排查 ODP 连接问题
当前使用 ODP 时,请求执行的链路主要为:客户端发送请求到 ODP --> ODP 将请求路由到对应的 OBServer 节点 --> OBServer 节点处理请求发送回包给 ODP --> ODP 回包给客户端。
目前整条链路上都可能发生断连接的场景,比如:请求处理时间较长导致客户端长时间没有收到回包而断开连接、用户登录信息填写错误的集群租户等导致无法登录、ODP 以及 OceanBase 数据库的内部错误导致断开连接等等。
排查 ODP 问题的基本方法
个人建议重点看一下 “排查 ODP 问题的基本方法” 这一部分的内容,能根据 trace id 捞出日志,对于大多数场景,基本也就够用了。
初步排查 ODP 问题的方法,和排查 observer 问题的方法类似。
例如连接报错,想看详细的报错日志。
[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby]
$obclient -h 127.0.0.1 -P2883 -uroot@sys#xiaofeng_91_435 -Dtest
ERROR 4669 (HY000): cluster not exist
这个例子举的不太好,在初始报错 cluster not exist 的时候基本就能看出是啥问题了,大家重在领会精神。
一般不确定是否属于 ODP 的责任,会先在 /oceanbase/log 目录中 grep "ret=-4669" *(如果 log 目录中的日志较多,可以根据实际情况,把 grep 后面的 * 改成 observer.log.202412171219* 等)。
[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/oceanbase/log]
$sudo grep "ret=-4669" *
如果在 observer 目录中 grep 不到任何错误信息,大概率就是 ODP 的问题了。可以再到 /obproxy/log 下面去 grep 一把。
[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/obproxy/log]
$grep "ret=-4669" *
# 这里的输出原本是一行,为了方便在网页中展示,手动拆成了多行。
obproxy.log:[2024-12-17 14:34:14.024891]
WDIAG [PROXY.SM] setup_get_cluster_resource (ob_mysql_sm.cpp:1625)
[125907][Y0-00007F630AAA2A70] [lt=0] [dc=0]
cluster does not exist, this connection will disconnect
(sm_id=26403246, is_clustername_from_default=false, cluster_name=xiaofeng_91_435, ret=-4669)
一般到这步就能够根据日志看出一些端倪了,日志里明确说了这个 cluster_name 叫 xiaofeng_91_435 的集群不存在,所以 this connection will disconnect。
在上面的日志里,还可以获得一个 trace id:[Y0-00007F630AAA2A70],如果希望进一步获得更多信息,grep 这个 trace id 就能够获得所有这次操作相关的所有日志信息。
[xiaofeng.lby@sqaobnoxdn011161204091.sa128 /home/xiaofeng.lby/obproxy/log]
$grep Y0-00007F630AAA2A70 *
obproxy_diagnosis.log:[2024-12-17 14:34:14.024938] [125907][Y0-00007F630AAA2A70] [LOGIN]
(trace_type="LOGIN_TRACE",
connection_diagnosis={
cs_id:278640, ss_id:0, proxy_session_id:0, server_session_id:0,
client_addr:"127.0.0.1:9988", server_addr:"*Not IP address [0]*:0",
cluster_name:"xiaofeng_91_435", tenant_name:"sys", user_name:"root",
error_code:-4669, error_msg:"cluster does not exist",
request_cmd:"OB_MYSQL_COM_LOGIN", sql_cmd:"OB_MYSQL_COM_LOGIN",
req_total_time(us):196}
{internal_sql:"", login_result:"failed"})
obproxy_error.log:2024-12-17
14:34:14.024960,xiaofeng_cluster_430_proxy,,,,xiaofeng_91_435:sys:,OB_MYSQL,,,
OB_MYSQL_COM_LOGIN,,failed,-4669,,194us,0us,0us,0us,
Y0-00007F630AAA2A70,,127.0.0.1:9988,,0,,cluster not exist,
obproxy.log:[2024-12-17 14:34:13.584801] INFO [PROXY.NET] accept (ob_mysql_session_accept.cpp:36)
[125907][Y0-00007F630AAA2A70] [lt=0] [dc=0] [ObMysqlSessionAccept:main_event]
accepted connection(netvc=0x7f630aa7d2e0, client_ip={127.0.0.1:9980})
...
当发生断连接之后,ODP 会记录一段断连接日志到 obproxy_diagnosis.log 日志文件中,这里会详细记录断连接相关的信息,以租户名写错为例:
# 这里的输出原本是一行,为了方便在网页中展示,手动拆成了多行。
[2023-08-23 20:11:08.567425]
[109316][Y0-00007F285BADB4E0] [CONNECTION]
(trace_type="LOGIN_TRACE",
connection_diagnosis={
cs_id:1031798792, ss_id:0, proxy_session_id:0, server_session_id:0,
client_addr:"10.10.10.1:58218", server_addr:"*Not IP address [0]*:0",
cluster_name:"undefined", tenant_name:"test", user_name:"root",
error_code:-4043,
error_msg:"dummy entry is empty, please check if the tenant exists",
request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:""})
看到最后 error_msg 中的 please check if the tenant exists,基本也就能猜出断连接的原因了。
在这个文档中,后面的部分都是一些 “类字典” 的内容,只需要粗略过一遍(因为认真看完也记不住)。
建议先收藏。如果真出了问题,捞出日志,拿着日志里的关键信息,在下面查一下对应的解决方法即可。
obproxy_diagnosis 日志通用内容如下:
-
LOG_TIME:日志打印时间,即示例中的
2023-08-23 20:11:08.567425 -
TID:线程 ID,即示例中的
109316 -
TRACE_ID:trace_id,即示例中的
Y0-00007F285BADB4E0,可以通过 trace_id 与其他日志进行关联 -
CONNECTION:表示这条日志为连接诊断相关的日志
-
trace_type:诊断类型,目前诊断日志有以下几种类型,不同的诊断类型也对应不同的断连接问题
-
LOGIN_TRACE:登录问题相关的诊断日志
-
SERVER_INTERNAL_TRACE:OceanBase 数据库内部错误的诊断信息
-
PROXY_INTERNAL_TRACE:ODP 内部错误导致断连接的诊断信息
-
CLIENT_VC_TRACE:客户端主动断连的诊断日志
-
SERVER_VC_TRACE:OceanBase 数据库主动断连的诊断日志
-
TIMEOUT_TRACE:ODP 执行超时的诊断日志
-
-
CS_ID:ODP 内部标识客户端连接的 ID
-
SS_ID:ODP 内部标识 ODP 与 OceanBase 数据库之间连接的 ID
-
PROXY_SS_ID:由 ODP 生成的标识客户端连接的 ID,会传递给 OceanBase 数据库,可以用来筛选 OceanBase 数据库日志或者 sql_audit 表
-
SERVER_SS_ID:由 OceanBase 数据库生成的标识 ODP 与 OceanBase 数据库之间连接的 ID
-
CLIENT_ADDR:客户端的 IP 地址
-
SERVER_ADDR:出错或者断连接时对应的 OBServer 节点的地址
-
CLUSTER_NAME:集群名
-
TENANT_NAME:租户名
-
USER_NAME:用户名
-
ERROR_CODE:错误码
-
ERROR_MSG:错误信息,诊断断连接的关键内容
-
REQUEST_CMD:ODP 当前正在执行的 SQL 语句的类型,可能为内部请求的 SQL 语句类型
-
SQL_CMD:用户 SQL 语句的类型
除上述通用的信息外,诊断日志还包含额外诊断信息,具体内容由 trace_type 决定。
常见断连接场景
接下来为大家介绍几种常见的断连接场景,以及对应断连接场景的排查和解决方法。
登录断连接
登录断连接对应的 trace_type 为 LOGIN_TRACE,租户名错误导致断连接的诊断日志示例如下:
[2023-09-08 10:37:21.028960] [90663][Y0-00007F8EB76544E0] [CONNECTION](
trace_type="LOGIN_TRACE",
connection_diagnosis={
cs_id:1031798785, ss_id:0, proxy_session_id:0, server_session_id:0,
client_addr:"10.10.10.1:44018", server_addr:"*Not IP address [0]*:0",
cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10018,
error_msg:"fail to check observer version, empty result", request_cmd:"COM_SLEEP",
sql_cmd:"COM_LOGIN"}
{internal_sql:"SELECT ob_version() AS cluster_version"})
额外诊断信息为 internal_sql,表示 ODP 当前执行的内部请求。
登录断连接产生的原因比较复杂,本文从用户操作和 OceanBase 数据库两个方面介绍产生原因和解决方法。
从用户操作方面来看,有如下几种场景会导致产生断连接:
| 场景 | 错误码 | 错误信息 | 解决方法 |
|---|---|---|---|
| 集群名错误 | 4669 | cluster xxx does not exist | 确保对应集群存在且集群名正确,可直连 OBServer 节点后执行 show parameters like 'cluster'; 命令进行确认,输出中 value 值即为待连接的集群名。 |
| 租户名错误 | 4043 | dummy entry is empty, please check if the tenant exists | 确保对应的租户存在,可使用系统租户(root@sys)直连 OBServer 节点后执行 SELECT * FROM DBA_OB_TENANTS; 命令,查看集群中的所有租户。 |
| ODP 白名单校验失败 | 8205 | user xxx@xxx can not pass white list | 通过管控台确认 ODP 白名单是否配置正确,详细操作可参见 OB Cloud 云数据库文档 白名单分组。 |
| OceanBase 数据库白名单校验失败 | 1227 | Access denied | 确认 OceanBase 数据库白名单是否配置正确,可通过查看 ob_tcp_invited_nodes 变量进行确认。 |
| 客户端连接数达上限 | 5059 | too many sessions | 可通过执行 ALTER proxyconfig SET <var_name> = <var_value>; 命令调整 ODP 的配置项 client_max_connections 做暂时的规避。 |
| ODP 配置要求使用 SSL 协议,但是用户发起普通协议请求 | 8004 | obproxy is configured to use ssl connection | 修改 SSL 协议配置 enable_client_ssl 为不使用 SSL 协议连接(值为 false);或者使用 SSL 协议访问。 |
| 直接访问 proxyro@sys | 10021 | user proxyro is rejected while proxyro_check on | 不应直接使用 proxyro@sys 访问数据库。 |
云上用户在关闭 enable_cloud_full_user_name 的场景下使用三段式访问 | 10021 | connection with cluster name and tenant name is rejected while cloud_full_user_name_check off | 云上用户关闭 enable_cloud_full_user_name 时,ODP 会限制三段式的访问。您可开启 enable_cloud_full_user_name 配置,或者使用非三段式访问。 |
| proxyro 密码配置错误 | 10018 | fail to check observer version, proxyro@sys access denied, error resp { code:1045, msg:Access denied for user xxx } | 默认情况下,proxyro 的密码不会存在问题的,如果手动更改过 OceanBase 数据库中 proxyro@sys 用户的密码,请确保 ODP 的配置项 observer_sys_password 值和 proxyro@sys 用户密码一致。 |
| 启动 ODP 时配置的 rootservice_list 不可用 | 10018 | fail to check observer version, empty result | 这里可以通过直连 OBServer 节点,通过 SHOW PARAMETERS LIKE 'rootservice_list'; 命令查看 OceanBase 数据库的 Root Service,以确认 ODP 启动时配置的 server ip 是否可用。 |
从 OceanBase 数据库方便来看,有如下几种场景会导致产生断连接:
| 场景 | 错误码 | 错误信息 | 解决方法 |
|---|---|---|---|
| 集群信息查询为空 | 4669 | cluster info is empty | 直连 OceanBase 数据库,执行 internal_sql 字段的 SQL 语句确认 OceanBase 数据库返回的集群信息是否为空。 |
| 集群信息查询失败 | 10018 | fail to check observer version fail to check cluster info fail to init server state | 直连 OceanBase 数据库,执行 internal_sql 字段的 SQL 语句确认 OceanBase 数据库返回的集群信息是否为空。 |
| Config Server 信息查询失败 | 10301 | fail to fetch root server list from config server fail to fetch root server list from local | 可以手动拉取启动时配置的 Config Server 的 URL(obproxy_config_server_url 的值),确认 Config Server 返回的信息是否正常。 |
超时断连接
超时断连接对应的 trace_type 为 TIMEOUT_TRACE,集群信息过期导致断连接的诊断日志示例如下:
[2023-08-17 17:10:46.834897] [119826][Y0-00007FBF120324E0] [CONNECTION](trace_type="TIMEOUT_TRACE", connection_diagnosis={cs_id:1031798785, ss_id:7, proxy_session_id:7230691830869983235, server_session_id:3221504994, client_addr:"10.10.10.1:42468", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10022, error_msg:"OBProxy inactivity timeout", request_cmd:"COM_SLEEP", sql_cmd:"COM_END"}{timeout:1, timeout_event:"CLIENT_DELETE_CLUSTER_RESOURCE", total_time(us):21736})
额外诊断信息有如下两条。
-
timeout_event:表示超时事件
-
total_time:表示请求执行时间
下表根据不同的超时事件介绍如何解决断连接问题。
| 超时事件 | 场景 | 错误码 | 相关配置 | 解决方法 |
|---|---|---|---|---|
| CLIENT_DELETE_CLUSTER_RESOURCE | 集群信息发生变化 | 10022 | ODP 配置项 cluster_expire_time | 可以通过执行 ALTER proxyconfig SET <var_name> = <var_value>; 命令调整 ODP 中 cluster_expire_time 配置项暂时规避,cluster_expire_time 配置项默认过期时间为一天,新的请求会重置过期时间。 |
| CLIENT_INTERNAL_CMD_TIMEOUT | 内部请求执行超时 | 10022 | 固定时间 30s | 非预期超时,建议联系技术支持人员配合诊断。 |
| CLIENT_CONNECT_TIMEOUT | 客户端与 ODP 建连超时 | 10022 | 固定时间 10s | 非预期超时,建议联系技术支持人员配合诊断。 |
| CLIENT_NET_READ_TIMEOUT | ODP 等待用户请求数据超时 | 10022 | OceanBase 数据库系统变量 net_read_timeout | 修改系统变量 net_read_timeout,需注意修改 Global 级别的系统变量不会对已有连接生效。 |
| CLIENT_NET_WRITE_TIMEOUT | ODP 等待回包数据超时 | 10022 | OceanBase 数据库系统变量 net_write_timeout | 修改系统变量 net_write_timeout,需注意修改 Global 级别的系统变量不会对已有连接生效。 |
| CLIENT_WAIT_TIMEOUT | 用户请求过程中,客户端连接长时间没有发生交互导致超时 | 10022 | OceanBase 数据库系统变量 wait_timeout | 修改系统变量 wait_timeout 暂时规避。 |
| SERVER_QUERY_TIMEOUT | 用户请求查询超时 | 10022 | OceanBase 数据库系统变量 ob_query_timeout、hint 指定的 query_timeout | 修改系统变量 ob_query_timeout 暂时规避。 |
| SERVER_TRX_TIMEOUT | 用户事务执行超时 | 10022 | OceanBase 数据库系统变量 ob_trx_timeout | 修改系统变量 ob_trx_timeout 暂时规避。 |
| SERVER_WAIT_TIMEOUT | 用户请求过程中,OceanBase 数据库连接长时间没有发生交互导致超时 | 10022 | OceanBase 数据库系统变量 wait_timeout | 修改系统变量 wait_timeout 暂时规避。 |
OceanBase 数据库主动断开连接
OceanBase 数据库主动断开连接对应的 trace_type 为 SERVER_VC_TRACE,ODP 与 OceanBase 数据库建连失败的诊断日志示例如下:
[2023-08-10 23:35:00.132805] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="SERVER_VC_TRACE", connection_diagnosis={cs_id:838860809, ss_id:0, proxy_session_id:7230691830869983240, server_session_id:0, client_addr:"10.10.10.1:45765", server_addr:"", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10013, error_msg:"Fail to build connection to observer", request_cmd:"COM_QUERY", sql_cmd:"COM_HANDSHAKE"}{vc_event:"unknown event", total_time(us):2952626, user_sql:"select 1 from dual"})
额外诊断信息有如下三条。
-
vc_event:表示断连接相关的事件,您无需太过关注
-
total_time:表示请求执行时间
-
user_sql:表示用户请求
OceanBase 数据库主动断连接有如下几种场景。
| 场景 | 错误码 | 错误信息 | 解决方法 |
|---|---|---|---|
| ODP 与 OceanBase 数据库建连失败 | 10013 | Fail to build connection to observer | 需与 OceanBase 数据库配合诊断。 |
| ODP 传输请求给 OceanBase 数据库时连接断开 | 10016 | An EOS event eceived while proxy transferring request | 需与 OceanBase 数据库配合诊断。 |
| ODP 传输 OceanBase 数据库回包时连接断开 | 10014 | An EOS event received while proxy reading response | 需与 OceanBase 数据库配合诊断。 |
说明
OceanBase 数据库主动断连接的场景下,ODP ��无法收集更为详细的信息,如果 ODP 配置的 OBServer 节点状态正常,则需要配合 OceanBase 数据库的日志进行诊断。
客户端主动断连接
客户端主动断连接对应的 trace_type 为 CLIENT_VC_TRACE,ODP 读请求时客户端断开连接的诊断日志示例如下:
[2023-08-10 23:28:24.699168] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="CLIENT_VC_TRACE", connection_diagnosis={cs_id:838860807, ss_id:26, proxy_session_id:7230691830869983239, server_session_id:3221698209, client_addr:"10.10.10.1:44701", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10010, error_msg:"An EOS event received from client while obproxy reading request", request_cmd:"COM_SLEEP", sql_cmd:"COM_END"}{vc_event:"VC_EVENT_EOS", total_time(us):57637, user_sql:""})
额外诊断信息有如下三条。
-
vc_event:表示断连接相关的事件,您无需太过关注
-
total_time:表示请求执行时间
-
user_sql:表示用户请求
客户端主动断连接有如下几种场景。
| 场景 | 错误码 | 错误信息 | 解决方法 |
|---|---|---|---|
| ODP 收发包时客户端发生断连接 | 10010 | An EOS event received from client while obproxy reading request | 需客户端配合诊断。 |
| ODP 处理请求时客户端断连接 | 10011 | An EOS event received from client while obproxy handling response | 需客户端配合诊断。 |
| ODP 回包时客户端发送断连接 | 10012 | An EOS event received from client while obproxy transferring response | 需客户端配合诊断。 |
说明
客户端断连接的场景下,ODP 无法收集更为详细的信息,只能指出客户端方面主动断开连接的操作。比较常见的断连接问题有驱动超时主动断开连接、Druid / Hikaricp / Nginx 等中间件主动断连接、网络抖动等问题,具体情况可与客户端配合诊断。
ODP 或 OceanBase 数据库内部错误
ODP 内部错误对应的 trace_type 为 PROXY_INTERNAL_TRACE,OceanBase 数据库内部错误对应的 trace_type 为 SERVER_INTERNAL_TRACE。ODP 内部错误的诊断日志示例如下:
[2023-08-10 23:26:12.558201] [32339][Y0-00007F74C9A244E0] [CONNECTION](trace_type="PROXY_INTERNAL_TRACE", connection_diagnosis={cs_id:838860805, ss_id:0, proxy_session_id:7230691830869983237, server_session_id:0, client_addr:"10.10.10.1:44379", server_addr:"", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10019, error_msg:"OBProxy reached the maximum number of retrying request", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{user_sql:"USE `ý<8f>ý<91>ý<92>`"})
额外诊断信息为 user_sql,表示用户请求 SQL。
ODP 或 OceanBase 数据库内部错误有如下几种场景。
| 诊断类型 | 场景 | 错误码 | 错误信息 | 解决方法 |
|---|---|---|---|---|
| PROXY_INTERNAL_TRACE | 租户分区信息查询失败 | 4664 | dummy entry is empty, disconnect | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| PROXY_INTERNAL_TRACE | ODP 部分内部请求执行失败 | 10018 | proxy execute internal request failed, received error resp, error_type: xxx | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| PROXY_INTERNAL_TRACE | ODP 重试请求达上限 | 10019 | OBProxy reached the maximum number of retrying request | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| PROXY_INTERNAL_TRACE | ODP 目标 Session 被关闭 | 10001 | target session is closed, disconnect | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| PROXY_INTERNAL_TRACE | 其他未预期的错误场景 | 10001 | 诊断信息为空 | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| SERVER_INTERNAL_TRACE | CheckSum 校验出错 | 10001 | ora fatal error | 未预期错误场景,您可联系技术支持人员协助排查或在开源官网 问答区 提问。 |
| SERVER_INTERNAL_TRACE | 主备库切换场景 | 10001 | primary cluster switchover to standby, disconnect | 主备库�切换过程中可能存在的断连接问题,符合预期的场景。 |
其他场景
除上述场景外,诊断日志中还会存在如下两种符合预期的场景,对应的 trace_type 为 PROXY_INTERNAL_TRACE。
| 场景 | 错误码 | 错误信息 | 备注 |
|---|---|---|---|
| kil 当前会话 | 5065 | connection was killed by user self, cs_id: xxx | 符合预期的场景,诊断日志作记录。 |
| kill 其他会话 | 5065 | connection was killed by user session xxx | 符合预期的场景,诊断日志作记录。 |
诊断日志示例如下,额外诊断信息为 user_sql,表示用户请求 SQL。
[2023-08-10 23:27:15.107427] [32339][Y0-00007F74CAAE84E0] [CONNECTION](trace_type="PROXY_INTERNAL_TRACE", connection_diagnosis={cs_id:838860806, ss_id:21, proxy_session_id:7230691830869983238, server_session_id:3221695443, client_addr:"10.10.10.1:44536", server_addr:"10.10.10.1:21100", cluster_name:"undefined", tenant_name:"sys", user_name:"", error_code:-5065, error_msg:"connection was killed by user self, cs_id: 838860806", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{user_sql:"kill 838860806"})
示例
客户端请求到 OceanBase 数据库的链路比较常见的有下图两种。
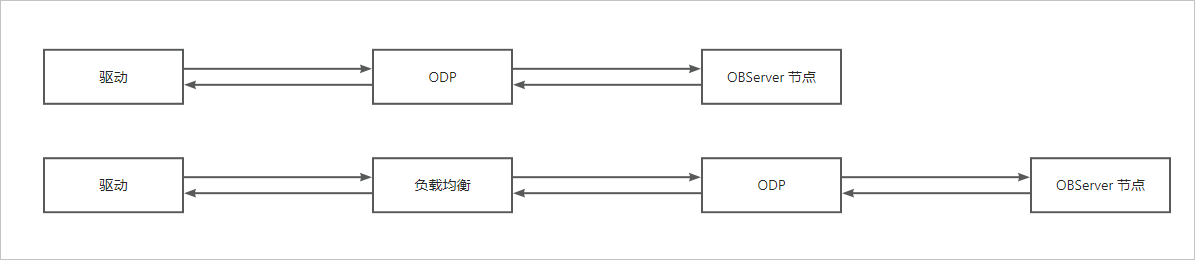
客户端的请求到 OceanBase 数据库之间的链路需要经过多个节点,任一节点出现问题都有可能会导致客户端的连接断开。所以当发生断连接且客户端没有收到明确的错误包提示断连接原因时,排查断连接问题需先确定断连接方,之后再根据断连接方对应排查断连接原因。具体操作如下。
步骤一:确定断连接方
如果当前使用的 ODP 具备连接诊断能力,可通过诊断日志 obproxy_diagnosis.log 快速判断出现断连接问题的一方。您可根据用户名、租户名、集群名、从驱动中拿到的 thread_id(对应日志 cs_id)、断连接时间等信息从日志中快速筛选出对应的断连接日志,根据 trace_type 字段判��断断连接方,trace_type 字段和断连接方的对应情况如下。
-
CLIENT_VC_TRACE:客户端断连接
-
SERVER_VC_TRACE:OceanBase 数据库主动断开连接
-
SERVER_INTERNAL_TRACE:OceanBase 数据库内部错误
-
PROXY_INTERNAL_TRACE:ODP 内部错误
-
LOGIN_TRACE:登录失败
-
TIMEOUT_TRACE:执行超时
步骤二:排查断连接原因
根据不同的断连接方,有如下几种不同的排查方法。
客户端断连接
JDBC 默认的 socketTimeout 配置为 0,即不会产生 socketTimeout 超时,但是部分客户端比如 Druid/MyBatis 自身有控制 socketTimeout 的参数,如果发生请求执行时间过长导致的断连接,可以优先确认 socketTimeout 的配置,详细信息可参见 OceanBase 数据库文档 数据库连接池配置。
-
查看对应的 ODP 连接诊断日志,确定断连接的基本信息。
[2023-09-07 15:59:52.308553] [122701][Y0-00007F7071D194E0] [CONNECTION](trace_type="CLIENT_VC_TRACE", connection_diagnosis={cs_id:524328, ss_id:0, proxy_session_id:7230691833961840700, server_session_id:0, client_addr:"10.10.10.1:38877", server_addr:"10.10.10.2:50110", cluster_name:"ob1.changluo.cc.10.10.10.2", tenant_name:"mysql", user_name:"root", error_code:-10011, error_msg:"An unexpected connection event received from client while obproxy handling request", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{vc_event:"VC_EVENT_EOS", total_time(us):5016353, user_sql:"select sleep(20) from dual"})主要诊断信息如下。
-
trace_type: 示例中诊断类型为
CLIENT_VC_TRACE,可判断出是客户端主动断开的连接。 -
error_msg : 示例中错误信息为
An unexpected connection event received from client while obproxy handling request,可判断出客户端在 ODP 处理请求时断开连接。 -
total_time: 示例中请求执行时间为
5016353,表示请求总的执行时间为 5s 左右,可以通过 total_time 去匹配客户端的超时参数。
-
-
根据 ODP 连接诊断日志信息确定是客户端主动断开了连接,从客户端入手排查,查看 JDBC 堆栈。
The last packet successfully received from the server was 5,016 milliseconds ago.
The last packet sent successfully to the server was 5,011 milliseconds ago.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1129)
at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3720)
at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3609)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4160)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2819)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2768)
at com.mysql.jdbc.StatementImpl.execute(StatementImpl.java:949)
at com.mysql.jdbc.StatementImpl.execute(StatementImpl.java:795)
at odp.Main.main(Main.java:12)
Caused by: java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:170)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:114)
at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:161)
at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:189)
at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3163)
at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3620)
9 more从堆栈以及收发包时间可大致判断出示例中为 socketTimeout 触发的问题。
ODP 断连接
ODP 会读取 OceanBase 数据库设置的 net_write_timeout 配置,控制收包和发包时传包的超时时间,该配置默认时间为 60s。当网络环境比较极端或者 OceanBase 数据库回包处理较慢时,可能会出现 ODP 等待回包数据超时断连接的问题。此处以 ODP 等待回包数据超时场景为例介绍如何排查断连接原因。
根据 ODP 断连接诊断日志判断断连接方。
[2023-09-08 01:22:17.229436] [81506][Y0-00007F455197E4E0] [CONNECTION](trace_type="TIMEOUT_TRACE", connection_diagnosis={cs_id:1031798827, ss_id:342, proxy_session_id:7230691830869983244, server_session_id:3221753829, client_addr:"10.10.10.1:34901", server_addr:"10.10.10.1:21102", cluster_name:"undefined", tenant_name:"mysql", user_name:"root", error_code:-10022, error_msg:"OBProxy inactivity timeout", request_cmd:"COM_QUERY", sql_cmd:"COM_QUERY"}{timeout(us):6000000, timeout_event:"CLIENT_NET_WRITE_TIMEOUT", total_time(us):31165295})
主要诊断信息如下。
-
trace_type: 示例中诊断类型为
TIMEOUT_TRACE, 可判断出是因为 ODP 执行超时导致断连接。 -
timeout_event: 示例中超时事件为
CLIENT_NET_WRITE_TIMEOUT,可判断出 ODP 因为等待回包数据超时而发生断连接。
根据诊断信息可以确定触发了 net_write_timeout,客户端连接等待数据超过 6s(非默认值),导致连接断开,通过修改系统变量延长超时限制可暂时规避。
登录失败
此处以两种场景介绍如何排查断连接原因。
-
以 rootservice_list 指定的 OBServer 节点不可用为例介绍如何排查断连接原因,连接诊断日志如下。
[2023-09-08 10:37:21.028960] [90663][Y0-00007F8EB76544E0] [CONNECTION](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:1031798785, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"10.10.10.1:44018", server_addr:"*Not IP address [0]*:0", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-10018, error_msg:"fail to check observer version, empty result", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:"SELECT ob_version() AS cluster_version"})主要诊断信息如下。
-
trace_type:示例中诊断类型为
LOGIN_TRACE,可确定是登录失败的问题。 -
internal_sql:示例中 ODP 当前执行的内部请求为
SELECT ob_version() AS cluster_version,可确定登录过程中 ODP 执行该内部请求失败。 -
error_msg:示例中错误信息为
fail to check observer version, empty result,可确定内部请求失败的原因为结果集为空。
诊断信息总结即为:ODP 执行内部请求
SELECT ob_version() AS cluster_version失败,结果集为空。SELECT ob_version() AS cluster_version这条 SQL 是 ODP 查询集群版本的请求,在您首次登录时 ODP 会执行这条请求校验集群信息,当 ODP 启动时配置的 rootservice_list 错误或者 OBServer 节点宕机时,ODP 查询失败,便会导致登录失败。 -
-
以客户端连接达到 ODP 上限为例介绍如何排查断连接原因。
客户端连接达到 ODP 上线导致断连接有如下两种排查方法。
-
方法一:排查连接诊断日志。
[2023-09-08 11:19:26.617385] [110562][Y0-00007FE1F06AC4E0] [CONNECTION](trace_type="LOGIN_TRACE", connection_diagnosis={cs_id:1031798805, ss_id:0, proxy_session_id:0, server_session_id:0, client_addr:"127.0.0.1:40004", server_addr:"*Not IP address [0]*:0", cluster_name:"undefined", tenant_name:"sys", user_name:"root", error_code:-5059, error_msg:"Too many sessions", request_cmd:"COM_SLEEP", sql_cmd:"COM_LOGIN"}{internal_sql:""})主要诊断信息如下。
-
trace_type:示例中诊断类型为
LOGIN_TRACE,可确定是登录失败的问题。 -
error_msg:示例中错误信息为
Too many session,可确定是因为连接数达到上限导致登录失败。
-
-
方法二:直接根据错误包判断,执行连接命令,输出
Too many sessions。$ obclient -h127.0.0.1 -P2899 -uroot@sys -Dtest -A -c
ERROR 1203 (42000): Too many sessions
-