs/how_to_build.md。
vscode配置
使用vscode打开miniob工程目录。
cd miniob
code .
安装插件
 |  |
|---|
配置编译tasks.json
在工程的.vscode目录下新建tasks.json
{
"options": {
"cwd": "${workspaceFolder}/build"
},
"tasks": [
{
"label": "cmake",
"command": "cmake",
"args": [
"-DDEBUG=ON",
".."
]
},
{
"label": "make",
"command": "make"
},
{
"label": "CMake Build",
"dependsOn": [
"cmake",
"make"
]
}
],
"version": "2.0.0"
}
注意:
- options:cmake临时文件的目录
- args:cmake需要的参数
配置调试launch.json
在工程的.vscode目录下新建launch.json
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) 启动",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/bin/observer",
"args": ["-f", "../../etc/observer.ini"],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "将反汇编风格设置为 Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
],
"preLaunchTask": "CMake Build"
}
]
}
注意:
- program:编译出来的可执行文件
- args:运行参数
- preLaunchTask:
"label": "CMake Build"对应
演示
- 重新使用vscode打开,打开后会自动运行tasks的cmake。
- 设置断点、启动调试
注意:启动是会触发make,对工程进行编译。因为是单线程编译,所以第一次惦记启动gdb时需要时间较长,后续如果没有修改源码的操作,则直接踢动gdb进行调试。如果想使用多线程编译可以在tasks.json中配置make参数。
{
"label": "make",
"command": "make",
"args": [
"-j",
"4"
]
},
args中配置相当于make -j 4
终端输出如下:

- 调试
注意:同种标记部分包括调试常用的功能,如:查看变量、调用栈、断点,以及n, s, finish, r等命令。
使用 Docker 和 VSCode 远程开发 Miniob
本文档阐述如何使用 Docker 构建一个具备 Miniob 开发环境的容器,并且通过 VSCode 的 Remote-SSH 插件 SSH 到容器中进行远程开发。Docker 和 VSCode 可以安装在不同机器上。
方法简单易行,仅需配置 2 个 环境变量(仓库 URL、SSH秘钥)及安装必要的 VSCode 开发插件即可。
- 使用 Docker 和 VSCode 远程开发 Miniob
安装 Docker 和 Docker-compose
Windows
参考本仓库文档 在 Windows 上使用 Docker 安装 Docker Desktop 即可。只需执行 安装 Docker 这一小节。
Linux
如果你选择在远程建议参考官方文档安装 Docker Engine 和 Docker Compose.
安装 VSCode
前往官网下载 Visual Studio Code,正常安装即可。
配置 Dockerfile
文件在 docker/Dockerfile.
配置 Root 密码
默认密码 root,可在 64 行自行修改。不需修改可跳过。
若镜像于服务器运行建议使用强密码,并在第一次登录后关闭密码登录,改用秘钥登录。
配置 Docker Compose
Fork 仓库
Fork 本仓库,复制 Fork 后仓库的 HTTPS 地址,如 https://github.com/oceanbase/miniob.git.
也可以不 Fork,用本仓库 Git HTTPS 地址,后续自行进行 git remote add.
下面配置镜像中的仓库 URL 及克隆方式。
修改 docker/docker-compose.yml 文件的最后两行。注意等号前后不要有空格。
Clone by SSH
REPO_ADDR 设置为 SSH URL, 如:git@github.com:oceanbase/miniob.git
Clone by HTTPS
私有仓库
如果 fork 出来的是私有仓库。
假设仓库 HTTPS 地址为:https://github.com/oceanbase/miniob.git.
REPO_ADDR 格式:https://<username>:<password>@github.com/oceanbase/miniob.git
username 和 password GitHub / Gitee(GitHub 不支持 password,需要创建 token,见链接)。
用户名如果是邮箱,字符 '@' 需要转义为 '%40'.
# example
REPO_ADDR=https://oceanbase%40email.com:mypassword@github.com/oceanbase/miniob.git
公有仓库
如果 fork 出的是公有仓库,直接将 REPO_ADDR 设置为仓库地址即可。
REPO_ADDR=https://github.com/oceanbase/miniob.git
配置映射端口
默认映射本机端口 10000 到容器端口 22. 可在 docker-compose.yml 中自行修改。不许修改可跳过此步骤。
启动容器
Clone by SSH
如果用 SSH 的方式 clone,需要将 Github/Gitee 对应的 SSH 私钥设置到环境变量内再启动 Container.
假设 Github/Gitee 上传的公钥对应的秘钥位于 ~/.ssh/id_rsa.
terminal 进入本仓库 docker 目录,在 docker 目录下执行命令启动容器。
Linux Shell
export PRIVATE_KEY=$(cat ~/.ssh/id_rsa) && docker-compose up -d --build
Windows Powershell
$env:PRIVATE_KEY=$(cat ~/.ssh/id_rsa) && docker-compose up -d --build
Clone by HTTPS
不需要 PRIVATE_KEY 环境变量。
docker-compose up -d --build
此输出表示容器启动成功。

管理容器
一些管理容器的命令。
# 停止容器
docker stop miniob-dev
# 启动容器
docker start miniob-dev
# 重启容器
docker restart miniob-dev
使用 VSCode 远程开发
打开 VSCode,设置远程开发及调试。
安装 Remote-SSH 插件
一般会默认安装。快捷键组合 Ctrl + Shift + x 打开 VSCode 插件面板,检查 Remote - SSH 插件是否安装,如果没有安装就安装此插件。
连接 Docker 容器
配置 SSH Host
按快捷键 Ctrl + p, 输入 remote-ssh: connect to host 连接远程主机。
选择 Add new ssh host.
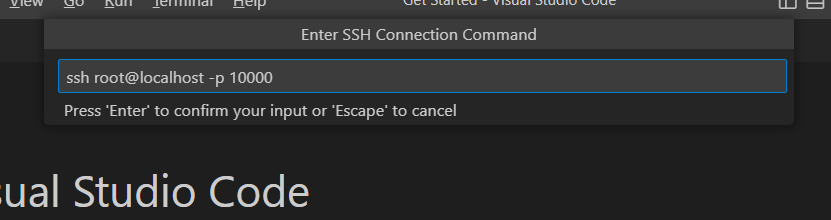
输入命令.
ssh root@localhost -p 10000
以 root 用户连接容器的 10000 端口.
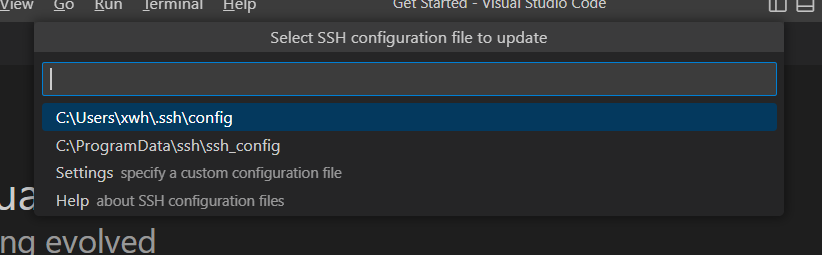
选择写入哪个配置文件,默认第一个就行。
连接容器
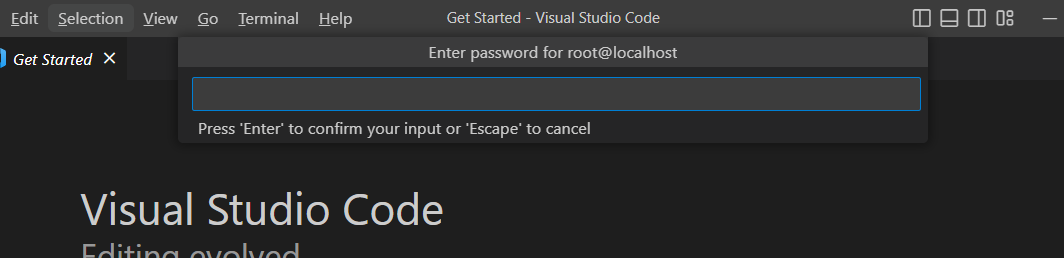
按快捷键 Ctrl + p, 输入 remote-ssh: connect to host 连接远程主机。
主机选 localhost 并回车,跳出密码输入页面。若在之前步骤没有修改,密码默认为 root.
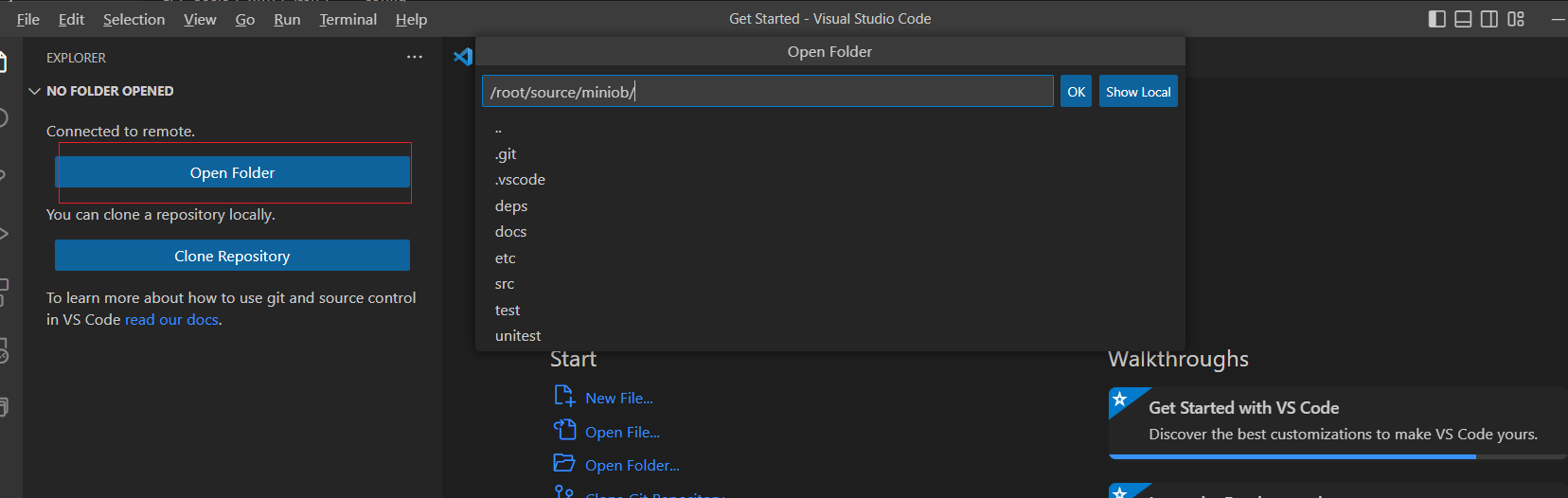
打开代码目录
代码位于 /root/source/miniob. 点击左侧 open folder,进入该目录。需要再输入一次密码。
安装开发插件
Ctrl + Shift + x 打开 VSCode 插件面板, 安装如下插件. 注意要安装在 Docker 容器中,点击 install in SSH:localhost.
C/C++ 和 C/C++ Extension Pack.
C/C++ Extension Pack 安装好后会让你选择 kits, 选 GCC 8.5 这个。
CMake 和 CMake Tools.

进行 Debug
启动 Server
在 src/observer/sql/parser/parse_stage.cpp 的 handle_event 函数开头打个断点, 也就是第 90 行。
按 F5 开始调试。出现如下界面表示 miniob 的 server 端启动成功。
启动 Client
Ctrl + Shift + ` 新启动一个 shell.
执行 ./build/bin/obclient 启动客户端.
执行 SQL
执行一句 SQL 测试断点是否正常工作。
show tables;
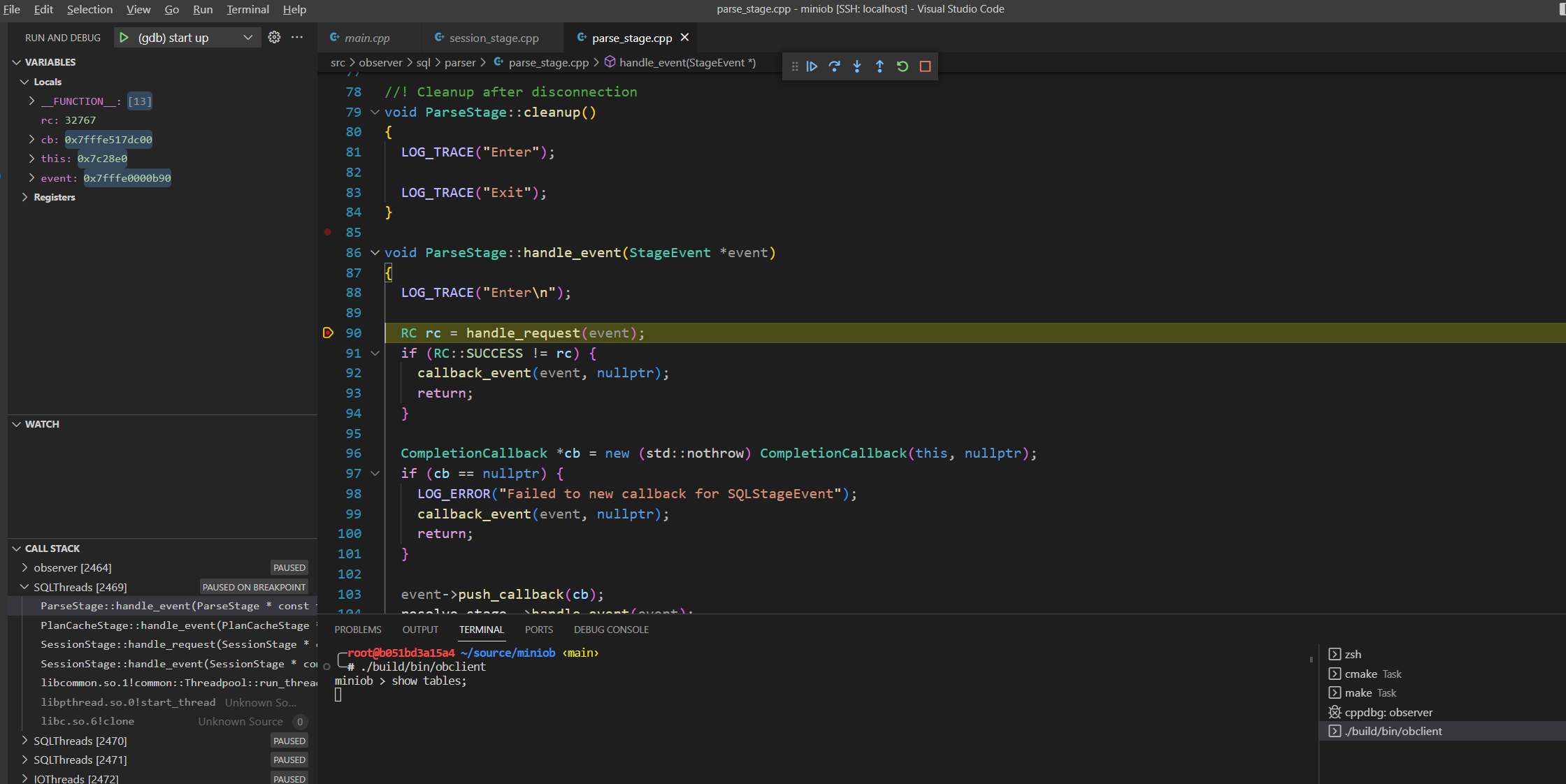
正常进入断点。后续可以配置 Git 进行开发了。
Windows 如何使用 Docker 开发miniob
miniob 是 OceanBase联合华中科技大学开发的一款帮助零基础开发者数据库开发实战的系统,目前已经开源,可以在GitHub网站查看:miniob github首页。
Miniob 是一个基于Linux的系统,可以在Linux和Mac上开发测试。使用Windows的同学,可以尝试Docker、Linux 子系统或者Cygwin等方式。本篇文章介绍在Windows系统上如何使用Docker来开发miniob。
安装Docker
Windows系统上默认不会安装Docker,需要自行安装。安装Docker有一些依赖,比如要开启电脑的虚拟化功能、Windows的Hyper-V 功能,具体操作可以参考这篇文档在Windows系统上安装Docker。
虽然文档已经比较详细,而且网上可以搜到大量的教程,这里还是给一些步骤提示。
如何开启电脑的虚拟化
以ThinkPad X1 Carbon 为例(不同的电脑可能会有些不同)
开机按 F1 进入:BIOS (不同的电脑进入BIOS的方式可能不同)
- 选择:Security
- 选择:Virtualization
- 选择:
- Intel(R) Virturalization Technology=Enable
- Intel(R) VT-d Feature=Enable
下载Docker Desktop
这个步骤没有什么特殊的,下载即可。
开启Windows 子系统
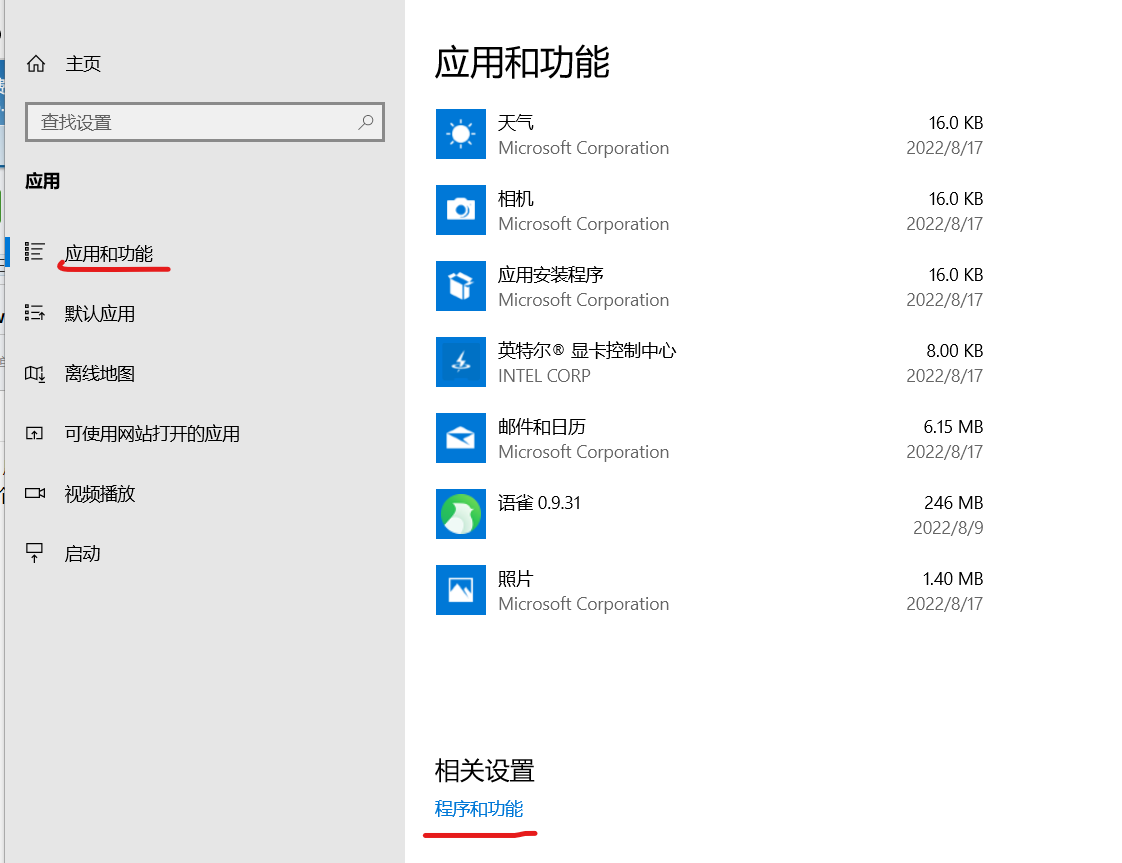
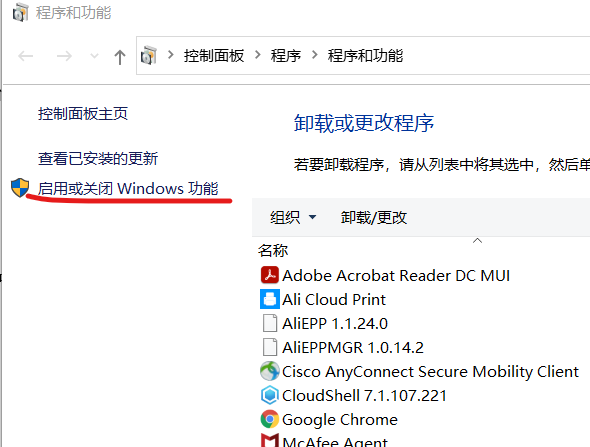
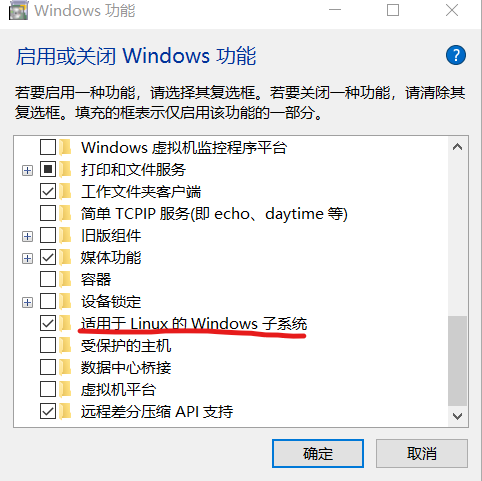
可以在Windows应用中找到Windows功能的开关,具体步骤以Windows 10为例,参考下面的步骤。
安装Docker
Windows应用程序的典型安装,点击下载好的安装包即可。
运行Docker
在PowerShell 中执行以下命令,下载并启动miniob镜像
docker run -d --name miniob --privileged oceanbase/miniob
其中 privileged 参数是为了方便在容器中进行调试。
运行下面的命令可以进入到容器并进行开发
docker exec -it miniob bash
这个命令可以在终端上执行多次,开启多个窗口方便操作。
到这里就可以结束了,但是为了方便后续的开发,还有一些建议。
- 将代码放在自己的电脑上,Docker仅作为一个开发环境。启动镜像时这么做
docker run -d --name miniob --privileged -v $PWD/miniob:/root/miniob oceanbase/miniob
其中 -v $PWD/miniob:/root/miniob 是说将本地的 $PWD/miniob 目录映射到容器中的/root/miniob 目录,这里假设 $PWD/miniob 是你本地代码存放的位置,需要按照实际目录来调整。
代码放在自己的电脑上,好处是如果容器出现什么异常,自己最重要的数据不会丢失。
- 启动镜像时忘记增加一些参数,但是又不想重新创建怎么办?
有时候启动镜像时(docker run),忘记增加一些参数,比如 privileged,但是又在容器中做了蛮多操作,对环境做了调整,不希望启动全新的容器,可以这么做
- 提交当前的容器,创建新的镜像
docker commit -m 'commit message' -t miniob:vx miniob
docker stop miniob
docker rm miniob
- 启动新的镜像
docker run -d --name miniob xxxx miniob:vx
NOTE: 参数中 miniob:vx 中的vx 是一个版本号,你可以自己设置,每次使用不同的名字即可。
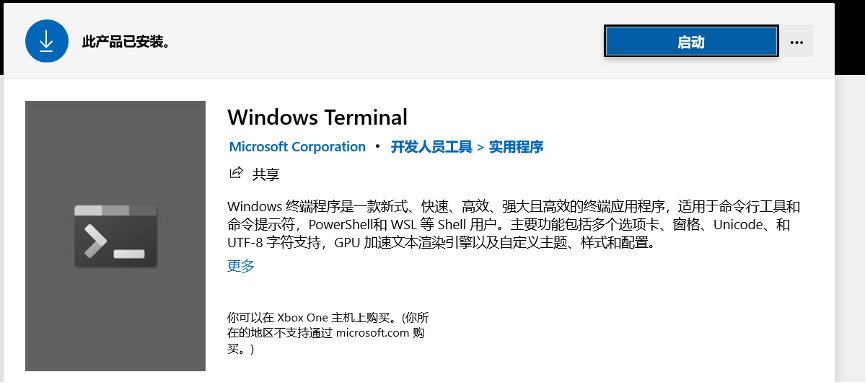
- 在Windows上安装 Windows Terminal 应用
说实话,Windows自带的PowerShell和命令提示符实在太丑了,而且不支持配置。可以在应用商城中下载Windows Terminal 应用,此应用免费,默认界面非常漂亮并且支持多种终端。
FAQ
- Docker Desktop requires the Server service to be enabled. 开启Windows服务即可
-
搜索 service 应用
-
开启server应用
- miniob 镜像中当前包含哪些信息 可以参考miniob镜像的网站首页:miniob 镜像首页
在windows上通过docker配置环境并利用vscode调试代码(手把手版)
-- 由严奕凡编写,就读于重庆大学.
系统情况: windows操作系统,版本win11
个人情况: from 0 to 1 不想用虚拟机,不想用gitpod
参考资料: https://oceanbase.github.io/miniob 、小伙伴们的讨论、亲身经历
配置思路: 1、使用docker提供linux编译环境 2、使用vscode进行代码编辑 3、使用vscode的docker插件,在vscode终端调试
个人理解1: docker对我来说就是在windows系统上提供一个虚拟的linux环境,它只在build和调试时起到作用
个人理解2: vscode用来编辑代码
个人理解3: vscode里面docker插件的attach功能可以在vscode的终端实现一个linux的虚拟环境,使得miniob的build.sh能在其中通过bash指令运行
实操:
1、下载docker
2、获取oceanbase/miniob的docker环境
方法是在任意位置启动 终端(cmd或者powershell)
运行以下代码
docker run --privileged -d --name=miniobtest oceanbase/miniob
其中 --name=miniobtest 这个“miniobtest”是自己容器的名字 可以自己改 这个代码大概理解成从远程oceanbase/miniob拉取适合miniob的配置好的环境
这一步之后先把docker放一放,后面需要将本地文件与docker进行一个连接,先不放代码以免产生误解
3、在vscode中使用git 对官网miniob进行clone ,在本地创建一个代码仓库
PS:这一步部分小伙伴可能会遇到网络问题,提示您clone的时候连接到github失败,有两种解决办法,其一是解决访问github的问题,其二是直接从github上下载源代码下来,另外还可以用ssh的方式clone代码,速度比https快很多(本文档暂未给出ssh使用办法,有兴趣的小伙伴可以进行补充)
1)准备工作(有vscode和git,并且配置好环境变量的小伙伴可以看下一步):
下载vscode Visual Studio Code - Code Editing. Redefined
下载git Git (git-scm.com)
配置vscode设置 ,下载所需插件:例如docker

配置环境变量(这是为了让git能在vscode终端中使用):
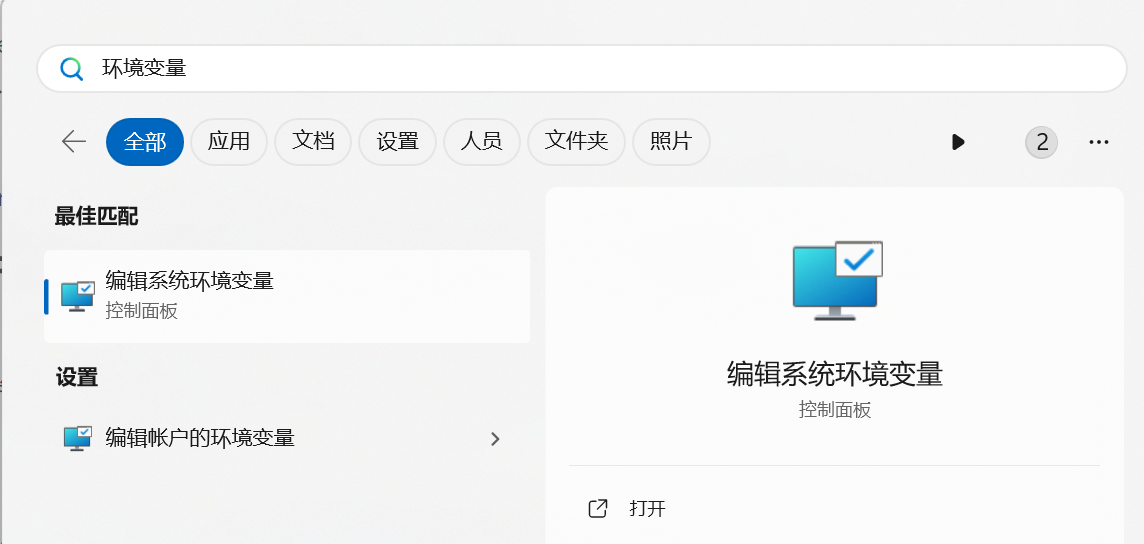
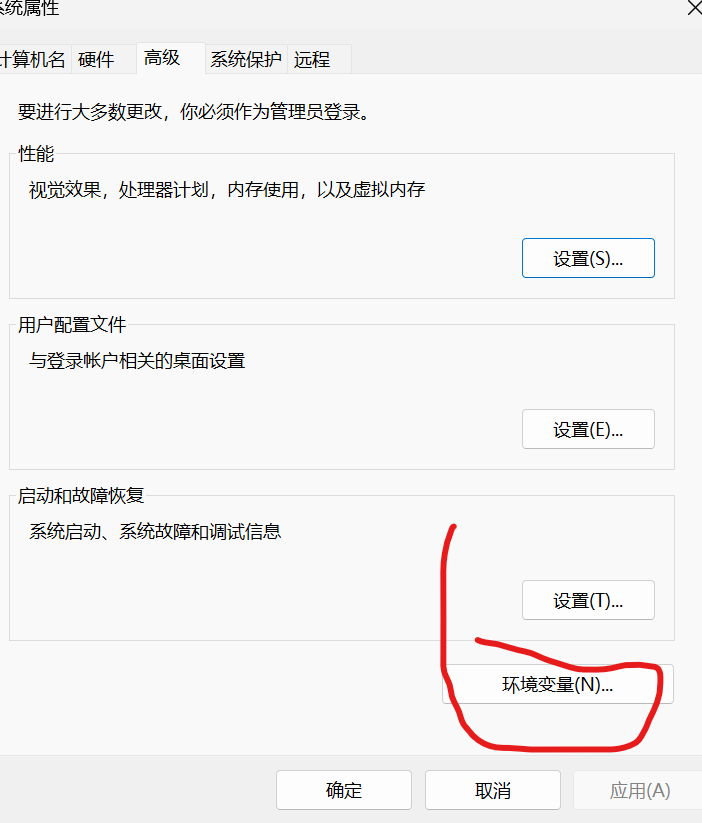
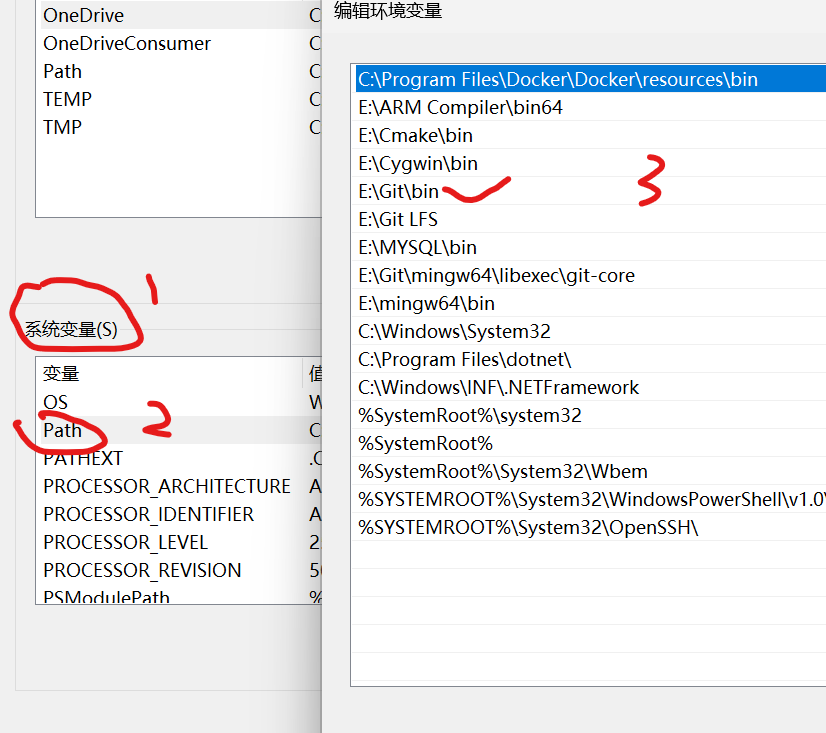
验证以下路径是否存在(如果没有,请添加文件路径)
2)进入vscode clone 代码
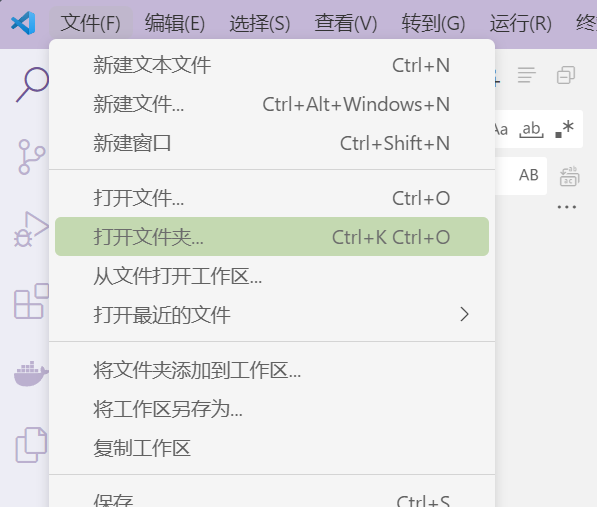
文件-打开文件夹,选取一个用于保存代码的文件夹
然后ctrl+shift+~ (快速新建一个终端) (PS:Mac 系统 Command + J)
在终端里输入
git clone https://github.com/oceanbase/miniob.git
如果git配置正确并且能成功连接到github
您可以得到
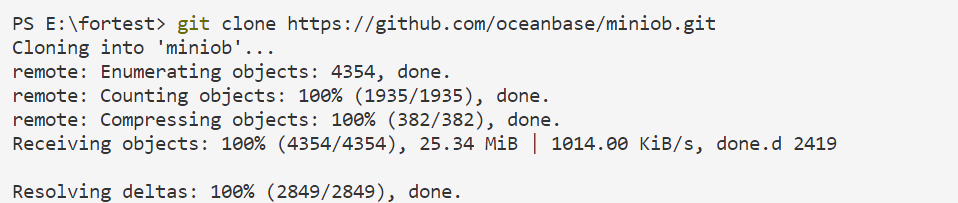
然后您可以进入得到的代码文件查看分支信息:例如
ls --查看当前目录
cd ‘文件名’ --进入
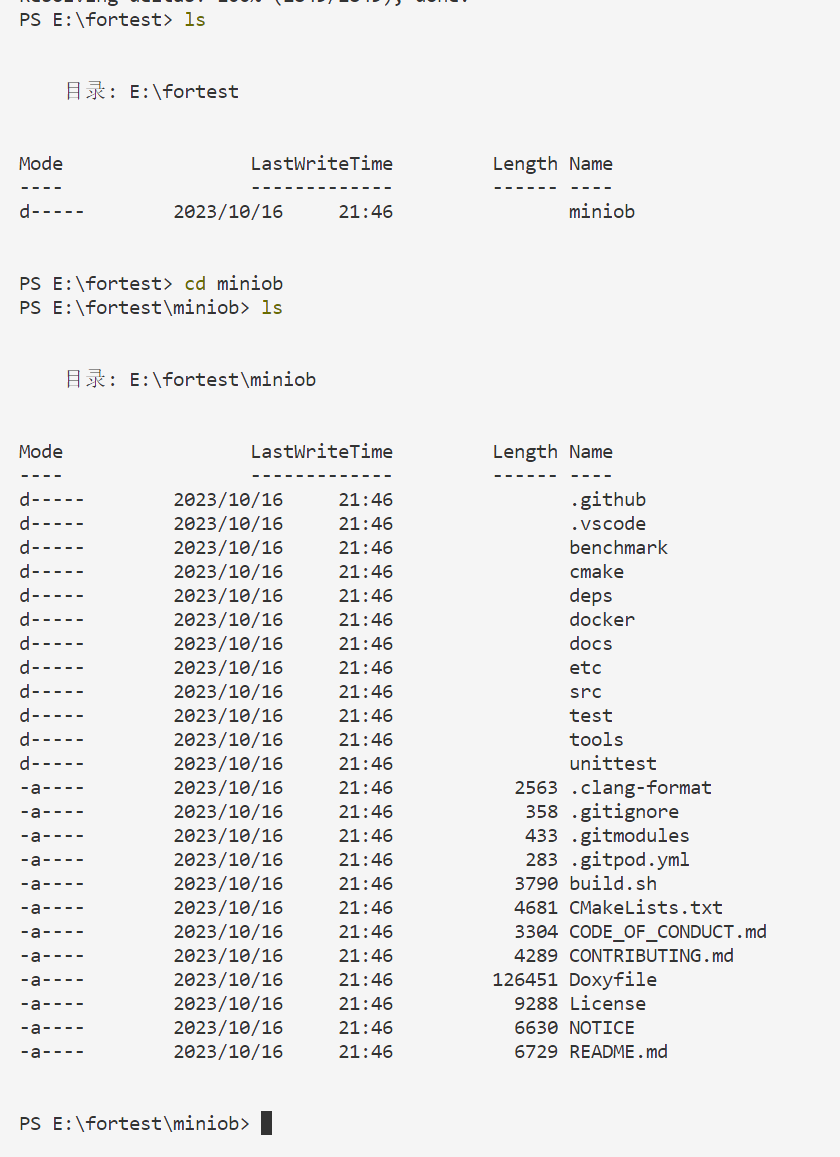
您可以输入 (要先进入clone得到的代码文件里面,才能读取到.git文件)
git branch -a
查看所有分支
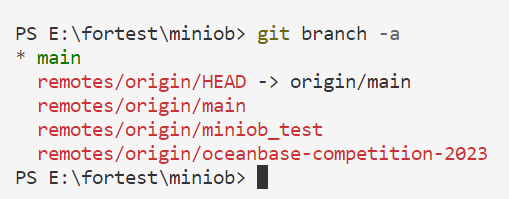
4、将获取到的文件与docker容器 映射连接
创建一个container(映射方式)
恭喜!您已经获取到代码文件,并且实现了大部分配置!
接下来我们进入clone得到的文件夹的上一层目录,在那打开终端(这是方便后续代码的实现)
您也可以用cd 指令进入得到的文件夹的上一层目录
像这样
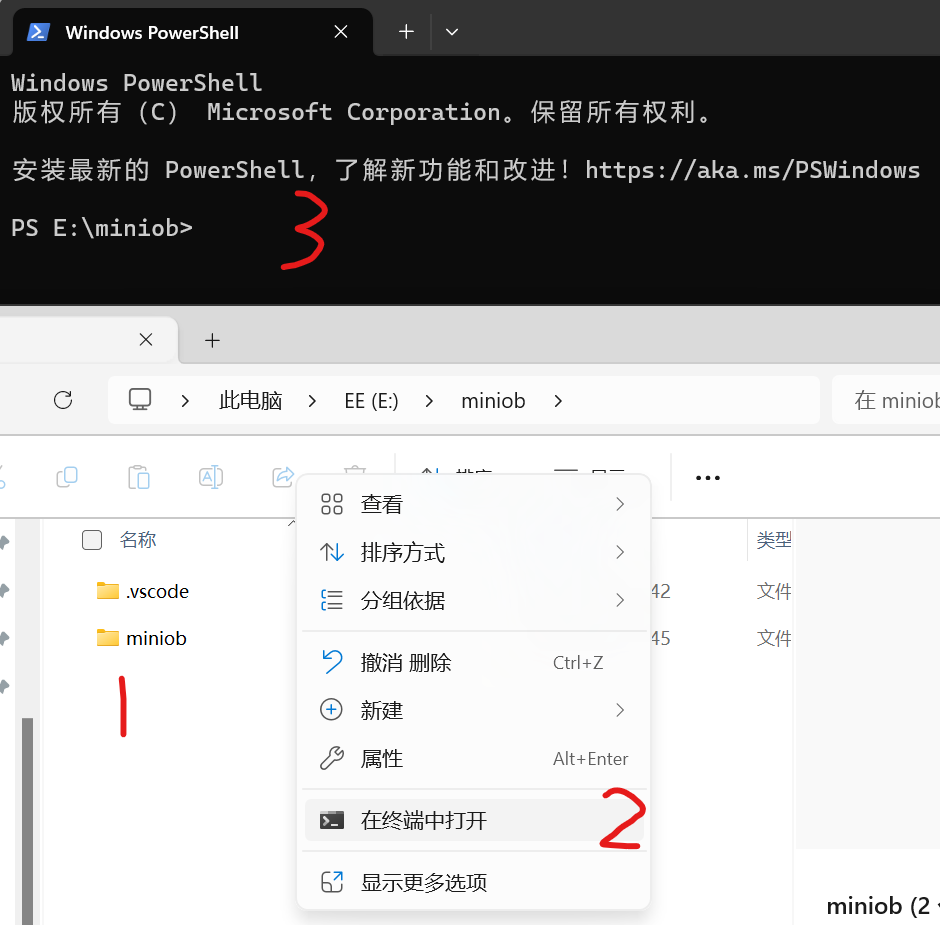
然后输入
docker run -d --name fortest --privileged -v $PWD/miniob:/root/miniob oceanbase/miniob
分析如下:
您提供的命令
docker run用于运行具有特定选项和配置的 Docker 容器,但它还指定要运行的映像。让我们分解一下命令:
docker run:这是启动新 Docker 容器的基本命令。-d:此选项以分离模式运行容器,这意味着它在后台运行,允许您继续使用终端。--name fortest:此选项指定容器的名称为“fortest”。--privileged:这是一个与安全相关的选项,可授予容器额外的权限,从而有效地赋予其对主机系统的更高访问权限。使用时要小心,--privileged因为它可能会带来安全风险。-v $PWD/miniob:/root/miniob:此选项用于创建卷安装。它将主机系统上的目录或文件映射到容器内的目录。在本例中,它将主机系统上miniob当前工作目录 ( ) 中的目录映射到容器内的目录。这是向容器提供数据或配置的常见方法。$PWD``/root/minioboceanbase/miniob:指定要运行的 Docker 映像。镜像“oceanbase/miniob”用于创建容器。如果您的系统上尚未提供该映像,Docker 将尝试从 Docker Hub 中提取该映像。因此,总体命令是以分离模式运行名为“fortest”的 Docker 容器,授予其提升的权限,将目录
miniob从主机系统安装到/root/miniob容器内的目录,并使用“oceanbase/miniob”映像作为容器。此命令对于运行基于具有特定配置的“oceanbase/miniob”映像的容器非常有用。
得到的结果如图

此时您应该可以在docker里面查看到container
5、在vscode中启动docker
1)先打开docker软件(每次重启电脑后都需要做)
2)打开vscode,在左侧边栏找到下载好的docker插件
然后选中您刚才用以下代码生成的容器,如果是初次生成,您可能只会显示一个容器
docker run -d --name fortest --privileged -v $PWD/miniob:/root/miniob oceanbase/miniob
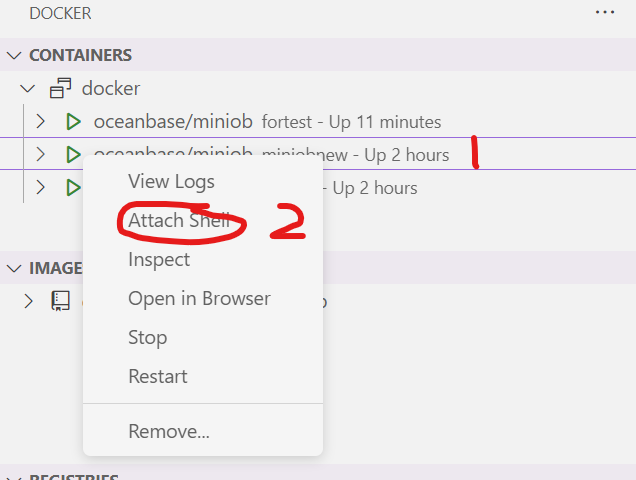
右键选中容器然后attach shell
然后在打开的终端中就可以编译miniob了!
(注意,一开始是不会有build 和build_debug文件的,这两个是通过运行bash.sh生成的)
综合运用以下代码运行build.sh文件
ls
cd miniob
bash build.sh
解释如下
您提供的命令是类 Unix 操作系统终端(例如 Linux)中使用的典型命令。让我分解一下命令:
ls:该命令是“list”的缩写。它用于列出当前目录中的文件和目录。运行ls将显示当前工作目录中的文件和文件夹列表。cd miniob:此命令将当前工作目录更改为名为“miniob”的子目录。您将导航到“miniob”目录。bash build.sh:此命令正在运行名为“build.sh”的 Bash 脚本。该脚本可能用于构建或编译某些软件、设置开发环境或执行与“miniob”项目或应用程序相关的其他任务。运行此脚本将执行其中定义的命令。假设“build.sh”是“miniob”项目的构建脚本,则运行这些命令是构建或设置项目的常见顺序。该
ls命令用于检查当前目录的内容,cd用于更改到“miniob”目录,并bash build.sh用于执行构建脚本。
编译通过后你可以在目录看到 build 或者build_debug 文件 然后可以进去调试
示例代码:
cd build_debug
./bin/observer -f ../etc/observer.ini -P cli
#这会以直接执行命令的方式启动服务端程序,可以直接输入命令,不需要客户端。所有的请求都会以单线程的方式运行,配置项中的线程数不再有实际意义。
示例图(ps:drop table功能一开始没有实习,需要您自己去尝试实现)
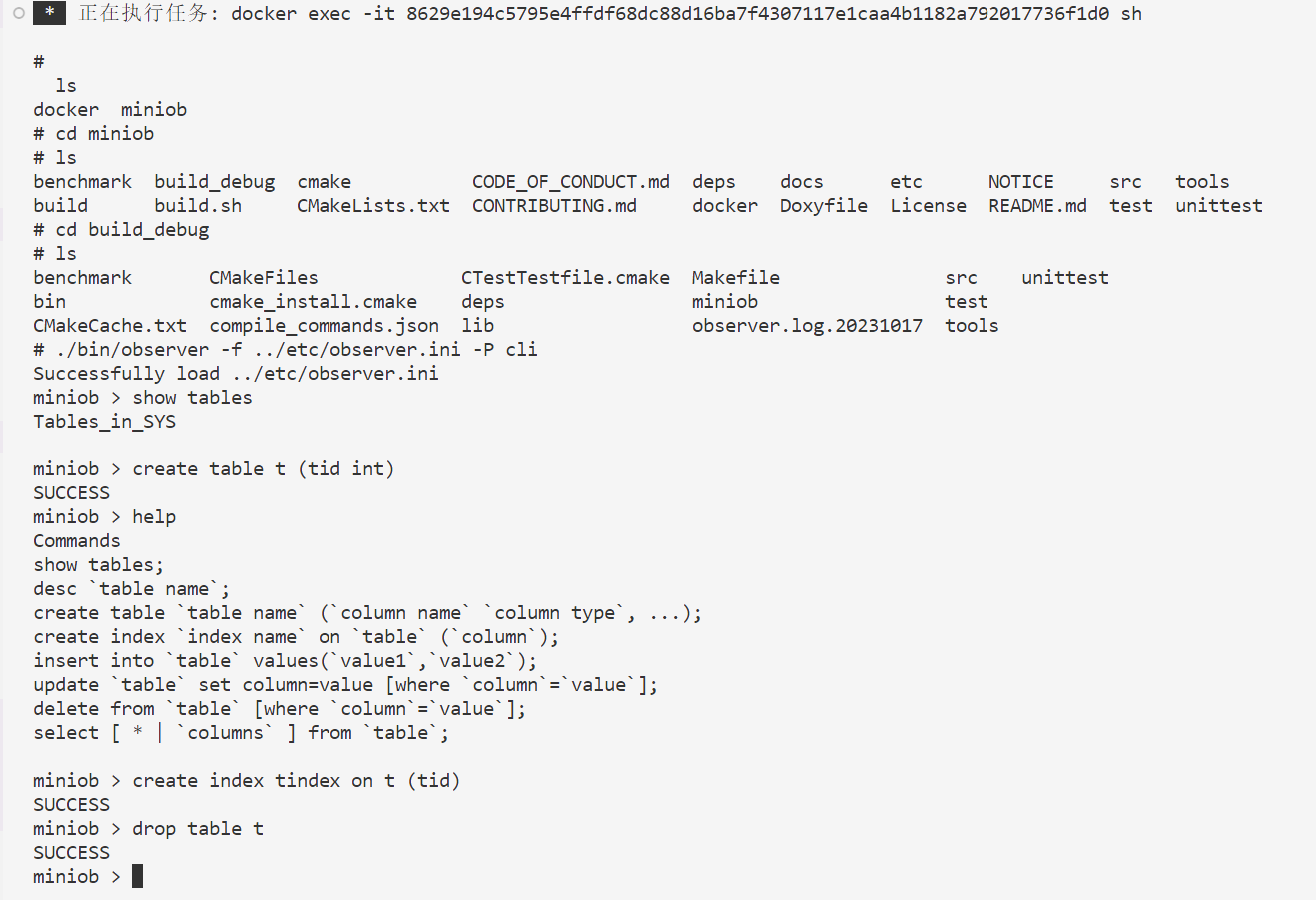
您也可以启动服务端后再启用客户端,也可以实现类似效果 在vscode中操作为 再次attach shell新建一个终端 参考文档:https://oceanbase.github.io/miniob/how_to_run.html
以监听TCP端口的方式启动服务端程序
./bin/observer -f ../etc/observer.ini -p 6789
这会以监听6789端口的方式启动服务端程序。 启动客户端程序:
./bin/obclient -p 6789
这会连接到服务端的6789端口。
编辑日期 2023-10-17
本篇文章介绍如何使用Docker来开发MiniOB。
MiniOB 依赖的第三方组件比较多,搭建开发环境比较繁琐,建议同学们直接使用我们提供的Docker环境进行开发。
首先要确保本地已经安装了Docker。 如果对Docker还不太熟悉,可以先在网上大致了解一下。
我们提供了原始的Dockerfile,也有已经打包好的镜像,可以选择自己喜欢的方式。 自行构建参考本文档。
- 使用docker hub 镜像运行
docker run --privileged -d --name=miniob oceanbase/miniob
此命令会创建一个新的容器,然后可以执行下面的命令进入容器:
docker exec -it miniob /usr/bin/zsh
Docker环境说明:
docker基于anolisos:8.6制作。
镜像包含:
- jsoncpp
- google test
- libevent
- flex
- bison(3.7)
- gcc/g++ (version=11)
- miniob 源码(/root/source/miniob)
docker中在/root/source/miniob目录下载了github的源码,可以根据个人需要,下载自己仓库的源代码,也可以直接使用git pull 拉取最新代码。 /root/source/miniob/build.sh 提供了一个编译脚本,以DEBUG模式编译miniob。
miniob调试篇
-- by caizj
调试c/c++程序,常用的有两种方式,一是打印日志调试,二是gdb调试,调试不仅可以定位问题,也可以用来熟悉代码。
miniob关键代码
首先,拿到一份陌生的代码,要先确定代码的大致结构,一些关键数据结构和方法,这里的技巧和经验不展开了
miniob的关键数据结构
部分关键数据结构:
parse_def.h:
struct Selects;//查询相关
struct CreateTable;//建表相关
struct DropTable;//删表相关
enum SqlCommandFlag;//sql语句对应的command枚举
union Queries;//各类dml和ddl操作的联合
table.h
class Table;
db.h
class Db;
miniob的关键接口
部分关键接口
RC parse(const char *st, Query *sqln);//sql parse入口
ExecuteStage::handle_request
ExecuteStage::do_select
DefaultStorageStage::handle_event
DefaultHandler::create_index
DefaultHandler::insert_record
DefaultHandler::delete_record
DefaultHandler::update_record
Db::create_table
Db::find_table
Table::create
Table::scan_record
Table::insert_record
Table::update_record
Table::delete_record
Table::scan_record
Table::create_index
打印日志调试
miniob提供的日志接口
deps/common/log/log.h:
#define LOG_PANIC(fmt, ...)
#define LOG_ERROR(fmt, ...)
#define LOG_WARN(fmt, ...)
#define LOG_INFO(fmt, ...)
#define LOG_DEBUG(fmt, ...)
#define LOG_TRACE(fmt, ...)
日志相关配置项observer.ini
LOG_FILE_NAME = observer.log
# LOG_LEVEL_PANIC = 0,
# LOG_LEVEL_ERR = 1,
# LOG_LEVEL_WARN = 2,
# LOG_LEVEL_INFO = 3,
# LOG_LEVEL_DEBUG = 4,
# LOG_LEVEL_TRACE = 5,
# LOG_LEVEL_LAST
LOG_FILE_LEVEL=5
LOG_CONSOLE_LEVEL=1
gdb调试
调试工具有很多种,但是它们的关键点都是类似的,比如关联到进程、运行时查看变量值、单步运行、跟踪变量等。GDB是在Linux环境中常用的调试工具。其它环境上也有类似的工具,比如LLDB,或者Windows可能使用Visual Studio直接启动调试。Java的调试工具是jdb。
另外,很多同学喜欢使用Visual Studio Code(vscode)开发项目,vscode提供了很多插件,包括调试的插件,这些调试插件支持gdb、lldb等,可以按照自己的平台环境,设置不同的调试工具。
这里介绍了gdb的基本使用,其它工具的使用方法类似。
-
Attach进程
[caizj@localhost run]$ gdb -p `pidof observer` GNU gdb (GDB) Red Hat Enterprise Linux 8.2-15.el8 Copyright (C) 2018 Free Software Foundation, Inc. (gdb) -
设置断点
(gdb) break do_select Breakpoint 1 at 0x44b636: file /home/caizj/source/stunning-engine/src/observer/sql/executor/execute_stage.cpp, line 526. (gdb) info b Num Type Disp Enb Address What 1 breakpoint keep y 0x000000000044b636 in ExecuteStage::do_select(char const*, Query*, SessionEvent*) at /home/caizj/source/stunning-engine/src/observer/sql/executor/execute_stage.cpp:526(gdb) break Table::scan_record Breakpoint 2 at 0x50b82b: Table::scan_record. (2 locations) (gdb) inf b Num Type Disp Enb Address What 1 breakpoint keep y 0x000000000044b636 in ExecuteStage::do_select(char const*, Query*, SessionEvent*) at /home/caizj/source/stunning-engine/src/observer/sql/executor/execute_stage.cpp:526 2 breakpoint keep y <MULTIPLE> 2.1 y 0x000000000050b82b in Table::scan_record(Trx*, ConditionFilter*, int, void*, void (*)(char const*, void*)) at /home/caizj/source/stunning-engine/src/observer/storage/common/table.cpp:421 2.2 y 0x000000000050ba00 in Table::scan_record(Trx*, ConditionFilter*, int, void*, RC (*)(Record*, void*)) at /home/caizj/source/stunning-engine/src/observer/storage/common/table.cpp:426 (gdb) -
继续执行
(gdb) c Continuing. -
触发断点
执行:miniob > select * from t1;
[Switching to Thread 0x7f51345f9700 (LWP 54706)] Thread 8 "observer" hit Breakpoint 1, ExecuteStage::do_select (this=0x611000000540, db=0x6040000005e0 "sys", sql=0x620000023080, session_event=0x608000003d20) at /home/caizj/source/stunning-engine/src/observer/sql/executor/execute_stage.cpp:526 526 RC rc = RC::SUCCESS; (gdb) -
单步调式
575 std::vector<TupleSet> tuple_sets; (gdb) next 576 for (SelectExeNode *&node: select_nodes) { (gdb) n 577 TupleSet tuple_set; (gdb) 578 rc = node->execute(tuple_set); (gdb) -
跳入 跟踪到函数内部
(gdb) s SelectExeNode::execute (this=0x60700002ce80, tuple_set=...) at /home/caizj/source/stunning-engine/src/observer/sql/executor/execution_node.cpp:43 43 CompositeConditionFilter condition_filter; (gdb) -
打印变量
(gdb) p tuple_set $3 = (TupleSet &) @0x7f51345f1760: {tuples_ = std::vector of length 0, capacity 0, schema_ = { fields_ = std::vector of length 0, capacity 0}} (gdb) -
watch变量
(gdb) n 443 RC rc = RC::SUCCESS; (gdb) n 444 RecordFileScanner scanner; (gdb) n 445 rc = scanner.open_scan(*data_buffer_pool_, file_id_, filter); (gdb) watch -l rc Hardware watchpoint 3: -location rc (gdb) c Continuing. Thread 8 "observer" hit Hardware watchpoint 3: -location rc Old value = SUCCESS New value = RECORD_EOF 0x000000000050c2de in Table::scan_record (this=0x60f000007840, trx=0x606000009920, filter=0x7f51345f12a0, limit=2147483647, context=0x7f51345f11c0, record_reader=0x50b74a <scan_record_reader_adapter(Record*, void*)>) at /home/caizj/source/stunning-engine/src/observer/storage/common/table.cpp:454 454 for ( ; RC::SUCCESS == rc && record_count < limit; rc = scanner.get_next_record(&record)) { (gdb) -
结束函数调用
(gdb) finish Run till exit from #0 0x000000000050c2de in Table::scan_record (this=0x60f000007840, trx=0x606000009920, filter=0x7f51345f12a0, limit=2147483647, context=0x7f51345f11c0, record_reader=0x50b74a <scan_record_reader_adapter(Record*, void*)>) at /home/caizj/source/stunning-engine/src/observer/storage/common/table.cpp:454 -
结束调试
(gdb) quit A debugging session is active. Inferior 1 [process 54699] will be detached. Quit anyway? (y or n) y Detaching from program: /home/caizj/local/bin/observer, process 54699 [Inferior 1 (process 54699) detached]
Visual Studio Code 调试
代码中已经为vscode配置了launch.json,可以直接启动调试。 launch.json中有两个调试配置,一个是Debug,一个是LLDB。其中Debug使用cppdbg,会自动探测调试工具gdb或lldb,而LLDB会使用lldb调试工具。通常情况下,大家使用Debug就可以了,但是我在测试过程中发现cppdbg不能在macos上正常工作,因而增加了LLDB的配置,以便在macos上调试,如果使用macos的同学,可以使用LLDB配置启动调试程序。
功能模块设计说明
- Miniob架构
- 存储实现
- Double Write Buffer
- 事务
- 持久化
- SQL Parser
- 如何新增支持一种新类型SQL
- 表达式解析
- B+树实现
- 并发B+树实现
- 线程池模型
- 通讯协议简介
- Doxy文档
MiniOB代码架构框架设计和说明
MiniOB代码结构说明
背景
MiniOB旨在帮助不太熟悉数据库设计和实现的同学快速掌握和深入学习数据库内核。我们希望通过MiniOB的培训,学生能够理解不同数据库内核模块的功能和它们之间的联系。这个项目主要面向在校学生,对模块的设计和实现进行了简化处理,以便于他们更好地理解和学习。
MiniOB架构介绍

- 网络模块(NET Service):负责与客户端交互,收发客户端请求与应答;
- SQL解析(Parser):将用户输入的SQL语句解析成语法树;
- 语义解析模块(Resolver):将生成的语法树,转换成数据库内部数据结构;
- 查询优化(Optimizer):根据一定规则和统计数据,调整/重写语法树;
- 计划执行(Executor):根据语法树描述,执行并生成结果;
- 存储引擎(Storage Engine):负责数据的存储和检索;
- 事务管理(MVCC):管理事务的提交、回滚、隔离级别等。当前事务管理仅实现了MVCC模式,因此直接以MVCC展示;
- 日志管理(Redo Log):负责记录数据库操作日志;
- 记录管理(Record Manager):负责管理某个表数据文件中的记录存放;
- B+ Tree:表索引存储结构;
- 会话管理:管理用户连接、调整某个连接的参数;
- 元数据管理(Meta Data):记录当前的数据库、表、字段和索引元数据信息;
- 客户端(Client):作为测试工具,接收用户请求,向服务端发起请求。
各模块工作原理介绍
服务端启动过程
虽然代码是模块化的,并且面向对象设计思想如此流行,但是很多同学还是喜欢从main函数看起。那么就先介绍一下服务端的启动流程。
main函数参考 main@src/observer/main.cpp。启动流程大致如下:
解析命令行参数 parse_parameter@src/observer/main.cpp
加载配置文件 Ini::load@deps/common/conf/ini.cpp
初始化日志 init_log@src/observer/init.cpp
初始化网络服务 init_server@src/observer/main.cpp
启动网络服务 Server::serve@src/net/server.cpp
建议把精力更多的留在核心模块上,以更快的了解数据库的工作原理。
网络模块
网络模块代码参考src/observer/net,主要是Server类。 当前支持TCP socket和Unix socket,TCP socket可以跨主机通讯,需要服务端监听特定端口。Unix socket只能在本机通讯,测试非常方便。 在处理具体连接的网络IO请求时,会有具体的线程模型来处理,当前支持一对一连接线程模型和线程池模型,可以参考文档MiniOB线程模型。 网络服务启动后,会监听端口(TCP)或Unix连接,当接收到新的连接,会将新的连接描述字加入网络线程模型中。 线程模型会在进程运行时持续监听对应socket上新请求的到达,然后将请求交给具体的处理模块。
SQL解析
SQL解析模块是接收到用户请求,开始正式处理的第一步。它将用户输入的数据转换成内部数据结构,一个语法树。
解析模块的代码在src/observer/sql/parser下,其中lex_sql.l是词法解析代码,yacc_sql.y是语法解析代码,parse_defs.h中包含了语法树中各个数据结构。
对于词法解析和语法解析,原理概念可以参考《编译原理》。
其中词法解析会把输入(这里比如用户输入的SQL语句)解析成成一个个的“词”,称为token。解析的规则由自己定义,比如关键字SELECT,或者使用正则表达式,比如"[A-Za-z_]+[A-Za-z0-9_]*" 表示一个合法的标识符。
对于语法分析,它根据词法分析的结果(一个个token),按照编写的规则,解析成“有意义”的“话”,并根据这些参数生成自己的内部数据结构。比如SELECT * FROM T,可以据此生成一个简单的查询语法树,并且知道查询的columns是"*",查询的relation是"T"。
NOTE:在查询相关的地方,都是用关键字relation、attribute,而在元数据中,使用table、field与之对应。
更多相关内容请参考 MiniOB SQL语法解析。
语义解析
语法解析会将用户发来的SQL文本内容,解析为一个文本描述的语法树,语义解析(Resolver)将语法树中的一些节点,比如表名、字段名称等,转换为内部数据结构中的真实对象。
解析可以做的更多,比如在解析表字段映射的过程中,可以创建Tuple,将字段名直接转换为使用更快的Field或数字索引的方式来访问某一行数据的字段。当前没有做此优化,每次都是在执行过程中根据字段名字来查找特定的字段,参考类 ProjectTuple。
优化
优化决定SQL执行效率非常重要的一环,通常会根据一定的规则,对SQL语法树做等价调整,再根据一些统计数据,比如表中的数据量、索引情况等,来选择更好的执行计划。
MiniOB中的执行计划优化仅实现了简单的框架,可以参考 OptimizeStage。
计划执行
顾名思义,计划执行就是按照优化后生成的执行计划原意执行,获取SQL结果。
当前查询语句被转换成了火山执行计划,执行时按照火山模型算子中,通过执行算子的 next 方法获取每行的执行结果。
对于DDL等操作,SQL最终被转换为各种Command,由CommandExecutor来执行。
计划执行的代码在src/observer/sql/executor/下,主要参考execute_stage.cpp的实现。
元数据管理模块
元数据是指数据库一些核心概念,包括db、table、field、index等,记录它们的信息。比如db,记录db文件所属目录;field,记录字段的类型、长度、偏移量等。代码文件分散于src/observer/storage/table,field,index中,文件名中包含meta关键字。
客户端
这里的客户端提供了一种测试miniob的方法。从标准输入接收用户输入,将请求发给服务端,并展示返回结果。这里简化了输入的处理,用户输入一行,就认为是一个命令。
通信协议
MiniOB 采用TCP通信,支持两种通讯协议,分别是纯文本模式和MySQL通讯协议,详细设计请参考 MySQL 通讯协议设计。 对于纯文本模式,客户端与服务端发送数据时,使用普通的字符串来传递数据,使用'\0'字符作为每个消息的终结符。
注意:测试程序也使用这种方法,请不要修改协议,后台测试程序依赖这个协议。 注意:返回的普通数据结果中不要包含'\0',也不支持转义处理。
为了方便测试,MiniOB 支持不使用客户端,可以直接启动后在终端输入命令的方式做交互,在启动 observer 时,增加 -P cli 参数即可,更多信息请参考 如何运行MiniOB。
参考
- 《数据库系统概念》
- 《数据库系统实现》
- 《flex_bison》 flex/bison手册
- flex开源源码
- bison首页
- cmake官方手册
- libevent官网
- OceanBase数据库文档
- OceanBase开源网站
附录-编译安装测试
编译
参考 如何构建MiniOB 文件。
运行服务端
参考 如何运行MiniOB。
MiniOB 存储实现
本节将从存储层面介绍 MiniOB 的实现。
MiniOB 框架简介
首先回顾一下 MiniOB 的框架,在 MiniOB 概述章节已经简单的介绍过,本节重点介绍执行器(Executor)访问的存储引擎。
存储引擎控制整个数据、记录是如何在文件和磁盘中存储,以及如何跟内部 SQL 模块之间进行交互。存储引擎中有三个关键模块:
-
Record Manager:组织记录一行数据在文件中如何存放。
-
Buffer Pool:文件跟内存交互的关键组件。
-
B+Tree:索引结构。
MiniOB 文件管理
首先介绍 MiniOB 中文件是怎么存放,文件需要管理一些基础对象,如数据结构、表、索引。数据库在 MiniOB 这里体现就是一个文件夹,如下图所示,最上面就是一个目录,MiniOB 启动后会默认创建一个 sys 数据库,所有的操作都默认在 sys 中。
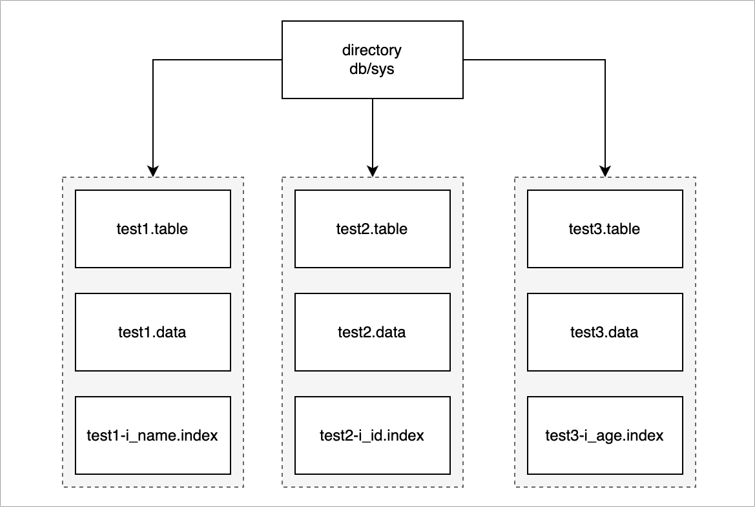
一个数据库下会有多张表。上图示例中只有三张表,接下来以 test1 表为例介绍一下表里都存放什么内容。
-
test1.table:元数据文件,这里面存放了一些元数据。如:表名、数据的索引、字段类型、类型长度等。
-
test1.data:数据文件,真正记录存放的文件。
-
test1-i_name.index:索引文件,索引文件有很多个,这里只展示一个示例。
MiniOB Buffer Pool 模块介绍
Buffer Pool 在传统数据库里是非常重要的基础组件。
首先来了解一下为什么要有一个 Buffer Pool ,数据库的数据是存放在磁盘里的,但不能直接从磁盘中读取数据,而是需要先把磁盘的数据读取到内存中,再在 CPU 做一些运算之后,展示给前端用户。写入也是一样的,一般都会先写入到内存,再把内存中的数据写入到磁盘。这种做法也是一个很常见的缓存机制。
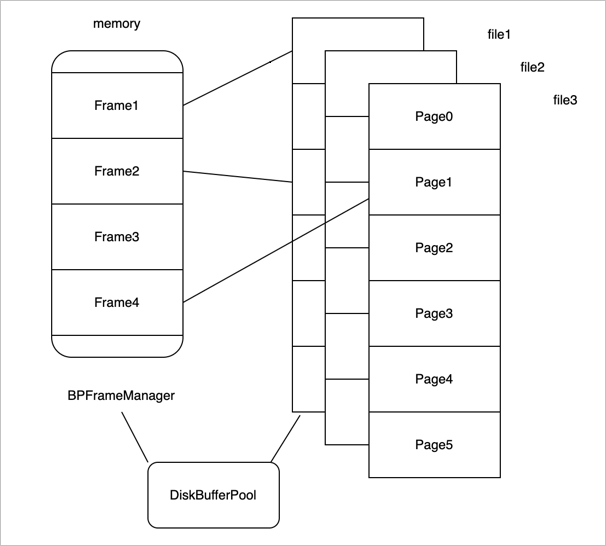
接着来看 Buffer Pool 在 MiniOB 中是如何组织的。如上图所示,左边是内存,把内存拆分成不同的帧(frame)。假如内存中有四个 frame,对应了右边的多个文件,每个文件按照每页来划分,每个页的大小都是固定的,每个页读取时是以页为单位跟内存中的一个 frame 相对应。
Buffer Pool 在 MiniOB 里面组织的时候,一个 DiskBufferPool 对象对应一个物理文件。所有的 DiskBufferPool 都使用一个内存页帧管理组件 BPFrameManager,他是公用的。
再来看下读取文件时,怎么跟内存去做交互的。如上图所示,frame1 关联了磁盘中一个文件的页面,frame2 关联了另一个页面,frame3 是空闲页面,没有关联任何磁盘文件,frame4 也关联了一个页面。
比如现在要去读取 file3 的 Page3 页面,首先需要从 BPFrameManager 里面去找一个空闲的 frame,很明显,就是 frame3,然后再把 frame3 跟它关联起来,把 Page3 的数据读取到 frame3 里。现在内存中的所有 frame 都对应了物理页面。
如果再去读取一个页面,如 Page5,这时候已经找不到内存了,通常有两种情况:
-
内存还有空闲空间,可以再申请一个 frame,跟 Page5 关联起来。
-
内存没有空闲空间,还要再去读 Page4,已经没有办法去申请新的内存了。此时就需要从现有的 frame 中淘汰一个页面,比如把 frame1 淘汰掉了,然后把 frame1 跟 Page4 关联起来,再把 Page4 的数据读取到 frame1 里面。淘汰机制也是有一些淘汰条件和算法的,可以先做简单的了解,暂时先不深入讨论细节。
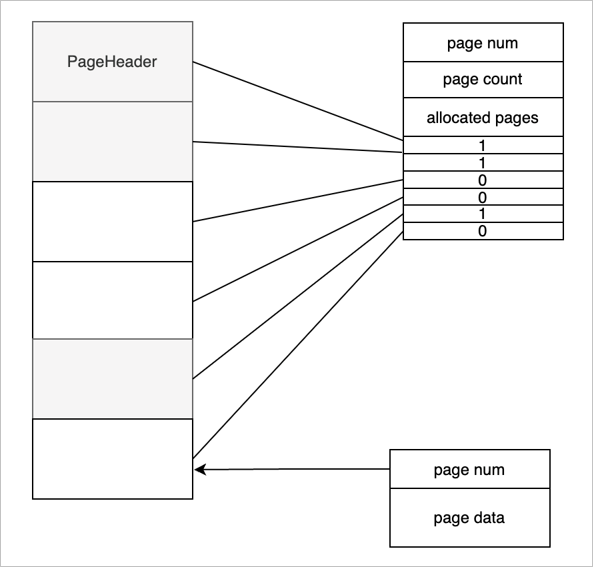
再来看一下,一个物理的文件上面都有哪些组织结构,如上图所示。
-
文件上的第一页称为页头或文件头。文件头是一个特殊的页面,这个页面上会存放一个页号,这个页号肯定都是零号页,即 page num 是 0。
-
page count 表示当前的文件一共有多少个页面。
-
allocated pages 表示已经分配了多少个页面。如图所示标灰的是已经分配的三个页面。
-
Bitmap 表示每一个 bit 位当前对应的页面的分配状态,1 已分配页面,0 空闲页面。
当前这一种组织结构是有一个缺陷的,整个文件能够支持的页面的个数受页面大小的限制,也就是说能够申请的页面的个数受页面大小的限制的。有兴趣的,可以思考一下怎么能实现一个无限大或支持更大页面的算法。
接下来介绍一下普通页面(除 PageHeader 外),普通页面对 Buffer Pool 来说,第一个字段是用四字节的 int 来表示,就是 page num。接下来是数据,这个数据是由使用 Buffer Pool 的一些模块去控制。比如 Record Manage 或 B+Tree,他们会定义自己的结构,但第一个字段都是 page num,业务模块使用都是 page data 去做组织。
MiniOB 记录管理
记录管理模块(Record Manager)主要负责组织记录在磁盘上的存放,以及处理记录的新增与删除。需要尽可能高效的利用磁盘空间,尽量减少空洞,支持高效的查找和新增操作。
MiniOB 的 Record Manager 做了简化,有一些假设,记录通常都是比较短的,加上页表头,不会超出一个页面的大小。另外记录都是固定长度的,这个简化让学习 MiniOB 变得更简单一点。
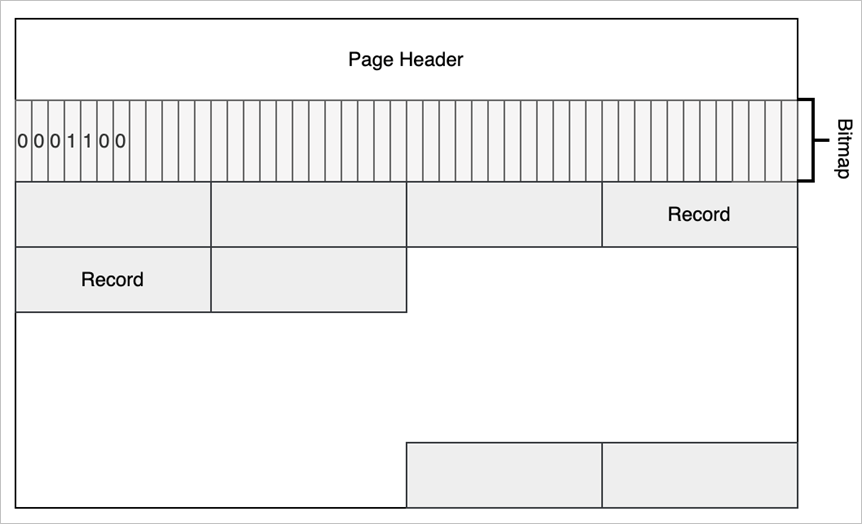
上面的图片展示了 MiniOB 的 Record Manager 是怎么实现的,以及 Record 在文件中是如何组织的。
Record Manage 是在 Buffer Pool 的基础上实现的,比如 page0 是 Buffer Pool 里面使用的元数据,Record Manage 利用了其他的一些页面。每个页面有一个头信息 Page Header,一个 Bitmap,Bitmap 为 0 表示最近的记录是不是已经有有效数据;1 表示有有效数据。Page Header 中记录了当前页面一共有多少记录、最多可以容纳多少记录、每个记录的实际长度与对齐后的长度等信息。
MiniOB Double Write Buffer 实现
当前MiniOB的问题
因为buffer内的数据页比文件系统的数据页要大,所以在进行刷盘操作时,可能会发生如下场景:
当数据库准备刷新脏页时,需要多次IO才能加数据页全部写入磁盘。
但当执行完第一次IO时,数据库发生意外宕机,导致此时才刷了一个文件系统里的页,这种情况被称为写失效(partial page write)。
此时重启后,磁盘上的页就是不完整的数据页,就算使用redo log也无法进行恢复。
Double Write Buffer解决的问题
在数据库进行脏页刷新时,如果此时宕机,有可能会导致磁盘数据页损坏,丢失我们重要的数据。此时就算重做日志也是无法进行恢复的,因为重做日志记录的是对页的物理修改。
Double Write其实就是在重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是double write。
Double Write Buffer架构
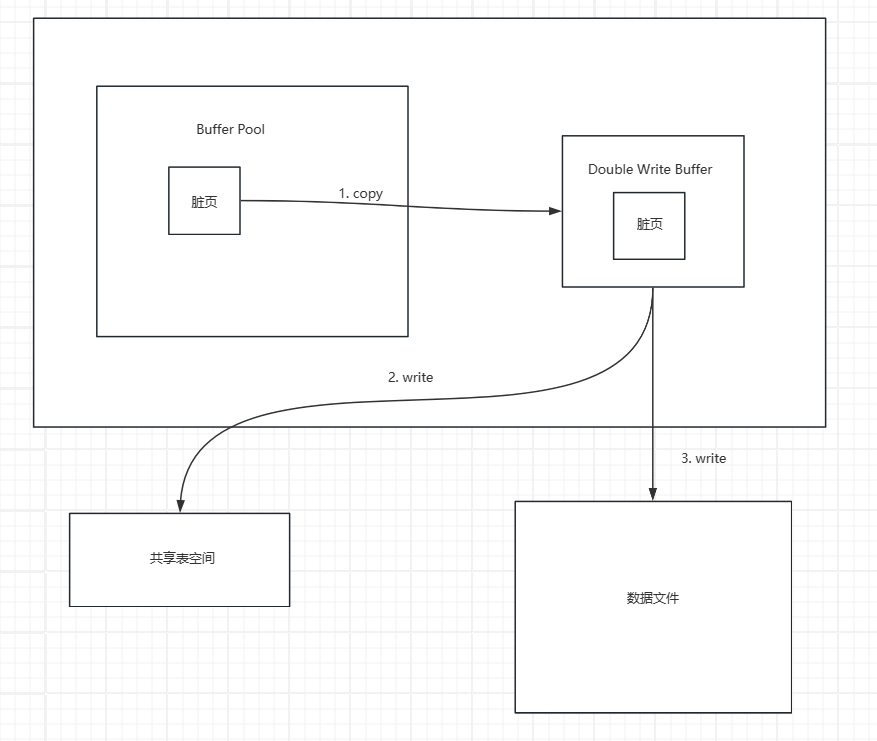
Double Write Buffer 工作流程
- 添加页面 :当buffer pool要刷脏页时,不直接写磁盘,而是把脏页添加到double write buffer中,double write buffer再将页面写入共享表空间。
- 读取页面 :当buffer pool要读取页面时,先查看double write buffer中是否存在该页面,若存在,则直接拷贝,若不存在,则从磁盘中读取页面。
- 写入页面 :当double write buffer装满时,double write buffer会先同步磁盘,防止缓冲写带来的问题。再将页面写入对应的数据文件中。
- 崩溃恢复 :当数据库重启恢复时,先读取共享表空间中的文件,若该页面未损坏,则直接拷贝至磁盘中对应的数据页面,若页面损坏,则忽略该页面。此举可以保证数据库在恢复时数据文件中的页面是完好的。
Double Write Buffer的问题
Double write buffer 它是在物理文件上的一个buffer, 其实也就是file,所以它会导致系统有更多的fsync操作,而因为硬盘的fsync性能问题,所以也会影响到数据库的整体性能。
本篇文档介绍 MiniOB 中的事务模块是如何工作的。
背景
事务是数据库中非常基础的一个模块,也是非常核心的功能。事务有一些基本的概念,叫做ACID,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。如果你对事务的基本概念不太清楚,建议先学习了解事务的基本概念,比如学习事务处理章节,或者在网上搜索更多资料。
MiniOB 中的事务
实现简介
MiniOB 作为一个帮助学习数据库的代码,为了使其学习起来更简单,实现了两种类型的事务。一个叫做Vacuous,另一个叫做MVCC,可以在启动observer时,选择特定的事务模块。
Vacuous(真空)
顾名思义,这个事务模块,将不会做任何事务相关的处理,这保留了原始的简单性,有利于学习其它模块时,简化调试。
MVCC
多版本并发控制,是一种常见的事务实现。著名的MySQL数据库也支持MVCC,OceanBase也实现了此机制。
简单来说,MVCC 会在修改数据——MiniOB当前支持插入和删除——时,不会直接在现有的数据上修改,而是创建一个新的行记录,将旧数据复制出来,在新数据上做修改。并将新旧数据使用链表的方式串联起来。每个数据都会有自己的版本号(或者称为时间戳),而版本号通常使用单调递增的数字表示,每个事务根据自己的版本号与数据的版本号,来判断当前能够访问哪个版本的数据。由此可见,MVCC 一个优点就是可以提高只读事务的并发度,它不与其它的写事务产生冲突,因为它访问旧版本的数据就可以了。
NOTE: 不同的数据库,会有不同的实现方式。对MVCC感兴趣的同学,可以阅读一些相关的论文。
如何运行与测试
当前MiniOB支持两种类型的事务模型,并且默认情况下是Vacuous,即不开启事务特性。
测试MVCC
编译时增加选项 -DCONCURRENCY=ON:
cmake -DCONCURRENCY=ON ..
然后在build目录执行 make。编译完成后启动 observer 服务端进程。
也可以使用 bash build.sh -DCONCURRENCY=ON 来编译
可以在启动observer时,增加 -t mvcc 选项来开启MVCC,假设当前目录是build(或build_debug之类):
./bin/observer -f ../etc/observer.ini -s miniob.sock -t mvcc
-f 是配置文件,-s 指使用unix socket,-t 指定使用的事务模型
启动observer后,可以使用obclient连接observer:
./bin/obclient -s miniob.sock
可以开启多个客户端。在命令行界面执行 begin 可以开启事务,执行 commit 提交事务,rollback 回滚事务。
更多的实现原理
事务代码位于 src/observer/storage/trx 目录下,代码很少。
事务模型选择
trx.h 文件中有一个抽象类 TrxKit,它可以根据运行时参数传入的名字来创建对应的 VacuousTrxKit 和 MvccTrxKit。这两个类可以创建相应的事务对象,并且按照需要,初始化行数据中事务需要的额外表字段。当前 Vacuous 什么字段都不需要,而MVCC会额外使用一些表字段。
事务接口
不同的事务模型,使用了一些统一的接口,这些接口定义在 Trx 中。
事务本身相关的操作
- start_if_need。开启一个事务。在SQL请求处理过程中,通常需要开启一个事务;
- commit。提交一个事务;
- rollback。回滚一个事务。
行数据相关的操作
- insert_record。插入一行数据。事务可能需要对记录做一些修改,然后调用table的插入记录接口。提交之前插入的记录通常对其它事务不可见;
- delete_record。删除一行数据。与插入记录类似,也会对记录做一些修改,对MVCC来说,并不是真正的将其删除,而是让他对其它事务不可见(提交后);
- visit_record。访问一行数据。当遍历记录,访问某条数据时,需要由事务来判断一下,这条数据是否对当前事务可见,或者事务有访问冲突。
MVCC 相关实现
版本号与可见性
与常见的MVCC实现方案相似,这里也使用单调递增的数字来作为版本号。并且在表上增加两个额外的字段来表示这条记录有效的版本范围。两个版本字段是begin_xid和end_xid。每个事务在开始时,就会生成一个自己的版本号,当访问某条记录时,判断自己的版本号是否在该条记录的版本号的范围内,如果在,就是可见的,否则就不可见。
有些文章或者某些数据库实现中,使用"时间戳"来表示版本号。如果可以保证时间戳也是单调递增的,那这个时间戳确实更好可以作为版本号,并且在分布式系统中,比单纯的单调递增数字更好用。
记录版本号与事务版本号
行数据上的版本号,是事务设置的,这个版本号也是事务的版本号。一个写事务,通常会有两个版本号,在启动时,会生成一个版本号,用来在运行时做数据的可见性判断。在提交时,会再生成一个版本号,这个版本号是最终设置在记录上的。
trx start:
trx_id = next_id()
read record: is_visible(trx_id, record_begin_xid, record_end_xid)
trx commit:
commit_id = next_id()
foreach updated record: update record begin/end xid with commit_id
Q:为什么一定要在提交时生成一个新的版本号?只用该事务之前的版本号不行吗?会有什么问题?
版本号与插入删除
新插入的记录,在提交后,它的版本号是 begin_xid = 事务提交版本号,end_xid = 无穷大。表示此数据从当前事务开始生效,对此后所有的新事务都可见。
而删除相反,begin_xid 保持不变,而 end_xid 变成了当前事务提交的版本号。表示这条数据对当前事务之后的新事务,就不可见了。
记录还有一个中间状态,就是事务刚插入或者删除,但是还没有提交时,这里的修改对其它事务应该都是不可见的。比如新插入一条数据,只有当前事务可见,而新删除的数据,只有当前事务不可见。需要使用一种特殊的方法来标记,当然也是在版本号上做动作。对插入的数据,begin_xid 改为 (-当前事务版本号)(负数),删除记录将end_xid改为 (-当前事务版本号)。在做可见性判断时,对负版本号做特殊处理即可。
假设某个事务运行时trx id是 Ta,提交时是 Tc
| operation | trx state | begin xid | end xid |
|---|---|---|---|
| inserted | committed | Tc | +∞ |
| deleted | committed | some trx_id | Tc |
| insert | uncommit | -Ta | +∞ |
| delete | uncommit | some trx_id | -Ta |
并发冲突处理
MVCC很好的处理了只读事务与写事务的并发,只读事务可以在其它事务修改了某个记录后,访问它的旧版本。但是写事务与写事务之间,依然是有冲突的。这里解决的方法简单粗暴,就是当一个写事务想要修改某个记录时,如果看到有另一个事务也在修改,就直接回滚。如何判断其它事务在修改?判断begin_xid或end_xid是否为负数就可以。
隔离级别
我们通常在聊事务隔离级别时,都会说脏读(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和可串行化(Serializable),说这些时也通常都会提到大名鼎鼎的MySQL。但实际上隔离级别不止是这4种。 不过这里也没有对隔离级别做特殊的处理,让它顺其自然。
Q: 通过上面的描述,你知道这里的MVCC是什么隔离级别吗?
遗留问题和扩展
当前的MVCC是一个简化版本,还有一些功能没有实现,并且还有一些已知BUG。同时还可以扩展更多的事务模型。
-
事务提交时,对外原子可见
当前事务在提交时,会逐个修改之前修改过的行数据,调整版本号。这造成的问题是,在某个时刻,有些行数据的版本号已经修改了,有些还没有。那可能会存在一个事务,能够看到已经修改完成版本号的行,但是看不到未修改的行。 比如事务A,插入了3条数据,在提交的时候,逐个修改版本号,某个情况下可能会存在下面的场景(假设A的事务ID是90,commit id是100):
record begin xid end xid data R1 100 +∞ ... R2 100 +∞ ... R3 -90 +∞ ... 此时有一个新的事务,假设事务号是 110,那么它可以看到记录R1和R2,但是看不到R3,因为R3从记录状态来看,还没有提交。
-
垃圾回收
随着数据库进程的运行,不断有事务更新数据,不断产生新版本的数据,会占用越来越多的资源。此时需要一种机制,来回收对任何事务都不再可见的数据,这称为垃圾回收。垃圾回收也是一个很有趣的话题,实现方式有很多种。最常见的是,开启一个或多个后台线程,定期的扫描所有的行数据,检查它们的版本。如果某个数据对当前所有活跃事务都不可见,那就认为此条数据是垃圾,可以回收掉。当然,这种回收方法最简单,也是最低效的,同学们如何优化或者实现新的回收方法。
-
多版本存储
当前miniob仅实现了插入和删除,并不支持更新操作。而插入和删除最多会存在两个版本的数据,从实现上来看,最多需要一条数据就可以。这大大简化了MVCC的实现。但是也因此没有涉及到MVCC非常核心的多版本数据存储问题。如何合理的存储多个版本的数据,对数据库的性能影响也是巨大的。比如多个版本数据串联时,使用从新到旧,还是从旧到新。两种方式都有合理性,适用于不同的场景。另外还有,多版本的数据存储在哪里?内存还是磁盘,是与原有的数据放在同一个存储空间,还是规划单独的空间,各有什么优缺点,都适用于什么场景。还有,更新数据时,复制整行数据,还是仅记录更新的字段。各有什么优缺点,各适用于什么场景。
-
持久化事务
持久性是事务的基本要素之一,是指事务修改后的数据,在数据库重启或者出现异常时,能够从磁盘中将数据恢复出来。除了将修改的数据直接写入到磁盘,还有一个常用的技术手段是WAL,比如Redo日志和Undo日志。那么什么情况下使用Redo,什么时候使用Undo,以及如果只使用Redo或者只使用Undo会有什么问题。另外还有如何存储这些日志,B+树的持久化怎么处理等。有兴趣的同学可以再了解一下
Steal/No-Steal和Force/No-Force的概念。 -
MVCC的并发控制
如前文描述,这里的写事务并发冲突处理过于简单粗暴,以至于可以避免的冲突却没有避免。
-
基于锁的并发控制
MVCC的并发控制通常认为是乐观事务,就是我们认为此系统中事务之间大部分情况下不会存在冲突。但是在OLTP系统中,访问冲突可能是非常频繁发生的,这时候使用悲观事务,效率会更高一点。常见的悲观事务实现方法就是基于锁来实现。假设使用记录锁(行锁)来实现并发,在读数据时加读锁,写时加写锁,也可以实现多种级别的隔离机制。另外,还可以将使用基于锁的机制与MVCC结合起来,实现更好的并发控制。
顺便提一下一个常见的问题,就是在使用行锁时,如何与页面锁(latch)协调? 大家都知道,latch 都是短锁,在latch保护范围内,都不应该出现长期等待的事情。另外,latch没有死锁检测,不处理锁冲突。而行锁是一种长锁,需要做锁冲突处理,可能需要等待。那在拿着某个latch时,需要等待行锁时,如何处理?
这是很多做了CMU 15445课程的同学没有考虑的问题,15445 课程中将
Lock Manager模块单独拎出来让同学们做练习。但是当行锁与latch同时工作时,它的复杂度将提升好几个量级。
进一步学习
事务是非常复杂非常有趣的,相关的话题也已经有非常多的研究。如果对事务感兴趣,可以在了解数据库整体实现基础之上,深入研究事务的实现原理。 这里推荐一些介绍数据库入门的书籍:
- 《数据库系统概念》该书是数据库领域的经典教材之一,涵盖了数据库基本概念、关系型数据库设计、事务处理、并发控制等方面的内容,也可以着重阅读事务相关的内容
- 《数据库系统实现》:该书是一本数据库系统实现方面的教材,讲解了数据库系统的核心组成部分,包括事务处理、索引、查询优化等方面的内容,对事务处理机制进行了较为细致的讲解
- 《MySQL技术内幕:InnoDB存储引擎》:该书是一本MySQL数据库方面的重要教材,对InnoDB存储引擎的事务处理机制进行了详细的阐述,包括事务的隔离级别、MVCC实现、锁机制等方面。
想直接上手看工业届的事务实现原理,欢迎阅读:
内功深厚想要直接阅读源码:OceanBase 事务源码
还有一些著名开放课程,理论结合实践,比如
如果上面的还感觉太浅,可以持续找一些事务的论文研读:
-
A Critique of ANSI SQL Isolation Levels 该论文针对ANSI SQL标准中隔离级别的定义进行了深入的分析,提出了一些改进的建议。天天看到RC/RR名词的,可以看看这篇论文,了解更详细一点。
-
Granularity of Locks and Degrees of Consistency in a Shared Data Base 这也是一个又老又香的论文,提出了基于锁的并发控制。
-
An Empirical Evaluation of InMemory Multi-Version Concurrency Control 介绍MVCC可扩展性的。通过这篇论文可以对MVCC有非常清晰的认识。
-
Scalable Garbage Collection for In-Memory MVCC Systems 这里对各种垃圾回收算法做了说明,并且有些创新算法。
大家看了这些论文会发现,都是一些陈年老论文。数据库领域发展这么多年了,技术依然不过时。
如果这些还不够,可以问问ChatGPT还有啥资料。如果觉得单机上的玩腻了,可以再看看分布式事务,总之希望你能玩得愉快。
本文介绍 MiniOB 中的 clog 模块是如何工作的。
背景
持久化(Durability) 是事务中非常重要的一个模块,也是最复杂的一个模块,实现持久化才能保证数据不丢失。而持久化同时还要保证事务的原子性与数据完整性。如果对事务的一些概念不太了解,建议先学习了解事务的基本概念,比如学习事务处理章节,或者在网上搜索更多资料。
MiniOB 日志设计与实现
实现简介
MiniOB 本身使用堆表保存数据,B+树作为索引基础结构。与传统数据库一样,使用 buffer pool manager 管理堆表与索引数据在内存与磁盘中的存放。我们将表数据文件和索引文件(B+树),都使用分页模式进行管理,即在磁盘存储时,它是一个大文件,在读取和写入时,都按照固定大小的页来操作。当我们对数据库数据做修改时,不管修改的内容比较多(几十兆字节)还是比较少(几个字节),我们都会按照修改数据内容所在页面为单元进行操作,包括数据在内存中的修改、持久化到磁盘以及记录相关的日志。当我们对文件内容进行修改时,就会先记录日志,称为Writing Ahead Log(WAL),每次修改后的页面刷新到磁盘之前,都确保对应的日志已经写入到磁盘。
如何运行与测试
以mvcc模式启动miniob:
./bin/observer -f ../etc/observer.ini -s miniob.sock -t mvcc -d disk
其中 -d 参数指定了记录日志的方式,disk 表示将日志记录到磁盘中,vacuous 表示不记录日志。
客户端连接做操作,就可以看到 miniob/db/sys/clog 文件在增长。
如何测试日志恢复流程?
observer运行过程中产生了一些日志,这时执行 kill -9 pidof observer 将服务端进行强制杀死,然后再使用上面的启动命令将服务端启动起来即可。启动时,就会进入到恢复流程。
可以使用 clog_dump 程序读取日志文件,查看日志内容。
(base) build_debug $ ./bin/clog_dump miniob/db/sys/clog/clog_0.log
begin dump file miniob/db/sys/clog/clog_0.log
lsn=1, size=12, module_id=3:TRANSACTION, operation_type:2:COMMIT, trx_id:1, commit_trx_id: 2
lsn=2, size=12, module_id=0:BUFFER_POOL, buffer_pool_id=1, page_num=1, operation_type=0:ALLOCATE
lsn=3, size=16, module_id=2:RECORD_MANAGER, buffer_pool_id:1, operation_type:0:INIT_PAGE, page_num:1, record_size:20
lsn=4, size=36, module_id=2:RECORD_MANAGER, buffer_pool_id:1, operation_type:1:INSERT, page_num:1, slot_num:0
lsn=5, size=20, module_id=3:TRANSACTION, operation_type:0:INSERT_RECORD, trx_id:3, table_id: 0, rid: PageNum:1, SlotNum:0
lsn=6, size=36, module_id=2:RECORD_MANAGER, buffer_pool_id:1, operation_type:3:UPDATE, page_num:1, slot_num:0
lsn=7, size=12, module_id=3:TRANSACTION, operation_type:2:COMMIT, trx_id:3, commit_trx_id: 4
lsn=8, size=36, module_id=2:RECORD_MANAGER, buffer_pool_id:1, operation_type:1:INSERT, page_num:1, slot_num:1
lsn=9, size=20, module_id=3:TRANSACTION, operation_type:0:INSERT_RECORD, trx_id:5, table_id: 0, rid: PageNum:1, SlotNum:1
设计与实现
MiniOB 的持久化模块代码放在 clog 目录中。 CLog 的命名取自 OceanBase 中的日志模块,全称是 commit log。
日志模块设计
日志接口
日志模块对外的接口是 LogHandler,它定义了日志的写入、读取、恢复等接口。有两个实现模式,一个是 DiskLogHandler,一个是 VacuousLogHandler。前者是将日志写入到磁盘中,后者是不记录日志。VacuousLogHandler 虽然也是当前默认的日志记录方式,但它主要是为了方便测试。我们这里只介绍 DiskLogHandler。
日志写入
在程序正常运行过程中,调用DiskLogHandler 的append接口,将日志写入到日志缓冲区(LogEntryBuffer)。DiskLogHandler会启动一个后台线程,不停地将日志缓冲区中的日志写入到磁盘中。
日志缓冲
日志缓冲 LogEntryBuffer 的设计很简单,使用一个列表来记录每条日志。这里是一个优化点,感兴趣的同学欢迎提交PR。
日志文件
为了防止单个日志文件过大,DiskLogHandler 在每个日志文件中存放固定个数的日志,当日志文件满了,会创建新的日志文件。日志文件的命名规则是 clog_0.log、clog_1.log、clog_2.log...。管理日志文件的类是 LogFileManager,负责创建文件、枚举日志文件等,LogFileWriter 负责将日志写入文件,LogFileReader 负责从文件中读取日志。注意,当前没有删除日志文件的接口。
日志内容
日志文件中存放的是一条条数据,写入的时候也是一条条写入的,那这一条日志在代码中就是 LogEntry。一个 LogEntry 包含一个日志头 LogHeader。一个日志头包含日志序列号LSN、不包含日志头的数据大小(size)和日志所属模块(module_id)。
日志序列号 LSN: Log Sequence Number,一个单调递增的数字,每生成一条新的日志,就会加1。并且在对应的磁盘文件页面中,也会记录页面对应日志编号。这样从磁盘恢复时,如果某个页面的LSN比当前要重做的日志LSN要小,就需要重做,否则就不需要重做。
日志数据大小 size: 不包含日志头的日志大小,在 LogEntry 中,通过 payload_size 获取。
日志所属模块 module_id: 持久化模块不仅仅为事务服务,其它的模块,比如B+树,也需要依赖日志来保证数据的完整性和一致性。我们将日志按照模块来划分,在重做时各个模块处理自己的数据。
当前一共有四个模块(参考 LogModule),每个模块负责组织自己的数据内容。在LogEntry中都表述为一个二进制数组 data,在读取和重放时,每个模块自己负责解析具体的数据。
系统快照
我们为了防止日志无限增长,或者减少日志恢复时间,会以不同的方式创建一个系统快照,我们就可以把日志快照之前的日志清除或减少日志恢复时间。
MiniOB的系统快照是在当前没有任何页面更新操作时执行的,其将所有的表相关的文件数据都刷新到磁盘中,然后记录当前日志编号(LSN),作为一次完整的系统快照,代码可以参考 Db::sync。
每次执行完一个DDL任务时,就会执行一次快照操作。 注意,执行快照时(包括DDL),由操作者自己确保当前没有其它任何正在进行的操作,比如插入、删除以及其他的DDL。MiniOB当前并没有做DDL相关的并发控制。
日志重做
当系统出现异常,比如coredump、掉电等,重启后,需要读取本次磁盘中的日志来恢复没有写入磁盘文件中的数据。
通常我们会从一个一致性点开始读取日志重做,一致性点就是最新的一次系统快照。
重做的过程比较简单,我们会把每条日志读取出来(DiskLogHandler::replay),按照日志头中的模块来划分执行每个模块的重放接口(IntegratedLogReplayer::replay)。
Buffer Pool 模块的日志
Buffer Pool 模块对页面数据几乎没有修改,除了分配新的页面和释放页面。Buffer Pool会将文件的第一个页面当做元数据页面,记录当前文件大小、页面分配情况等,也就是说Buffer Pool需要记录的日志有两类(BufferPoolOperation):分配页面、释放页面,并且修改的页面都是第一个页面。我们实现了一个辅助类来帮助记录相关的日志 BufferPoolLogHandler。
Record Manager 模块的日志
Record Manager 负责在表普通数据上进行增删改查记录,也就是行数据管理。除了增删改会对页面进行修改,Record Manager还增加了一类特殊的日志,就是初始化空页面。与 Buffer Pool 日志实现类似,Record Manager 的日志实现在 record_log.h/.cpp 文件中。
B+ 树模块的日志
相对于Buffer Pool和Record Manager来说,B+树的日志要复杂很多。因为Buffer Pool和Record Manager每次修改数据时不会超过一个页面,那我们使用一条简单的日志就可以保证数据的完整性。但是B+树不同,B+树的一次修改可能会涉及多个页面。比如一次插入操作,如果叶子节点满了,就需要分裂成两个页面,然后在它们的父节点上插入一个节点,此时父节点也可能会满导致需要分裂。依次类推,一个插入操作可能会影响多个页面。而我们必须要保证在程序运行时和异常宕机重启通过日志恢复后,还能保持一致性,即这个操作完全执行成功,所有受到影响的页面都恢复,或者恢复到这个操作没有执行的状态,相当于没有插入过这条数据。
MiniOB的解决方法很简单。在每次操作过程中,所有更新过的页面在操作结束之前,都不会刷新到磁盘中。并且我们会把所有页面更新的数据都记录到一个日志中,并且在记录日志时,同时记录页面更新前的数据在内存中,即undo日志。这样,如果某次操作中间过程由于某种原因失败了,我们可以通过undo日志将数据都恢复过来。在宕机重启时,我们每次重做一条B+树日志,也可以完整的恢复出一个操作相关联的所有数据。
将一次操作所有的更新都记录在一个日志中,并可以保证一次操作要么全部成功要么全部失败,我们称为一个MiniTransaction,可以参考代码 BplusTreeMiniTransaction。在其它数据库中,我们也可以看到类似的概念,比如InnoDB中的mini trans,还有些系统称之为系统事务,与用户事务区分开。
B+树涉及到需要记录日志的类型很多,可以参考 bplus_tree::LogOperation。由于每个类型的大小和具体数据都不一样,我们使用各种 Handler 辅助类来帮助序列化反序列化日志,可以参考 LogEntryHandler及其子类。与Buffer Pool和Record Manager不同,这个类增加了 rollback 接口,用于在运行过程中利用Undo数据执行回滚操作。
事务日志
相对于前面介绍的几个模块的日志,事务日志是完全不同的一个层面的内容。Buffer Pool 等模块记录日志是为了确保系统底层数据不会出现不一致的情况,是系统“自己”发起的。而事务不同,事务是用户发起的。事务日志相对于前面几个“系统”日志,有几个不同的地方:
- 由用户发起的,除了系统方面的原因需要回滚,提交或回滚由用户控制的;
- 理论上持续时间任意长。用户可能开启一个事务,但是长时间不提交;
- 事务日志不关联具体的页面,而系统日志都与具体的页面数据修改相关;
- 事务的大小不确定。系统日志通常都是很小的,但是事务日志可能会很大,比如用户增加或删除了几千万条数据。
MiniOB 的事务日志并没有记录每次操作具体的数据,而只是记录操作了什么,比如插入了一条数据,会记录在哪个表的哪个位置上插入了一条数据。具体的数据日志是在Record Manager中记录的。也就是说,整个事务日志是一个逻辑日志,而不是物理日志。同时,MiniOB的整个日志系统是分层的,事务日志依赖Record Manager和B+树,而这两个模块会依赖Buffer Pool。
MiniOB 提供了两种事务模型,MVCC(MvccTrx)和Vacuous(VacuousTrx)。MVCC是多版本并发控制,Vacuous本意是不支持事务,因此也不会记录事务日志。这里仅介绍MVCC模式下的事务日志。
MVCC 相关的日志代码可以参考 mvcc_trx_log.h/.cpp。在一个事务中,我们记录用户执行过什么,比如插入一条数据、删除一条数据与提交或回滚事务,操作类型参考 MvccTrxLogOperation。每条事务日志会包含一个事务头 MvccTrxLogHeader,记录事务ID、操作类型等。在事务提交时,一定会等对应的所有事务日志都写入到磁盘中后,才会返回。
与B+树操作类似,事务也有提交和回滚的概念。但是它们的实现方式不同。通常我们认为,B+树涉及到的数据量比较少,所有操作过的数据,会记录undo日志在内存中,在操作过程中,不会记录日志到磁盘上,在提交时,也不会强制要求将对应的日志刷新到磁盘上。而事务日志不同,因为事务日志的大小不确定、持续时间不确定,我们会在操作执行过程中就会生成一条条日志,通过日志模块写入到缓冲区或者磁盘上。在提交时,为了给用户保证提交的事务不丢失,也必须等日志写入磁盘后再返回。由于在进行过程中就有一部分日志会写入到磁盘上,所以即使事务失败了,我们也会记录一条回滚的日志。
事务的重做
由于事务日志中并不真正的记录修改过的数据,只是记录做过什么操作,也只有不完整的事务,才需要做回滚操作。不完整的事务回滚时,将曾经做过的操作执行一遍逆过程即可。完整的事务,不需要做任何动作,因为不管是提交还是回滚,它的动作都已经真实的处理过了。重做的代码可以参考 MvccTrxLogReplayer 和事务相关的代码 MvccTrx::redo。
一些缺陷和遗留问题
页面丢失的风险
当前设计的分层设计,事务依赖Record Manager和B+树,Record Manager和B+树依赖Buffer Pool,让整体上看起来更清晰,代码也更简单,但是隐藏了一个问题。各层之间的配合与衔接就会出现一些问题。 比如Record Manager中插入了一条数据,此时我们需要申请一个新的页面。那么在日志中会记录:
- Buffer Pool分配了一个新的页面;
- Record Manager初始化了这个页面;
- Record Manager插入了一条数据。
假设在Record Manager在第2步时失败了,我们就会丢失一个页面。因为第2步的失败,是不会回滚第1步的操作,我们并没有把整个操作当做一个事务来处理。这个问题在B+树中也会出现。
日志缓冲设计过于简单
日志缓冲直接放在日志中,没有内存限制,可能会导致内存膨胀。 日志按条缓存,会导致内存碎片,对内存不友好。
页面原子写入问题
一个页面不管是8K还是4K,都存在原子写入问题,即我们现在无法保证一个页面完整的刷新到磁盘上。如果一个页面只写一半在磁盘上,会导致无法判断的一致性问题。这个问题在MySQL中也出现过。
日志文件删除问题
当前没有删除日志文件的接口,会导致日志文件无限增长。
写一半的日志
假设某个日志写入一半的时候停电了,那这个日志在恢复时肯定会失败。如果我们不对这条日志做处理,后面的日志接着文件写,后续这个日志文件就不能再恢复了。通常的处理方法是把这条日志给truncate掉。
扩展
-
ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging 该论文提出了ARIES算法,这是一种基于日志记录的恢复算法,支持细粒度锁和部分回滚,可以在数据库崩溃时恢复事务。如果想要对steal/no-force的概念有比较详细的了解,可以直接阅读该论文相关部分。
-
Shadow paging 除了日志做恢复,Shadow paging 是另外一种做恢复的方法。
-
Aether: A Scalable Approach to Logging 介绍可扩展日志系统的。
-
InnoDB之REDO LOG 非常详细而且深入的介绍了一下InnoDB的redo日志。
-
B+树恢复 介绍如何恢复B+树。
-
Principles and realization strategies of multilevel transaction management 介绍了多层事务管理的原理和实现策略。
这部分内容会介绍一些如何对miniob中的词法语法分析模块进行开发与调试,以及依赖的工具。
简介
SQL 解析分为词法分析与语法分析,与编译原理中介绍的类似。这里主要介绍如何扩展MiniOB的SQL解析器,并对词法分析和语法分析文件做一些简单的介绍。
词法分析
词法分析文件 lex_sql.l
词法分析的基本功能是读取文件或字符串的一个一个字符,然后按照特定的模式(pattern)去判断是否匹配,然后输出一个个的token。比如对于 CALC 1+2,词法分析器会输出 CALC、1、+、2、EOF。
扩展功能时,我们最关心的是词法分析的模式如何编写以及flex如何去执行模式解析的。 在lex_sql.l文件中,我们可以看到这样的代码:
[\-]?{DIGIT}+ yylval->number=atoi(yytext); RETURN_TOKEN(NUMBER);
HELP RETURN_TOKEN(HELP);
DESC RETURN_TOKEN(DESC);
CREATE RETURN_TOKEN(CREATE);
DROP RETURN_TOKEN(DROP);
每一行都是一个模式,左边是模式,使用正则表达式编写,右边是我们返回的token,这里的token是枚举类型,是我们在yacc_sql.y中定义的。
[\-]?{DIGIT}+ 就是一个表示数字的正则表达式。
HELP 表示完全匹配"HELP" 字符串。
flex 在匹配这些模式时有一些规则,如果输出的结果与自己的预期不符,可以使用这些规则检查一下,是否自己写的模式和模式中的顺序是否符合这些规则:
- 优先匹配最长的模式
- 如果有多个模式匹配到同样长的字符串,那么优先匹配在文件中靠前的模式
另外还有一些词法分析的知识点,都在lex_sql.l中加了注释,不多做赘述,在这里罗列提示一下。
- flex 根据编写的 .l 规则文件,和指定的命令生成.c代码。不过miniob把.c文件改成了.cpp后缀;
%top{}的代码会放在flex生成的代码最开头的地方;%{ %}中的代码会被移动到flex生成的代码中;- flex提供了一些选项,可以在命令行中指定,也可以在.l文件中,使用 %option指定;
- flex 中编写模式时,有一些变量是预定义的,yylval就是返回值,可以认为是yacc中使用%union定义的结构; yytext 是解析的当前token的字符串,yyleng 是token的长度,yycolumn 是当前的列号,yylineno 是当前行号;
- 如果需要每个token在原始文本中的位置,可以使用宏定义 YY_USER_ACTION,但是需要自己编写代码记录才能传递给yacc;
%% %%之间的代码是模式匹配代码,之后的代码会被复制到生成代码的最后。
语法分析
语法分析文件 yacc_sql.y
语法分析的基本功能是根据词法分析的结果,按照语法规则,生成语法树。
与词法分析类似,语法分析工具(这里使用的是bison)也会根据我们编写的.y规则文件,生成.c代码,miniob 这里把.c代码改成了.cpp代码,因此.y文件中可以使用c++的语法和标准库。
类似词法分析,我们在扩展语法分析时,最关心的也只有规则编写的部分。
在yacc_sql.y文件中,我们可以看到这样的代码:
expression_list:
expression
{
$$ = new std::vector<Expression*>;
$$->emplace_back($1);
}
| expression COMMA expression_list {
if ($3 != nullptr) {
$$ = $3;
} else {
$$ = new std::vector<Expression *>;
}
$$->emplace_back($1);
}
;
这个规则描述表达式列表的语法,表达式列表可以是单个表示,或者"单个表达式 逗号 表达式列表"的形式,第二个规则是一个递归的定义。 可以看到,多个规则模式描述使用 "|" 分开。
为了方便说明,我这里再换一个语句:
create_table_stmt: /*create table 语句的语法解析树*/
CREATE TABLE ID LBRACE attr_def attr_def_list RBRACE
{
$$ = new ParsedSqlNode(SCF_CREATE_TABLE);
CreateTableSqlNode &create_table = $$->create_table;
create_table.relation_name = $3;
free($3);
std::vector<AttrInfoSqlNode> *src_attrs = $6;
if (src_attrs != nullptr) {
create_table.attr_infos.swap(*src_attrs);
}
create_table.attr_infos.emplace_back(*$5);
std::reverse(create_table.attr_infos.begin(), create_table.attr_infos.end());
delete $5;
}
;
每个规则描述,比如create_table_stmt 都会生成一个结果,这个结果在.y中以 "$$" 表示,某个语法中描述的各个token,按照顺序可以使用 "$1 $2 $3" 来引用,比如ID 就是 $3, attr_def 是 $5。"$n" 的类型都是 YYSTYPE。YYSTYPE 是bison根据.y生成的类型,对应我们的规则文件就是 %union,YYSTYPE 也是一个union结构。比如 我们在.y文件中说明 %type <sql_node> create_table_stmt,表示 create_table_stmt 的类型对应了 %union 中的成员变量 sql_node。我们在 %union 中定义了 ParsedSqlNode * sql_node;,那么 create_table_stmt 的类型就是 ParsedSqlNode *,对应了 YYSTYPE.sql_node。
%union 中定义的数据类型,除了简单类型,大部分是在parse_defs.h中定义的,表达式Expression是在expression.h中定义的,Value是在value.h中定义的。
由于在定义语法规则时,这里都使用了左递归,用户输入的第一个元素会放到最前面,因此在计算得出最后的结果时,我们需要将列表(这里很多使用vector记录)中的元素逆转一下。
语法分析中如何使用位置信息
首先我们要在.y文件中增加%locations,告诉bison我们需要位置信息。其次需要与词法分析相配合,需要词法分析返回一个token时告诉语法分析此token的位置信息,包括行号、token起始位置和结束位置。与访问规则结果 $$ 类似,访问某个元素的位置信息可以使用 @$、 @1、@2 等。
词法分析中,yylineno记录当前是第几行,不过MiniOB当前没有处理多行文本。yycolumn记录当前在第几列,yyleng记录当前token文本的长度。词法分析提供了宏定义 YY_USER_INIT 可以在每次解析之前执行一些代码,而 YY_USER_ACTION 宏在每次解析完token后执行的代码。我们可以在YY_USER_INIT宏中对列号进行初始化,然后在YY_USER_ACTION计算token的位置信息,然后使用 yylloc 将位置信息传递给语法分析。而在引用 @$ 时,就是引用了 yylloc。
这些宏定义和位置的引用可以参考lex_sql.l和yacc_sql.y,搜索相应的关键字即可。
如果觉得位置信息传递和一些特殊符号 $$或 @$ 等使用感到困惑,可以直接看 flex和bison生成的代码,会让自己理解的更清晰。
如何编译词法分析和语法分析模块
在 src/observer/sql/parser/ 目录下,执行以下命令:
./gen_parser.sh
将会生成词法分析代码 lex_sql.h 和 lex_sql.cpp,语法分析代码 yacc_sql.hpp 和 yacc_sql.cpp。
注意:flex 使用 2.5.35 版本测试通过,bison使用3.7版本测试通过(请不要使用旧版本,比如macos自带的bision)。
注意:当前没有把lex_sql.l和yacc_sql.y加入CMakefile.txt中,所以修改这两个文件后,需要手动生成c代码,然后再执行编译。
如果使用visual studio code,可以直接选择 "终端/Terminal" -> "Run task..." -> "gen_parser",即可生成代码。
如何调试词法分析和语法分析模块
代码中可以直接使用日志模块打印日志,对于yacc_sql.y也可以直接使用gdb调试工具调试。
参考
本文介绍如何新增一种类型的SQL语句。
当前的SQL实现已经比较复杂,这里以新增一个简单的SQL语句为例,介绍如何新增一种类型的SQL语句。 在介绍如何新增一种类型的SQL语句之前,先介绍一下MiniOB的SQL语句的执行流程。
SQL语句执行流程
MiniOB的SQL语句执行流程如下图所示:
左侧是执行流程节点,右侧是各个执行节点输出的数据结构。
┌──────────────────┐ ┌──────────────────┐
│ SQL │ ---> │ String │
└────────┬─────────┘ └──────────────────┘
│
┌────────▼─────────┐ ┌──────────────────┐
│ Parser │ ---> │ ParsedSqlNode |
└────────┬─────────┘ └──────────────────┘
│
│
┌────────▼─────────┐ ┌──────────────────┐
│ Resolver │ ---> │ Statement │
└────────┬─────────┘ └──────────────────┘
│
│
┌────────▼─────────┐ ┌──────────────────┐
│ Transformer │ ---> │ LogicalOperator |
└────────┬─────────┘ │ PhysicalOperator │
│ │ or │
┌────────▼─────────┐ │ CommandExecutor |
│ Optimizer │ ---> │ │
└────────┬─────────┘ └──────────────────┘
│
┌────────▼─────────┐ ┌──────────────────┐
│ Executor │ ---> │ SqlResult │
└──────────────────┘ └──────────────────┘
- 我们收到了一个SQL请求,此请求以字符串形式存储;
- 在Parser阶段将SQL字符串,通过词法解析(lex_sql.l)与语法解析(yacc_sql.y)解析成ParsedSqlNode(parse_defs.h);
- 在Resolver阶段,将ParsedSqlNode转换成Stmt(全称 Statement, 参考 stmt.h);
- 在Transformer和Optimizer阶段,将Stmt转换成LogicalOperator,优化后输出PhysicalOperator(参考 optimize_stage.cpp)。如果是命令执行类型的SQL请求,会创建对应的 CommandExecutor(参考 command_executor.cpp);
- 最终执行阶段 Executor,工作量比较少,将PhysicalOperator(物理执行计划)转换为SqlResult(执行结果),或者将CommandExecutor执行后通过SqlResult输出结果。
新增一种类型的SQL语句
这里将以CALC类型的SQL为例介绍。
CALC 不是一个标准的SQL语句,它的功能是计算给定的一个四则表达式,比如:
CALC 1+2*3
CALC 在SQL的各个流程中,与SELECT语句非常类似,因此在增加CALC语句时,可以参考SELECT语句的实现。
首先在Parser阶段,我们需要考虑词法分析和语法分析。CALC 中需要新增的词法不多,简单的四则运算中只需要考虑数字、运算符号和小括号即可。在增加CALC之前,只有运算符号没有全部增加,那我们加上即可。参考 lex_sql.l。
"+" |
"-" |
"*" |
"/" { return yytext[0]; }
在语法分析阶段,我们参考SELECT相关的一些解析,在yacc_sql.y中增加CALC的一些解析规则,以及在parse_defs.h中SELECT解析后的数据类型,编写CALC解析出来的数据类型。 当前CALC是已经实现的,可以直接在parse_defs.h中的类型定义。 yacc_sql.y中需要增加calc_stmt,calc_stmt的类型,以及calc_stmt的解析规则。由于calc_stmt涉及到表达式运算,所以还需要增加表达式的解析规则。具体可以参考yacc_sql.y中关于calc的代码。
在语法解析结束后,输出了CalcSqlNode,后面resolver阶段,将它转换为Stmt,这里就是新增CalcStmt。通常在resolver阶段会校验SQL语法树的合法性,比如查询的表是否存在,运算类型是否正确。在CalcStmt中,逻辑比较简单,没有做任何校验,只是将表达式记录下来,并且认为这里的表达式都是值类型的计算。
在Transformer和Optmize阶段,对于查询类型的SQL会生成LogicalOperator和PhysicalOperator,而对于命令执行类型的SQL会生成CommandExecutor。CALC是查询类型的SQL,参考SELECT的实现,在SELECT中,有PROJECT、TABLE_SCAN等类型的算子,而CALC比较简单,我们新增CalcLogicalOperator和CalcPhysicalOperator。
由于具有执行计划的SQL,在Executor阶段,我们仅需要给SqlResult设置对应的TupleSchema即可,可以参考ExecuteStage::handle_request_with_physical_operator。
总结一下,新增一种类型的SQL,需要在以下几个地方做修改:
- 词法解析,增加新的词法规则(lex_sql.l);
- 语法解析,增加新的语法规则(yacc_sql.y);
- 增加新的SQL语法树类型(parse_defs.h);
- 增加新的Stmt类型(stmt.h);
- 增加新的LogicalOperator和PhysicalOperator(logical_operator.h, physical_operator.h, optimize_stage.cpp,如果有需要);
- 增加新的CommandExecutor(command_executor.cpp,如果有需要);
- 设置SqlResult的TupleSchema(execute_stage.cpp,如果有需要)。
本文介绍如何解析表达式
介绍
表达式是SQL操作中非常基础的内容。
我们常见的表达式就是四则运算的表达式,比如1+2、3*(10-3)等。在常见的数据库中,比如MySQL、OceanBase,可以运行 select 1+2、select 3*(10-3),来获取这种表达式的结果。但是同时在SQL中,也可以执行 select 1、select field1 from table1,来查询一个常量或者一个字段。那我们就可以把表达式的概念抽象出来,认为常量、四则运算、表字段、函数调用等都是表达式。
MiniOB 中的表达式实现
当前MiniOB并没有实现上述的所有类型的表达式,而是选择扩展SQL语法,增加了 CALC 命令,以支持算术表达式运算。这里就以 CALC 支持的表达式为例,介绍如何在 MiniOB 中实现表达式。
本文的内容会有一部分与 如何新增一种类型的SQL语句 重复,但是这里会更加详细的介绍表达式的实现。
这里假设大家对 MiniOB 的SQL运行过程有一定的了解,如果没有,可以参考 如何新增一种类型的SQL语句 的第一个部分。
在介绍实现细节之前先看下一个例子以及它的执行结果:
CALC 1+2
执行结果:
1+2
3
注意这个表达式输出时会输出表达式的原始内容。
SQL 语句
MiniOB 从客户端接收到SQL请求后,会创建 SessionEvent,其中 query_ 以字符串的形式保存了SQL请求。
比如 CALC 1+2,记录为"CALC 1+2"。
SQL Parser
Parser部分分为词法分析和语法分析。
如果对词法分析语法分析还不了解,建议先查看 SQL Parser。
词法分析
算术表达式需要整数、浮点数,以及加减乘除运算符。我们在lex_sql.l中可以看到 NUMBER 和 FLOAT的token解析。运算符的相关模式匹配定义如下:
"+" |
"-" |
"*" |
"/" { return yytext[0]; }
语法分析
因为 CALC 也是一个完整的SQL语句,那我们先给它定义一个类型。我们定义一个 CALC 语句可以计算多个表达式的值,表达式之间使用逗号分隔,那 CalcSqlNode 定义应该是这样的:
struct CalcSqlNode
{
std::vector<Expression *> expressions;
};
在 yacc_sql.y 文件中,我们增加一种新的语句类型 calc_stmt,与SELECT类似。它的类型也是sql_node:
%type <sql_node> calc_stmt
接下来分析 calc_stmt 的语法规则。
calc_stmt:
CALC expression_list
{
$$ = new ParsedSqlNode(SCF_CALC); // CALC的最终类型还是一个ParsedSqlNode
std::reverse($2->begin(), $2->end()); // 由于左递归的原因,我们需要得出列表内容后给它反转一下
// 直接从 expression_list 中拿出数据到目标结构中,省的再申请释放内存
$$->calc.expressions.swap(*$2);
delete $2; // expression_list 本身的内存不要忘记释放掉
}
;
CALC expression_list CALC 仅仅是一个关键字。expression_list 是表达式列表,我们需要对它的规则作出说明,还要在%union和 %type 中增加其类型说明。
%union {
...
std::vector<Expression *> *expression_list;
...
}
...
%type <expression_list> expression_list
expression_list 的规则如下:
expression_list:
expression // 表达式列表可以是单个表达式
{
$$ = new std::vector<Expression*>;
$$->emplace_back($1);
}
// 表达式列表也可以是逗号分隔的多个表达式,使用递归定义的方式说明规则
| expression COMMA expression_list
{
if ($3 != nullptr) {
$$ = $3;
} else {
$$ = new std::vector<Expression *>; // 表达式列表的最终类型
}
$$->emplace_back($1); // 目标结果中多了一个元素。
}
;
expression 的规则会比较简单,加减乘除,以及负号取反。这里与普通的规则不同的是,我们需要关心运算符的优先级,以及负号运算符的特殊性。
优先级规则简单,乘除在先,加减在后,如果有括号先计算括号的表达式。
%left '+' '-'
%left '*' '/'
%left 表示左结合,就是遇到指定的符号,先跟左边的符号结合。而定义的顺序就是优先级的顺序,越靠后的优先级越高。
负号运算符的特殊性除了它的优先级,还有它的结合性。普通的运算,比如 1+2,是两个数字即两个表达式,一个运算符。而负号的表示形式是 -(1+2),即一个符号,一个表达式。
%nonassoc UMINUS
表示 UMINUS 是一个一元运算符,没有结合性。在.y中,放到了 %left '*' '/' 的后面,说明优先级比乘除运算符高。
expression 的规则如下:
expression '+' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::ADD, $1, $3, sql_string, &@$);
}
| expression '-' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::SUB, $1, $3, sql_string, &@$);
}
| expression '*' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::MUL, $1, $3, sql_string, &@$);
}
| expression '/' expression {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::DIV, $1, $3, sql_string, &@$);
}
| LBRACE expression RBRACE { // '(' expression ')'
$$ = $2;
$$->set_name(token_name(sql_string, &@$));
}
// %prec 告诉yacc '-' 负号预算的优先级,等于UMINUS的优先级
| '-' expression %prec UMINUS {
$$ = create_arithmetic_expression(ArithmeticExpr::Type::NEGATIVE, $2, nullptr, sql_string, &@$);
}
| value {
$$ = new ValueExpr(*$1);
$$->set_name(token_name(sql_string, &@$));
delete $1;
}
;
create_arithmetic_expression 是一个创建算术表达式的函数,它的实现在.y文件中,不再罗列。
表达式的名称,需要在输出结果中展示出来。我们知道当前的SQL语句,也知道某个token的开始列号与截止列号,就可以计算出来这个表达式对应的SQL命令输入是什么。在 expression 规则描述中,就是 $$->set_name(token_name(sql_string, &@$));,其中 sql_string 就是当前的SQL语句,@$ 是当前的token的位置信息。
抽象表达式类型
上面语法分析中描述的都是算术表达式,但是真实的SQL语句中,像字段名、常量、比较运算、函数、子查询等都是表达式。我们需要定义一个基类,然后派生出各种表达式类型。
这些表达式的定义已经在expression.h中定义,但是没有在语法解析中体现。更完善的做法是在 select 的属性列表、where 条件、insert 的 values等语句中,都使用表达式来表示。
'-' 缺陷
由于在词法分析中,负号'-'与数字放在一起时,会被认为是一个负值数字,作为一个完整的token返回给语法分析,所以当前的语法分析无法正确的解析下面的表达式:
1 -2;
这个表达式的结果应该是 -1,但是当前的语法分析会认为是两个表达式,一个是1,一个是-2,这样就无法正确的计算出结果。 当前修复此问题的成本较高,需要修改词法分析的规则,所以暂时不做处理。
MiniOB B+Tree 实现
简介
在基本的逻辑上,MiniOB 的 B+Tree 和 B+Tree 是一致的,查询和插入都是从根逐层定位到叶结点,然后在叶结点内获取或者插入。如果插入过程发生叶结点满的情况,同样会进行分裂,并向上递归这一过程。
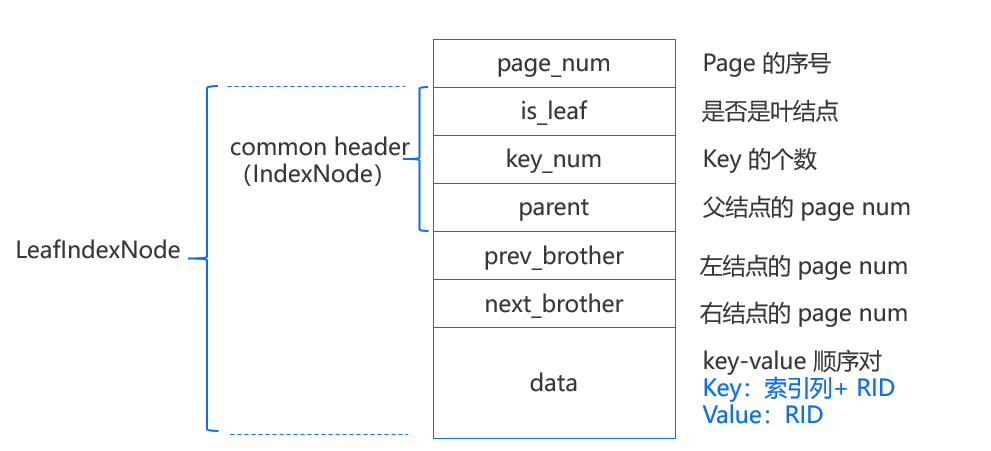
如上图,每个结点组织成一个固定大小的 page,之前介绍过每个 page 首先有一个 page_num 表示 page 在文件中的序号,每个结点 page 都有一个common header 实现为 IndexNode 结构,其中包括 is_leaf(是否为叶结点)、key_num(结点中 key 的个数)、parent(结点父结点的 page num),当 parent=-1 时表示该结点没有父结点。
除此之外,Leaf page 还有 prev_brother(左结点的 page num)和 next_brother(右结点的 page num),这两项用于帮助遍历。最后 page 所剩下的空间就顺序存放键值对,叶结点所存放的 key 是索引列的值加上 RID(该行数据在磁盘上的位置),Value 则为 RID,也就是说键值数据都是存放在叶结点上的,和 B+Tree 中叶结点的值是指向记录的指针不同。
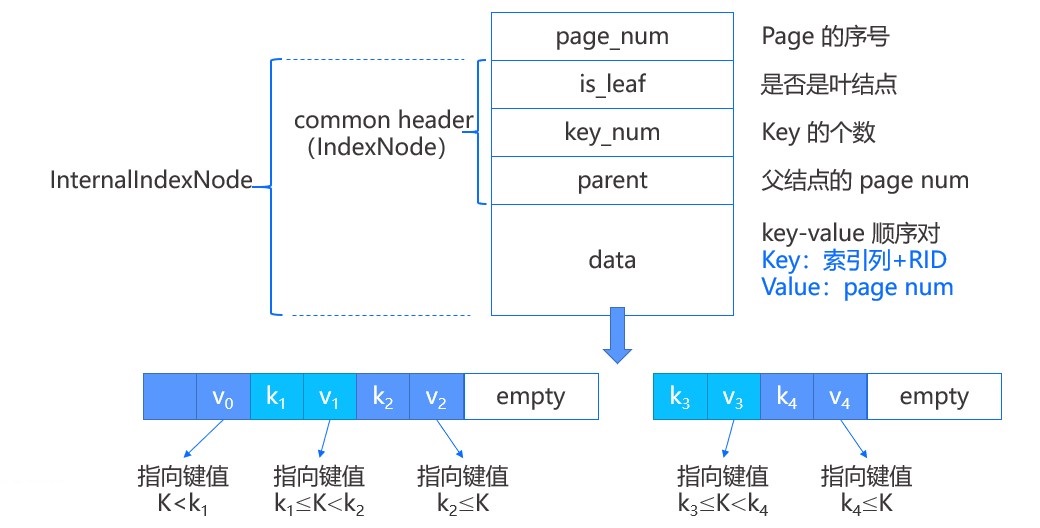
内部结点和叶结点有两点不同,一个是没有左右结点的 page num;另一个是所存放的值是 page num,也就是标识了子结点的 page 位置。如上图所示,键值对在内部结点是这样表示的,第一个键值对中的键是一个无效数据,真正用于比较的只有 k1 和 k2。
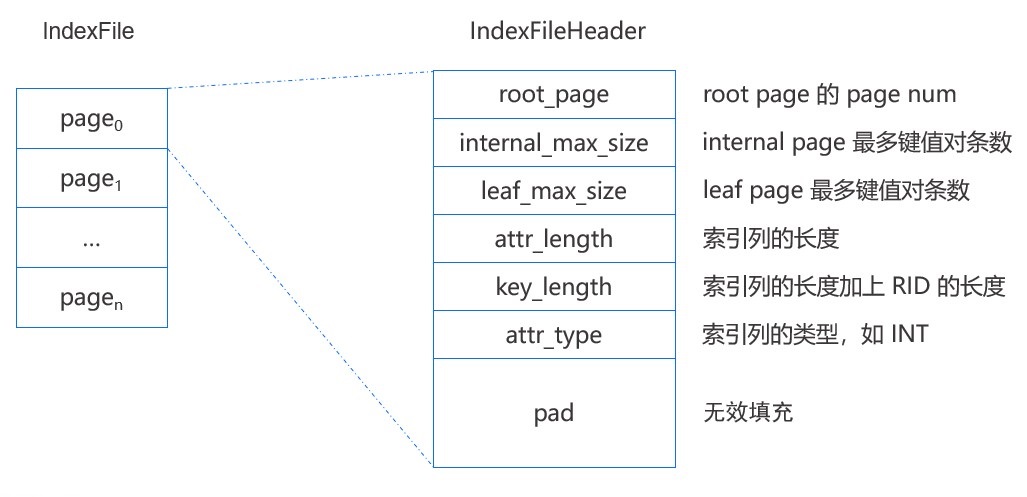
所有的结点(即 page)都存储在外存的索引文件 IndexFile 中,其中文件的第一个 page 是索引文件头,存储了一些元数据,如 root page 的 page num,内部结点和叶子结点能够存储键值对的最大个数等。
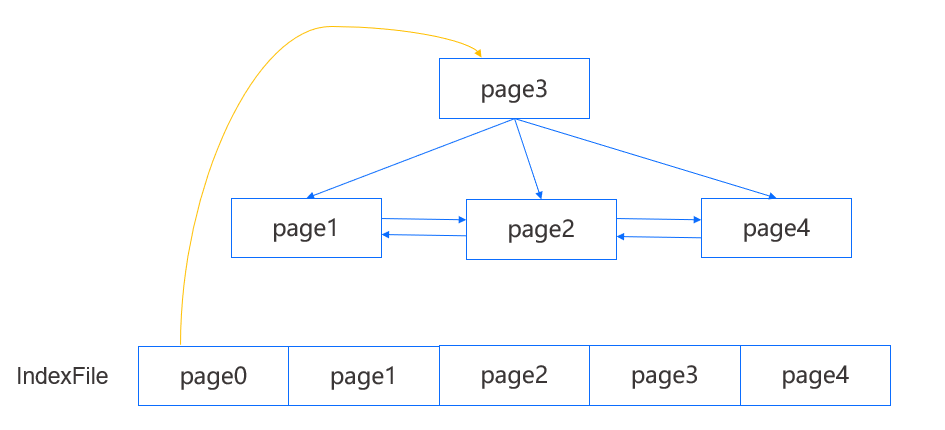
上图是一个简单的 MiniOB B+Tree 示例,其中叶结点能够访问到左右结点,并且每个结点能够访问到父结点。我们能够从 IndexFile 的第一个 page 得到 root page,而在知道一棵 B+Tree 的 root page 以后就足够访问到任意一个结点了。查询时我们会从 root page 开始逐层向下定位到目标叶结点,在每个 page 内遍历搜索查找键。
插入
在插入时,我们首先定位到叶结点,如下图中的 page2,然后在结点内定位一个插入位置,如果结点未满,那么将键值对插入指定位置并向后移动部分数据即可;如果结点已满,那么需要对其进行分裂。
我们将先创建一个新的右兄弟结点,即 page5,然后在原结点内保留前一半的键值对,剩余的键值对则移动到新结点,并修改 page2 的后向 page num,page5 的前后向 page num 以及 page4 的前向 page num,再根据之前定位的插入位置判断是插入 page2 还是 page5 ,完成叶结点的插入。
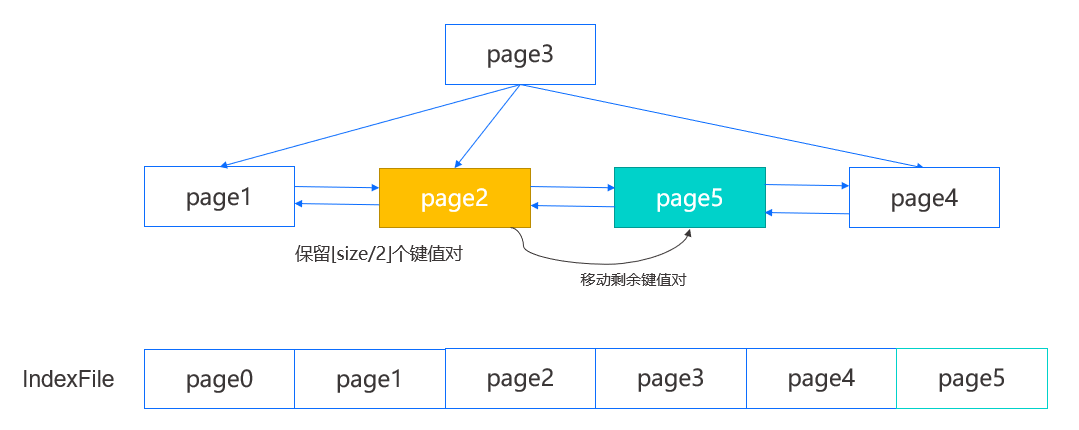
此外,由于我们新增了结点,我们需要在父结点也插入新的键值对,这一步将涉及到原结点,新结点以及新结点中的最小键,分为以下两种情况:
-
有父结点,那么直接将新结点中的最小键以及新结点的 page num 作为键值对插入父结点即可。
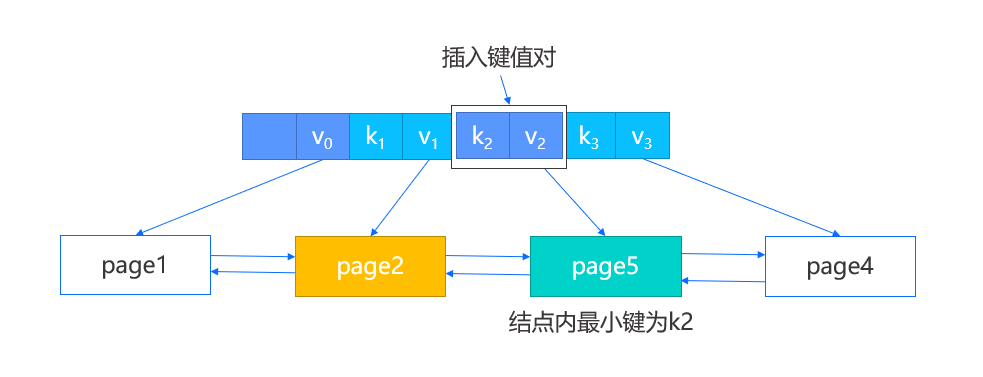
-
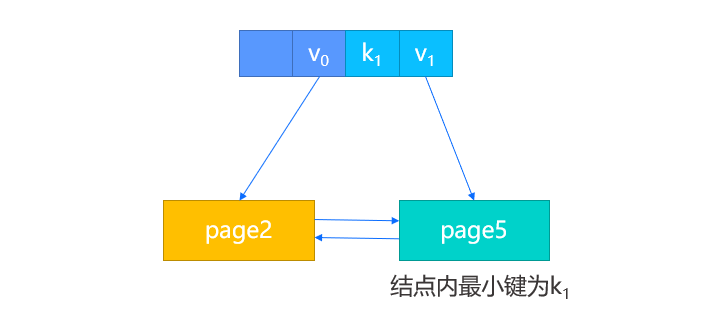
假设此时没有父结点,那么我们将创建一个新的根结点,除了把新结点键值对插入,还会将原结点的 page num 作为第一个键值对的值进行插入。
如果父结点的键值对插入同样触发了分裂,我们将按上述的步骤递归执行。
删除
正常的删除操作我们就不再介绍,这里介绍一些涉及结点合并的特殊情况。
首先在结点内删除键值对,然后判断其中的键值对数目是否小于一半,如果是则需要进行特殊处理。比如 page2 中删除一个键值对,导致其键值对数目小于一半,此时通过它的父结点找到该结点的左兄弟,如果是最左边的结点,则找到其右兄弟。
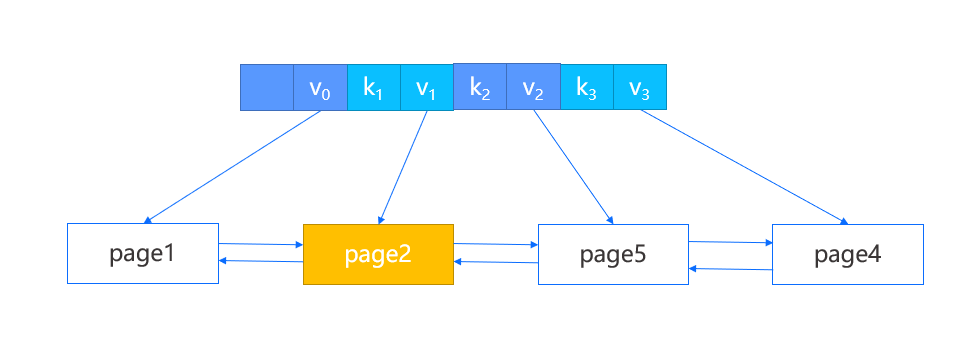
-
如果两个结点的所有键值对能容纳在一个结点内,那么进行合并操作,将右结点的数据迁移到左结点,并删除父结点中指向右结点的键值对。

-
如果两个结点的所有键值对不能容纳在一个结点内,那么进行重构操作。
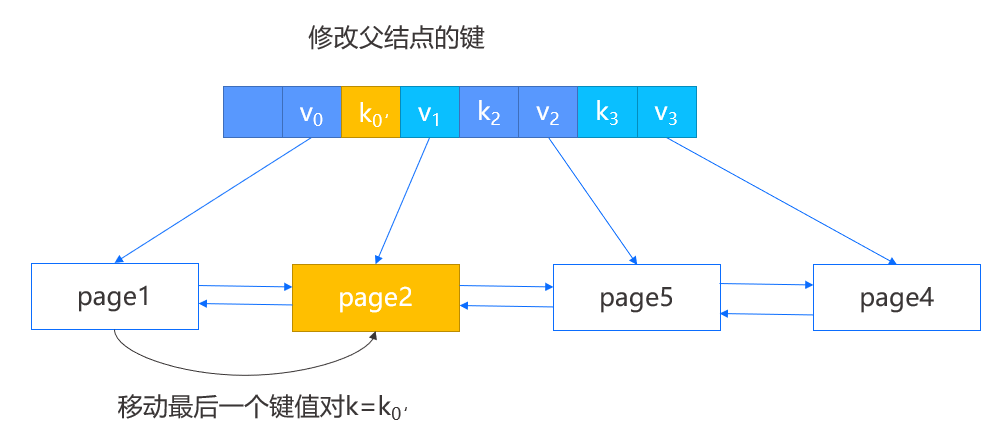
-
当所删除键值对的结点不是第一个结点时,那么选择将左兄弟的最后一个键值对移动到当前结点,并修改父结点中指向当前结点的键。
-
当所删除键值对的结点是第一个结点时,那么选择将右兄弟的第一个键值对移动到当前结点,并修改父结点中指向右兄弟的键。
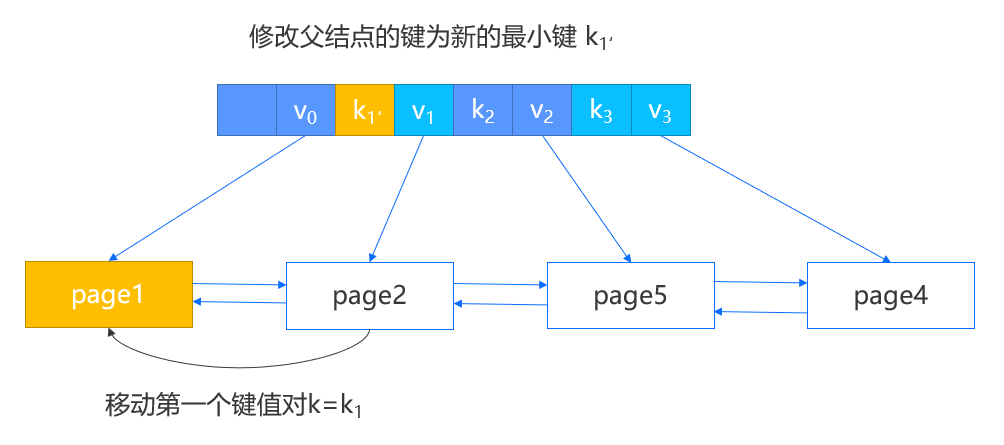
-
在上述两种操作中,合并操作会导致父结点删除键值对,因此会向上递归地去判断是否需要再次的合并与重构。
MiniOB 是 OceanBase 联合华中科技大学推出的一款用于教学的小型数据库系统,希望能够帮助数据库爱好者系统性的学习数据库原理与实战。
B+ 树介绍
B+ 树是传统数据库中常见的索引数据结构,比如MySQL、PostgreSQL都实现了B+树索引。B+ 树是一个平衡多叉树,层级少(通常只有3层)、数据块(内部节点/叶子节点)大小固定,是一个非常优秀的磁盘数据结构。关于B+ 树的原理和实现,网上有非常多的介绍,就不在此聒噪。这里将介绍如何实现支持并发操作的B+树以及MiniOB中的实现。
B+树的并发操作
在多线程并发操作时,通常使用的手段是加锁,这里的实现方法也是这样。不过在学习并发B+树实现原理之前,需要对B+树的实现比较熟悉,有兴趣的同学可以网上搜索一下。
Crabing Protocol
在操作B+树时加对应的读写锁是一种最简单粗暴但是有效的方法,只是这样实现效率不高。于是就有一些研究创建了更高效的并发协议,并且会在协议设计上防止死锁的发生。

B+树是一个树状的结构,并且所有的数据都是在叶子节点上,每次操作,几乎都是从根节点开始向下遍历,直到找到对应的叶子节点。然后在叶子节点执行相关操作,如果对上层节点会产生影响,必须需要重新平衡,那就反方向回溯调整节点。 Crabing协议是从根节点开始加锁,找到对应的子节点,就加上子节点的锁。一直循环到叶子节点。在拿到某个子节点锁时,如果当前节点是“安全的”,那就可以释放上级节点的锁。
什么是“安全的” 如果在操作某个节点时,可以确定这个节点上的动作,不会影响到它的父节点,那就说是“安全的”。 B+树上节点的操作有三个:插入、删除和查询。
- 插入:一次仅插入一个数据。如果插入一个数据后,这个节点不需要分裂,就是当前节点元素个数再增加一个,也不会达到一个节点允许容纳的最大个数,那就是安全的。不会分裂就不会影响到父节点。
- 删除:一次仅删除一个数据。如果删除一个数据后,这个节点不需要与其它节点合并,就是当前节点元素个数删除一个后,也不会达到节点允许容纳的最小值,那就是安全的。不需要合并就不会影响到父节点。
- 查询:读取数据对节点来说永远是安全的。
B+树的操作除了上述的插入、删除和查询,还有一个扫描操作。比如遍历所有的数据,通常是从根节点,找到最左边的叶子节点,然后从向右依次访问各个叶子节点。此时与加锁的顺序,与之前描述的几种方式是不同的,那为了防止死锁,就需要对遍历做特殊处理。一种简单的方法是,在访问某个叶子节点时,尝试对叶子节点加锁,如果判断需要等待,那就退出本次遍历扫描操作,重新来一遍。当然这种方法很低效,有兴趣的同学可以参考[2],了解更高效的扫描加锁方案。
问题:哪种场景下,扫描加锁可能会与更新操作的加锁引起死锁? 问题:请参考[2],给出一个遍历时不需要重试的加锁方案。
MiniOB实现
MiniOB的B+树并发实现方案与上个章节描述的方法是一致的。这里介绍一些实现细节。
在这里假设同学们对B+树的实现已经有了一定的了解。
B+树与Buffer Pool
B+树的数据是放在磁盘上的,但是直接读写磁盘是很慢的一个操作,因此这里增加一个内存缓冲层,叫做Buffer Pool。了解数据库实现的同学对这个名词不会陌生。在MiniOB中,Buffer Pool的实现是 class DiskBufferPool。对Buffer Pool实现不太了解也没关系,这里接单介绍一下。
DiskBufferPool 将一个磁盘文件按照页来划分(假设一页是8K,但是不一定),每次从磁盘中读取文件或者将数据写入到文件,都是以页为单位的。在将文件某个页面加载到内存中时,需要申请一块内存。内存通常会比磁盘要小很多,就需要引入内存管理。在这里引入Frame(页帧)的概念(参考 class Frame),每个Frame关联一个页面。FrameManager负责分配、释放Frame,并且在没有足够Frame的情况下,淘汰掉一些Frame,然后将这些Frame关联到新的磁盘页面。
那如何知道某个Frame关联的页面是否可以释放,然后可以与其它页面关联?
如果这个Frame没有任何人使用,就可以重新关联到其它页面。这里使用的方法是引用计数,称为 pin_count。每次获取某个Frame时,pin_count就加1,操作完释放时,pin_count减1。如果pin_count是0,就可以将页面数据刷新到磁盘(如果需要的话),然后将Frame与磁盘文件的其它数据块关联起来。
为了支持并发操作,Frame引入了读写锁。操作B+树时,就需要加对应的读写锁。
B+ 树的数据保存在磁盘,其树节点,包括内部节点和叶子节点,都对应一个页面。当对某个节点操作时,需要申请相应的Frame,pin_count加1,然后加读锁/写锁。由于访问子节点时,父节点的锁可能可以释放,也可能不能释放,那么需要记录下某个某个操作在整个过程中,加了哪些锁,对哪些frame 做了pin操作,以便在合适的时机,能够释放掉所有相关的资源,防止资源泄露。这里引入class LatchMemo 记录当前访问过的页面,加过的锁。
问题:为什么一定要先执行解锁,再执行unpin(frame引用计数减1)?
处理流程
B+树相关的操作一共有4个:插入、删除、查找和遍历/扫描。这里对每个操作的流程都做一个汇总说明,希望能帮助大家了解大致的流程。
插入操作 除了查询和扫描操作需要加读锁,其它操作都是写锁。
- leaf_node = find_leaf // 查找叶子节点是所有操作的基本动作
memo.init // memo <=> LatchMemo,记录加过的锁、访问过的页面
lock root page
- node = crabing_protocal_fetch_page(root_page)
loop: while node is not leaf // 循环查找,直到找到叶子节点
child_page = get_child(node)
- node = crabing_protocal_fetch_page(child_page)
frame = get_page(child_page, memo)
lock_write(memo, frame)
node = get_node(frame)
// 如果当前节点是安全的,就释放掉所有父节点和祖先节点的锁、pin_count
release_parent(memo) if is_safe(node)
- insert_entry_into_leaf(leaf_node)
- split if node.size == node.max_size
- loop: insert_entry_into_parent // 如果执行过分裂,那么父节点也会受到影响
- memo.release_all // LatchMemo 帮我们做资源释放
删除操作 与插入一样,需要对操作的节点加写锁。
- leaf_node = find_leaf // 查找的逻辑与插入中的相同
- leaf_node.remove_entry
- node = leaf_node
- loop: coalesce_or_redistribute(node) if node.size < node.min_size and node is not root
neighbor_node = get_neighbor(node)
// 两个节点间的数据重新分配一下
redistribute(node, neighbor_node) if node.size + neighbor_node.size > node.max_size
// 合并两个节点
coalesce(node, neighbor_node) if node.size + neighbor_node.size <= node.max_size
memo.release_all
查找操作 查找是只读的,所以只加读锁
- leaf_node = find_leaf // 与插入的查找叶子节点逻辑相同。不过对所有节点的操作都是安全的
- return leaf_node.find(entry)
- memo.release_all
扫描/遍历操作
- leaf_node = find_left_node
loop: node != nullptr
scan node
node_right = node->right // 遍历直接从最左边的叶子节点,一直遍历到最右边
return LOCK_WAIT if node_right.try_read_lock // 不直接加锁,而是尝试加锁,一旦失败就返回
node = node_right
memo.release_last // 释放当前节点之前加到的锁
根节点处理
前面描述的几个操作,没有特殊考虑根节点。根节点与其它节点相比有一些特殊的地方:
- B+树有一个单独的数据记录根节点的页面ID,如果根节点发生变更,这个数据也要随着变更。这个数据不是被Frame的锁保护的;
- 根节点具有一定的特殊性,它是否“安全”,就是根节点是否需要变更,与普通节点的判断有些不同。
按照上面的描述,我们在更新(插入/删除)执行时,除了对节点加锁,还需要对记录根节点的数据加锁,并且使用独特的判断是否“安全的”方法。
在MiniOB中,可以参考LatchMemo,是直接使用xlatch/slatch对Mutex来记录加过的锁,这里可以直接把根节点数据保护锁,告诉LatchMemo,让它来负责相关处理工作。
判断根节点是否安全,可以参考IndexNodeHandler::is_safe中is_root_node相关的判断。
如何测试
想要保证并发实现没有问题是在太困难了,虽然有一些工具来证明自己的逻辑模型没有问题,但是这些工具使用起来也很困难。这里使用了一个比较简单的方法,基于google benchmark框架,编写了一个多线程请求客户端。如果多个客户端在一段时间内,一直能够比较平稳的发起请求与收到应答,就认为B+树的并发没有问题。测试代码在bplus_tree_concurrency_test.cpp文件中,这里包含了多线程插入、删除、查询、扫描以及混合场景测试。
其它
有条件的开启并发
MiniOB是一个用来学习的小型数据库,为了简化上手难度,只有使用-DCONCURRENCY=ON时,并发才能生效,可以参考 mutex.h中class Mutex和class SharedMutex的实现。当CONCURRENCY=OFF时,所有的加锁和解锁函数相当于什么都没做。
并发中的调试
死锁是让人非常头疼的事情,我们给Frame增加了调试日志,并且配合pin_count的动作,每次加锁、解锁以及pin/unpin都会打印相关日志,并在出现非预期的情况下,直接ABORT,以尽早的发现问题。这个调试能力需要在编译时使用条件 -DDEBUG=ON 才会生效。
以写锁为例:
void Frame::write_latch(intptr_t xid)
{
{
std::scoped_lock debug_lock(debug_lock_); // 如果非DEBUG模式编译,什么都不会做
ASSERT(pin_count_.load() > 0, // 加锁时,pin_count必须大于0,可以想想为什么?
"frame lock. write lock failed while pin count is invalid. "
"this=%p, pin=%d, pageNum=%d, fd=%d, xid=%lx, lbt=%s", // 这里会打印各种相关的数据,帮助调试
this, pin_count_.load(), page_.page_num, file_desc_, xid, lbt()); // lbt会打印出调用栈信息
ASSERT(write_locker_ != xid, "frame lock write twice." ...);
ASSERT(read_lockers_.find(xid) == read_lockers_.end(),
"frame lock write while holding the read lock." ...);
}
lock_.lock();
write_locker_ = xid;
LOG_DEBUG("frame write lock success." ...); // 加锁成功也打印一个日志。注意日志级别是DEBUG
}
参考
[2] Concurrency of Operations on B-Trees
[3] MySQL/MariaDB mini trans相关代码
本篇文档介绍 MiniOB 中的线程池模型。
简介
多线程是提高系统资源利用率的一种常用手段,也是我们学习软件开发进阶的必经之路。 MiniOB 实现了一个可扩展的线程模型,当前支持两种线程池模型:
- 一个连接一个线程;
- 一个线程池处理所有连接。
这种设计是模仿了MySQL/MariaDB的线程模型设计。
线程模型设计
命令行参数
当前MiniOB的线程池模型通过命令行接口指定使用哪种类型:
# 一个连接一个线程(默认)
observer -T=one-thread-per-connection
# 一个线程池处理所有连接
observer -T=java-thread-pool
ThreadHandler::create 会根据传入的名字创建对应的 ThreadHandler 对象。
线程池模型做什么
这个模型并不负责所有的任务,只处理客户端发来的请求。包括监听客户端是否有消息到达、处理SQL请求与返回应答、关闭连接等。
线程模型并不负责监听新的客户端连接,这是在主线程中做的事情,参考 NetServer::serve。当有新的连接到达时,会调用 ThreadHandler::new_connection,线程模型按照自己的模型设计来处理新来的连接。
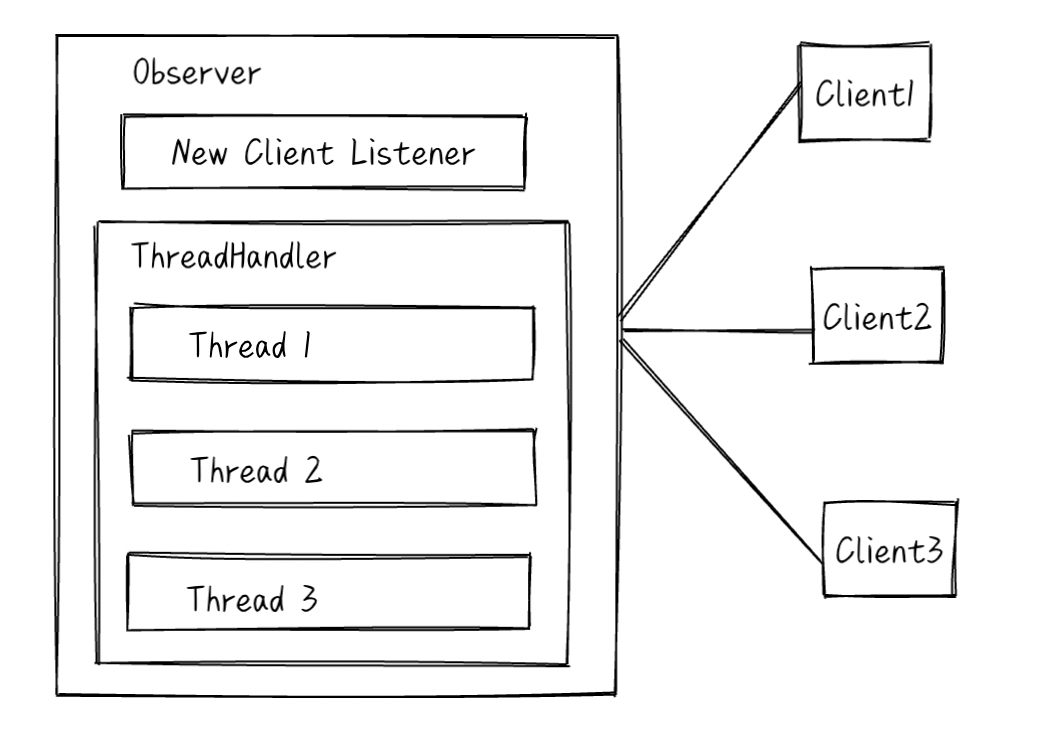
一个连接一个线程
OneThreadPerConnectionThreadHandler 会为每个连接创建一个线程,这个线程负责监听这个连接是否有消息到达、处理SQL请求与返回应答、关闭连接等。
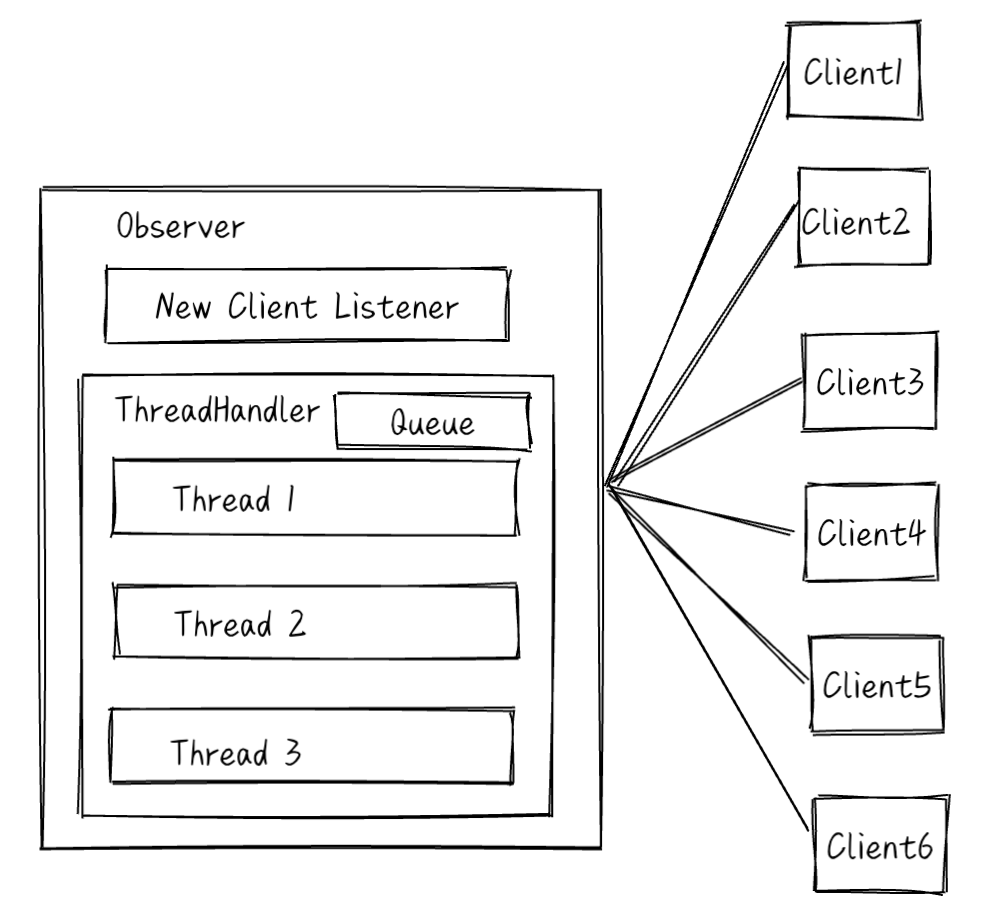
线程池模型
JavaThreadPoolThreadHandler 会创建一个线程池,线程池中一个线程负责监听所有连接是否有消息到达。如果有消息到达,就将这个连接对象放入线程池任务队列中,等待线程池中的线程来处理。在某个连接的任务处理完成之前,不会监听它的新消息。
这个线程池使用libevent实现消息监听,参考 JavaThreadPoolThreadHandler::start。
这里解释一下为什么叫做JavaThreadPoolThreadHandler,因为这个线程池的设计是参考了Java的线程池设计,但是做了简化,参考 ThreadPoolExecutor。
ThreadPoolExecutor 是一个简单的可伸缩线程池。当任务比当前空闲线程多的时候,就会扩容。当某些线程空闲时间比较久,就会自动退出。
参考
本篇文档介绍MySQL的通讯流程以及MiniOB对它的支持与实现
MiniOB 通讯协议简介
MiniOB 支持使用客户端/服务端模式,客户端与服务端需要通过通讯来交互。当前服务端支持普通的文本协议与MySQL协议。 普通的文本协议非常简单,每个请求和应答都使用字符串来传递,字符串以'\0'字符结尾,因此文本协议不能支持二进制数据的传输。 MySQL 是一个非常流行的开源数据库,它有非常丰富的周边生态工具,如果MiniOB可以支持MySQL协议,后续就可以逐步扩展支持这些工具。
MySQL 通讯协议
MySQL 服务端与客户端交互的过程。
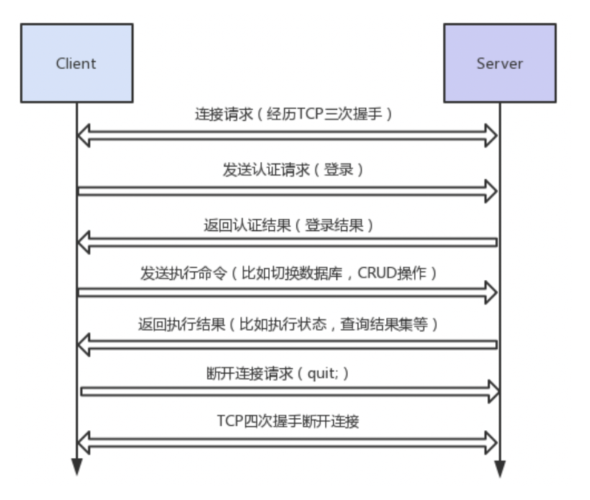
- 三次握手建立 TCP 连接。
- 建立 MySQL 连接,也就是认证阶段。 服务端 -> 客户端:发送握手初始化包 (Handshake Initialization Packet)。 客户端 -> 服务端:发送验证包 (Client Authentication Packet)。 服务端 -> 客户端:认证结果消息。
- 认证通过之后,客户端开始与服务端之间交互,也就是命令执行阶段。 客户端 -> 服务端:发送命令包 (Command Packet)。 服务端 -> 客户端:发送回应包 (OK Packet, or Error Packet, or Result Set Packet)。
- 断开 MySQL 连接。 客户端 -> 服务器:发送退出命令包。
- 四次握手断开 TCP 连接。
MySQL Packet
MySQL 协议通过packet来交互。每个packet都包含一个packet header和packet payload。 packet header包含payload的长度和当前消息包的sequence。sequence是从1开始,每发出一个消息包,sequence都会加1。 每个消息包都由一些字段构成,字段的类型有很多种,主要有整形和字符串。每种类型又有多种编码方式,比如字符串有固定长度的、以'\0'结尾的和带长度编码的。这些可以参考 mysql_communicator.cpp::store_xxx 函数。
注意,MySQL协议中数字都是小端编码。而MiniOB没有对大小端做处理,所以当前只能运行在小端的机器上。
认证阶段
完成MySQL客户端与MiniOB的建连。 构造handshake包,解析验证包, 返回OK包,确保server与客户端的建连。
握手包handshake格式
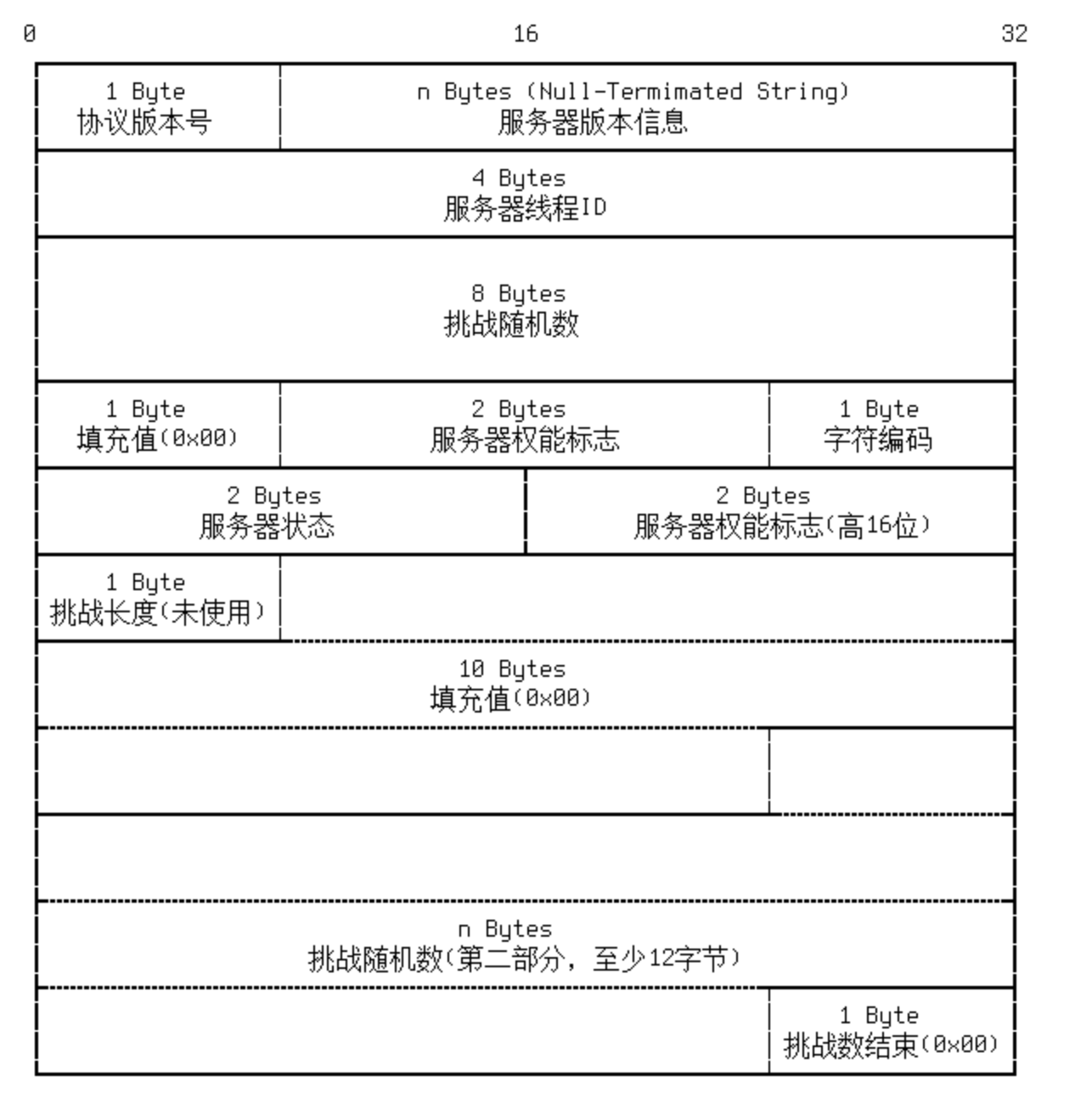
在accept接收到新的连接时,server端需要先发起handshake握手包给客户端。
认证报文
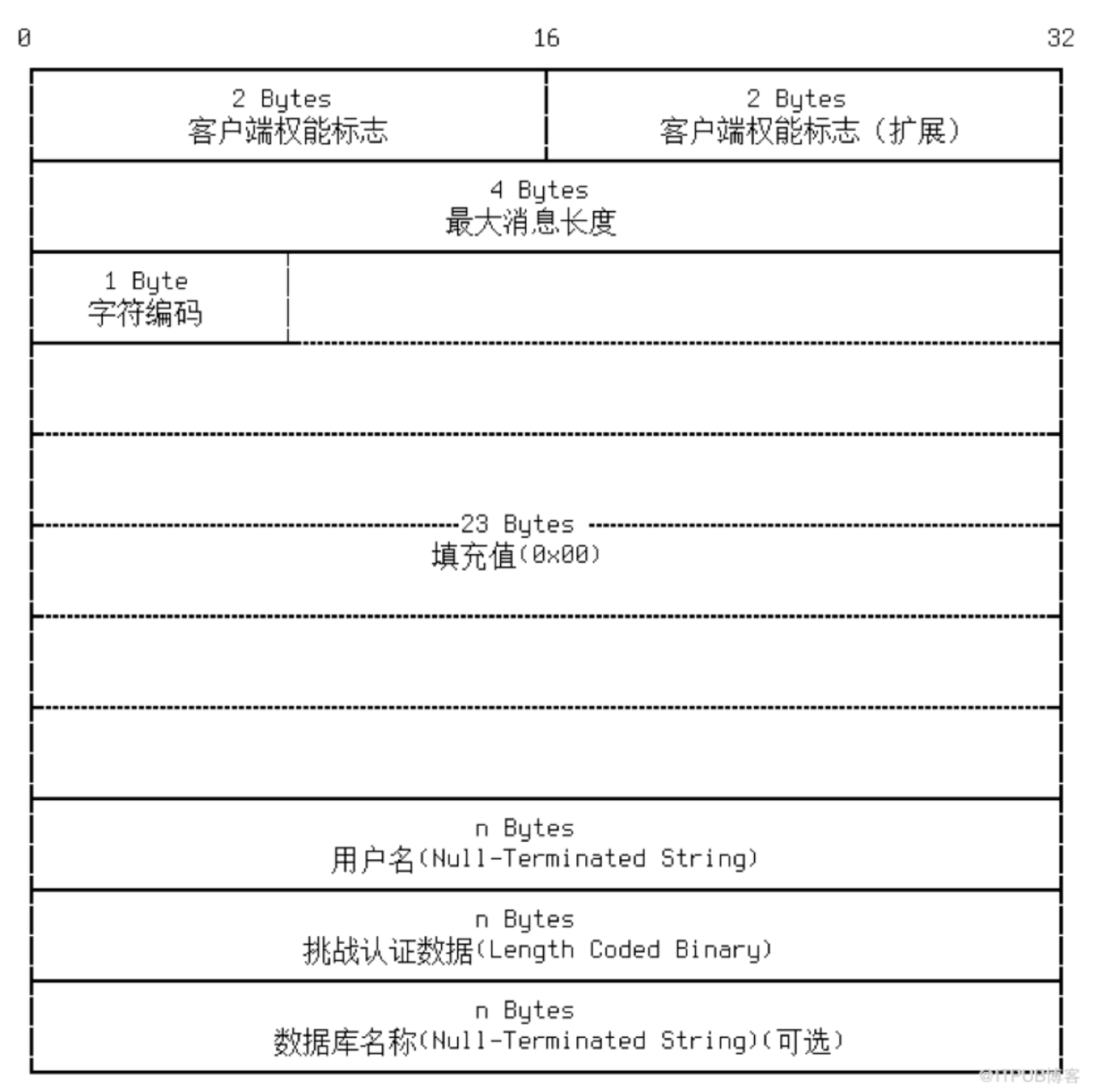
这里有两次hash加密,基于随机挑战码和密码加密后返回给server端。
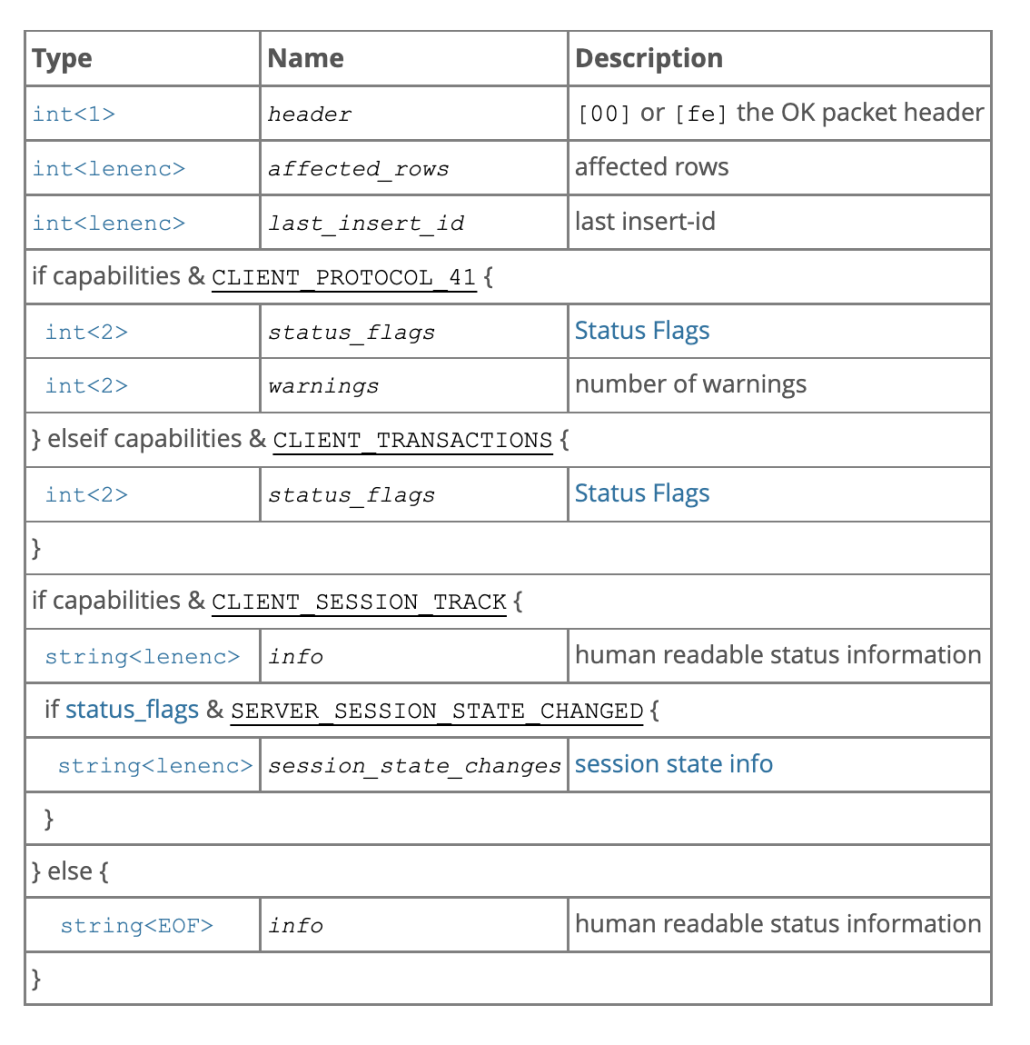
MyqlCommunicator::init是在刚接收到新的客户端连接时的接口,它会构造一个握手包发给客户端。在第一次接收客户端数据时,即在MysqlCommunicator::read_event中,如果判断还没有做过鉴权,就会做一个特殊处理,判断是否可以认证通过。不过当前MiniOB不会真的做密码验证。如果已经做过鉴权,就会认为接收的数据包是一个普通的命令消息。在接收到客户端的认证报文后,需要返回OK包给客户端。
OK包报文
请求交互阶段
在完成鉴权后,客户端就可以发送普通的请求命令到服务端,比如 "select * from t;" 查询语句。

MiniOB 仅考虑支持普通的文本查询命令。普通的文本查询命令,包格式也符合MySQL Packet的要求。其payload的第一个字节是command,接着就是请求命令,也就是SQL语句。
SQL请求的返回数据类型比较丰富,有OK、Error、EOF和ResultSet。 如果SQL请求不需要返回行数据,那直接返回处理结果即可,比如OK或者Error。 如果需要返回行数据,比如 "select * from t;" 查询请求,需要通过ResultSet包来返回客户端这些数据。有时候为了表示没有更多的数据,需要返回一个EOF包。
OK/EOF包
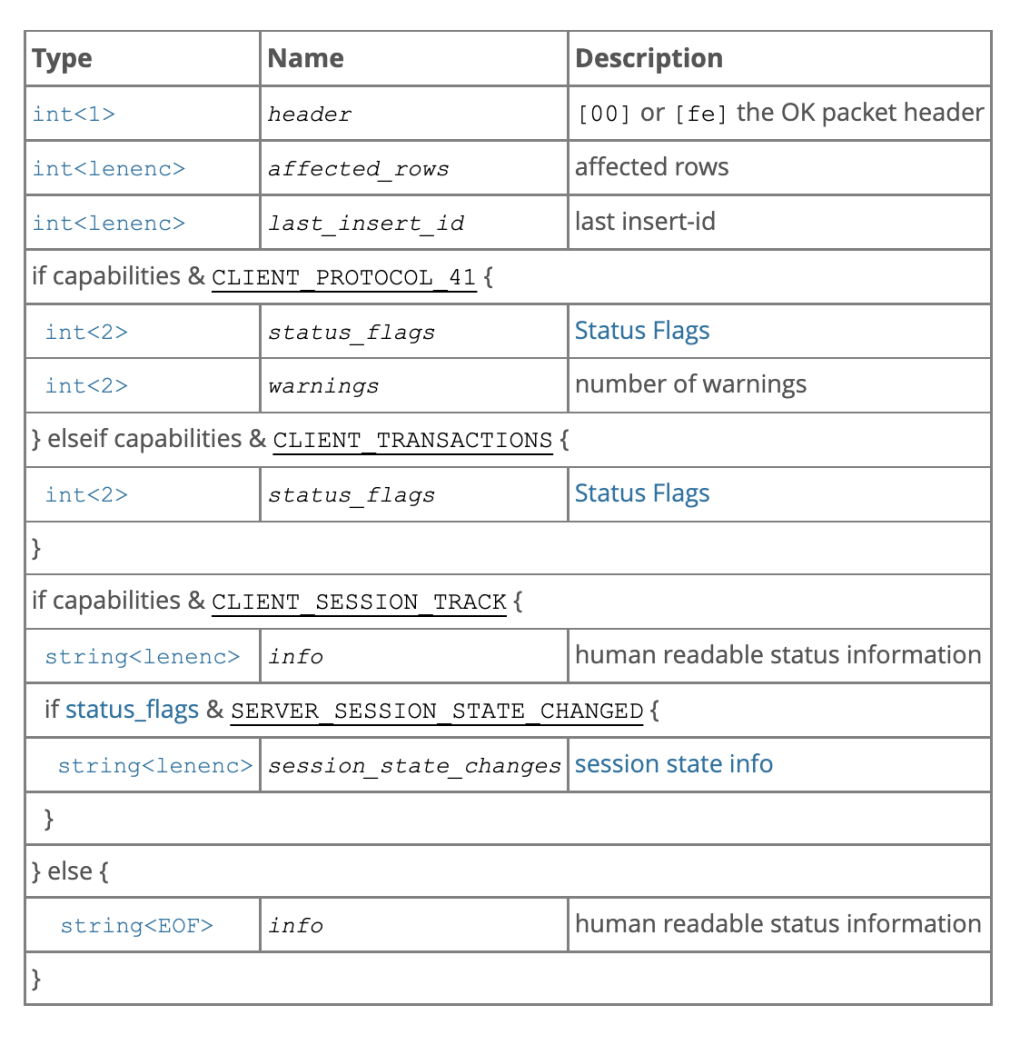
Error包

ResultSet
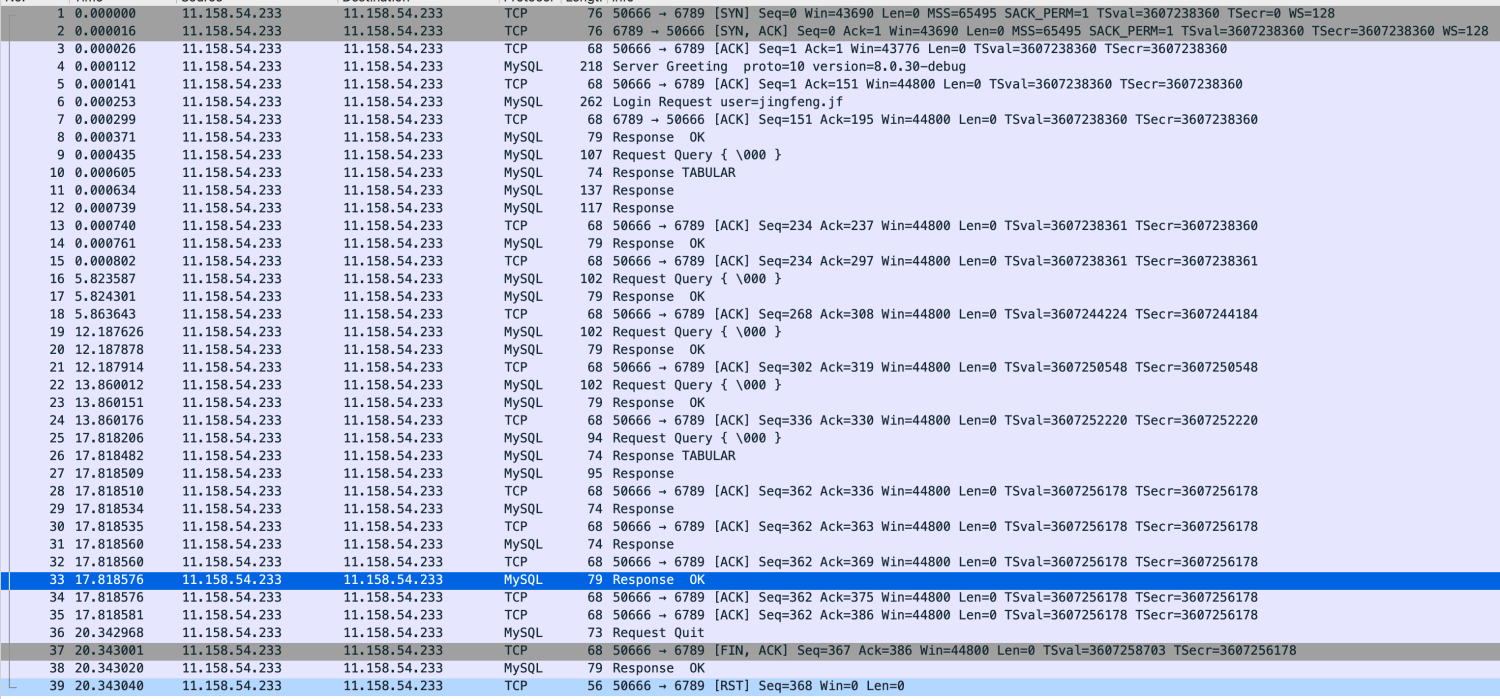
抓包
抓包可以很清晰的看到整个流程。
Doxy代码文档
注意 由于最新代码的事务模型与2022年已经不同,因此最新代码不能通过MiniOB-2022的训练营测试的basic用例,但是不影响做其它的用例测试。同学们遇到官方代码无法通过MiniOB-2022的basic用例,请忽略。
OceanBase 数据库大赛
2022 OceanBase 数据库大赛是由中国计算机学会(CCF)数据库专业委员会指导,OceanBase 与蚂蚁技术研究院学术合作团队联合举办的数据库内核实战赛事。本次大赛主要面向全国爱好数据库的高校学生,以“竞技、交流、成长”为宗旨,搭建基于赛事的技术交流平台,促进高校创新人才培养机制,不仅帮助学生从0开始系统化学习数据库理论知识,提升学生数据库实践能力,更能帮助学生走向企业积累经验,促进国内数据库人才的发展,碰撞出创新的火花。
更多详情, 请参考 OceanBase 大赛
在开始参加大赛或者训练营之前,需要创建自己的代码仓库,这里有一个gitee的使用说明: 大赛手把手入门教程
作为参考,这里有第一届数据库大赛的题目介绍: 第一届数据库大赛题目介绍
还有往届选手给出了一些题解:
在参赛前,除了学习基础的理论知识,还可以使用OceanBase提供的训练营,来快速上手: 训练营
训练营是一个自动化黑盒测试平台。同学们可以按照题目的描述要求,基于MiniOB实现相应的SQL功能,然后将自己的代码提交至训练营做测试验证,最终得到测试结果。
当前训练营有两个MiniOB的题库,其中MiniOB是2021年OceanBase大赛的题库,MiniOB-2022是2022年数据库大赛的题库。题库中都会有basic测试用例,是MiniOB官方代码中既有的功能,通常不需要同学们做修改。此题目的目的是为了检测在实现新功能时,不破坏现有的功能。
注意 由于最新代码的事务模型与2022年已经不同,因此最新代码不能通过MiniOB-2022的训练营测试的basic用例,但是不影响做其它的用例测试。同学们遇到官方代码无法通过MiniOB-2022的basic用例,请忽略。
训练营的使用方法比较简单,不过这里也有一个小手册: 训练营使用手册
为了方便大家使用训练营时获取调试信息,这里有一个小手册: 训练营调试输出手册
注意,在训练营开始前,需要注意自己的程序输出需要满足一定的要求,请参考: 提交测试需要满足的输出要求
我们也收集了一些常见问题,可以参考: 常见问题
训练营建议: 训练营对同学们的大工程实战能力提升非常高,在现在有的几万行代码上需要添加非常多的功能,整个训练营完成后代码量很可观。因此,同学们在实现各种功能时,不要一直堆砌代码,需要不停的优化重构现有功能模块与架构,以使自己的代码能够稳步前进。
对于比赛和训练营测试后台,需要做一些输出约定,才能正确的进行测试。
*** 注意: 后台测试环境,依赖本章节的输出要求。如果输出格式不满足要求,有些case将无法通过***
输出是指服务端返回给客户端的数据。为了可以做测试,需要对输出的格式做约定。 NOTE:后台测试程序,是将预先编辑好的Case执行后,将执行结果与预期输出结果(预先编写完成)做对比,与mysql test工作原理类似,因此需要严格按照输出约束来输出。
这里虽然列出了很多约束条件,但是同学们并不需要担心,当前的实现已经满足了这些约束条件,或者给出了满足约束的帮助函数,只要按照要求使用即可。
-
语法解析错误,返回 FAILURE(只返回这个字符串,不带任何多余字符)。
-
对于DML和DDL操作,执行成功返回SUCCESS,失败返回FAILURE。更新和删除操作时没有数据变更,只要没有错误,输出也是SUCCESS。
-
对于QUERY操作,如果执行失败,返回FAILURE(包括语法错误)。否则按照下面的格式要求输出:列名显示和顺序说明:
- 单表查询,没有指定列名(select * from t) ,按照建表语句的顺序列出列名,列名不需要带表明
- 单表查询,指定了列名,按照指定的顺序输出列名,列名不需要带表名
- 表查询,没有指定列名(select * from t,t1),列名需要带表明,使用'.'分开。每张表的列名与建表时顺序保持一致,多张表按照from后指定的顺序依次排列
- 多表查询,指定列名,就按照指定的顺序排列
- 多表查询,有些指定列名,有些没有指定(select t1.*, t2.id from t1,t2)。没有指定的与建表时保持一致,否则按照指定的顺序排列 输出格式: 列名之间使用 ' | '分开,注意 '|'左右各有一个空格。输出列名后,第二行开始输出列值,值之间也使用' | '隔开。 注意:第一列和最后一列没有分隔符,也没有空格 如果没有数据,显示列名即可。
- 聚合函数字段输出,保留与输入相似的格式。比如select max(age) from t; 那么输出时,列名输出max(age)。注意,圆括号内没有空格。
-
所有输出不区分大小写
-
日期(date)输出格式使用:"YYYY-mm-DD"
-
输出的字符串不使用单引号双引号或其它括起来
-
浮点数输出,不要带后面多余的0,可以参考C sprintf的%g格式输出,保留两位小数。参考函数 double_to_str
FAQ
- 某张表或者某个查询结果一行数据都没有,但是依然需要输出表头信息
- 查询语句输入的字段名带了表名,比如select t.id from t; ,因为只有一张表,还是仅输出字段名称
- 测试不考察大小写,所以输入输出都不区分大小写
本篇文档介绍如何向训练营输出调试信息。
在使用训练营提交测试时,有时候会遇到本地环境没有问题,但是训练营上的输出总是不符合预期。但是训练营没有办法调试,这时候就需要在训练营上输出调试信息,以便于定位问题。
如何输出调试信息
可以参考文件 sql_debug.h,在需要输出调试信息的地方,调用sql_debug函数即可。sql_debug 的使用与打印日志类似,不过可以在向客户端输出正常结果后,再输出调试信息。
执行sql_debug同时会在日志中打印DEBUG级别的日志。
示例
CreateTableStmt::createTableScanPhysicalOperator::next
注意 由于训练营上能够容纳的信息有限,所以输出太多信息会被截断。
开关
每个连接都可以开启或关闭调试,可以参考 Session::sql_debug_。
在交互式命令行中,可以使用 set sql_debug=1 开启调试,使用 set sql_debug=0 关闭调试。
当前没有实现查看变量的命令。
示例
miniob > select * from t;
id
1
# get a tuple: 1
miniob > set sql_debug=0;
SUCCESS
miniob > select * from t;
id
1
miniob 题目
背景
这里的题目是2021年OceanBase数据库大赛初赛时提供的赛题。这些赛题的入门门槛较低, 适合所有参赛选手。 面向的对象主要是在校学生,数据库爱好者, 或者对基础技术有一定兴趣的爱好者, 并且考题对诸多模块做了简化,比如不考虑并发操作, 事务比较简单。 初赛的目标是让不熟悉数据库设计和实现的同学能够快速的了解与深入学习数据库内核,期望通过miniob相关训练之后,能够对各个数据库内核模块的功能与它们之间的关联有所了解,并能够在使用时,设计出高效的SQL, 并帮助降低学习OceanBase 内核的学习门槛。
题目介绍
预选赛,题目分为两类,一类必做题,一类选做题。选做题按照实现的功能计分。
计分规则:必做题和选做题都有分数。但是必做题做完后,选做题的分数才会进行累计。
作为练习,这些题目在单个实现时,是比较简单的。因为除了必做题,题目之间都是单独测试的。希望你能够在实现多个功能时,考虑一下多个功能之间的关联。比如实现了多字段索引,可以考虑下多字段索引的唯一索引、根据索引查询数据等功能。另外,可以给自己提高一点难度。比如在实现表查询时,可以想象内存中无法容纳这么多数据,那么如何创建临时文件,以及如何分批次发送结果到客户端。
必做题
| 名称 | 分值 | 描述 | 测试用例示例 |
|---|---|---|---|
| 优化buffer pool | 10 | 必做。实现LRU淘汰算法或其它淘汰算法。 题目没有明确的测试方法。同学可以通过这个简单的题目学习disk_buffer_pool的工作原理。 | |
| 查询元数据校验 select-meta | 10 | 必做。查询语句中存在不存在的列名、表名等,需要返回失败。需要检查代码,判断是否需要返回错误的地方都返回错误了。 | create table t(id int, age int); select * from t where name='a'; select address from t where id=1; select * from t_1000; select * from t where not_exists_col=1; |
| drop table drop-table | 10 | 必做。删除表。清除表相关的资源。 注意:要删除所有与表关联的数据,不仅仅是在create table时创建的资源,还包括索引等数据。 | create table t(id int, age int); create table t(id int, name char); drop table t; create table t(id int, name char); |
| 实现update功能 update | 10 | 必做。update单个字段即可。 可以参考insert_record和delete_record的实现。目前能支持update的语法解析,但是不能执行。需要考虑带条件查询的更新,和不带条件的更新。 | update t set age =100 where id=2; update set age=20 where id>100; |
| 增加date字段 date | 10 | 必做。要求实现日期类型字段。date测试不会超过2038年2月,不会小于1970年1月1号。注意处理非法的date输入,需要返回FAILURE。 当前已经支持了int、char、float类型,在此基础上实现date类型的字段。 这道题目需要从词法解析开始,一直调整代码到执行阶段,还需要考虑DATE类型数据的存储。 注意: - 需要考虑date字段作为索引时的处理,以及如何比较大小; - 这里限制了日期的范围,所以简化了溢出处理的逻辑,测试数据中也删除了溢出日期,比如没有 2040-01-02; - 需要考虑闰年。 | create table t(id int, birthday date); insert into t values(1, '2020-09-10'); insert into t values(2, '2021-1-2'); select * from t; |
| 多表查询 select-tables | 10 | 必做。当前系统支持单表查询的功能,需要在此基础上支持多张表的笛卡尔积关联查询。需要实现select * from t1,t2; select t1.*,t2.* from t1,t2;以及select t1.id,t2.id from t1,t2;查询可能会带条件。查询结果展示格式参考单表查询。每一列必须带有表信息,比如: t1.id | t2.id 1 | 1 | select * from t1,t2; select * from t1,t2 where t1.id=t2.id and t1.age > 10; select * from t1,t2,t3; |
| 聚合运算 aggregation-func | 10 | 实现聚合函数 max/min/count/avg. 包含聚合字段时,只会出现聚合字段,不会出现如select id, count(age) from t;这样的测试语句。聚合函数中的参数不会是表达式,比如age +1。 | select max(age) from t1; select count(*) from t1; select count(1) from t1; select count(id) from t1; |
选做题
| 名称 | 分值 | 描述 | 测试用例示例 |
|---|---|---|---|
| 多表join操作 join-tables | 20 | INNER JOIN。需要支持join多张表。主要工作是语法扩展。注意带有多条on条件的join操作。 | select * from t1 inner join t2 on t1.id=t2.id; select * from t1 inner join t2 on t1.id=t2.id inner join t3 on t1.id=t3.id; selec * from t1 inner join t2 on t1.id=t2.id and t2.age>10 where t1.name >='a'; |
| 一次插入多条数据 insert | 10 | 单条插入语句插入多行数据。一次插入的数据要同时成功或失败。 | insert into t1 values(1,1),(2,2),(3,3); |
| 唯一索引 unique | 10 | 唯一索引:create unique index。 | create unique index i_id on t1(id); insert into t1 values(1,1); insert into t1 values(1,2); -- failed |
| 支持NULL类型 null | 10 | 字段支持NULL值。包括但不限于建表、查询和插入。默认情况不允许为NULL,使用nullable关键字表示字段允许为NULL。 Null不区分大小写。 注意NULL字段的对比规则是NULL与任何 数据对比,都是FALSE。 如果实现了NULL,需要调整聚合函数的实现。 | create table t1 (id int not null, age int not null, address nullable); create table t1 (id int, age int, address char nullable); insert into t1 values(1,1, null); |
| 简单子查询 simple-sub-query | 10 | 支持简单的IN(NOT IN)语句; 支持与子查询结果做比较运算; 支持子查询中带聚合函数。 子查询中不会与主查询做关联。 | select * from t1 where name in(select name from t2); select * from t1 where t1.age >(select max(t2.age) from t2); select * from t1 where t1.age > (select avg(t2.age) from t2) and t1.age > 20.0; NOTE: 表达式中可能存在不同类型值比较 |
| 多列索引 multi-index | 20 | 多个字段关联起来称为单个索引。 | create index i_id on t1(id, age); |
| 超长字段 text | 20 | 超长字段的长度可能超出一页,比如常见的text,blob等。这里仅要求实现text(text 长度固定4096字节),可以当做字符串实现。 注意:当前的查询,只能支持一次返回少量数据,需要扩展 如果输入的字符串长度,超过4096,那么应该保存4096字节,剩余的数据截断。 需要调整record_manager的实现。当前record_manager是按照定长长度来管理页面的。 | create table t(id int, age int, info text); insert into t values(1,1, 'a very very long string'); select * from t where id=1; |
| 查询支持表达式 expression | 20 | 查询中支持运算表达式,这里的运算表达式包括 +-*/。 仅支持基本数据的运算即可,不对date字段做考察。 运算出现异常,按照NULL规则处理。 只需要考虑select。 | select * from t1,t2 where t1.age +10 > t2.age *2 + 3-(t1.age +10)/3; select t1.col1+t2.col2 from t1,t2 where t1.age +10 > t2.age *2 + 3-(t1.age +10)/3; |
| 复杂子查询 complex-sub-query | 20 | 子查询在WHERE条件中,子查询语句支持多张表与AND条件表达式,查询条件支持max/min等。 注意考虑一下子查询与父表相关联的情况。 | select * from t1 where age in (select id from t2 where t2.name in (select name from t3)) |
| 排序 order-by | 10 | 支持oder by功能。不指定排序顺序默认为升序(asc)。 不需要支持oder by字段为数字的情况,比如select * from t order by 1; | select * from t,t1 where t.id=t1.id order by t.id asc,t1.score desc; |
| 分组 group-by | 20 | 支持group by功能。group by中的聚合函数也不要求支持表达式 | select t.id, t.name, avg(t.score),avg(t2.age) from t,t2 where t.id=t2.id group by t.id,t.name; |
测试常见问题
测试Case
优化buffer pool
题目中要求实现一个LRU算法。但是LRU算法有很多种,所以大家可以按照自己的想法来实现。因为不具备统一性,所以不做统一测试。
另外,作为练习,除了实现LRU算法之外,还可以考虑对buffer pool做进一步的优化。比如支持更多的页面或无限多的页面(当前buffer pool的实现只能支持固定个数的页面)、支持快速的查找页面(当前的页面查找算法复杂度是O(N)的)等。
basic 测试
基础测试是隐藏的测试case,是代码本身就有的功能,比如创建表、插入数据等。如果选手把原生仓库代码提交上去,就能够测试通过basic。做其它题目时,可能会影响到basic测试用例,需要注意。
select-meta 测试
这个测试对应了“元数据校验”。选手们应该先做这个case。
常见测试失败场景有一个是 where 条件校验时 server core了。
注意,训练营和此处关于 select-meta 题目的描述是过时的,错误地沿用了2021 select-meta 题目的描述。2022 select-meta 赛题的要求为:为 select 查询实现类似 SELECT *, attrbutes FROM RELATIONS [WHERE CONDITIONS] 的功能。
drop-table case测试
目前遇到最多的失败情况是没有校验元数据,比如表删除后,再执行select,按照“元数据校验”规则,应该返回"FAILURE"。
date 测试
date测试需要注意校验日期有效性。比如输入"2021-2-31",一个非法的日期,应该返回"FAILURE"。
date不需要考虑和string(char)做对比。比如 select * from t where d > '123'; select * from t where d < 'abc'; 不会测试这种场景。但是需要考虑日期与日期的比较,比如select * from t where d > '2021-01-21';。
date也不会用来计算平均值。
select * form t where d=’2021-02-30‘; 这种场景在mysql下面是返回空数据集,但是我们现在约定都返回 FAILURE。
温馨提示:date 可以使用整数存储,简化处理
浮点数展示问题
按照输出要求,浮点数最多保留两位小数,并且去掉多余的0。目前没有直接的接口能够输出这种格式。比如 printf("%.2f", f); 会输出 1.00,printf("%g", f); 虽然会删除多余的0,但是数据比较大或者小数位比较多时展示结果也不符合要求。
浮点数与整数转换问题
比如 create table t(a int, b float); 在当前的实现代码中,是不支持insert into t values(1,1); 这种做法的,因为1是整数,而字段b是浮点数。那么,我们在比赛中,也不需要考虑这两种转换。
但是有一种例外情况,比如聚合函数运算:select avg(a) from t;,需要考虑整数运算出来结果,是一个浮点数。
update 测试
update 也要考虑元数据校验,比如更新不存在的表、更新不存在的字段等。
需要考虑不能转换的数据类型更新,比如用字符串更新整型字段。
对于整数与浮点数之间的转换,不做考察。学有余力的同学,可以做一下。
更新需要考虑的几个场景,如果这个case没有过,可以对比一下:
假设存在这个表:
create table t (id int, name char, col1 int, col2 int);
表上有个索引
create index i_id on t (id);
-- 单行更新
update t set name='abc' where id=1;
-- 多行更新
update t set name='a' where col1>2; -- 假设where条件能查出来多条数据
-- 更新索引
update t set id=4 where name='c';
-- 全表更新
update t set col1=100;
-- where 条件有多个
update t set name='abc' where col1=0 and col2=0;
一些异常场景:
- 更新不存在的表
- 更新不存在的字段
- 查询条件中包含不合法的字段
- 查询条件查出来的数据集合是空(应该什么都不做,返回成功)
- 使用无法转换的类型更新某个字段,比如使用字符串更新整型字段
多表查询
多表查询的输入SQL,只要是字段,都会带表名。比如不会存在 select id from t1,t2;
不带字段名称的场景(会测试):select * from t1,t2;
带字段:select t1.id, t1.age, t2.name from t1,t2 where t1.id=t2.id;
或者:select t1.* , t2.name from t1,t2 where t1.id=t2.id;
多表查询,查询出来单个字段时,也需要加上表名字。原始代码中,会把表名给删除掉。比如select t1.id from t1,t2; 应该输出列名: t1.id。这里需要调整原始代码。输出列名的规则是:单表查询不带表名,多表查询带表名。
不要仅仅使用最简单的笛卡尔积运算,否则可能会内存不足。
聚合运算
不需要考虑聚合字段与普通字段同时出现的场景。比如: select id, count(1) from t1;
必做题中的聚合运算只需要考虑单张表的情况。
字符串可以不考虑AVG运算。
最少需要考虑的场景:
假设有一张表 create table t(id int, name char, price float);
select count(*) from t;
select count(id) from t;
select min(id) from t;
select min(name) from t; -- 字符串
select max(id) from t;
select max(name) from t;
select avg(id) from t; -- 整数做AVG运算,输出可能是浮点数,所以要注意浮点数输出格式
select avg(price) from t;
select avg(price), max(id), max(name) from t;
还需要考虑一些异常场景:
select count(*,id) from t;
select count() from t;
select count(not_exists_col) from t;
支持NULL类型
NULL的测试case描述的太过简单,这里做一下补充说明。
NULL的功能在设计时,参考了mariadb的做法。包括NULL的比较规则:任何 值与NULL做对比,结果都是FALSE。
因为miniob的特殊性,字段默认都是不能作为NULL的,所以这个测试用例中,要求增加关键字nullable,表示字段可以是NULL。
需要考虑的场景
- 建表 create table t(id int, num int nullable, birthday date nullable); 表示创建一个表t,字段num和birthday可以是NULL, 而id不能是NULL。
建索引 create index i_num on t(num); 支持在可以为NULL的字段上建索引
需要支持增删改查
insert into t values(1, 2, '2020-01-01');
insert into t values(1, null, null);
insert into t values(1, null, '2020-02-02'); -- 同学们自己多考虑几种场景
insert into t values(null, 1, '2020-01-02'); -- 应该返回FAILURE,因为ID不能是NULL
select * from t; -- 全表遍历
-- null 条件查询,同学们自己多测试几种场景
select * from t where id is null;
select * from t where id is not null;
select * from t where num is null;
select * from t where num > null;
select * from t where num <> null;
select * from t where 1=null;
select * from t where 'a'=null;
select * from t where null = null;
select * from t where null is null; -- 注意 = 与 is 的区别
select * from t where '2020-01-31' is null;
不要忘记多表查询
聚合
select count(*) from t;
select count(num) from t;
select avg(num) from t;
字段值是NULL时,比较特殊,不需要统计在内。如果是AVG,不会增加统计行数,也不需要默认值。
inner-join
inner-join 与 多表查询类似,很多同学做完多表查询就开始做inner-join了。 inner-join出现非常多的一个问题就是下面的语句,返回了空数据,或者没有任何返回,可能是测试时程序coredump,或者长时间没有返回结果,比如死循环。测试语句是:
select * from join_table_large_1 inner join join_table_large_2 on join_table_large_1.id=join_table_large_2.id inner join join_table_large_3 on join_table_large_1.id=join_table_large_3.id inner join join_table_large_4 on join_table_large_3.id=join_table_large_4.id inner join join_table_large_5 on 1=1 inner join join_table_large_6 on join_table_large_5.id=join_table_large_6.id where join_table_large_3.num3 <10 and join_table_large_5.num5>90;
表达式
表达式需要考虑整数和浮点数的比较。比如 t.id > 1.1 或者 5/4 = 1等。
MiniOB GitHub 在训练营中的使用说明
训练营测试后端现在支持使用 GitHub 和 Gitee 作为代码仓库管理平台。
本文介绍如何在GitHub上创建私有仓库,并将MiniOB代码提交到自己的仓库中,然后在训练营中进行测试。
MiniOB 仓库地址:https://github.com/oceanbase/miniob
训练营地址:https://open.oceanbase.com/train
GitHub 私有仓库创建
首先你要有一个自己的GitHub账号。账号的注册流程比较简单,没有账号的同学登录GitHub网站创建即可。
-
登录GitHub网站,并登录自己的账号
-
在网站右上角点击 "Import Repository"
- 填写导入表单
在"Your old repository's clone URL"项目中填写仓库的地址:
https://github.com/oceanbase/miniob
- 点击"Begin import"按钮,开始导入仓库
导入会花费一定时间,导入完成后,可以看到:
- 查看仓库首页
点击"Code" 标签,就可以进入到仓库首页。
- 邀请OceanBase测试账号
点击"Settings"标签,进入仓库设置页面,点击"Collaborators"标签,进入仓库权限管理页面。
在"Search by username, full name or email address"中输入"oceanbase-ce-game-test"(官方测试账号),点击"Add collaborator"按钮,即可将OceanBase测试账号添加到仓库中。
GitHub 在邀请别人加入仓库时,会发送邮件通知被邀请人,需要对方同意后,才能加入。 因此这个步骤需要等待,官方测试人员会定期刷新邮件处理邀请。如果长时间没有看到邀请成功的信息,请联系官方人员。 也可以直接将邀请链接发送给官方人员,邀请链接可以点击"Pending invite" 右侧的方形按钮复制。
- 提交测试
等官网人员通过邀请后,就可以提交测试了。训练营的使用说明不再赘述,可以参考 训练营使用说明。
MiniOB Gitee 在训练营中的使用说明
实战 MiniOB 编程需要在 Gitee 上创建自己的 private 仓库,在开发完成后,将代码提交到自己的仓库中,然后在训练营中进行测试。
MiniOB 仓库地址:https://github.com/oceanbase/miniob
训练营地址:https://open.oceanbase.com/train
本文将以 Gitee 为例介绍如何在训练营中进行提测以及常用的 Git 操作命令。
Gitee 提测流程
前提条件:已注册 Gitee 账号,Gitee 官网地址:https://gitee.com。
-
创建私有仓库
-
登录 Gitee 平台,选择 新建仓库。
-
输入仓库信息,单击 创建。设置为私有仓库后其他人无法查看到你的代码。
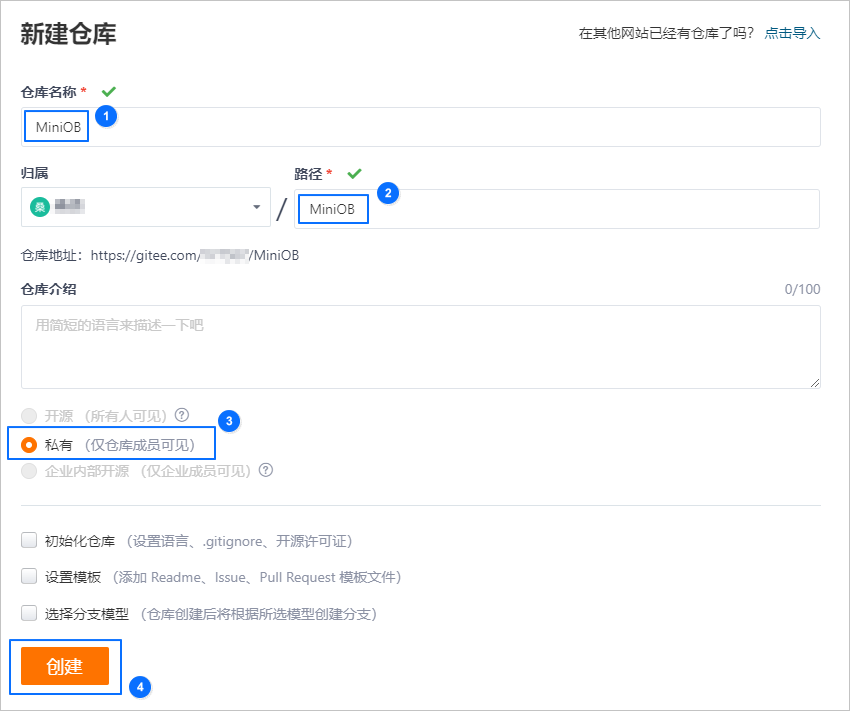
-
-
下载代码
# 将代码拉到本地 git clone https://github.com/oceanbase/miniob -b miniob_test说明
若网络状态不好,也可以直接在 GitHub 上下载代码压缩包,下载时需要先选择 miniob_test 分支。
-
将 MiniOB 代码 push 到自己的仓库
# 进入到 miniob 目录,删除 .git 目录,清除已有的 git 信息 cd miniob rm -rf .git # 重新初始化 git 信息,并将代码提交到自己的仓库 git init git add . git commit -m 'init' # 提交所有代码到本地仓库 # 将代码推送到远程仓库 git remote add origin https://gitee.com/xxx/miniob.git # 注意替换命令中的 息为自己的库信息 git branch -M main git push -u origin main -
赋权官方测试账号
对于私有仓库,默认情况下其他人看不到,同样 OceanBase 测试后台也无法拉取到代码,这时想要提交测试,需要先给 OceanBase 的官方测试账号增加一个权限。
官方测试账号为:
oceanbase-ce-game-test首先在网页上打开自己的仓库,然后按照如下顺序操作即可。如果有疑问,也可以在 OceanBase 社区论坛或钉钉群(33254054)提问。
-
选择 管理 > 仓库成员管理 > 观察者 。
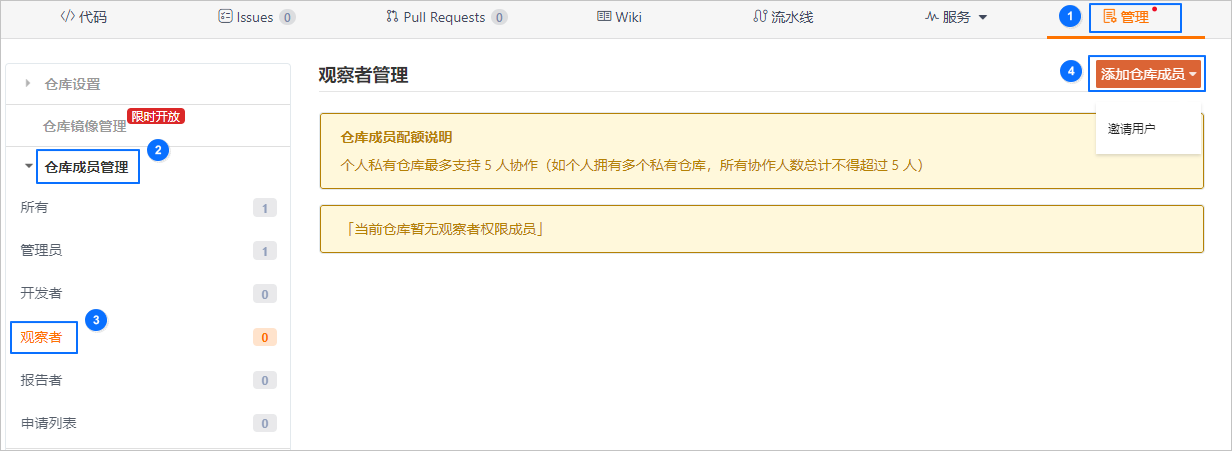
-
选择 直接添加,搜索官方测试账号。
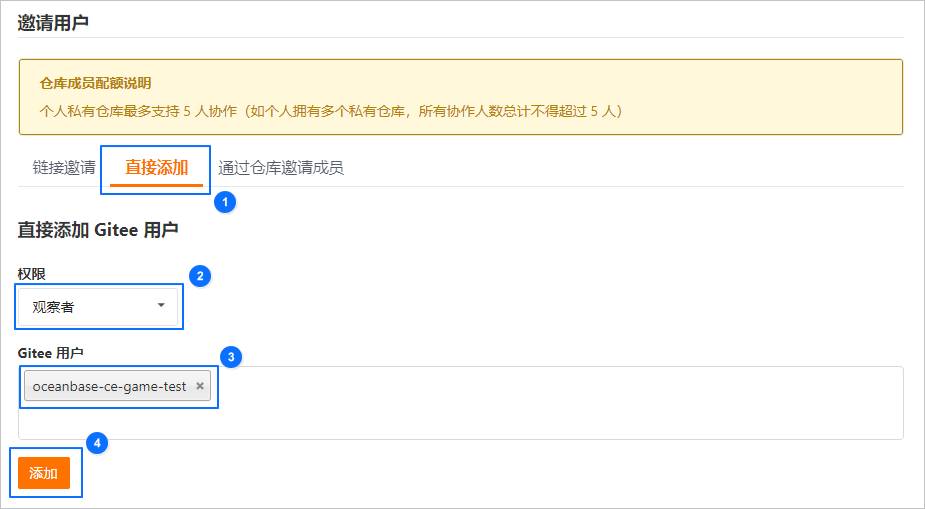
-
添加完成后,单击 提交。
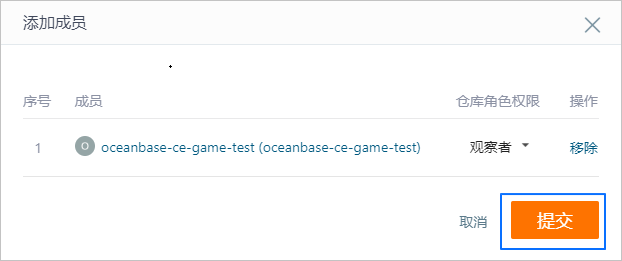
-
日常 Git 开发命令
-
查看当前分支
git branch # 查看本地分支 git branch -a # 查看所有分支,包括远程分支 -
创建分支
git checkout -b 'your branch name' git branch -d 'your branch name' # 删除一个分支 -
切换分支
git checkout 'branch name' -
提交代码
# 添加想要提交的文件或文件夹 git add 'the files or directories you want to commit' # 这一步也可以用 git add . 添加当前目录 # 提交到本地仓库 # -m 中是提交代码的消息,建议写有意义的信息,方便后面查找 git commit -m 'commit message' -
推送代码到远程仓库
git push # 可以将多次提交,一次性 push 到远程仓库 -
合并代码
# 假设当前处于分支 develop 下 git merge feature/update # 会将 feature/update 分支的修改,merge 到 develop 分支 -
临时修改另一个分支的代码
# 有时候,正在开发一个新功能时,突然来了一个紧急 BUG,这时候需要切换到另一个分 去开发 # 这时可以先把当前的代码提交上去,然后切换分支。 # 或者也可以这样: git stash # 将当前的修改保存起来 git checkout main # 切换到主分支,或者修复 BUG 的分支 git checkout -b fix/xxx # 创建一个新分支,用于修复问题 # 修改完成后,merge 到 main 分支 # 然后,继续我们的功能开发 git checkout feature/update # 假设我们最开始就是在这个分支上 git stash pop # stash 还有很多好玩的功能,大家可以探索一下
此实现解析有往届选手提供。具体代码实现已经有所变更,因此仅供参考。
miniob-date 测试解说
本篇文章针对在miniob中增加date字段类型做解析,希望可以帮助参加比赛的同学能够顺利通过。
题目描述
date测试不会超过2038年2月,不会小于1970年1月1号。注意处理非法的date输入,需要返回FAILURE。
测试示例
create table t(id int, birthday date);
insert into t values(1, '2020-09-10');
insert into t values(2, '2021-1-2');
select * from t;
注意:所有的字符都是英文。浏览器如果将英文字符转成中文字符,请留意。
如何选择date的存储长度
当前已经有的字段类型有:INTS/FLOATS/CHARS,这几个字段的内存大小都是4个字节。而题目中要求 date 类型,时间范围在1970年1月1日和2038年2月之间,说明date 字段也可以用4个字段来存储。这个原理可以参考time函数的说明,4个字节存储的时间戳,如果起始时间是1970年1月1日,那么将会在2038年某一天越界,而这一天是在2038年2月之后的。因此 date 字段也可以使用 4 字节存储。
使用4字节存储的好处还有,可以将4字节数据直接当做一个整数来处理,这样做比较运算时,也可以直接使用整数运算。
如何解析date 相关SQL
date作为一个关键字,可以直接在lex文件中添加。
[Dd][Aa][Tt][Ee] RETURN_TOKEN(DATE);
当然也需要增加token DATE。
对于日期数据,比如"2021-10-25",建议不要在词法解析和语法解析模块中写正则表达式来解析,因为它本身就是一个字符串。如果写正则表达式来解析,那就不能再将它作为普通字符串来处理,另外,正则表达式规则将会非常复杂,难以维护和扩展。比如我想让日期支持更多的格式:"2021/10/25","2021年10月25日";对与普通的字符串字段,理论上是能够接收"2021-10-25",这样的字符串作为参数去更新或插入的,如果在词法/语法解析中处理,那还需要处理使用日期更新字符串字段的场景。
需要考虑的场景
日期解析
需要判断类型为日期的地方,都需要按照一定格式去解析日期。当前输入格式年月日是按照'-'来分隔的,这样就非常简单了。将字符串分割为3个字符串,然后分别当成数字解析就可以。
日期是否合法
用字符串表示日期是有合法性要求的。比如2021-02-30,就不能算是正确的日期。
可能出现日期的地方有(不一定全面):
-
插入数据的值;
-
更新数据的值;
-
比较条件中的日期;
考虑再周全一点,可以支持一下聚合函数中有date数据类型。
建表
建表需要支持date类型字段
建索引
当前Miniob默认支持了B+-Tree索引,需要对这个索引做扩展。
日期比较
查询条件中可能有日期,查询可能是通过索引查询,也可能只是普通的查询。
输出格式
注意按照题目提示来输出 "YYYY-mm-dd",位数不够,需要用'0'填充。
Date实现解析
此实现解析有往届选手提供。具体代码实现已经有所变更,因此仅供参考。
- by caizj
DATE的存储
一种实现方式:date以int类型的YYYYMMDD格式保存,比如2021-10-21,保存为整数就是2021*1000 + 10*100 + 21,在select展示时转成字符串YYYY-MM-DD格式,注意月份和天数要使用0填充。
在parse.cpp中,参考
int value_init_date(Value* value, const char* v) {
value->type = DATES;
int y,m,d;
sscanf(v, "%d-%d-%d", &y, &m, &d);//not check return value eq 3, lex guarantee
bool b = check_date(y,m,d);
if(!b) return -1;
int dv = y*10000+m*100+d;
value->data = malloc(sizeof(dv));//TODO:check malloc failure
memcpy(value->data, &dv, sizeof(dv));
return 0;
}
修改点
语法上修改支持
需要可匹配date的token词和DATE_STR值(一定要先于SSS,因为date的输入DATE_STR是SSS的子集)
语法(yacc文件)上增加type,value里增加DATE_STR值
[Dd][Aa][Tt][Ee] RETURN_TOKEN(DATE_T); // 增加DATE的token,需要在yacc文件中增加DATE_T的token
{QUOTE}[0-9]{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01]){QUOTE} yylval->string=strdup(yytext); RETURN_TOKEN(DATE_STR); // 使用正则表达式过滤DATE。需要在yacc文件中增加 %token <string> DATE_STR
同时,需要增加一个DATE类型,与INTS,FLOATS等含义相同:
// in parse_defs.h
typedef enum { UNDEFINED, CHARS, INTS, FLOATS, DATES, TEXTS, NULLS } AttrType;
Date的合法性判断
输入日期的格式可以在词法分析时正则表达式里过滤掉。润年,大小月日期的合法性在普通代码中再做进一步判断。
在parse阶段,对date做校验,并格式化成int值保存(参考最前面的代码),同时对日期的合法性做校验,参考:
bool check_date(int y, int m, int d)
{
static int mon[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
bool leap = (y%400==0 || (y%100 && y%4==0));
return y > 0
&& (m > 0)&&(m <= 12)
&& (d > 0)&&(d <= ((m==2 && leap)?1:0) + mon[m]);
}
增加新的类型date枚举
代码里有多处和类型耦合地方(增加一个类型,要动很多处离散的代码,基础代码在这方面的可维护性不好)
包括不限于,以下几处:
- DefaultConditionFilter 需要增加DATES类型的数据对比。因为这里将date作为整数存储,那么可以直接当做INTS来对比,比如:
case INTS:
case DATES: {
// 没有考虑大小端问题
// 对int和float,要考虑字节对齐问题,有些平台下直接转换可能会跪
int left = *(int *)left_value;
int right = *(int *)right_value;
cmp_result = left - right;
} break;
- BplusTreeScanner
与
DefaultConditionFilter类似,也需要支持DATE类型的对比,可以直接当做整数比较。参考其中一块代码:
case INTS:case DATES: {
i1 = *(int *) pdata;
i2 = *(int *) pkey;
if (i1 > i2)
return 1;
if (i1 < i2)
return -1;
if (i1 == i2)
return 0;
}
break;
- ATTR_TYPE_NAME(storage/common/field_meta.cpp) 保存元数据时,需要这里的信息,比较简单,参考:
const char *ATTR_TYPE_NAME[] = {
"undefined",
"chars",
"ints",
"floats",
"dates"
};
- insert_record_from_file(storage/default/default_storage_stage.cpp)
这个接口主要是为了支持从文件导入数据的,同样,实现可以与int类型保持一致。
switch (field->type()) {
case INTS: case DATES:{
deserialize_stream.clear(); // 清理stream的状态,防止多次解析出现异常
deserialize_stream.str(file_value);
int int_value;
deserialize_stream >> int_value;
if (!deserialize_stream || !deserialize_stream.eof()) {
errmsg << "need an integer but got '" << file_values[i]
<< "' (field index:" << i << ")";
rc = RC::SCHEMA_FIELD_TYPE_MISMATCH;
} else {
value_init_integer(&record_values[i], int_value);
}
}
Date select展示
TupleRecordConverter::add_record时做格式转换,需要按照输出要求,将日期类型数据,转换成合适的字符串。参考:
case DATES: {
int value = *(int*)(record + field_meta->offset());
char buf[16] = {0};
snprintf(buf,sizeof(buf),"%04d-%02d-%02d",value/10000, (value%10000)/100,value%100); // 注意这里月份和天数,不足两位时需要填充0
tuple.add(buf,strlen(buf));
}
break;
异常失败处理
只要输入的日期不合法,输出都是FAILURE\n。包括查询的where条件、插入的日期值、更新的值等。这里在解析时(parse.cpp)中就可以直接返回错误。
自测覆盖点
- 日期输入,包括合法和非法日期格式。非法日期可以写单元测试做。
- 日期值比较=、 >、 <、 >=、 <=
- 日期字段当索引。很多同学漏掉了这个点。
- 日期展示格式,注意月份和天数补充0
miniob - drop table 实现解析
此实现解析有往届选手提供。具体代码实现已经有所变更,因此仅供参考。
代码部分主要添加在:
drop table 与create table相反,要清理掉所有创建表和表相关联的资源,比如描述表的文件、数据文件以及索引等相关数据和文件。
sql流转到default_storge阶段的时候,在处理sql的函数中,新增一个drop_table的case。
drop table就是删除表,在create table t时,会新建一个t.table文件,同时为了存储数据也会新建一个t.data文件存储下来。同时创建索引的时候,也会创建记录索引数据的文件,在删除表时也要一起删除掉。
那么删除表,就需要删除t.table文件、t.data文件和关联的索引文件。
同时由于buffer pool的存在,在新建表和插入数据的时候,会写入buffer pool缓存。所以drop table,不仅需要删除文件,也需要清空buffer pool ,防止在数据没落盘的时候,再建立同名表,仍然可以查询到数据。
如果建立了索引,比如t_id on t(id),那么也会新建一个t_id.index文件,也需要删除这个文件。
这些东西全部清空,那么就完成了drop table。
具体的代码实现如下: 在default_storage_stage.cpp 中的处理SQL语句的case中增加一个
case SCF_DROP_TABLE: {
const DropTable& drop_table = sql->sstr[sql->q_size-1].drop_table; // 拿到要drop 的表
rc = handler_->drop_table(current_db,drop_table.relation_name); // 调用drop table接口,drop table要在handler中实现
snprintf(response,sizeof(response),"%s\n", rc == RC::SUCCESS ? "SUCCESS" : "FAILURE"); // 返回结果,带不带换行符都可以
}
break;
在default_handler.cpp文件中,实现handler的drop_table接口:
RC DefaultHandler::drop_table(const char *dbname, const char *relation_name) {
Db *db = find_db(dbname); // 这是原有的代码,用来查找对应的数据库,不过目前只有一个库
if(db == nullptr) {
return RC::SCHEMA_DB_NOT_OPENED;
}
return db->drop_table(relation_name); // 直接调用db的删掉接口
}
在db.cpp中,实现drop_table接口
RC Db::drop_table(const char* table_name)
{
auto it = opened_tables_.find(table_name);
if (it == opened_tables_.end())
{
return SCHEMA_TABLE_NOT_EXIST; // 找不到表,要返回错误,测试程序中也会校验这种场景
}
Table* table = it->second;
RC rc = table->destroy(path_.c_str()); // 让表自己销毁资源
if(rc != RC::SUCCESS) return rc;
opened_tables_.erase(it); // 删除成功的话,从表list中将它删除
delete table;
return RC::SUCCESS;
}
table.cpp中清理文件和相关数据
RC Table::destroy(const char* dir) {
RC rc = sync();//刷新所有脏页
if(rc != RC::SUCCESS) return rc;
std::string path = table_meta_file(dir, name());
if(unlink(path.c_str()) != 0) {
LOG_ERROR("Failed to remove meta file=%s, errno=%d", path.c_str(), errno);
return RC::GENERIC_ERROR;
}
std::string data_file = std::string(dir) + "/" + name() + TABLE_DATA_SUFFIX;
if(unlink(data_file.c_str()) != 0) { // 删除描述表元数据的文件
LOG_ERROR("Failed to remove data file=%s, errno=%d", data_file.c_str(), errno);
return RC::GENERIC_ERROR;
}
std::string text_data_file = std::string(dir) + "/" + name() + TABLE_TEXT_DATA_SUFFIX;
if(unlink(text_data_file.c_str()) != 0) { // 删除表实现text字段的数据文件(后续实现了text case时需要考虑,最开始可以不考虑这个逻辑)
LOG_ERROR("Failed to remove text data file=%s, errno=%d", text_data_file.c_str(), errno);
return RC::GENERIC_ERROR;
}
const int index_num = table_meta_.index_num();
for (int i = 0; i < index_num; i++) { // 清理所有的索引相关文件数据与索引元数据
((BplusTreeIndex*)indexes_[i])->close();
const IndexMeta* index_meta = table_meta_.index(i);
std::string index_file = index_data_file(dir, name(), index_meta->name());
if(unlink(index_file.c_str()) != 0) {
LOG_ERROR("Failed to remove index file=%s, errno=%d", index_file.c_str(), errno);
return RC::GENERIC_ERROR;
}
}
return RC::SUCCESS;
}
数据库管理系统实现基础讲义
作者 华中科技大学谢美意 左琼
版权声明
本版权声明仅针对《数据库管理系统实现基础讲义》(以下简称“本教材”)的所有内容。
- 本教材刊载的所有内容,包括但不限于文字报道、图片、视频、图表、标志标识、商标、版面设计、专栏目录与名称、内容分类标准等,均受《中华人民共和国著作权法》、《中华人民共和国商标法》、《中华人民共和国专利法》及适用之国际公约中有关著作权、商标权、专利权以及或其它财产所有权法律的保护,相应的版权或许可使用权均属华中科技大学谢美意老师、左琼老师所有。
- 凡未经华中科技大学谢美意老师、左琼老师授权,任何媒体、网站及个人不得转载、复制、重制、改动、展示或使用《数据库管理系统实现基础讲义》的局部或全部的内容。如果已转载,请自行删除。同时,我们保留进一步追究相关行为主体的法律责任的权利。
- 本教材刊载的所有内容授权给北京奥星贝斯科技有限公司。
第1章 数据库管理系统概述
1.1 课程简介
随着信息时代的发展,数据的重要性日益凸显,它是各级政府机构、科研部门、企事业单位的宝贵财富和资源,因此数据库系统的建设对于这些组织的生存和发展至关重要。作为数据库系统的核心和基础,数据库管理系统(Data Base Management System,DBMS)得到了越来越广泛的应用。DBMS帮助用户实现对共享数据的高效组织、存储、管理和存取,经过数十年的研究发展,已经成为继操作系统之后最复杂的系统软件。
对于DBMS的学习一般可分为两个阶段:
第一个阶段是学习DBMS的使用,包括如何运用数据库语言创建、访问和管理数据库,如何利用DBMS设计开发数据库应用程序。在这个阶段,学习者只需掌握DBMS提供的功能,并不需要了解DBMS本身的工作原理。
第二个阶段是学习DBMS的内部结构和实现机制。通过学习DBMS的实现技术,学习者对数据库系统的工作原理会有更深入的理解,这有助于学习者分析数据库系统在复杂应用环境中可能出现的各种性能问题,设计开发出更高效的数据库应用程序,并为其从事数据库管理软件和工具的开发及改进工作打下基础。
在本教程中,我们从DBMS开发者的视角,讨论实现一个关系型DBMS需要考虑的一些关键问题,比如:数据库在存储介质上是如何组织和存储的?一条SQL语句是如何被正确地解析执行的?有哪些结构和方法可以用来快速定位数据库中的记录,提高存取效率?多用户共享数据库时,如何在避免并发错误的同时提高并发度?发生故障时,如何保证数据库能够恢复到正确的状态?在此基础上,学习者可以尝试自己从零开始开发一个简单的DBMS,并逐渐完善、增强它的功能,在这个过程中掌握各种计算机专业知识在DBMS这样的复杂系统软件设计中的应用,提高自己的系统综合能力。
作为学习本课程的前提条件,我们假设学习者已经具备了一定的计算机学科背景知识,包括关系代数、关系数据库语言SQL、数据结构、算法,以及操作系统及编译的相关知识。
1.2 数据库管理系统的组成
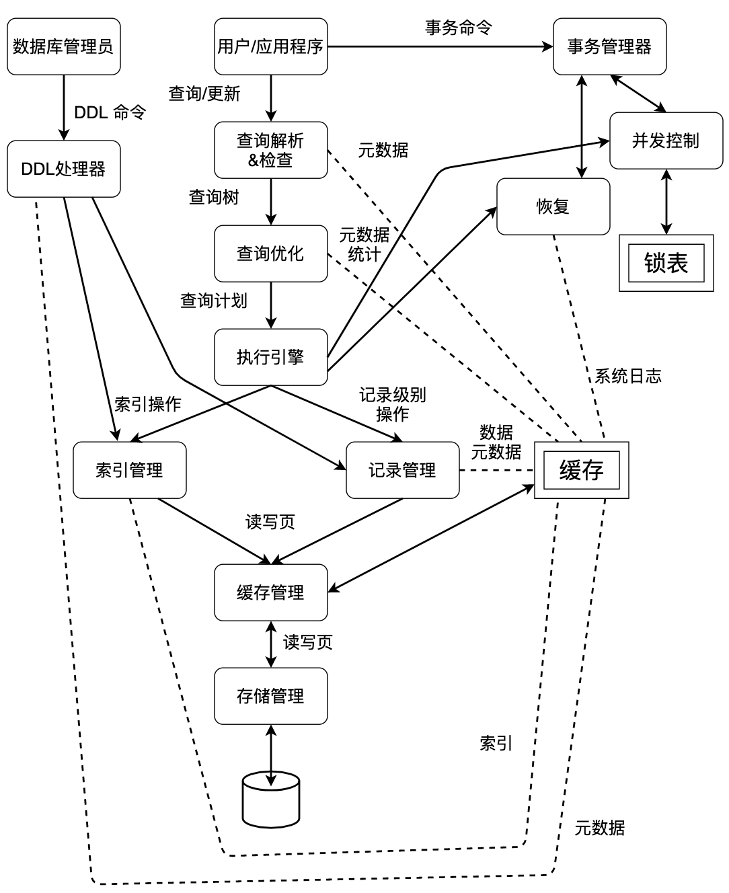
DBMS允许用户创建数据库并对数据库中的数据进行查询和修改,同时提供故障时的数据恢复功能和多用户同时访问时的并发控制功能。图1-1是一个DBMS的内部结构示意图。其中单线框表示系统模块,双线框表示内存中的数据结构,实线表示控制流+数据流,虚线表示数据流。该图反映了DBMS的几大主要功能的处理流程,即数据定义、数据操纵和事务管理,这些功能均依赖底层的存储管理及缓冲区管理组件提供对磁盘中数据的访问支持。以下我们分别对这几个功能进行简要说明。
1.2.1 存储及缓冲区管理
数据库中的数据通常驻留在磁盘中,当系统需要对数据进行操作时,要先将其从磁盘读入内存。
存储管理器的任务是控制数据在磁盘上的放置和数据在磁盘与内存之间的交换。很多DBMS依赖底层操作系统的文件系统来管理磁盘中的数据,也有一些DBMS为了提高效率,直接控制数据在磁盘设备中的存储和访问。存储管理器登记了数据在磁盘上所处的位置,将上层模块提出的逻辑层面的页面访问请求映射为物理层面的磁盘访问命令。
缓冲区管理器将内存空间划分为与页面同等大小的帧,来缓存从磁盘读入的页面,并保证这些页面在内存和磁盘上的副本的一致性。DBMS中所有需要从磁盘获取信息的上层模块都需要与缓冲区管理器交互,通过缓冲区读写数据。这些信息包括以下类型:
- 数据:数据库自身的内容。
- 元数据:描述数据库的结构及其约束的数据库模式。
- 日志记录:记录事务对数据库所做修改的信息,用于保证数据库的一致性和持久性。
- 统计信息:DBMS收集和存储的关于表、索引等数据库对象的大小、 取值分布等信息,用于查询优化。
- 索引:支持对数据进行高效存取的数据结构。
1.2.2 DDL命令的处理
DDL是指数据定义语言,这类命令一般由DBA等有特殊权限的用户执行,用于定义或修改数据库的模式,比如创建或者删除表、索引等。关于数据库模式的描述信息称为元数据。元数据与普通数据一样,也是以表(称为系统表)的形式存在的。DDL命令由DDL处理器解析其语义,然后调用记录管理器及索引管理器对相应的元数据进行修改。
1.2.3 DML命令的处理
DML是指数据操纵语言,这类命令一般由普通用户或应用程序执行。DML又可分为对数据库的修改操作(增、删、改)和对数据库的查询操作。
对DML命令的处理中最重要的部分是查询处理。查询处理的过程分为以下几步:
- 查询分析及检查:先对查询语句的文本进行语法分析,将其转换为语法树,然后进行查询检查(例如,检查查询中所提到的关系是否确实存在),并将语法树中的某些结构转换成内部形式,形成查询树。查询树表示了一个关系代数表达式,即要在关系上执行的一系列操作。
- 查询优化:查询优化器利用元数据和关于数据的统计信息来确定哪个操作序列可能是最快的,将最初的查询树等价转换为最高效的操作序列。
- 查询执行:执行引擎负责查询计划的执行,它通过完成查询计划中的各个操作,得到最终的执行结果。在执行过程中,它需要与DBMS中很多其他组件进行交互。例如,调用记录管理器和索引管理器获取需要的数据,调用并发控制组件对缓冲区中的某条记录加锁以避免并发错误,或者调用日志组件登记对数据库所做的修改。
1.2.4 事务处理
事务是一组数据库操作,这组操作要么都做,要么都不做,不可分割。一个事务中包含哪些操作是由用户定义的,可以包含多个数据库操作,也可以只包含单个数据库操作。对事务的处理由事务管理器负责,它包括并发控制组件和日志及恢复组件,目的是保证事务的ACID特性,即原子性、一致性、隔离性和持久性。
事务管理器接收来自用户或应用程序的事务命令,从而得知什么时候事务开始、什么时候事务结束、以及事务的参数设置(例如事务的隔离级),然后在事务运行过程中执行下列任务:
- 登记日志:为了保证一致性和持久性,事务对于数据库的每一个修改都在磁盘上记录日志,以保证不管在什么时候发生故障,日志及恢复组件都能根据日志将数据库恢复到某个一致的状态。日志一开始被写到缓冲区中,然后会在适当的时机从日志缓冲区写回到磁盘中。
- 并发控制:事务的执行从表面上看必须是孤立的,但是在大多数系统中,实际上有许多事务在同时执行。因此,并发控制组件必须保证多个事务的各个动作以一种适当的顺序执行,从而使得最终的结果与这些事务串行执行的结果相同。常见的并发控制方式是封锁机制,通过加锁来防止两个事务以可能造成不良后果的方式存取同一数据。
1.3 关系模型和SQL
本教程讨论的关系型DBMS是以关系模型为理论基础的。另一方面,SQL作为一种关系数据库标准语言,得到了几乎所有商用关系DBMS的广泛支持。要实现一个关系DBMS,我们需要考虑如何在系统中支持符合关系模型定义的数据结构、数据操作和数据约束,同时支持用户通过SQL命令来访问系统。本节将简单回顾关系模型和SQL中的一些重要概念,并讨论二者的关系。
1.3.1关系模型
1970年,E.F.Codd在他的论文《A Relation Model of Data for Large Shared Data Banks》中首次提出关系模型。关系模型相对于层次模型和网状模型的优势在于:它提供了一种只使用自然结构来描述数据的方法,而不需要为了方便机器表示而附加任何额外的结构。这样就为更高级的数据语言提供了基础,这种语言使得程序能够独立于数据的机器表示及组织方式,具有更好的数据独立性。
1.3.1.1关系
关系模型采用的数据结构称为关系。在关系模型中,数据库中的全部数据及数据间的联系都用关系来表示。关系是一个无序的元组集合,每个元组由一组属性值构成,表示一个实体。一个有n个属性的关系称为n元关系。由于关系中的元组是无序的,因此DBMS可以采用任何它希望的方式存储它们,以便进行优化。
1.3.1.2 主键和外键
主键和外键反映了关系模型的实体完整性约束和参照完整性约束。
主键可唯一地标识关系中的一个元组,以确保没有任何两个元组是完全一样的。如果用户没有定义主键,有些DBMS会自动创建内部主键。
外键指定一个关系中的属性在取值时必须与另一个关系中的某个元组相对应,不能随意取值。
1.3.1.3 关系代数
关系代数是关系模型定义的一组运算符,用于检索和操作关系中的元组。每个运算符接受一个或多个关系作为输入,并输出一个新的关系。为了表示查询,可以将这些运算符连接在一起以创建更复杂的运算,称为关系代数表达式。
常见的关系代数运算符包括:
- 选择(selection):选择运算是从关系R中选取满足给定条件的元组构成结果关系,记作σF(R)。
- 投影(Projection) :投影运算是从关系R中选取若干属性列A构成结果关系,记作 ΠA(R)。
- 并( Union ) :两个关系R和S的并是由属于R或属于S的元组构成的集合,记为 R∪S。
- 交( Intersection) :两个关系R和S的交是由既属于R又属于S的元组构成的集合,记为 R ∩ S。
- 差(Difference ) :两个关系R和S的差是由属于R但不属于S的元组构成的集合,记为 R-S。
- 笛卡尔积( Cartesian Product) :两个关系R和S的笛卡尔积是由这两个关系中元组拼接而成的所有可能的元组的集合,记为R×S。
- 自然连接(Natural Join) :两个关系R和S的自然连接是由这两个关系中在共同属性上取值相等的元组拼接而成的所有可能的元组的集合,记为R⋈S。
关系代数可以被视为一种过程化语言,因为一个关系代数表达式指定了查询的具体计算步骤。例如, 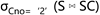 指定的计算步骤是先计算关系S和SC的自然连接,然后选择,而
指定的计算步骤是先计算关系S和SC的自然连接,然后选择,而  指定的计算步骤则是先选择后连接。这两个表达式其实是等价的,它们的计算结果相同,但是计算速度却不同,后者明显更快。如果像这样由用户来指定查询的计算步骤,性能优化的压力就会落在用户身上,因为他们必须考虑如何写出更高效的查询表达式。所以更好的方法是DBMS提供一种非过程化语言,用户只指定需要什么数据,而不指定如何找到它。这正是SQL的成功之处。
指定的计算步骤则是先选择后连接。这两个表达式其实是等价的,它们的计算结果相同,但是计算速度却不同,后者明显更快。如果像这样由用户来指定查询的计算步骤,性能优化的压力就会落在用户身上,因为他们必须考虑如何写出更高效的查询表达式。所以更好的方法是DBMS提供一种非过程化语言,用户只指定需要什么数据,而不指定如何找到它。这正是SQL的成功之处。
1.3.2 SQL
SQL 是关系数据库的标准语言,它是1974 年由Boyce和Chamberlin提出的,最初叫 Seque(Structured English Query Language), 并在IBM公司研发的关系数据库管理系统原型System R上实现,后改名为SQL(Structured Query Language)。SQL是一种通用的、功能极强的关系数据库语言,其功能不仅仅是查询,而是包括数据库模式创建、数据库数据的插入与修改、数据库安全性完整性定义与控制等一系列功能。但是,数据查询仍然是SQL中最重要、也最具特色的功能。
关系模型中的关系在SQL中被映射为表或视图。其中,表是指数据实际存储在数据库中的关系,视图是指不实际存储数据,但是需要时可以由实际存储的关系构造出来的关系。
需要指出的是,关系模型中的关系和SQL中的表和视图在概念上存在一些差异。前者是基于集合(set)的,即关系中的元组是不允许重复的;而后者是基于包(bag)的,允许表、视图或结果集中出现重复的元组。
SQL的查询通过SELECT语句来表达,它的基本语法如下:
SELECT <列名或表达式序列>
FROM <表名或视图名序列>
[WHERE <行条件表达式>]
[GROUP BY <列名序列>
[HAVING <组条件表达式>] ]
[ORDER BY <排序列名>[ASC|DESC] [,...]]
以上语法成分中,只有SELECT和FROM子句是必不可少的。此外,SQL还提供了一个强大的特性,允许在WHERE、FROM或HAVING子句中嵌入子查询。子查询也是一个SELECT语句,在上述的WHERE、FROM或HAVING子句中可以使用子查询的返回结果来进行计算,这也是SQL之所以称为"结构化"查询语言的原因。
对于一条典型的查询语句,其结果可以这样计算:
- 读取FROM子句中基本表及视图的数据,并执行笛卡尔积操作;
- 选取其中满足WHERE子句中条件表达式的元组;
- 按GROUP BY子句中指定列的值分组;
- 提取满足HAVING子句中组条件表达式的那些分组;
- 按SELECT子句投影出结果关系;
- 按ORDER BY子句对结果关系进行排序。
以上计算过程可以被看作是对一系列关系代数运算的执行。实际上一个SELECT语句在DBMS中就是被解析为一个关系代数表达式,再由执行引擎来对其进行计算的。但是对于同一条SELECT语句,可能存在多个等价的关系代数表达式。例如,对于以下语句:
SELECT 姓名
FROM 学生, 选课
WHERE 学生.学号=选课.学号 AND 课号=2 ;
存在多个等价的关系代数表达式:
- Π姓名(σ学生.学号=选课.学号 ∧ 课号=2 (学生×选课))
- Π姓名(σ课号=2 (学生⋈选课))
- Π姓名(学生⋈σ课号=2 (选课)
这三个表达式的计算代价差异巨大,而DBMS的一个重要任务就是通过查询优化处理找到其中代价最小的那一个。SQL采用的这种非过程化语言形式,既简化了用户的表达,又为DBMS优化查询语句的执行性能提供了巨大的灵活性。
第2章 数据库的存储结构
2.1 存储设备概述
大多数计算机系统中都存在多种数据存储类型,根据不同存储介质的速度和成本,可以把它们按层次结构组织起来,如图2-1所示。位于顶部的存储设备是最接近CPU的,其存取速度最快,但是容量最小,价格也最昂贵。离CPU越远,存储设备的容量就越大,不过速度也越慢,每比特的价格也越便宜。
按其存储数据的持久性,可将存储设备分为易失性存储和非易失性存储两类。
- 易失性存储: 易失性意味着当机器掉电时存储介质中的数据会丢失。易失性存储支持随机字节寻址方式,程序可以跳转到任意字节地址并获取数据。易失性存储通常指的是内存。
- 非易失性存储: 非易失性是指存储设备不需要通过连续供电来保证其存储的数据不丢失。非易失性存储设备是块寻址的,这意味着为了读取该设备中特定偏移位置上的一个值,必须先将包含这个值的一个块的数据加载到内存中。非易失性存储设备虽然也支持随机存取,但通常在顺序访问时(即同时读取多个连续块时)性能表现更好。目前常见的非易失性存储有固态硬盘(SSD)和机械硬盘(HDD),在本教程中不刻意区分,统称为磁盘。
除了上述存储设备,目前还有一种称为持久内存(persistent memory)的新型存储设备。持久内存既有内存的高速性,又有磁盘的持久性,兼具双重优势,不过这类设备不在本教程的讨论范围内。
2.2 面向磁盘的DBMS概述
根据数据库的主存储介质的不同,DBMS可分为面向磁盘(disk-oriented)和面向内存(memory-oriented)两种体系结构,本教程重点介绍经典的面向磁盘的体系结构。这种体系结构的特点是,为了保证在系统发生故障时的数据持久化,数据库使用非易失的磁盘作为主存储介质,但是由于系统不能直接操作磁盘上的数据,因此还需使用易失的内存作为缓存。众所周知,相对于内存,磁盘的访问速度非常慢,因此在面向磁盘的DBMS中,需要重点考虑的一个问题就是,如何在磁盘和内存之间交换数据才能减少磁盘I/O带来的性能延迟。
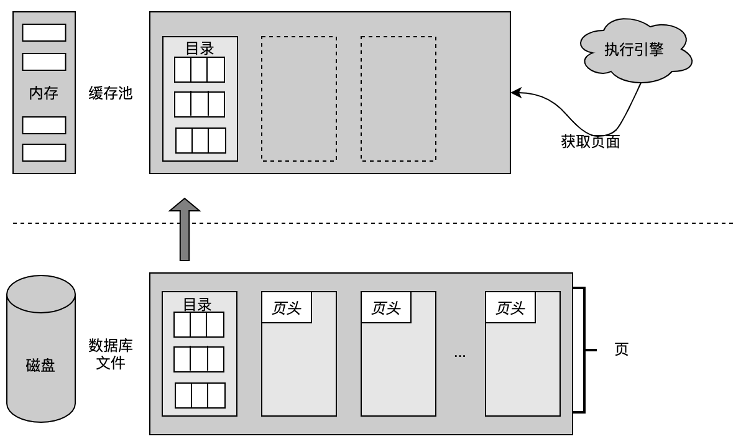
面向磁盘的DBMS的存储架构如图2-2所示。DBMS将数据库映射到文件中,这些文件由底层操作系统维护,永久存储在磁盘上。因为文件存取是操作系统提供的基本功能,所以我们默认文件系统总是作为DBMS的基础而存在的。主流操作系统提供的通常为无结构的流文件,DBMS会将每个文件再划分为固定大小的数据块,称为页(page)。页是DBMS在磁盘和内存间交换数据的基本单元。
如果需要对数据库进行读写操作,DBMS需要先将数据从磁盘读取到内存中的缓冲池内,缓冲池管理器负责在磁盘和内存之间以页为单位进行数据交换。DBMS的执行引擎在语句处理过程中需要使用某个数据页时,会向缓冲池提出请求,缓冲池管理器负责将该页读入内存,并向执行引擎提供该页在内存中的指针。当执行引擎操作那部分内存时,缓冲池管理器必须确保该页面始终驻留在那片内存区域中。
2.3 文件的组织结构
2.3.1文件的分页
DBMS最常见的做法是将数据库以文件的形式存储在磁盘上。有些DBMS可能使用一组文件来存储数据库,有些DBMS可能只使用单个文件。
从操作系统的角度来看,一个文件就是一个字节流序列,操作系统并不关心和了解文件的内容以及文件之间的关联性。数据库文件的内容只有创建它的DBMS才知道如何解读,因为它是由DBMS以其特定的方式来组织的。
数据库文件的组织和管理由DBMS的存储管理器负责,它将文件划分为页面的集合,并且负责跟踪记录这些页面的使用情况,包括哪些页面存储了什么数据,哪些页面是空闲的等等。页面中可以存储不同类型的数据,比如记录、索引等,但是DBMS通常不会将不同类型的数据混合存储在同一个页面中。
2.3.2 页的标识
每个页面都有一个唯一的标识符。如果数据库是单个文件,那么页面ID可以直接映射为文件内的偏移量;如果数据库包含多个文件,则还需加上文件标识符来进行区分。大多数DBMS都有一个间接层,能够将页面ID映射为文件路径和偏移量。系统上层模块请求一个页面时,先给出页面ID,存储管理器将该页面ID转换为文件路径和偏移量,并由此定位到对应页面。
2.3.3 页的大小
大多数DBMS使用固定大小的页面,因为支持可变大小的页面会带来很多麻烦。例如,对于可变大小的页面,删除一个页面可能会在数据库文件中留下一个空缺,而由于页面的大小不等,这个空缺位置很难被一个新页填满,从而导致碎片问题。
大多数数据库默认使用4~8KB的页大小,但是许多数据库允许用户在创建数据库实例时自定义页的大小。
需要注意区分以下两个关于页的概念:
- 硬件页: 即磁盘块,大小通常为4 KB,是磁盘I/O的基本单位。
- 数据库页: 大小通常为磁盘块大小的整数倍,是DBMS在磁盘和缓冲池之间交换数据的基本单位。
二者的区别在于,对硬件页的写操作是原子的,但是对数据库页的写操作则不一定。换言之,如果硬件页的大小为4KB,那么当系统尝试向磁盘写入一个硬件页时,这4KB数据要么全部写入,要么全部不写入,这一点是由存储设备来保证的。但是,如果数据库页大于硬件页,那么DBMS对一个数据库页的写操作将被操作系统分解为对多个硬件页的写操作,此时DBMS必须采取额外措施来确保数据被安全地写入磁盘,因为系统可能会在将一个数据库页写入到磁盘的过程中发生崩溃,从而导致该数据库页的内容出现不一致性错误。
2.3.4 堆文件
关系是记录的集合,这些记录在数据库文件中可以有多种组织方式:
- 堆文件组织( heap file organization) :堆文件是页的无序集合,记录在页中以随机的顺序存储。即,一条记录可以放在文件中的任何地方,只要那里有足够的空间存放这条记录,记录间不用考虑先后顺序的。 通常每个关系使用一个单独的堆文件。
- 顺序文件组织(sequential file organization):记录根据其"查找键"的值顺序存储。
- 散列文件组织( hash file organization) :在每条记录的某个/些属性上计算一个散列函数,根据散列的结果来确定将记录放到文件的哪个页面中。
在本节中,我们重点介绍堆文件的组织方式。由于这种组织方式并不关心记录间的顺序,因此DBMS只需要登记堆文件中哪些页面中是存储了数据的(数据页),哪些页面是空闲的(空闲页)。具体可以采用以下两种表示形式:
- 链表:以链表的形式将文件中的空闲页和数据页分别勾连起来,并在文件的首页维护两个指针,分别指向空闲页链表和数据页链表的第一个页面,如图2-3所示。这种方式下,如果想要找到一个特定的数据页,需要从链首开始逐个扫描链表中的页面,直到找到为止,I/O开销较大。
- 页目录:维护一种特殊的页面(目录页),在该页中记录每个数据页的位置以及该数据页中剩余的空闲空间大小,如图2-4所示。页目录将页面的状态信息集中存放在一起,可以提高查找特定页面的速度。
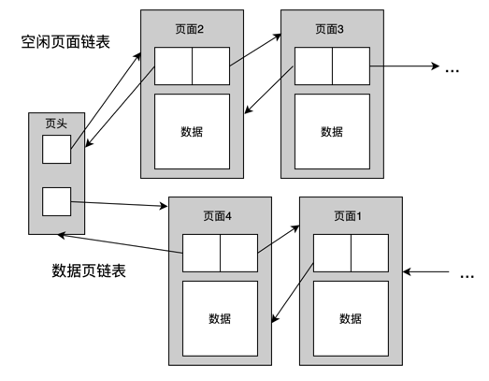
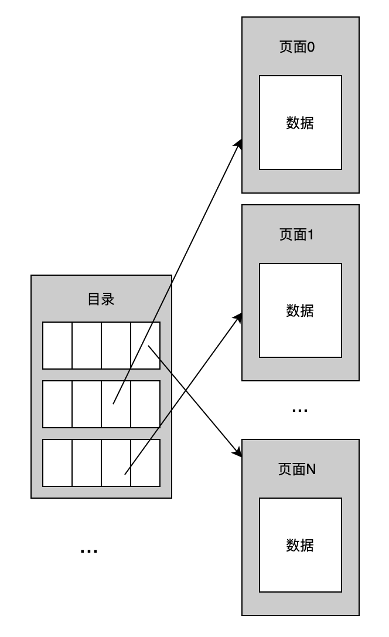
2.4 页的组织结构
一个页面的内部结构可以粗略的划分为两部分:
- 页头 :页头登记了关于页面内容的元数据,如页面大小、校验和、DBMS版本、事务可见性、压缩信息等。有些系统(如Oracle)要求页面是自包含的,即关于该页的所有描述信息都可以在该页面中找到。
- 数据区 :存放数据的区域。这里我们只讨论如何在数据区中存放记录。目前DBMS中最常用的方法是采用槽式页面。这种方法将数据区划分为一个个插槽(slot),每个插槽中放置一条记录。
注意,本节的讨论基于以下限制条件:(1)不存在整个数据区放不下单条记录的情况;(2)一条记录必须包含在单个页面中,换言之,没有哪条记录是一部分包含在一个页面中、一部分包含在另一个页面中的(第5节讨论的溢出页除外),这个限制可以简化并加速数据访问。
2.4.1 槽式页面
在槽式页面结构中,为了登记当前页面中有多少条记录以及每条记录的位置,必须在页头中维护以下信息:
- 本页中已使用的槽的数量;
- 最后一个已使用的槽的起始位置;
- 一个槽数组,登记本页中每个记录的起始位置。
如果允许记录是变长的,我们一开始并不能确定一个页面中能存放多少条记录,因此也就无法确定槽数组的最大长度,也就是说页头所占的区域大小是不确定的。因此比较合理的做法是,向页中插入记录时,槽数组从前向后增长,而被插入的记录数据则是从页尾向前增长。当槽数组和记录数据相遇时,则认为该页面是满页。槽式页面的布局示意图如图2-5所示。
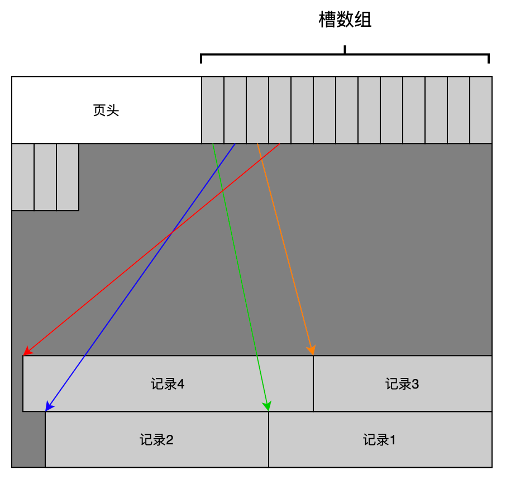
2.4.2 插入记录
向关系中插入一条记录时,对于堆文件,只需要找到一个有足够空闲空间能放得下这条记录的页面,或当所有已分配页面中都没有足够空闲空间时,就申请一个新的空闲页,然后将记录放置在那里。
2.4.3 删除记录
从页中删除记录时,需要考虑如何回收该记录的空间。
一种方法是在页内滑动记录,使得记录间没有空隙,从而保证页面中未使用的区域一定位于槽数组和已使用区域之间,图2-5表示的就是这种方式。
如果不滑动记录,则需要在页头维护一个空闲区列表,以保证当向页中插入一条新记录时,我们能知道该页中的空闲区在哪里,有多大。当然,页头通常不必存储全部空闲区列表,只存列表的链头就够了,然后可以使用空闲区自身的空间存储下一个空闲区的信息。
2.4.4 修改记录
如果修改的是定长记录,对页面存储没有影响,因为修改后记录占用的空间与修改前完全相同。但是如果修改的是变长记录,就会碰到与插入和删除类似的问题。
如果修改后的记录比其旧版本长,则我们需要在当前页面中获得更多的空间,这个过程可能涉及记录的滑动。如果当前页面中的空闲区域不够,还需要将记录移动到其他页面。反之,如果记录由于修改而变短,我们可以像删除记录时那样回收其释放的空间。
2.5 记录的组织结构
记录本质上就是一个字节序列,如何将这些字节解释为属性类型和值是DBMS的工作。与页面结构类似,记录内部结构也可以分为两部分:
- 记录头 :存放关于记录的元数据,例如DBMS并发控制协议的可见性信息(即哪个事务创建/修改了此记录的信息)、NULL值的位映射等。注意,关于数据库模式的元数据没有必要存储在记录头里。
- 记录数据 :包含记录中各个属性的实际数值。如前所述,大多数DBMS不允许记录的长度超过页面的大小,且一个页面中一般只存放同一个关系的记录。
2.5.1 定长记录
定长记录全部由定长字段组成,是最简单的记录组织形式。定长记录的插入和删除是比较容易实现的,因为被删除的记录留出的可用空间恰好是插入新的记录所需要的空间。
定长记录在组织时需要注意的一个问题是内存对齐问题。很多处理器需要在数据的开始地址为4或8的倍数时才能实现更高效的内存读写,所以DBMS在组织记录数据时通常会根据情况使所有字段的起始地址是4或8的倍数。采用这种做法时,一个字段前可能会存在一些没有被上一个字段使用的空间,这些空间其实是被浪费掉了。但尽管如此,这样做还是有必要的。因为记录虽然是存放在磁盘而不是内存中,但是对记录的操作仍需在内存中进行,所以在组织记录时需要考虑如何让它在内存能够被高效访问。
2.5.2 变长记录
变长记录允许记录中存在一个或多个变长字段。由于变长字段在记录中的偏移位置是不确定的,因此记录中必须包含足够多的信息,让我们能够方便地提取记录的任何字段。变长记录的实现可以采用以下两种方法。
一种简单有效的实现方法,是将所有定长字段放在变长字段之前,然后在记录头写入以下信息:(1)记录长度;(2)除第一个变长字段之外的所有变长字段的偏移位置。之所以不需要存第一个变长字段的偏移位置,是因为我们知道第一个变长字段就紧跟在定长字段之后。一个变长记录的例子如图2-6所示,该记录共包含四个字段,其中有两个变长字段:name和address。
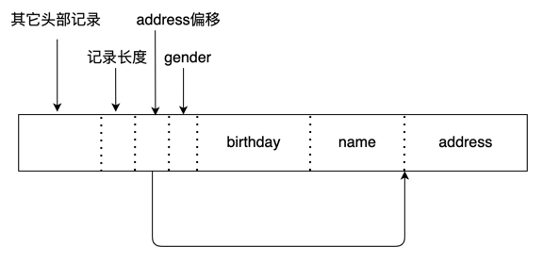
变长记录的另一种表示方法是保持记录定长,将变长部分放在另一个溢出页中,而在记录本身存储指向每一个变长字段开始位置的指针,如图2-7所示。
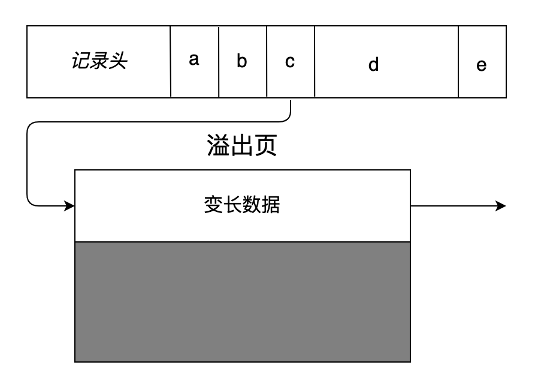
这种方法的好处是可以保持记录定长,能够更有效地对记录进行搜索,记录也很容易在页内或页间移动。但是另一方面,将变长部分存储在另一个页中,增加了为检索一条记录的全部数据而需要进行的磁盘I/O次数。
溢出页不仅可以存储变长字段,还可以用于存储大值数据类型的字段,比如TEXT和BLOB字段,这些数据往往需要使用多个页面来存储。
2.6 缓冲池管理
面向磁盘的DBMS的一个主要目标就是尽量减少磁盘和内存之间传输的页面数量。减少磁盘访问次数的一种方法是在内存中保留尽可能多的页面,理想情况下,要访问的页面正好都已经在内存中了,这样就不再需要访问磁盘了。
但是在内存中保留所有的页面是不可能的,所以就需要有效地管理内存中用于缓存页面的空间,尽可能提高页面在内存中的命中率。用于缓存页面的那部分内存空间称为缓冲池,负责缓冲池空间分配的子系统称为缓冲池管理器。
2.6.1 缓冲池结构
缓冲池本质上是在DBMS内部分配的一大片内存区域,用于存储从磁盘获取的页面。这片内存空间被组织为一个数组,其中每个数组项被称为一个帧(frame),一个帧正好能放置一个页面。当一个页面被请求时,DBMS首先搜索缓冲池,如果在缓冲池中没有找到该页,就从磁盘获取该页的副本,并放置到缓冲池的一个帧中。缓冲池的组织结构如图2-8所示。
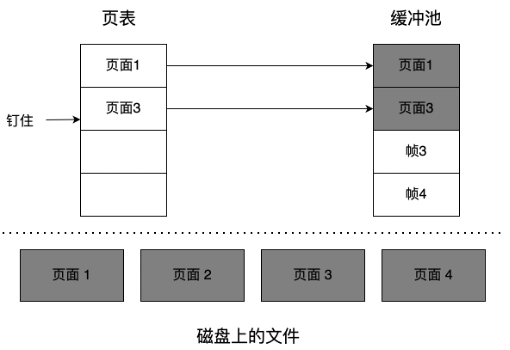
为了有效和正确地使用缓冲池,缓冲池管理器必须维护一些元数据。
页表是一个内存哈希表,用于登记当前已经在内存中的页面的信息。页表将页面ID映射到缓冲池中一个帧的位置。因为缓冲池中页面的顺序不一定反映磁盘上的顺序,所以需要通过这个额外的数据结构来定位页面在缓冲池中的位置。
除了保存页面的内存地址,页表还为每个页面维护一个脏标志和一个引用计数器。
- 脏标志:脏标志由线程在修改页面时设置。如果一个页面被设置了脏标志,就意味着缓冲池管理器必须将该页写回磁盘,以保证磁盘上的页面副本包含最新的数据。
- 引用计数:引用计数表示当前访问该页(读取或修改该页)的线程数。线程在访问该页之前必须增加引用计数。如果页的引用计数大于零,说明该页面正在被使用,此时不允许缓冲池管理器从内存中淘汰该页。
关于缓冲池中的内存空间如何分配的问题,缓冲池管理器可采取两种策略:
- 全局策略:有利于当前整体工作负载的策略。全局策略综合考虑所有活动事务,以找到分配内存的最佳方案。
- 本地策略:以保证单个查询或事务运行得更快为目标的策略。本地策略将一个帧分配给特定事务时,不考虑其他并发事务的行为,即使这样可能对整体工作负载不利。
2.6.2 缓冲池替换算法
与其他应用程序一样,DBMS对数据库文件的读写操作都需要通过调用操作系统的接口来实现。通常,为了优化I/O性能,操作系统自身也维护了一个缓冲区来缓存从磁盘读入的数据块。这个缓冲区和DBMS的缓冲池在功能上显然是重复的,会导致同一个数据库页面的数据在内存中的冗余存储,而且操作系统缓冲区的管理策略还使得DBMS难以控制内存与磁盘之间的页面交互。因此,大多数DBMS都使用直接I/O绕过操作系统的缓存。
当DBMS需要释放一个帧来为新的页面腾出空间时,它必须决定从缓冲池中淘汰哪个页面,这取决于DBMS采用的缓冲池替换算法。替换算法的目标是提高正确性、准确性、速度和元数据开销。需要注意的是,引用计数大于零的页面是不能淘汰的。
常用的替换算法有最近最少使用(LRU)算法和时钟(CLOCK)算法。
- LRU算法:LRU算法为每个页面维护其最后一次被访问的时间戳,这些时间戳可以存储在一个单独的数据结构(如队列)中,以便对其进行排序来提高效率。需要淘汰页面时,DBMS总是选择淘汰时间戳最早的页面。
- CLOCK算法:CLOCK算法是一种近似LRU算法,它不需要每个页面都有单独的时间戳,而是为每个页面维护一个引用位。当某个页面被访问时,就将它的引用位的值置为1。想象页面被组织在循环缓冲区中,需要选择淘汰页面时,有一个"时钟指针"在循环缓冲区中扫描,检查页面的引用位是否为1。如果是,则将引用位重新置0并移动指针到下一个页面;否则,淘汰当前页面。
LRU算法和CLOCK算法应用于DBMS的缓冲池管理时存在许多问题。比如顺序扫描时,LRU和CLOCK容易使缓冲池的内容出现顺序溢出问题。因为顺序扫描会依次读取每个页面,所以读取页面的时间戳并不能反映我们实际想要哪些页面。换句话说,最近使用的页面实际上是最不需要的页面。
有三种解决方案可以解决LRU和CLOCK算法的缺点。
第一种解决方案是LRU-K,它会以时间戳的形式登记最后K次引用的历史,并计算连续引用之间的时间间隔,将此历史记录用于预测页面下一次被访问的时间。
第二种解决方案是对每个查询进行局部化,DBMS在每个查询的局部范围内选择要淘汰的页面,这样可以最小化每个查询对缓冲池的污染。
最后一种解决方案是优先级提示,它允许事务在查询执行期间根据每个页面的上下文,告诉缓冲池管理器该页面是否重要。
在淘汰页面时,对于脏页可以有两种处理方法:(1)总是优先淘汰缓冲池中的非脏页面;(2)先将脏页写回磁盘以确保其更改被持久化,然后再将其淘汰。后者会降低替换页面的速度;而前者虽然速度快,但是有可能将未来不会被再次访问的脏页留在缓冲池。
避免在淘汰页面时执行页面写出操作的一种方法是后台写。采用这种方法的DBMS会定期遍历页表并将脏页写入磁盘。当脏页被安全写入磁盘后,将该页面的脏标志重新置零。
2.6.3 缓冲池的优化
有许多方法来优化缓冲池,使其适合应用程序的工作负载。
(1)多缓冲池
DBMS可以维护多个用于不同目的的缓冲池,比如每个数据库使用一个缓冲池,每种页面类型使用一个缓冲池。然后针对其中存储的数据的特点,每个缓冲池可以采用量身定制的管理策略。
将所需页面映射到缓冲池有两种方法:对象ID和散列。对象ID这种方法需要扩展元数据,使其包含关于每个缓冲池正在管理哪些数据库对象的信息,然后通过对象ID,就可以实现从对象到特定缓冲池的映射。另一种方法是散列,DBMS散列页面ID以选择访问哪个缓冲池。
(2)预取
DBMS还可以根据查询计划通过预取页面来进行优化。然后,在处理第一组页面时,系统可以将第二组页面预取到缓冲池中。这种方法通常在顺序访问多个页面时使用。
(3)扫描共享
查询游标可以重用从磁盘读入的数据或操作符的计算结果。这种方法允许将多个查询附加到扫描表的单个游标上。当一个查询开始扫描时,如果已经有另一个查询在扫描,DBMS会将第一个查询附加到第二个查询的游标上。DBMS登记第二个查询加入时的位置,以便在到达数据结构末尾时结束扫描。
(4)缓冲池旁路
为了避免开销,顺序扫描操作符不会将获取的页存储在缓冲池中,而是使用正在运行的查询的本地内存。如果操作符需要读取磁盘上连续的大量页序列,那么这种方法可以很好地工作。缓冲池旁路也可以用于临时数据,如排序、连接。
2.6.4 其他内存池
除了元组和索引,DBMS还需要内存来存放其他东西。这些内存池中的内容可能并不总是来自磁盘或者需要写入磁盘,具体取决于实现。
- 排序+连接缓冲区
- 查询缓存
- 维护缓冲区
- 日志缓冲区
- 字典缓存
第3章 索引结构
3.1 索引结构概述
许多查询只涉及表中的少量记录。例如"查找学号为'U2021001'的学生的专业",这个查询最多只涉及学生表中的一条记录。如果系统为了找到学号为"U2021001"的记录而读取整个学生表,这样的操作方式显然是低效的。理想情况下,系统应该能够直接定位到这条记录。为了支持这种访问方式,需要额外设计一些与表相关联的附加结构,我们称之为索引。
索引是这样的数据结构:它以一个或多个属性的值为输入,并能快速地定位具有该值的记录的位置。建立索引的属性(组)称为查找键(search key)。与表一样,索引结构同样存储在数据库文件中。例如,我们可以用一个数据文件来存储一个表,用一个索引文件来存储一个索引。一个数据文件可能拥有一个或多个索引文件。
由于索引是表的附加结构,当表的内容发生变化时,DBMS必须同步更新该表的索引,以确保索引的内容与表的内容一致。由此可见,索引虽然有助于提高查询性能,但是索引本身也会带来存储和维护开销,因此在一个数据库应用中,具体创建什么索引、以及创建多少索引,用户是需要权衡的。不过在查询的执行过程中,是否需要使用索引、以及使用哪些索引,则是由DBMS来决定的,用户并不能干涉。如何恰当地利用索引来提高查询的执行效率,是DBMS的重要工作。
数据库系统中存在不同类型的索引结构,这些索引结构之间没有绝对的优劣之分,只能说某种索引结构在某种特定的场景下是最合适的。评价一种索引结构一般参考以下指标:
- 查找类型:该索引结构能有效支持的查找类型,比如等值查找、范围查找等。
- 查找时间:使用该索引结构找到一个特定索引项(集)所需的时间。
- 插入时间:插入一个新的索引项所需的时间,包括找到插入这个新索引项的正确位置,以及更新索引结构所需的时间。
- 删除时间:删除一个索引项所需的时间,包括找到待删除项所需的时间, 以及更新索引结构所需的时间。
- 空间开销:索引结构所占用的存储空间。
在本教程中,我们将介绍数据库系统中最常用的索引结构: B+树和散列表。
3.2 B+树
3.2.1 B+树的结构
B+树是一种平衡排序树,树中根结点到叶结点的每条路径的长度相同,并且保持键的有序排列。在B+树中进行搜索、顺序访问、插入和删除的时间复杂度均为O(log(n)),它是在数据插入和删除的情况下仍能保持其执行效率的几种使用最广泛的索引结构之一,几乎所有现代DBMS都使用B+树。
B+树可以定义为具有以下性质的m路搜索树:
- 除非整棵树只有一个结点,否则根结点至少有两个子结点;
- 除根结点外的所有内结点至少是半满的,即有⌈m/2⌉到m个子结点;
- 所有叶结点的深度相等;
- 叶结点中键的数量必须大于等于 ⌈(m-1)/2⌉ 且小于等于 m-1 ;
- 每个有k个键的内结点都有k+1个非空子结点;
- 叶结点中包含所有查找键值。
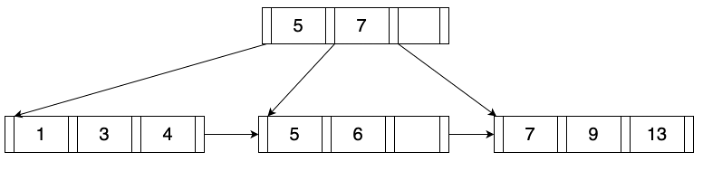
B+树的示意图如图3-1所示。树中的每个结点中都包含一个键/值对数组,这个数组是按键排序的。键/值对中的键来自索引的查找键,值则根据结点类型而有不同含义。如果结点是内结点,则值是指向子结点的指针。如果结点是叶结点,则结点中的值可能是记录ID,比如对于数据库中的非聚集索引,B+树中存放的就是指向记录位置的指针;叶结点中的值也可能是记录数据,比如对于聚集索引, B+树中存放的就是记录的实际数据。
在树的最底层,叶结点间通过兄弟指针链接起来,形成一个按所有键值大小排序的链表,以便更高效地支持范围查找等顺序处理。
图3-1中的B+树,其m的取值为4。在具体实现中,将B+树索引存储到磁盘文件中时,通常用一个页面来存储一个结点,在页面能够容纳的前提下,应该把m的值取得尽可能大,从而使得树的高度尽可能小。
3.2.2 B+树的查找
- 等值查找
假设有一棵B+树,如果想找出键值为K的记录,则需要执行从根结点到叶结点的递归查找,查找过程为:
-
若当前结点为内结点,且结点中的键为K1,K2,…,Kn,则根据以下规则来决定下一步对此结点的哪一个子结点进行查找:
-
如果K<K1,则下一个结点为第1个子结点;
-
如果Ki≤K<Ki+1,则下一个结点为第i+1个子结点;
-
如果K≥Kn,则下一个结点为第n+1个子结点。
递归执行此查找过程,直到查找到叶结点;
-
若当前结点为叶结点,在该结点的键值中查找,若第i个键值为K,则根据第i个值即可找到所需记录;否则查找失败。
-
范围查找
如果想在B+树中找出在范围[a, b]之间的所有键值,先通过等值查找来查找键a,不论键a在B+树中是否存在,都会到达可能出现a的叶结点,然后在该叶结点中查找等于或大于a的那些键。只要在当前叶结点中不存在比b大的键,就根据兄弟指针找到下一个叶结点,继续查找[a, b]之间的所有键值。
上面的查找算法在查找范围只有上界或者只有下界时也有效:
- 当查找范围为[a,+∞)时,先找到键a可能出现的叶结点,然后从该结点中第一个等于或大于a的键开始,一直到最后一个叶结点的最后一个键。
- 当查找范围为(‐∞, b]时,则从B+树的第一个叶结点开始向后查找,直到遇到第一个超过b的键时停止查找。
3.2.3 B+树的插入
要向B+树中插入一个新索引项,必须遍历该树并使用内部结点来确定将键插入到哪个叶结点。在插入过程中,当结点太满时需要对其进行拆分,过程如下:
-
找到正确的叶结点L;
-
将新索引项按顺序插入到L中:
-
如果L有足够的空间,则执行插入操作,算法结束;
-
否则,将L平均拆分为L和L2两个结点,并复制L2的第一个键,将其插入到L的父结点中。
-
如果父结点中有足够的空间,则执行插入操作,算法结束;否则拆分父结点,将该结点的中间键上移插入到其父结点,然后将剩余的索引项平均拆分为两个结点。递归执行此步骤直到算法结束。
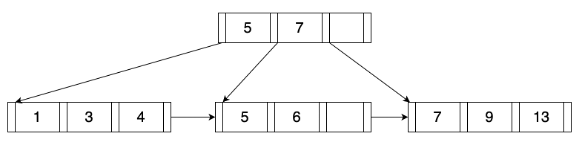

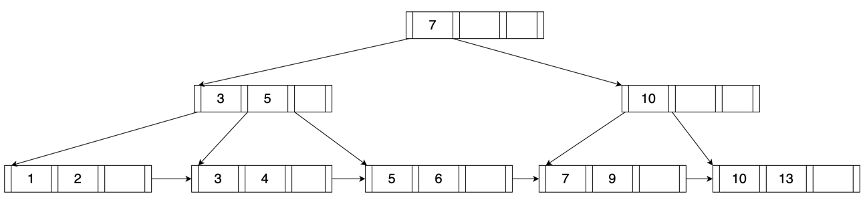
图3-2是向一棵4路B+树分别插入键值10和2的过程。可以看到,插入键值10后,原B+树中最右的叶结点发生了分裂,新增叶结点的第一个键值10被复制并插入到父结点中。插入键值2后,最左的叶结点发生了分裂,新增叶结点的第一个键值3被复制并插入到父结点中,而且还进一步导致了父结点的分裂,其中间键值7被上移并插入到新增的根结点中。
3.2.4 B+树的删除
在删除过程中,如果因删除索引项导致结点小于半满状态,则必须合并结点。过程如下:
-
找到待删除的索引项所在的叶结点L;
-
从L中删除该索引项,删除后:
-
如果L不低于半满状态,则算法结束;
-
否则,通过向兄弟结点借索引项来满足约束条件,如果能成功借到,则算法结束;
-
如果兄弟结点也没有多余的索引项可借,则合并L和兄弟结点,删除父结点中指向被合并子结点的索引项。递归执行以上删除操作,直至算法结束。
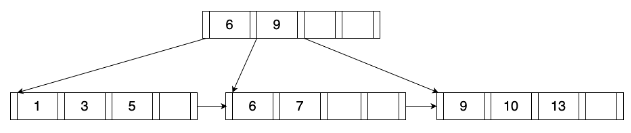
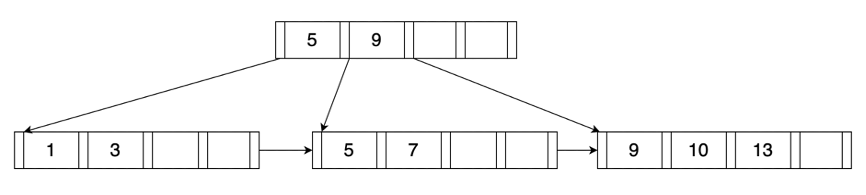
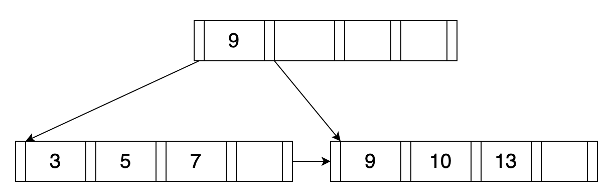
图3-3是从一棵5路B+树中先后删除键值6和1的过程。可以看到,删除键值6时,原B+树中第二个叶结点中的项数已经无法满足最低要求,因此向左边的兄弟结点借了1项来达到约束条件。删除键值1时,最左的叶结点中项数无法满足最低要求,而且兄弟结点也没有多余的项可借,因此只能对最左的两个结点进行合并。
3.2.5 非唯一查找键
基于某个查找键来构建索引时,假如表中存在两条或者多条记录在查找键属性上拥有相同的值,那么该查找键称为非唯一查找键。
非唯一查找键的一个问题在于影响记录删除的效率。假设某个查找键值出现了很多次,当表中拥有该查找键值的某条记录被删除时,为了维护索引与表数据的一致性,删除操作需要在B+树中查看很多个索引项,才能从中找出和被删除记录相对应的那个索引项并删除它,这个过程可能需要遍历多个叶结点。
解决以上问题的方法有两种:
一种简单的解决方法是创建包含原始查找键和其他额外属性的复合查找键,确保该复合查找键对于所有记录是唯一的,这种方法通常被大多数数据库系统使用。这个额外属性也叫唯一化属性,它可以是记录ID,或者是在拥有相同查找键值的所有记录中取值唯一的任何其他属性。删除一条记录时,先计算该记录的复合查找键值,然后再用这个复合键值到索引中查找。因为复合查找键值是唯一的,所以不会影响记录删除的效率。在这种方法中,一个查找键值在记录中出现多少次,它在索引中就会被重复存储多少次。
另一种方法是,每个查找键值在B+树中只存储一次,并且为该查找键值维护一个记录指针的桶(或者列表)来解决非唯一问题。这种方法虽然没有存储冗余信息,但是索引维护和修改起来更加复杂。
3.3 散列表
散列表也叫哈希表,是一种常见的数据结构,它通过把键值映射到桶数组中的某个位置来加快查找记录的速度。散列表中包含两个关键元素:
- 散列函数 :散列函数h以查找键(散列键)为参数并计算出一个介于0到B-1之间的整数。
- 桶数组 :桶数组是一个编号从0到B-1、长度为B的数组,其中包含B个链表头,每个链表头对应一个桶,用于存储记录。
构造散列表时,如果一条记录的查找键为K,则将该记录链接到桶号为h(K)的桶中存储。
散列表在DBMS中被广泛运用,例如基于散列表来组织数据文件、基于散列表来构造索引文件、或者基于散列表进行连接运算等。当散列表的规模大到内存难以容纳时,或者出于数据持久化的目的,就需要将散列表存储在磁盘中。本教程主要讨论散列表在磁盘上的实现。
磁盘中的散列表与内存中的散列表存在一些区别。首先,桶数组是由页面组成,而不是由指向链表的指针组成;其次,散列到某个桶中的记录是存储在磁盘上的页面而非内存中。因此,磁盘上的散列表在设计时需要考虑访问磁盘的I/O代价以及表规模的扩展问题。
3.3.1 静态散列表
对于一个散列表,如果其桶数组的规模B(即桶的数量)一旦确定下来就不再允许改变,则称其为静态散列表。
3.3.1.1散列函数
由于在设计时无法事先准确知道文件中将存储哪些搜索键值,因此我们希望选择一个具有下列特性的散列函数:
- 函数的输出是确定的。相同的搜索键值应该总是生成相同的散列值。
- 输出值的分布是随机且均匀的。散列函数应该表现为随机的,即散列值不应与搜索键的任何外部可见的排序相关,且不管搜索键值实际怎样分布,每个桶应分配到的记录数应该几乎相同。
- 易于计算。散列函数的执行时间不能太长,因为它需要执行很多次。
理想的散列函数是能将搜索键值均匀地分布到所有桶中,使每个桶含有相同数目的记录,但是这样的函数往往需要非常长的时间来进行计算。因此,散列函数需要在冲突率和快速执行之间进行权衡。目前最先进的散列函数是Facebook XXHash3。
3.3.1.2散列表的插入
当一个查找键为K的新记录需要被插入时,先计算h(K),找到桶号为h(K)的桶。如果桶内还有空间,我们就把该记录存放到此桶对应的页面中。如果该桶的页面中已经没有空间了,就增加一个新的溢出页,链接到该桶之后,并把新记录存入该页面。这种处理桶溢出问题的方式称为溢出链,如图3-4所示。
3.3.1.3散列表的删除
删除查找键值为K的记录与插入操作的方式类似。先找到桶号为h(K)的桶,由于不同的查找键值可能被映射到同一个桶中,因此还需要在桶内搜索,查找键值为K的记录,继而将找到的记录删除。删除记录后,如果允许记录在页面中移动,还可以选择合并同一桶链上的页面来减少链的长度。但是合并页面也有一定的风险,如果交替地往一个桶中插入和删除记录,可能导致页面被反复地创建和删除。
3.3.1.4散列表的效率
如果希望达到最好的查找效率,理想情况是散列表中有足够的桶,每个桶只由单个页面组成。如果是这样,那么查询一条记录就只需一次磁盘I/O,且记录的插入和删除也只需两次磁盘I/O。
为了减少桶溢出的可能性,桶的数量B可选为 (n/f)*(1+d),其中n是要存储的记录总数,f是一个桶中能存放的记录数,d表示避让因子,一般取值为0.2。这种做法会导致一定的浪费,平均每个桶有20%的空间是空的,好处则是减少了溢出的可能性。
但是,如果记录不断增长,而桶的数量固定不变,那么最终还是会出现很多桶都包含多个页面的情况。这种情况下,我们就需要在由多个页面构成的桶链中查找记录,每访问一个新的页面就增加一次磁盘I/O,这显然会严重影响散列表的查找效率。
3.3.2 动态散列表
静态散列表由于其桶的数量不能改变,因此当无法预知记录总数时,难以解决由于记录数不断增长而带来的性能问题。本节我们将讨论两种动态散列表,它们能够以不同的方式动态调整散列表的大小,既不需要重新构建整个表,又能保证每个桶大多只有一个页面,从而最大化读写效率。
3.3.2.1 可扩展散列表
与静态散列表相比,可扩展散列表在结构上做了以下改变:
- 增加了一个间接层,用一个指向页面的指针数组(桶地址表)而非页面数组来表示桶数组。
- 指针数组能动态增长,且数组长度总是2的幂,因此数组每增长一次,桶的数量就翻倍。
- 并非每个桶都单独拥有一个页面。如果多个桶的记录只需一个页面就能放下,那么这些桶可能共享一个页面,即多个桶指针指向同一个页面。
- 散列函数h为每个键计算出一个长度为N的二进制序列,N的值足够大(比如32),但是在某一时刻,这个序列中只有前i位(i≤N)被使用,此时桶的数量为 2i个。
可扩展散列表的一般形式如图3-5所示。
向可扩展散列表中插入键值为K的记录的方法如下:
-
计算h(K),取出该二进制序列的前i位,并找到桶数组中编号与之相等的项,定位到该项对应的页面,假设该页面的编号为j;
-
如果页面j中还有剩余空间,则将该记录插入该页面,操作结束;
-
如果页面j已满,则需要分裂该页面:
a) 如果i=ij,说明在桶地址表中只有一个表项指向页面j,此时分裂该页,需要增加桶地址表的 大小,以容纳由于分裂而产生的两个桶指针。令i=i+1,使桶地址表的大小翻倍。桶地址表扩 展后,原表中的每个表项都被两个表项替代,且这两个表项都包含和原始表项一样的指针, 所以也应该有两个表项指向页面j。此时,分配一个新的页面n,并让第二个表项指向页面n。 将ij和in的值均置为当前的i值,并将原页面j中的各条记录重新散列,根据前i位来确定该记录 是放在页面j中还是页面n中,然后再次尝试插入新记录。极端情况下,新纪录要插入的页面 可能仍然是满的,说明原页面j中的所有记录在分裂后仍然被散列到了同一个页面中,此时需 要继续上述分裂过程,直至为新纪录找到可存放的空间。
b) 如果i> ij,说明在桶地址表中有多个表项指向页面j,此时不需要扩大桶地址表就能分裂页面 j。分配一个新的页面n,将ij和in置为原ij加1后的值;调整桶地址表中原来指向页面j的表项, 其中一半仍指向页面j,另一半则指向新创建的页面n;重新散列页面j中的各条记录,将其分 配到页面j或页面n中,并再次尝试插入新记录。与上一种情况一样,插入仍有可能失败,此 时需继续进行页面分裂的处理。
以下是一个可扩展散列表的例子。图3-6(a)所示为一个小型的可扩展散列表,假设其散列函数h能产生4位二进制序列,即N=4。散列表只使用了1位,即i=1。此时桶数组只有2项,一个编号为0,一个编号为1,分别指向两个页面。第一页存放所有散列值以0开头的记录,第二页存放所有散列值以1开头的记录。每个页面上都标注了一个数字,表示由散列函数得到的二进制序列中的前几位用于判定记录在该页面中的成员资格。目前两个页面都只用了1位。
接下来向表中插人一个散列值为1010序列的记录。因为第一位是1,所以该记录应放入第二个页面,但第二页已经满了,因此需要分裂该页。而此时i2=i=l,因此先要将桶数组翻倍,令i=2,将数组的长度扩展为4。
扩展桶数组后,以0开头的两个项都指向存放散列值以0开头的记录的第一页,且该页上标注数字仍然为1, 说明该页中记录的成员资格只由其散列值的第一位判定。而原本存放散列值以1开头的记录的页面则需要分裂,把这个页面中以10开头和11开头的记录分别存放到两个页面中。在这两个页面上方标注的数字是2,表示该页面中记录的成员资格需要使用散列值的前两位来判定。改变后的散列表如图3-6(b)所示。
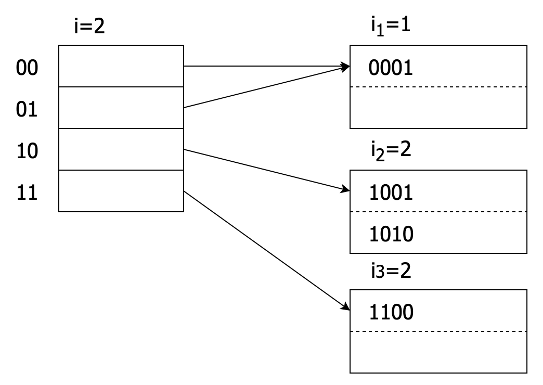
可扩展散列表的优点在于每个桶只有一个页面,所以如果桶地址表小到可以驻留在内存的话,查找一个记录最多只需要一次磁盘I/O。但是由于它是以桶数组翻倍的形式扩展的,所以也存在以下缺点:
- 随着i的增大,每次桶数组翻倍时需要做的工作将越来越多,而且这些工作还会阻塞对散列表的并发访问,影响插入和并发操作的效率。
- 随着i的增大,桶地址表会越来越大,可能无法全部驻留在内存,或者会挤占其他数据在内存中的空间,导致系统中的磁盘I/O操作增多。
3.3.2.2 线性散列表
针对可扩展散列表存在的问题,下面介绍另一种动态散列表,称为线性散列表。相对于可扩展散列表,线性散列表中桶的增长较为缓慢,它有以下特点:
- 桶数n的大小,要能使所有桶中的实际记录总数与其能容纳的记录总数之间的比值保持在一个指定的阈值之下(如80%),如果超过该阈值,则增加一个新桶。
- 允许桶有溢出页,但是所有桶的平均溢出页数远小于1。
- 若当前的桶数为n,则桶数组项编号的二进制位数i=⌈ log2n⌉。
令一个线性散列表当前桶数为n,桶数组项编号的二进制位数为i,向线性散列表中插入键值为K的记录的方法如下:
- 计算h(K),取出该二进制序列右端的i位,假设为a1a2…ai,令a1a2…ai对应的二进制整数为m。如果m<n,说明编号为m的桶存在,将记录存入桶m中;如果n≤m<2i,说明编号为m的桶还不存在,则将记录存入编号为(m-2i-1)的桶中,即将a1a2…ai中的a1改为0时对应的桶。
- 如果要插入的桶中没有空间,则创建一个溢出页,将其链到该桶上,并将记录就存入该溢出块中。
- 插入记录后,计算 (当前实际记录总数r) / (n个桶能容纳的记录总数) 的值,并跟阈值相比,若超过阈值,则增加一个新桶到线性散列表中。注意,新增加的桶和之前发生插入的桶之间没有任何联系。如果新桶编号的二进制表示为la2a3…ai,则分裂桶号为0a2a3…ai的桶中的记录,根据这些记录的散列值的后i-1位分别散列到这两个桶中。
当n的值超过2i时,需要将i的值加1。理论上,对于现有的桶编号,要在它们的位序列前面增加一个0,来保证跟新的桶编号的位数一致,但是由于桶编号被解释成二进制整数,因此实际上它们只需要保持原样即可。
以下是一个线性散列表的例子。
图3-7(a)所示为一个桶数n=2 的线性散列表,桶编号所需要的二进制位数i = ⌈ log22⌉ = 1,表中的记录数r=3。图中两个桶的编号分别为0和1,每个桶包含一个页面,每个页面能存放两个记录。假设散列函数产生4位二进制序列,用记录散列值的末位来确定该记录所属的桶,所有散列值以0结尾的记录放入第一个桶,以1结尾的记录放入第二个桶。
在确定桶数n时,本例使用的阈值是85%,即桶的平均充满率不超过总容量的85%。
下面先插入散列值为0101的记录。因为0101以1结尾,所以记录应放入第二个桶。插入该记录后,两个桶中存放了四个记录,平均充满率为100%,超过了85%,因此需要增加一个新桶,即桶数n=3。i = ⌈log23⌉ = 2,即桶编号需要2位。新增的桶的编号为10。接着,分裂桶00(即原来的桶0),将散列值为0000 (末两位为00)的记录保留在桶00中,散列值为1010(末两位为10)的记录存入桶10中,改变后的散列表如图3-7(b)所示。
接下来再插入散列值为0001的记录。因为0001的末两位为01,所以应将该记录存入桶01中。不巧的是,该桶的页面已经装满,所以需要增加一个溢出页来提供存储空间。插入后,3个桶中有5条记录,平均充满率约83%,未超过85%,所以不需要创建新桶。改变后的散列表如图3-7(c)所示。
第4章 查询处理
4.1查询处理概述
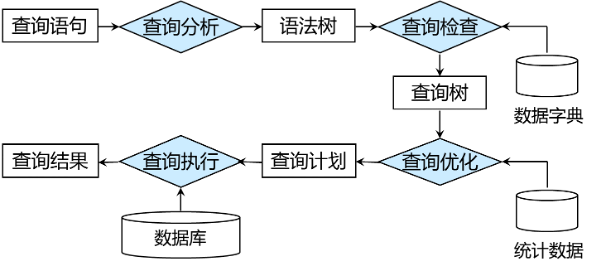
关系数据库管理系统查询处理可以分为4个阶段:查询分析、查询检查、查询优化和查询执行。
- 查询分析 :对用户提交的查询语句进行扫描、词法分析和语法分析,判断是否符合SQL语法规则,若没有语法错误,就会生成一棵语法树。
- 查询检查 :对语法树进行查询检查,首先根据数据字典中的模式信息检查语句中的数据对象,如关系名、属性名是否存在和有效;还要根据数据字典中的用户权限和完整性约束信息对用户的存取权限进行检查。若通过检查,则将数据库对象的外部名称转换成内部表示。这个过程实际上是对语法树进行语义解析的过程,最后语法树被解析为一个具有特定语义的关系代数表达式,其表示形式仍然是一棵树,称为查询树。
- 查询优化 :每个查询都会有多种可供选择的执行策略和操作算法,查询优化就是选择一个能高效执行的查询处理策略。一般将查询优化分为代数优化和物理优化。代数优化指对关系代数表达式进行等价变换,改变代数表达式中操作的次序和组合,使查询执行更高效;物理优化则是指存取路径和底层操作算法的选择,选择依据可以是基于规则、代价、语义的。查询优化之后,形成查询计划。
- 查询执行 :查询计划由一系列操作符构成,每一个操作符实现计划中的一步。查询执行阶段,系统将按照查询计划逐步执行相应的操作序列,得到最终的查询结果。
4.2 选择运算
选择操作的典型实现方法有全表扫描法和索引扫描法。
4.2.1 全表扫描法
对查询的基本表顺序扫描,逐一检查每个元组是否满足选择条件,把满足条件的元组作为结果输出。
假设可以使用的内存为M块,全表扫描的算法思想如下:
- 按物理次序读表T的M块到内存;
- 检查内存的每个元组t,如果t满足选择条件,则输出t;
- 如果表T还有其他块未被处理,重复(1)和(2)。
这种方法适合小表,对规模大的表要进行顺序扫描,当选择率(即满足条件的元组数占全表比例)较低时,此算法效率很低。
4.2.2 索引扫描法
当选择条件中的属性上有索引(例如B+树索引或Hash索引)时,通过索引先找到满足条件的元组指针,再通过元组指针直接在要查询的表中找到元组。
[例1 ] 等值查询:select * from t1 where col=常量,并且col上有索引(B+树索引或Hash索引均可) ,则使用索引得到col为该常量元组的指针,通过元组指针在表t1中检索到结果。
[例2 ] 范围查询: select * from t1 where col > 常量,并且col上有B+树索引,使用B+树索引找到col=常量的索引项,以此为入口点在B+树的顺序集上得到col > 常量的所有元组指针, 通过这些元组指针到t1表中检索满足条件的元组。
[例 3 ] 合取条件查询:select * from t1 where col1=常量a AND col2 >常量b,如果 col1和 col1上有组合索引(col1,col2),则利用此组合索引进行查询筛选;否则,如果 col1和 col2上分别有索引,则:
方法一:分别利用各自索引查找到满足部分条件的一组元组指针,求这2组指针的交集,再到t1表中检索得到结果。
方法二:只利用索引查找到满足该部分条件的一组元组指针,通过这些元组指针到t1表中检索,对得到的元组检查另一些选择条件是否满足,把满足条件的元组作为结果输出。
一般情况下,当选择率较低时,基于索引的选择算法要优于全表扫描。但在某些情况下,如选择率较高、或者要查找的元组均匀分散在表中,这时索引扫描法的性能可能还不如全表扫描法,因为还需要考虑扫描索引带来的额外开销。
4.3 排序运算
排序是数据库中的一个基本功能,用户通过Order by子句即能达到将指定的结果集排序的目的,而且不仅仅是Order by子句,Group by、Distinct等子句都会隐含使用排序操作。
4.3.1 利用索引避免排序
为了优化查询语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为一些索引本身也是有序的,如B+树,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序过程,提高查询速度。
例如:假设t1表存在B+树索引key1(key_part1, key_part2),则以下查询可以利用索引来避免排序:
SELECT * FROM t1 ORDER BY key_part1, key_part2;
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1;
SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
如果排序字段不在索引中,或者分别存在于多个索引中,或者排序键的字段顺序与组合索引中的字段顺序不一致,则无法利用索引来避免排序。
4.3.2 数据库内部排序方法
对于不能利用索引来避免排序的查询,DBMS必须自己实现排序功能以满足用户需求。实现排序的算法可以是文件排序,也可以是内存排序,具体要由排序缓冲区(sort buffer)的大小和结果集的大小来确定。
数据库内部排序的实现主要涉及3种经典排序算法:快速排序、归并排序和堆排序。对于不能全部放在内存中的关系,需要引入外排序,最常用的就是外部归并排序。外部归并排序分为两个阶段:Phase1 – Sorting,对主存中的数据块进行排序,然后将排序后的数据块写回磁盘;Phase2 – Merging,将已排序的子文件合并成一个较大的文件。
4.3.2.1 常规排序法
一般情况下通用的常规排序方法如下:
(1) 从表t中获取满足WHERE条件的记录;
(2) 对于每条记录,将记录的主键+排序键(id,colp)取出放入sort buffer;
(3) 如果sort buffer可以存放所有满足条件的(id,colp)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用快速排序);
(4) 若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的;
(5) 循环执行上述过程,直到所有满足条件的记录全部参与排序;
(6) 扫描排好序的(id,colp)对,并利用id去取SELECT需要返回的目标列;
(7) 将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,colp)对。此外一次排序涉及两次I/O:第一次是取(id,colp),第二次是取目标列。由于第一次返回的结果集是按colp排序,因此id是乱序的。通过乱序的id去取目标列时,会产生大量的随机I/O。因此,可以考虑对第二次I/O进行优化,即在取数据之前首先将id排序并放入缓冲区,然后按id顺序去取记录,从而将随机I/O转为顺序I/O。
为了避免第二次I/O,还可以考虑一次性取出(id,colp,目标列),当然这样对缓冲区的需求会更大。
4.3.2.2 堆排序法
堆排序法适用于形如"order by limit m,n"的这类排序问题,即跳过m条数据,提取n条数据。这种情况下,虽然仍然需要所有元组参与排序,但是只需要m+n个元组的sort buffer空间即可,对于m和n很小的场景,基本不会出现因sort buffer不够而需要使用临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的n个元素;对于降序,则采用小顶堆,最终堆中的元素组成了最大的n的元素。
4.4 连接运算
连接操作是查询处理中最常用最耗时的操作之一。主要有4种实现方法:嵌套循环、排序-合并、索引连接和散列连接。
首先引入2个术语:外关系(outer relation)和内关系(inner relation)。外关系是左侧数据集,内关系是右侧数据集。例如:对于A JOIN B,A为外关系,B为内关系。多数情况下,A JOIN B 的成本跟 B JOIN A 的成本是不同的。假定外关系有n个元组,内关系有m个元组。
4.4.1 嵌套循环连接
嵌套循环连接是最简单且通用的连接算法,其执行步骤为:针对外关系的每一行,查看内关系里的所有行来寻找匹配的行。这是一个双重循环,时间复杂度为O(n*m)。
在磁盘 I/O 方面, 针对外关系的每一行,内部循环需要从内关系读取m行。这个算法需要从磁盘读取 n+ n*m 行。但是,如果外关系足够小,我们可以把它先读入内存,那么就只需要读取 n+m 行。按照这个思路,外关系就应该选更小的那个关系,因为它有更大的机会装入内存。
当然,内关系如果可以由索引代替,对磁盘 I/O 将更有利。
当外关系太大无法装入内存时,采用块嵌套循环连接方式,对磁盘 I/O 更加有利。其基本思路是将逐行读取数据,改为以页(块)为单位读取数据。算法如下:
(1) 从磁盘读取外关系的一个数据页到内存;
(2) 从磁盘依次读取内关系的所有数据页到内存,与内存中外关系的数据进行比较,保留匹配的结果;
(3) 从磁盘读取外关系的下一个数据页,并继续执行(2),直至外关系的最后一个页面。
与嵌套循环连接算法相比,块嵌套循环连接算法的时间复杂度没有变化,但降低了磁盘访问开销,变为M+M*N。其中,M为外关系的页数,N为内关系的页数。
4.4.2 索引嵌套循环连接
在嵌套循环连接中,若在内关系的连接属性上有索引,则可以用索引查找替代文件扫描。对于外关系的每一个元组,可以利用索引查找内关系中与该元组满足连接条件的元组。这种连接方法称为索引嵌套循环连接,它可以在已有索引或者为了计算该连接而专门建立临时索引的情况下使用。
索引嵌套循环连接的代价可以如下计算。对于外关系的每一个元组,需要先在内关系的索引上进行查找,再检索相关元组。在最坏的情况下,缓冲区只能容纳外关系的一页和索引的一页。此时,读取外关系需M次I/O操作,这里的M指外关系的数据页数;对于外关系中的每个元组,在内关系上进行索引查找,假设索引查找带来的I/O开销为C,则总的I/O开销为:M+(m×C),其中m为外关系的元组数。
这个代价计算公式表明,如果两个关系上均有索引时, 一般把元组较少的关系作外关系时效果较好。
4.4.3 排序-合并连接
排序-合并连接算法常用于等值连接,尤其适合参与连接的表已经排好序的情况。其方法如下:
第一步:如果参与连接的表没有排好序,则根据连接属性排序;
第二步:sorted_merge:
(1) 初始化两个指针,分别指向两个关系的第一个元组;
(2) 比较两个关系的当前元组(当前元组=指针指向的元组);
(3) 如果匹配,保留匹配的结果,两个指针均后移一个位置;
(4) 如果不匹配,就将指向较小元组的那个指针后移一个位置;
(5) 重复步骤(2)、(3)、(4),直到其中一个关系的指针移动到末尾。
因为两个关系都是已排序的,不需要"回头去找",所以此方法的时间复杂度为O(n+m)。如果两个关系还需要排序,则还要考虑排序的成本:O(n*Log(n) + m*Log(m))。
很多情况下,参与连接的数据集已经排好序了,比如:表内部就是有序的,或者参与连接的是查询中已经排好序的中间结果,那么选用排序-合并算法是比较合适的。
4.4.4 散列连接
散列连接算法也是适用于等值连接的算法。
散列连接分成两个阶段:第一步,划分阶段,为较小的关系建立hash表,将连接属性作为hash码;第二步,试探阶段,对另一张表的连接属性用同样的hash函数进行散列,将其与相应桶中匹配的元组连接起来。
本算法要求内存足够大,小表的hash表如果能全部放进内存,则效果较好。
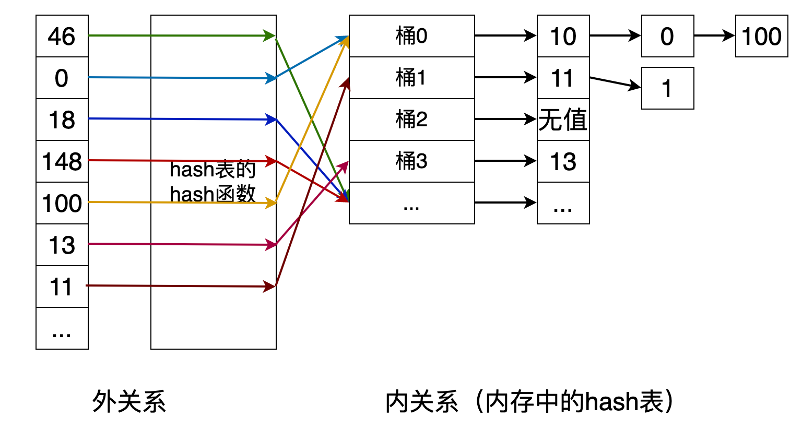
在时间复杂度方面需要做些假设来简化问题:
(1) 内关系被划分成 X 个散列桶。散列函数几乎均匀地分布每个关系内数据的散列值,即散列桶大小一致。
(2) 外关系的元素与散列桶内所有元素的匹配,成本是散列桶内元素的数量。
算法的开销包括创建散列表的成本(m) +散列函数的计算开销*n + (m/X) * n。如果散列函数创建的散列桶的规模足够小,则算法复杂度为O(m+n)。
4.4.5 连接算法的选择
具体情况下,应该选择以上哪种连接算法,有许多因素要考量:
(1) 空闲内存:没有足够的内存就无法使用内存中的散列连接。
(2) 两个数据集的大小。比如,如果一个大表连接一个很小的表,那么嵌套循环连接就比散列连接快,因为后者有创建散列表的高昂成本;如果两个表都非常大,那么嵌套循环连接的CPU成本就很高。
(3) 是否有索引:如果连接属性上有两个B+树索引的话,合并连接会是很好的选择。
(4) 关系是否已经排序:这时候合并连接是最好的选择。
(5) 结果是否需要排序:即使参与连接的是未排序的数据集,也可以考虑使用成本较高的合并连接(带排序的),比如得到排序的结果后,我们还可以将它用于另一个合并联接,或者查询中存在ORDER BY/GROUP BY/DISTINCT等操作符,它们隐式或显式地要求一个排序结果。
(6) 连接的类型:是等值连接?还是内连接?外连接?笛卡尔积?或者自连接?有些连接算法在某些情况下是不适用的。
(7) 数据的分布:如果连接条件的数据是倾斜的,用散列连接不是好的选择,因为散列函数将产生分布极不均匀的散列桶。
(8) 多表连接:连接顺序的选择很重要。
另外,还可能考虑实现方式问题,比如连接操作使用多线程或多进程的代价考量。因此,DBMS需要通过查询优化器来选择恰当的执行计划。
4.5 表达式计算
如何计算包含多个运算步骤的关系代数表达式?有两种方法:物化计算和流水线计算。
4.5.1 物化计算
物化计算以适当的顺序每次执行一次操作;每次计算的结果被物化到一个临时关系以备后用。其缺点为:需要构造临时关系,而且这些临时关系必须写到磁盘上(除非很小)。
表达式的执行顺序可以依据表达式在查询树中的层次而定,从树的底部开始。
如图4-6所示,此例中只有一个底层运算:department上的选择运算,底层运算的输入是数据库中的关系department。用前面提到的算法执行树中的运算,并将结果存储在临时关系中。在树的高一层中,使用这个临时关系来进行计算,这时输入的要么是临时关系,要么是一个数据库关系。通过重复这一过程,最终可以计算位于树的根节点的运算,从而得到表达式的最终结果。
由于运算的每个中间结果会被物化用于下一层的运算,此方法称为物化计算。物化计算的代价不仅是那些所涉及的运算代价的总和,还可能包括将中间结果写到磁盘的代价。
4.5.2 流水线计算
流水线计算可同时计算多个运算,运算的结果传递给下一个,而不必保存临时关系。这种方法通过减少查询执行中产生的临时文件的数量,来提高查询执行的效率。
如图4-6中,可以将选择、连接操作和投影操作组合起来,放入一条流水线,选择得到一个结果传给连接、连接产生一个结果元组马上传送给投影操作去做处理,避免中间结果的创建,从而直接产生最终结果。
创建一个操作的流水线可以带来的好处是:
(1) 消除读和写临时关系的代价,从而减少查询计算代价。
(2) 流水线产生查询结果,边生成边输出给用户,提高响应时间。
流水线可按两种方式来执行:
方式一:需求驱动方式,在操作树的顶端的将数据往上拉。
方式二:生产者驱动方式,将数据从操作树的底层往上推。
需求驱动的流水线方法比生产者驱动的流水线方法使用更广泛,因为它更容易实现。但流水线技术限制了能实现操作的可用算法。例如,若连接运算的左端输入来自流水线,则不能使用排序-合并连接,但可以用索引连接算法。由于这些限制,并非所有情况下流水线方法的代价都小于物化方法。
第5章 查询优化
5.1 查询优化概述
查询优化即求解给定查询语句的高效执行计划的过程。它既是关系数据库管理系统实现的关键技术,又是关系系统的优点所在。由DBMS进行查询优化的好处在于:查询优化的优点不仅在于用户不必考虑如何最好的表达查询以获得较高的效率,而且在于系统可以比用户程序的"优化"做得更好。
查询计划,从形式上看是一颗二叉树,树叶是每个单表对象,两个树叶的父节点是一个连接操作符连接后的中间结果(另外还有一些其他节点如排序等也可以作为中间结果),这个结果是一个临时关系,这样直至根节点。
从一个查询计划看,涉及的主要"关系节点"包括:
- 单表节点:考虑单表的获取方式(全表扫描,或索引获取,或索引定位再I/O到数据块获取数据)。这是一个物理存储到内存解析成逻辑字段的过程。
- 两表节点:考虑两表以何种方式连接,代价有多大,连接路径有哪些等。表示内存中的元组如何进行元组间的连接。此时,元组通常已经存在于内存中。这是一个完整用户语义的逻辑操作,但只是局部操作,只涉及两个具体的关系。完成用户全部语义,需要配合多表的连接顺序的操作。
- 多表中间节点:考虑多表连接顺序如何构成代价最少的"执行计划"。决定连接执行的顺序。
查询优化的总目标是选择有效的策略,求得给定关系表达式的值,使得查询代价较小。因为查询优化的搜索空间有时非常大,实际系统选择的策略不一定是最优的,而是较优的。
查询优化主要包括逻辑优化和物理优化。其中,逻辑优化又可包含语法级查询优化、基于规则的优化等;而物理优化主要指基于代价的优化。语法级优化是基于语法的等价转换;基于规则的优化(如依据关系代数的规则或依据经验的规则等)具有操作简单且能快速确定执行方式的优点,但这种方法只是排除了一部分不好的可能;基于代价的优化是在查询计划生成过程中,计算每条存取路径进行量化比较,从而得到开销最小的情况,但如果组合情况多则开销的判断时间就很多。查询优化器的实现,多是这两种优化策略的组合使用。
5.2 逻辑优化
查询优化器在逻辑优化阶段主要解决的问题是:如何找出SQL语句的等价变换形式,使SQL执行更高效。
5.2.1代数优化
代数优化是基于关系代数等价变换规则的优化方法。
代数优化策略是通过对关系代数表达式的等价变换来提高查询效率。所谓关系代数表达式的等价是指用相同的关系代替两个表达式中相应的关系所得到的结果是相同的。两个关系表达式E1和E2是等价的。
5.2.1.1 关系代数表达式等价变换规则
常用的关系代数等价变换规则如下:
- 连接、笛卡尔积的交换律
设E1和E2为关系代数表达式,F为连接运算条件,则有:
E1×E2 ≡ E2×E1
E1⋈E2 ≡ E2⋈E1
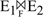 ≡
≡ 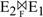
对于连接和笛卡尔积运算,可以交换前后位置,其结果不变。例如,两表连接算法中有嵌套循环连接算法,对外表和内表有要求,外表尽可能小则有利于做"基于块的嵌套循环连接",所以通过交换律可以将元组少的表作为外表。
- 连接、笛卡尔积结合律
设E1、E2、E3为关系代数表达式,F1、F2为连接运算条件。则有:
(E1×E2)×E3 ≡ E1×(E2×E3)
(E1⋈E2)⋈E3 ≡ E1⋈(E2⋈E3)
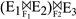 ≡
≡ 
对于连接、笛卡尔积运算,如果新的结合有利于减少中间关系的大小,则可以优先处理。
- 投影的串接定律
设E为关系代数表达式,Ai(i=1,2,3,…,n),Bj(j=1,2,3,…,m)是属性名,且{A1,A2,…,An}为{B1,B2,…,Bm}的子集。则有:
∏A1,A2,…,An(∏B1,B2,…,Bm(E)) ≡ ∏A1,A2,…,An (E)
在同一个关系上,只需做一次投影运算,且一次投影时选择多列同时完成。所以许多数据库优化引擎会为一个关系收集齐该关系上的所有列,即目标列和WHERE、GROUP BY等子句中涉及到的所有该关系的列。
- 选择的串接律
设E为关系代数表达式,F1、F2为选择条件。则有:
σF1(σF2(E)) ≡ σF1∧F2(E)
此变换规则对于优化的意义在于:选择条件可以合并,使得一次选择运算就可检查全部条件,而不必多次过滤元组,所以可以把同层的合取条件收集在一起,统一进行判断。
- 选择和投影的交换律
设E为关系代数表达式,F为选择条件,Ai(i=1,2,3,…,n)是属性名。选择条件F只涉及属性A1,A2,…,An。则有:
σF(∏A1,A2,…,An (E)) ≡∏A1,A2,…,An(σF(E))
此变换规则对于优化的意义在于:先投影后选择可以改为先选择后投影,这对于以行为单位来存储关系的主流数据库而言,很有优化意义。按照这种存储方式,系统总是先获取元组,然后才能解析得到其中的列。
设E为关系代数表达式,F为选择条件,Ai(i=1,2,3…,n)是属性名,选择条件F中有不属于A1,A2,…,An的属性B1,B2,…,Bn。则有:
∏A1,A2,…,An(σF(E)) ≡ ∏A1,A2,…,An(σF(∏A1,A2,…,An,B1,B2,…,Bm(E)))
此变换规则对于优化的意义在于:先选择后投影可以改为先做带有选择条件中的列的投影,然后选择,最后再完成最外层的投影。这样内层的选择和投影可以同时进行,不会增加过多的计算开销,但能减小中间结果集的规模。
- 选择与笛卡尔积的交换律
设E1、E2为关系代数表达式,F为选择条件,F中涉及的属性都是E1中的属性,则有:
σF(E1×E2) ≡ σF(E1)×E2
如果F=F1∧F2,且F1只涉及E1中的属性,F2只涉及E2中的属性,则有:
σF(E1×E2) ≡ σF1(E1)×σF2(E2)
此变换规则对于优化的意义在于:条件下推到相关的关系上,先做选择后做笛卡尔积运算,这样可以减小中间结果的大小。
- 选择与并的分配律
如果E1和E2有相同的属性名,且E= E1∪E2,则有:
σF(E1∪E2) ≡ σF(E1) ∪σF (E2)
此变换规则对于优化的意义在于:条件下推到相关的关系上,先选择后做并运算,可以减小每个关系输出结果的大小。
- 选择与差的分配律
如果E1和E2有相同的属性名,则:
σF(E1-E2) ≡ σF(E1)-σF(E2)
此变换规则对于优化的意义在于:条件下推到相关的关系上,先选择后做差运算,可以减小每个关系输出结果的大小。
- 投影与笛卡尔积的交换律
设A1,A2,…,An是E1的属性,B1,B2,…,Bm是E2的属性,则有:
∏A1,A2,…,An,B1,B2,…,Bm(E1×E2) ≡ ∏A1,A2,…,An(E1)×∏B1,B2,…,Bm(E2)
此变换规则对于优化的意义在于:先投影后做笛卡尔积,可减少做笛卡尔积前每个元组的长度,使得计算后得到的新元组的长度也变短。
- 投影与并的交换律
如果E1和E2有相同的属性名,则有:
∏A1,A2,…,An (E1∪E2) ≡ ∏A1,A2,…,An (E1)∪∏A1,A2,…,An (E2)
此变换规则对于优化的意义在于:先投影后做并运算,可减少做并运算前每个元组的长度。
5.2.1.2 针对不同运算符的优化规则
针对不同运算符的优化规则如表5-1~5-3所示。
| 运算符 | 子类型 | 根据特点可得到的优化规则 | 可优化的原因 |
|---|---|---|---|
| 选择 | 对同一个表的同样选择条件,作一次即可。 | 单行文本输入框 | 幂等性:多次应用同一个选择有同样效果; 交换性:应用选择的次序在最终结果中没有影响 选择可有效减少在它的操作数中的元组数的运算(元组个数减少)。 |
| 分解有复杂条件的选择 | 合取,合并多个选择为更少的需要求值的选择,多个等式则可以合并①。 | 合取的选择等价于针对这些单独条件的一系列选择。 | |
| 析取,分解它们使得其成员选择可以被移动或单独优化②。 | 析取的选择等价于选择的并集。 | ||
| 选择和笛卡尔积 | 尽可能先做选择。 | 运算关系分别有N和M行,先做积运算将包含N×M行。先做选择运算减少N和M,则可避免不满足条件的元组参与积运算,节约时间同时减少结果集的大小。 | |
| 尽可能下推选择。 | 如果积运算后面没有跟随选择运算,可以尝试使用其它规则从表达式树更高层下推选择。 | ||
| 选择和集合运算 | 选择下推到的集合运算中,如表5-2中的3种情况。 | 选择在差集、交集和并集算子上满足分配律。 | |
| 选择和投影 | 在投影之前进行选择。 | 如果选择条件中引用的列是投影中的列的子集,则选择与投影满足交换性。 | |
| 投影 | 基本投影性质 | 尽可能先做投影 | 投影是幂等的;投影可以减少元组大小。 |
| 投影和集合运算 | 投影下推到集合的运算中,如表5-3中的情况。 | 投影在差集、交集和并集算子上满足分配律。 |
- 如WHERE A.a=B.b AND B.b=C.c可以合并为={A.a,B.b,C.c}而不是两个等式={A.a,B.b}和={B.b,C.c}。
- 如WHERE A.a=3 OR A.b>8,如果A.a、A.b列上分别有索引,也许SELECT * FROM A WHERE A.a=3 UNION SELECT * FROM A WHERE A.b>8可以分别利用各自的索引提高查询效率。
表5-2 选择下推到集合的运算
| 初始式 | |||
|---|---|---|---|
| 等价表达式一 | 等价表达式二 | 等价表达式三 | |
| σA(R-S) | σA(R)-σA(S) | σA(R)-S | |
| σA(R∪S) | σA(R)∪σA(S) | ||
| σA(R∩S) | σA(R)∩σA (S) | σA(R)∩S | R∩σA(S) |
表5-3 投影下推到集合的运算
| 初始式 | 优化后的等价表达式 |
|---|---|
| ∏A1,A2,…,An(R-S) | ∏A1,A2,…,An(R)- ∏A1,A2,…,An(S) |
| ∏A1,A2,…,An(R∪S) | ∏A1,A2,…,An(R) ∪∏A1,A2,…,An(S) |
| ∏A1,A2,…,An(R∩S) | ∏A1,A2,…,An(R) ∩∏A1,A2,…,An(S) |
5.2.1.3 查询树启发式规则
包括:
- 选择运算应尽可能先做。
- 把投影运算和选择运算同时进行。如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描次关系的同时完成所有这些运算以避免重复扫描关系。
- 把投影同其前或后的双目运算结合起来,没有必要为了去掉某些字段而扫描一遍关系。
- 把某些选择同在它前面要执行的笛卡尔积结合起来称为一个连接运算。连接(特别是等值连接)运算比笛卡尔积性能高很多。
- 找出公共子表达式,将其计算结果缓存起来,避免重复计算。
5.2.2 语法级查询优化
语法级优化要解决的主要问题是找出SQL语句的等价变换形式,使得SQL执行更高效,包括:
- 子句局部优化。如等价谓词重写、where和having条件简化等。
- 关联优化。如子查询优化、连接消除、视图重写等。
- 形式变化优化。如嵌套连接消除等。
以下介绍几种常见的优化方法。
5.2.2.1 子查询优化
早期的查询优化器对子查询都采用嵌套执行的方式,即对父查询中的每一行都执行一次子查询,这样效率很低,因此对其进行优化很有必要。例如,将子查询转为连接操作之后,有如下好处:
- 子查询不用多次执行;
- 优化器可以根据统计信息来选择不同的连接方法和不同的连接顺序;
- 子查询中的连接条件、过滤条件分别变成了父查询的连接条件和过滤条件,优化器可以对这些条件进行下推,以提高执行效率。
- 常见子查询优化技术
(1) 子查询合并
在语义等价条件下,多个子查询可以合并成一个子查询,这样多次表扫描,多次连接减少为单次表扫描和单次连接。例如:
SELECT *
FROM t1
WHERE a1<10 AND (
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2)
);
可优化为:
SELECT *
FROM t1
WHERE a1<10 AND (
EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2)
);
此例中,两个EXISTS子查询合并为一个子查询,查询条件也进行了合并。
(2) 子查询展开
子查询展开又称子查询反嵌套,子查询上拉。实质是把某些子查询重写为等价的多表连接操作。带来好处是,有关的访问路径、连接方法和连接顺序可能被有效使用,使得查询语句的层次尽可能地减少。常见的IN / ANY / SOME / ALL / EXISTS依据情况转为半连接(SEMI JOIN)。例如:
SELECT *
FROM t1, (SELECT * FROM t2 WHERE t2.a2>10) v_t2
WHERE t1.a1<10 AND v_t2.a2<20;
可优化为:
SELECT *
FROM t1, t2
WHERE t1.a1<10 AND t2.a2<20 AND t2.a2>10;
此例中,原本的子查询变为了t1、t2表的连接操作,相当于把t2表从子查询中上拉了一层。
子查询展开是一种最常用的子查询优化技术,如果子查询是只包含选择、投影、连接操作的简单语句,没有聚集函数或者group子句,则可以上拉,前提是上拉后的结果不能带来多余元组,需遵循以下规则:
- 如果上层查询结果没有重复(select包含主键),则可以展开子查询,并且展开后的查询的select子句前应加上distinct标志;
- 如果上层查询的select语句中有distinct标志,则可以直接子查询展开;
- 如果内层查询结果没有重复元组,则可以展开。
子查询展开的具体步骤如下:
- 将子查询和上层查询的from子句连接为同一个from子句,并且修改相应的运行参数;
- 将子查询的谓词符号进行相应修改(如IN修改为=ANY);
- 将子查询的where条件作为一个整体与上层查询的where条件进行合并,并用and连接,从而保证新生成的谓词与原谓词的语义相同,成为一个整体。
(3) 聚集子查询消除
这种方法将聚集子查询的计算上推,使得子查询只需计算一次,并与父查询的部分或全表做左外连接。例如:
SELECT *
FROM t1
WHERE t1.a1 > (SELECT avg(t2.a2) FROM t2);
可优化为:
SELECT t1.*
FROM t1, (SELECT avg(t2.a2) FROM t2) as tm(avg_a2) )
WHERE t1.a1 ? tm.avg_a2;
(4) 其他
此外还有利用窗口函数消除子查询、子查询推进等技术,本文不再细述。
- 针对不同类型子查询的优化方法
(1) IN类型子查询
IN类型有3种格式:
格式一:
outer_expr [not] in (select inner_expr from ... where subquery_where)
格式二:
outer_expr = any (select inner_expr from ... where subquery_where)
格式三:
(oe_1, ..., oe_N) [not] in (select ie_1, ..., ie_N from ... where subquery_where)
对于in类型子查询的优化,如表5-4所示。
情况一:outer_expr和inner_expr均为非NULL值。
优化后的表达式为:
exists (select 1 from ... where subquery_where and outer_expr=inner_expr)
子查询优化需要满足2个条件:
-
outer_expr和inner_expr不能为NULL;
-
不需要从结果为FALSE的子查询中区分NULL。
情况二:outer_expr是非空值。
优化后的表达式为:
exists (select 1 from ... where subquery_where and
(outer_expr=inner_expr or inner_expr IS NULL);
情况三:outer_expr为空值。
则原表达式等价为:
NULL in (select inner_expr FROM ... where subquery_where)
当outer_expr为空时,如果子查询结果为:
- NULL,select语句产生任意行数据;
- FALSE,select语句不产生数据。
对上面的等价形式,还有2点需说明:
- 谓词IN等价于=ANY。如:以下2条SQL语句是等价的。
select col1 from t1 where col1 =ANY (select col1 from t2);
select col1 from t1 where col1 IN (select col1 from t2);
- 带有IN谓词的子查询,如果满足上述3种情况,可做等价变换,把外层条件下推到子查询中,变形为EXISTS类型的逻辑表达式判断。而EXISTS子查询可以被半连接算法实现优化。
(2) ALL/ANY/SOME类型子查询
ALL/ANY/SOME子查询格式如下:
outer_expr operator ALL (subquery)
outer_expr operator ANY (subquery)
outer_expr operator SOME (subquery)
其中,operator是操作符,可以是>、>=、=、<、<=中任何一个。其中,
- =ANY与IN含义相同,可采用IN子查询优化方法;
- SOME与ANY含义相同;
- NOT IN 与 <>ALL含义相同;
如果子查询中没有group by子句,也没有聚集函数,则以下表达式可以使用聚集函数MAX/MIN做等价转换:
val>=ALL (select ...)等价变换为:val>= (select MAX...)val<=ALL (select ...)等价变换为:val<= (select MAX...)val>=ANY (select ...)等价变换为:val>= (select MIN...)val>=ANY (select ...)等价变换为:val>= (select MAX...)
(3) EXISTS类型子查询
存在谓词子查询格式为:[NOT] EXISTS (subquery)
需要注意几点:
- EXISTS(subquery)值为TRUE/FALSE,不关心subquery返回的内容。
- EXISTS(subquery)自身有"半连接"的语义,部分DBMS用半连接来实现它;NOT EXISTS通常会被标识为"反半连接"处理。
- IN(subquery)等子查询可以被转换为EXISTS(subquery)格式。
所谓半连接(Semi Join),是一种特殊的连接类型。如果用"t1.x semi= t2.y"来表示表T1和表T2做半连接,则其含义是:只要在表T2中找到一条记录满足t1.x=t2.y,则马上停止搜索表T2,并直接返回表T1中满足条件t1.x=t2.y的记录,因此半连接的执行效率高于普通的内连接。
5.2.2.2 等价谓词重写
等价谓词重写包括:LIKE规则、BETWEEN-AND规则、IN转换OR规则、IN转换ANY规则、OR转换ANY规则、ALL/ANY转换集函数规则、NOT规则等,相关原理比较简单,有兴趣的同学可以自行查找相关查询重写规则。
5.2.2.3 条件化简
WHERE、HAVING和ON条件由许多表达式组成,而这些表达式在某些时候彼此间存在一定的联系。利用等式和不等式性质,可将WHERE、HAVING和ON条件简化,但不同数据库的实现可能不完全相同。
将WHERE、HAVING和ON条件简化的方式通常包括如下几个:
-
去除表达式中冗余的括号:以减少语法分析时产生的AND和OR树的层次;
-
常量传递:对不同关系可使用条件分离后有效实施"选择下推",从而减小中间关系的规模。如:
col1=col2 AND col2=3可化简为:col1=3 AND col2=3操作符=、<、>、<=、>=、<>、LIKE中的任何一个,在
col1<操作符>col2条件中都会发生常量传递 -
消除死码。化简条件,将不必要的条件去除。如:
WHERE (0>1 AND s1=5),0>1使得AND为恒假,去除即可。 -
表达式变换。化简条件(如反转关系操作符的操作数顺序),从而改变某些表的访问路径。如:-a=3可化简为a=-3,若a上有索引,则可利用。
-
不等式变换。化简条件,将不必要的重复条件去除。如:
a>10 AND b=6 AND a>2可化简为:a>10 AND b=6。 -
布尔表达式变换。包括:
- 谓词传递闭包。如:
a>b AND b>2可推导出a>2,减少a、b比较元组数。 - 任何一个布尔表达式都能被转换为一个等价的合取范式。一个合取项为假,则整个表达式为假。
5.3 物理优化
代数优化改变查询语句中操作的次序和组合,但不涉及底层的存取路径。物理优化就是要选择高效合理的操作算法或存取路径,求得优化的查询计划,达到查询优化的目标。
查询优化器在物理优化阶段,主要解决的问题是:
- 从可选的单表扫描方式中,挑选什么样的单表扫描方式最优?
- 对于两表连接,如何连接最优?
- 对于多表连接,哪种连接顺序最优?
- 对于多表连接,是否需要对每种连接顺序都探索?如果不全部探索,如何找到一种最优组合?
选择的方法可以是:
- 基于规则的启发式优化。
- 基于代价估算的优化。
- 两者结合的优化方法。常常先使用启发式规则选取若干个较优的候选方案,减少代价估算的工作量,然后分别计算这些候选方案的执行代价,较快地选出最终的优化方法。
启发式规则优化是定性的选择,比较粗糙,但是实现简单而且优化本身的代价较小,适合解释执行的系统。因为解释执行的系统,其优开销包含在查询总开销之中,在编译执行的系统中,一次编译优化,多次执行,查询优化和查询执行是分开的,因此,可以用精细复杂一些的基于代价的优化方法。
5.3.1 基于代价的优化
5.3.1.1 查询代价估算
查询代价估算基于CPU代价和I/O代价,计算公式如下:
总代价 = I/O代价 + CPU代价
COST = P * a_page_cpu_time + W * T
其中:
P是计划运行时访问的页面数,a_page_cpu_time是每个页面读取的时间开销,其乘积反映了I/O开销。
T为访问的元组数,如果是索引扫描,还要考虑索引读取的开销,反映了数据读取到内存的CPU开销。
W为权重因子,表明I/O到CPU的相关性,又称选择率(selectivity),用于表示在关系R中,满足条件“A
选择率在代价估算模型中占有重要地位,其精确程度直接影响最优计划的选取。选择率计算常用方法如下:
- 无参数方法:使用ad hoc(点对点)数据结构或直方图维护属性值的分布,直方图最常用;
- 参数法:使用具有一些自由统计参数(参数是预先估计出来的)的数学分布函数逼近真实分布;
- 曲线拟合法:为克服参数法的不灵活性,用一般多项式来标准最小方差来逼近属性值的分布;
- 抽样法:从数据库中抽取部分样本元组,针对这些样本进行查询,然后收集统计数据;
- 综合法:将以上几种方法结合起来,如抽样法和直方图法结合。
由于其中I/O代价占比最大,通常以I/O代价为主来进行代价估算。
- 全表扫描算法的代价估算公式
- 如果基本表大小为 B 块,全表扫描算法的代价 cost = B;
- 如果选择条件是"码=值",则平均搜索代价 cost = B/2。
2. 索引扫描算法的代价估算公式
- 如果选择条件为"码=值",则采用该表的主索引,若为B+树,设索引层数为L,需要存取B+树中从根节点到叶节点L块,再加上基本表中该元组所在的那一块,cost=L+1。
- 如果选择条件涉及非码属性,若为B+树索引,选择条件是相等比较,S为索引选择基数(有S个元组满足条件),假设满足条件的元组保存在不同块上,则最坏情况下cost=L+S。
- l 若比较条件为>,>=,<,<=,假设有一半元组满足条件,则需要存取一半的叶节点,并通过索引访问一半的表存储块,cost=L+Y/2+B/2。若可以获得更准确的选择基数,可进一步修正Y/2与B/2。
3.嵌套循环连接算法的代价估算公式
- 嵌套循环连接算法的代价为:cost=Br+BrBs/(K-1), 且K<B(R)<B(S),其中K表示缓冲区大小为K块;
- 若需要把中间结果写回磁盘,则代价为:cost=Br+BrBs/(K-1) + (Frs*Nr*Ns)/Mrs。Frs为连接选择率,表示连接结果数的比例,Mrs为块因子,表示每块中可以存放的结果元组数目。
4.排序合并连接算法的代价估算公式
- 如 果 连 接 表 已 经 按 照 连 接 属 性 排 好 序 , 则 cost =Br+Bs+(Frs*Nr*Ns)/Mrs。
- 如果必须对文件排序,需要在代价函数中加上排序的代价对 于 包 含 B 个 块 的 文 件 排 序 的 代 价 大 约 是:cost =(2*B)+(2*B*log2B)。
5.3.1.2 基于代价的连接顺序选择
多表连接算法实现的是在查询路径生成的过程中,根据代价估算,从各种可能的候选路径中找出最优的路径。它需要解决两个问题:
- 多表连接的顺序
- 多表连接的搜索空间:N个表的连接可能有N!种连接组合,这可能构成一个巨大的搜索空间。如何将搜索空间限制在一个可接受的范围内,并高效生成查询执行计划将成为一个难点。
多表间的连接顺序表示了查询计划树的基本形态。在1990年,Schneder等人在研究查询树模型时提出了左深树,右深树和紧密树3种形态,如图5-1所示。
即使是同一种树的生成方式,也有细节需要考虑。如图5-1-a中{A,B}和{B,A}两种连接方式开销可能不同。比如最终连接结果{A,B,C}则需要验证比较6种连接方式,找出最优的一种作为下次和其他表连接的依据。
多表连接搜索最优查询树,有很多算法,如启发式、分枝界定计划枚举、贪心、动态规划、爬山法、System R优化方法等。其中,常用算法如下。
-
动态规划
在数据库领域,动态规划算法主要解决多表连接的问题。它是自底向上进行的,即从叶子开始做第一层,然后开始对每层的关系做两两连接(如果满足内连接进行两两连接,不满足则不可对全部表进行两两连接),构造出上层,逐次递推到树根。以下介绍具体步骤:
初始状态:构造第一层关系,即叶子结点,每个叶子对应一个单表,为每一个待连接的关系计算最优路径(单表的最优路径就是单表的最佳访问方式,通过评估不同的单表的数据扫描方式代价,找出代价最小的作为每个单表的局部最优路径)
归纳:当第1层到第n-1层的关系已经生成,那么求解第n层的关系方法为:将第n-1层的关系与第一层中的每个关系连接,生成新的关系(对新关系的大小进行估算),放于第n层,且每一个新关系,均求解最优路径。每层路径的生成都是基于下层生成的最优路径,这满足最优化原理的要求。
还有的改进算法,在生成第n层的时候,除了通过第n-1层和第一层连接外,还可以通过第n-2层和第二层连接...。
PostgreSQL查询优化器求解多表连接时,采用了这种算法。
-
启发式算法
启发式算法是相对最优化算法提出的,是一个基于直观或者经验构造的算法,不能保证找到最好的查询计划。在数据库的查询优化器中,启发式一直贯穿于整个查询优化阶段,在逻辑查询优化阶段和物理查询优化阶段,都有一些启发式规则可用。PostgreSQL,MySQL,Oracle等数据库在实现查询优化器时,采用了启发式和其他方式相结合的方式。
物理查询优化阶段常用启发式规则如下:
- 关系R在列X上建立索引,且对R的选择操作发生在列X上,则采用索引扫描方式;
- R连接S,其中一个关系上的连接列存在索引,则采用索引连接且此关系作为内表;
- R连接S,其中一个关系上的连接列是排序的,则采用排序连接比hash连接好。
-
贪心算法
贪心算法最后得到的是局部最优解,不一定全局最优,其实现步骤如下:
(1) 初始,算法选出的候选对象集合为空;
(2) 根据选择函数,从剩余候选对象中选出最有可能构成解的对象;
(3) 如果集合中加上该对象后不可行,那么该对象就被丢弃并不再考虑;
(4) 如果集合中加上该对象后可行,就加到集合里;
(5) 扩充集合,检查该集合是否构成解;
(6) 如果贪心算法正确工作,那么找到的第一个解通常都是最优的,可以终止算法;
(7) 继续执行第二步。
MySQL查询优化器求解多表连接时采用了这种算法。
-
System-R算法
对自底向上的动态规划算法进行了改进,主要思想是把子树的查询计划的最优查询计划和次优查询计划保留,用于上层的查询计划生成,以便使得查询计划总体上最优。
| 算法名称 | 特点与适用范围 | 缺点 |
|---|---|---|
| 启发式算法 | 适用于任何范围,与其它算法结合,能有效提高整体效率 | 不知道得到的解是否最优 |
| 贪婪算法 | 非穷举类型的算法。适合解决较多关系的搜索 | 得到局部最优解 |
| 爬山法 | 适合查询中包含较多关系的搜索,基于贪婪算法 | 随机性强,得到局部最优解 |
| 遗传算法 | 非穷举类型的算法。适合解决较多关系的搜索 | 得到局部最优解 |
| 动态规划算法 | 穷举类型的算法。适合查询中包含较少关系的搜索,可得到全局最优解 | 搜索空间随关系个数增长呈指数增长 |
| System R优化 | 基于自底向上的动态规划算法,为上层提供更多可能的备选路径,可得到全局最优解 | 搜索空间可能比动态规划算法更大一些 |
5.3.2 基于规则的优化
基于代价优化的一个缺点是优化本身的代价。因此,查询优化器使用启发式方法来减少优化代价。
- 选择操作的启发式规则:
-
对于小关系,全表扫描;
-
对于大关系:
(1) 若选择条件是主码,则可以选择主码索引,因为主码索引一般是被自动建立的;
(2) 若选择条件是非主属性的等职查询,并且选择列上有索引,如果选择比例较小(10%)可以使用索引扫描,否则全表扫描;
(3) 若选择条件是属性上的非等值查询或者范围查询,同上;
(4) 对于用and连接的合取选择条件,若有组合索引,优先用组合索引方法;如果某些属性上有一般索引,则用索引扫描,否则全表扫描;
(5) 对于用OR连接的析取选择条件,全表扫描。
- 连接操作的启发式规则
-
若两个表都已经按连接属性排序,则选用排序-合并算法;
-
若一个表在连接属性上有索引,则使用索引连接方法;
-
若其中一个表较小,则选用hash join;
-
最后可以使用嵌套循环,小表作为外表。
还有嵌套子查询优化、物化视图等多种优化手段,这里不再展开。
第6章 事务处理
6.1 事务概念
在数据库系统中,事务是指由一系列数据库操作组成的一个完整的逻辑过程。数据库提供了增、删、改、查等几种基础操作,用户可以灵活地组合这几种操作来实现复杂的语义。在很多场景下,用户希望一组操作可以作为一个整体一起生效,这就是事务的产生背景。
例如,一个银行转帐业务,在数据库中需要通过两个修改操作来实现:1. 从账户A扣除指定金额;2. 向账户B添加指定金额。这两个操作构成了一个完整的逻辑过程,不可拆分。如果第一个操作成功而第二个操作失败,说明转账没有成功。在这种情况下,对于银行来说,数据库中的账户数据是处于一种不正确的状态的,必须撤销掉第一个操作对数据库的修改,让账户数据恢复到转账前的状态。由此例可见,事务是数据库状态变更的基本单元,在事务将数据库从一个正确状态变更到另一个正确状态的过程中,数据库的那些中间状态,既不应该被其他事务看到或干扰,也不应该在事务结束后依然保留。
根据以上描述的事务概念,事务应具有四个特性,称为事务的ACID特性。它们分别是:
- 原子性 (Atomicity):一个事务中的所有操作,要么全做,要么全不做。事务如果在执行过程中发生错误,该事务修改过的数据应该被恢复到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性 (Consistency):当数据库只包含成功事务提交的结果时,称数据库处于一致性状态。事务执行的结果必须使数据库从一个一致性状态变到另一个一致性状态。由此可见,一致性与原子性是密切相关的。
- 隔离性 (Isolation):一个事务的执行不能被其他事务干扰。DBMS允许多个并发事务同时执行,隔离性可以防止多个事务并发执行时由于相互干扰而导致数据的不一致。
- 持久性 (Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
在SQL中,开始和结束事务的语句如下:
- BEGIN TRANSACTION:开始一个事务。除了用该语句显式地开始一个事务,DBMS也允许隐式的开始一个事务。隐式开始事务时无需执行任何语句,每当用户连接成功,即开始一个事务,前一个事务结束时,即自动开始下一个事务。
- COMMIT:提交一个事务。此语句表示事务正常结束,DBMS应永久保存该事务对数据库的修改。
- ROLLBACK:回滚一个事务。此语句表示事务异常结束,DBMS应撤销该事务对数据库的所有修改。需要注意的是,当事务发生故障时,即使用户没有显式执行ROLLBACK语句,DBMS也应自动回滚事务。
一个支持事务的DBMS必须能保证事务的ACID特性,这部分工作是由事务处理机制来负责的。事务处理机制又分为并发控制机制和故障恢复机制两部分,以下分别介绍。
6.2 并发控制
所谓并发操作,是指在多用户共享的数据库中,多个事务可能同时对同一数据进行操作。如果对这些操作不加控制,则可能导致数据的不一致问题。因此,为了保证事务的一致性和隔离性,DBMS需要对并发操作进行正确调度。这就是并发控制机制的任务。
6.2.1 并发错误
并发操作带来的数据不一致性包括丢失修改、读脏和不可重复读。
-
丢失修改
两个以上事务从数据库中读入同一数据并修改,其中一个事务(后提交的事务)的提交结果破坏了另一事务(先提交的事务)的提交结果,导致先提交的事务对数据库的修改被丢失。
-
读脏
事务读取了被其他事务修改且未提交的数据,即从数据库中读到了临时性数据。
-
不可重复读
一个事务读取数据后,该数据又被另一事务修改,导致前一事务无法再现前一次的读取结果。
不可重复读又可分为两种情况:一种情况是第一次读到的数据的值在第二次读取时发生了变化;还有一种情况是事务第二次按相同条件读取数据时,返回结果中多了或者少了一些记录。后者又被称为幻读。
6.2.2 并发控制的正确性标准
并发控制机制的任务就是对并发事务进行正确的调度,但是什么样的调度才是正确的呢?我们需要一个正确性的判断标准。
6.2.2.1 可串行化
串行调度是指多个事务依序串行执行,仅当一个事务的所有操作执行完后才执行另一个事务。这种调度方式下,不可能出现多个事务同时访问同一数据的问题,自然也就不可能出现并发错误。串行调度显然是正确的,但是串行调度无法充分利用系统资源,因此其效率显然也是用户难以接受的。
并发调度是指在数据库系统中同时执行多个事务。DBMS对多个并发事务进行调度时,可能产生多个不同的调度序列,从而得到不同的执行结果。如何判断某个调度是不是正确呢?如果这些并发事务的执行结果与它们按某一次序串行执行的结果相同,则认为该并发调度是正确的,我们称之为可串行化调度。
6.2.2.2 冲突可串行化
可串行化是并发控制的正确性准则。但是按照可串行化的定义,如果想要判断一个并发调度是不是可串行化调度,需要知道这批事务所有可能的串行调度的结果,然后将该并发调度的结果与这些结果进行比较,这显然是难以实施的。因此,我们需要一种可操作的判断标准,即冲突可串行化。
冲突可串行化是可串行化的充分条件。如果一个并发调度是冲突可串行化的,那么它一定是可串行化的。在定义冲突可串行化之前,需要先了解什么是冲突操作。
冲突操作是指不同的事务对同一个数据的读写操作或写写操作。例如,事务1对数据A的读操作"r1(A)"与事务2对数据A的写操作"w2(A)"就是一对冲突操作。
我们规定,不同事务的冲突操作和同一事务的两个操作是不能交换的。因为如果改变冲突操作的次序,则最后的数据库状态会发生变化。按照这个规定,在保证一个并发调度中的冲突操作次序不变的情况下,如果通过交换两个事务的非冲突操作,能够得到一个串行调度,则称该并发调度是冲突可串行化的。
例如,对于以下两个并发调度序列:
SC1:r1(A) w1(B) r2(B) w1(C) w2(B)
SC2:r1(B) r2(A) w1(A) w2(B)
SC1就是冲突可串行化的,因为可以通过交换非冲突操作3和4得到一个串行调度序列。而SC2则是非冲突可串行化的,因为操作2和3是冲突操作,无法交换。
6.2.3 事务隔离级别
可串行化是一个很严格的正确性标准。在实际应用中,有时候可能会希望降低这个标准,通过牺牲一定的正确性,达到提高并发度的目的。为此,SQL标准将事务的隔离程度划分为四个等级,允许用户根据需要自己指定事务的隔离级。这四种隔离级包括读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和可串行化(Serializable)。
- 读未提交:在该隔离级别,事务可以看到其他未提交事务的执行结果,即允许读脏数据。
- 读提交:这是大多数DBMS的默认隔离级别,它要求事务只能看见已提交事务所做的修改,因此可以避免读脏数据。但是由于在某个事务的执行期间,同一个数据可能被另一个事务修改并提交,所以该事务对该数据的两次读取可能会返回不同的值,即出现不可重复读错误。
- 可重复读:在该隔离级别,同一事务多次读取同一数据时,总是会读到同样的值。不过理论上,该隔离级不能避免幻读,即使用相同条件多次读取时,满足读取条件的数据的数量可能有变化,比如多出一些满足条件的数据。
- 可串行化:这是最高的隔离级别,能够避免所有并发错误。可串行化的概念前面已经介绍过,此处不再赘述。
6.3 封锁机制
6.3.1什么是封锁
封锁机制是一种常用的并发控制手段,它包括三个环节:第一个环节是申请加锁,即事务在操作前对它要使用的数据提出加锁请求;第二个环节是获得锁,即当条件满足时,系统允许事务对数据加锁,使事务获得数据的控制权;第三个环节是释放锁,即完成操作后事务放弃数据的控制权。为了达到并发控制的目的,在使用时事务应选择合适的锁,并遵从一定的封锁协议。
基本的封锁类型有两种:排它锁(Exclusive Locks,简称X锁)和共享锁(Share Locks,简称S锁)。
-
排它锁
排它锁也称为独占锁或写锁。一旦事务T对数据对象A加上了排它锁(X锁),则其他任何事务不能再对A加任何类型的锁,直到T释放A上的锁为止。
-
共享锁
共享锁又称读锁。如果事务T对数据对象A加上了共享锁(S锁),其他事务对A就只能加S锁而不能加X锁,直到事务T释放A上的S锁为止。
6.3.2 封锁协议
简单地对数据加X锁和S锁并不能保证数据库的一致性。在对数据对象加锁时,还需要约定一些规则,包括何时申请锁、申请什么类型的锁、何时释放锁等,这些规则称为封锁协议。不同的规则形成了各种不同的封锁协议。封锁协议分三级,它们对并发操作带来的丢失修改、读脏和不可重复读等并发错误,可以在不同程度上予以解决。
-
一级封锁协议
一级封锁协议是指事务T在修改数据之前必须先对其加X锁,直到事务结束才释放。
一级封锁协议可有效地防止丢失修改,并能够保证事务T的可恢复性。但是,由于一级封锁没有要求对读数据进行加锁,所以不能防止读脏和不可重复读。遵循一级封锁协议的事务可以达到读未提交的事务隔离级。
-
二级封锁协议
二级封锁协议是指事务T在修改数据之前必须先加X锁,直到事务结束才释放X锁;在读取数据之前必须先加S锁,读完后即可释放S锁。
二级封锁协议不但能够防止丢失修改,还可进一步防止读脏。遵循二级封锁协议的事务可以达到读提交的事务隔离级。
-
三级封锁协议
三级封锁协议是事务T在读取数据之前必须先对其加S锁,在修改数据之前必须先对其加X锁,直到事务结束后才释放所有锁。
由于三级封锁协议强调即使事务读完数据A之后也不释放S锁,从而使得别的事务无法更改数据A,所以三级封锁协议不但能够防止丢失修改和读脏,而且能够防止不可重复读。遵循三级封锁协议的事务至少可以达到可重复读的事务隔离级,至于是否能到达可串行化级别,则取决于S锁的粒度。比如,如果只对要读取的记录加锁,则无法避免幻读问题;但如果是对整个表加锁,则幻读问题可以避免,代价是并发度的下降。
6.3.3 封锁的实现
锁管理器可以实现为一个进程或线程,它从事务接受请求消息并反馈结果消息。对于事务的加锁请求消息,锁管理器返回授予锁消息,或者要求事务回滚的消息(发生死锁时);对于事务的解锁请求消息,只需返回一个确认消息,但可能触发锁管理器向正在等待该事务解锁的其他事务发送授予锁消息。
锁管理器使用以下数据结构:
- 为目前已加锁的每个数据对象维护一个链表,链表中的每个结点代表一个加锁请求,按请求到达的顺序排序。一个加锁请求包含的信息有:提出请求的事务ID,请求的锁的类型,以及该请求是否已被授予锁。
- 使用一个以数据对象ID为索引的散列表来查找数据对象(如果有的话),这个散列表叫做锁表。
图6-1是一个锁表的示例图,该表包含5个不同的数据对象14、17、123、144和1912的锁。锁表采用溢出链表示法,因此对于锁表的每一个表项都有一个数据对象的链表。每一个数据对象都有一个已授予锁或等待授予锁的事务请求列表,已授予锁的请求用深色阴影方块表示,等待授予锁的请求则用浅色阴影方块表示。 例如,事务T23在数据对象17和1912上已被授予锁,并且正在等待对数据对象14加锁。
虽然图6-1没有标示出来,但对锁表还应当维护一个基于事务标识符的索引,这样它可以快速确定一个给定事务持有的锁的集合。
锁管理器这样处理请求:
- 当一条加锁请求消息到达时,如果锁表中存在相应数据对象的链表,则在该链表末尾增加一个请求;否则,新建一个仅包含该请求的链表。对于当前没有加锁的数据对象,总是满足事务对其的第一次加锁请求,但当事务向已被加锁的数据对象申请加锁时,只有当该请求与当前持有的锁相容、并且所有之前的请求都已授予锁的条件下,锁管理器才为该请求授予锁,否则,该请求只能等待。
- 当锁管理器收到一个事务的解锁消息时,它先找到对应的数据对象链表,删除其中该事务的请求,然后检查其后的请求,如果有,则看该请求能否被满足,如果能,锁管理器授权该请求,再按相同的方式处理后续的请求。
- 如果一个事务被中止,锁管理器首先删除该事务产生的正在等待加锁的所有请求;当系统采取适当动作撤销了该事务后,该中止事务持有的所有锁也将被释放。
这个算法保证了锁请求无饿死现象,因为在先接收到的请求正在等待加锁时,后来的请求不可能获得授权。
为了避免消息传递的开销,在许多DBMS中,事务通过直接更新锁表来实现封锁,而不是向锁管理器发送请求消息。事务加锁和解锁的操作逻辑与上述锁管理器的处理方法类似,但是有两个明显的区别:
- 由于多个事务可以同时访问锁表,因此必须确保对锁表的互斥访问。
- 如果因为锁冲突而不能立刻获得锁,加锁事务需要知道自己何时可以被授予锁,解锁事务需要标记出那些可以被授予锁的事务并通知它们。这个功能可以通过操作系统的信号量机制来实现。
6.3.4 死锁处理
封锁机制有可能导致死锁,DBMS必须妥善地解决死锁问题,才能保障系统的正常运行。
如果事务T1和T2都需要修改数据Rl和R2,并发执行时Tl封锁了数据R1,T2封锁了数据R2;然后T1又请求封锁R2,T2又请求封锁Rl;因T2已封锁了R2,故T1等待T2释放R2上的锁。同理,因T1已封锁了R1,故T2等待T1释放R1上的锁。由于Tl和T2都没有获得全部需要的数据,所以它们不会结束,只能继续等待。这种多事务交错等待的僵持局面称为死锁。
一般来讲,死锁是不可避免的。DBMS的并发控制子系统一旦检测到系统中存在死锁,就要设法解除。通常采用的方法是选择一个处理死锁代价最小的事务,将其中止,释放此事务持有的所有的锁,使其他事务得以继续运行下去。当然,被中止的事务已经执行的所有数据修改操作都必须被撤销。
数据库中解决死锁问题主要有两类方法:一类方法是允许发生死锁,然后采用一定手段定期诊断系统中有无死锁,若有则解除之,称为死锁检测;另一类方法是采用一定措施来预防死锁的发生,称为死锁预防。
6.3.4.1 死锁检测
锁管理器通过waits-for图记录事务的等待关系,如图6-2所示。其中结点代表事务,有向边代表事务在等待另一个事务解锁。当waits-for图出现环路时,就说明出现了死锁。锁管理器会定时检测waits-for图,如果发现环路,则需要选择一个合适的事务中止它。
6.3.4.2 死锁避免
当事务请求的锁与其他事务出现锁冲突时,系统为防止死锁,杀死其中一个事务。选择要杀死的事务时,一般持续越久的事务,保留的优先级越高。这种防患于未然的方法不需要waits-for图,但提高了事务被杀死的比率。
6.3.7 封锁粒度
封锁粒度是指封锁对象的大小。封锁对象可以是逻辑单元,也可以是物理单元。以关系数据库为例,封锁对象可以是属性值、属性值的集合、记录、表、直至整个数据库;也可以是一些物理单元,例如页(数据页或索引页)、块等。封锁粒度与系统的并发度及并发控制的开销密切相关。封锁的粒度越小,并发度越高,系统开销也越大;封锁的粒度越大,并发度越低,系统开销也越小。
如果一个DBMS能够同时支持多种封锁粒度供不同的事务选择,这种封锁方法称为多粒度封锁。选择封锁粒度时应该综合考虑封锁开销和并发度两个因素,选择适当的封锁粒度以求得最优的效果。通常,需要处理一个表中大量记录的事务可以以表为封锁粒度;需要处理多个表中大量记录的事务可以以数据库为封锁粒度;而对于只处理少量记录的事务,则以记录为封锁粒度比较合适。
6.4 故障恢复
故障恢复机制是在数据库发生故障时确保数据库一致性、事务原子性和持久性的技术。当崩溃发生时,内存中未提交到磁盘的所有数据都有丢失的风险。故障恢复的作用是防止崩溃后的信息丢失。
故障恢复机制包含两个部分:
- 为了确保DBMS能从故障中恢复,在正常事务处理过程中需要执行的操作,如登记日志、备份数据等。
- 发生故障后,将数据库恢复到原子性、一致性和持久性状态的操作。
6.4.1 故障分类
由于DBMS根据底层存储设备被划分为不同的组件,因此DBMS需要处理许多不同类型的故障。
-
事务故障
一个事务出现错误且必须中止,称其为事务故障。可能导致事务失败的两种错误是逻辑错误和内部状态错误。逻辑错误是指事务由于某些内部条件无法继续正常执行,如非法输入、找不到数据、溢出等;内部状态错误是指系统进入一种不良状态,使当前事务无法继续正常执行,如死锁。
-
系统故障
系统故障是指导致系统停止运转、需要重新启动的事件。系统故障可能由软件或硬件的问题引起。软件问题是指由于DBMS的实现问题(如未捕获的除零异常)导致系统不得不停止;硬件问题是指DBMS所在的计算机出现崩溃,如系统突然掉电、CPU故障等。发生系统故障时,内存中的数据会丢失,但外存数据不受影响。
-
介质故障
介质故障是指当物理存储损坏时发生的不可修复的故障,如磁盘损坏、磁头碰撞、强磁场干扰等。当存储介质失效时,DBMS必须通过备份版本进行恢复。
6.4.2 缓冲池管理策略
缓冲池管理策略是指,对于已提交和未提交的事务,它们在内存缓冲池中修改的数据页被写出到磁盘的时机。
对于已提交事务,存在两种策略:
- FORCE:事务提交时必须强制将其修改的数据页写盘;
- NOFORCE:允许在事务提交后延迟执行写盘操作。
对于未提交事务,也存在两种策略:
- STEAL:允许在事务提交前就将其修改的数据页写盘;
- NOSTEAL:不允许在事务提交前执行写盘操作。
对于恢复来说,FORCE+ NOSTEAL是最简单的策略,但是这种策略的一个缺点是要求内存能放下事务需要修改的所有数据,否则该事务将无法执行,因为DBMS不允许在事务提交之前将脏页写入磁盘。
从高效利用内存和降低磁盘I/O开销的角度出发,NOFORCE+ STEAL策略是最灵活的,这也是很多DBMS采用的策略。在这种策略下,一旦发生故障,恢复机制可能需要执行以下操作:
- UNDO:发生故障时,尚未完成的事务的结果可能已写入磁盘,为保证数据一致性,需要清除这些事务对数据库的修改。
- REDO:发生故障时,已完成事务提交的结果可能尚未写回到磁盘,故障使得这些事务对数据库的修改丢失,这也会使数据库处于不一致状态,因此应将这些事务已提交的结果重新写入磁盘。
为了保证在恢复时能够得到足够的信息进行UNDO和REDO,DBMS在事务正常执行期间需要登记事务对数据库所做的修改,这就是日志机制。
6.4.3 日志
6.4.3.1 日志的原理
日志是由日志记录构成的文件,几乎所有DBMS都采用基于日志的恢复机制。它的基本思路是:DBMS在对磁盘页面进行修改之前,先将其对数据库所做的所有更改记录到磁盘上的日志文件中,日志文件包含足够的信息来执行必要的UNDO和REDO操作,以便在故障后恢复数据库。DBMS必须先将对数据库对象所做修改的日志记录写入日志文件,然后才能将该对象刷新到磁盘,这一过程称为WAL(Write Ahead Log)。WAL的执行过程如图6-3所示。事务开始后,所有对数据库的修改在发送到缓冲池之前都被记录在内存中的WAL缓冲区中。事务提交时,必须把WAL缓冲区刷新到磁盘。一旦WAL缓冲区被安全地写进磁盘,事务的修改结果就也可以写盘了。
日志文件中应该记录以下信息:
- l 事务开始时,向日志中写入一条该事务的开始记录
。 - l 事务结束时,向日志中写入一条该事务的结束记录,结束记录包括两类:正常结束记录
,和异常结束记录 。 - 事务对每个数据对象的修改操作对应一条日志记录,其中包含以下信息:
- 事务ID
- 对象ID
- 修改前的值(用于UNDO)
- 修改后的值(用于REDO)
将日志记录从日志缓冲区写入磁盘的时机有这样几个:
- 接收到提交事务的命令后,在返回提交成功的消息之前,DBMS必须将该事务的所有日志记录写入磁盘。系统可以使用"组提交"的方式来批处理多个事务的提交,以降低I/O开销。
- 日志缓冲区空间不足的时候,需要将缓冲区中的日志记录写入磁盘。
- 在将一个脏数据页写入磁盘之前,与更新该页有关的所有日志记录都必须先被写入磁盘。
需要注意的是,登记日志时必须严格按事务的操作顺序记录,并且写到磁盘中的日志记录顺序必须与写入日志缓冲区的顺序完全一致。
6.4.3.2 日志的类型
根据实现时采用的恢复方法的不同,日志中记录的内容也不一样,分为以下几类。
- 物理日志:物理日志中记录的是事务对数据库中特定位置的字节级更改。例如,日志中记录的是事务对指定数据页中从指定位置开始的若干字节的修改。
- 逻辑日志:逻辑日志中记录的是事务执行的逻辑操作。例如,日志中记录的是事务执行的UPDATE、DELETE和INSERT语句。与物理日志相比,逻辑日志需要写的数据更少,因为每条日志记录可以在多个页面上更新多个元组。然而,当系统中存在并发事务时,通过逻辑日志实现恢复很困难。
- 混合日志:日志中记录的是事务对指定页面中指定槽号内元组的更改,而不是对页中指定偏移位置的更改。
6.4.4 恢复算法
6.4.4.1 事务故障的恢复
事务故障是指事务在运行至正常终止点前被终止,这时恢复子系统应利用日志文件UNDO此事务己对数据库进行的修改。事务故障的恢复应由DBMS自动完成,对用户完全透明。恢复步骤如下:
- 反向扫描日志文件,查找该事务的更新日志记录。
- 对该事务的更新操作执行逆操作, 即将日志记录中 "更新前的值" 写入数据库。如果记录中是插入操作,则逆操作相当于做删除操作:若记录中是删除操作,则逆操作相当于做插入操作;若是修改操作,则逆操作相当于用修改前的值代替修改后的值。
- 继续反向扫描日志文件,查找该事务的其他更新日志记录并做相同处理,直至读到此事务的开始标记。
6.4.4.2 系统故障的恢复
系统故障导致数据库处于不一致状态的原因,一方面是未提交事务对数据库的更新已经被写入数据库,另一方面则是已提交事务对数据库的更新没有被完全写入数据库。因此对于系统故障的恢复操作,就是要UNDO故障发生时未提交的事务,REDO已提交的事务。系统故障也是由DBMS在重启时自动完成,对用户完全透明。恢复步骤如下:
- 正向扫描日志文件,通过事务开始记录和COMMIT记录找出在故障发生前已提交的事务集合和未提交的事务集合。已提交的事务既有开始记录也有COMMIT记录,未提交的事务则只有开始记录,没有相应的COMMIT记录。将已提交的事务加入重做队列(REDO-LIST),未提交的事务加入撤销队列(UNDO-LIST)。
- 反向扫描日志文件,对UNDO-LIST中的各个事务进行UNDO处理。
- 正向扫描日志文件,对REDO-LIST中的各个事务进行REDO处理。
6.4.4.3 介质故障的恢复
发生介质故障后,磁盘上的物理数据和日志文件被破坏,这是最严重的一种故障,恢复方法是重装数据库,然后重做已完成的事务。介质故障的恢复需要用户人工介入,由DBA装入最新的数据库备份及日志文件备份,然后执行系统提供的恢复命令。
DBA装入相关备份文件后,系统执行的恢复过程与系统故障的恢复过程类似,也是通过扫描日志文件构造REDO-LIST和UNDO-LIST,然后对REDO-LIST和UNDO-LIST中的事务分别进行REDO和UNDO处理,这样就可以将数据库恢复到最近一次备份时的一致性状态。
6.4.5 检查点
以上讨论的基于日志的恢复算法存在两个问题:1. 构造REDO-LIST和UNDO-LIST需要搜索整个日志文件,耗费大量的时间;2.处理REDO-LIST时,很多事务的修改实际上已经写入了磁盘,但是仍然不得不进行REDO处理,浪费大量时间。为了解决上述问题,提高恢复效率,很多DBMS都采用了检查点技术,通过周期性地对日志做检查点来避免故障恢复时检查整个日志。
检查点技术的基本思路是:在日志文件中增加一类记录——检查点记录,并增加一个文件——重新开始文件。恢复子系统周期性地执行以下操作:
- 将日志缓冲区中的日志记录全部写入磁盘中的日志文件;
- 在日志文件中写入一个检查点记录;
- 将数据缓冲区中的数据写入磁盘;
- 将检查点记录在日志文件中的地址写入重新开始文件。
其中,检查点记录中包含以下信息:
- 检查点时刻,当前所有正在执行的事务清单
- 清单中每个事务最近一个日志记录的地址
由检查点时刻系统执行的操作可知,如果一个事务在一个检查点之前已经提交了,那么它对数据库所做的修改一定都被写入了磁盘,因此在进行恢复处理时,就没有必要再对该事务执行REDO操作了。
增加了检查点之后,基于日志的恢复步骤如下:
- 从重新开始文件中找到最后一个检查点记录在日志文件中的地址,根据该地址在日志文件中找到最后一个检查点记录。
- 由该检查点记录得到检查点时刻正在执行的事务清单ACTIVE-LIST。初始化两个事务队列UNDO-LIST和REDO-LIST,令UNDO-LIST = ACTIVE-LIST,令REDO队列为空。
- 从检查点开始正向扫描日志文件直到日志文件结束,如有新开始的事务,则将其放入UNDO-LIST,如有提交的事务,则将其从UNDO-LIST队列移到REDO-LIST队列。
- 对UNDO-LIST和REDO-LIST中的每个事务,分别执行UNDO和REDO操作。
参考资料
- 王珊, 萨师煊. 数据库系统概论(第5版). 北京: 高等教育出版社, 2014
- Hector Garcia-Mlina, Jeffrey D. Ullman, Jennifer Widom. 杨冬青 等译. 数据库系统实现. 北京: 机械工业出版社, 2010
- Abraham Silberschatz, Henry F.Korth, S. Sudarshan. 杨冬青 等译. 数据库系统概念(第6版). 北京: 机械工业出版社, 2012
- 李海翔. 数据库查询优化器的艺术原理解析与SQL性能优化. 北京: 机械工业出版社, 2014
- CMU 15445
MiniOB 博客放一些数据库技术实现原理相关的内容,有些来自OceanBase 内部分享的一些论文阅读笔记、技术分享、开发心得等,希望能够帮助大家了解数据库。
本篇文章来自 OceanBase 内部论文分享
本篇文章分享的论文是《High-Performance Concurrency Control Mechanisms for Main-Memory Databases》,该论文介绍了微软SQL Server内存数据库Hekaton所使用的并发控制算法原型,提出了一种无锁的乐观并发控制以及一种无锁的悲观并发控制方法,最终Hekaton采用的是其中的乐观并发控制方法,其也是第一个在生产中将OCC落地的数据库。欢迎感兴趣的同学一起交流学习~
Background
本篇论文讨论内存数据库(Main-Memory Database)中MVCC的设计。
Main-Memory Database
产生背景:
- 服务器内存大小不断增加(TB级)
- 服务器处理器核数不断增加
- 内存价格持续下降
特点:
- 表数据完全存在内存中,无需从磁盘读取
- 进行针对性优化,如无锁结构、无锁并发控制方法等
- 性能优异
SQL Server Hekaton
集成在SQL Server中针对内存数据以及OLTP负载进行优化的数据库引擎。 优化点:
- 优化内存索引
- 无锁结构
- 解释执行
Hekaton Concurrency Control Mechanism
论文介绍了Hekaton高性能事务并发控制算法的原型方法,基于事务不阻塞的原则以及MVCC技术,介绍了一种无锁的多版本悲观并发控制(PCC)以及一种无锁的多版本乐观并发控制(OCC)策略,并实现了面向内存优化的单版本加锁基线方案,在不同场景对这三种方法进行了测试与比较。
这里的事务不阻塞不是说永远不等待,是说不等锁。 不阻塞的好处是会有更少的上下文切换。
MVCC Storage Engine
存储和索引
设计原则
避免等待,设计为lock-free
论文以 lock-free hashtable index为例,介绍并发控制策略,也可用于trees以及skip list等顺序索引结构中。
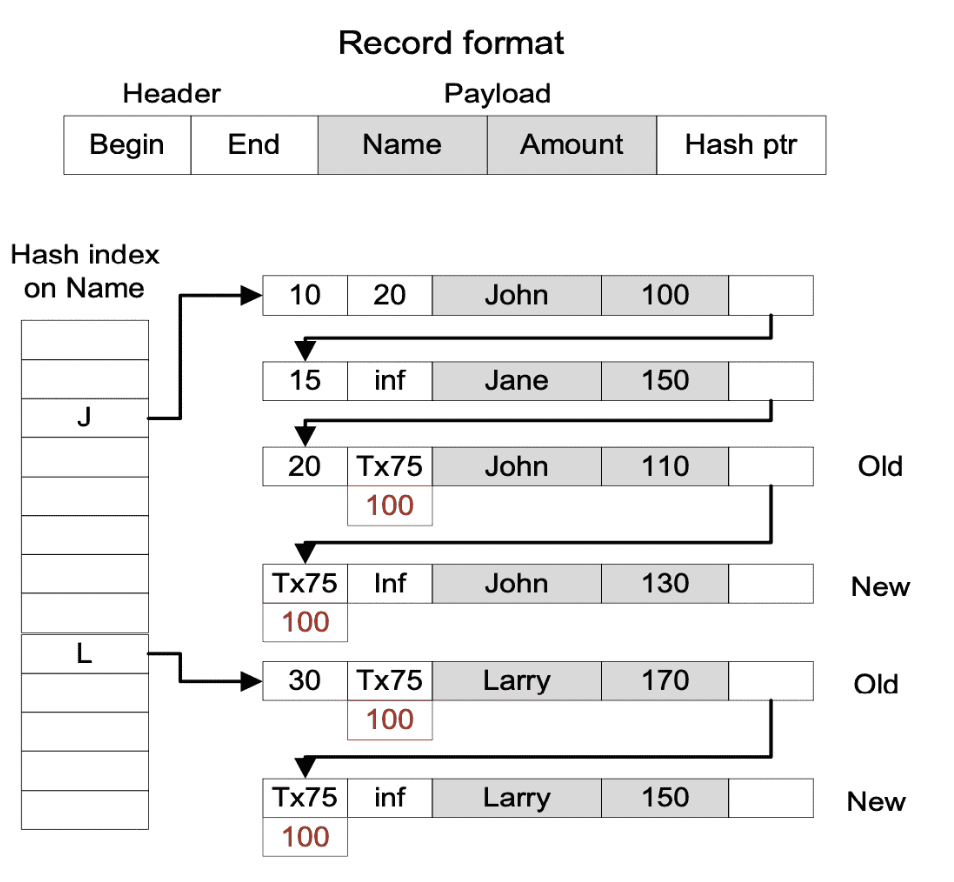
Record
- 包含Name、Amount两列
- 包含Begin、End字段,存储时间戳或事务id,代表该版本有效时间范围
- 相同hash bucket版本通过指针相连,从旧到新
- 与原型基本结构相同
- 增加将相同key的version连接的指针
- 增加了一个无锁B-tree(Bw-tree)用于范围查询,叶子节点指向第一个版本
- 可同时存在多个hash index(见附录)
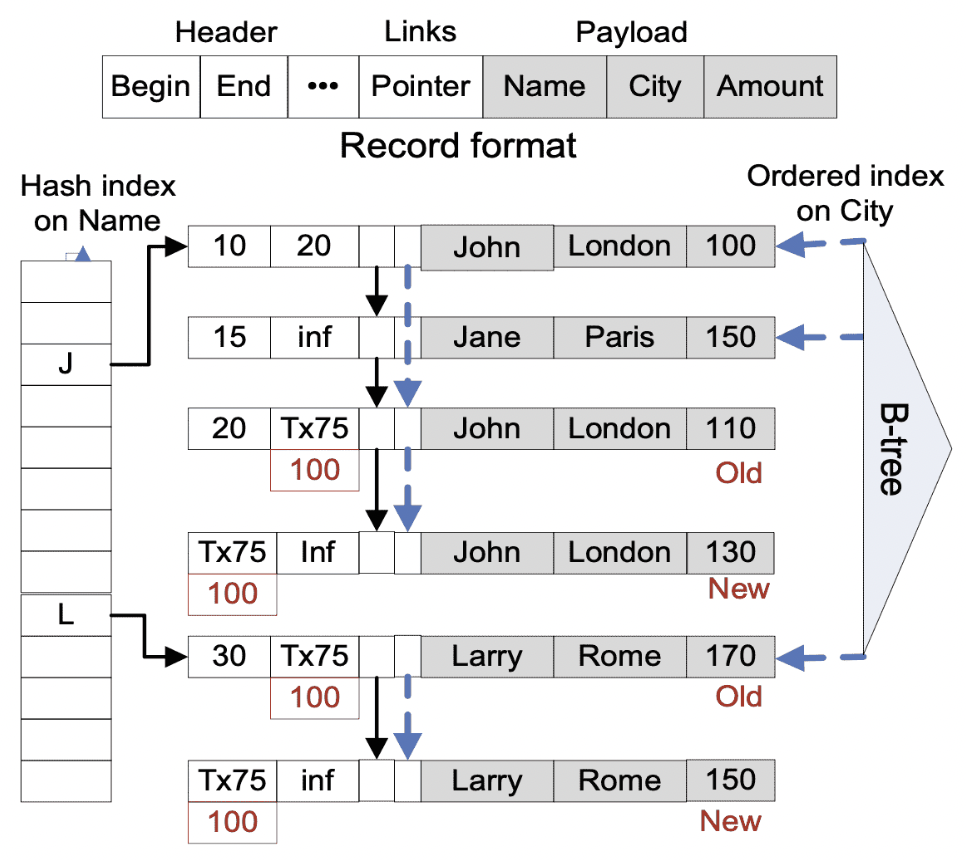
事务执行
- Active:事务创建,获取开启时间戳
- Normal processsing phase:事务执行。
- Preparation phase:若commit,则将新version以及delete版本相关信息写redo log并等待日志持久化
- Postprocessing phase:commit成功则替换新旧版本中事务ID为事务end时间戳;abort则将事务ID替换为infinity
- Transaction terminated:旧版本通过garbage colloctor
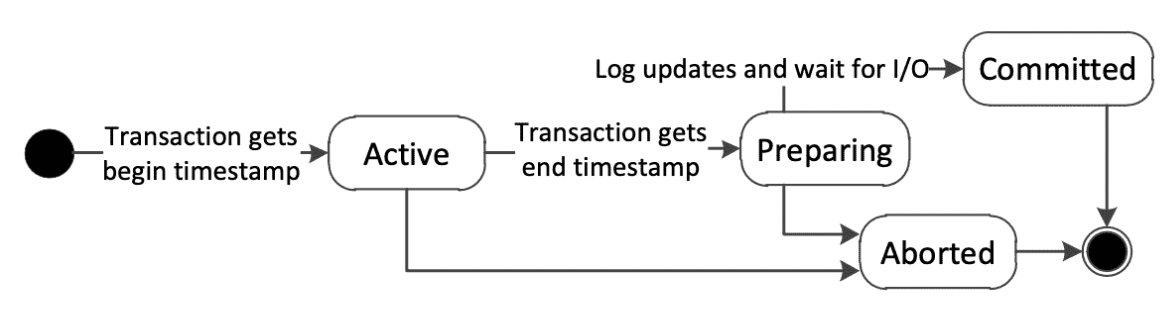
版本可见性
RT为事务T读取时间,
场景一、Begin与End都为时间戳
TBegin <= RT < TEnd则可读
场景二、Begin为 TB 事务ID
| TB状态 | TB的结束时间戳 | 事务T检查版本V的记录是否可见 |
|---|---|---|
| Active | 未设置 | 只有TBeigin=T并且V的结束时间戳是infinity才可见 |
| Preparing | TS | V的开始时间戳是TS但是V还没有提交。使用TS作为V的开始时间戳来检测可见性 |
| Committed | TS | V的开始时间戳就是TS |
| Aborted | 不相关 | 忽略,这是一个垃圾版本 |
| Terminated 或没找到 | 不相关 | 重新读取V的Begin字段 |
场景三、End 为 TE 事务ID
| TE状态 | TE的结束时间戳 | 事务T检查版本V的记录是否可见 |
|---|---|---|
| Active | 未设置 | TE=T就可见 |
| Preparing | TS | V的结束时间戳会在提交时变成TS。如果TS>RT,就可见 |
| Committed | TS | 使用TS做可见性判断 |
| Aborted | 不相关 | V可见 |
| Terminated 或没找到 | 不相关 | 重新读取V的结束时间戳字段 |
版本更新
事务只允许更新最新版本V:
- V的结束时间戳字段End是infinity
- V End 字段=TE事务,事务TE Aborted
- V End 字段=TE事务,事务TE是Active或Preparing,产生写写冲突,采用first-write-win策略,事务终止
Commit 依赖
如果T1必须在T2提交后才能提交,那就认为T1依赖T2:
- 提前读
- 提前忽略
每个事务增加:
- CommitDepCounter:commit依赖事务数
- AbortNow:是否需要abort
- CommitDepSet:依赖于本事务commit的事务ID
如果事务T2提交成功,就将T1 的 CommitDepCounter 减1并唤醒它。 如果事务T2 Abort,那就将 T1 的AbortNow置为1。
Commit依赖将所有的等待步骤都推迟到了Commit阶段。 事务在commit之前很可能不需要等待,因为很可能它依赖的事务也都提交了。 也免去了死锁问题,总是年轻事务等待年老事务。
Optimistic Concurrency Control
事务维系数据集合
串行化级别:
- ReadSet: 所读版本
- ScanSet: 重复scan操作所需要的信息
- WriteSet: 新旧版本指针
Normal Processing Phase
包含Index Scan定位对应版本以及读/写。 可串行化级别下,使用事务开始时间作为读操作TS。
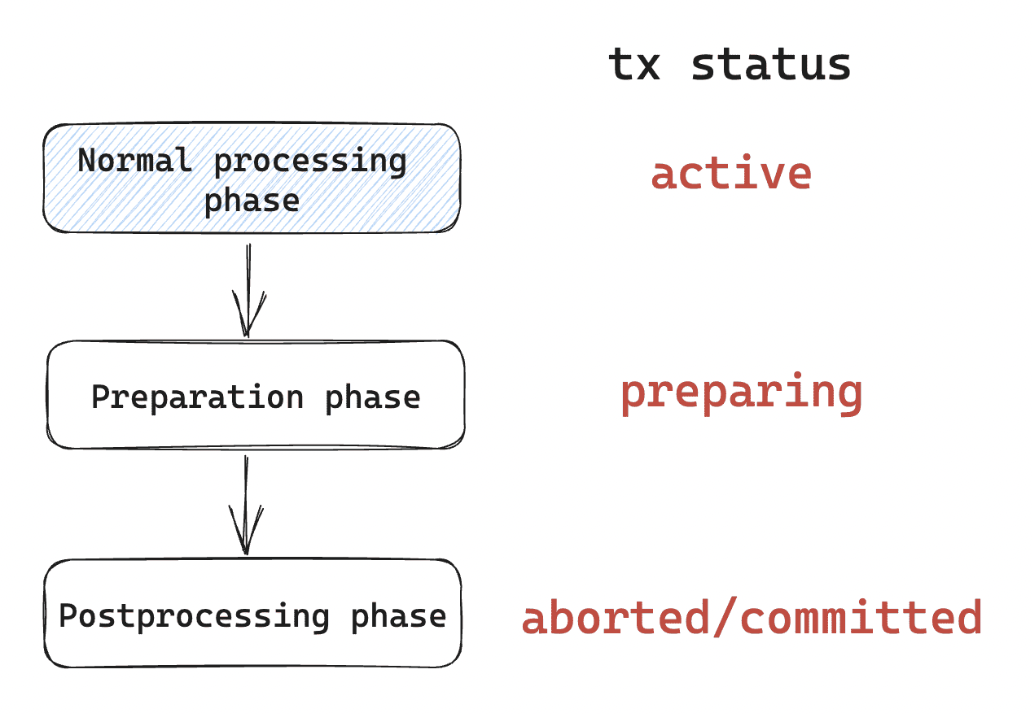
- Start Scan: 执行scan操作,记录scan信息
- Check Predicate: 谓词检查
- Check visibility: 可见性判断,同时添加commit依赖
- Read Version: 读数据,记录指针到ReadSet
- Check Updatability: 确定版本可以更新;可提前更新,前提是该版本的事务已经完成normal processing
- Update Version: 执行更新,插入新版本,旧版本end修改为事务ID(失败就abort),写入WriteSet
- Delete Version: 修改旧版本end字段为事务ID,记录其指针到WriteSet
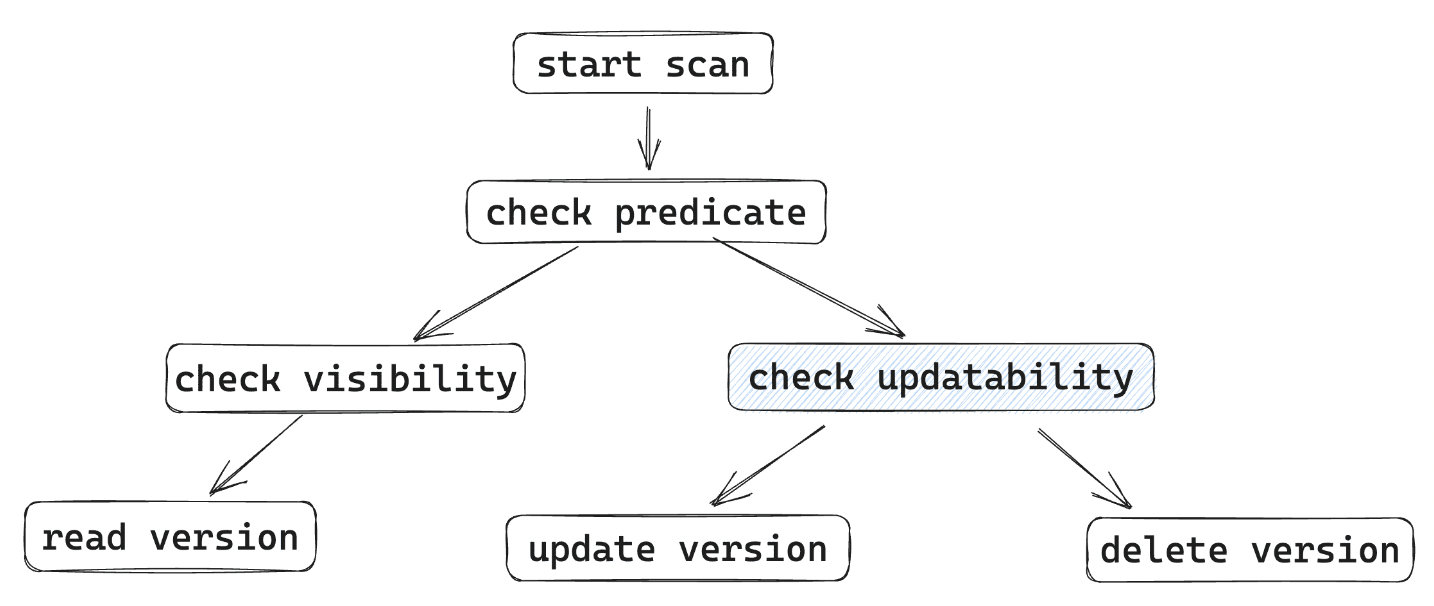
PreCommit
- 获取事务end ts(commit ts)
- 设置事务状态为Preparing
- 进入Preparation phase
Preparation Phase
- Read validation:
- 可重复读检查。重新扫描ReadSet,确认版本仍然可见
- 幻读检查: 重新执行ScanSet中的扫描,检查是否有新版本
- Wait for commit dependencies
- 等待所有依赖事务提交, CommitDepCounter=0
- 未通过或者AbortNow=1,就abort,进入 postprocessing phase
- Logging
- 将创建的新版本、删除版本的信息写入日志
设置事务状态:aborted/committed
Postprocessing Phase
成功commit就把TS写到旧版本end字段和新版本的begin字段。 如果abort就把WriteSet中的新版本end字段设置为infinity,新版本start字段设置为infinity。 这里的abort动作不会阻塞其它事务。
Low Level Isolation
Repeatable read
不需要做幻读检查。读操作使用事务开始时间。
Snapshot Isolation
不做可重复读检查与幻读检查,使用事务开始时间作为读操作时间戳。
Read Committed
不做可重复读检查与幻读检查。读操作使用当前时间。
Read-only Transaction
SI 或者 RC隔离级别性能更好
Pessimistic Concurrency Control
事务维系数据集合
串行化级别:
- ReadSet: 事务读到的版本数据
- BucketSet: 访问上锁的bucket集合
- WriteSet: 新旧版本指针
Lock Types
Record Lock
- 保证可重复读
- 只对最新版本加锁
- 使用Record End 字段实现(64 bits)
Bucket Lock(Range Locks)
- 避免幻读
- 存储于hash bucket中,扫描的时候上锁
数据结构:
LockCount: 上锁的数目
LockList: 加锁的事务
Eager update & Wait-For Dependencies
可串行化场景下,传统的多版本加锁方法更新/删除某一行,下面的场景会导致阻塞:
- 行已经加了read lock
- Bucket 已经加锁
Eager Update
允许对有read lock和bucket lock的bucket进行update。
但是锁释放之前不允许precommit 进入preparing阶段。 还需要添加wait-for依赖。
Wait-For Denpendencies
一个事务有以下结构:
WaitForCounter: 事务依赖的的个数
NoMoreWaitFors: 不允许再添加wait-for依赖
WaitingTxnList: 依赖当前事务结束的事务集合
Wait-For类型:
- Read Lock Denpendency
- Bucket Lock Denpendency
Read Lock Denpendencies
一个事务TU想要对版本V更新或删除,但是V已经有了read lock:
- 将TU的事务ID写入V的 WriteLock 字段
- ReadLockCounter > 0,TU WaitForCounter加1
事务TR对V加读锁:
- NoMoreReadLocks=true 或 ReadLockCount=max_value,TR abort
- ReadLockCounter > 0,将其加1
- 若已存在事务TU添加的write lock,且TR为第一个读锁,检查TU NoMoreWaitFor,若true,abort,否则强制TU等待TR(添加wait-for依赖)
事务 TR 对版本 V 释放read lock
- 不存在write lock,直接将ReadLockCounter减1
- 存在write lock 且 ReadLockCounter > 1,同上
- 存在write lock 且 ReadLockCounter = 1, ReadLockCounter置为0,并将其NoMoreReadLocks置为1,TU WaitForCounter减1避免后续read lock进一步阻塞TU commit
Bucket Lock Denpendencies
允许Bucket提前插入,但需要上锁事务完成,才能进行precommit,通过添加wait-for依赖实现。
TU在Bucket B插入/删除新版本:
- B不存在Bucket lock,直接上锁事务维系结构
- B存在Bucket lock
- TU NoMoreWaitFors=true,TU abort
- TU NoMoreWaitFors=false,对B LockList事务添加wait-for依赖
这时是TU给自己加了一个依赖(Wait-For Denpendency)。
事务TS scan Bucket B,发现满足查询条件但不可见版本V,且更新其事务TU为Active,为避免幻读,需添加wait-for依赖:
- TU NoMoreWaitFors=true,TS abort
- TU NoMoreWaitFors=false:TU添加到自身WaitingTxnList;将TU WaitForCounter加1
这时是TS给TU添加依赖。
Normal Processing Phase
| 阶段/控制策略 | OCC | PCC |
|---|---|---|
| Start Scan | 记录Scan信息到ScanSet(Serializable) | 对Scan的Bucket加锁,放入BUcketLockSet(Serializable) |
| Check Predicate | 条件检查 | 条件检查 |
| Check Visibility | 可见性判断,commit 依赖条件添加 | 与OCC相同,但是需要添加Wait-For依赖(Serializable) |
| Read Version | 读版本指针存入ReadSet(Serializable、RR) | 添加read lock(Serializable、RR) |
| Check Updatability | 可更新检查,commit依赖添加 | 与OCC相同 |
| Update Version | 更新,加入WriteSet | 更新,添加wait-for依赖 |
| Delete Version | 删除,加入WriteSet | 删除,添加wait-for依赖 |
| Process End | Precommit | wait-for等待,precommit,释放read/bucket lock |
Preparation Phase
不需要做Read Validation。 直接等待commit denpendencies。 然后记录日志。
Postprocessing Phase
与乐观并发控制一致,通过修改版本的begin、end字段,隐式释放写锁。
Experimental Results
实验环境
- 2-socket CPU,共12核24线程,NUMA架构,访问remote memory比local memory慢30%
- Log异步刷盘,组提交避免IO带宽成为瓶颈
- 测试0 - 24线程,24线程CPU利用率最高,加线程吞吐下降
实现面向内存优化的单版本加锁(1V)方案作为基线,测试不同场景1V、OCC(MV/O)以及PCC(MV/L)的表现。
同构负载-RC
低竞争:
- 多版本管理以及垃圾回收开销,吞吐不如1V
- MV/L 比 MV/O慢30%,依赖追踪以及锁的额外写导致内存流量增加
高竞争:
- 热点数据访问cache同步导致核间流量大
- MV/O表现最好
Higher Isolation Level
固定24线程,改变隔离级别:
- 加锁方式,RR级别损失很小<2%;MV/O 可重复读检查,损失8%
- Serializable:1V > MV/L > MV/O
- MV/O需要承担更多隔离级别造成的性能损失
异构负载—短只读事务影响
低竞争:
- 只读比例增加,gap减小——多版本以及垃圾回收代价减小
- 绝大多数只读,MV比1V好,纯只读MV相同,1V略差
高竞争: 80%是只读,MV比1V高73%以及63%——MV只读不影响写
异构负载—长只读事务影响
存在长事务时更新吞吐:
- 存在1个长事务,1V下降75%,MV下降5%,MV为1V两倍
- 50%长事务,MV为1V 80倍
存在长事务时读吞吐: MV优于1V
Conclusion
- 可在获取锁不成为瓶颈的情况下有效的实现1V-Lock方式
- 1V-Lock方式在短事务、低竞争下表现好,但不同场景适应性很差
- 高竞争以及存在长事务时MVCC优于1V-Lock
- MVCC-O表现比MVCC-P好
悲观并发控制:访问数据时加锁,有可能需要等待锁释放 乐观并发控制:假设数据一般不会造成冲突,只在事务提交时进行冲突检测
最终Hekaton所采用为其中的乐观并发控制(OCC)方法。而基于磁盘的数据库通常采用悲观并发控制(PCC)方法,其解释原因如下:
- 在对数据update时进行冲突检测(写写冲突)
- 假设前提不同:
- 基于磁盘的PCC事务tx1 等到tx2 回滚时才能继续,tx2 commit产生conflict error(假设tx2会提交失败)
- 基于内存的PCC事务tx1 直接产生conflict Error(假设tx2会提交成功)
Main-Memory Database Concurrency Control Mechanisms
| Main-Memory 数据库 | 并发控制方法 | 支持隔离级别 |
|---|---|---|
| Microsoft Hekaton | MVCC-O(lock-free) | Serializable, RR, SI, RC(single stmt) |
| Oracle TimesTen | Single-version + multiple-lock | Serializable, RC |
| SAP HANA | MVCC-P(lock) | Serializable, SI, RC |
| IBM SolidDB | Single-version + multiple-lock | RR, RC |
| VoltDB | Deterministic Concurrency Control | Serializable |
References
- Hekaton: SQL Server’s Memory-Optimized OLTP Engine
- SQL Server In-Memory OLTP Internals for SQL Server 2016
- OCC的前世今生
附录