租户间资源隔离
OceanBase 数据库是多租户的数据库系统,为了确保租户间不出现资源争抢保障业务稳定运行,OceanBase 数据库针对租户间的资源进行了隔离。
所谓资源隔离,就是节点控制本地多个 Unit 间的资源分配的行为, 它是节点本地的行为。类似的技术是 Docker 和虚拟机,但 OceanBase 数据库并没有依赖 Docker 或虚拟机技术,而是在数据库内部实现资源隔离。
OceanBase 数据库中把 Unit 当作给租户��分配资源的基本单位,一个 Unit 可以类比于一个 Docker 容器。一个节点上可以创建多个 Unit,在节点上每创建一个 Unit 都会占用一部分该节点的 CPU、内存等物理资源,节点的资源分配情况会记录在内部表中以便 DBA 查看。
一个租户可以在多个节点上放置多个 Unit,但一个租户在某个节点上只能有一个 Unit。一个租户的多个 Unit 相互独立,OceanBase 数据库目前没有汇总多个 Unit 的资源占用进行全局的资源控制, 具体来讲,不会因为一个租户在某个节点上的资源没得到满足,就让它在另一个节点上去抢其它租户的资源。
OceanBase 数据库租户隔离的优势
相比 Docker 和虚拟机,OceanBase 数据库的租户隔离更加轻量,并且便于实现优先级等高级特性。 从 OceanBase 数据库的需求来看,Docker 或虚拟机的主要有以下几个问题:
-
Docker 或虚拟机运行环境的开销太重,OceanBase 数据库需要支持轻量级租户。
-
Docker 或虚拟机规格变化以及迁移开销比较大,OceanBase 数据库希望租户的规格变化和迁移尽量快。
-
Docker 或虚拟机不便于租户间的资源共享, 例如,对象池的共享。
-
Docker 或虚拟机的资源隔离很难定制,例如,租户内的优先级支持。
除此之外,Docker 或虚拟机的实现不便于暴露统一视图。
隔离效果
-
内存完全隔离。
-
SQL 执行过程各种算子使用的内存是分离的,一个租户的内存耗尽不会影响到另一个租户。
-
Block Cache 和 MemTable 是分离的,一个租户的内存耗尽不会影响到另一个租户的写入和读取。
-
-
CPU 完全隔离。
-
最基础的 CPU 隔离是通过用户态调度,控制活跃线程数来实现的。每个租户有独立的线程池,线程池的规格是由租户规格和一些配置参数来决定的。一个租户能使用的 CPU 资源是由 Unit 规格决定的。
-
为了达到更好的隔离效果,从 V4.0.0 版本开始,支持配置 cgroup 来进行 CPU 隔离。cgroup (Control Groups)是 Linux 内核提供的一种机制,这种机制可以根据特定的行为,将一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。cgroup 能对线程的 CPU 使用率进行精准的限制,达到租户之间 CPU 强隔离的效果。
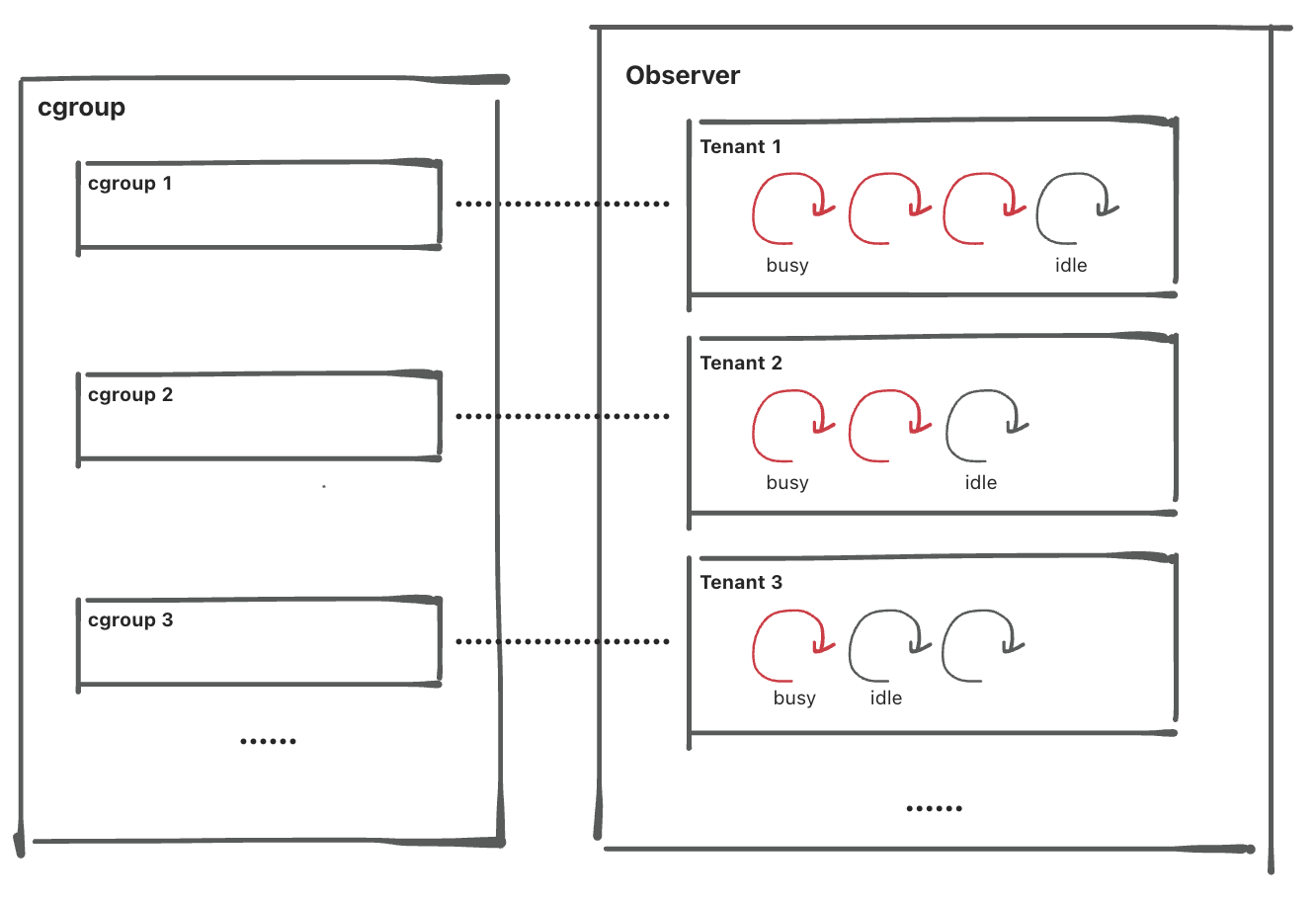
-
-
不同租户的 SQL 模块是不会互相影响的。
-
SQL 的 Plan Cache 是按租户分离的,一个租户的 Plan Cache 淘汰不会影响另一个租户。
-
SQL 的 Audit 表是分离的,一个租户的 QPS 太高,不会冲洗掉另一个租户的 Audit 信息。
-
-
不同租户的事务模块是不会互相影响的。
-
一个租户的行锁挂起,不会影响到其他租户。
-
一个租户的事务挂起,不会影响到其他租户。
-
一个租户的回放出问题,不会影响到其它租户。
-
-
不同租户的 Clog 模块是不会互相影响的。
日志�流的目录以租户为单位,最终在磁盘上的实现表现为如下:
tenant_id
├── unit_id_0
│ ├── log
│ └── meta
├── unit_id_1
│ ├── log
│ └── meta
└── unit_id_2
├── log
└── meta
资源分类
从设计上,OceanBase 数据库从 V4.0.0 版本支持租户间 CPU、Memory、IOPS 隔离,一个 Unit 可以指定 CPU、Memory、IOPS、log_disk_size 这 4 种资源。
obclient>
CREATE RESOURCE UNIT name
MAX_CPU = 1, [MIN_CPU = 1,]
MEMORY_SIZE = '5G',
[MAX_IOPS = 1024, MIN_IOPS = 1024, IOPS_WEIGHT=0,]
[LOG_DISK_SIZE = '2G'];
节点的可用 CPU
节点在启动时会探测物理机或容器的在线 CPU 个数,如果节点探测得不准确(例如在容器化环境里),也可以通过 cpu_count 配置项来指定。
由于节点会为后台线程预留两个 CPU,故实际可以分给租户的 CPU 总数会少两个。
节点的可用 Memory
节点在启动时会探测物理机或容器的内存,由于节点需要为其它进程预留一部分内存,故 observer 进程的可用内存等于 物理内存 * memory_limit_percentage。也可以通过配置项 memory_limit 直接配置 observer 进程可用的总内存大小。
observer 进程可用的内存需要进一步扣除掉内部共用模块的那一部分,这部分内存大小由配置项 system_memory 指定,剩下的内存才是租户可用的总内存。
查看每个节点的可用资源
您可��以通过 oceanbase.GV$OB_SERVERS 视图查看每个节点的可用资源,示例如下:
obclient> SELECT * FROM oceanbase.GV$OB_SERVERS\G
*************************** 1. row ***************************
SVR_IP: xx.xx.xx.xx
SVR_PORT: 57234
ZONE: zone1
SQL_PORT: 57235
CPU_CAPACITY: 14
CPU_CAPACITY_MAX: 14
CPU_ASSIGNED: 6.5
CPU_ASSIGNED_MAX: 6.5
MEM_CAPACITY: 10737418240
MEM_ASSIGNED: 6442450944
LOG_DISK_CAPACITY: 316955164672
LOG_DISK_ASSIGNED: 15569256438
LOG_DISK_IN_USE: 939524096
DATA_DISK_CAPACITY: 10737418240
DATA_DISK_IN_USE: 624951296
DATA_DISK_HEALTH_STATUS: NORMAL
DATA_DISK_ABNORMAL_TIME: NULL
1 row in set
资源隔离
内存隔离
节点的内存资源实际上不支持超卖,引入内存超卖反而会导致租户工作不稳定,从 V4.0.0 版本开始,OceanBase 数据库不再支持内存超卖。废弃 MIN_MEMORY 和 MAX_MEMORY 配置,采用 MEMORY_SIZE 参数代替。
CPU 隔离
在 OceanBase 数据库 V3.1.x 版本之前,主要通过控制线程数来控制 CPU 的占用;在 OceanBase 数据库 V3.1.x 及之后的版本,允许配置 cgroup 来控制 CPU 的占用。
线程分类
节点会启动很多不同功能的线程,本节按照最粗略的标准可以分为以下两类:
-
一类是处理 SQL 和事务提交的线程,统称为租户工作线程。
-
其余的是处理网络 IO、磁盘 IO、Compaction 以及定时任务的线程,统称为后台线程。
在当前版本,租户工作线程和大部分后台线程是分租户的,网络线程是共享线程的。
基于线程数的租户工作线程的 CPU 隔离
Unit 的 CPU 隔离是通过一个 Unit 的活跃租户工作线程数实现的。
由于 SQL 执行过程中可能会有 IO 等待、锁等待等,所以一个线程无法用满一个物理 CPU,故在缺省配置下,OBServer 节点会给每个 CPU 启动 4 个线程,4 这个倍数可以通过配置 cpu_quota_concurrency 来控制。这就意味着如果一个 Unit 的 MAX_CPU 是 10,那么它能同时运行的活跃线程是 40,最大物理 CPU 的占用是 400%。
基于 cgroup 的租户工作线程的 CPU 隔离
开启 cgroup 后最大的变化是不同租户的工作线程放到不同的 cgroup 目录内,租户间的 CPU 隔离效果会更好。最后的隔离效果如下:
-
如果一个 OBServer 上只有一个租户负载很高,其余租户比较空闲,那么这个负载高的租户的 CPU 也会受到
MAX_CPU的限制。 -
延续上面的场景,如果有多个空闲的租户的负载上升了,导致物理 CPU 不够了,cgroup 会按照权重分配时间片。
后台线程的 CPU 隔离
-
V4.0.0 版本的后台拆分了租户,每个租户下有对应的线程数控制。
-
为了更好的隔离效果,后台线程也会放到不同的 cgroup 目录内,实现租户间隔离,租户内和工作线程隔离。
大查询处理
我们认为相比于大查询,让短查询尽快返回对用户更有意义,即大查询的查询优先级更低,当大查询和短查询同时争抢 CPU 时,系统会限制大查询的 CPU 使用。
当一个线程执行的 SQL 查询耗时太长,这条查询就会被判定为大查询, 一旦判定为大查询,执行大查询的线程会等在一个 Pthread Condition 上,这样就为其它的租户工作线程让出了 CPU。
具体实现上,OBServer 节点在代码中插入了很多检查点,租户工作线程在运行过程中会通过检查点定期检查自己的状态,如果判断应该挂起,那么线程就会等待在一个 Pthread Condition 上,等到合适的时机再被唤醒。
如果同时有大查询和小查询,大查询最多占用 30% 的租户工作线程,30% 这个百分比值可以通过配置项 large_query_worker_percentage 来设置。
有两点需要说明:
-
当没有小查询的时候,大查询可以用到 100% 的租户工作线程。只有当同时有大查询和小查询时,30% 的比例才生效。
-
一个租户工作线程因为执行大查询被挂起时,作为补偿,系统可能会新创建一个租户工作线程,但是总的租户工作线程数不能超过
MAX_CPU的 10 倍,10 这个倍数可以通过配置项workers_per_cpu_quota来设置。
提前识别大查询
由于节点挂起一个大查询线程,就会启动一个新的租户工作线程, 但是如果有大量大查询涌入,OBServer 节点新创建的线程还是被用来处理大查询,很快达到租户工作线程数上限,在这批大查询消耗完之前就没有机会再处理短查询了。
为了优化这个场景,OBServer 节点会在 SQL 开始执行之前预判它��是不是大查询,预判的本质就是估计 SQL 的执行时间。预判主要依据以下假设场景:如果两条 SQL 的执行 Plan 是一样的,可以猜测它们的执行时间也是相似的,这样就可以用 Plan 最近的执行时间来判断 SQL 会不会是大查询。
如果某条 SQL 被预判为大查询,那么该查询就会被放入一个特殊的大查询队列,其线程会被释放,系统就会接着执行后面的请求了。