存储引擎背景知识
在收集大家对进阶教程建议的过程中,有非常多用户希望能够更进一步了解相对深入一些的背景知识,以及关键技术的实现原理。因此专门在这里增加了一个小节,为大家简单介绍 OceanBase 的存储引擎的架构、编码压缩技术,以及几种降低编码对查询性能影响的能力。
本文中标红的内容,均为用户在使用 OceanBase 进行测试和生产过程中容易被忽略的问题,且忽略后往往可能会造成严重影响。希望大家能够重点关注。
OceanBase 的存储引擎架构
历史归档库一般都是写多读少的场景,OceanBase 的 LSM-Tree 存储引擎天生具有高效的写入性能。而且既能够通过旁路导入高效处理定期的批量数据同步,又能够承载一些实时数据同步和历史库数据修改的场景。
OceanBase 的存储引擎基于 LSM-Tree 架构,将数据分为基线数据(放在基线 SSTable 中)和增量数据(放在 MemTable / 转储的 SSTable 中)两部分。其中基线数据是只读的,一旦生成就不再被修改;增量数据支持读写。
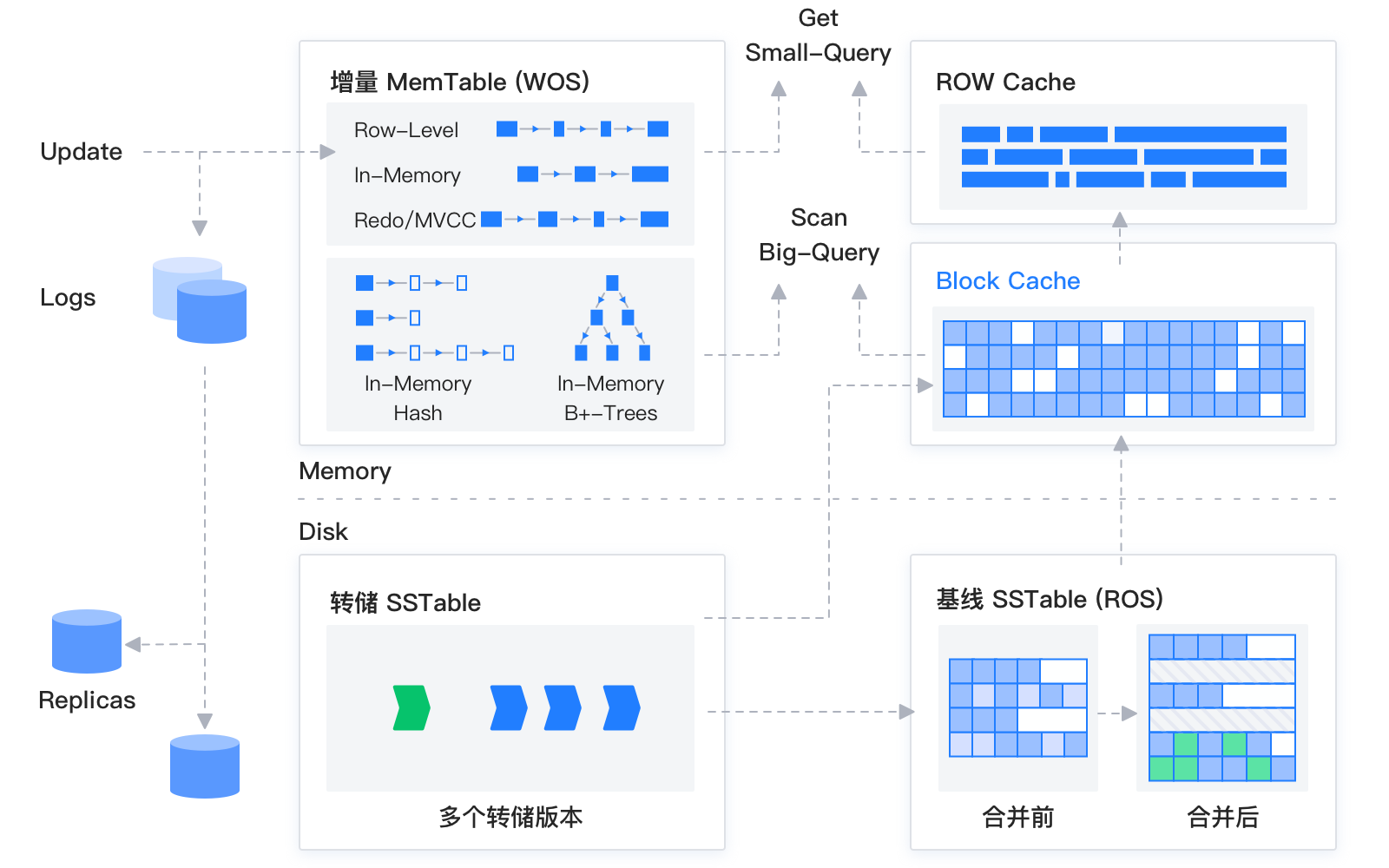
OceanBase 数据库的 DML 操作插入、更新、删除等操作,首先写入内存里的 MemTable,所以在写入性能上就相当于内存数据库的写入性能,超级适合历史归档库写多读少的场景。
等到 MemTable 达到一定大小时转储到磁盘成为增量的 SSTable(上图中的转储 SSTable 部分),转储到磁盘上的过程是批量的顺序写,相比 B+ 树架构离散的随机写,还会大大提高写盘的性能。
当增量的 SSTable 达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据和基线数据做一次整合,基线数据在合并完成之后就不会发生变化了,直到下一次合并。同时每天凌晨的业务低峰期,系统也会自动进行每日合并。
但是 LSM-Tree 的架构也存在一个问题,就是读放大(上图中的右侧箭头向上的部分)。在进行查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行一次归并,然后再将归并后的查询结果返回 SQL 层。OceanBase 为了减小读放大带来的影响,在内存实现了多级的缓存,例如 Block Cache 和 Row cache,来避免对基线数据频繁的进行随机读。
对于历史库数据的定期跑批报表,和一些 ad-hoc 的分析型查询带来的大量数据扫描的需求,因为历史库中的增量数据较少,所以绝大多数数据都存储在基线的 SSTable 中,这时计算下推可以只扫描基线数据,绕过了 LSM Tree 架构常见的读放大问题。而且 OceanBase 支持在压缩数据上执行下推算子和向量化解码的压缩格式可以轻松地处理大量数据查询和计算。
对于大量历史数据存储的需求, OceanBase 的 SSTable 存储格式和数据编码压缩功能可以使 OceanBase 更轻松地支持超大容量的数据存储。而且高度压缩的数据和在同等硬件下更高效的查询性能也能够大幅度降低存储和计算的成本。
此外,企业可以选择将历史库所在的集群部署在更经济的硬件上,但是对数据库进行运维基本不需要感知数据编码与压缩的相关配置,应用开发也可以做到在线库和历史库使用完全相同的访问接口,简化应用代码和架构。
这些特点让越来越多的企业开始在历史库场景使用 OceanBase 进行降本增效的实践。OceanBase 也将继续不断在存储架构,降本增效方面做出更多的探索。
OceanBase 的数据压缩技术
OceanBase 支持无需感知数据特征的通用压缩 (compression) 和感知数据特征并按列进行压缩的数据编码 (encoding)压缩。这两种压缩方式是正交的,也就是说,可以对一个数据块先进行编码压缩,然后再进行通用压缩,以此来实现更高的压缩率。
OceanBase 中的通用压缩是在不感知微块内部数据格式的前提下,将整个微块通过通用压缩算法进行压缩,依赖通用压缩算法来检测并消除微块中的数据冗余。目�前 OceanBase 支持用户选择 zlib、 snappy、 zstd、 lz4 算法进行通用压缩。用户可以根据表的应用场景,通过 DDL 对指定表的通用压缩算法进行配置和变更。
说明:微块的概念和传统数据库的 page / block 的概念比较类似。但是借助 LSM-Tree 的特性,OceanBase 数据库的微块是做过压缩的且在压缩后是变长的数据块,微块的压缩前大小可以通过建表的时候指定 block_size 来确定。(是不是终于知道 show create table 时显示的 block_size 是啥含义了~)
这里要注意的一点是:如果把 block_size(默认是 16KB)设置成更大的数值,虽然肯定可以让压缩的效果变的更好,但是因为微块是数据文件读 IO 的最小单位,所以可能会在一定程度上影响读性能(不过当需要读微块中的一行数据时,只会对这一行数据进行解码,在一定程度上可以避免部分解压算法读一部分数据要解压整个数据块的计算放大)。而且如果微块被设置成很大的数值,在合并时就无法重用有数据更新的微块,而需要对微块进行重写,进而影响合并速度。 总之,调整 block_size 的大小有利有弊,请大家根据实际业务情况,一定要在了解 block_size 含义和影响的基础上,再对其进行修改!(建议最好不改,直接使用默认值~)
由于通用压缩后的数据块在读取进行扫描前需要对整个微块进行解压,会消耗一定 CPU 并带来 overhead。为了降低解压数据块对于查询性能的影响,OceanBase 将解压数据的动作交给异步 I/O 线程来进行,并按需将解压后的数据块放在 block cache 中。这样结合查询时对预读(prefetching)技术的应用,可以为查询处理线程提供数据块的流水线,消除解压带来的额外开销。
编码压缩技术
-
当通过一列数据存储城市、性别、产品分类等具有类型属性的值时,这些列数据块内部数据的基数(cardinality)也会比较小,这时数据库可以直接在用户数据字段上建立字典,来实现更高的压缩率;
-
当数据按时序插入数据库,这些插入的数据行中的时间相关字段、自增序列等数据的值域会相对较小,也会有单调递增等特性,利用这些特性,数据库可以更方便地为这些数据做 bit-packing、差值等编码。
为了实现更高的压缩比,帮助用户大幅降低存储成本, OceanBase 设计了多种编码算法,最终在 OceanBase 的负载上实现了很好的压缩效果。 OceanBase 根据实际业务场景需求实现了单列数据的 bit-packing 编码、字符串 HEX 编码、字典编码、 RLE 编码、常量编码、数值差值编码、定长字符串差值编码,同时,创新地引入了列间等值编码和列间子串编码,能够分别对数据库中一列数据或几列数据间可能产生的不同类型数据冗余进行压缩。
降低存储的位宽:Bit-packing 和 HEX 编码
Bit-packing 和 HEX 编码类似,都是在压缩数据的基数较小时,通过更小位宽的编码来表示原数据。而且这两种编码可以与其他编码叠加,对于其他编码产生的数值或字符串数据,都可以再通过 bit-packing 或 HEX 编码进一步去除冗余。
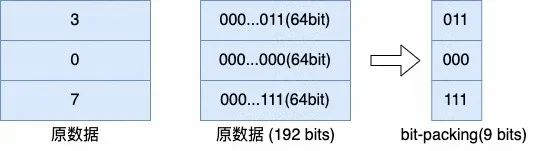
(bit-packing)
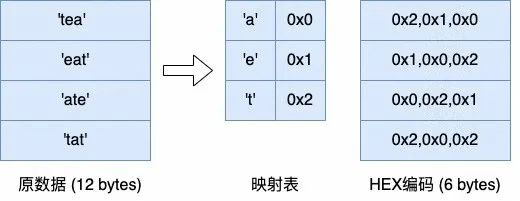
(HEX 编码)
单列数据去重:字典编码和 RLE 编码等
字典编码则可以通过在数据块内建立字典,来对低基数的数据进行压缩。当低基数的数据在微块内的分布符合对应的特征时,也可以使用游程编码 / 常量编码等方法进行进一步的压缩。
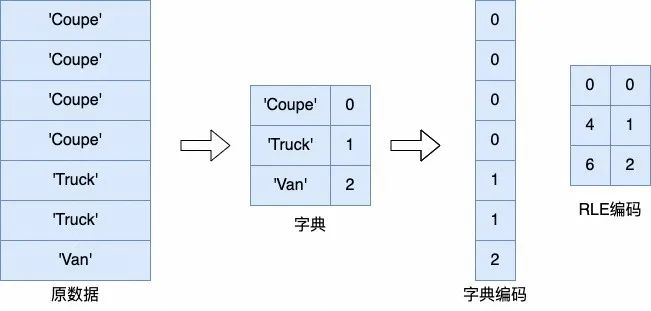
(字典编码 / RLE 编码)
说明:上图中最右侧 RLE(Run-Length Encoding,游程长度编码)编码里的第一列数据 0、4、6 是指左边字典编码中 0、1、2 第一次出现时各自的初始下标,适用于存在大量连续重复数据的场景。
利用数据的值域压缩:差值编码等
差值编码也是常用的编码方法, OceanBase 中的差值编码分为数值差值编码和定长字符串差值编码。数值差值编码主要用来对值域较小的数值类数据类型进行压缩。对于日期、时间戳等数据,或其他临近数据差值较小的数值类数据,可以只存储最小值,每行存储原数据与最小值的差值。定长字符串编码则可以比较好地对人工生成的 ID,如订单号/身份证号、url 等有一定模式的字符串进行压缩,对一个微块的数据存储一个模式串,每行额外存储与模式串不同的子串差值,来达到更好的压缩效果。
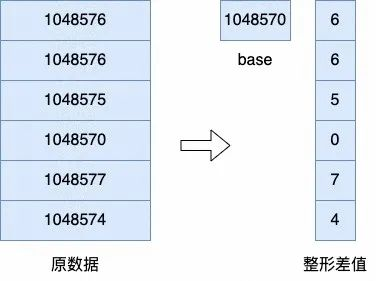
(整形差值)
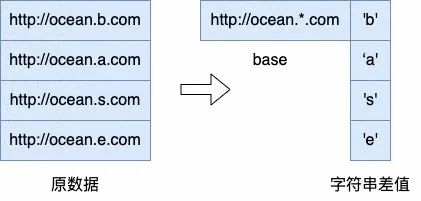
(字符串差值)
减小多列数据冗余:列间编码
为了利用不同列间数据的相似性增强压缩效果,OceanBase 引入了列间编码。通常情况下,列存数据库只会对数据在列内部进行编码,但在实际应用中有很多表除了同一列数据之间存在相似性,不同列的数据之间也可能有一定的关系,利用这种关系可以通过一列数据表示另外一列数据的部分信息。
列间编码可以对复合列、系统生成的数据做出更好的压缩,也能够降低在数据表设计范式上的问题导致的数据冗余。
说明:一般列间编码会被用于两列数据有特定的关系,例如两列间大部分数据都是等值关系,或者大部分数据有前缀关系或者子串关系时,系统会选择列间编码。
自适应压缩技术
自适应压缩技术,也就是让数据库系统自动选择最优的编码算法。
数据编码的压缩效果不仅与表的 schema 相关,同时还与数据的分布,微块内数据值域等数据本身的特征相关,这也就意味着比较难以在用户设计表数据模型时指定列编码来实现最好的压缩效果。
为了减轻用户的使用负担,也为了实现更好的压缩效果,OceanBase 支持在合并过程中分析数据类型、值域、NDV 等特征,结合 compaction 任务中上一个微块对应列选择的编码算法和压缩率自适应地探测合适的编码,对同一列在不同数据块中支持使用不同的算法来进行编码,也保证了选择编码算法的开销在可接受的区间内。
降低数据编码对查询性能影响的能力
为了能够更好地平衡压缩效果和查询的性能,我们在设计数据编码格式时也考虑到了对查询性能带来的影响。
行级粒度数据随机访问
通用压缩中,如果要访问一个压缩块中的一部分数据,通常需要将整个数据块解压后访问。某些其他的分析型系统的数据编码大多面向扫描的场景,点查的场景比较少,因��此采用了在访问某一行数据时,需要对相邻数据行,甚至数据库内的所有行进行解码的方式。
而 OceanBase 需要更好地支持事务型负载,这就意味着要支持相对更高效的点查。因此 OceanBase 在设计数据编码格式时保证了编码后的数据是可以以行为粒度随机访问的。也就是在对某一行进行点查时只需要对这一行相关的元数据进行访问并解码,减小了随机点查时的计算放大。同时对于编码格式的微块,解码数据所需要的所有元数据都存储在微块内,让数据微块有自解释的能力,也在解码时提供了更好的内存局部性。
说明:可以简单理解为在点查时,支持对单行数据进行解码,无需对整个微块进行解码。
计算下推
由于编码数据中会存储对应的有序字典、 null bitmap、常量等可以描述数据分布的元数据,在扫描数据时可以利用这些数据对于部分过滤、聚合算子的执行过程进行优化,从而实现在未解码的数据上直接进行计算的能力。
OceanBase 对分析处理能力进行了大幅的优化,其中包括聚合与过滤计算下推到存储层执行,和在向量化引擎中利用编码数据的列存特征进行向量化的批量解码等特性。
在查询时充分利用了编码元数据和编码数据列存储的局部性,在编码数据上直接进行计算,大幅提高了下推算子的执行效率和向量化引擎中的数据解码效率。基于数据编码的计算下推和向量化解码也成为了支持 OceanBase 高效处理分析型负载,在 TPC-H benchmark 中达到优秀性能指标的重要功能。
说明:可以简单理解为 OceanBase 对于常见的过滤条件和简单的聚合计算,无需由存储层将数据传递到 SQL 层进行计算,而是直接在存储层就可以完成计算(节省了存储层向 SQL 层吐行的开销)。在计算时,也有在未解码的数据上直接进行计算的能力(节省了解码的开销)。
编码压缩基础测试
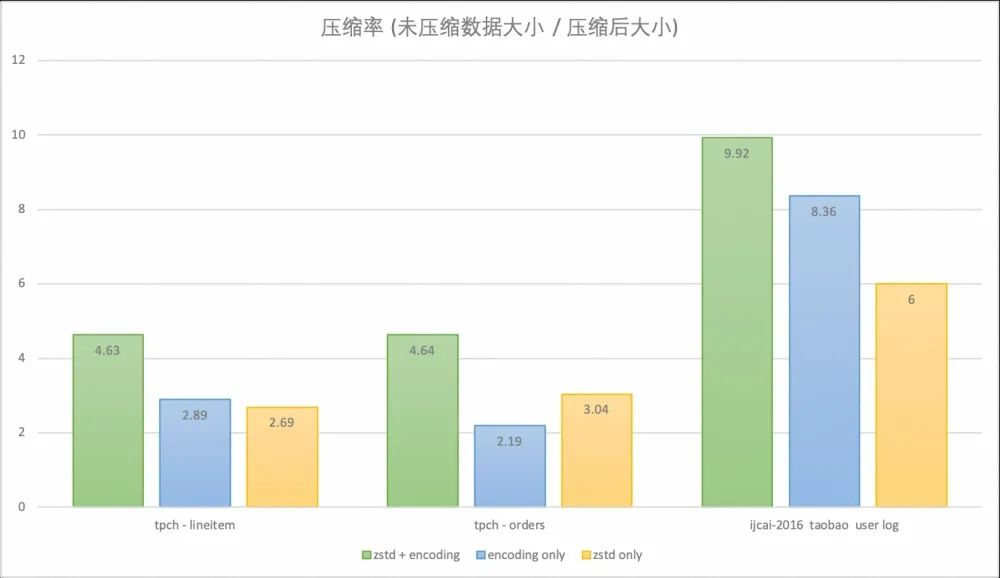
不同的压缩方式如何影响 OceanBase 的压缩效果,以下会通过一个简单的测试进行观察。
使用 OceanBase 4.0 版本分别在交易场景的 TPC-H 10g 的数据模型和用户行为日志场景的 IJCAI-16 Brick-and-Mortar Store Recommendation Dataset 数据集上对 OceanBase 的压缩率进行测试。
-
TPC-H 是对订单,交易场景的建模,对 TPC-H 模型中数据量比较大的两张表,即存储订单的 ORDERS 表和存储商品信息的 LINEITEM 表的压缩率进行统计。在 OceanBase 默认配置(zstd + encoding)下,这两张表的压缩率可以达到 4.6 左右,相较只开启 encoding 或 zstd 压缩时提升明显。
-
IJCAI-16 taobao user log 则是淘宝脱敏后的真实业务数据,存储了用户浏览商品时的行为日志。在 OceanBase 默认配置( zstd + encoding )下压缩率可以达到 9.9 ,只开启 encoding 压缩率可以达到 8.3 ,只开启 zstd 压缩率为 6.0 。