Flink CDC + OceanBase integration solution for full and incremental synchronization
This article introduces OceanBase and explains the application scenarios of Flink CDC and OceanBase.
This article was compiled from the speech by Wang He (Chuanfen) (OceanBase Technical Expert) at the Flink CDC Meetup on May 21. The main contents include:
- An Introduction to OceanBase
- The Implementation Principle of Flink CDC OceanBase Connector
- The Application Scenarios of Flink CDC + OceanBase
- The Future Outlook of Flink CDC OceanBase Connector
1. An Introduction to OceanBase
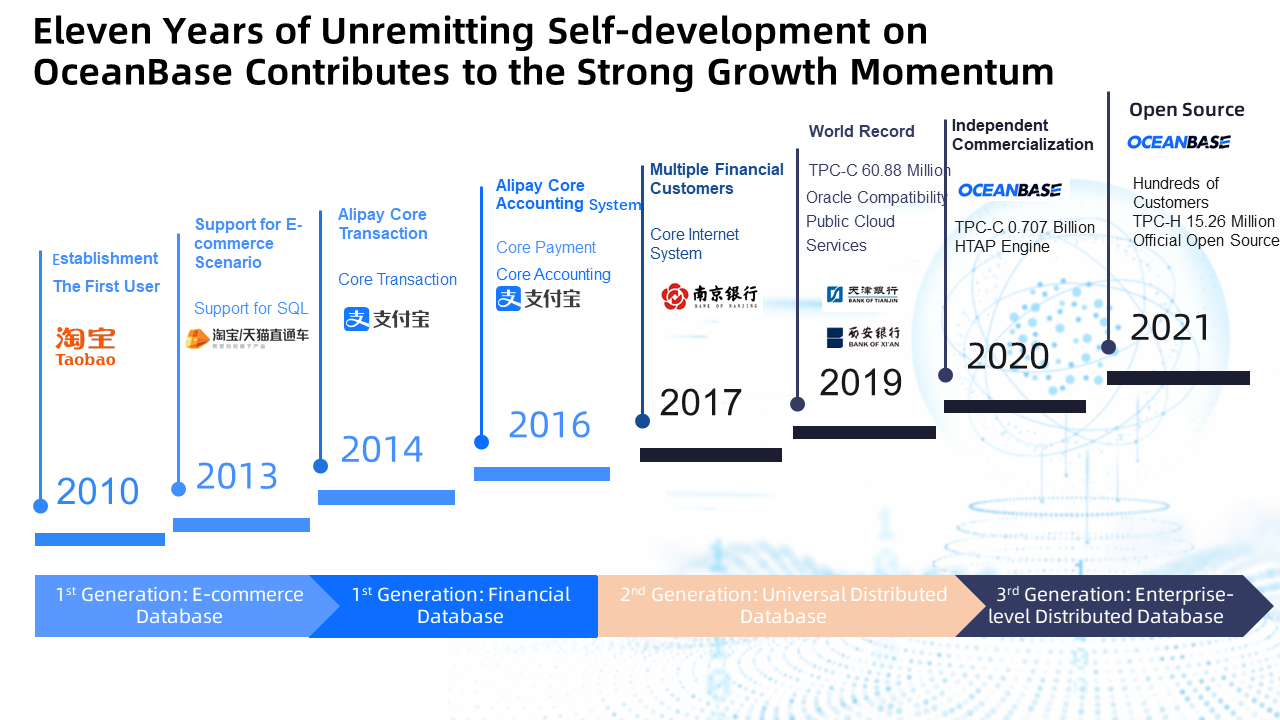
OceanBase is a distributed database developed by Ant Group. The project was established in 2010 and developed iteratively. Its earliest application is to Taobao's favorites. In 2014, the OceanBase R&D Team moved from Taobao to Ant Group, mainly responsible for Alipay's internal de-IOE work. It means replacing the Oracle database used by Alipay. Currently, all the data in Ant Group databases have been migrated to OceanBase. On June 1, 2021, OceanBase was officially opened source to the public, and a MySQL-compatible version was launched.
OceanBase has undergone three generations of architecture upgrades, including a distributed storage system initially applied to e-commerce companies, a general-purpose distributed database, and an enterprise-level distributed database.
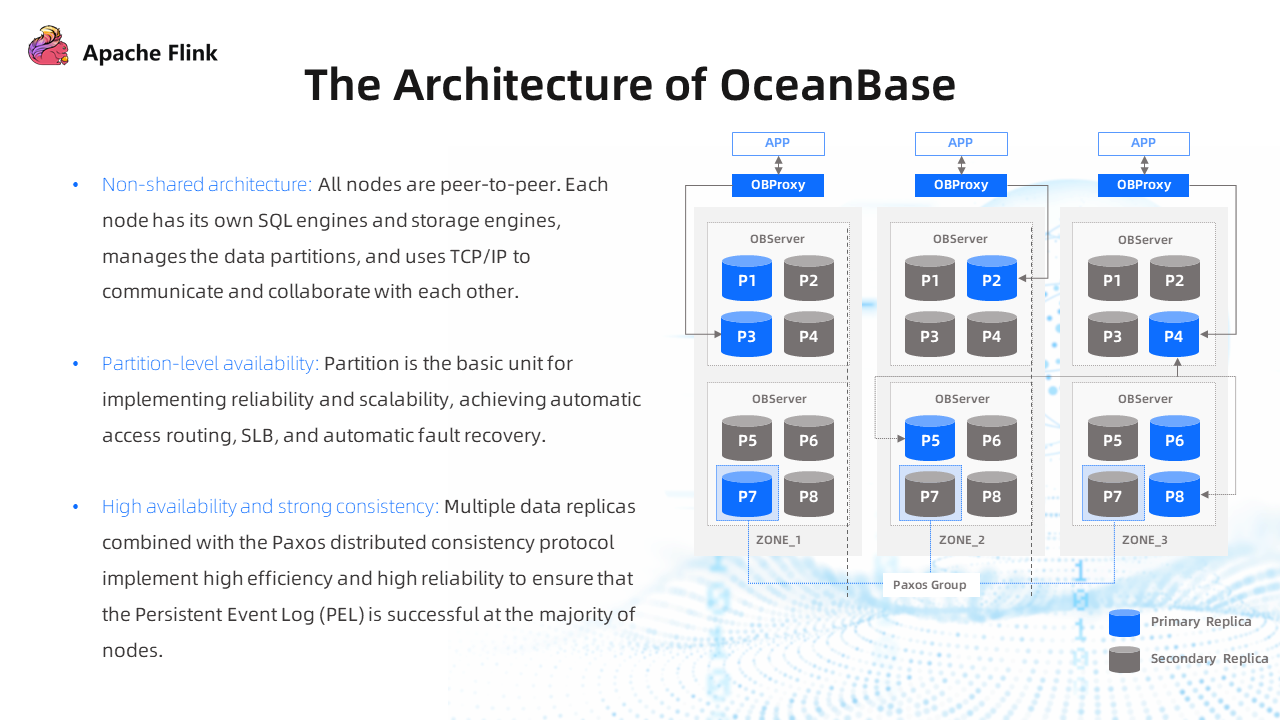
The preceding figure shows the architecture of OceanBase.
The top-level app accesses the server side of the OceanBase database through the OBProxy (SLB proxy). The data on the server side has multiple replicas. The relationship between the replicas is similar to the primary-secondary relationship in the database architecture, but it is table-level. The partition of the partition table is divided into multiple replicas at the table level and then scattered on multiple servers.
The architecture of OceanBase has the following features:
- No Shared Architecture: Each node has its complete SQL engines, storage engines, and transaction processing logic. All nodes are completely peer-to-peer, and there are no layered structures.
- Partition-Level Availability: It provides partition-level availability. The partition is the basic unit for implementing reliability and scalability, achieving access routing, SLB, and automatic fault recovery in the OceanBase database.
- High Availability and Strong Consistency: There are multiple data replicas. The consistency protocol of Paxos is used to provide high reliability between multiple replicas and ensure the Persistent Event Log (PEL) is successful at the majority of nodes.
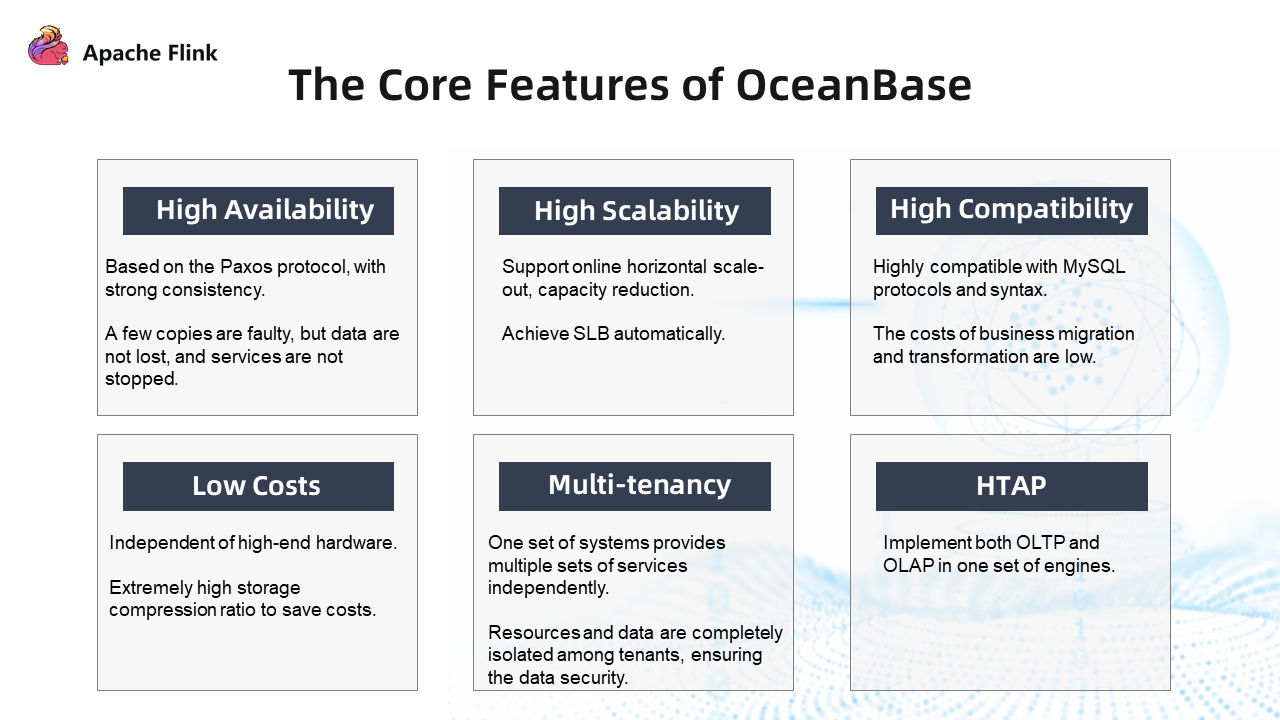
The core features of OceanBase:
- High Availability: It is based on the Paxos protocol, with strong consistency. A few copies are faulty, but data is not lost, and services are not stopped.
- High Scalability: It supports online horizontal scale-out and capacity reduction. Nodes can automatically achieve SLB.
- High Compatibility: The Community Edition is compatible with MySQL protocols and syntax.
- Low Cost: OceanBase database costs about one-third of MySQL. The storage compression ratio is extremely high because of its low hardware quality requirements and a lot of optimization of storage.
- Multi-Tenancy: Resources are completely isolated between tenants. Different service parties only need to manage data in their tenants, which can save costs.
- HTAP: It implements both OLTP and OLAP in one set of engines.
2. The Implementation Principle of Flink CDC OceanBase Connector
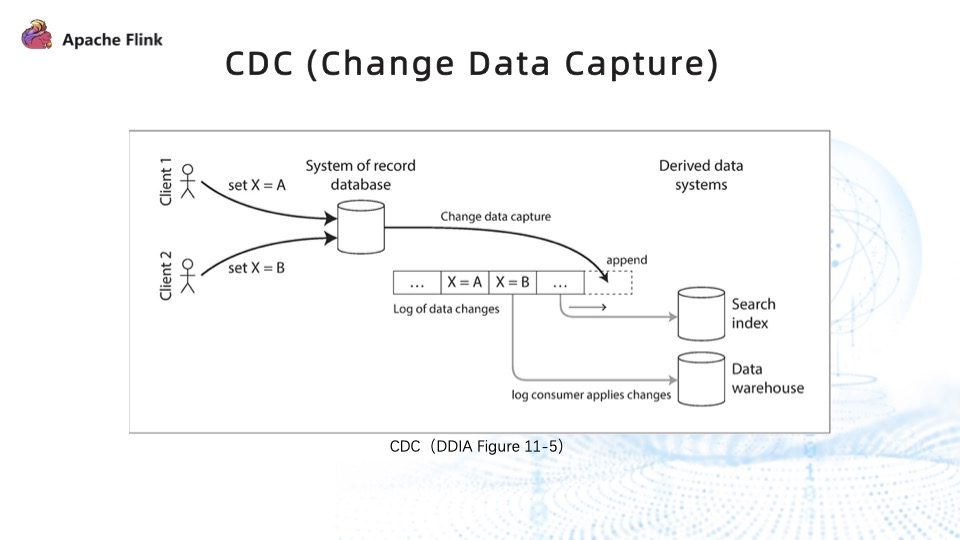
The current mainstream CDC mainly relies on the logs of the database. After capturing the incremental logs of the database, it is necessary to ensure their orderliness and integrity, process the logs, and write them to the destination, such as a data warehouse or query engine.

OceanBase provides some components for capturing incremental data. It is a distributed database, so its data is scattered when it falls into the log. It provides an obcdc component for capturing database logs. It interacts with the OceanBase Server through RPC to capture the original log information. After processing, an orderly log flow can be spit out, and the downstream can consume the orderly log flow by accessing the obcdc component.
There are currently three major downstream consumers:
- Oblogproxy: An open-source component that is used to consume log flows. Flink CDC relies on this component to capture incremental data.
- OMS Store: The data migration service provided by OceanBase. The commercial version of OMS has been upgraded in many iterations and supports many data sources. Last year, OMS supported the community edition of the two data sources, OceanBase and MySQL.
- JNI Client: You can directly use obcdc to interact with OBSserver to capture incremental logs. This downstream consumer is under an open-source plan.
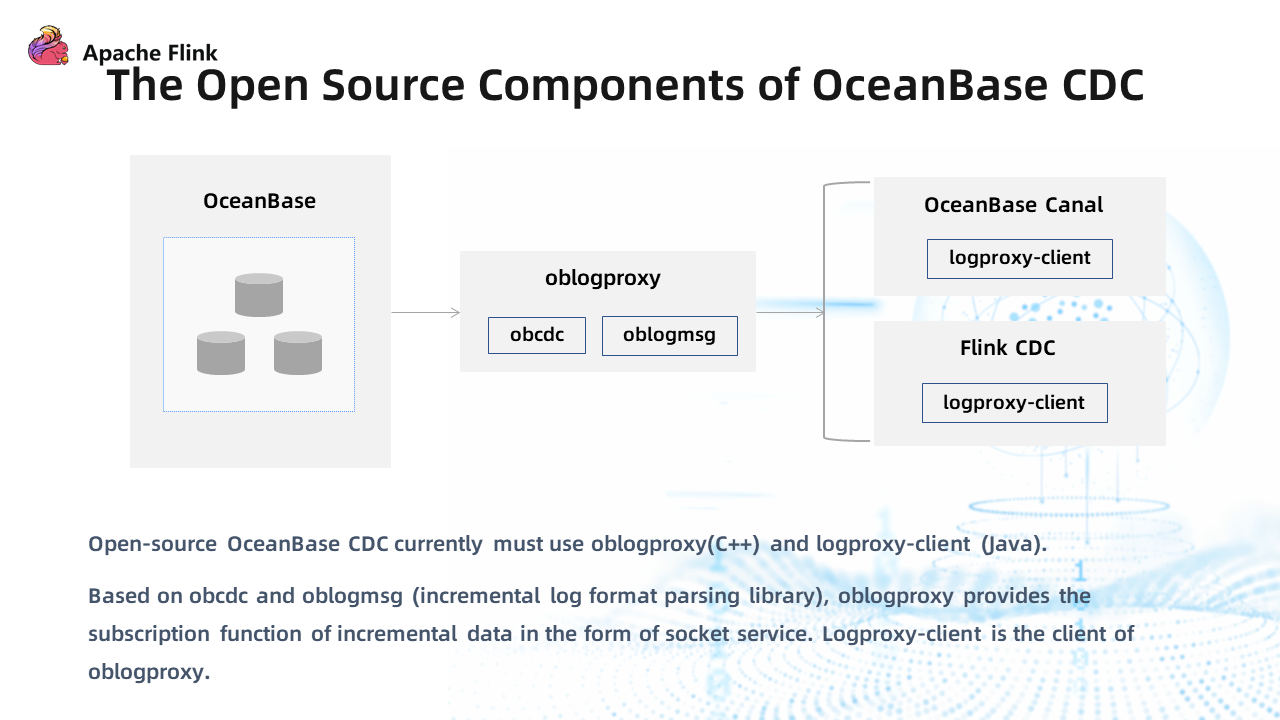
Currently, there are two OceanBase CDC components provided by the Open-Source Community:
- OceanBase Canal: Canal is an open-source tool of Alibaba for capturing MySQL incremental logs. OceanBase community strengthens the ability to capture and parse incremental logs based on the latest code of Canal in the open-source edition.
- Flink CDC: Flink CDC uses obcdc through oblogproxy to capture incremental logs from OceanBase and then uses another open-source component logproxy-client to consume incremental logs and process them.
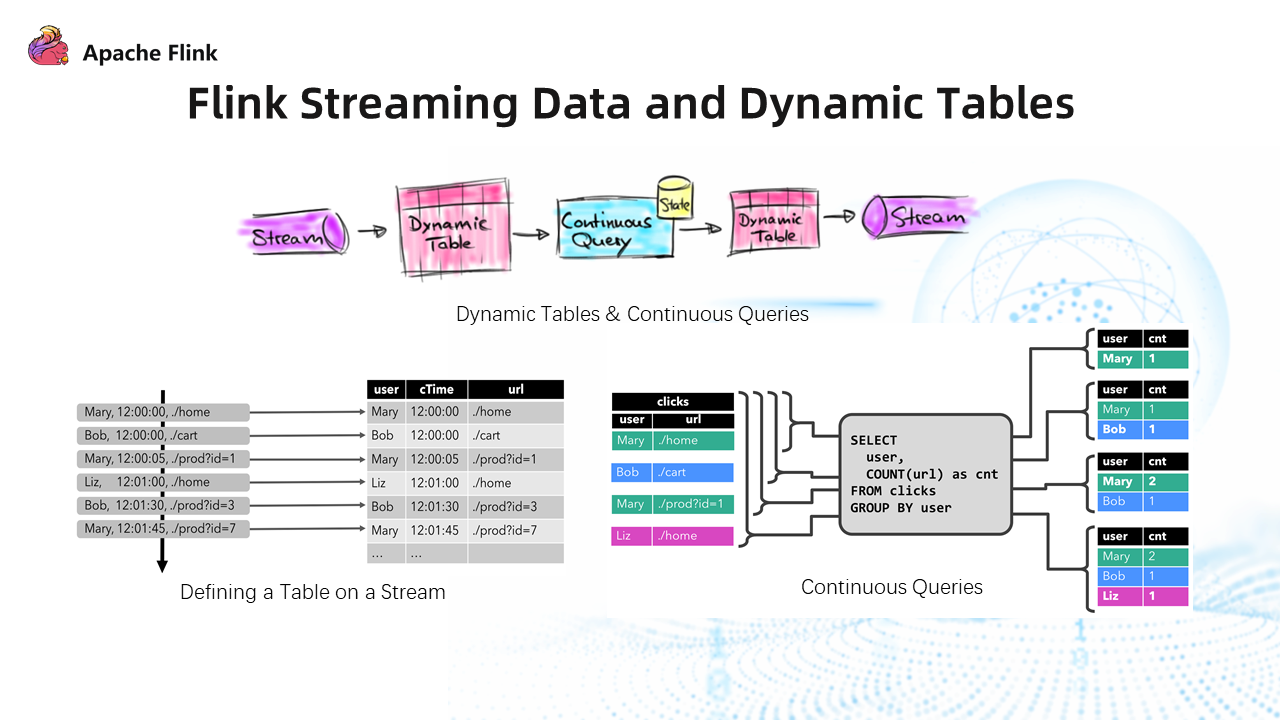
The lower-left corner of the figure above shows how to define a dynamic table. Data streams are converted into tables in Flink in the form of dynamic tables. You can only perform SQL operations if the data stream is converted into a table. After that, Continuous Query queries the growing dynamic table. The obtained data is still presented in the form of a table. Then, the Continuous Query will convert it into a data stream and send it to downstream consumers.
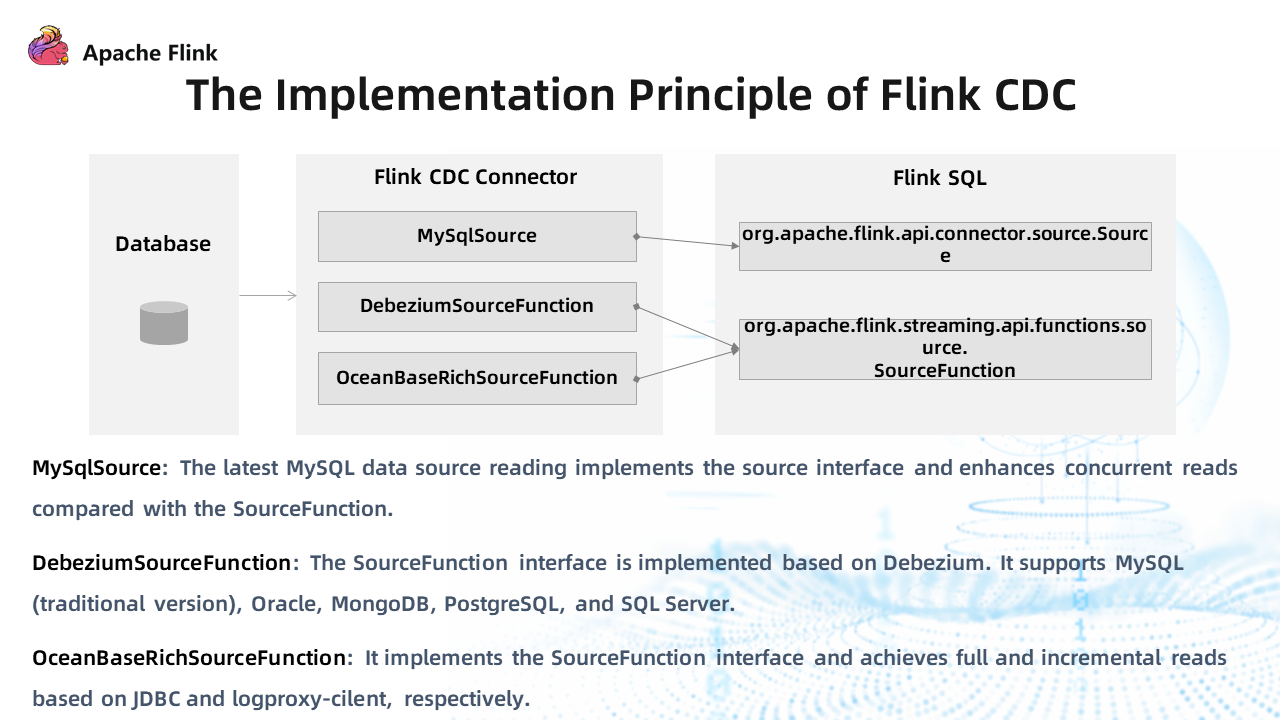
The figure above shows the implementation principle of Flink CDC.
Flink CDC Connector only reads the source data. It only reads the data from the data source and then inputs it to the Flink engine.
The current Flink CDC Connectors are mainly divided into the following three categories:
- MySqlSource: It implements the latest source interface and achieves concurrent reads.
- DebeziumSourceFunction: It implements SourceFunction based on Debezium and supports earlier versions of MySQL, Oracle, MongoDB, SqlServer, and PostgreSQL.
- OceanBaseSourceFunction: It implements the SourceFunction interface and achieves full and incremental reads based on JDBC and logproxy-client.
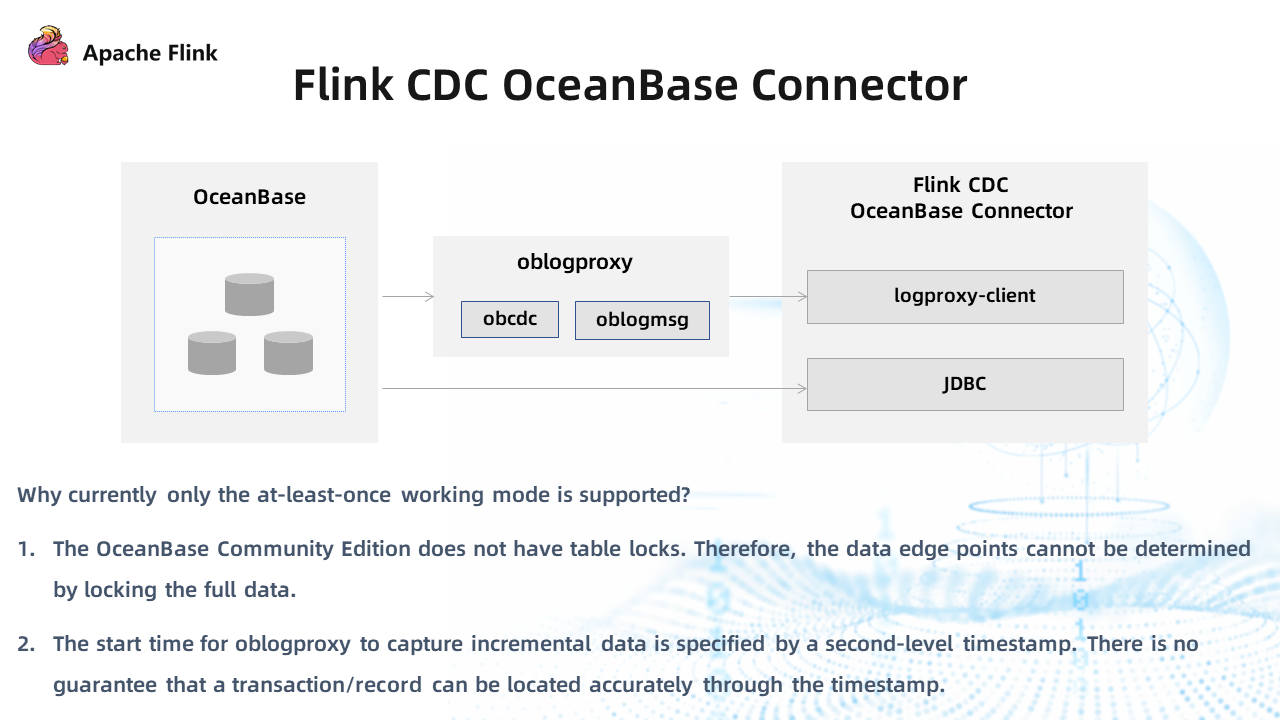
The preceding figure shows the data path of the Flink CDC OceanBase Connector.
Incremental data is captured first through logproxy. The logproxy-client monitors the data stream of incremental logs. After Flink CDC reads the incremental logs, the data will be written to Flink in line with the processing logic of Flink CDC. Full data are captured through JDBC.
The functions supported by the current Flink CDC OceanBase Connector are mainly limited by logproxy. Currently, it supports capturing data at a specified time. However, since OceanBase is a distributed database, you cannot accurately find the starting point of incremental log data. However, if you specify the starting point with a timestamp, there may be some duplicate data.
OceanBase Community Edition does not have table locks in the process of capturing full data. Therefore, the data edge points cannot be determined by locking the full data.
Considering the two aspects above, currently, only the at-least-once working mode is supported, and the exactly-once mode has not been realized.
3. Application Scenarios of Flink CDC + OceanBase
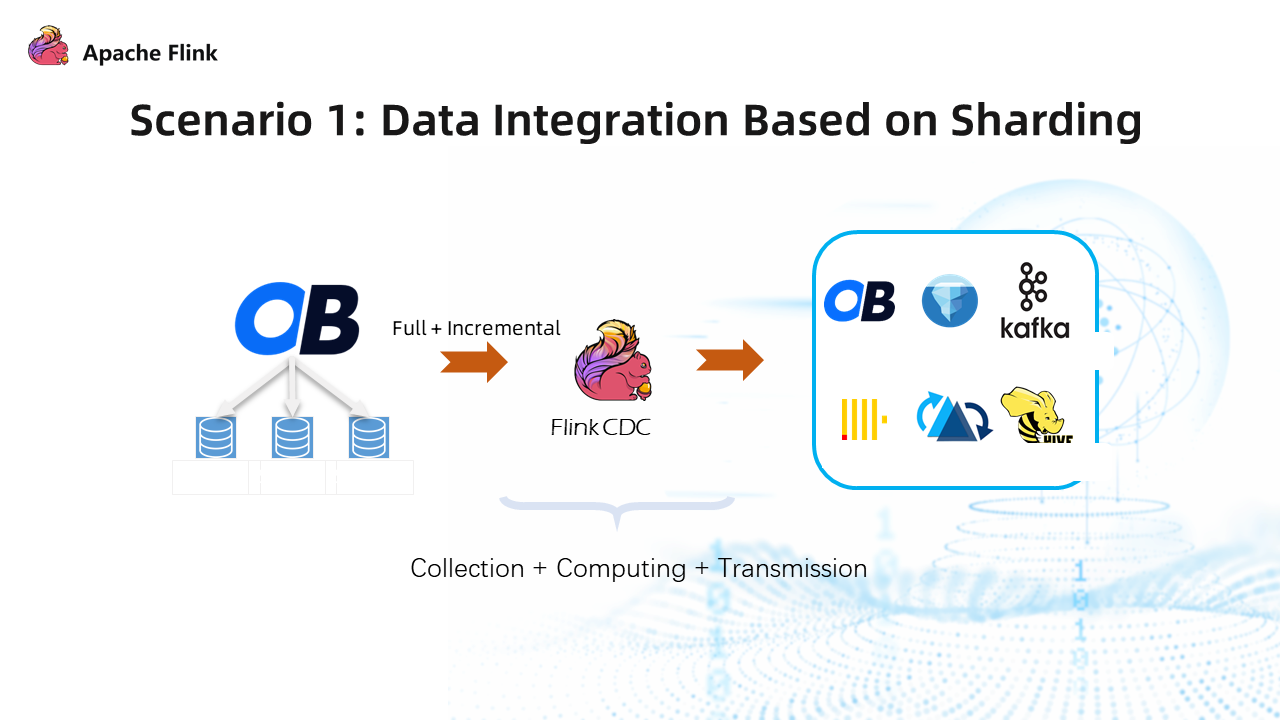
3.1 Scenario 1: Data Integration Based on Database and Table Sharding
Flink CDC supports real-time consistent synchronization and processing of full data and incremental data in tables. OceanBase Connector supports regular expression matching for reading data. For database and table sharding, the OceanBase Connector can be used to create dynamic tables to read data from data sources and write all the data into a table to realize the aggregation of table data.
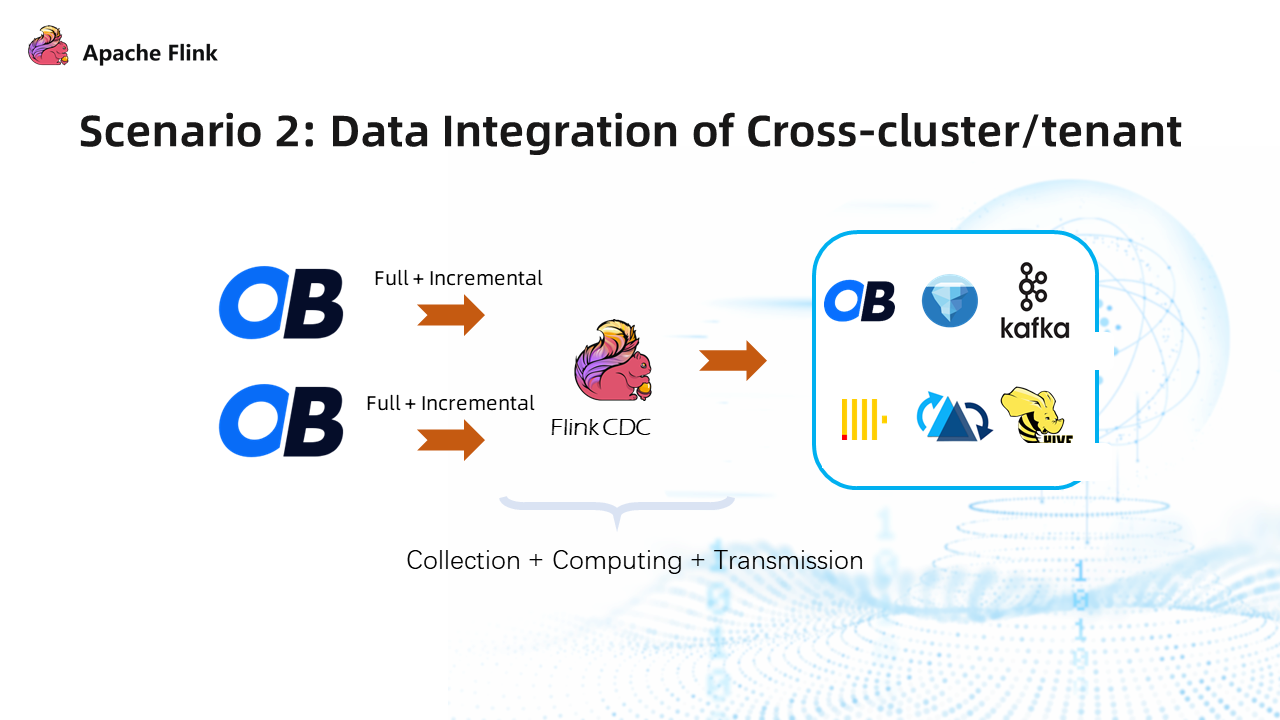
3.2 Scenario 2: Cross-Cluster/Tenant Data Integration
OceanBase is a multi-tenant system. Currently, cross-tenant access is not available for the tenants of the community edition of MySQL. Therefore, if you need to read data across tenants, you must connect with multiple databases to read data separately. Flink CDC is naturally suitable for cross-tenant data reading, in which each tenant corresponds to a dynamic table for data source reading, and then the data converges in Flink.
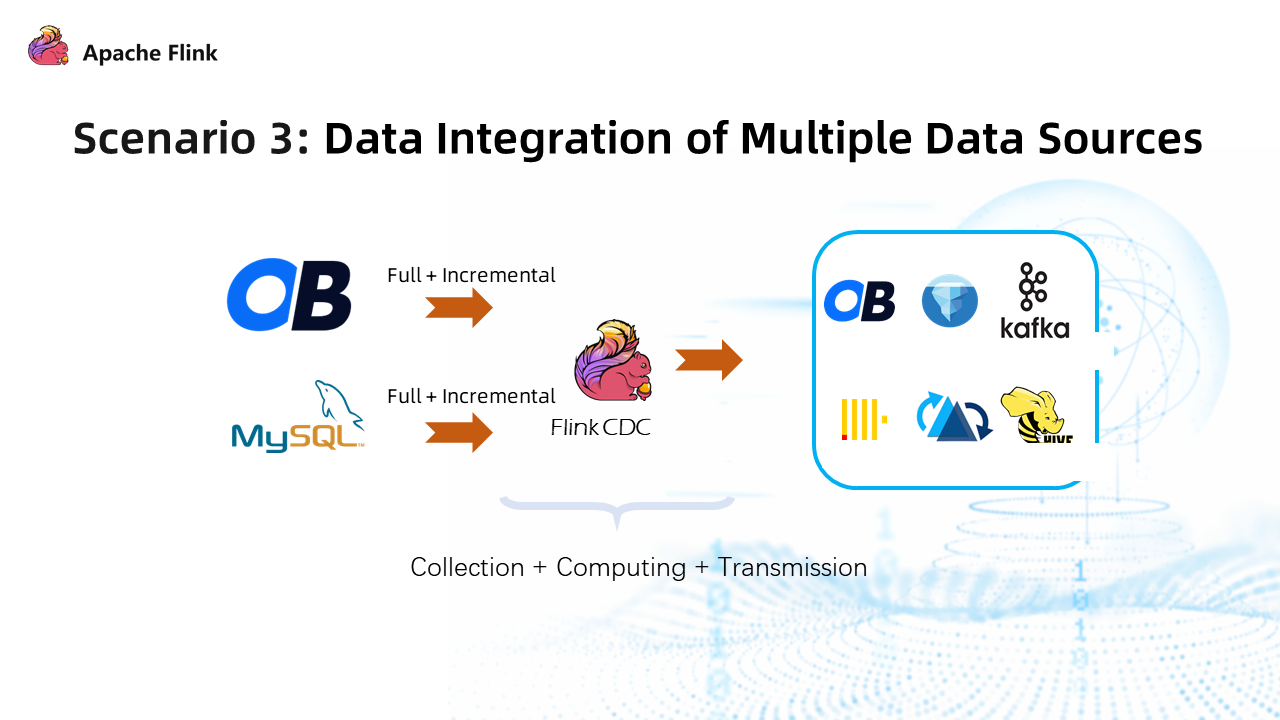
3.3 Scenario 3: Data Integration of Multiple Data Sources
You can aggregate data from different types of data sources. There is no change in cost for the integration of MySQL, TiDB, and other data sources compatible with the MySQL protocol since the data format is the same.
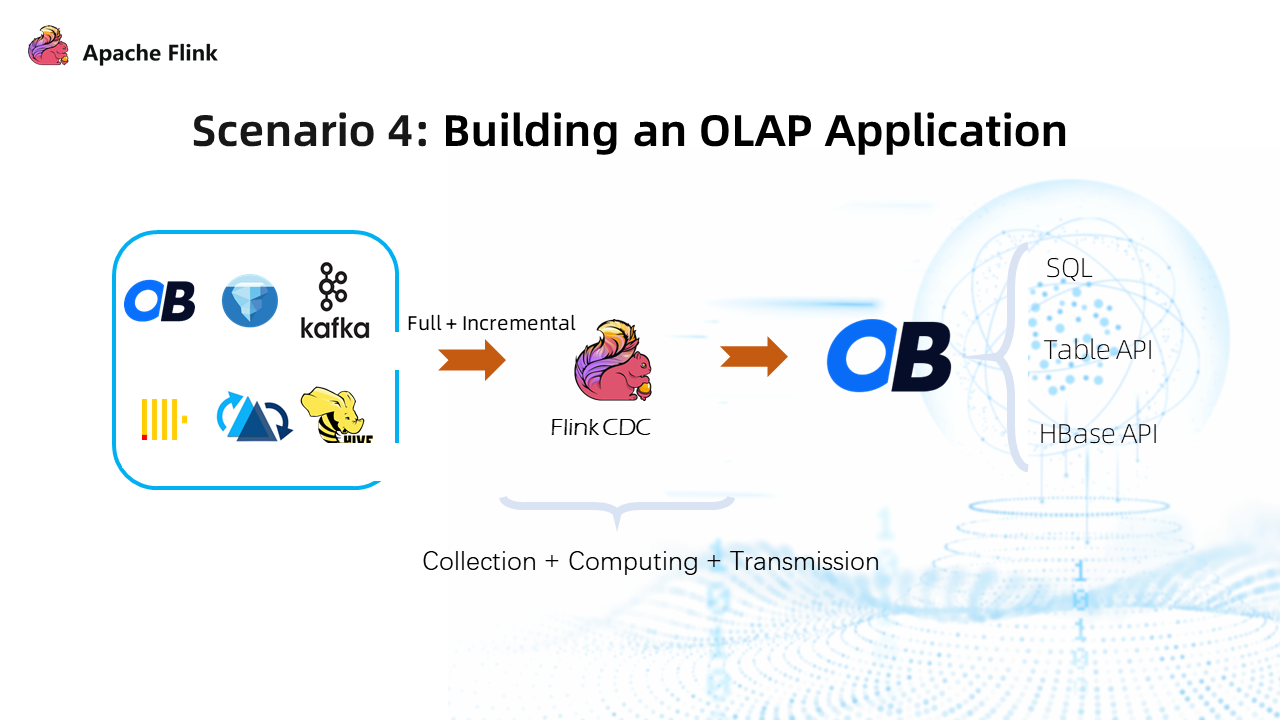
3.4 Scenario 4: Building an OLAP Application
OceanBase is an HTAP database that has a strong TP capability and can be used as a data warehouse. The JDBC connector in Flink allows you to write data to databases compatible with the MySQL protocol. Therefore, you can use Flink CDC to read source data and write this data to OceanBase through the Flink JDBC connector. OceanBase is used as a destination.
OceanBase provides three data processing methods: SQL, Table API, and HBase API. All required components are open-source.
4. The Future of OceanBase Connector

The preceding figure lists the current status of the OceanBase CDC solution.
OMS Community Edition: It is a functional subset of OMS Commercial Edition, but it is not open-source. As a white screen tool, its operation is friendly, and it supports real-time consistent synchronization and processing of full data and incremental data, with data checksum and O&M capabilities. Its disadvantage is that the deployment process is a bit cumbersome. It only supports two data sources, MySQL and OceanBase Community Edition, and does not support incremental DDL.
DataX + Canal/Otter: It is an open-source solution for data migration. Otter is the parent project of Canal. It is mainly aimed at multi-site high availability and supports two-way data synchronization. Its incremental data reading is based on Canal. The advantage of this solution is that it supports a variety of targets and supports HBase, ES, and RDB. The disadvantage is that Canal and Otter do incremental, DataX do full, incremental and full are separated, and data redundancy will occur in the connection part.
Flink CDC: It is a pure open-source solution. The community is active, and the users are growing rapidly. It supports multiple sources and targets as well as real-time consistent synchronization and processing of full data and incremental data. At the same time, as an excellent big data processing engine, Flink can be used for ETL. The downside is that OceanBase Connector currently does not support incremental DDL and exactly-once. Therefore, there may be data redundancy in the overlap between incremental and full data.

We will optimize data reading in the future. Parallelize the full data part and use the new parallel processing framework of the source interface. In the incremental data part, skip the logproxy service and directly capture incremental data from the OceanBase database. Use the obcdc component through the JNI client to directly capture data.
Secondly, enrich the functional features. Currently, Flink CDC only supports OceanBase Community Edition, which uses the same components for incremental log reading as the OceanBase Enterprise Edition. Therefore, OceanBase Enterprise Edition can support incremental log reading, incremental DDL, exactly-once mode, and rate limiting, with only minor changes.
Finally, improve code quality. First, we will operate end-to-end testing. As for format conversion, use runtime converter instead of JdbcValueConverters to improve performance. Implement support for the new source interface (parallel processing framework).
Q&A
Q: How about the usability and stability after Flink CDC OceanBase Connector is open-source?
A: In terms of usability, we have successively developed many open-source components with the support of non-open-source community editions (such as OMS and OCP). In terms of stability, OceanBase has been widely used in Ant Group, and the MySQL-compatible version has been put into large-scale applications in more than 20 enterprises. Therefore, there is no need to worry about its stability.
Q: Where is metadata (such as the shard information and the index information) stored in OceanBase?
A: They are stored in the OB server and can be directly queried through SQL.