磁盘故障
业务及数据库表现
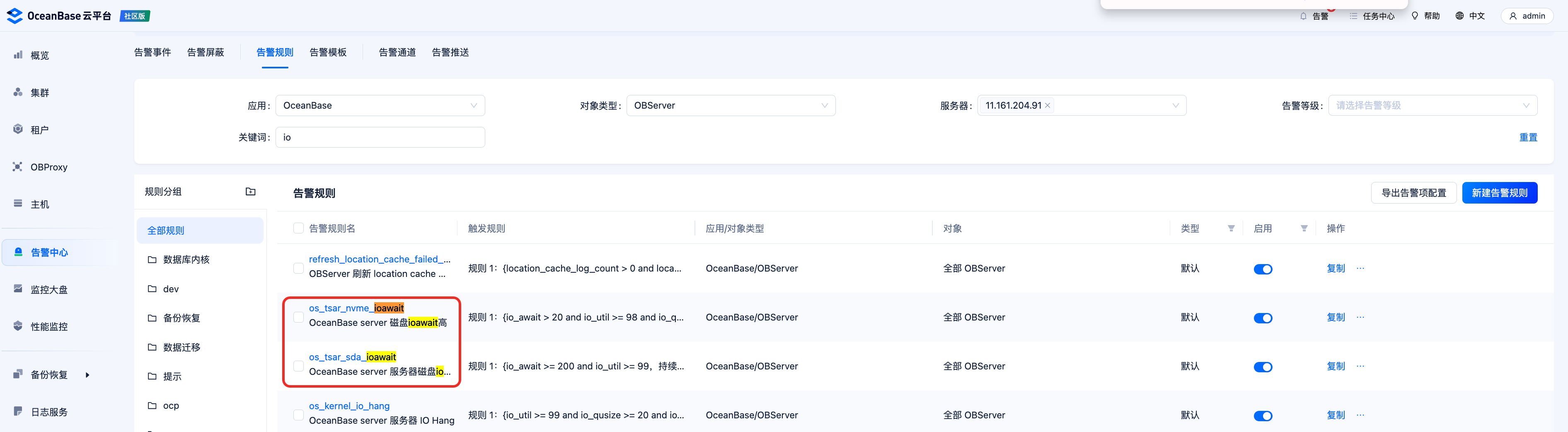
数据库没有给磁盘 IO 压力,但是 IO await 数值依然较高。
io_await 表示 I/O 请求在队列中等待处理的平均时间,可以反映 IO 的处理效率,ioawait 越低,越说明 IO 队列不拥塞。
ioawait 接近于 svctm(反映磁盘的性能,一般小于 20ms)时,说明 IO 几乎不等待。
排查方向
OCP 对于 io_await 有对应监控项 os_tsar_nvme_ioawait 和 os_tsar_sda_ioawait,在 io_await 值异常时,默认会进行监控告警。
-
如果没有过多业务流量,也没有其他进程占用磁盘 IO,一般是迁移复制、合并等因素叠加的结果。处理的思路通常是将一些高 IO 的负载任务降级。
-
如果没有��合并等消耗磁盘 IO 的任务,进一步检查是否磁盘本身的故障。一般来说,如果是掉盘等严重故障,OCP 监控的告警将会是 OBServer 不可用,而非 io_await 相关告警。
磁盘故障应急流程
流程和 “节点宕机”、“网络抖动” 大同小异,这里就不再啰嗦一遍了,大家详见前两个小节吧。
简单来说,少数派的磁盘故障:
-
直接依赖 OceanBase 的高可用机制,实现自愈。
-
一般的磁盘故障,难以在短时间内完成修复,需要在集群中添加并上线新主机。
-
在业务低峰期,把租户切主回原来配置的 zone。
多数派副本所在的节点同时出现磁盘故障的概率极低,如果不幸遇到,需要切换至备集群(第三次祭出备库)。
磁盘 IO 负载高应急流程
这种情况大概率是后台的每日合并搞的鬼,先通过 OCP 检查下系统是否处于合并状态。
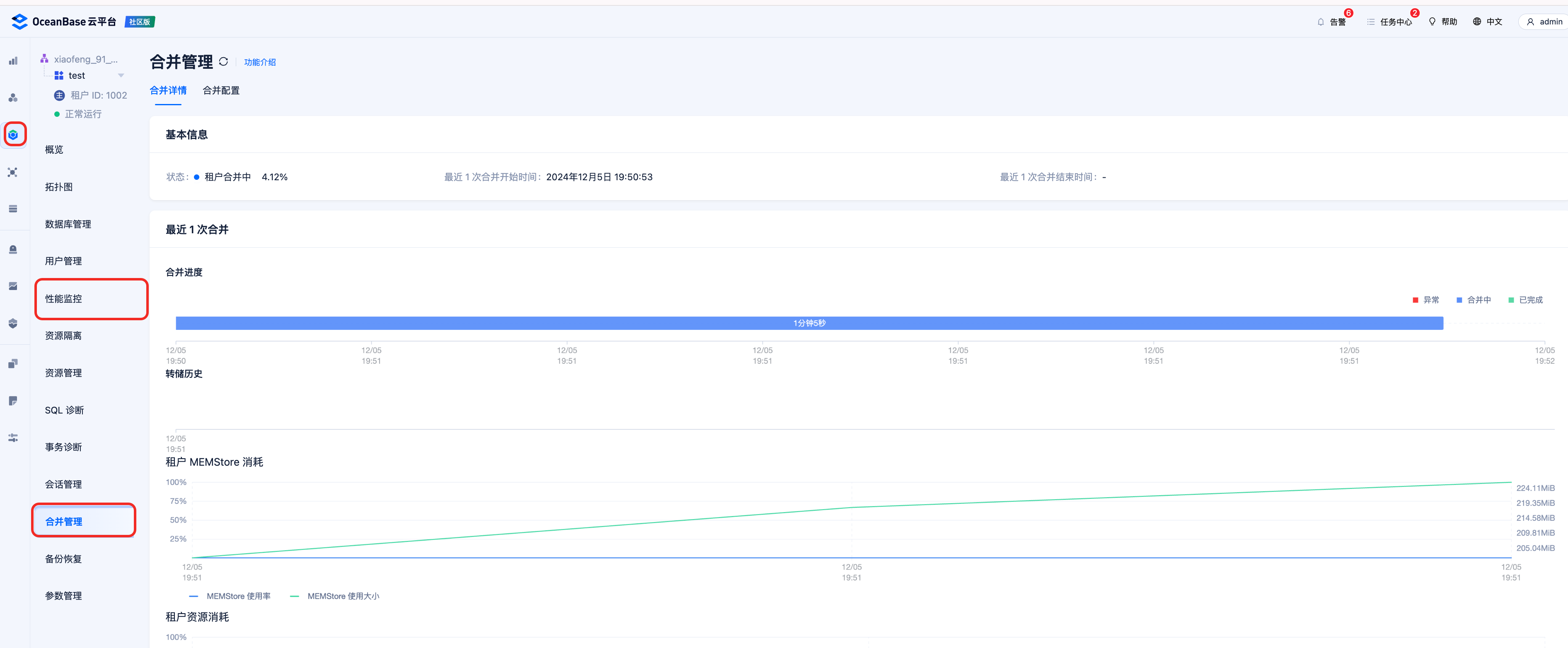
如果处于合并合并状态,可以先暂停合并,流量高峰过后再恢复合并。
-- 暂停进行中的合并
ALTER SYSTEM SUSPEND MERGE [ZONE [=] 'zone'];
-- 根据业务需求,恢复合并
ALTER SYSTEM RESUME MERGE [ZONE [=] 'zone'];
其他情况都不太常见,一般都是你自己正在执行一些类似于导数、备份之类的大任务导致的了,可以参考这篇 OceanBase 官网文档(正好可以偷点儿懒)。不过目前(2024.12.05)这篇官方文档的某些调参内容和参数介绍也许存在一些问题,调参前建议在官网上搜下这个参数的真实含义。
个人不建议用户通过手动调参的方式对合并和转储使用的资源进行限制(因为没有建议值,调完之后未必有正向的效果)。通过调整每日�合并的时间实现错峰合并,也许是更合适的方式。